基于改进自适应DBSCAN的混合式MOOC视频观看模式挖掘
2023-09-18王若宾耿芳东张永梅王伟锋
王若宾,耿芳东,张永梅,宋 威,王伟锋,徐 琳
(1.北方工业大学信息学院,北京 100144;2.南澳大学STEM学院,澳大利亚 阿德莱德 5095)
1 引言
近年来,混合式MOOC教学快速发展,已经进入越来越多的高校课堂。不同于传统的课堂教学,混合式MOOC可以记录大部分学习行为,为精准分析提供了数据来源;也不同于纯MOOC学习,学习者异质化程度高,导致行为模式差异明显。混合式MOOC学习行为模式的差异往往体现为较高同质化程度下更为微妙的区别,而学习模式的精准分类对于进一步理解和把握翻转课堂情境中基于教师指导的自我调节学习规律具有重要的启迪作用。
在实际教学活动中,学生往往会因为不同的视频观看行为呈现不同的分布,在部分行为上学生分布趋于集中,而在另外一些行为上却差异明显,尤其是对于一些难度较高、操作性强以及必修课表以外的课程[1]。因此,混合式MOOC教学情境对学习行为模式挖掘提出了更高的要求。
聚类分析是数据挖掘中一种重要的技术方法,也是无监督学习中一个重要的研究方向。它能够把数据划分为若干簇,同一簇间的数据具有较高的相似性,不同簇间具有较低相似性,可实现无监督模式下的合理划分,进而获得分类后的数据聚合形态。因此,以聚类算法对混合式MOOC教学情境下的视频观看模式进行挖掘具有一定的适用性。其中基于密度的聚类算法因适应性好而得到广泛应用,如DBSCAN(Density-Based Spatial Clustering Applications with Noise)[2],具有抗噪声和可以处理复杂数据等优点。然而DBSCAN也存在参数依赖以及人工参与度高的缺陷。
基于此,本文提出一种基于k-dist图斜率的自适应DBSCAN算法KSSA-DBSCAN(Self-Adaptive DBSCAN based on K-dist Slope),可以根据实际应用场景和数据集本身的统计特征自动选择合适的参数输入,不仅实现了在未知聚类数情况下对任意形态的样本聚类,而且克服了传统DBSCAN难以确定参数以及人工参与度高的不足。本文将其应用到混合式MOOC视频观看模式挖掘中,可以根据具体的学生行为和分布特征,自动选取合适的参数输入,聚类出视频观看行为模式不同的学生,进而实现混合式MOOC教学情境下学生视频观看行为模式的自动挖掘。
2 相关工作
聚类分析算法一般情况下可分为基于划分的算法(如K-means)、基于层次的算法(如CURE(Clustering Using REpresentative)、BIRCH(Balanced Iterative Reducing and Clustering using Hierarchies))、基于密度的算法(如DBSCAN)、基于网格的算法(如STING(STatistical INformation Grid))以及基于模型的算法(如EM(Expectation Maximization Algorithm))等。其中基于密度的聚类实际上是找出数据集中不同密度区域的集合,集合中对象之间平均距离较小的区域即为高密度区域,平均距离较大的即为低密度区域。DBSCAN就是一种传统的密度聚类算法,其复杂度低、抗噪性强,且不需要提前指定聚类个数,能够发现任意形态的高密度区域,但是其对于参数的选择过于敏感,且需要人工的参与,这一缺陷限制了其在实际中的应用。
