基于预训练模型的命名实体识别研究
2023-09-18胡叮叮张琛王之原
胡叮叮 张琛 王之原
摘 要:目前中文命名实体识别存在的主要的问题有:实体的边界模糊,实体边界和非实体之间也存在边界模糊问题,并且在小数据集下模型识别效果不明显。为了解决以上问题,通过加强对文本上下文语义特征的提取能力,使模型能够根据上下文语义特征来精准地推测出实体,提出一种BERT_BiLSTM_CRF的模型,BERT可以根据文本上下文信息,使每个词在文本语义中对应一个低纬的稠密的词向量,BiLSTM可以捕获时序特征,并且使用CRF来对输出标签的顺序进行约束。经实验表明,使用预训练模型获取的动态词向量比随机初始化的词嵌入有显著提高。
关键词:预训练模型;命名实体识别;动态词向量;BiLSTM;CRF
中图分类号:TP391.1;TP183 文献标识码:A 文章编号:2096-4706(2023)15-0078-05
Research on Named Entity Recognition Based on Pre-training Model
HU Dingding, ZHANG Chen, WANG Zhiyuan
(Gansu University of Political Science and Law, Lanzhou 730070, China)
Abstract: The main problems in Chinese named entity recognition are the boundary of entities is blurry, the boundary between entity boundary and non-entity is also blurry, and the recognition effect of small data set model is not obvious. In order to solve the above problems, by strengthening the extraction ability of semantic features of the text context, this paper makes the model can accurately infer the entity according to the context semantic features, and proposes a BERT _BiLSTM_ CRF model. According to the text context information, BERT can make each word in the text semantic to correspond to a dense word vector at low latitude. BiLSTM can capture temporal features, and use the CRF to constraint the order of output labels. The experiments show that the acquired dynamic word vector by using the pre-training model improves significantly over the randomly initialized word embedding.
Keywords: pre-training model; named entity recognition; dynamic word vector; BiLSTM; CRF
0 引 言
随着互联网技术的蓬勃发展,网络上产生了海量的数据,同时这些海量的数据又促进了数据处理技术的发展。以文本为信息载体的数据形式,即自然语言,在网络数据中占据一定的比例。研究如何自动化地从这些文本数据中挖掘出有价值的信息,是自然语言处理的一个热门方向。命名实体识别任务研究如何从文本中自动化地将实体提取出来的一门技术,主要是识别出文本中的人名,地名,机构名等,对下游任务的进行起到基础性的作用,比如知识图谱的构建。命名实体作为自然语言处理的上游任务,其抽取的准确率对于后续的文本处理任务具有重要的意义。
