基于模型混合的智能交易行为异常检测
2023-09-18张晨亮柳永翔黄艳婷
张 耐,张晨亮,柳永翔,陈 聪,黄艳婷
(1.华东师范大学计算机科学与技术学院,上海 200062;2.上海华鑫股份有限公司,上海 200032)
1 引言
长久以来,金融领域发展与社会进步息息相关,诸如贸易、借贷、投资和金融风险管理等均是金融领域的重点研究对象。金融领域每天产生大量数据,例如股票交易数据、用户借贷数据等。如何从这些数据中自动挖掘有价值信息,对于降低金融领域从业人员人力成本将有重大意义。人工智能技术的崛起为金融智能化的开展带来了契机[1]。作为智能金融的重要体现之一,基于交易软件的智能化交易在国内金融市场方兴未艾,越来越多的传统投资模式在向智能化交易转型,这其中既有资本市场快速发展的原因,也有金融科技蓬勃发展的强力助推。
然而,智能化交易在金融券商平台中的部署和实施也带来了一些实际问题。其中具有一定规模的不同用户往往采用自身的智能交易软件,因此交易软件类型往往较多。由于不同软件涉及的交易策略、设计思路等各不相同,因而交易软件存在异常、不合规风险。参差不齐的安全性降低了证券行业信息系统的运行安全和合规程度。目前,针对智能交易行为的异常检测在行业内是一大缺失,这限制了券商评估交易对象安全性的能力,制约了金融科技创新的步伐。因此,研究面向智能交易行为的异常检测方法具有实际应用需求,也为智能交易在国内的下一步发展打下坚实的基础。
交易数据本身的复杂性和专业性决定了异常检测方法需要结合对证券业务的深度理解进行设计,这仍是一个新兴的研究问题,未形成系统、完整的研究体系。同时,由于不同国家的证券交易规则存在差别,针对中国证券市场中的异常检测及相应安全性评估是有待研究的问题。为此,本文针对智能交易场景中的交易行为序列异常检测展开研究。需要说明的是,本文异常主要是根据证券交易所的异常交易监控细则等相关文件设定。
为此,本文提出了一种模型混合的智能交易异常行为检测模型。针对交易数据蕴含的时序性和合规性,从序列表征学习和融入领域特征规则的角度出发,分别利用深度神经网络捕捉交易行为的序列性和规则集成树模型LightGBM(Light Gradient Boosting Machine)[2]融入领域特征,并将两部分模型的异常预测结果进行整合,得到最终的异常评估结果。特别地,针对交易数据存在的双序列,本文设计了相应的注意力计算机制来提升序列表征能力。本文的主要工作如下:
(1)提出了面向智能交易的异常检测新问题,并进行了数据集的收集和整理,为后续相关研究工作的开展做好铺垫。
(2)提出了融合深度学习方法和集成树方法的混合模型,从交易数据的序列性和合规性2方面进行针对性考虑。
(3)在收集的数据集上进行了多方面实验,证明了所提方法相比于一些代表性基准方法更有优势,并进行了规则重要性分析。
2 相关工作
2.1 金融数据挖掘
人工智能和数据挖掘在金融领域扮演着日益重要的角色,其旨在从大量金融相关数据中透过表象构建业务相关模型,开展模型学习,并提取出隐藏在其中的规律和事务间的联系。在金融市场中,以机器学习和深度学习为代表的新兴数据挖掘技术得到了多方面的创新应用[3]。在银行业务方面,数据挖掘技术可以帮助银行对用户进行信用评级,调整贷款额度[4];可以对客户进行细分,提供差异化的服务[5,6];可以对信用卡等业务进行风险评估[7]。在证券市场中,数据挖掘技术可以用来设计量化策略自动交易[8],通过时序模型进行股票预测[9],为投资者交易提供一定的参考;通过风险-收益模型评估,可以推荐出最适合的投资方案。在保险行业,数据挖掘技术可以帮助保险公司规避保险欺诈[10],更好地管理客户关系[11]、实现精确营销[12]。然而,目前针对智能交易行为的异常检测工作还相对较为匮乏,这也是本文展开研究的动机所在。
2.2 异常检测方法
异常检测的主要目的是发现与大部分数据模式不同的数据实例,在学术界得到了长期的关注,面临的主要挑战是数据不平衡,即正常样本的数量远大于异常样本的数量。传统的异常检测方法包括基于重构的方法[13]、基于聚类分析的方法[14,15]和基于支持向量机的方法[16,17]。这些方法的性能往往依赖于专家设计的领域特征。近年来,深度学习技术逐渐兴起,并在诸如自然语言处理、计算机视觉等多个领域取得成功。在异常检测领域,深度学习也得到了相应应用,主要涉及特征抽取、正常态特征表示和端到端异常分值计算3个方面[18]。
例如,生成对抗网络异常检测AnoGAN(Anomaly detection with Generative Adversarial Network)[19]等基于生成对抗模型的方法认为在生成对抗网络的隐空间中相较于异常样本,正常样本会被更准确地生成;卷积长短期记忆ConvLSTM (Convolutional Long Short-Term Memory)[20]网络等基于预测模型的异常检测方法通过使用时间窗口内的历史数据预测当前样本,认为正常样本能良好地保持时序数据间的依赖关系,而异常样本常常会违背这些关系,预测结果与实际样本间的差距定义为异常指数。针对智能交易行为的特点,本文考虑通过结合深度网络表征学习和集成树模型融入领域特征的优势,实现交易行为的异常检测。
3 智能交易行为异常检测模型
3.1 问题描述
智能交易行为异常检测框架如图1所示。该框架以交易报单数据作为输入,通过神经网络模块和机器学习模块后得到异常检测结果。其中,输入的交易报单分为用户通过智能交易软件委托证券公司下单的委托报单数据及在证券市场中成功交易后产生的成交报单数据。这2类数据针对每个用户都具有时序性。在证券公司的系统中还存有持仓报单和资产报单的数据,此类数据对于智能交易的安全性不造成影响,故不对其建模。