在算法改进方面,近年来,陆续有学者提出新的改进算法。Rodriguez等[3]提出基于快速搜索和发现密度峰值的聚类算法,但是算法容噪性低并且需要人工参与。Chen等[4]基于新的局部邻域搜索技术提出NQ-DBSCAN(Neighbor Query- DBSCAN)算法,减少了大量不必要的距离运算,但是未能解决参数依赖问题。Brown等[5]基于密度网格提出一种快速聚类算法,虽然缩短了运行时间,但是与DBSCAN相比在精度上未有提升。 Chen等[6]针对大规模数据提出BLOCK- DBSCAN,虽然优化了时间复杂度,但是仍需要人工的参与。Ohadi等[7]提出基于网格和局部参数的SW-DBSCAN(Sliding Window DBSCAN)聚类算法,通过使用动态Eps和MinPts参数提升了算法性能,但仍需要人工确定初始参数。Gholizadeh等[8]基于K-means++提出K-DBSCAN算法,缩短了DBSCAN算法执行时间,但忽视了噪声的影响,并且没有解决参数依赖的问题。周红芳等[9]基于距离分布矩阵提出自适应确定参数的方法,但是其拟合过程在理论上存在误差。李文杰等[10]提出KANN-DBSCAN(K-Average Nearest Neighbor-DBSCAN)算法,利用数据集自身分布特性生成候选Eps和MinPts参数,并引入Density概念能够根据簇数变化实现自适应确定最优参数,但是不适合处理较大规模数据和高维数据。综上所述,尽管有一系列针对DBSCAN的改进研究,但是难以确定参数以及人工参与度高的缺陷仍然没有得到有效解决。
在实际应用方面,丁兆颖等[11]将改进的DBSCAN应用在码头挖掘场景中,利用改进的DBSCAN算法聚类出包含码头的停泊区域,并通过融合了岸基结构物等的空间数据对临时停泊区域进行排除,最终实现了较好的码头位置选择。于彦伟等[12]基于Cell距离分析理论提出简单高效的CDBSCAN(Cell-DBSCAN)算法,解决了面向位置大数据的聚类问题。李文昊等[13]通过DBSCAN算法产生的类来约束层次聚类的聚类空间,并将其应用到了代码包层次重构的问题上,对软件进行了合理划分。但是,相比工程问题中的应用,把DBSCAN算法用于学习行为挖掘的研究仍然比较少。
基于此,本文提出基于k-dist图斜率的自适应DBSCAN算法KSSA-DBSCAN,不仅实现了在未知聚类数情况下对任意形态的样本聚类,而且克服了参数依赖的缺陷,提高了聚类的准确率,适用于MOOC视频观看行为模式的自动挖掘。
3 相关概念
3.1 DBSCAN
密度聚类算法DBSCAN能够通过密度差异划分出高密度区域,并能有效发现任意形状的簇。该算法定义密度为数据集中以某给定对象为圆心、以给定Eps为半径的空间区域内的对象个数。下面给出DBSCAN算法中一些必要的定义:
定义1(邻域Eps) 以给定某对象为圆心、以Eps为半径所确定的区域。
