基于相空间重构的辐射源个体识别技术综述
2023-09-15赵雨睿黄知涛
赵雨睿 黄知涛 王 翔
(国防科技大学电子科学学院 长沙 410073)
1 引言
辐射源个体识别(Specific Emitter Identification,SEI)技术,是指对接收的电磁信号进行特征测量,根据已有的先验信息确定产生信号辐射源个体身份的技术[1],又称为辐射源指纹识别。同型号、同参数辐射源个体的差异是由于内部物理器件的非理想特性造成的,通过提取辐射源信号中能够反映这种差异的有效特征(又称指纹特征),就能准确辨识辐射源个体身份。“特定辐射源识别技术”这一技术概念可追溯至20世纪60年代。美国海军研究实验室率先将其应用于雷达目标系统的识别任务。经过长达半个世纪的发展,国内外学者研究设计了大量的指纹特征,拓展SEI技术应用于雷达、通信、导航等目标,使得SEI技术在频谱监管、目标跟踪、物理网安全等领域取得了一定的应用效果[2]。
现有SEI技术的分类方法主要有3种:一是根据目标对象进行划分[3,4],如雷达辐射源个体识别技术[5,6]、通信辐射源个体识别技术、导航设备个体识别技术等;二是根据信号状态进行划分[4,7],如基于瞬态信号的辐射源个体识别技术[8]、基于稳态信号的辐射源个体识别技术[9]等;三是根据特征提取方式进行划分[2],如基于特征工程的辐射源个体识别技术[10]、基于深度学习的辐射源个体识别技术[11-13]等。此外,还可以根据指纹特征提取变换域不同,分为时频图[14]、星座图[15]、高阶谱[16]、相空间重构(Phase Space Reconstruction,PSR)[17]等分支。其中,基于相空间重构的辐射源个体识别方法(Specific Emitter Identification based on Phase Space Reconstuction,SEI-PSR)是由美国海军研究室的资深研究员Carroll[17]在2007年首次提出的。Carroll研究员凭借其在非线性动力系统领域的多年研究经验,推断相空间重构技术可有效表征探究辐射源系统的非线性动力学特性,进而描述独一无二的辐射源硬件特性。Carroll研究员搭建了采用不同功放的信号发射电路,实验表明通过比较相轨迹的时间微分所获得的统计量,可从信号正弦稳态部分中提取由功放引起的非线性无意调制指纹特征。在此研究基础上,诸多学者在15年的时间内对SEI-PSR技术展开了一系列的研究,所设计的指纹特征包含关联维数[18,19]、最大Lyapunov指数[18,19]、相轨迹形状[20]等。目前,该技术已经成功应用于雷达、通信电台、通用软件无线电、无线网卡、手机、舰船等诸多类型辐射源。从信号体制角度而言,该类技术广泛覆盖了单音信号、雷达信号、数字调制信号、蓝牙信号、WiFi信号等。
大量的实验表明,相空间重构技术以其刻画非线性动力性的出色能力,在辐射源个体识别领域具有独特的优势。首先,相空间重构技术将辐射源设备视作一个完整的系统,描述其内部器件的电路特性,与辐射源硬件特性紧密相关,具有较强的可解释性,可用于解决指纹特征可解释性弱的问题。其次,重构相空间通过相点及相点间的转移规律,着重描述了系统的动力学特性,为放大微小硬件差异、提取有效的指纹特征提供可能。再次,与以往对某一器件单独建模分析不同,重构相空间是从动力学角度对辐射源整个系统进行描述,蕴含了所有器件的特性以及器件间的耦合关系,具备提取未知辐射源指纹特征的潜能。但由于SEI-PSR技术研究时间较短且研究较为分散,现有的综述文献大多总结罗列了现有的基于相空间重构的辐射源个体识别方法[2-4,7],未能系统地阐述SEI-PSR技术的理论基础及发展脉络。
为弥补这一领域欠缺,本文从理论基础、研究现状、未来前景3个方面对SEI-PSR技术进行系统性梳理归纳。
2 理论机理探究
2.1 理论基础
2.1.1 系统吸引子
在非线性动力学中,每个辐射源都可视为一个确定性动力系统,即所有系统变量可用确切的函数关系来描述,系统的运动特性可以完全确定。可采用微分方程描述辐射源系统在相空间S(S ⊂Rm)中的时间演化规律[21],表示为
其中,x=[x1(t)x2(t) ...xm(t)]为辐射源系统在t时刻的状态,属于系统状态空间S内,相空间的维数m表示系统的自由度。随着系统的演化,系统状态x趋向于某一组稳定状态集合A,即系统的初始状态终将会被吸引到低维集合A上。该集合是系统相空间的子集,描述了系统的稳定行为,称为吸引子(Attractor)。根据非线性动力学特性不同,系统吸引子结构也不相同。系统吸引子可以是一个点、一组点的集合、一条曲线、一个流形,甚至是一个具有分形结构的复杂集合。
根据非线性动力学规律,辐射源系统的工作状态终将收敛至其吸引子上。系统吸引子上的状态点描述了辐射源系统稳定时所有可能处于的状态集合,状态点之间的转移描述了系统的演化规律,即其非线性动力学特性。由于生产工艺的限制,每个辐射源系统硬件均与理想情况存在一定的偏差,表现为系统非线性动力学特性间的差异,故每个辐射源系统都具有与之一一对应的吸引子。独一无二的系统吸引子能够描述辐射源硬件的特性,蕴含个体身份信息,可以作为系统辨识的依据。相比于其他变换域,系统吸引子能够更为直接地呈现辐射源系统的非线性动力学特征,有利于提取具有高辨识度的指纹特征。然而,由于观测手段的限制,通常难以测量辐射源系统中各个变量的实时状态,即无法直接获得辐射源系统吸引子。为解决这一问题,需从观测数据中测量系统吸引子结构,并寻找其特性作为辐射源个体指纹特征。
2.1.2 相空间重构技术
由于动力学系统中的每一个状态分量都与其他分量相互作用,因此整个吸引子的动力学特性反映在系统某一状态分量的观测值中,即通过观测系统的标量时间序列便能够重构系统的状态空间,且其中蕴含着系统吸引子。从标量时间序列中重构与系统吸引子等价的相空间,称为相空间重构技术[21]。相空间重构技术为从时间序列中分析系统动力学特性并预测系统演化规律提供可能,被广泛应用于金融分析[22,23]、故障检测[24,25]、时序预测等领域[23]。
在如何重构系统相空间这一问题上,目前有两种方法应用较为广泛。一是1980年Packard等人[26]提出的导数法,即一维序列的不同阶导数构建相空间矢量。二是1981年Takens[27]提出坐标延迟法,即采用不同的延时时间构建相空间矢量。Noakes[28]对这一定理的证明过程进行了详细的补充。在两者基础上,Gibson等人[29]证明了在一定条件下导数法是坐标延迟法的旋转。二者相比而言,坐标延迟重构法计算量小,数值精度高、物理意义明晰,应用更为普遍。因此,本文采用坐标延迟重构法重构系统相空间。假设系统的观测时间序列为
其中,N为信号长度。在SEI任务中,观测时间序列s(n)即 为接收机截获信号。利用不同的延迟时间τ来构造m维相空间矢量
为实现对系统的非线性动力学特性分析,需要设置适当的延迟时间τ与嵌入维数m,进而保证系统重构相空间S与其吸引子等价。
Takens[27,28]在提出延迟坐标法的同时证明了嵌入定理,即对于无限长、无噪声的d维系统吸引子,只要维数m ≥2d+1,总可以从其标量时间观测序列s(n)中找到一个m维的嵌入相空间,且该重构相空间与系统吸引子微分同胚等价。嵌入定理保证了延迟坐标技术可以从一维观测时间序列中重构一个与原动力系统在拓扑意义下等价的相空间,即二者微分拓扑等价。然而,在现实的应用场景中,理想的无噪声、无限长信号是不存在的,因此如何选择适当的延迟时间τ与嵌入维数m尤为重要。
2.1.3 重构参数确定
在利用坐标延迟技术重构系统相空间时,嵌入维数m与延迟时间τ的确定在很大程度上决定了重构相空间的质量。重构参数选择的目标是使重构相空间和吸引子的近似程度达到最优,即尽可能地做到微分同胚。
选取延迟时间τ的目标是使原时间序列经过延迟时间后可以作为相对独立的坐标使用。如果τ太小,则相空间矢量的任意两个分量在数值上非常接近,具有强关联性,信息冗余量较大。如果τ太大,则两坐标在统计意义上又是完全独立的,即二者间不存在关联性。因此需要确定一个合适的τ值。选择嵌入维数m的目标是尽可能保证重构相空间与系统吸引子拓扑等价。若嵌入维数m过小,则吸引子可能会出现折叠甚至自相交的现象,即重构相空间某些区域的较小邻域内会包含吸引子不同轨道上的相点,导致重构相空间和原始吸引子结构差异较大。若嵌入维数m过大,虽然吸引子的几何结构被完全打开,但计算量显著增加,带来计算资源的大量消耗,且在重构相空间中噪声的影响会被进一步放大。
现有的延迟时间τ与嵌入维数m的估计算法主要可以分为两种:
第1种观点认为延迟时间τ与嵌入维数m是互不相关的,即先求出延迟时间之后再根据它求出合适的嵌入维数。对于延迟时间的选取,目前常用的方法有自相关法[30]、平均位移法[31]和互信息法[32]等。而对于最小嵌入维数m的选取,目前的方法主要是几何不变量法[33]、虚假最临近点法(False Neighbor Nodes,FNN)[34]及其改进形式Cao氏方法[35]。
第2种观点则是认为延迟时间τ和嵌入维数m是相关的,即通过算法同时估计出延迟时间τ和嵌入维数m。1986年,Broomhead和King[36]提出在实际数据处理中,可以采用固定的时间窗口tw=(m-1)τ来确定延迟时间和嵌入维数两个参数,通过两个参数值之间的相互变化来确定最佳的参数组合。1996年Kugiumtzis[37]提出两个参数的选择是不能相互独立的,两个值应该依赖于延迟窗长tw=(m-1)τ的变化而变化,即只要延迟时间和嵌入维数满足最优的时间窗长度tw>top,则可保证关联维不变。但是该算法在求解的过程中需要经过大量的试验,因此计算量较大。1999年,Kim等人[38]提出了C-C方法,该方法使用关联积分同时估计出延迟时间τ和时间窗tw=(m-1)τ。虽然,C-C方法相对简单,容易实现,但其时间窗参数的估计易被干扰,进而导致嵌入维数的估计有较大的偏差。
综合考虑算法的准确度与复杂度,本文选择分别估计延迟时间和嵌入维数的算法,并分别采用互信息法和Cao氏方法估计延迟时间τ和嵌入维数m。
(1) 延迟时间
在互信息法[32]中,令系统P和Q分别代表两离散信息系统{p1,p2,...,pn}和{q1,q2,...,qm},则根据信息论可知从两系统测量中所获得的信息熵分别为
其中,H(P)和H(Q)分别表示两系统的信息熵,即平均信息量。而Pp(pi)和Pq(qj)则分别代表系统P和Q中事件pi和qj的概率。
在已知系统P的情况下,可获得的关于系统Q的信息,称之为P和Q的互信息,其表达式为
其中,H(Q,P)为系统P和Q的联合熵,可以表示为
其中,Ppq(pi,qj)为事件pi和事件qj的联合分布概率。将式(5)和式(7)代入式(6),则系统P和Q的互信息I(Q,P)可以表示为
在确定延迟时间τ时,定义两时间序列p与q分别为
其中,p代表时间序列s(n),q为其延迟时间τ的时间序列s(n+τ),则二者的互信息I(Q,P)与延迟时间τ紧密相关。令互信息为I(τ),则I(τ)的大小代表了在已知系统s(n) 的情况下,系统s(n+τ)的确定性大小。
当I(τ)=0 时,表示s(n) 与s(n+τ)完全不相关,即在已知s(n) 的情况下s(n+τ)完全不可预测。当遍历延迟时间τ时,I(τ)的极小值表示了s(n)与s(n+τ)最大可能的不相关。因此,在互信息法中选取I(τ)的第1个极小值所对应的延迟时间τ作为最优延迟时间。
(2) 嵌入维数
在Cao氏方法[35]中,m维重构相空间S的每一个相点矢量si=[s(i)s(i+τ) ...s(i+(m-1)τ)]都具有一个最近临点。采用欧氏距离度量两个相点间的距离,则二者间距离为
进一步定义描述距离比变化规律的指标E1(m)为
其中,E(m)统计了整个重构相空间的距离比,可以表示为
若时间序列s(n) 是随机信号,则E1(m)随着m增大而增加;若时间序列s(n)是 确定信号,E1(m)将在m大于某一特定值m0后不再变化。该特定值m0为最小嵌入维数,即当嵌入维数大于该特征值m0时,重构相空间结构完全打开,可以充分体现系统吸引子特性。通常为了提高计算效率,降低计算矩阵维度,直接采用最小嵌入维数m0作为重构相空间中的嵌入维数。
2.2 机理证明
本节旨在采用相空间重构技术从观测数据中重构辐射源系统相空间,进而将辐射源个体识别问题转化为系统吸引子辨识问题。重构辐射源相空间的核心是建立起观测数据与系统吸引子之间的精确映射关系。系统吸引子蕴含了硬件的非理想性特性,可以作为个体身份的辨识依据。本节首先介绍辐射源个体识别的问题模型,而后推导了系统吸引子与其重构相空间的关联,并提出一种基于相空间重构的辐射源个体识别理论框架,最后阐释该框架的优势与意义。
2.2.1 问题模型
从非线性动力学的角度出发,辐射源是一个包含多个子系统的非线性动力学系统,该系统的状态由多个子系统的状态组成,其观测过程则是利用接收机截获辐射源所发射的无线电信号。因此,辐射源个体识别过程是基于截获信号完成对辐射源系统硬件的辨识,如图1所示。

