基于异构图病历注意力网络的临床辅助诊断研究
2023-09-18李勇,冯俐,王霞
李 勇,冯 俐,王 霞
(1.西北师范大学计算机科学与工程学院,甘肃 兰州 730070;2.新疆理工学院信息工程学院,新疆 阿克苏 843100;3.甘肃省人民医院药剂科,甘肃 兰州 730000)
1 引言
电子病历EMRs(Electronic Medical Records)是医疗机构的电子设备中保存、管理的数字化的病人诊疗记录,主要包含患者在就诊过程中产生并被记录的完整、详细的临床信息,电子病历的积累为健康医疗领域的研究和智能应用奠定了坚实基础。近年来,基于深度学习模型的电子病历分析在健康医疗领域得到广泛应用,例如疾病风险评估[1]、表型分析[2]和药物推荐[3]等。疾病预测[4-6]是深度学习模型在健康医疗领域重要的应用场景之一,常用于预测患者是否患有某种疾病,以便进一步提高个性化诊疗的质量。然而,已有的疾病预测模型都存在不足。
首先,EMRs数据存在不平衡问题。现有的临床决策支持系统CDS(Clinical Decision Support)大多基于人工构建的知识库,通过规则匹配进行辅助诊断,由于隐私保护等原因,公开发布的电子病历数据量非常有限。而且不同病症因发病率不同[7],导致电子病历数据中不同病症数据分布也存在不平衡问题,训练一个健壮且可靠的分类器需要收集大量的电子病历数据,这些数据必须满足完整性、一致性和可理解性等特征,在实践中,对于数据的这些要求极难做到。
其次,EMRs数据存在异构性。EMRs数据中蕴含的多种实体和实体间不同的语义关系,表现出明显的异构性[8],传统的同构建模方法无法有效处理这些复杂的结构信息,无法识别出有意义的实体和路径关系信息。在疾病预测中,如何选择患者节点最有意义的邻居节点和语义关系,并为它们赋予适当的权重是一个尚未解决的难题。
最后,EMRs情境信息多源,除了包含患者的病情描述之外,还包含患者基本信息、诊疗过程和生理记录等情境信息[9]。这些信息对细化患者病情诊断有辅助作用,但由于其既不规则且又无序,很难对其进行结构化处理[10],以往的研究丢弃了这些情境信息,降低了预测准确率。
针对以上问题,本文主要进行了以下3方面研究:(1)提出了一种基于异构图病历注意力网络的临床辅助诊断HCAD(Clinical Assistant Diagnosis based on Heterogeneous graph)模型,基于外部医学知识图谱,将领域知识与电子病历的内部信息进行融合,解决了数据不平衡问题;(2) HCAD模型中增加了分层注意力机制,使得患者节点的嵌入表示能更精确地捕捉到异构图病历网络的结构信息和语义信息;(3) 将电子病历中多种情境信息纳入患者节点嵌入表示,有效提高了预测准确率。在真实电子病历数据集上进行实验,结果表明,在高血压、心脏病等10种常见疾病预测任务上,本文提出的HCAD模型在F1值和其他评价指标上均优于基准模型。
2 相关工作
