融合双通道特征学习机制的图像铅垂方向识别
2023-09-24施泓羽杜韵琦
施泓羽,杜韵琦,贺 智,2*
(1. 中山大学地理科学与规划学院,广州 510275;2. 南方海洋科学与工程广东省实验室(珠海),珠海 519082)
0 引言
近年来,图像铅垂方向(image vertical direction,IVD)识别的应用场景和需求与日俱增[1-2],而各类传感器的高速发展使得图像数据呈指数级增长,IVD 识别因此具有更加重要的研究价值和更广阔的应用前景:例如,在智能驾驶领域,通过对IVD 的正确识别有利于更好地矫正图像畸变,提高对道路线和地平线的识别精度[3-4];在无人设备领域,无人机、无人车等的迅猛发展也对设备姿态自动调整有了新的需求,识别IVD有助于准确调整设备姿态[5]。但目前尚无可用的图像的观察垂直方向与IVD 一致的数据集与成熟的IVD 识别方法,因此IVD 的识别是一项具有挑战性的任务。
传统可用于检测IVD 的算法(如Hough 变换[6]、SIFT 变换[7]等),当图像较为复杂时,难以仅依据图像自身特征实现高精度IVD 识别。近年来,深度学习技术获得了快速发展,已有大量研究聚焦于自然语言处理[8]、目标检测[9]、图像分类[10]和姿态估计[11]等领域。且其中很多方法都引入了角度,可大致将其归纳分为三类:①在数据预处理阶段引入角度,通过多次旋转图像达到扩增数据集的目的[12-13],使网络模型更好地学习数据集的旋转不变特征。该类方法在测试类别相同但姿态各异的图像时,能获得更好的泛化能力,但由于其数据扩增数量有限,学习到的旋转不变特征不够完整;②在模型预训练阶段引入角度[14-15],通过旋转角度分类任务将经过随机旋转的图像输入网络,由自监督学习提取结构或语义信息,从而在图像检测和分割等任务中获得更快的收敛速度和更高的训练精度。该类研究证明了图像分类算法在IVD识别方面的可行性,但仅识别少数几个角度(如0°、90°、180°、270°等),因而IVD 识别范围有限;③在网络模型中引入角度[16-18],典型的如目标检测[16],通过引入角度来旋转并最小化目标框。但其使用的研究数据为俯拍的遥感影像,只存在观察方向而丢失IVD,所以其研究成果难以迁移至IVD 的识别上。总之,已有研究对IVD 的识别具有局限性,无法满足精确识别IVD的任务需求。
针对上述问题,本文提出融合双通道特征学习机制的网络模型(double channel feature learning model,DouCFL)的IVD 识别方法,主要贡献如下:①据笔者所知,目前尚无专门进行IVD 识别的研究,本文首次提出一种准确识别IVD 的方法。DouCFL 由数据预处理模块、特征学习模块以及IVD 识别模块三个模块组成,并创新性地提出随机旋转组合的数据增广方法、“特征复用+特征生成”的双通道特征学习方法和顾及物体类别识别与IVD 识别的损失函数,使网络模型能够有效识别图像内容并学习其旋转不变特征。②针对用于IVD 识别的数据集缺失的问题,创建了一个新数据集RotData。本文从ImageNet-1k 数据集[19]中提取了近70000 张正直图像(即图像的观察垂直方向与IVD 一致),创建了一个名为RotData 的图像数据集,并公开了下载网址,便于相关领域的研究者进行模型训练和测试。