图1 辐射源个体识别系统流程Fig.1 Flowchart of Specific Emitter Identification (SEI)
从图1可以看出,一个典型的辐射源系统一般包括6个部分,即信号源、调制器、高频振荡器、混频器、滤波器以及功率放大器。每一个部分可以认定为一个子系统,则辐射源系统的相点x可以表示为
其中,相点x中每一维度描述了各子系统状态,不同维度共同描述了整个系统当前的状态。辐射源系统中每个组成部分的演变趋势与整个系统当前所处状态和硬件特性关联密切。
令每个子系统的演化方程分别为
进而每个子系统的演化趋势为
考虑更为一般的情况,辐射源系统的非线性动力学特性可以表示为
其中,t是辐射源系统时间,x是辐射源系统相点,F(x,t)是系统的非线性动力学模型。和分别是时间t和相点x的微分,描述了二者的变化趋势。
为简化方程表达式,令系统时间t为系统中的一维变量,则辐射源系统的非线性动力学模型可以表示为
其中,fi(·)为第i个子系统的演化方程,且仅具有非线性特性,而不具有微分结构。d是系统的内蕴维数,反映系统的复杂程度。
在观测辐射源系统时,接收机通过采集、放大、下变频等观测步骤S(·)获 得信号s(n),并将其输入到处理器中,完成辐射源个体身份辨识的任务。当辐射源正常工作时,系统吸引子A的内蕴维数为d,且辐射源系统所有的状态都蕴含其中。
忽略信道和接收机的影响,直接采集辐射源系统所发射的信号,则此时辐射源系统的观测过程可以描述为
其中,S(·)为观测函数,s为系统某一时刻观测值。
辐射源个体间的差异来自器件生产过程。受到工艺水平的制约,每个硬件的工作参数都与理想参数存在着一定的偏差,即fi(·)参数与理想值存在一定偏差。辐射源个体识别的任务就是基于截获的信号,提取独一无二的硬件特性,作为个体识别的依据。从观测信号中,提取辐射源系统的非线性动力学特性,可以表示为
至此辐射源个体识别问题转化为采用观测序列s(n)辨 识演化方程F(·)的特性,进而完成辐射源个体身份的识别。
2.2.2 等价关系证明
当辐射源系统工作在稳定状态时,系统不会出现混沌状态,则其吸引子可以视作一个d维紧致流形A,其中每一相点可表示为x∈A。根据Takens定理[27,28],d维的系统流形A可完全嵌入至一个2d+1维的欧氏空间R2d+1。令F(·)为嵌入函数,则有
其中,ϕ(·)为 系统流形A上 的一个光滑函数,ϕ(i)(·)上标 (i)代表第i阶导数。考虑特殊情况,令观测函数S(·)为 光滑函数ϕ(·),则式(23)可以写为
在延迟坐标技术中,令φ(·):A →A表示流形A上延迟时间τ的作用函数,且S(·):A →R2d+1为流形A的 (2d+1)次 的叠加观测S(·):A →R。进而有
其中,φi(·) 的上标i代表延迟i次τ时长的观测。代入系统动力学方程F(·),则有
其中,Fi·τ(·)为 系统推演i次τ时长的动力学方程。考虑第k次观测s(k),则式(26)可表示为
由于S(·)为微分同胚映射,所以重构相空间S与系统吸引子A间微分同胚,故重构相空间S中包含系统吸引子A,蕴含辐射源个体的指纹特性,可以作为个体身份的辨识依据。
2.2.3 非理想性分析
辐射源中各个器件的非理想性都会造成信号的无意调制,例如数模转换器、成型滤波器、高频振荡器、功率放大器等。不同器件带来的无意调制程度不同,其中贡献最多的是功率放大器的非线性。
理想辐射源发射的单频信号可以表示为
其中,fc为 信号载频,a0为单频信号的幅度。此时辐射源内部结构简单,发射信号即蕴含了整个非线性动力学系统特性。令x=s(t),则此时辐射源系统的非线性动力学方程可以表示为
(1) 功率放大器的非线性
根据文献[39],辐射源的非线性特性模型可以用泰勒级数表示,即
其中,Kam为功率放大器非线性带来的谐波阶数,为功率放大器的非线性参数,k为第k个谐波分量。考虑到阶数越高的谐波分量,能量越弱,本实验中仅考虑模型中的前3项分量,仿真生成10个非线性参数不同的辐射源。
若考虑式(34)中功率放大器的非线性,则此时的非线性动力学方程可以表达为
(2) 高频振荡器的相位噪声
根据文献[40]可知,高频振荡器的相位噪声可以表示为
其中,Kos表示杂散分量的阶数,fk表示第k个杂散分量的频 率,且有fk ≪fc,即fk+fc≈fc。此 时的非线性动力学方程可以表达为
其中,A=diag(a1,a2,...,aKos)描述了不同杂散分量的贡献程度。注意到fk ≪fc,这意味着杂散分量变化的时间尺度远大于其他变量。然而,与变量不同,它是一个缓慢变化的变量。因此,含有杂散分量的吸引子可以看作吸引子在某一频率下漂移。漂移频率取决于杂散分量频率,而漂移幅值与杂散分量幅值相对应。
3 研究脉络梳理
3.1 方法框架
从观测信号s(n)反 推其生成因素F(·)的过程可以归纳为一反问题。该类问题难以获得具体的数值解。基于前文证明的重构吸引子与系统吸引子微分同胚的结论,可以推断出重构相空间S蕴含着硬件的非理想特性F(·),能用于提取硬件的指纹特征。为了解决这一问题,本节提出基于相空间重构的辐射源个体识别理论框架,如图2所示。