Figure 1 Framework of intelligent trading behavior anomaly detection

基于交易行为序列的时序特性,本文使用循环神经网络RNN(Recurrent Neural Network)[21]建模交易行为间的依赖性,并通过注意力机制捕捉成交序列和委托序列的内部相关性。具体地,用2个RNN模型分别学习成交报单序列和委托报单序列中的隐含信息,并利用注意力机制从每条报单隐藏层的表示中提取成交序列和委托序列内部的相关性因子。这2条对应序列再次经过注意力层后输入到多层感知机MLP(MultiLayer Perceptron),得到神经网络模块的检测结果。由于交易行为异常的界定一部分取决于交易所的规则规定,本文将相应指标进行特征提取后,使用LightGBM模型可以很好地进行相应判定。最后,本文将神经网络模块的结果和机器学习模块的结果加权求和,得到最终的智能交易行为异常检测结果。
3.2 机器学习模块
机器学习模块主要包含特征提取、特征构建和LightGBM模型3个部分,主要负责从合规性的角度对交易行为进行建模。
3.2.1 集成树模型输入
集成树模型LightGBM需要的特征是数据单元整体的统计信息。以股票为例,特征包括集合竞价阶段和连续竞价阶段的申报数量、申报金额、撤销申报数量比例、快速撤销、成交数量和成交金额等。
3.2.2 LightGBM模型
LightGBM是一种使用基于梯度的单侧采样和互斥特征捆绑的GBDT(Gradient Boosting Decision Tree)框架。相比于其他GBDT框架,LightGBM缩短了特征选择和分割的时间;另外LightGBM直接支持高申买低申卖、低申买高申卖等类别特征。针对本文所采用的上百万条交易行为数据,集成树模型LightGBM采用基于直方图的决策树计算、带深度限制的叶子生长策略、高效并行和Cache命中率优化,为海量数据提供更低的内存消耗、更快的训练速度和更高的准确率。因此,本文选择集成树模型LightGBM作为基于领域特征的分类模型。
3.3 神经网络模块
神经网络模块主要从交易行为的序列性角度建模,其具体结构如图2所示。本文将交易报单数据处理成委托报单序列SO(o1,o2,…,on)和成交报单序列SD(d1,d2,…,dm),然后通过2个不共享参数的循环神经网络获得每条报单序列的隐变量表示,并通过序列内的注意力机制对中间信息进行汇总得到成交报单序列表示BD和委托报单序列表示BO。2个序列表示再次经过序列间注意力网络处理得到融合表示,依次经过多层感知机、线性分类层和Sigmoid归一化后得到预测为异常的概率。