定义2(密度阈值MinPts) 以给定的某对象为圆心、以Eps邻域为半径所确定的区域内的对象数目。
定义3(核心点) 如果某一对象在Eps邻域中至少包含了MinPts个对象,则该对象为核心点。
定义4(直接密度可达) 在给定对象集合里,如果对象p是一个核心点,q在p的Eps邻域内,则称p到q直接密度可达。
定义5(密度可达) 如果存在对象链P1,P2,P3,…,Pn,P1=p,Pn=q,如果满足Pi+1是Pi关于Eps和MinPts直接密度可达,则称p到q密度可达。
定义6(密度相连) 如果在同一对象集合里,p和q都是关于Eps和MinPts密度可达的,则对象p和对象q是密度相连的。
定义7(噪声点) 对象p不属于数据集里的任何一个簇,则p为噪声点。
DBSCAN算法基本步骤:
(1)给定MinPts=4(针对二维数据),采用k-最近邻算法kNN(k-Nearest Neighbor)生成候选Eps列表,令k=4,求出所有点的第k个邻居距离集合distk作为Eps候选值,并进行降序排列,画出此时的k-dist图,通过人工确定k-dist图的第1个“拐点”(Valley)确定Eps的值。
(2)从数据集中依次访问没有被标记为任意簇的核心点,再把该核心点与它密度相连的对象聚类为同一簇。
(3)重复步骤(2),直至所有对象都被访问。
3.2 KSSA-DBSCAN基本思想
由于DBSCAN算法难以确定输入参数,且需要人工的参与,不仅耗费人力,而且在准确率上也难以保证。因此,本文基于k-dist图斜率的思想提出了一种KSSA-DBSCAN算法,可以根据实际应用场景和数据集本身的统计特征自动选择合适的参数输入。其基本思想如算法1所示,具体实现流程如图 1所示。
算法1KSSA-DBSCAN算法
输入:数据Data,数据大小N。
输出:聚类结果。
步骤1计算k值,k=N/25。
步骤2遍历数据,利用kNN计算每个样本点的第k个邻居距离并降序排列,作为候选Eps参数表。
步骤3根据降序的候选Eps列表画出k-dist图。
步骤4确定Slope阈值,并根据Slope阈值确定k-dist图的第1个拐点作为最佳Eps参数。
步骤5根据最佳Eps参数确定初始MinPts参数,并执行第1次聚类DBSCAN(Data,最佳Eps,初始MinPts),记录聚类数,递减MinPts参数值分别与最佳Eps聚类迭代,选取聚类数目第1个突变点对应的MinPts值为最佳MinPts参数。
步骤6DBSCAN(Data,最佳Eps,最佳MinPts)。
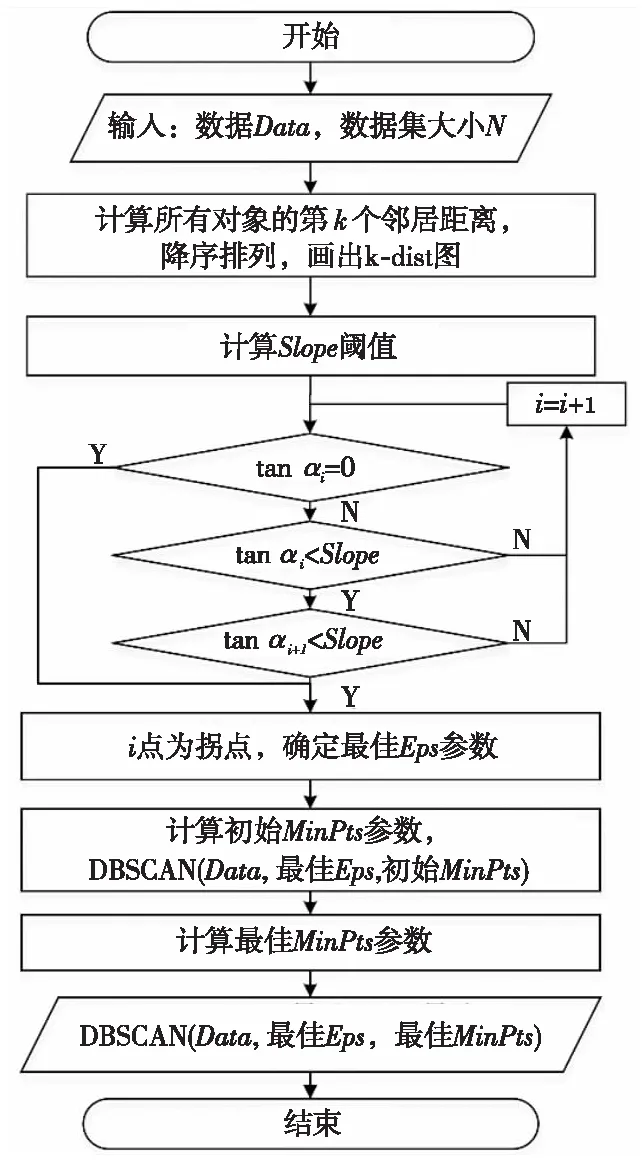
Figure 1 Flow chart of KSSA-DBSCAN
3.3 确定Eps参数
采用k-最近邻算法kNN生成候选Eps列表,kNN算法的基本思想是使用输入数据找到距离某数据点最近的第k个邻居(k=1时,即为最近邻距离)。考虑k值选择为所有对象数目的1/25(即k=N/25,N为对象总数量),求出所有点的第k个邻居距离集合distk并进行降序排列,作为Eps候选值,画出此时的k-dist图,如图 2所示。