图2 基于相空间重构的辐射源个体识别方法框架Fig.2 Framework of Specific Emitter Identification based on Phase Space Reconstruction (SEI-PSR)
从图2可以看出,首先对信号进行预处理主要完成抑制噪声、标准化数据样本等任务,为后续特征提取提供有效样本。其次,利用延迟坐标技术从观测信号中重构系统相空间。重构相空间与系统吸引子具有微分拓扑的等价关系,能够反映辐射源的非线性动力学特性,蕴含着硬件独一无二的非理想性,可以作为个体身份辨识的依据。延迟坐标技术中的延迟时间与嵌入维数的选择分别采用互信息法与Cao氏方法确定。最后,依据重构相空间中所蕴含的辐射源非线性动力学特性进行个体身份的辨识。
辐射源指纹特征提取的实现既可以依赖于人为设计指纹特征,也可利用深度学习自动提取指纹特征。若采用人工特征,则需根据专家经验设计相空间特性的有效表征并选择合适的分类器完成这一任务;若采用深度学习方法,则特征提取步骤与分类识别步骤可一同依赖神经网络完成。
3.2 算法分类
从非线性动力学角度出发,相空间是辐射源个体所有可能状态的集合,描述着辐射源系统的动力学特性,蕴含着辐射源个体独一无二的特性。
自2007年美国海军实验室Carroll[17]利用相空间中相轨迹的微分统计量对不同的功放模型进行识别始,基于相空间的辐射源个体识别技术历经近15年的发展。诸多学者从不同的角度提出了个体识别方法。根据分析所采用信号对象不同,现有的SEI-PSR技术可以分为基于瞬态信号的SEI-PSR技术与基于稳态信号的SEI-PSR技术。瞬态信号是发射机在开/关机或切换工作状态时无意发出的,蕴含辐射源的非线性动力学特性,易于分辨。但瞬态信号是突发形式,不易捕获。相比而言稳态信号更容易获取,但其中包含传输信息的有意调制,不利于指纹特征的提取。根据分析的对象不同,现有的SEI-PSR技术又可以分为雷达、通信电台、软件无线电、手机等。本节则从SEI所提的不同特征入手对现有的SEI-PSR技术进行归纳梳理,进而将现有算法分为统计特性、矩阵特性、几何构型、转移特性以及系统等效性5个方面,如表1所示。
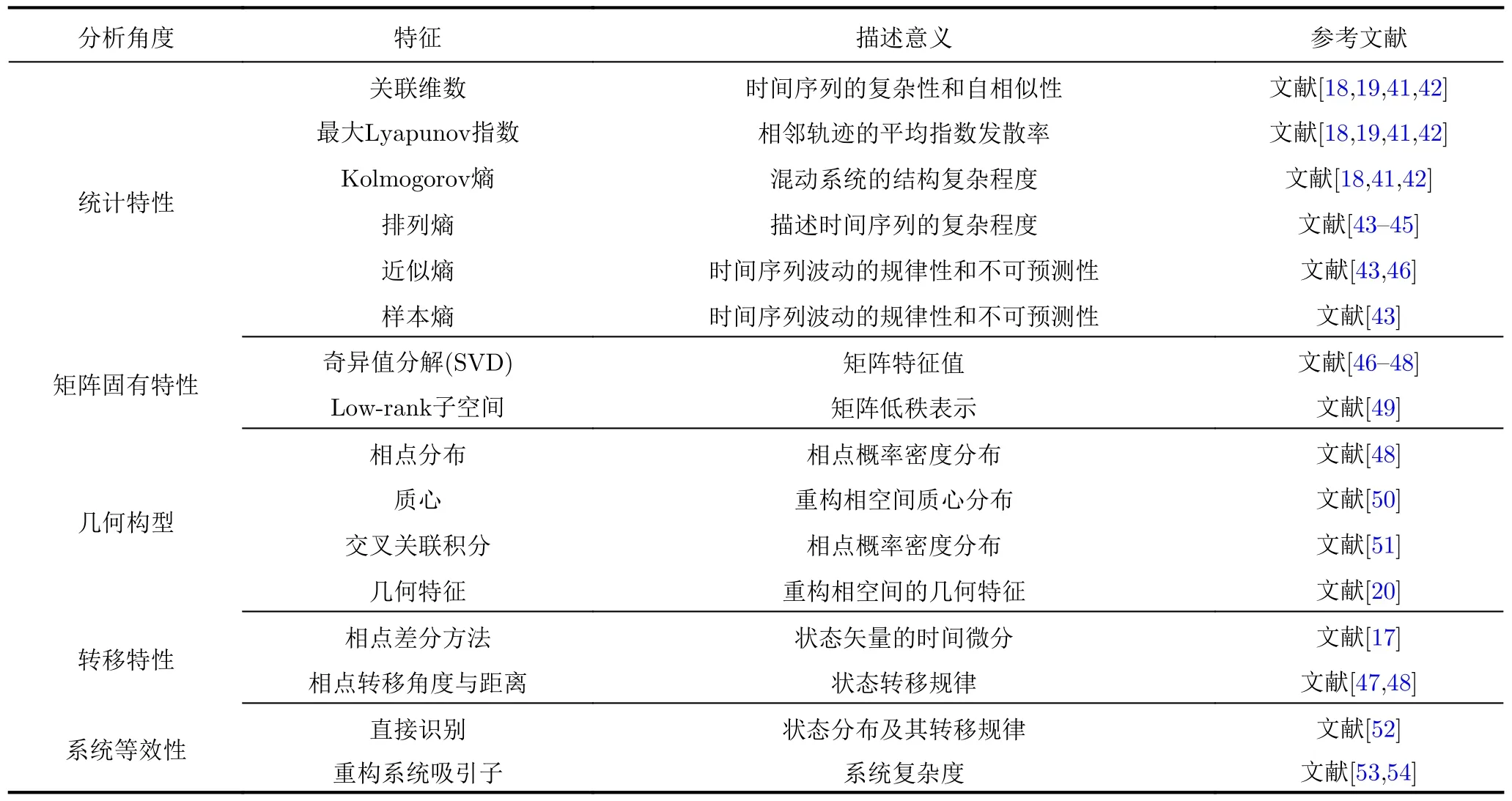
表1 基于重构相空间的辐射源个体识别指纹特征总结Tab.1 Summary of the Specific Emitter Identification (SEI) methods based on Phase Space Reconstruction (PSR)
通常情况下辐射源个体硬件非理想性带来的无意调制能量较小,不同个体的信号间差异较少,重构相空间的延迟时间和嵌入维数相同。本节所总结的算法就是针对延迟时间和嵌入维数相同的情况下重构相空间的指纹特征提取过程。当辐射源个体间差异较大时,即不同个体的嵌入维数或延迟时间不同,延迟时间和嵌入维数即可直接作为辐射源个体身份的辨识依据。
3.2.1 统计特性
从统计学角度而言,统计特性是用数理统计方法研究总体,而非组成总体的个体本身。为通过重构相空间辨识辐射源个体身份,部分学者提出统计重构相空间中相点的特性,作为重构相空间的特性描述,进而用于辨识辐射源个体身份。
(1) 关联维数
关联维数(Correlation Dimension,CD)是混沌系统分析中一个常见的定量分析参数,可以反映吸引子的结构[18,19,41,42],进而间接地说明系统的混沌程度,是刻画吸引子的重要参数,体现了非线性时间序列在高维空间中的结构的复杂度和自相似性。令r为重构相空间中相点的临界距离,则在重构相空间中两相点间距离小于临界距离的概率为
其中,Cm(r) 又称为关联积分,N-(m-1)τ为重构相空间中的相点数,Θ(·)为Heaviside函数,即
(2) Kolmogorov熵
Kolmogorov熵,又称Kolmogorov-Sinai熵(Kolmogorov Shannon,KS)是Shannon熵的拓展概念[18,41,42],能够描述系统动力学的随机性大小,表示相点概率分布的混乱度,也可体现系统的结构复杂程度及其混沌程度,其被定义为
其中,m为重构相空间的嵌入维数,r是临界距离,Cm(r)为式(40)中的关联积分。由式(43)可以看出,Kolmogorov熵越大,那么信息的损失速率越大,系统的混沌程度越大,即系统越复杂。
(3) 最大Lyapunov指数
Lyapunov指数(Lyapunov Exponent,LE)是混沌系统分析中常见的定量分析参数,并且与初始值无关,是吸引子本身固有的性质[18,19,41,42]。Lyapunov指数能够描述吸引子中某两条轨迹随时间演化后其距离分离速度的量。若LE为正数,则说明系统是混沌的,且LE值越大,系统的混沌程度越大;若LE小于零,则说明系统具有可预测性。令si,sj为一组点,则这二者经历了n次状态转移后,距离变化为
其中,D0为 初始距离,Dn为经历了n次状态转移后的距离,进而Lyapunov指数λ可以表示为
一般情况下,系统的Lyapunov指数不止一个值,其中最大的Lyapunov指数(Largest Lyapunov Exponent,LLE)具有代表性,所以在分析时间序列时,只计算最大Lyapunov指数即可。
(4) 排列熵
(5) 近似熵
近似熵(Approximate Entropy,AE)从统计学角度衡量时间序列的复杂度,描述了一个时间序列产生新模式概率的大小。对于一个系统而言,其产生新模式的概率越大,时间序列的复杂度越大,则其对应的近似熵也越大[43,46]。定义两相点si,sj间的距离d为两者对应元素最大差值的绝对值,即
其中,k=0,τ,...,(m-1)τ。对m维重构相空间中的每一个相点si,向量间距离d小于临界距离r的相点个数与相点总个数N-(m-1)τ的比值为
(6) 样本熵
样本熵(Sample Entropy,SE)作为一种非线性动力学参数,是近似熵的改进算法[43]。通过式(48),求得在距离内相点个数与总相点个数比值为(r)。求重构相空间中(r)的平均值,则有
增加重构相空间嵌入维数至m+1,重复上述步骤,可以得到ℵm+1(r),进而样本熵ES为
3.2.2 矩阵固有特性
矩阵固有特性是指通过矩阵分解等矩阵分析工具,捕获矩阵中蕴含的固有特性。在辐射源个体识别问题中,将重构相点视作行向量,则整个重构相空间可以视作包含多个行向量的矩阵。进一步,提取其固有特征,描述重构相空间特性,并用作辐射源个体识别任务。
(1) 奇异值
文献[46-48]从矩阵固有特性的角度出发,提出采用奇异值分解(Singular Value Decomposition,SVD)的方法提取重构相空间中所蕴含的低维特征作为个体身份的辨识依据。奇异值分解是一个有效的矩阵分解工具,具有旋转不变性、尺度不变性等数学性质,分解后获得的奇异值是矩阵的固有特征,因此可以用来作为矩阵特征的一种度量。
奇异值分解定理如下,设S是秩为r的(N-(m-1)·τ)×m阶实矩阵,则存在一个分解使得
(2) Low-rank表示
