基于K-means聚类的城市轨道站点周边共享单车需求预测方法研究
2023-09-28胡雅群哈米提许子凯
胡雅群,哈米提,许子凯
(1.新疆维吾尔自治区交通建设管理局项目执行三处,乌鲁木齐 830000;2.长安大学公路学院,西安 710064)
0 引言
共享单车大提高了公共交通利用效率.在城市轨道交通与共享单车接驳需求预测的研究方面,学者们主要关注预测模型的比较和改进[1].Zilu Kang等[2]利用机器学习构建了3类预测模型,并比较模型优劣.此外,其他学者也提出了不同的预测方法,如基于马尔可夫链模型的预测方法[3-4]、贝叶斯分类[5]引入注意力机制的长短时记忆网络预测模型[6]、二元Logit选择模型[7-8]等.综合现有研究可知,轨道交通接驳共享单车需求预测的研究主要关注于预测模型的比选.此类研究通常采用传统的线性回归预测和时间序列预测作为起点,转变为数据驱动型预测方法.然而,目前的研究多采用单一预测方法,而对于组合模型的精度比较研究仍有提升空间.
针对轨道交通站点接驳共享单车停车分类研究,研究人员通常关注轨道交通站点的功能定位和停车需求特征.轨道交通站点是城市公共交通布局的核心,随着地铁物业的发展,使其成为城市集聚关键点[9-10].CERVERO[11-13]聚焦于香港地铁,站点被聚为5类,计算了地体规模开发强度及混合度均值.其他研究,针对不同区位[14]、不同交通功能[15]将轨道交通站点划分为不同类别.但是,由于轨道站点分类有差异,致使接驳的共享单车停放需求特征差异,产生不同类型站点配合停车设施规模不同的结果.值得注意的是,目前很少有研究考虑到不同类型的轨道交通站点对共享单车停车规模的影响,这导致共享单车在城市轨道交通站点周围的投放显得无序.因此,为了合理配置共享单车停车设施,需要进一步研究不同类型轨道交通站点的停车需求特征和对共享单车停车设施规模的影响.
基于上述分析,本文以K-means聚类算法进行分析,将分时段共享单车借还量作为变量,构建随机森林和套索回归算法下城市轨道站点周边共享单车需求预测模型,最终对比不同算法下需求预测结果,为后续研究起到参考价值.
1 城市轨道站点K-means聚类方法
1.1 城市轨道站点K-means聚类算法步骤
1)选择K个聚类中心;
2)计算各站点到聚类中心的间距,以距离作为条件进行分配;
3)更新每个簇的聚类中心,如果变化则重新进行分配,直到收敛;
4)输出聚类结果.
在开始之前,需要选择合适的距离度量方法和目标函数来计算聚类质心.计算误差平方和:
(1)
(2)
式中,SSE为误差平方和;k为聚类簇的数量;Ci为第i个簇;x为样本数据;μi为第i个簇Ci的聚类中心(质心).
1.2 K-means聚类簇数估计
在轨道交通站点K-means分析中,多利用站点周围土地利用维度、时间空间维度、商业经济维度.然而,这些变量对于共享单车连接站点需求差异的解释并不直观.因此,本文利用站点周边分时段共享单车借还量作为变量.
轮廓系数(Sihouette Coefficient)用来评估聚类簇离散程度.当轮廓系数值离1近时,即效果越好,密集度越高;当轮廓系数值越接近-1时,即分离度高,结果不合理;轮廓系数计算见式(3):


(3)
式中,ai为样本点i的簇内不相似度;bi为样本点i的簇外分散度;i为样本数.
如图1所示,聚类簇数为5时,轮廓系数的值为0.856,为聚类结果中最接近1的簇数,故本文将轨道交通站点类型划分为5类,为了达到最好的结果.

图1 轮廓系数确定聚类簇数
2 城市轨道站点周边共享单车需求预测方法
2.1 随机森林算法
随机森林是机器学习中的分支集成学习算法[17-19],即训练时从原始数据集N里面,有放有回的抽取样本,从而得到训练集,但这样会导致1个样本可能会重复出现.根据统计学理论,当n足够大时,1个样本不会被取到的概率约为0.368.
(4)
本文对m个结果计算算术平均值,从而得到弱学习器最终结果.即Bagging集成算法,它通过将多个模型的预测结果进行平均或投票等方式计算结果.如图2所示.

图2 集成学习示意图
随机森林算法如图3所示.