1 RotData数据集构建
ImageNet 数据集是深度学习领域中图像分类、检测、定位的最常用数据集之一[19]。但是,当深度学习任务转变成识别IVD 时,ImageNet数据集中的某些图像并不适用。例如,从顶部或底部观察的物体,或图像物理环境信息过少的,如图1(a)所示,这些图像是模糊的(即只可确定图像的观察垂直方向而无法确定IVD),利用它们进行模型训练会严重影响深度学习模型对图像特征的理解与学习。所以,本文以ILSVRC2012(ImageNet Large-Scale Visual Recognition Challenge 2012)为基础数据集,该数据集共有1000 个类别,每类约有1000 张图像。本文从ILSVRC2012 数据集中挑选了383 个较易确定图像是否正直的物体类别(图1(b)为部分示例),并在这些类的约1000 张图像中分别挑选170 张正直图像和10 张模糊图像,组成了一个由约70000 张图像组成的旋转数据集RotData,将其用于模型训练和测试。RotData 已公开于https://doi.org/10.6084/m9.figshare.c.6085845.v2。

图1 ILSVRC2012中模糊图像和正直图像示例
2 基于DouCFL的IVD识别方法
2.1 整体方法架构
DouCFL 的整体架构如图2 所示。首先,在数据预处理模块中对输入的原始图像进行预处理,将大小不一的原始图像统一成尺寸为384×384像素的输入图像,然后对输入图像分别进行0~359°角度范围内的随机逆时针旋转,并添加圆形掩膜,以防止模型忽略主体对象特征而学习图像的边缘信息。在模型训练的每一次迭代中,该预处理操作都会重复,且在每个Epoch中,RotData 数据集也将重新随机打乱,通过该“随机旋转组合”操作来扩增数据集,模型能更全面地学习到图像的旋转不变特征,从而更好地识别IVD。其次,将预处理后的数据输入至特征学习模块,经过特征复用通道和特征生成通道的“双通道”操作,输出长度为360的角度特征向量以及长度为383 的类别特征向量。最后,在IVD 识别模块中,输入角度特征向量、类别特征向量、旋转角度标签和物体类别标签,通过同时识别IVD 的偏离角度与物体类别来计算模型的旋转损失(rotation loss,RotLoss)。

图2 DouCFL模型架构
2.2 特征学习模块
为使模型更全面地学习旋转不变特征,DouCFL Net 采用如图3 所示的结构,将预处理后的图像输入Stage 1、Stage 2、Stage 3、Stage 4、Stage 5 和Output六个模块后得到输出长度为743特征向量。其中,Stage 1~Stage 5模块以DouCFL Block 为基础结构,Conv 代表卷积层,Maxpool代表最大池化层,通道数后圆括号内的数字为DouCFL Block 中特征生成通道的通道数。

图3 DouCFL Net网络结构