命名实体识别[1]任务中最基础的一步是文本向量表示,一个好的文本向量表示是下游任务的关键。文本向量表示最简单的方式是独热编码(one-hot),但其仅可以获得词频和词共现的特征,丢失了文本时序信息。随后Bengio [2]等人2003年提出神经网络语言模型,通过高维空间连续稠密的词向量解决one-hot编码中稀疏的问题,神经网络获得更好的泛化能力。并且首次提出词向量的概念。词向量的引入解决了统计语言模型部分相似性的问题,为后续NLP(Natural Language Processing)词向量时代的发展做了铺垫。但是作为早期的文本表示方法,依然存在一些问题,比如训练时间长、学习出的词向量效果一般等。随后Word2Vec[3]出现,在经过大量的中文语料进行无监督的学习,最终得到的词向量具有一定的通用性,但Word2Vec是一种静态的词向量,Word2Vec无法应对灵活多变的中文多义词情况,此种情况下对文本的理解会产生歧义,从而导致命名实体识别的识别效果不够准确。
2018年,预训练语言模型BERT [4]横空出世,学者们将BERT应用于NLP各项任务,比如文本分类任务[5]、序列标注任务[6]等,因其可以根据文本上下文动态地表示词向量,解决了一词多义问题。Wen等人[7]在中医中使用BERT进行了实体识别,证明了预训练的语言模型在中医文本的命名实体识别任务中的有效性。
本文使用BERT作为命名实体识别的词向量表示模型。在模型特征提取过程中使用BiLSTM模型,其由两个单向的长短时记忆神经网络(Long Short-Term Memory, LSTM)组成,最终形成的词向量作为该词的最终特征表达。这种神经网络结构模型对文本特征的提取效率和性能要优于单个LSTM结构模型。由于CRF(Conditional random field)[8]可以对输出序列的顺序进行约束而被广泛用于序列标注任务中,本文在模型的最后加上CRF作为模型最终的输出,进一步提高输出序列的精度。经过实验验证,本文提出的模型在命名实体识别任务上較其他模型的精度有所提高。
1 相关技术
1.1 词向量
词向量主要有静态词向量和动态词向量。静态词向量最典型且使用最广泛的是Word2Vec,虽然在各个领域上具有一定的通用性,但其无法解决一词多义问题,即一个词只对应一个固定的向量,而现实情况是,根据不同的语境,同一个词会有多种含义,使用静态词向量就会导致无法正确理解文本的含义。而动态词向量,顾名思义,是可以根据文本上下文信息来动态地表示每个词在文本中的意思。例如“我喜欢苹果”这句话,如果没有下文,“苹果”一般会被认为是一种实体,但是接了下文,比如“像素高”,“苹果”和“像素高”产生了关联,那么“苹果”对应的词向量表示会大不一样。而静态词向量,即一个词只能有一个固定的含义,而现实情况是,中文在不同的语境下有多种含义,静态词向量容易产生歧义。而动态词向量是通过周围词的关联来确定的,就不存在多义词问题,获取动态词向量的方式主要介绍两种:随机初始化的Embedding和预训练模型。
随机初始化Embedding,主要的实现过程是先统计出整个语料所有不同字的字数为n,并且预先设定每个字以多少维度的向量表示,假设以d维向量表示每个字,随机初始化一个二维的矩阵H n×d,H相当于一个词表,通过梯度下降,更新这个词表。假设Embedding层的输入形状为b×m(b为batch_size,m是序列的长度),则输出的形状是b×m×d。
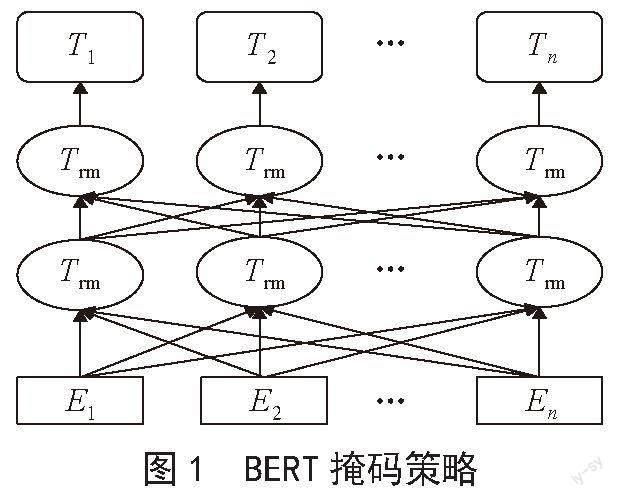