图3 随机森林算法示意图
2.2 套索回归算法
套索回归是由Robert Tibshirani提出的线性回归方法.
给定数据集D=[(x1,y1),(x2,y2),…,(xm,ym)].线性回归模型优化函数为:
(5)
式中,θ为函数的回归系数;y为预测值;L为线性回归优化函数;x为样本数据.
为了缓解函数过拟合,本文采用套索回归模型正则化范数L1,从而式(5)变为:
(6)
3 实例分析
3.1 数据来源
2017年由《共享单车与电动车停放》研究表明,2017年北京地区摩拜共享单车的投放量占总量的40%,具有相对的代表性.故本文数据使用2017年摩拜单车在北京地区数据.同时为了进行轨道站点接驳共享单车分布解析,笔者提前对数据进行筛选和清洗,留下合理的数据集.
3.2 城市轨道站点K-means聚类空间分布与结果
3.2.1 K-means聚类结果分布
通过计算轮廓指标系数,确定了最佳的聚类簇数为5,并使用Python程序实现了K-means算法,并获得了5类轨道站点的聚类结果.根据聚类结果,轨道站点类型被分别记为类型1~5,分布情况如图4所示.

图4 各类站点在北京城市轨道上的分布情况
站点类型的具体统计如表1所示.
3.2.2 K-means聚类结果分析
本节根据前文的聚类结果,得到五大类站点的共享单车借还状况.通过标准化处理不同时段共享单车借还量,进而利用借还时间变化图清晰展示借还特征.结果见表2.
由表2可知,类型2早高峰借车率最低、晚高峰借车率最高,类型3早高峰还车率最低、晚高峰借车率最高.相反,类型2晚高峰最低,类型3早高峰借车率最高,晚高峰借车率最低.
见图5,结合不同类型轨道站点共享单车借还率分析得到对应类型:
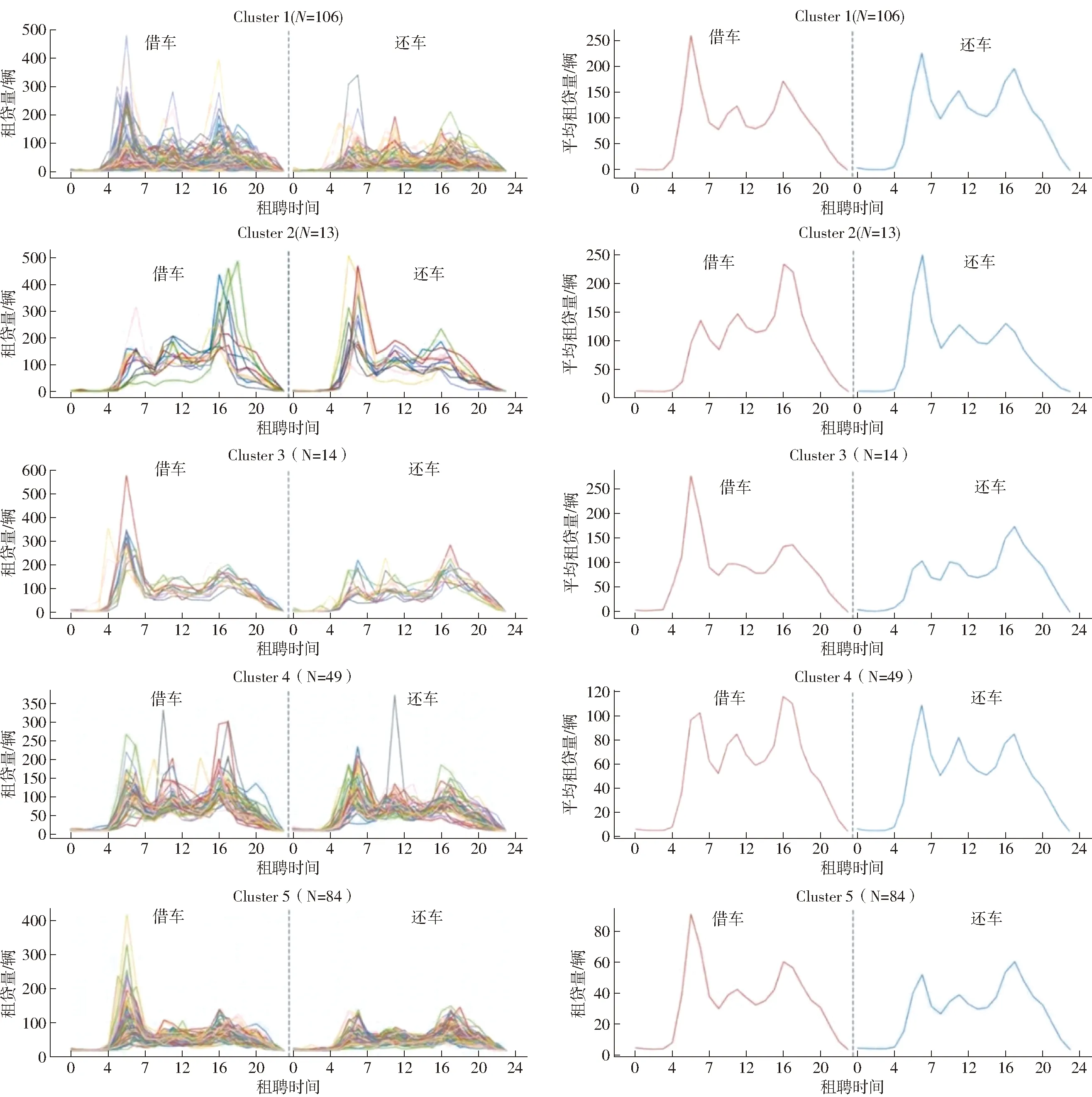
图5 共享单车时均借还率时间变化图
1) 类型1从表中可看出,在早高峰时段,还车率略低于借车率.在晚高峰时段,借车率低于还车率.符合“居住就业混合型”站点特征.
2) 类型2从表中可看出,在早高峰时段,该类型站点的还车率远高于借车率.在晚高峰时段,借车率远高于还车率.符合“居住型”站点特征.
3) 类型3从表2中可看出,在早高峰时段,该类型站点的借车率远高于还车率.在晚高峰时段,该类型站点的还车率远高于借车率.符合“就业型”站点特征.
4) 类型4轨道交通站点在早高峰时段的借车量占全天借车总量的16.61%,而在全天还车总量中,早高峰时段的还车量占17.76%.符合“居住就业商业混合型”站点特征.
5) 类型5在早高峰时段,该类型站点在早高峰时段的借车率高于还车率.此外,在晚高峰时段内,还车率高于借车率.符合“以居住为主的居住就业混合型”站点特征.
3.3 算法对比下的轨道站点周边共享单车需求预测分析
3.3.1 实验验证评价标准
EV(解释方差):
(7)
MAE(平均绝对误差):
(8)
MSE(均方误差):
(9)
R2(决定系数):
(10)
式中,m为测试集数量;yi为测试集上的真实值;i为测试集上的预测值;为实际的平均值.
实验验证评价标准中EV、R2的值接近1代表预测效果越好,MSE、MAE值越小代表预测精度越高.
3.3.2 随机森林预测结果
随机森林预测结果如图6所示.

