改进SO优化KELM的液体火箭发动机故障检测*
2023-09-04王闻浩
王闻浩,许 亮
1.天津理工大学电气工程与自动化学院,天津 300384 2.天津市复杂系统控制理论与应用重点实验室,天津 300384
0 引言
液体火箭发动机作为液体火箭的核心,其运行工况的正常与否直接决定了火箭是否可以成功发射。液体火箭发动机属于多学科、多领域的复杂耦合系统,当其运行于高温高压的极端环境下,极易出现难以预料的故障[1]。因此,对液体火箭发动机进行故障检测显得尤为重要。
分类算法是液体火箭发动机故障检测的主要手段和方法。早期的故障检测方法以神经网络为主。王克昌[2]将BP神经网络应用于火箭发动机故障诊断,指出在大量训练样本的支撑下,诊断结果的正确性可以得到保证。但其局限性在于,对于训练样本中不存在的故障情况,诊断结果的可信度大大降低。同时,当存在参数相近,而故障模式不同的样本时,训练过程较慢,且难以获得理想的结果。王平等[3]采用神经网络对滚动轴承故障包络信号进行自动识别。从包络信号的时域和频域提取故障特征信息,作为神经网络的输入。结果表明,该神经网络可以有效识别滚动轴承的各类运行故障。随着分类算法的快速发展,火箭发动机故障检测方法也更加多元。韩泉东等[4]将支持向量机应用于火箭发动机故障检测。采用支持向量机对所有的故障类型设计一个分类器。根据所有分类器的输出结果,对样本故障类型进行判断,仿真结果表明该方法可以有效识别故障。俞刚等[5]将支持向量机和卡尔曼滤波器结合。首先采用最小二乘支持向量机,对部件故障进行分类。最后由卡尔曼滤波器估计故障部件参数,从而进行故障检测。
以上算法均可实现火箭发动机的故障检测,但也存在一定的问题。BP神经网络采用反向传播学习算法,其网络结构、初始权值和阈值对网络训练的影响很大。支持向量机分类的重要环节是惩罚因子和核函数参数的选取。对于这些问题,人们只能依靠已有的经验,或将随机参数带入模型,通过观察输出结果选取最优值。为了解决这些问题,多数学者开始使用群体算法来优化分类模型。杨晋朝[6]采用遗传算法优化BP神经网络的权值和阈值,结果表明该模型可以有效避免网络陷入局部最优。Xu等[7]采用量子遗传算法优化BP神经网络。许亮等[8]采用粒子群算法对小波神经网络的权值和基函数参数进行了寻优,仿真结果表明所提出的模型训练时间最少,且精度最高。陈占国等[9]建立了松鼠搜索算法优化支持向量机的故障检测模型,实验表明该模型具有较高的准确率。马硕[10]采用改进后的哈里斯鹰算法优化概率神经网络(Probabilistic Neural Networks,PNN),并与PNN和BP算法的分类结果进行了对比。结果表明所提出的故障检测模型要优于另外两种算法。
