花叶病胁迫下甘蔗叶片叶绿素含量的高光谱预测模型
2023-09-11王敬湧谢洒洒盖倞尧王梓廷
王敬湧, 谢洒洒, 盖倞尧*, 王梓廷*
1. 广西大学机械工程学院, 广西 南宁 530004
2. 广西大学农学院, 广西 南宁 530004
3. 广西大学广西甘蔗生物学重点实验室, 广西 南宁 530004
引 言
甘蔗是禾本科甘蔗属作物, 属于多年生草本植物, 是世界上主要的糖料作物。 据统计, 全球甘蔗的种植面积约26 522 734公顷, 占世界农业总面积的0.72%。 目前, 甘蔗作为原料生产的糖量约占全球糖供应量的85%[1]。 如今, 世界食糖的消费需求不断增加, 人们对甘蔗生产力的要求也随之增大。 但甘蔗在生长发育中会存在许多问题限制其生产力的发展, 其中花叶病就是一个因素。
甘蔗花叶病症状主要在叶片表现, 病毒会遍及全株, 使整株甘蔗染病。 甘蔗感染花叶病后, 叶片的叶绿素被破坏, 叶片出现黄色或浅绿色的条纹[2]。 因此叶绿素含量可以作为评估甘蔗是否受到病害胁迫的一项指标。 但是传统的叶绿素检测方法操作复杂、 昂贵费时, 且是有损检测, 所以不适合在田间大规模进行。 随着遥感技术的发展, 人们开始对不同作物探索建立高光谱数据与植物生理参数之间的关系。 通常采集到的高光谱数据不仅数据量大, 还包含大量冗余信息和干扰信息。 因此为了减少干扰信息, 一般会对高光谱数据进行预处理。 常用的预处理方法有: 小波去噪[3]、 MSC[4]、 SNV[4]、 一阶导数等。 而为了减少数据量和冗余信息, 会对高光谱数据进行特征波段的选择。 常用的特征波段选择的方法有: 随机蛙跳算法[5]、 SPA[6]、 植被系数法[7-8]、 小波变换[9]、 相关系数[10]。 最终将预处理过后的高光谱数据或选择的特征波段作为机器学习的输入, 对不同作物的叶绿素含量进行预测。 目前较为常用的机器学习方法有: PLSR[11]、 BPNN[12]、 KNN[13]、 SVR[14]等。
综上所述, 目前国内外学者利用光谱对不同作物的叶绿素反演进行了大量的研究, 涉及到的光谱处理技术通常包括光谱信息预处理、 数据降维、 以及机器学习回归模型等。 但利用高光谱对花叶病胁迫下甘蔗叶片叶绿素含量反演的研究较少。 为此, 以盆栽甘蔗为研究对象, 研究如下问题: (1)比较分析感染花叶病叶片和健康叶片的叶绿素含量和光谱响应特性差异; (2)探究不同预处理对叶绿素含量预测的影响; (3)建立多个叶绿素含量反演模型, 并通过比较反演性能, 选取最优模型, 实现用对花叶病胁迫下甘蔗叶片的叶绿素含量无损测量。 本工作系统地分析比较了不同预处理方法、 数据降维方法以及机器学习模型在甘蔗叶片高光谱数据处理中的性能, 可为遥感监测甘蔗病害胁迫程度提供理论依据以及技术支持。
1 实验部分
1.1 试验地点及时间
于2021年7月—11月在广西大学农学院教学科研基地开展试验, 选用中2号蔗甘蔗品种。 样本总量为70株, 其中35株为控制组即感染花叶病植株, 另35株为对照组即健康植株。 控制组甘蔗病害样本均通过人工接种发病后获得, 花叶病病种来源广西大学农学院。 所有甘蔗在接种染花叶病之前于温室里培育。 在对控制组植株进行接种过后, 为避免感染健康植株, 将对照组甘蔗放置于温室外独立的大棚内进行种植。
1.2 光谱数据采集
叶片光谱数据使用CID便携式CI-710光纤光谱仪(CID Bio-Science Inc., 美国)进行采集(图1), 具体的技术参数见表1。 选择天气晴朗时进行数据采集, 采集时间为10:00—12:00。 每次测量前均使用白板进行校正, 使用叶夹方式在不同叶位即刻进行测量。 每个叶位重复测量10次, 取平均值作为该叶位的光谱反射值。 由于测量的光谱数据在400~520和920~950 nm的噪音较大, 因此截取520~920 nm的光谱数据做后续的分析。