预训练模型是设计较为复杂的神经网络模型,由双向的Tranformer的encoder组成,整体是一个自编码语言模型,从损坏的输入数据中预测重建原始数据,核心技术就是自注意力机制[9],如图1所示。第一个任务是采用MaskLM的方式来训练语言模型,思路是在输入一句话,随机地选15%的进行掩盖,用一个特殊的符号[mask]来代替被掩盖的词,然后让模型根据所给的标签去预测这些被掩盖的词。第二个任务是在双向语言模型的基础上增加了一个句子级别的连续性预测任务,即预测输入BERT的两段文本是否为连续的文本,引入这个任务可以更好地让模型学到连续的文本片段之間的关系。BERT相较于原来的RNN、LSTM可以做到并发执行,同时提取词在句子中的关系特征,并且能在多个角度提取关系特征,进而更全面反映句子语义。相较于Word2Vec,其又能根据句子上下文获取词义,从而避免歧义出现。BERT作为一种预训练模型,在特定场景使用时不需要用大量的语料来进行训练,节约时间效率高效,泛化能力较强,在小数据集下通过微调,也能够取得不错的效果。BERT是一种端到端的模型,不需要调整网络结构,只需根据下游任务在最后加上特定的输出层即可。
1.2 BiLSTM模型
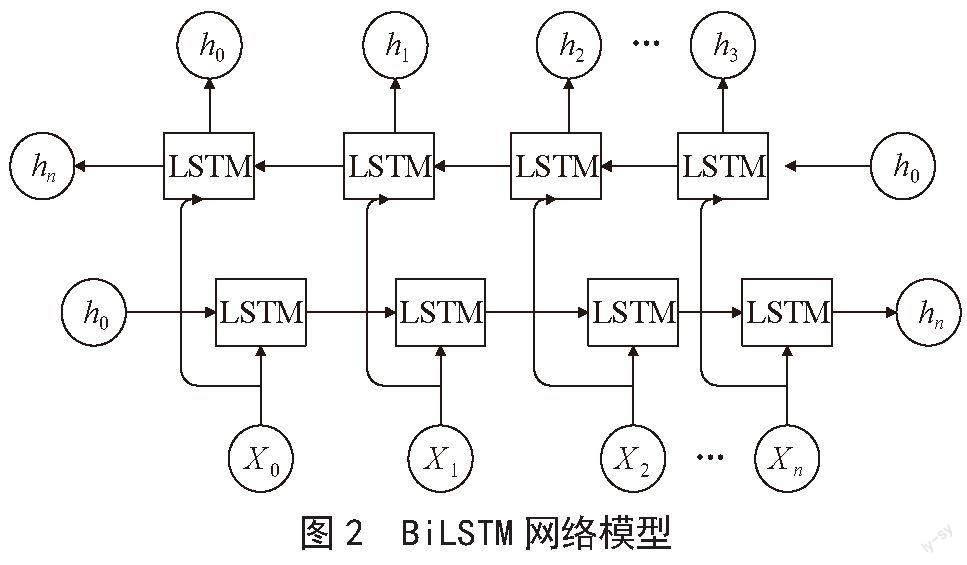
长短时记忆网络LSTM是属于循环神经网络的一种,在时序数据预测上表现出不错的效果,例如语音识别、文本翻译等领域。LSTM作为RNN的有效改进,解决了长距离信息丢失的问题。在命名实体识别领域,LSTM可以有效提取文本时序特征,从而能够更好地理解文本内容。而双向长短时记忆网络BiLSTM在提取文本特征上更进一步。BiLSTM由前向LSTM与后向LSTM组合而成,在时序数据的序列输入中,当前的输出不仅与前面的文本有关系,也与后面的文本有关系,单向的LSTM只能按照从前往后的顺序进行更新隐藏层状态,无法利用序列的后文信息,而BiLSTM可以捕捉双向语义,即可以捕获输出序列从前往后的信息,也可以获得输出序列的从后往前的信息。最后将两者不同的顺序进行结合,得到BiLSTM模型的输出,BiLSTM的结构如图2所示。
1.3 条件随机场
条件随机场(CRF)是一种判别式的模型,在通过输入文本序列中建立远程依赖关系,从全局的角度获得最优的预测标签序列。假设给定输入文本序列x,和对应的标签序列y。对文本序列对应的打分如下:
式中:A表示转移概率矩阵,是序列标签的个数,另外两维是起始状态和结束状态, 表示由标签转移到标签的转移得分,Pij表示第i个字为j的概率得分,整个序列的分数总数等于各个位置的打分之和。因为预测的序列有很多种情况,种类为标签的排列组合大小。只需选取得分最大的组合,通过神经网络训练使得最大得分的Score在所有Score中的比重越大越好。最后使用Softmax函数归一化得到所有的标签序列的概率。如式所示:
1.4 序列标注
在命名实体识别任务中通常采用序列标注的形式,即对文本中每一个汉字给出一个对应的标签,例如使用最简单的BIO标注方式。B表示实体的开头,I表示实体的除了开头的其他部分,O表示其他的词。如B-PER、I-PER代表人名首字、人名非首字的其他部分,B-LOC、I-LOC代表地名的首字、地名非首字的其他部分,而B-ORG、I-ORG同理代表组织机构的相应位置。模型通过大量的训练,最后预测出输入文本对应的标签。
2 模型构建
2.1 模型整体架构
提出的模型由BERT、BiLSTM和CRF三部分组成,如图3所示。输入序列经过BERT得到序列中每个字的向量表示,然后在特征提取层,使用BiLSTM层提取序列的时序特征,最后将经过BiLSTM得到的输出作为CRF算法的输入,对标签序列的顺序进行约束,得到最终输出的标签序列。
2.2 BERT层
首先将文本输入序列的每个字进行id映射,变成机器能够识别的数值型,此过程为文本的token嵌入,再将输入序列进行位置编码,融入每个字的位置信息,然后进行分段编码,分段编码将整个输入句子编码为0,最后将三个嵌入向量对应位置进行相加,得到BERT的输入。由于训练BERT预训练模型需要花费大量的时间和算力,因此本文下载已经训练好的模型参数作为初始化参数。假设xi表示输入句子的第i个词的id,经过BERT模型,每个字对应的输出维度是768,每个字对应的动态向量具体为:
vwi=BERT(wi)(3)
2.3 BiLSTM层
前向LSTM和后向LSTM同时进行训练,输出也是由前向隐藏状态和后向隐藏状态共同决定,即将双向的LSTM的每个时刻的输出进行向量拼接,得到某一时刻的状态输出,t时刻的BiLSTM的输出如下:
2.4 CRF层
CRF层的作用就是对最终序列标注进行约束,由式(2)得到每个输出序列标签的概率,目标是使得其中的一组输出序列的概率最大。假设y′表示真实标签,Yc表示所有可能标签的集合空间,然后使用最大似然函作为损失函数来优化模型参数,最后利用维特比算法求得全局最优序列,最优序列为最终序列标注任务的标签序列结果。最终的损失函数如下:
模型以预测出概率最高的标注序列为目标进行训练,通过梯度下降法,使得Loss的值下降,最终转为求Loss最小值的数学问题。
3 实验及结果分析
3.1 实验数据集
本章所有实验数据来源自Aishell 3语音对应的文本内容,经分析发现该数据集含有大量的实体数据,涉及智能家具、无人驾驶、工业生产等11个领域,因此作为本实验的训练语料。在实验数据上选取了句子长度在5个到25个之间的数据,选取了5 000条数据作为模型的训练集,500条作为模型的验证集。
3.2 预训练模型的微调方式
训练BERT模型需大量的时间和算力,而且需要大量的语料作为训练集,并且从头开始训练,对于BERT具有千万参数量的大型神经网络是不现实的。因此本文采用训练好的已经发布的“bert-base-chinese”模型,并在此基础上进行微调。微调的方式有以下两种:
1)固定预训练模型的所有参数,只对自定义的网络参数进行训练。
2)不固定任何的参数,将预训练模型的参数作为整个模型的初始化,并且更新整个网络的参数。
第一种方式因为只训练自定义的网络,更新的参数量少,节省计算时间和成本,但是只训练自定义的网络,在一些非通用數据集上效果往往不明显。因此,本文选择第二种方式,使用经过大量语料训练后的预训练模型参数进行模型的部分初始化,然后在本文提出的数据集上进行模型的训练,在训练过程中不断地更新网络中的所有参数。
3.3 参数设置
优化器使用Adam(Adaptive Moment Estimation),学习率设为0.001,批处理为64,BERT的隐藏单元数为768,BiLSTM的隐藏单元为768,为了防止模型过拟合,除了Embedding模型,所有的模型都设置了dropout,且都设为0.2。
3.4 评价指标
为了准确评估所提出模型的命名实体识别性能,使用精确率P(precision)、召回率R(recall)和F1评价指标在验证集上来衡量模型的准确度。混淆矩阵的一般形式如表1所示。
评价方法:采用精确率P,召回率R,和F1为模型评价指标,其计算式如下。
P的公式可以表示:
3.5 实验结果与分析
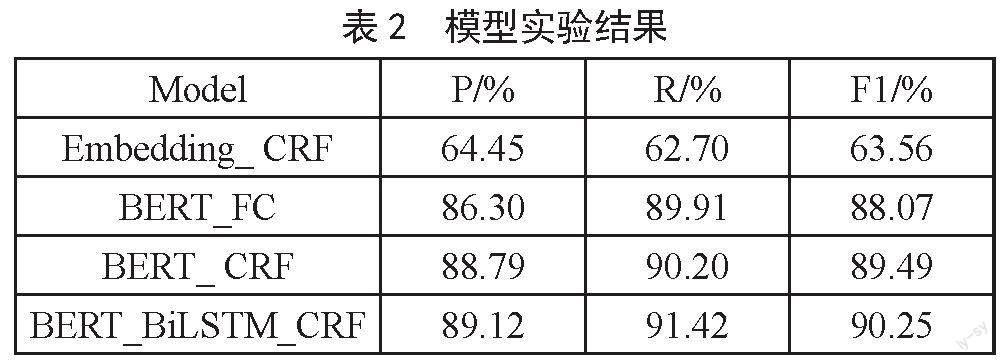
为了验证BERT对文本表示向量的准确性,选取了随机初始化的Embedding作为模型的对比,也为了验证加入的深度学习模型BiLSTM和CRF能够提高命名实体识别性能,设置了一组消融实验,如只有简单的BERT和全连接层FC、BERT_CRF,并在自选的小数据集上进行实验验证。实验结果如图表2所示。
从表2可以看出,随机初始化的词嵌入模型Embedding_CRF模型和使用BERT_CRF模型的F1的值相差约26%,由此可见使用BERT模型具有明显的优势,说明经过大量的中文语料的学习,预训练模型可以学习到更多的文本语义信息。随机初始化的Embedding虽然可以经过反向传播进行更新网络参数,学习到词与词之间的关系,但是所得的动态词向量依然达不到文本表示向量精确度的要求,并且和预训练模型存在较大的差距。分析其原因有:第一,在小数据集下,训练文本语料不足,而预训练模型是经过大量的文本语料的学习从而模型具有强大的泛化能力,在小数据集上同样也表现出较好的效果。第二,网络的设计,Embedding模型的网络结构简单,最重要的网络结构只有线性层网络,而BERT的网络结构设计复杂,有多头注意力层、归一化层、前馈神经网络层和残差网络,其中最重要的多头注意力层可以从文本的多个角度来提取文本特征,从而使得BERT在文本表示上具有显著的效果。