对电子病历中蕴含的丰富信息进行挖掘、分析与应用是一个跨学科且十分重要的研究问题,近年来,代表性的工作主要体现在3个方面。
2.1 图神经网络
图神经网络的目标是学习网络中每个节点的低维向量表示,将其用于节点分类、节点聚合和链路预测等下游任务,其基本原理是每个节点向量均是由自身的特征和周围邻居节点的信息所构成。文献[11]提出了一种非常有影响力的模型GCN(Graph Convolutional Network),该模型简化了以前谱域中的图卷积。文献[12]提出了一种新的算法GraphSage,利用采样和聚合函数学习归纳生成节点嵌入。文献[13]在GCN的基础上增加了注意力机制,实现了对不同邻居权重的自适应分配。文献[14]研究了如何将患者病历中的时间序列信息融入到预测中,利用反向时间注意力机制来提高模型的预测准确性和可解释性。然而,GraphSage虽能适应大规模网络更新变化,但其精确度相比GCN有一定程度降低。GAT(Graph ATtention network)在提高精确度的同时也使得复杂度大幅度增加。
2.2 基于同构图嵌入的电子病历分析
近年来,许多学者用图神经网络来分析EMRs,这些模型可以从原始的EMRs中捕获结构信息。但是,由于电子病历文本的专业性较强[15],术语中存在大量的同义词或上下位词,传统的图网络模型并不适用。基于此,学术界提出了多个改进模型,以便学习节点更为合理的嵌入表示,并用于预测任务。文献[16]用医学本体固有的层次信息来补充EMRs,它可以学习到节点的合理嵌入,并用于下游预测任务。文献[17]是在结构信息缺失的情况下联合学习EMRs底层结构,在执行预测的同时联合学习EMRs隐藏的因果结构。但是,以上研究仅限于同构图,没有利用EMRs数据中有利于细化患者表示的多源情境信息。原始的EMRs中包含着多种实体和实体间的各种关系,具有天然的、客观事实存在的异构性,基于同构图嵌入的电子病历分析的方法不能充分利用网络复杂的结构信息和丰富的语义信息。
2.3 基于异构图嵌入的电子病历分析
异质信息网络是含有多种实体和多种关系的信息网络,充分学习异质信息网络的核心是处理好该网络的异构性,先前很多研究中也给出了消除网络异构性的方法。文献[18]将异构图分割成多个同构图,以相似矩阵作为输入,使用注意力机制来衡量每个元路径的影响,每个同构图包含原始EMRs图的部分信息进行预测分析。为了更好地建模分析复杂的异构图,文献[19]利用注意力机制从多方面表示节点并进行加权融合,但是,这种方法忽略了元路径中间节点的信息。为了充分考虑元路径上所有节点的信息,文献[20]提出了元路径内聚合器和元路径间聚合器对异构图进行建模分析。然而,这些方法在特定的复杂医疗网络中,既没有考虑异构图病历网络中各类实体节点的重要性,也没有考虑实体之间语义关系的重要性。
3 异构图病历网络
3.1 相关定义
定义1(异构图病历网络) 若节点类型数|C|和节点之间关系类型数|R|满足|C|+|R|>2,则称之为异构图病历网络G={V,E},其中,V表示节点集合,E表示边集合, 如图1a所示。