DouCFL Block 的结构如图4 所示,其通过“双通道”(即特征复用通道和特征生成通道)来提升对旋转不变特征的学习能力。假定xi为DouCFL Net 的第i个DouCFL Block 的输入特征图,首先对xi进行通道降维(1×1卷积层);然后通过卷积提取图像特征(3×3卷积层),并利用分组卷积压缩模型参数;其次将提取到的图像特征进行投影以与xi保持维度的一致(1×1 卷积层),得到特征图(xi)in;再通过通道分裂操作将(xi)in分裂成和,分别作为输入特征图输入至特征复用通道与特征生成通道,得到复用特征和新生成特征;最后通过通道联结操作将特征图和合并,得到输出特征图xi+1,即第i+ 1 个DouCFL Block 的输入特征图。其中,特征复用通道通过残差相加来强调对初始特征xi的复用,以防止特征退化;而特征生成通道则保留了3×3 卷积层中新提取的图像特征,以跳脱复用特征而寻找新特征。
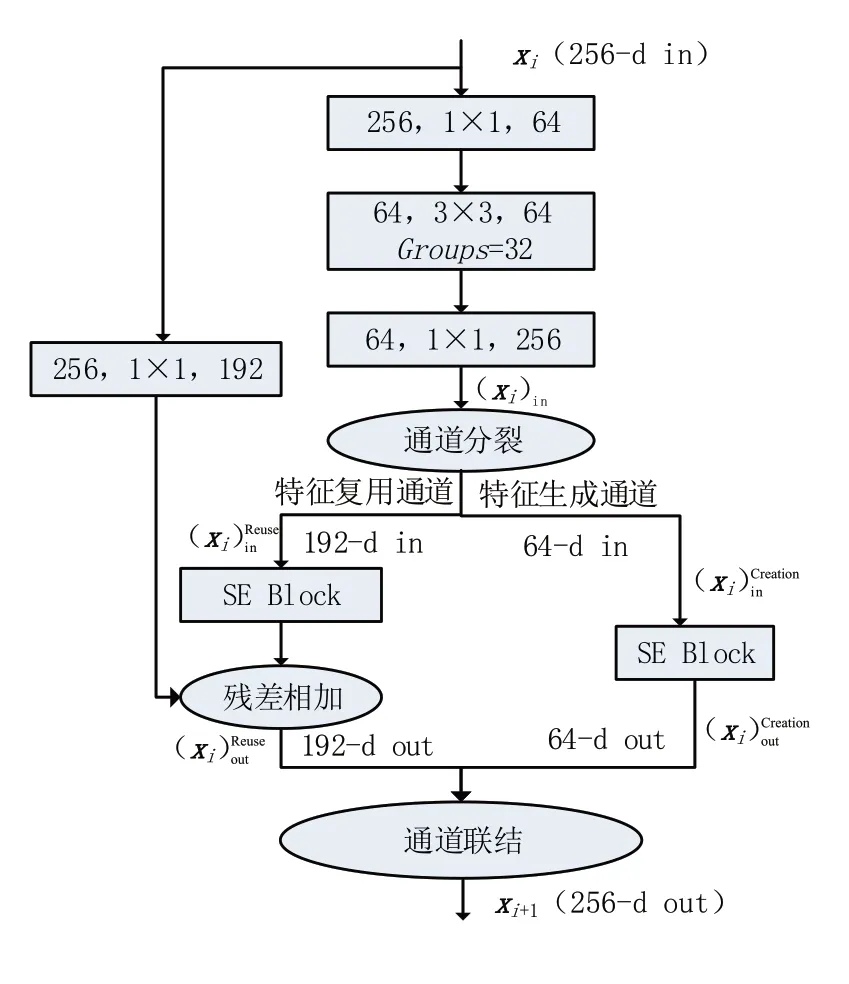
图4 DouCFL Block结构(以Stage 2为例)
另外,在特征复用通道与特征生成通道中引入通道注意力模块SE(squeeze-and-excitation)Block[20],它可以对特征图进行重标定, 对每个特征图学习一个对应的权重,以筛选出复用特征和新生成特征中的有效信息,达到突出重要特征的作用。而为确保DouCFL Block 的输入和输出维度相同,增加了一个卷积核大小为1×1 的卷积层,将该Block 的输入特征xi映射到更低的维度上,进而使DouCFL Block 在不改变输入输出特征维度的基础上学习图像新特征。
具体而言,假定xi为DouCFL Net 的第i个DouCFL Block 的输入与输出数据,则xi+1可由以下计算过程得到:
其中:Split(· ) 代表通道分裂操作;Θi(· ) 代表SE Block 的注意力函数;Φ( ·) 代表转换函数,用于将DouCFL Block 的输入特征x映射到更低的维度;Concat(· ) 代表通道联结操作。
DouCFL Net 中各模块的具体结构参数见表1。其中,分组卷积的分组数量为32,圆括号内部数字表示每个DouCFL Block 中特征生成通道的通道数。

表1 DouCFL Net结构参数
2.3 IVD识别模块
对图像内容(即图像中物体类别)的正确识别可以帮助模型更好地寻找图像的旋转不变特征[14-15]。为使模型能更有效地学习该特征,本文在IVD 识别模块中加入物体类别识别部分,构建同时识别IVD 的偏离角度与物体类别的损失函数RotLoss。假定给定一个预处理后的训练集(Xj为S中第j个图像的矩阵表达,N为样本数目),则RotLoss可以表示为
其中:θ代表DouCFL Net中IVD偏离角度识别部分的可被学习的模型参数;代表DouCFL Net中物体类别识别部分的可被学习的模型参数;α为权重系数;Loss(· ) 为分类损失函数;c为旋转角度标签;z为物体类别标签;而分类损失函数Loss(· ) 可以表示为
其中:τ代表DouCFL Net 中可被学习的模型参数;label为Xj的真实标签;β是用以平滑分类损失的权重;M为类别总数;Pk(Xj|τ)代表模型在参数为τ的条件下,识别Xj的类别为k的概率值。
3 实验
3.1 实验环境
本文深度学习框架为PyTorch,操作系统为Ubuntu 18.04 LTS,硬件设备为4 张24 GB 显存的NVIDIA RTX A5000 GPU 和56 张Intel(R)Xeon(R)Gold 6330 CPU。
3.2 实验数据