BERT和BERT_CRF模型的对比实验中加入了CRF,F1的值提升了1%,说明CRF对模型的最终输出序列的顺序起到了约束的作用,这种约束规范有助于提高模型的准确率。模型BERT_BiLSTM_CRF和模型BERT_CRF对比实验,发现加入了BiLSTM比没有加入的模型,提取效果有了一定的提高,说明BiLSTM捕获双向的时序信息,对模型的准确率起到了一定的作用。
4 结 论
针对命名实体存在边界模糊和在小数据集下效果不明显的问题,本文主要从提高文本表示能力角度出发,提出使用预训练模型获得动态词向量。该动态词向量携带了大量的语义信息,可以更加精确地表示文本。在特征提取模块,选择了BiLSTM,可以从文本前后两个角度深入提取文本特征,在最终输出的标签序列使用CRF对标签序列输出顺序进行约束,减少非法的输出,来获得最优的输出序列。实验和随机初始化的词嵌入方式进行对比,发现预训练模型在命名实体识别中,效果有显著提高,说明了预训练模型作为文本表示具有明显的而优势,并且通过消融实验发现,加入了BiLSTM和CRF模型具有更好的特征提取能力。
虽然使用预训练模型进行中文命名实体识别取得了较好的效果,但是依然存在一些问题,如BERT预训练模型的参数量大,导致训练时间过长,后续的研究将选取一个轻量级的预训练模型,并搭配不同的神经网络模型,进一步寻找文本序列内部联系。
参考文献:
[1] 王颖洁,张程烨,白凤波,等.中文命名实体识别研究综述[J].计算机科学与探索,2023,17(2):324-341.
[2] BENGIO Y,DUCHARME R,VINCENT P,et al. A Neural Probabilistic Language Model [J].Journal of Machine Learning Research,2003(3):1137–1155.
[3] MIKOLOV T,CHEN K,CORRADO G,et al. Efficient Estimation of Word Representations in Vector Space [J/OL].arXiv: 1301.3781 [cs.CL].(2013-01-16).https://arxiv.org/abs/1301.3781v1.
[4] DEVLIN J,CHANG W,LEE K,et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [J/OL].arXiv: 1810.04805 [cs.CL].(2018-10-11).https://arxiv.org/abs/1810.04805.
[5] 苗將,张仰森,李剑龙.基于BERT的中文新闻标题分类[J].计算机工程与设计,2022,43(8):2311-2316.
[6] 李雪思,张智雄,刘欢.一种基于序列标注的概念短语抽取方法[J].图书情报工作,2022,66(11):121-128.
[7] WEN S,ZENG B,LIAO W X. Named entity recognition for instructions of Chinese medicine based on pre-trained language model [C]//Proceedings of the 2021 3rd International Conference on Natural Language Processing.Piscataway:IEEE,2021:139-144.
[8] 宋功鹏,李阳,安新周,等.基于CRF和LSTM的文本序列标注方法研究[J].信息技术与信息化,2022(7):129-132.
[9] VASWANI A,SHAZEER N,PARMAR N,et al. Attention is all you need [C]//NIPS'17:Proceedings of the 31st International Conference on Neural Information Processing Systems.Long Beach:Curran Associates Inc,2017:6000-6010.