Figure 1 Heterogeneous graph medical record network

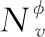
3.2 患者病历网络构建
从患者的电子病历原始文本中提取出患者的年龄、性别、主诉、现病史和生理记录等重要信息,将每个患者及其症状表示为病历记录网络,形式化表示为P=(Vp∪Vs′,Eps′),其中,Vp是患者节点集,Vs′是症状节点集,Eps′表示患者与其表现出的症状之间的边集,若症状s∈Vs′与患者p∈Vp相关联,则2个节点之间存在一条连边,即Eps′=1。图1a右侧展示了1个患者病历网络。
3.3 外部医学知识图谱
本文选取10种常见疾病进行分析,疾病名称均采用国际疾病分类标准ICD-10表示,参考海量知识图谱CMeKG(Chinese Medical Knowledge Graph)中疾病临床症状等信息,将每种疾病与其对应的症状提取出来表示为一个概念图,形式化表示为D=(Vd∪Vs,Eds),其中,Vd是疾病节点集,Vs是症状节点集,Eds是边的集合。若症状s∈Vs与疾病d∈Vd相关联,则2个节点之间存在一条连边,即Eds=1。如图1a左侧所示,以高血压d1和慢性肺源性心脏病d2这2种疾病为例,两者有共同的症状s1和s3,则将疾病与症状进行连边,以此类推构建所有疾病和症状的外部医学知识图谱。本文以外部医学知识图谱作为领域知识,与3.2节构建的患者病历网络中的症状节点进行融合,以解决因发病率不同造成的数据不平衡的问题。
4 基于异构图病历注意力网络的临床辅助诊断模型
本文提出的模型框架如图2所示,在生成患者节点嵌入表示时,主要融合了2种分层注意力机制:节点级注意力机制和语义关系级注意力机制。节点级注意力机制可以筛选出有意义的邻居节点,并将其聚合在一起形成节点的嵌入表示。
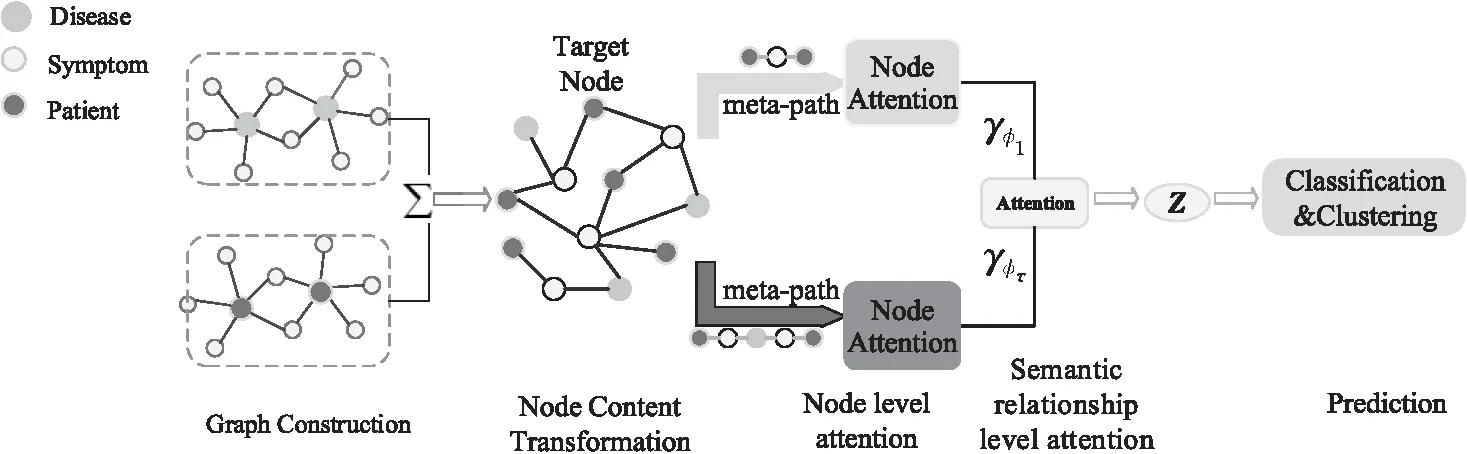
Figure 2 Framework of HCAD model
将3.2节构建的异构图病历网络P和3.3节构建的外部医学知识图谱D进行数据集成,构成异构图病历网络G作为模型的输入。为方便起见,对于G中节点的特征向量矩阵表示为(A,X),其中,A是根据边集合E生成的邻接矩阵,当(vi,vj)∈E时,Aij=1;信息矩阵X是从电子病历原文中提取的患者年龄、性别和生理记录等信息进行区间变量向量化构成的,矩阵中的每一个行向量对应一个患者节点的初始嵌入表示。
4.1 节点级注意力机制
由于异构图病历网络中不同类型节点都有不同的特征表示t,对每种类型节点vi的邻居节点信息聚合之前,需将不同类型节点的特征经节点类型的变换矩阵Hvi投影到相同的特征空间中,投影过程可描述为式(1):
t′vi=Hvi·tvi
(1)
此外,为了有效分辨出起决定性作用的邻居节点,模型引入了节点级注意力机制,将有意义的基于元路径的邻居节点信息聚合在一起,形成节点的低维嵌入表示。
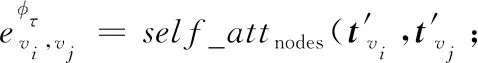
(2)
满足此元路径的2个节点均共享self_attnodes,self_attnodes表示执行节点级注意力机制的深度神经网络。

(3)
(4)
为充分利用注意力机制的表达能力,HCAD模型调用K组相互独立的注意力机制,使得训练更加稳定,将学习到的输出结果拼接在一起,如式(5)所示:
(5)