矩阵的Low-rank特性是指如果由样本数据集所构成数据矩阵的秩远远小于数据的维度,则这类数据矩阵称为Low-rank矩阵,即由矩阵表示的数据具有低秩特性。任一跳频电台的暂态信号其数据长度大于所需识别的电台个数,因此可以推断由跳频暂态信号构成的样本数据集具有Low-rank特性[49]。
其中,A被称为字典。实际上,该线性矩阵等式有无穷多解,任何一个解都可以被认为是矩阵关于字典A的一个表示。为了获得唯一的Z,同时提取给定数据集的隐含结构特征,Liu等人提出Lowrank聚类模型,数学表示为
其中,r ank(Z)为矩阵Z的秩。考虑到式(55)是非凸且不连续的,其凸松弛可以表示为
其中,‖Z‖∗为矩阵Z的原子范数。
3.2.3 几何构型
不同于统计特性和矩阵固有特性,几何构型是从几何学的角度出发,将重构相点、重构相空间分别视作高维空间中的顶点、空间几何,进而提取具有差异的高维空间几何特征,作为辐射源个体身份的辨识依据。
(1) 相点概率密度
a) 超球分层法
高维空间中的相点密度分布在一定程度上反映相空间中相点的分布规律,因此可以用来测量不同系统相空间的差异。最直接的方法是超球分层法[48]。对于m维重构相空间,所有相点可以看作分布于一个球心为 (0,0,...,0)1×m的m维超球中,所有相点到球心m的距离表示为
为了描述相点的分布,将超球等距分层。在每一层中,根据相点坐标向量中最小值对应的维数序号,将每一层分为m个区域。按照上述原则,统计每一层空间中各区域内相点个数,即可得到相点在整个超球中的密度分布。
b) 高斯混合模型
超球分层法在一定程度上反映了相点在相空间中分布,但其本质是一个无参数的概率密度估计,仅能获取某一区域的密度,不能获取相点分布形状等信息。对此,文献[48]进一步引入一种更有效的相空间概率密度分布估计方法--高斯混合模型方法(Gaussian Mixture Model,GMM)估计相空间中相点分布的详细信息。GMM方法的核心思想是利用M个高斯分布概率密度函数的组合来近似地描述相点在重构相空间中分布,其数学表达式为
其中,K为高斯分布个数,ωk为第k个高斯分布在整个分布组合中的权值,且满足
其中,s为特征矢量,µk为第k个高斯分布的均值向量,Σk为第k个高斯分布的协方差矩阵。
c) 交叉关联积分
文献[51]提出了基于重构相空间交叉关联积分(Cross-Correlation Integral,CCI)的辐射源个体识别技术。交叉关联积分可描述不同轨迹到参考点的统计距离,进而比较不同信号的相轨迹。其算法的基本思想是通过相空间重构获得重构向量,任取一组参考点sref,计算其余点stest(测试点)到它的距离,凡是距离小于给定临界距离r的向量对,称为关联向量对,通过对关联向量对的计数统计,获得不同轨迹到参考点的统计距离。交叉关联积分定义为
其中,Nref为参考点的个数,Ntest为测试点的个数,si,ref为第i个参考点,sj,test为 第j个参考点,Θ(·)为式(41)中的阶跃函数。该算法具有较高的鲁棒性,但当辐射源个体数目增加时,交叉关联积分的计算量呈平方次增加,系统实现难度显著增大。
(2) 质心
在m维空间中,重构相点共同构建了一个m维空间中的多面体,且该多面体共包含N-(m-1)τ个顶点。至此,辐射源个体识别问题转化为多面体的比较。为了兼顾特征维数低、具有辨识性、计算简便等优势,文献[50]采用质心作为个体识别的指纹特征,其表达式为
其中,si为重构相空间中的第i个相点,为重构相空间的质心。在计算重构相空间质心的基础上,根据式(58)对其分布进行建模。
(3) 几何特征
文献[20]则从重构相空间的几何特征入手,利用相空间重构方法将一维辐射源信号映射到高维空间中,构建几何形状,并提取5种几何特征进行描述,即吸引子到圆心的距离、吸引子之间的连续轨迹长度、吸引子之间的连续轨迹夹角、吸引子到标识线的距离、吸引子连续轨迹总长度。
a) 吸引子到圆心的距离
e) 吸引子连续轨迹总长度
文献[20]在提取上述5类特征的基础上,将对应特征的最小值、最大值、中值、均值、标准差、方差、偏度、峰度以及经小波变换得到的细节系数和近似系数进行结合,共同组成基于重构相空间的指纹特征向量。
3.2.4 转移特性
除相点分布外,重构相空间同样蕴含着系统状态转换特征。随着时间推移,动力学系统的行为不断变化,表现在状态空间中则体现为系统状态按时间顺序的转换过程。因此,不同的动力学系统可能会有不同的状态转换规律,可以作为动力学系统的指纹特征。
(1) 相点时间微分
美国海军实验室Carroll[17]利用相空间中相轨迹的微分统计量对不同的功放模型进行识别,结果表明在个体识别任务中重构相空间可用于表征功率放大器的非线性。但该技术只能用于正弦信号,识别效果受信噪比及相空间重构参数影响较大。该方法引入了索引点和最近邻的比较策略。
将两个要比较的相空间用其信号的重构矢量表示为Sref,Stest,其中Stest身 份属性未知,而Sref为已知身份的参考信号的重构矢量。为计算Sref到Stest的 距离,对Stest的每个时间微分矢量sj+1,testsj,test定 义索引点(sj+1,test,sj,test)。在参考相空间Sref中找到一个与其距离最近的点对 (si+1,ref,si,ref)。计算重构矢量微分的差δj=|(si+1,ref,si,ref)-(sj+1,test,sj,test)|,计算δj的统计平均得到两个相空间的平均差 〈δ〉。在算法实现的过程中,Carroll采用相点对齐的步骤以减小噪声等非理想因素的影响,进而得到两个相空间的平均差 〈∆〉。
(2) 距离变化矩阵
为了提取系统的状态转移特性,文献[47,48]首先提出了距离变化矩阵,以描述状态转移过程中的距离变化规律。设相空间中有两点si,sj,在高维空间中的两点的距离可以计算为
其中,D(si,sj)是si与sj间的距离,‖·‖2表示2范数。设j大于i,且j-i=k,则D(si,sj)表示经过k次状态变化产生的距离变化,本文将其称之为k阶距离变化。为了反映状态空间中不同阶状态变化产生的距离变化规律,将k设置为不同数值,得到相空间距离变化矩阵如下
其中,D是距离变化矩阵,反映了从1阶到k-1阶系统状态空间的距离变化规律。
(3) 角度变化矩阵
文献[47,48]在考虑距离变化的基础上,提出角度变化矩阵,以描述系统状态转移时的角度变化规律。通过引入两点间的夹角信息,可以更细致、更准确地反映二维空间中的状态变化,进而更好地反映状态空间的切换规律。设高维空间中的两点si,sj间的夹角为A(si,sj),则有
3.2.5 系统等效性
根据动力学系统理论,一旦确定性系统的当前状态确定,那么其未来状态也确定。在给定初始状态后,系统经过一段时间的演化,后续的向量会被吸引到相空间的一个子集,这个子集在动力学演化条件下保持不变,被称为系统的吸引子。随着时间的推移,系统中与吸引子邻近的轨迹都会逐渐地靠近它。因此,在足够长的时间后,相空间中的轨迹将形成固定的“形状”,而这一“形状”是由系统自身特性决定的。因此,吸引子蕴含了系统的非线性动力学特性,可以作为系统等效的表征。
(1) 点云深度学习
作者团队从重构相空间的系统等效性出发,提出了采用逐点对齐点云深度学习网络提取重构相空间相点分布和相点转移规律,完成系统的辨识[52],其算法流程如图3所示。