核极限学习机(Kernel Extreme Learning Machine,KELM)自提出以来,已被应用于多个领域。马超等[11]将KELM用于液压泵在线预测,为液压泵的预测控制和故障预测提供了参考。陈绍炜等[12]建立了基于KELM的模拟电路故障诊断模型,并且与支持向量机和极限学习机进行对比,结果显示准确率优于另外两个模型。刘鹭航等[13]采用半监督极限学习机进行故障检测,解决了由于控制力矩陀螺故障数据不足导致的结果不准确的问题。冯磊华等[14]用KELM优化电站锅炉,有效减少了有害气体的排放。
本文依据KELM在分类和拟合方面具有强大适应性的优点,将其应用于液体火箭发动机故障检测。依据蛇优化算法(Snake Optimizer,SO)较强的寻优能力和存在的一些不足,对SO进行了改进,并将改进后的算法用于优化核函数参数和惩罚因子。最后基于历史样本数据,对建立的故障检测模型进行了实验仿真。
1 核极限学习机
单隐层前馈神经网络在进行训练时,多采用梯度下降法。传统的学习算法存在训练速度慢、易陷入局部最优、学习速率难以选择等缺点。鉴于此,Huang教授提出了极限学习机(Extreme Learning Machine,ELM)算法[15]。该算法仅需设置隐含层的个数即可,输入层与隐含层之间的权值和隐含层的阈值由随机数生成。该方法具有训练速度快、泛化性能好等优点。算法结构如图1所示。

图1 极限学习机结构
通过图1可以看出,网络的输出受隐含层的输出和隐含层与输出层之间连接权值β影响。隐含层的输出由输入层与隐含层之间的连接权值a、隐含层的阈值b以及隐含层的激活函数G(·)决定。而输入层与隐含层之间的权值a和隐含层的阈值b由随机数生成。在确定激活函数后,可以求得隐含层的输出。因此,我们的目标是求得隐含层与输出层之间的权值β。
以单个训练样本为例。假设网络有n个输入层,m个输出层,l个隐含层。输入层与隐含层之间的权值矩阵为al×n,隐含层阈值矩阵为bl×1,隐含层与输出层之间的权值矩阵为βl×m。隐含层激活函数为G(·)。则网络的输出可以表示为:
(1)
式(1)可简化为:
Hβ=YT
(2)
式中:H1×l为隐含层输出矩阵,HT为输出矩阵Y的转置。为使得预测输出和实际输出误差尽可能小。对以下方程组进行求解:
(3)
得:
(4)
其中:H-1为输出矩阵H的逆矩阵。
在2012年,Huang等将支持向量机中核函数的思想引入ELM,提出了核极限学习机[16]。在保证网络结构泛化能力的前提下,提高了系统的鲁棒性和运算速度,且算法的实现也较为简单。
首先引入惩罚因子C,将隐含层与输出层之间的权值矩阵β重新定义为:
(5)
将核函数矩阵ΩKELM代替HHT,可得:
(6)
那么,KELM的输出函数为:


(7)
本文核函数采用径向基(RBF)核函数,其数学表达形式为:
(8)
其中:σ为核函数参数。