Figure 3 Stratified attention mechanism
4.2 语义关系级注意力机制
异构图病历网络中的节点包含多种类型语义信息,基于某一条元路径的节点嵌入,只表示异构图中某一方面的语义信息。为了更有效、更稳健地聚集节点邻居的信息,学习得到更为全面的节点嵌入表示,本文设计了一种新的语义关系级注意力机制,以自动学习不同元路径的重要性,选择起决定性作用的元路径并进行语义融合。语义关系级注意力机制以式(5)学习到的U组具有特定语义信息的节点嵌入为输入,获得每条元路径的权重,如式(6)所示:
(6)
(7)
(8)
其中,W表示权重矩阵,b表示偏置向量,q表示语义融合向量,计算所有元路径的权重系数时均共享上述参数。
最后,对所有元路径下的节点嵌入表示进行融合,得到最终的节点嵌入Z,如式(9)所示:
(9)
本文将最终的节点嵌入应用到临床预测问题中,在整个预测模型训练的过程中,通过式(10)量化预测误差:
(10)
其中,Yp表示患者节点p的标签,Zp表示患者节点p的最终嵌入表示,Q用来携带分类器的参数,通过反向传播来更新参数、优化模型。
基于异构图病历注意力网络的临床辅助诊断算法如算法1所示。
算法1基于异构图病历注意力网络的临床辅助诊断算法。
输出:最终节点嵌入表示Z,节点级注意力系数λ,语义关系级注意力系数γ。
2.fork←1 toKdo
3. 节点特征转换t′vi←Hvi·tvi;
4.forvi∈Vdo
8.endfor

10.endfor

12.endfor
13. 计算语义关系级注意力系数γ;
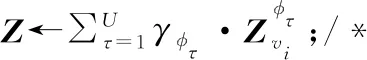
15.endfor
16.计算交叉熵损失函数L;
17.模型优化,参数更新;
18.ReturnZ,λ,γ
5 实验和结果分析
5.1 数据源及数据预处理
本文基于某三甲医院的真实电子病历数据和CCKS2017 Shared Task2开源中文电子病历标准数据集进行实验。真实电子病历数据共有8 000多份电子病历,包含每个科室最常见的疾病,即高血压、糖尿病和慢性阻塞性肺病等多种疾病,根据本文研究内容筛选符合要求的电子病历4 228份作为研究对象,每种疾病的数量和比例如图4所示。原始电子病历数据都是纯文本形式,包含患者的个人信息(已去除隐私信息)、主诉、现病史、家族史、体征检查和诊断结果等内容。基于这些数据构建一个干净高效的异构图病历网络,本文对数据进行以下处理:

Figure 4 Number of diseases in EMRs
(1)数据消歧:首先,进行文本分割、分词处理和症状提取,形成半结构化的中文病历数据集,获得500多种症状实体。然后,在临床专家的指导下,针对部分症状实体存在不同的表述或缩写形式,进行清洗以消除歧义,最终得到405种有效症状实体。
(2)数据融合:本文使用的数据中不同疾病的电子病历数量不平衡,高血压有501份,而肺源性心脏病只有249份。从电子病历中提取10种疾病对应的症状,且症状也存在不平衡问题。为解决电子病历数据量有限且不同病症数据分布不平衡等问题,本文构建外部医学知识图谱,将患者病历记录网络中能够与知识图谱中的症状实体匹配的节点进行融合。
(3)多源情境信息向量化:电子病历中患者的性别、年龄和体征检查结果的可能取值较多,需要对这类情境信息进行分段处理,分段的依据包括:生活常识,如性别分为男女;数据特征,如血压正常值一般为:90<收缩压<140,60<舒张压<90;根据年龄分段法对年龄进行分段,这种分段方式更贴近人们对于生活的认知[21]。以此将这类情境信息进行向量化处理并集成到患者节点的特征向量中,对于细化患者表示和预测诊断有重要的辅助作用。
5.2 基准方法和实验设置
为了验证本文提出的HCAD模型的效果,选择8种基准模型进行对比实验,这8种模型主要分为3类:同构图网络嵌入模型GCN[11]和GAT[13],异构图网络嵌入模型HIN2Vec[22]、HeGAN(Heterogeneous information network inspired by Generative Adversarial Network)[23]、DHNE(Deep Hyper-Network Embedding)[24]和MetaGraph2Vec[25],以及与本文模型相近的2种变体模型HCADnode和HCADpath。
实验过程中,参数学习率设置为0.005,Epochs设置为200。如果损失函数在连续50个Epochs上没有减少,则模型停止训练。异构图病历网络中节点的初始向量维度R设定为491,模型最终嵌入的节点向量维度Z为64,语义融合注意力向量q的维度设置为32,注意力头数K设置为8。所有模型使用的电子病历数据按照7∶1∶2划分训练集、验证集和测试集。
5.3 评价指标
临床诊断预测问题本质上既可以看作是一个分类任务[26],也可以看作是一个聚类任务。针对分类任务,本文采用通用的评价标准对实验结果进行评估:Precision、Recall和F1值,计算方法分别如式(11)~式(13)所示:
(11)
(12)
(13)
其中,TP表示预测为正的正样本个数,FP表示预测为正的负样本个数,FN表示预测为负的正样本个数。
在聚类任务中,本文使用归一化互信息NMI(Normalized Mutual Information)评估聚类质量[27],NMI值越大表示性能越好。
5.4 实验对比及分析
5.4.1 分类结果分析
本文将每个患者节点的低维向量表示作为下游任务的输入,将患者疾病诊断问题转化为节点分类任务。为了保证预测结果更加稳定可靠,分类过程重复10次取其平均值。实验结果如表1所示。根据表1可知,本文提出的HCAD模型具有以下优点:(1) 在所有模型中,HCAD模型的预测效果最好,F1值相比基准模型至少提高了4.86%;(2) 本文设计的2个消融实验的预测效果相比其他基准模型均有提高,但低于HCAD的预测准确率,这充分证明了本文模型中分层注意力机制的有效性;(3) 与基准模型相比,结合图结构信息和语义信息的HCAD模型在分类效果上有明显优势。这也表明HCAD模型不仅可以捕获重要的基于元路径的邻居节点,还可以捕获异构病历网络中更丰富的语义信息。