以RotData 为实验数据集,将该数据集以7∶1.5∶1.5 的比例划分为训练集、验证集和测试集。
3.3 实验参数设置
本文实验参数设置如下:BatchSize为20(即全局BatchSize 为80);Epoch 为200;使用SGD(stochastic gradient descent)优化器,初始学习率为0.01,优化器动量设置为0.9;学习率调整策略选用Cosine Annealing 和Warm Restart[21],并设置每50 个Epoch 进行一次重启;RotLoss的参数α设为0.75,β设为0.1。
在模型测试过程中,选取角度特征向量最大值对应的类别索引作为预测的IVD 偏离角度,并与旋转角度标签一起输入角度均方误差(angle mean square error,AngleMSE)和准确率(accuracy,AC)来评估模型的效果。模型的测试精度取在测试集上连续进行六次效果评估(测试集在每次效果评估过程中都经过“随机旋转组合”预处理)的平均值。
3.4 评价标准
本文使用角度均方误差AngleMSE和准确率AC作为指标来对算法的效果进行衡量,其公式如下:
其中:n表示样本数量,Yl表示第l个样本的旋转角度标签,表示第l个样本的预测的IVD 偏离角度。AngleMSE相较于均方误差(mean square error,MSE),考虑了预测的IVD 偏离角度和旋转角度标签之间的类间关系。例如,真实旋转角度标签1°和预测的IVD 偏离角度359°之间实际偏差为2°,而非358°。
3.5 实验结果
为了验证DouCFL 模型的有效性,本文选取了5种图像分类中的流行深度学习方法与其对比,分别是AlexNet[22]、ResNet-152[23]、DPN-107[24]、ConvNeXt-B[25]和Swin-B[26],并使用相同的数据预处理模块和IVD识别模块完成IVD识别任务。
首先,RotData 数据集上不同网络模型的对比实验结果如表2 所示。从表2 可以看出:DouCFL 在IVD 识别任务上优于目前流行的深度学习方法。DouCFL 在测试集上的AngleMSE为256.85,即对测试集中图像偏离铅垂方向的角度的预测误差约为16°,且在测试集上的AC达到了97.68%,其对IVD 有较高的识别精度。此外,DouCFL 的AngleMSE低于基础模型AlexNet 和ResNet-152。与同等参数量的深度学习方法(即DPN-107、ConvNeXt-B 和Swin-B)相比,DouCFL的AngleMSE至少降低了45,AC至少提升了约0.5%,这说明在同等参数量的条件下,DouCFL具有更强的旋转不变特征学习能力。

表2 RotData数据集上不同网络模型的对比实验
其次,不同损失函数的对比实验结果如表3所示。从表3 可以看出:本文提出的损失函数RotLoss能有效提升模型对IVD 的识别效果。将损失函数RotLoss和不关注物体类别的损失函数Loss(即将RotLoss的参数α 设为1)进行对比,对于不同的深度学习方法,RotLoss都能有效降低模型的AngleMSE。对于基础模型AlexNet 和ResNet-152,RotLoss能使模型的AngleMSE分别降低18.02%和8.37%。对于同等参数量的深度学习方法(即DPN-107、ConvNeXt-B、Swin-B 和DouCFL),RotLoss能使其AngleMSE至少降低8.05%(DPN-107:12.30%,ConvNeXt-B:11.78%,Swin-B:8.05%,DouCFL:23.64%)。