Figure 2 Structure of neural network model in intelligent trading behavior detection
3.3.1 GRU模型
交易行为报单序列具有时序性,循环神经网络可以很好地挖掘出交易行为间的依赖关系,从而进行建模。由于传统RNN会逐渐丢失序列间的长期依赖关系,导致交易序列中的早期重要信息。GRU(Gated Recurrent Unit)[22]和LSTM(Long Short-Term Memory)模型,作为RNN的变体,是目前广泛使用的循环神经网络模型,可以通过门控机制更好地保留长期信息。由于本文所处理的是大量交易行为数据,出于性能考虑,本文使用GRU模型。相较LSTM,GRU模型结构更简单,在计算复杂度方面更适配本文的数据集;另外,GRU模型在训练过程中更容易收敛且效果与LSTM相差无几,可保证本文模型实际工业落地的时效性。GRU有一个重置门rt和一个更新门zt,在本文中下标t表示时序编号。重置门决定了前一时刻的隐藏层状态有多少比例更新到当前候选隐藏层状态中;更新门决定了前一时刻的隐藏层状态有多少比例更新到当前隐藏层状态。本文所用的GRU模型的公式如式(1)~式(4)所示:
rt=δ(Wr·[ht-1,xt])
(1)
zt=δ(Wz·[ht-1,xt])
(2)
(3)
(4)
其中,Wr、Wz和W是待训练的参数,T(·)和δ(·)是激活函数,输入值xt在本文中为成交报单dt或委托报单ot。
3.3.2 注意力网络
近年来,Transformer 模型[23]及其变体在许多自然语言处理任务中取得了较佳表现,其使用的注意力机制也随之被大量应用于序列建模任务中。本文为了学习到成交报单序列和委托报单序列中隐含的异常信息,使用注意力机制提取循环神经网络隐藏层输出及序列表示中的有用信息。本文所使用的2个不同序列内注意力网络,结构相同,参数不共享。具体而言,本文所使用的注意力机制定义如式(5)所示:
(5)
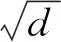
(1)委托/成交报单序列内注意力。
下文以委托报单序列为例,具体展示序列内注意力模块的应用,成交报单序列的操作与之相同。本文使用GRU来对用户委托报单序列SO(o1,o2,…,on)进行编码,得到oi,i∈[1,n],对应的隐藏状态hi∈Rl(l表示单个GRU的隐藏状态单元数),如式(6)所示:
hi=GRU(oi)
(6)
所有GRU输出的隐藏状态HO∈Rn×l如式(7)所示:
HO=[h1,h2,…,hn]
(7)
直观来看,用户委托序列中每条报单造成异常交易的风险是不同的,因此本文选取注意力机制对HO中不同GRU的隐藏状态进行加权融合,得到注意力向量αO∈R1×n如式(8)所示:
(8)
其中,w1∈R1×b,w2∈Rb×l,b为人为设置的参数。
注意力向量的权重大小反映了不同报单对于用户交易行为异常风险的不同贡献。将每个用户行为的隐藏状态hi加权求和,得到委托报单序列的表示BO∈R1×l,如式(9)所示:
BO=αOHO
(9)
同理可得,成交报单序列的表示BD∈R1×l,如式(10)所示:
BD=αDHD
(10)
其中,HD表示成交报单序列在GRU中的隐藏状态矩阵,αD表示相应的注意力权重。
(2)委托及成交报单序列间注意力。
如上文所示,本文存在成交报单SD和委托报单SO2个用户交易序列。注意力机制输入委托报单表示BO∈R1×l和成交报单表示BD∈R1×l,输出Hmix∈R1×d融合了2个表示的信息。注意力机制聚合2个行为序列表示的方法如式(11)所示:
Hmix=aDBD+(1-aD)BO
(11)
权重系数aD可通过softmax函数计算得到,如式(12)所示:
(12)
其中,eD和eO分别表示成交报单序列和委托报单序列的相关性系数。
相关性系数eD可以通过式(13)计算得到:
(13)
其中,Wq∈R1×d和Wk∈Rl×d分别表示可学习的参数向量。同理可得eO。
3.3.3 多层感知机
由于注意力机制的本质是线性模型,本文为了增强其在不同维度的交互性和模型的非线性能力,在注意力层后使用3层前馈神经网络,如式(14)所示:
pi=σ2((HmixW1+b1)W2+b2)W3+b3
(14)
其中,W1∈Rd×d,W2∈Rd×d,W3∈Rd×d,b1∈Rd,b2∈Rd,b3∈Rd为可学习的参数;σ2(·)表示对输入向量中的每个元素利用ReLU进行激活。前馈神经网络构成的多层感知机输出定义为P=[p1,p2,…,pn]∈Rn×d。
3.3.4 序列预测
(15)
其中,Linear(·)表示多维向量到标量的映射函数,sigmoid表示归一化操作。
3.4 损失函数
本文提出的交易行为检测方法可以看做是一个对序列数据进行异常检测的二分类任务,故使用均方误差损失作为损失函数,其计算如式(16)所示:
(16)