图3 基于逐点对齐点云深度学习网络的辐射源个体识别流程[52]Fig.3 SEI based on Alignment Point by Point-based PointNet (APBP-PointNet) [52]
作者团队分别对有意调制、无意调制以及加性噪声对重构相空间的影响进行了理论推导。推导后得到结论:有意调制和无意调制导致重构相空间的相点发生缩放变换,而加性信道噪声导致重构相空间中的相点发生平移变换。基于该结论,作者团队在网络结构中设计了堆叠的空间变换网络结构(见图4),以自动将重构相空间中的相点映射至规范空间内,从而削弱有意调制和加性噪声的影响,进而提升辐射源个体的识别效果。
(2) 重构系统吸引子
在证明重构相空间与系统吸引子等价的基础上(见本文第2节),作者团队提出采用流形学习算法从重构相空间中重构系统吸引子[53],并基于重构吸引子完成个体识别任务的算法框架,如图5所示。

图5 基于重构吸引子辐射源个体识别框架[53]Fig.5 SEI based on the reconstructed attractor[53]
在重构系统吸引子的基础上,为了实现辐射源个体识别的任务,提出了一种基于多层流形特征的辐射源个体识别方法[54]。为了全面且有效地表征辐射源个体间的差异,该算法采用了多层流形特征,即内蕴维数、拓扑特征、共形特征和黎曼度量特征,如图6所示。
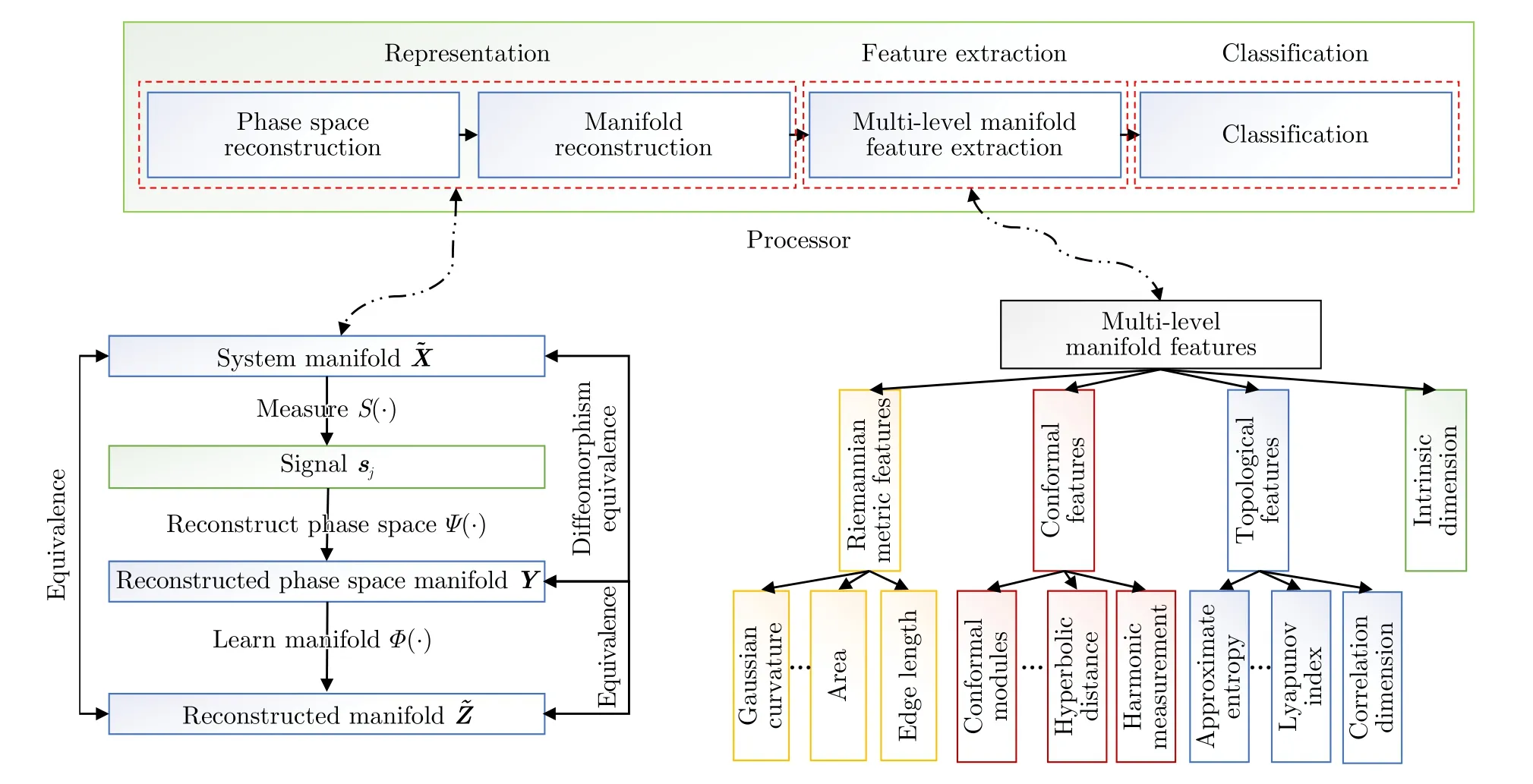
图6 基于多尺度流形特征的辐射源个体识别方法[54]Fig.6 SEI based on multi-level manifold features[54]
在文献[53,54]中,本团队采用大量的仿真数据和实测数据验证了重构吸引子与系统吸引子间的等价关系,并且证实了所提方法具有较高的识别准确率、突出的适应性和较强的鲁棒性。
3.3 算法应用效果
为了展现基于相空间重构的辐射源个体识别算法在实际任务中的广泛应用,本节将介绍SEIPSR方法在不同数据集上的应用效果,主要包括雷达、通信电台、通用软件无线电、无线网卡、对讲机、手机设备、舰船通信设备、任意波形发生器等,如表2所示。
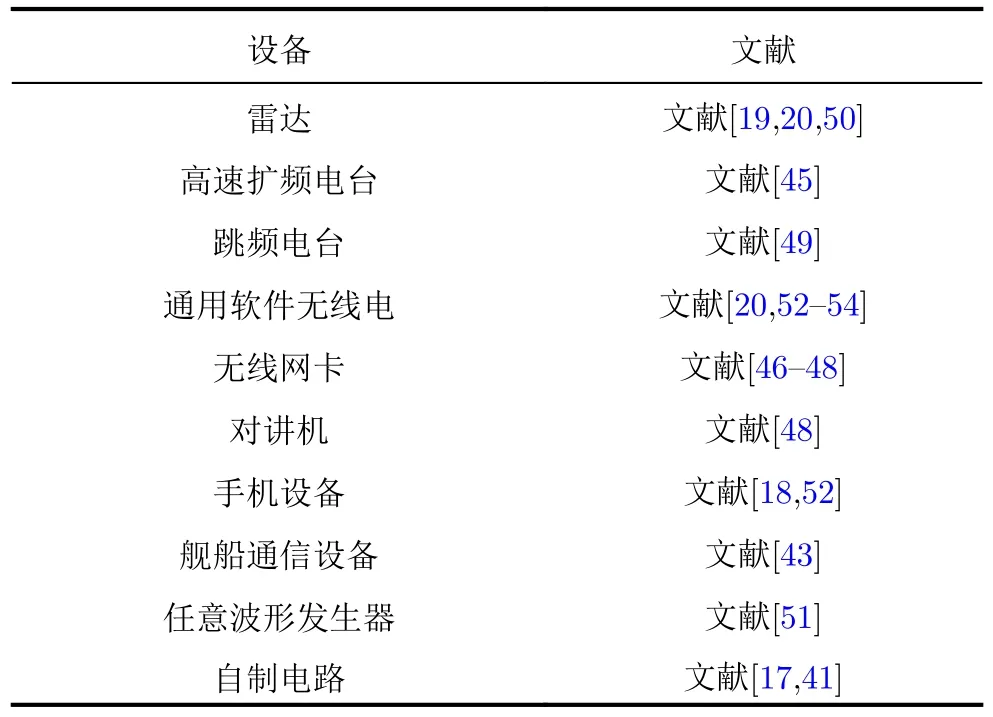
表2 基于重构相空间的辐射源个体识别技术在不同数据集上的应用总结Tab.2 Summary of the SEI-PSR applications on various datasets
3.3.1 雷达
电子科技大学张向前在文献[20]中,采用由美国海军实验室提供的雷达信号数据进行辐射源信号指纹的提取。该数据样本集共包含4部雷达辐射源,且每部雷达辐射源采集了50个脉冲信号样本,每个脉冲信号有150个采样点。此外,每部雷达辐射源信号的载波频率、脉冲宽度和调制方式均相同,其脉冲波形如图7所示。