表3 不同损失函数的对比实验
为了进一步解释RotLoss对于降低模型AngleMSE的效果,对模型学习到的图像旋转不变特征进行了可视化,图5 展示了DouCFL Net最后一层特征图的反向传播图[27]。其中,第1列为原图像,第2 和第5 列为预处理后的图像,第3 和第6 列为采用RotLoss损失函数训练的DouCFL Net 的反向传播图,第4和第7列为采用Loss损失函数训练的DouCFL Net 的反向传播图。由图5(a)、(c)和(d)可知,对于包含多个物体的图像,引入RotLoss可以使模型更加聚焦于物体类别标签所对应的物体,并能准确学习到它的旋转不变特征,如熊猫的五官、灯塔的塔身、狗的五官和身体。由图5(b)可知,对于只包含单个物体的图像,引入RotLoss可以使模型准确聚焦于图像中物体的显著旋转不变特征,如车头、前轮和车牌号。而对于采用Loss损失函数训练的DouCFL Net,其反向传播图关注的特征分布广泛且分散,且关注了较多环境中的干扰信息。这也证明,对图像内容即物体类别的正确识别,可以帮助模型更有效地学习图像的旋转不变特征,从而提升对IVD的识别效果。

图5 DouCFL Net最后一层特征图的反向传播激活图(续)

图5 DouCFL Net最后一层特征图的反向传播激活图
最后,通过消融实验进一步验证DouCFL Block 中各组成部分的有效性。如表4 所示,在DouCFL Net中去除特征生成通道与SE Block(即为加入分组卷积的ResNet-152)后,与ResNet-152相比精度基本保持不变,但是参数量减少29 M;在加入SE Block 后,模型精度(305.48)有所提升;在加入了特征生成通道后,模型精度(274.63)进一步提升;同时加入SE Block 和特征生成通道后,模型精度最终提升到了256.85,与只加入特征生成通道相比提升了近18。总之,SE Block和特征生成通道的引入能够有效提升模型在IVD识别任务上的效果。
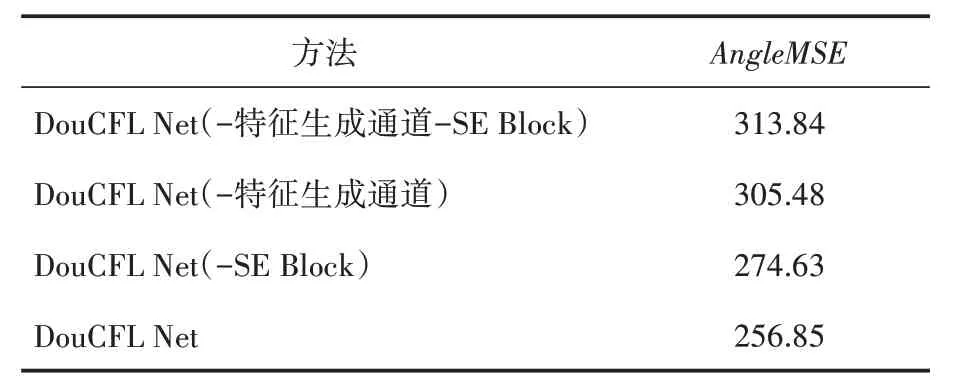
表4 DouCFL Block中各组成部分的对比实验
4 结语
本文提出了一种基于DouCFL 的图像铅垂方向识别方法,其由数据预处理模块、特征学习模块以及IVD 识别模块三个模块组成,并通过随机旋转组合的数据增广方法、“特征复用+特征生成”的双通道特征学习方法和顾及物体类别识别与IVD 识别的损失函数,使模型能够有效识别图像内容并学习其旋转不变特征。
本文根据ILSVRC2012 创建了用于IVD 识别的正直图像数据集,并利用该数据集训练提出的IVD 识别方法。实验结果表明,本文方法对IVD 识别具有一定的可行性,且识别正确率优于当前流行的深度学习方法。此外,对损失函数的对比实验结果表明,本文的损失函数能有效提升各类模型对物体旋转角度的识别效果,证明了对图像内容的正确识别可以帮助模型更有效地学习图像的旋转不变特征。下一步将对图像的旋转不变特征进行系统化地解释,并结合实际应用需求创建规模更大、类别更加丰富的数据集进行训练和测试。