在实际应用中,核极限学习机(KELM)的核函数参数σ和惩罚因子C对算法的输出结果影响较大,但其具体数值的确定又较为困难。学者们一般通过选取不同的数值进行多次尝试,选择输出结果较好的一组数值作为参数。但该方法需要消耗大量的时间,且存在随机性。鉴于此,本文采用一种新的群体智能算法对KELM模型参数进行寻优,以确定模型的最优参数。
2 ISO-KELM故障检测模型
1.1 蛇优化算法
蛇优化算法(SO)是由Hashim和Hussien两位学者根据蛇的交配行为所提出的一种新的元启发式算法[17]。该算法根据蛇在低温和食物充足的条件下进行交配这一特性,将算法流程分为探索和开发两个阶段。首先将所有个体划分为雄性种群和雌性种群,在整个算法流程中,两个种群的位置更新公式完全相同。因此下文仅对雄性种群更新公式进行介绍。
食物数量Q和温度T的更新公式为:
(9)
(10)
式中:N为最大迭代次数,n为当前迭代次数,c1为常数,设置为0.5。可以看出,食物数量随着迭代次数的增加而增加,温度随着迭代次数的增加而降低。
当Q<0.25时,算法处于探索阶段,种群个体通过移动自身位置来寻找食物,更新公式为:
Xi(t+1)=Xrand(t)±c2×A×
((Xmax-Xmin)×r+Xmin)
(11)
(12)
式中:Xi为更新后的雄性个体位置,fi为该个体的适应度。Xrand为随机雄性个体,frand为随机雄性个体的适应度。Xmax和Xmin分别为求解问题的上边界和下边界。r为0~1之间的随机数。c2为常数,设置为0.05。
当Q>0.25时,算法进入开发阶段。在该阶段,当T>0.6时,雄性个体在食物周围进行开发,其更新公式为:
Xi(t+1)=Xfood±c3×T×r×(Xfood-Xi(t))
(13)
式中:Xi为雄性个体位置,Xfood为所有种群中最优个体的位置。c3为常数,设置为2。
当T≤0.6时,雄性个体将进入战斗模式或交配模式,由随机数决定。战斗模式更新公式为:
Xi(t+1)=Xi(t)+c3×Fm×r×
(Q×Xbest,f-Xi(t))
(14)
(15)
式中:Xi为雄性个体位置,fi为其适应度。Xbest,f为雌性群体中的最优个体位置,fbest,f为其适应度。
交配模式更新公式为:
Xi,m(t+1)=Xi,m(t)+c3×Mm×r×
(Q×Xi,f(t)-Xi,m(t))
(16)
(17)
式中:Xi,m为雄性个体位置,fi,m为其适应度。Xi,f为雌性个体位置,fi,f为其适应度。
交配之后有50%的概率会产生后代,用以代替雄性种群中的最差个体。
2.2 蛇优化算法改进