图7 实验中4部雷达时域脉冲信号[20]Fig.7 Pulse waveforms of four radars[20]
实验中采用重构相空间的5类几何特征,即吸引子到圆心的距离、吸引子之间的连续轨迹长度、吸引子之间的连续轨迹夹角、吸引子到标识线的距离以及吸引子连续轨迹总长度。在提取4部雷达辐射源信号总样本下基于该特征的统计分布特征的基础上,利用CART决策树分类模型对经LDA特征优化后的指纹特征进行分类识别,得到4部雷达辐射源的识别率如表3所示。

表3 CART决策树模型在重构相空间特征下的信号“指纹”识别率(%)Tab.3 Accuracy with the CART decision tree (%)
3.3.2 通信电台
(1) 高速扩频电台
为探究基于相空间重构的辐射源个体识别方法对高速扩频电台指纹特征的描述能力,文献[45]采用了3台来自Anykey公司、型号为AKDS700[55]的高速扩频电台作为实验对象,如图8所示。

图8 实验中采用AKDS700装置图[55]Fig.8 The AKDS700 device[55]
实验中AKDS700不断发射直接序列扩频信号,其时域波形如图9所示。为了探究固定载荷和随机载荷对识别效果的影响,分别将信号的稳态部分和握手部分用于提取射频指纹。