表1 CI-710光纤光谱仪技术参数

图1 便携式CI-710光纤光谱仪
1.3 叶绿素含量测定
叶片光谱测量后, 将不同位置的叶片洗净组织表面污物, 剪碎(去掉中脉), 放入25 mL容量瓶中。 加入20 mL的80%丙酮浸提液, 放置于黑暗条件下, 浸泡至叶片发白。 用浸提试剂定容至25 mL, 摇匀静置后用浸提试剂为空白测定吸光度。 选择波段663和645 nm比色测出数值OD663、OD645, 利用式(1)计算出叶绿素含量
叶绿素含量(mg·cm-2)=(8.02×OD663+20.21×OD645)×V/(S×1 000)
(1)
式(1)中,V为浸提液体积;S为剪切叶片的面积。
1.4 数据处理
采用预处理-特征提取-机器学习反演的框架处理采集到的光谱数据。 首先, 在采集光谱数据时, 由于人为操作、 环境、 仪器等影响, 会造成光谱数据包含大量的干扰信息, 因此需要对光谱数据进行预处理, 突出光谱数据中有用信息。 其次, 每条光谱曲线通常包含几百甚至上千个数据点, 其中包含大量冗余信息, 且使用全部的数据预测叶绿素含量会造成模型过拟合, 从而降低精度, 因此本研究对光谱数据进行特征波段提取。 最后, 采用机器学习模型完成叶绿素含量的反演。 采用Microsoft Excel 2019整理数据, Origin2019进行统计分析和作图, 使用Python对数据进行建模与验证。
1.4.1 高光谱数据预处理
为了降低干扰信息的影响, 需要对光谱数据进行预处理。 使用Savitzky-Golay卷积, 变量标准化(standard normal variate, SNV), 多元散射校正(multiplicative scatter correction, MSC), 一阶导数(first derivative, 1stD), 二阶导数(second derivative, 2ndD)五种光谱变换预处理方法。
1.4.2 特征波段提取方法
特征波段的提取可以降低数据维度, 减少冗余数据的影响。 使用相关系数法、 连续投影算法、 随机森林算法, 构建最优特征波段的提取方法。
各分析方法原理如下: 相关系数法[15]: 计算光谱中每一个波段的反射率与特定物质含量的相关系数, 相关系数绝对值越大, 则表明该波段反射率包含的有效信息越多, 则该波段可能被选为特征波段。 连续投影算法(successive projection algorithm, SPA)[16]: 一种前向特征变量选择方法。 SPA利用向量的投影分析, 然后将波段投影到其他波段上, 比较投影向量大小, 以投影向量最大的波段为待选波段, 然后基于校正模型选择最终的特征波段。 随机森林算法(random forests, RF): 一种测量每个特征值对预测结果的相对重要性的方法。 高维度的特征互相之间可能具有相似性, 继而对模型能力贡献少, 并且影响计算效率。 基尼[17](Gini)系数通常可以作为衡量输入特征对随机森林算法贡献度大小的评价标准, 对样本中所有特征变量来说, 基于系数的变量重要性评分能直观量化各个特征对模型的贡献大小, 值越高特征重要性越高。
1.4.3 机器学习方法与模型验证
在BP神经网络(back propagation neural networks, BPNN)、 支持向量回归(support vector regression, SVR)、 K最邻近法(K-nearest neighbors, KNN)[12-14]三种机器学习方法中筛选出最优模型。 BPNN是一种具有输入层、 隐含层和输出层的典型多层前向型神经网络, 可以实现输入和输出间的任意非线性映射, 具有较好的非线性映射逼近能力和预测能力。 SVR是支持向量机非线性回归问题上的推广, 能在保证数据逼近精度的同时降低逼近函数的复杂度, 特别对有限样本、 非线性问题等方面具有诸多优势。 KNN是一种直观的数据挖掘分类计数方法。 除了用于分类, 该方法也适用于回归预测问题。 当进行回归预测时, 使用K个临近的均值作为预测结果。