3.5 组合预测
本文将以上模块组合为数据与知识双驱动的混合模型,通过结合多种特征来提高异常检测能力。其中,神经网络模块利用深度学习在训练过程中促进模型自动学习特征,机器学习模块利用领域专家人工构建特征。在训练过程中,神经网络模型和LightGBM模型分别对交易报单序列进行训练,各自达到收敛。具体预测时,由于不同模型存在不同的误差,本文考虑根据深度学习网络模型和集成树的误差来赋值,给误差平方和小的模型赋予较大的权重,相反给误差平方和大的模型赋予较小的权重。通过这种组合方式的模型进行组合预测,误差会减小,预测准确度会提高,异常预测结果如式(17)所示:
(17)

4 实验评估
4.1 实验设计
实验所用数据集为智能交易场景中的交易行为数据,包括股票数据集、期货数据集,以及融合了股票、期货、期权、融资融券场景的混合数据集。 其中,部分数据由华鑫证券公司提供,部分数据基于正常和异常的交易策略使用回测工具生成。由于真实数据未覆盖所有类型的异常交易行为,本文针对交易所认定的所有异常交易行为,利用基于正常和异常的交易策略使用回测工具生成相同异常占比的交易行为,其中包括了所有异常情况。在所有类型的数据中,华鑫证券公司提供的真实数据和使用回测工具生成的数据比例为3∶7,异常数据占各自数据0.54%。此外,交易所的异常交易行为判定是基于单个账户每日对单支股票的交易行为,故本文按相应要求将数据条目组织成数据单元,处理后数据集规模和异常情况如表1所示。

Table 1 Statistics of dataset
在评价指标方面,本文选取了针对异常样本的召回率(Recall)、精确率(Precision)、F1分数(F1-score)及全数据的准确率(Accuracy)。由于在异常检测中,异常样本漏检的代价成本更高,本文倾向于在保证模型准确率的前提下,尽量提高异常样本的召回率。模型的召回率、精确率和准确率都依赖于混淆矩阵(如表2所示)的4个基本属性,其中TP表示被正确预测异常的异常样本数量,FP表示被错判为异常的正常样本数量,FN表示被错判为正常的异常样本数量,TN表示被正确预测正常的正常样本数量。异常样本的召回率Recall=TP/TP+FN,异常样本的精确率Precision=TP/TP+FP,全样本的准确率Accuracy=(TP+TN)/(TP+FP+FN+TN)。