图9 直接序列扩频信号的时域波形[45]Fig.9 Waveforms of Direct Sequence Spread-Spectrum(DSSS) signals[45]
实验中,利用多维度排列熵(Multi-dimension Permutation Entropy)分别对稳态信号和握手信号进行识别,识别结果分别如表4、表5所示。实验结果表明,多维度排列熵在识别AKDS700个体身份时是有效的,单个个体的识别率均保持在90%以上。同时注意到,相比于采用包含随机载荷的稳态数据,采用具有固定载荷的握手数据可以获得识别性能的提升,但其提升幅度不大。

表4 采用稳态信号进行识别的混淆矩阵(%)Tab.4 Classification confusion matrix of random payload data:Steady-state signal of radios (%)

表5 采用握手信号进行识别的混淆矩阵(%)Tab.5 Classification confusion matrix of fixed payload data:Hand-shaking signal of radios (%)
(2) 跳频电台
空军工程大学信息与导航学院眭萍等人[49]利用实验室现有的截获频率在30~90 MHz,间隔为25 kHz的4部跳频发射机,搭建了一个小型电磁仿真环境,并且采用4部跳频发射机的暂态信号作为分析对象。在信号分选的过程中,首先重构信号相空间,并采用Low-rank分析重构相空间的矩阵固有特性,进而对跳频发射机的信号进行聚类分选,结果如图10所示。
从图10实验结果可知,在一定信噪比条件下,算法可实现较好的跳频信号电台分选功能。以上实验结果也证明了Low-rank特性可用于实现跳频电台个体身份识别任务。
3.3.3 通用软件无线电
作者团队利用实验室现有的5台通用软件无线电设备(Universal Software Radio Peripheral,USRP)进行实验[52]。设置信号发射载频为770 MHz,接收机中频为760 MHz,采样率为40 MHz,且每个辐射源个体包含5000个样本,每个样本包含128个采样点。为探究信道噪声的影响,通过计算机仿真模拟的方式向所采集信号中添加加性高斯白噪声(Additive White Gaussian Noise,AWGN),且信号信噪比的波动范围为50 dB~0 dB,步长为10 dB。实验结果如表6所示。

表6 不同信噪比下算法识别准确率Tab.6 Classification accuracy with different SNRs
实验结果表明基于APBP-PointNet的辐射源个体识别方法能够在低信噪比的情况下,以较高的识别率完成USRP设备的个体识别任务,这是由于APBP-PointNet网络中的堆叠STN模块能够有效地削弱信道噪声影响,使得所提算法具有更强的噪声鲁棒性。
3.3.4 无线网卡
国防科技大学袁英俊[48]在其博士论文中采用4部DareGlobal DW505无线网卡作为分析对象。实验中选取接收数据中的数据区的部分作为分析对象,并选择重构相空间的奇异值、相点概率密度分布以及转移特性作为辐射源个体识别的依据,实验结果如图11所示。
从图11(a)可以看出,相空间总体特征非常有效,可实现无线网卡信号的个体识别。相比之下,图11(b)中的相点密度分布特征效果稍差,但其仍然具有一定的分类能力。从图11(c)、图11(d)可以看出,状态转换特征非常有效,特别是图11(d)中的角度变化特征可以将无线网卡设备完全分离。
3.3.5 对讲机
除无线网卡外,国防科技大学袁英俊[48]在其博士论文中对来自4部摩托罗拉T5228对讲机的模拟信号也进行了测试实验。信号的工作频段为409~410 MHz,调制样式为FM。实验结果如图12所示。

图12 对讲机信号指纹特征[48]Fig.12 Fingerprint features of interphones[48]
从图12(a)可以看出,相空间总体特征非常有效,可将4部对讲机信号完全分离。从图12(b)可以看出,相点密度分布特征效果稍差,但仍然具有一定的分类能力。从图12(c)、图12(d)可以看出,状态转换特征非常有效,可以将对讲机完全分离。从上述结论可知,所提重构相空间的奇异值、相点概率密度分布以及转移特性等指纹特征是有效的。
3.3.6 手机设备
作者团队[52]将包含33部手机的蓝牙信号公开数据集[56]作为实验对象,数据集中共包含来自小米等5家制造厂家的16种型号手机,具体的型号与厂家如图13所示。蓝牙信号带宽约为82 MHz,持续时间约为10 µs,载频为2.5 GHz,信噪比由10 dB波动至6 dB。
图13 手机型号与厂商[52]Fig.13 Manufactures and models of mobile phones[52]
实验同时选取其他基于深度学习的辐射源个体识别方法[57-60]进行比较,实验结果如图14所示。
实验结果表明,文献[52]所提方法的识别准确率明显高于典型的基于深度学习的辐射源个体识别算法[58-60]。这是由于堆叠的空间变换网络结构能够有效地削弱有意调制与信道噪声的影响,提升个体识别算法的鲁棒性,满足手机蓝牙数据集复杂调制、低信噪比的特性。
3.3.7 舰船通信设备
解放军信息工程大学的任东方等人[43]选取6类实测舰船通信信号作为分析对象,提取其细微特征并进行识别实验。信号的采样频率为1 MHz,中心频率约为294.075 kHz。实验中首先采用固有时间尺度分解(Intrinsic Time-Scale Decomposition,ITD)将信号分解成若干个有实际物理意义的固有旋转分量,而后提取有价值分量的近似熵、样本熵、排列熵作为指纹特征,实验结果如表7所示。
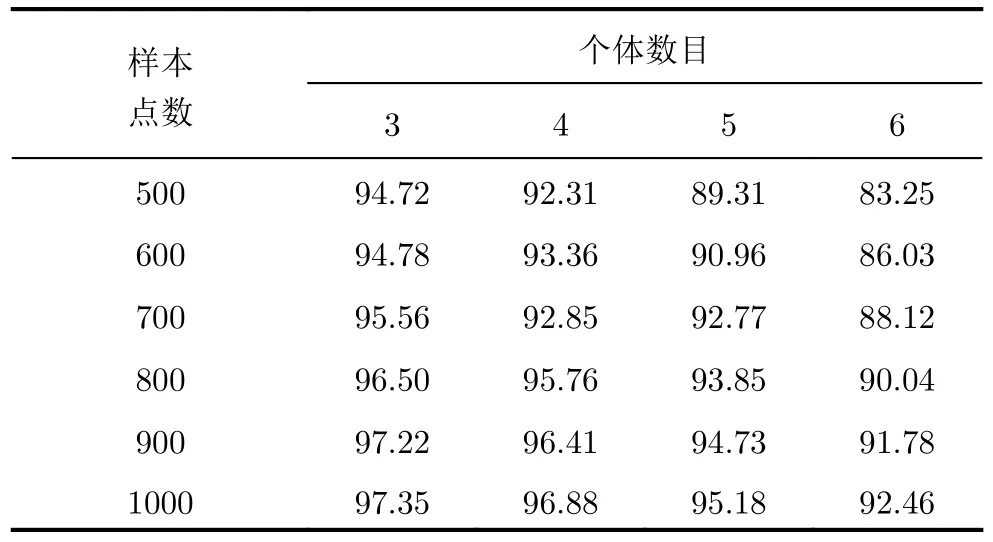
表7 不同信号长度、不同待识别个体数目下,所提方法的正确识别率(%)Tab.7 The identification accuracy of proposed method with different signal length and individuals (%)
从表7可以发现,信号样本长度N、个体数目K会对信号的识别率有一定的影响。总体来讲,信号样本的长度N越长、个体数目K越小,信号间的分类效果越好。
3.3.8 任意波形发生器
许丹[51]曾采用来自Tek公司、型号为AWG520的任意波形发生器(Any Wave Generator,AWG)。AWG520中有一个晶振信号源和两路输出通道,每个通道对信号源的信号进行独立的放大。实验时,两通道采用相同的设置,产生25 kHz的单频连续波信号,信号峰值为1 V。采集信号功率谱如图15所示。

图15 实测信号样本功率谱图[51]Fig.15 Power spectrum of collected signals[51]
实验中对信号进行数字滤波、下采样等操作,以消除高频噪声的影响,并通过仿真方式加入噪声,实验结果如图16所示。