(4)
(5)
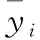
2 结果与讨论
2.1 花叶病对甘蔗叶片的影响
通过图2可以发现, 花叶病叶片的叶绿素含量明显低于健康叶片的叶绿素含量。 花叶病叶片的叶绿素含量为5.69~7.43 mg·cm-2, 均值为6.27 mg·cm-2, 标准差为0.45。 健康叶片的叶绿素含量为11.72~14.01 mg·cm-2, 均值为12.86 mg·cm-2, 标准差为0.71。 通过Welch’s 检验得到表2结果。 由于t Stat大于t双尾临界, 因此拒绝假设, 健康叶片和花叶病叶片叶绿素含量均值有显著的差异。 究其原因, 是花叶病破坏了叶片的叶绿素, 因此花叶病叶片的叶绿素含量险著低于健康叶片的叶绿素含量。
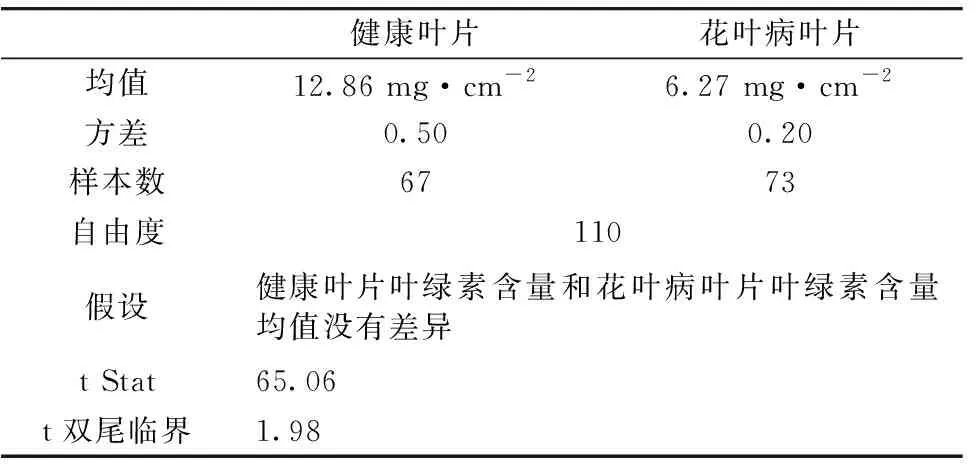
表2 Welch’s检验结果
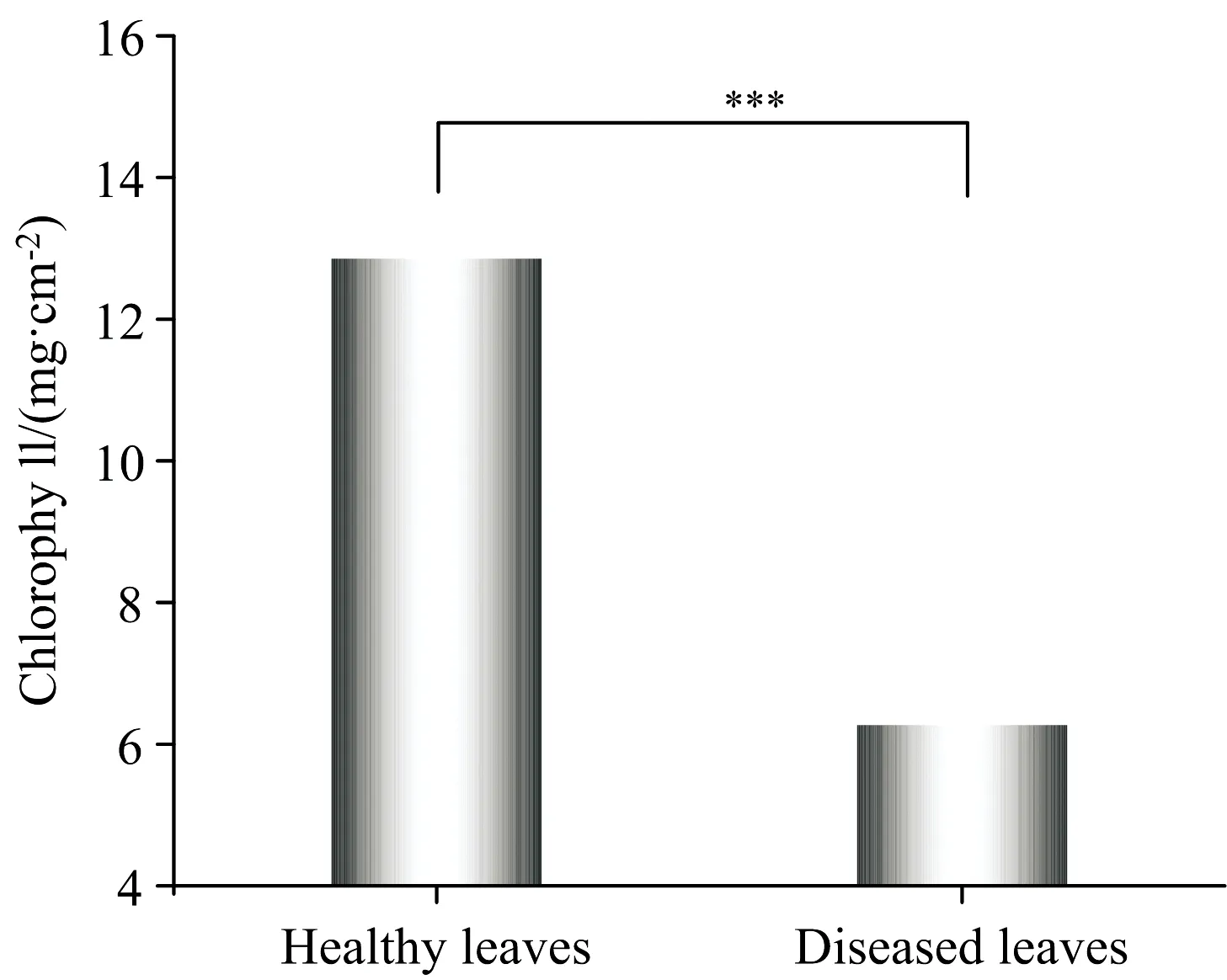
图2 感染花叶病叶片和健康叶片的叶绿素含量的平均值及标准差, ***p<0.05
感染花叶病的叶片和健康叶片的光谱曲线具有相同的趋势, 在520~600 nm间有一个反射峰, 600~700 nm间有一个吸收谷(图3)。 但在520~650和700~850 nm这两个区间, 花叶病叶片的反射率是要高于健康叶片的反射率。 通过图3发现甘蔗叶片在感染花叶病后, 其红边位置出现了“蓝移”。 由于甘蔗叶片感染花叶病, 大量叶绿素被破坏, 因此在光谱特征上与健康叶片会有较大的差异。