蛇优化算法(SO)的初始种群由软件的随机数函数生成,可能会使得初始个体离最优点较远,导致算法寻优能力不足;SO探索和开发阶段的转换由食物数量(Q)来决定。由于Q的大小仅受迭代次数影响,使得SO进入开发阶段较晚,导致算法后期寻优能力不足;同时,SO后期种群多样性减少,难以跳出局部最优点。
针对以上问题,分别提出以下3点算法改进策略。
2.2.1 Tent映射
针对初始化种群离散度不高,导致算法寻优能力下降的问题。采用Tent混沌映射对种群进行初始化操作。Tent映射表达式为:
(18)
本文将α的数值设置为0.499。因为当α等于0.5时,在经过50次左右的迭代后,种群会收敛至0,失去遍历性。
2.2.2 动态策略
针对算法较晚进入开发阶段,导致寻优能力较弱的特点,采用动态策略转换探索和开发阶段。为了使SO提前结束探索阶段,增加开发阶段的迭代次数,采用以下动态策略控制阶段转换:在探索阶段,当种群最优适应度连续6代不发生变化的时候,SO进入开发阶段。动态策略公式为:
D(t+1)=c4×D(t)+|fbest(t)-fbest(t-1)|
(19)
式中:D为动态参数。fbest为种群最优适应度。c4为常数,设置为0.1。当D的值小于1×10-6时,SO进入开发阶段。
此外,将常数c4引入探索阶段雌性种群的位置更新公式,加快种群的收敛。由于SO的特殊性,在雌性种群快速收敛的同时,雄性种群依旧可以在全局进行遍历。
2.2.3 柯西变异
针对SO后期易陷入局部最优的特点,采取柯西变异策略对陷入局部最优的种群进行处理。
柯西变异策略来源于柯西分布。柯西分布的概率密度函数为:
(20)
当a=1时,称为标准柯西分布。在SO中,柯西分布随机变量生成函数为:
μ=tan(π×(r-0.5))
(21)
r为0~1之间的随机数。个体位置扰动公式为:
Xworst(t+1)=Xworst(t)×(1+μ)
(22)
式中:Xworst为最优适应度较差的种群。
进入开发阶段后,当全局最优值连续6代没有发生变化的时候,对两个种群中最好适应度较差的群体进行柯西变异。
改进后的算法流程如图2所示。

图2 改进蛇优化算法流程图
2.3 算法优化流程
针对KELM参数难以确定的问题,采用上文改进后的蛇优化算法对参数进行寻优。
整个算法流程如图3所示。

图3 ISO-KELM模型流程图
具体寻优过程为:
1)导入数据,包括数据样本和标签;
2)将样本划分为训练集和测试集;
3)对训练集数据进行归一化处理,再使用训练集归一化时的映射对测试集进行归一化;
4)初始化ISO算法参数,包括种群数量,种群维度,种群上下限和测试函数;
5)建立ISO-KELM模型,对KELM参数进行寻优。具体过程如图2所示;
6)将所求得的最优惩罚因子C和核函数参数σ赋予KELM;
7)使用优化后的KELM进行故障检测;
8)对寻优结果进行评价对比。
3 实验仿真
3.1 故障模式