图16 实测信号识别率随信噪比变化曲线[51]Fig.16 Recognition results of different SNR[51]
从图16可以看出,所提算法能够有效地完成辐射源个体识别任务,且算法的鲁棒性较相点时间微分方法[17]有明显提升。
3.3.9 自制电路
考虑到封装的辐射源产品指纹特性难以明确,Carroll研究员[17]在实验中搭建了包含3台OP-07运算放大器的试验电路,并采用正弦信号作为激励,进行辐射源个体识别实验。实验示意图如图17所示。

图17 采用不同功率放大器的自制电路示意图[17]Fig.17 Schematic of the experiment with various amplifiers[17]
实验中采用相空间差分法,统计不同放大器发射信号的时间微分,统计结果如图18所示。

图18 不同功率放大器对应的相空间微分分布[17]Fig.18 Distributions of the phase space difference according to various amplifiers[17]
图18表明不同功率放大器发射对应的相空间微分分布具有明显的差异,因此可以作为辐射源个体身份的辨识依据。
3.4 算法初步对比
本节将从硬件非理想性刻画能力以及噪声鲁棒性两个角度对现有的SEI-PSR方法进行初步对比。
3.4.1 数据集大器非线性带来的谐波阶数Kam=3,功率放大器的非线性参数bk的变化范围为[1.00,0.00,0.00]至[1.00,1.00,0.50],且为均匀变化。数据集2:只考虑高频振荡器的相位噪声。令高频振荡器的杂散分量阶数Kos=3,杂散分量频率fk的变化范围为
仿真实验数据集采用单音信号,且信号的载频为50 kHz,采样率为200 kHz。每个数据集包含10台辐射源,且每个辐射源的样本数目为100,每个样本含有1024个数据点。在辐射源的非理想性仿真方面,采用功率放大器的非线性模型以及高频振荡器的相位噪声模型(详见本文第2节)。根据辐射源的非理想特性来源不同,数据集可分为3组。数据集1:只考虑功率放大器的非线性。令功率放[-0.10,0.00,0.10]至[-0.01,0.00,0.01],杂散分量幅度ak保持不变为0 .25。数据集3:同时考虑高频振荡器的相位噪声和功率放大器的非线性。器件的非理想性参数与数据集1和数据集2中保持相同,并且考虑二者间的耦合作用。
3.4.2 相空间重构
实验中分别通过互信息法和Cao氏法估计得到延迟时间τ=1和 嵌入维数m=5,而后重构辐射源相空间,如图19所示。

图19 不同硬件非理想性下信号重构相空间的可视化Fig.19 Reconstructed phase space of different hardware imperfections
3.4.3 识别结果与分析
实验中对5类SEI-PSR方法均进行了测试,即统计特性、矩阵固有特性、几何构型、转移特性、系统等效性。为了比较特征对非理想性的刻画能力,除APBP-PointNet算法采用深度学习网络中的Softmax结构作为分类器外,其余算法均采用支持向量机(Support Vector Machines,SVM)作为分类器。
(1) 实验1
首先探究特征对辐射源硬件非理想性的刻画能力。考虑无噪声的情况,分别在数据集1-数据集3上进行实验。实验结果如图20所示。

图20 不同数据集下算法的识别准确率Fig.20 Classification accuracy for different datasets
实验结果表明,在无噪声的条件下,SEI-PSR方法能够刻画高频振荡器的相位噪声与功率放大器的非线性,进而完成辐射源个体身份的辨识。对比数据集1与数据集2的实验结果,可知Kolmogorov熵、近似熵、样本熵对功率放大器的非线性不敏感,无法单独作为辐射源个体身份的辨识依据。
(2) 实验2
进一步探究噪声对算法识别性能的影响。在信号生成过程中引入AWGN,且信噪比波动范围为0~30 dB,步长为2 dB。
图21表明基于单一统计特性的算法,在噪声的影响下识别率普遍偏低,而基于几何构型、转移特性的方法的识别率普遍偏高。这是由于几何构型、转移特性描述较为复杂,需要多个特征值共同拼接,作为指纹特征,进而提升算法的识别率与鲁棒性。此外,采用深度学习方法的APBP-PointNet算法随信噪比的降低,识别率有明显下降,这是由于实验中样本数目较少,网络无法进行充分训练导致的。

图21 不同信噪比下算法识别准确率Fig.21 Classification accuracy with different SNRs
4 未来前景分析
4.1 前景分析
鉴于相空间重构的优势,其在辐射源个体识别领域中的应用前景主要包含以下3个方面。
(1) 相比于时频图、循环谱、高阶谱等变换域,重构相空间能够精确描述辐射源系统的非线性动力学特性,更有助于辐射源指纹特征的提取。前文证明了重构相空间与系统吸引子之间微分同胚的等价关系,即重构相空间与辐射源系统模型等价。这一等价关系为基于相空间重构的辐射源个体识别理论框架提供了理论支撑,可以解决辐射源个体识别中系统建模的挑战。但其仍面临着硬件参数差异微小、数据驱动依赖程度高两个难点。
(2) 从非线性动力学角度而言,有意调制、无意调制与信道噪声的作用效果是相对独立的。这一特性为在重构相空间中分离有意调制、无意调制与信道噪声提供可能。通过进一步探究有意调制与信道噪声对重构相空间的作用效果,设计相应的补偿模块,可以削弱有意调制与信道噪声的影响,放大细微的指纹特征,进而解决辐射源个体识别领域中所面临的硬件参数差异微小的挑战。
(3) 系统重构相空间描述了整个系统的非线性动力学特性,普遍适用于现有的辐射源系统,这为从未知辐射源信号中提取指纹特征提供可能。未知辐射源的重构相空间同样描述了其非线性动力学特性,可以作为其个体身份的判别依据。因此,基于相空间重构的辐射源个体识别技术可突破依赖数据驱动的局限,提取无标签信号中的指纹特征,满足辨识未知辐射源的任务需求。
4.2 现有问题与下一步工作
虽然基于重构相空间的辐射源个体识别技术在一定程度上得到了发展,但其距离构建真正的基于重构相空间的辐射源个体识别系统仍然面临着诸多困难:
(1) 现有的主流相空间重构方法--延迟坐标法,高度依赖延迟时间和嵌入维数的估计。能否精准地构建与原辐射源系统吸引子等价的重构相空间对后续的辐射源个体身份识别起到了决定性的作用。相空间重构可归纳为映射函数的构建问题,而这恰恰是深度学习所擅长的领域。未来可借助深度学习技术的自组织、自学习和自适应的优势,通过自动设计网络模块、自动调节网络结构、自动学习网络参数等手段,寻找从一维的时间序列到系统等效相空间的最优映射,以突破现有相空间重构方法的局限。
(2) 面对复杂的电磁环境,现有算法仍具有一定的应用局限性。现有个体识别算法大多根据某一特定应用场景,难以满足工作模式变化、传输信道变化、硬件特性变化等复杂场景的应用需求。以短波通信电台为例,该设备受多径信道影响显著,难以提取强鲁棒性指纹特征。未来工作可借鉴现有深度学习领域的迁移学习等思想,通过数据增强构建不同电磁环境的辐射源信号,并利用特征空间对齐等手段,设计具有强泛化能力的指纹特征。
(3) 现有算法的关注点在于提取信号中蕴含的指纹特征,而非构建辐射源系统的模型。如果能够根据重构相空间自动构建辐射源系统模型,就可以弥补现有基于硬件模型指纹特征提取方法的不足,从而进一步分析辐射源系统的行为特性,甚至推演辐射源指纹特征的演变规律。
5 结语
基于相空间重构的辐射源个体识别技术经过15年的发展,研究越来越深入,相关的技术应用也逐步成熟,为系统性梳理其发展脉络,本文从理论基础入手,探究将相空间重构技术应用于辐射源个体识别问题的物理基础,进而从方法框架、算法分类、算法应用效果以及算法初步对比4个方面总结介绍其研究现状,最后对其未来研究方向进行展望。
在当今高度发达的科技社会中,频谱精确监管所依赖的辐射源个体识别技术更是到达了空前的重要程度。未来,辐射源个体身份的辨识需要更可靠、更高效、更自动化的技术支持,而这离不开创新的算法。如何利用相空间重构技术,挖掘辐射源系统的非线性动力学特性,反映辐射源硬件的差异,极具现实应用与科学探究意义。