图3 感染花叶病叶片与健康叶片在520~920 nm的平均光谱曲线
通过上述分析, 花叶病影响甘蔗叶片的叶绿素生成, 从而导致光谱曲线变化。 因此利用光谱反射率, 预测甘蔗叶片的叶绿素含量的方案是可行的。
2.2 最优预处理的选择
对原始光谱使用不同的预处理方法, 结果如图4所示, 经SG处理后的光谱变得更加平滑, 经SNV、 MSC、 SG+SNV、 SG+MSC处理后, 原光谱曲线在700~850 nm的差异被消除, 曲线变得更集中。 经SG+1stD处理后, 将原始光谱在700~850 nm间的差异放大。 经1stD、 2ndD处理后, 噪音被放大。 经SG+2ndD处理后, 光谱差异不明显。

图4 光谱不同预处理的结果

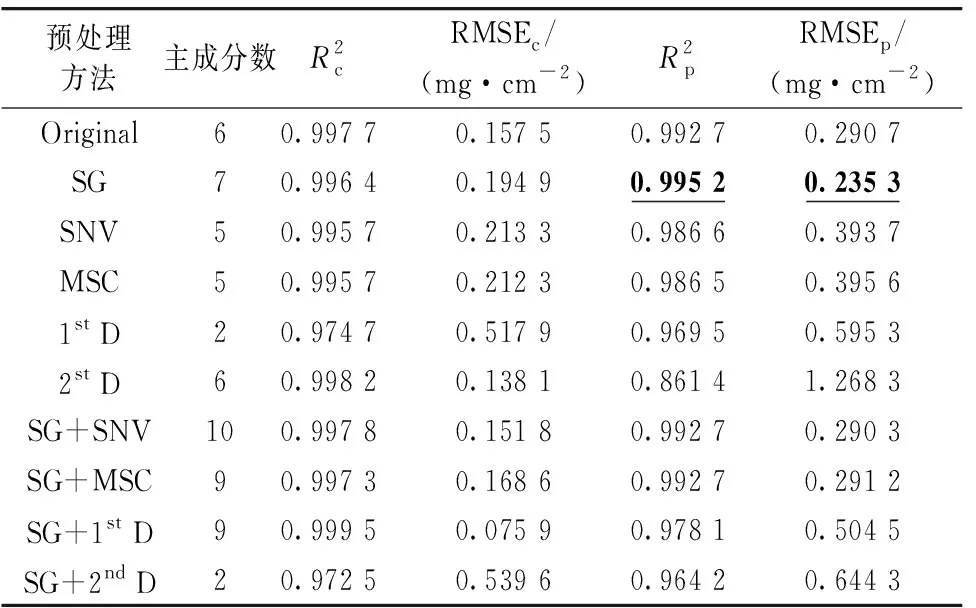
表3 不同预处理与原始光谱的PLSR模型对比分析
2.3 特征波段提取结果
通过计算各个波段的反射率与叶绿素含量的相关系数, 可知520~649和691~829 nm两区间内波段的反射率与叶绿素含量的相关系数绝对值大于0.8(图5), 说明在这两个区间内波段的反射率与叶绿素含量具有强相关性。 而花叶病叶片和健康叶片的光谱曲线在这两个区间具有较大的差异(图3)。 由于相关系数绝对值大于0.8的波段有269个, 为了减少计算量, 选择了相关系数绝对值前15的波段(图6), 选取的波段详见表4。