Table 2 Confusion matrix
本文选择以下3种基线模型进行对比实验:
(1)SVM(Support Vector Machine):针对有监督的二分类异常检测问题,SVM是最基本和最常用的模型之一,输入特征与针对LightGBM模型构造的特征相同。
(2)RNN:使用GRU模型对交易行为的成交报单序列和委托报单序列分别进行建模,联合预测。
(3)LGB(LightGBM):使用LightGBM模型基于交易行为序列的特征进行异常检测。
本文所提模型和基线模型的最优超参数组合均根据模型通过网格搜索法在验证集上的表现确定。对于LightGBM模型,学习率从集合{0.000 1,0.001,0.01,0.05,0.1}中选择,弱学习器最大个数从集合{50,100,125,150,200,500,1 000}中选择,叶节点最大个数从集合{31,63,127,255,511,1 023}中选择,数据子采样概率和列采样概率均从集合{0.5,0.6,…,1.0}中选择;对于GRU的层数从集合{1,2,3,4}中选择,隐藏层维度从集合{5,10,15,25}中选择,训练批次从集合{10,20,50,100}中选择,序列最大长度从集合{5,6,7,8,9,10}中选择;MLP的参数从集合{1,2,3,4}中选择,学习率从集合{0.000 1,0.001,0.01,0.05,0.1}中选择;本文使用的注意力层均从集合{1,2,3,4}中选择。
本文实验确定使用如下参数:对于LightGBM,学习率为0.1,弱学习器最大个数为1 000,叶节点最大个数为255,数据子采样概率和列采样概率均为0.8;对于GRU,层数为1,隐藏层维度为10,训练批次为10,序列最大长度为10,MLP的参数为3层,学习率为0.01;本文使用的注意力层均为1层;另外,对于SVM基准方法,核函数采用sigmoid,惩罚系数为2,核系数为10。
4.2 实验结果及讨论
本文模型在智能交易数据集上的实验结果如表3所示,可以发现融合LightGBM和GRU的组合模型在各种类型数据上的全部指标均取得了最佳结果。在这些金融异常检测的数据集中,单个LightGBM或者GRU也可以取得不错的准确率,而SVM在多类数据上表现欠佳。与文献[21]中提到的情况相同,SVM对于复杂的序列数据缺乏良好的建模能力,神经网络的隐藏单元可以更好地捕获其中的异常信息。

Table 3 Anomaly detection performance of each model under different types of data
4.3 消融实验
4.3.1 LightGBM模型特征影响分析
本节通过消融实验来验证所设计的数据特征在模型中的作用,实验结果如表4所示,其中,-1代表累计申报/成交金额类特征,-2代表累计申报/成交数量类特征,-3代表撤销申报数量比例类特征,-4代表是否快速撤销类。由于篇幅限制,表4只展示在全类型数据集上的结果。从表4可以看到,无论是单个LightGBM还是组合模型,每种特征的减少都会对模型性能造成负面影响。单个LightGBM虽然有训练快、简单易用的优点,但其更依赖于先验知识的特征工程,累积申报/成交金额数量和金额影响相对更大。而本文使用的LightGBM和神经网络的混合模型性能虽然同样会受到特征缺失的影响,但是深度神经网络可以学到部分特征中隐含的知识,性能影响的幅度更小。

Table 4 Ablation experimental results with different features
4.3.2 序列模型注意力机制影响分析
为了验证本文提出的用户行为序列间注意力机制和用户行为序列内注意力机制的有效性,本节在序列模型中对用户行为序列间注意力机制和用户行为序列内注意力机制进行消融实验。表5给出了不同网络结构在全类型数据集上的实验结果,其中,-Ⅰ表示缺失用户行为序列间注意力机制, -Ⅱ表示缺失用户行为序列内注意力机制,-Ⅲ表示缺失用户行为序列间注意力机制和用户行为序列内注意力机制。