Table 1 Quantitative results on the node classification task
5.4.2 聚类结果分析
临床诊断问题也可以看成是一个聚类任务,聚类效果可以用NMI来评价。由于聚类任务的性能受初始质点的影响,本文在聚类过程中重复实验10次取评价结果的平均值。聚类结果如图5所示,可以发现:(1)HCAD的表现始终优于所有基准模型,NMI值提高了8.23%;(2)HCAD模型能够识别具有较大影响力的邻居节点,能够有效解决语义混淆的问题;(3)GCN、GAT和传统异质模型MetaGraph2Vec的聚类效果相对较差;(4)增加了分层注意力机制的2种模型HCADnode和HCADpath在聚类效果上有不同程度的提高。

Figure 5 Quantitative results on the node clustering task
5.4.3 参数敏感度
本文进一步通过实验分析了模型对关键超参数的敏感度,主要发现:
(1)随着多头注意力K值的增加,预测准确性有较大改善,如图6a所示,多头注意力可使得训练过程更加稳定。

Figure 6 Parameter sensitivities of HCAD model
(2)增加患者多种情境信息后预测性能有较大提升。如图6b所示,患者节点的初始嵌入维度R为405,增加了患者情境信息后R达到491,使得预测效果有近2%的提高,这表明HCAD模型利用了更多的潜在结构信息。
(3)随着患者节点最终嵌入维度Z的增加,预测性能先增后减,如图6b所示。这是因为较大的节点嵌入维度会带来更多的噪声,从而导致预测性能下降,同时也增加了计算复杂性。
(4)随着语义融合向量q维度的增加,模型的预测性能也在提升,如图6c所示,当q维度大于32时,预测性能由最高点开始缓慢下降。这是因为较大的语义融合向量维度可能会导致模型产生过拟合现象。
5.4.4 分层注意力机制分析
(1)节点级注意力机制分析。患者节点的嵌入表示不仅依靠节点自身信息,还需要聚合基于元路径的邻居节点的信息,一些重要的邻居节点在聚合过程中需要更大的关注度。以图7a为例,中心节点507是一名慢性肺源性心脏病患者,其基于元路径PSP的邻居节点有163,6和545等。从图7b中模型为所有节点自动分配的权重值可以发现,中心节点507在聚合邻居信息过程中,更关注该节点自身以及具有相同疾病类别的患者节点,例如患有慢性肺源性心脏病的患者节点503,545和579,即节点级注意力机制更能区分邻居之间的差异,将较高的权重分配给重要的邻居节点。