表4 不同方法选取的特征波段

图5 各个波段反射率与叶绿素含量的相关系数
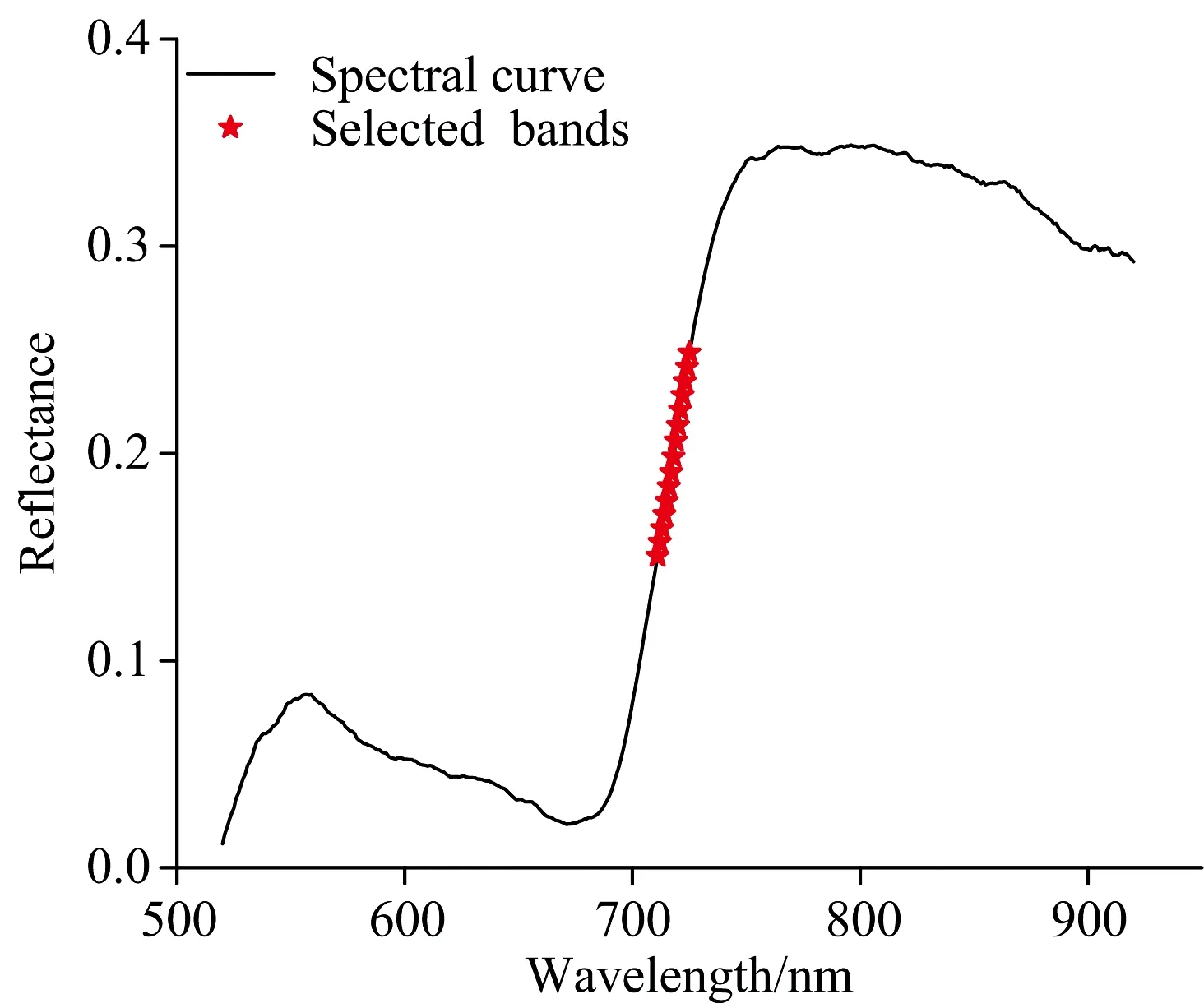
图6 相关系数法筛选出的波段
通过连续投影算法筛选出特征波段(图7), 最终筛选出15个特征波段, 占总波段的3.7%, 选取的具体波段见表4。 其中筛选出的波段在可见光范围内占33.3%, 在近红外范围内占66.7%。 但在520~650和700~850 nm这两个区间的波段, 花叶病叶片和健康叶片的光谱曲线具有较大的差异(图3), SPA却在这两个区间筛选出较少特征波段。 这与相关系数法选择的波段差异较大。