图6 随机森林预测结果
随机森林模型可对特征进行重要度评分,不同站点重要度如图7.
图7表示,类型4站点在午高峰期间具有较高的特征重要度,这与其自身的特性有关.不同类型的站点受特征影响的程度也不尽相同.对随机森林模型结果进行评估.评估结果见表3.

表3 随机森林预测结果评价
3.3.3 套索回归预测结果
套索回归预测效果对比结果如图8所示.

图8 套索回归预测结果
套索回归训练结果如图9所示.

图9 套索回归模型指标重要性评估
根据图9,在套索回归模型中,站点小时共享单车使用情况影响最大.结果见表4.

表4 套索回归模型预测结果评价
综上所述,随机森林模型在预测类型1、2、3、5站点上预测精度优于套索回归模型.套索回归模型在类型4预测结果优于随机森林模型.
4 结束语
建立精度更高的组合模型,本文旨在提供共享单车在不同类型轨道交通站点周边的使用情况,并比较了在不同类型轨道站点周围需求预测中随机森林和套索回归2种算法的精度,为后续轨道站点和轨道站点周围停车设施的规划和建设提供参考价值.
本文利用共享单车借还量为聚类变量,聚为5类站点.这些类别分别对应特征:类型1~5分别为居住就业混合型、居住型、就业型、居住就业商业混合型、以居住为主的居住就业混合型.进而使用随机森林和套索回归2种算法构建需求预测模型,对5类站点计算其结果.进而利用EV、MAE、MSE和R2评估预测结果.结果表明,除类型4以外站点,随机森林模型预测结果中表现最好.