Table 5 Ablation experimental results with different attention mechanisms
由表5可以看出,当去掉用户行为序列间注意力机制或用户行为序列内注意力机制时,模型效果均有所下降,一方面说明了注意力机制对模型异常检测的重要影响,另外也验证了融合用户行为序列内行为和融合委托序列和成交序列的必要性。
4.3.3 序列模型不同用户行为序列影响分析
本节主要讨论所提出的序列模型中涉及的2种用户行为序列,即成交序列和委托序列对模型效果的影响。表6给出了不同模型在全类型数据集上的实验结果,其中,-Ⅳ表示缺失成交序列,-Ⅴ表示缺失委托序列。
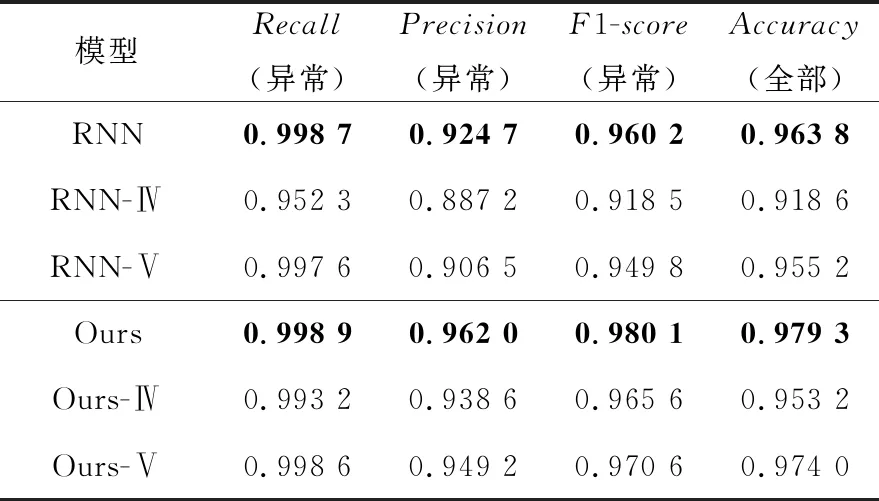
Table 6 Ablation experimental results with different user behavior sequences
由表6可以看出,当去掉成交序列或委托序列后,模型效果在F1-score指标上分别下降了4.17%和1.04%,在Accuracy指标上分别下降了4.52%和0.86%。这一方面说明了成交序列和委托序列都对序列模型的异常检测有重要影响,另外也看到成交序列对于模型效果的影响要远大于委托序列的,说明用户在成交序列上更容易出现异常交易行为。
4.4 案例分析
上述实验说明本文模型满足交易所异常检测的需求,但是反欺诈部门可能还需要了解一些用户为什么会被判断为异常。因此,本文在关注智能金融交易效率的同时,也针对智能金融领域的异常情况种类繁多、深度学习模型可解释性差的问题,利用自注意力机制结合LightGBM模型给出的特征重要性,通过以下案例说明本文提出的模型是如何判断出具体的用户异常行为的。
如前文所述,用户行为序列包括成交报单序列和委托报单序列,其中委托报单序列的每种行为包括以下7个特征:类型(股票或融资融券0、期货1、期权2)、阶段(不区分阶段0、开盘集合竞价1、连续竞价2、收盘集合竞价3)、组合开平标志(开仓0、平仓1、强平2、平今3、平昨4)、价格、数量、方向(买0、卖1)和撤销(未撤销0、非快速撤销1、快速撤销2);而成交报单序列的每种行为包括以下6个特征:类型(股票或融资融券0、期货1、期权2)、阶段(不区分阶段0、开盘集合竞价1、连续竞价2、收盘集合竞价3)、组合开平标志(开仓0、平仓1、强平2、平今3、平昨4)、价格、数量和方向(买0、卖1)。
选取如图3所示的一个异常的用户行为序列说明注意力机制的可解释性。图3中加黑数字代表注意力的权重大。

Figure 3 A case of abnormal user behavior sequence
如图3所示,正常的交易行为中不应该出现大量申报并撤销的情况,尤其是快速撤销申报,这种行为将引诱、误导或影响其他投资者的正常交易行为。本文基于注意力机制,会重点关注到委托报单数据的“撤销”特征,识别出其连续出现的“快速撤销”属性,注意力机制会赋予序列中相应位置的报单更高的权重,并最终作出该数据属于异常交易行为的判定。
5 结束语
智能交易的普及给券商平台带来了运营合规风险性。本文着重研究了智能交易行为的异常检测这一新问题并收集了多类型的智能交易数据集。针对智能交易行为数据中蕴含的序列性和合规性特点,本文提出了简单而有效的模型混合方法,将深度神经网络的序列表征能力和集成树模型LightGBM的规则融入能力相结合。交易数据集上的实验结果表明,所提出的模型优于有代表性的基线模型且具有合理性和可解释性。