图7 连续投影算法筛选出的波段
通过随机森林算法得到每个波段对叶绿素预测的重要性(图8)。 其中重要性较高的波段主要集中在520~650和700~830 nm之间, 总共有262个波段。 为了减少计算量, 选择特征重要性前15的波段(图9), 选取的波段见表4。
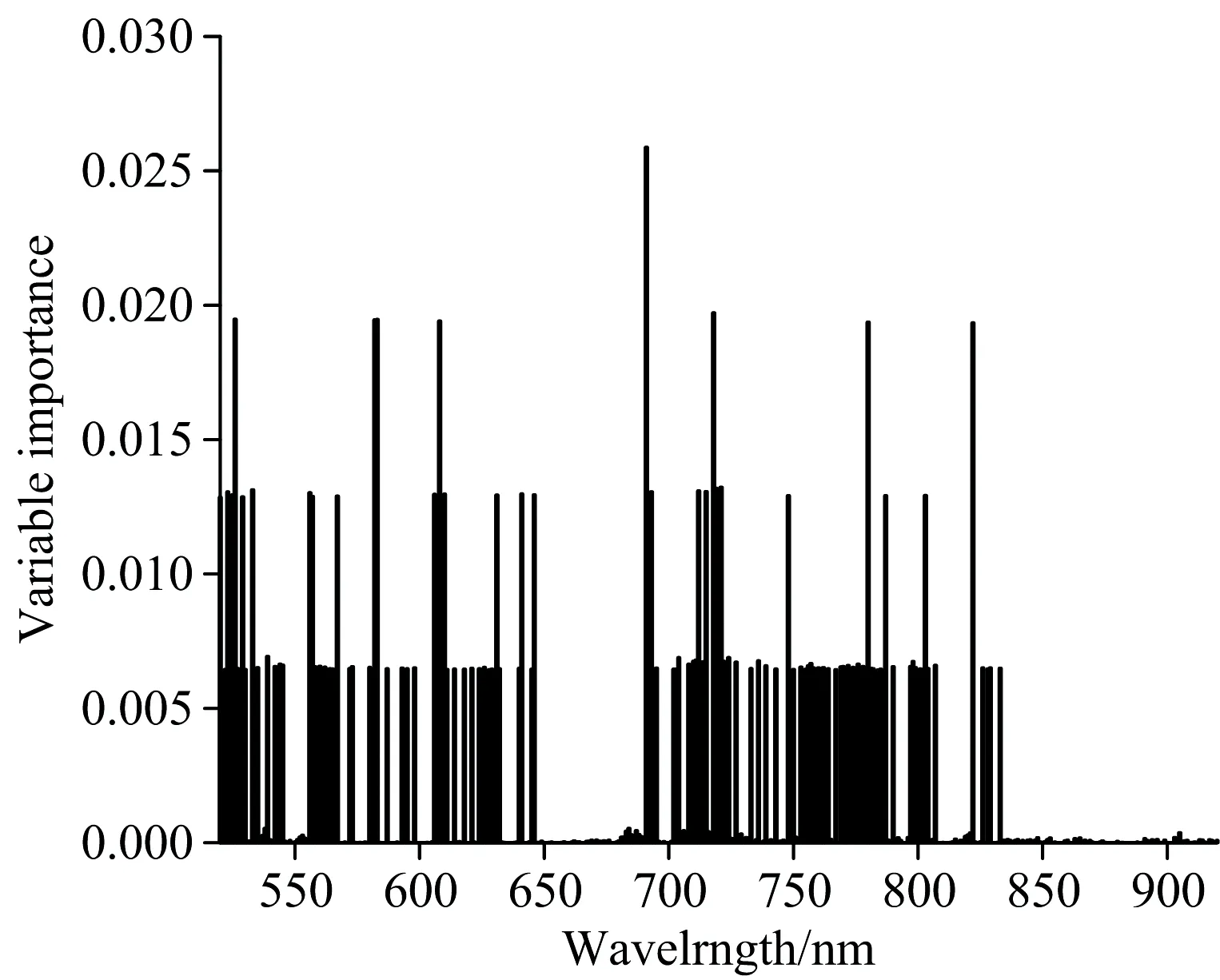
图8 各波段重要性分布图

图9 随机森林算法筛选出的波段
2.4 基于不同机器学习方法和不同特征波段选择方法的预测结果
将全波段和提取出的特征波段作为不同机器学习方法的输入变量(表5)。 其中M1为全波段(401个波段), M2、 M3、 M4分别为相关系数法、 连续投影算法、 随机森林算法筛选出的15个特征波段。 由于相关系数法和随机森林、 连续投影法选择的特征波段差异较大。 因此, 增加两组输入变量, 分别为M5和M6, 其中M5为M2与M3相结合的波段, M6为M2与M4相结合的波段。

表5 叶绿素含量预测模型输入变量分组


表6 甘蔗叶片叶绿素含量预测模型结果
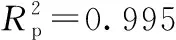


图10 基于M4和BPNN结合的模型预测叶绿素含量值与实测值比较
3 结 论
提出了一种使用高光谱数据预测花叶病胁迫下甘蔗叶片叶绿素的方法, 该方法对叶片的高光谱数据进行不同的预处理和降维, 最终使用机器学习对叶绿素含量进行预测。 通过分析实验结果可得到如下结果:
(1) 感染了花叶病的叶片相较于健康叶片, 叶片的叶绿素含量会显著降低。 且感染花叶病的叶片与健康叶片的光谱也有较大的差异。 染病叶片在520~650和700~850 nm之间的光反射率要高于健康叶片。 因此利用光谱数据, 反演叶片叶绿素含量是可行的。
(2) 通过SG、 MSC、 SNV、 1stD、 2ndD这些方法对原始光谱进行预处理, 通过偏最小二乘回归反演叶绿素含量, 发现SG预处理过后的光谱相较于原始光谱可以提高叶绿素反演的精度。

本研究为光谱遥感监测花叶病胁迫下甘蔗叶片生长状况建立了理论与技术基础。 此模型于田间的适应性将在后续工作中进一步验证。