Figure 2 k-dist graph
对于非平滑的曲线,传统的数学方法难以实现拐点的选择,然而经过多次实验验证,可以认为连续多点的坡度小于某一阈值时,则第1个点可判定为拐点。对于该阈值的选择,可以引入Slope参数概念,定义Slope为k-dist图中所有相邻数据点的正切值的均值,如式(1)所示:
(1)
(2)
其中,tanαi表示第i点与第i+1点的正切值,N表示数据集中对象总数。
由于式中|xi-xi+1|的值始终等于1,因此式(1)和式(2)可以简化为:
(3)
tanαi=yi-yi+1
(4)
对于小规模数据,可以认为如果连续2点的正切值(即tanαi和tanαi+1)均小于阈值Slope,则判定第i点为拐点,选取此点对应的y轴Eps值作为最佳Eps参数,如图 3所示。但是,如果在确定该拐点之前出现了截断点(即tanαi=0),则判定此时该i点对应y值为最佳Eps参数,如图 4所示。

Figure 3 Valley Pi
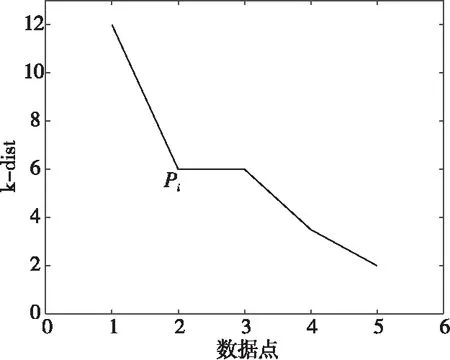
Figure 4 Cut-off point Pi
3.4 确定MinPts参数
本文通过数学期望法确定初始MinPts参数。对于上述方法确定的最佳Eps参数,计算每一个对象在该邻域中的邻域对象数量,并计算其数学期望值作为初始参数MinPts0,如式(5)所示:
(5)
其中,N表示数据集中对象的总数,Ti表示i点在邻域Eps中的邻域对象总数。
此时由于MinPts0为所有对象的邻域内对象数量的期望,其中包含了噪声对象,因此该值对于簇内对象来说是偏大的,应适当缩小该值以排除噪声对簇内对象的干扰并保持此时的聚类簇数稳定,由此得到更加稳定紧凑的聚类结果。首先选取最佳Eps参数和参数MinPts0进行第1次聚类,记录此时的聚类簇数为ClusterNo_mark。递减MinPts0值并分别与Eps进行聚类,生成ClusterNo列表,找出ClusterNo列表中最后一个等于ClusterNo_mark的数据点i(即第1个突变点),则选取该i点所对应的MinPts列表值为最佳MinPts参数,如图 5所示,p点即为突变点。
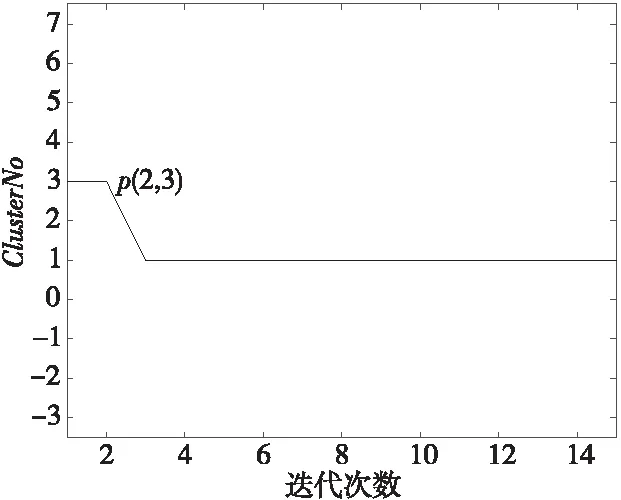
Figure 5 Clustering number change diagram