Figure 7 Analysis of node level attention mechanism
(2)语义关系级注意力机制分析。不同元路径在特定任务中表现出不同的有效性,若将每条元路径看作同等重要,则模型的预测性能就无法得到有效提升。语义关系级注意力机制可以为每条元路径赋予不同的权重,并对各个元路径代表的语义信息进行适当的融合。在聚类分析中,NMI值越高,表明元路径越有效,如图8所示。实验发现:①在异构图病历网络中,元路径PSP相比PSDSP更为重要,因而其权值较高;②虽然元路径PSP的权重比PSDSP的大,但两者差异并不明显,这可以解释为什么在图5中消融实验HCADpath通过简单加和平均计算也可以获得相对较好的预测结果;(3)元路径PSDSP在语义传播过程中,匹配到的邻居节点相比PSP更多,但大多数都不是同类型疾病的节点,使得通过元路径PSDSP得到的节点向量表示预测效果较差,因而其重要性相对较低。
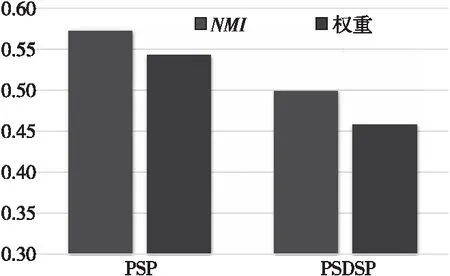
Figure 8 Analysis of semantic relational level attention mechanism
节点级注意力机制和语义关系级注意力机制为本文提出的HCAD模型的可解释性带来便利。由于节点级注意力机制能更加有效地区分邻居节点之间的差异,将较高的权重分配给更为重要的邻居节点;语义关系级注意力机制可以为每条元路径赋予不同的权重。当再次输入相同或者类似的数据时,通过回溯不同节点和元路径的重要性,可对HCAD模型的疾病预测结果给出一个合理的逻辑解释。
5.4.5 算法的复杂度分析
本文提出的HCAD模型与几种基准模型都是基于图神经网络,为了对比方便,用于训练模型的数据以相同的形式存储,处理过程涉及到的最大矩阵均为二维矩阵,所以空间复杂度一致。算法一次正向传播过程的时间复杂度对比如表2所示,其中,|V|表示异构图病历网络中节点的数量,|E|表示网络中边的数量,且该网络满足|E|>|V|,d表示节点向量的维度。本文HCAD模型的时间复杂度为O((|V|+|E|)d),与异构图病历网络的节点数和边数成线性关系。对比模型中时间复杂度最低的为DHNE。在实验中,本文HCAD模型的实际运行时间略大于GCN的实际运行时间。

Table 2 Comparison of model time complexities
6 结束语
本文提出了一种基于异构图病历注意力网络的临床辅助诊断模型HCAD,主要工作为:(1)利用电子病历中有效信息构建异构图病历网络,并建立外部医学知识图谱来解决数据不平衡问题;(2)模型能统一利用异构图病历网络中复杂的结构信息和丰富的语义信息来生成更完整且更具有区分度的患者节点表示,以达到更好的预测效果;(3)模型中设置了分层注意力机制,包括节点级注意力机制和语义关系级注意力机制,分别学习邻居节点和不同元路径的重要程度。实验表明,本文提出的临床辅助诊断模型在10种常见疾病的分类和聚类效果上都表现出明显的优越性,且具有较好的可解释性。
HCAD模型还存在以下不足之处:(1)本文所构建的异构图病历网络规模相对较小,模型仅对常见的10种疾病实验有效,针对其它疾病是否有效还需进一步实验分析;(2)本文提出的HCAD模型引入了分层注意力机制,使得准确率显著提升,但同时也造成了时间复杂度略高的问题。在未来的工作中,将从10种常见疾病扩展到其他疾病,并扩大患者异构图病历网络的数据规模,在本文提出的模型基础上寻找更佳的建模方法,提高准确率的同时降低时间复杂度,为临床辅助诊断,促进个性化诊疗,提升智慧医疗的服务水平提供技术支撑。