本次实验数据选取某型号液体火箭发动机历史试车数据,共420组。正常数据和故障数据分别为210组。故障数据包括涡轮叶片损坏、燃烧室喉部烧蚀、氧化剂泵汽蚀、氧化剂泵管路堵塞和氧增压系统减压阀故障5种典型故障模式。同时,为了使所提出算法具有较高的准确性和适用性,选取14个代表性强且相关性弱的发动机参数作为输入。
3.2 数据处理
本次实验采用仿真软件进行仿真。选取前42组数据作为测试集,剩余数据作为训练集。训练集中的前42组数据作为验证集,并将验证集的准确率作为ISO的适应度。
ISO参数设置如下:种群数量设置为30,种群维度为2,第一维代表惩罚因子C,第二维代表核函数参数σ。种群上限和下限分别设置为100和0.001。
3.3 结果对比
我们将核极限学习机(KELM)、蛇优化算法优化核极限学习机(SO-KELM)、改进后的蛇优化算法优化核极限学习机(ISO-KELM)3种模型的故障检测结果和传统BP神经网络模型故障检测结果进行对比。部分模型输出结果如图4所示。
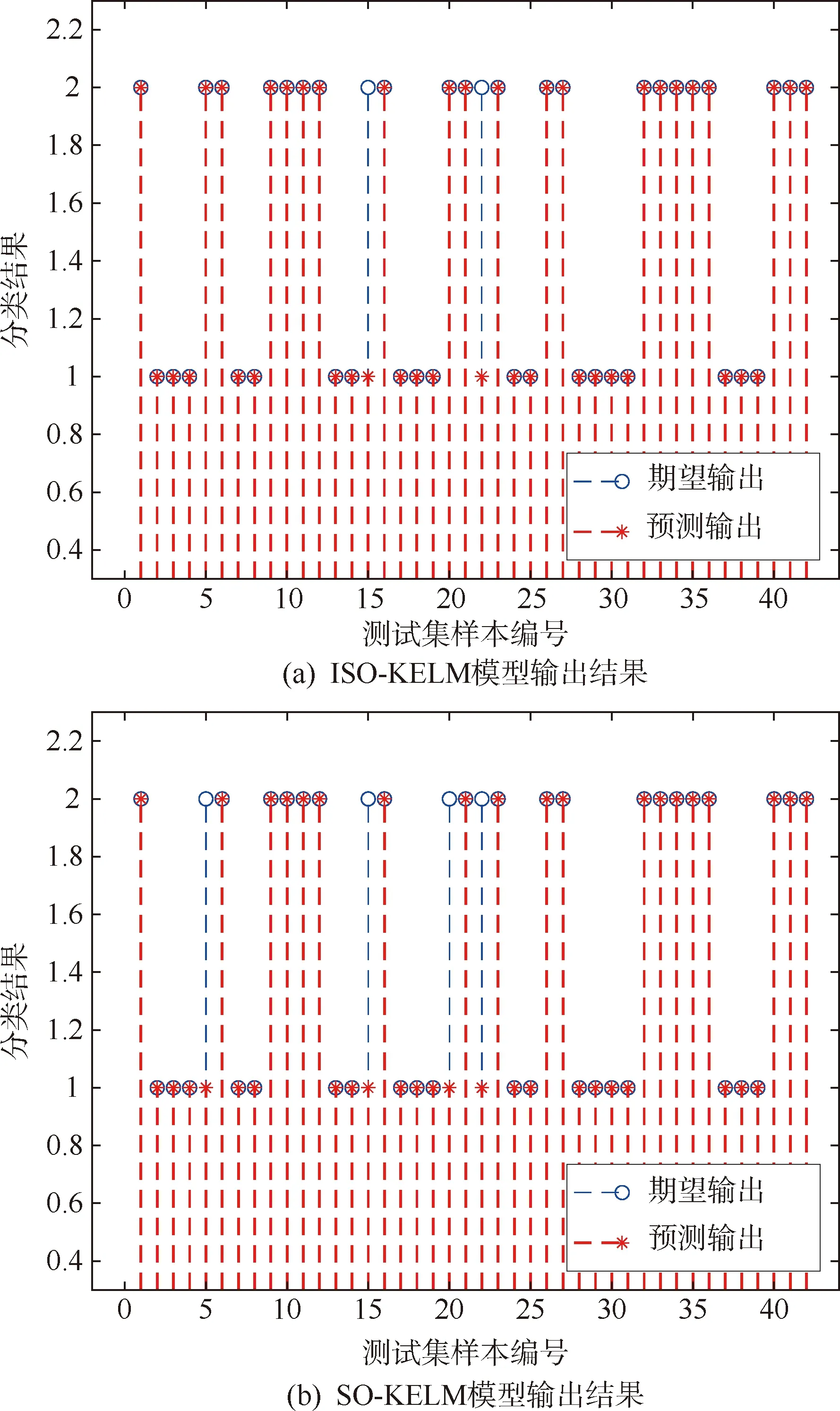
图4 部分模型输出结果
为便于直观了解各个故障检测模型的性能,采用误报率、漏报率和准确率对4种模型进行评估。具体结果如表1所示。
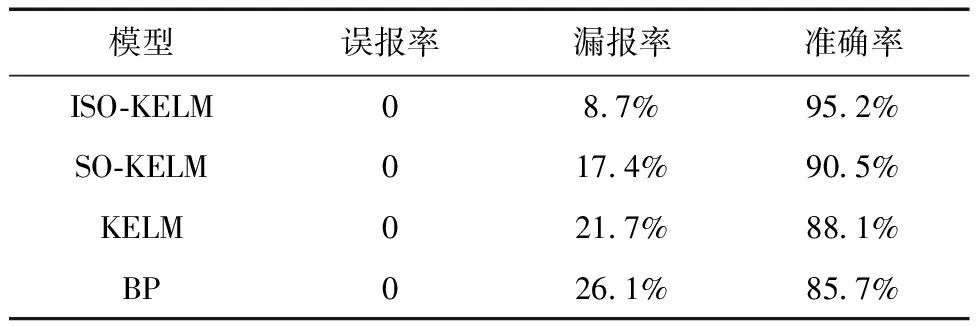
表1 模型检测结果对比
通过表1可以看出,4种模型的误报率均为0。漏报率的高低直接影响了模型的准确率。其中,KELM模型的漏报率相比于传统BP神经网络较低。同时,分别采用SO和ISO优化KELM后的模型均能提高检测结果的准确率,且ISO-KELM模型的漏报率更低,检测结果也更加准确。
为了验证改进蛇优化算法具有更好的性能,采用适应度曲线作为算法的评估条件。
图5分别为ISO和SO的适应度变化曲线。可以看出,在算法开始运行时,ISO的适应度低于SO的适应度,原因是ISO的初始种群遍历性较强,在前期有更强的寻优能力。由于ISO在探索阶段寻优能力有限,因此在前几次迭代过程中适应度没有发生变化。此时算法提前结束探索阶段,进入开发阶段。且在第18代寻得最优值。而SO整体收敛速度较慢,在第25代完成收敛,且寻得的最优值大于ISO。

图5 算法适应度曲线
4 结论
使用改进蛇优化算法优化核极限学习机(ISO-KELM),并将其应用于液体火箭发动机故障检测。可以得出以下结论:
(1)改进后的蛇优化算法可以提高种群前期的寻优能力,使种群提前进入开发阶段,加快后期收敛,且收敛能力更强;
(2)ISO可以和KELM模型相结合,通过ISO获得KELM模型的最优参数,从而实现对液体火箭发动机故障的有效检测;
(3)仿真实验表明,所提出ISO-KELM故障检测模型的准确率优于传统BP神经网络故障检测算法,实验结果更加理想。