Figure 6 Performance of two algorithms on three 2D data sets
3.5 性能对比
为测试KSSA-DBSCAN算法的性能,本节选取UCI(University of California Irvine Machine Learning Repository)的wine、seeds、iris标准数据集以及3个合成数据集DS1、DS2和DS3进行实验分析,并与KANN-DBSCAN和DBSCAN算法进行了对比,测试数据集基本属性如表 1所示。图 6展示了KSSA-DBSCAN和DBSCAN在DS1、DS2和DS3这3个二维数据集上的聚类结果,可以看出DBSCAN算法在3个二维数据集上的划分簇数分别为5,12和5,而本文提出的KSSA-DBSCAN算法的划分结果为9,15和6,相比之下KSSA-DBSCAN能够划分出更多具有细微差异的不同簇。

Table 1 Basic information of test data sets
为更加客观地对比KSSA-DBSCAN算法与其他聚类算法的性能差异,本文采用有监督的F度量(Fmeasure)方法检测准确率,3种算法在6个数据集上聚类的性能指标如表 2所示。可以看出,本文所提出的KSSA-DBSCAN算法在wine、seeds、DS2、DS3数据集上的准确率都优于其他算法,并且与DBSCAN相比准确率最大提高了25%。
4 混合式MOOC视频观看模式挖掘实验
4.1 实验场景
用KSSA-DBSCAN算法对混合式MOOC视频观看行为模式进行数据挖掘实验,实验选用某大学《大学计算机》混合式MOOC视频学习行为数据集作为研究对象。该数据集包含12个班级301名学生在该课程169个视频上共计50 119条视频观看行为记录。通过前期数据清洗及记录合并,最终选定198名学生在8章共169个课程视频上的行为数据。根据课程内容性质以及学习行为特征将聚类指标定为视频观视比(视频观看时长/视频时长)、次均观看时长(视频观看时长/观看次数)和移动观看量(视频观看时长/视频时长-PC端观看量)3个视频学习行为指标。具体实验环境参数及数据如表 3和表 4所示。

Table 2 Comparison of accuracy of different clustering algorithms

Table 3 Experimental configuration
该课程的第1~第4及第8章为课程内必修内容,第5~第7章为课程外学习内容,但是观看视频可以得到分数,具体信息及特征如表 5所示。

Table 4 Basic properties of experimental data
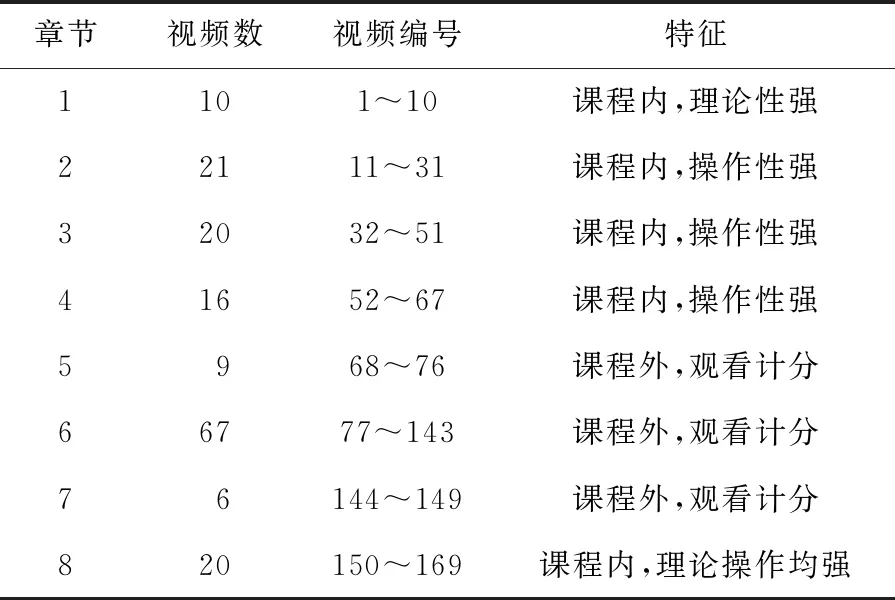
Table 5 Basic characteristics of each chapter
4.2 实验及结果分析
由于该数据集维度高达507,因此实验前先用PCA(Principal Component Analysis)进行降维,再通过t-SNE(t-distributed Stochastic Neighbor Embedding)将数据降至二维,以便可视化呈现,最终原始数据分布和聚类实验结果如图 7所示。从实验结果可以看到,198个对象被清晰地划分为了3个集群,并排除了噪声的干扰,图中圆圈表示噪声。

Figure 7 Original data graph and clustering result graph
为验证KSSA-DBSCAN算法实验结果的合理性,本文将其与其他算法聚类结果进行了对比,并通过内部评价指标DBI(Davies-Bouldin Index)进行评价。DBI计算如式(6)所示,可以看出DBI越低表示聚类结果越好。
(6)

对比结果如表 6所示。从表6中可以看出,DBSCAN未能成功聚类,因此DBI值显示为NAN,而KANN-DBSCAN虽然能够聚类,但是其DBI值高于KSSA-DBSCAN的。对KSSA-DBSCAN算法聚类的3个集群特征做进一步的分析,图 8展示了3个集群在169个视频3个维度上的均值,可以看出各个集群在3个维度上体现出视频观看行为模式的差异。

Table 6 Comparison of clustering results
进一步地,按照视频所属的章合并后取均值,这将进一步放大各章观看行为模式的差异。图 9展示了在每章的均值,可以看出3个集群在不同章3个维度上大多有较为明显的差异。
根据聚类的结果对每个集群特征总结如下:
(1)集群1:此类学生能完成课程内的观看任务,并在难度较大的内容上存在反复观看行为,且次均观看时长在各章都较长。基本完成课程外内容的观看,根据特征,被标记为“刻苦型”。

Figure 8 Performance of three clusters on different videos
(2)集群2:此类学生基本能完成课程内的任务,但重复观看率不高,一定程度上体现为刷课行为,并且有部分课程任务未能完成,学习积极性不高,因此此类学生被标记为“懈怠型”。
(3)集群3:此类学生不仅能完成课程内的观看任务,对难度较大和操作性强的内容反复学习,而他们的次均观看时长往往更短,显示出更好的自我调节学习行为。而且能积极主动学习课程外的内容,学习策略较好,因此被标记为“策略型”。
对3类学生的平均成绩进一步分析,发现“刻苦型”学生平均成绩为85.047 9,“懈怠型”学生平均成绩为80.041 5,“策略型”学生平均成绩为82.730 3,存在差异,说明学生的课程成绩与学习投入存在正相关关系,越多的视频观看投入越有可能获得较高的课程分数。由于本课程包含了课外观看内容,观看课外视频对课程成绩有一定的影响,这可能是导致“刻苦型”学生成绩均值比“策略型”学生成绩均值更高的一个原因。但是,单纯的视频观看时长并不能反映学习的真实效果,这一点从“策略型”学生的学习行为可以看出,根据图9可知,在观视比方面,“策略型”学生在难度较大的章,如第1章和第8章,观视比高于其他类型学生的,而在次均观看时长方面并不是最高的,显示出得当的学习策略在获得更好的学习效果方面具有优势。

Figure 9 Performance of three clusters on different chapters
5 结束语
本文提出了一种KSSA-DBSCAN算法,能够依据k-dist图斜率自动选择合适的k-dist图拐点作为最佳Eps参数,并在聚类迭代过程中依据聚类数目的变化自动确定最佳MinPts参数,克服了DBSCAN参数敏感以及需要人工参与的缺陷。通过与其他算法在6个测试数据集上的对比,验证了该算法在准确率上的优势,并且通过对混合式MOOC视频观看模式的挖掘,进一步验证了该算法在实际应用中的有效性。为使该算法适用更多应用场景,特别是大数据应用场景,未来研究将在时间复杂度上进行优化以适应大规模数据处理情境。
