基于特征优选的软件缺陷预测集成学习方法
2023-09-04卫梅特任洪敏
卫梅特,任洪敏
(上海海事大学信息工程学院,上海 201306)
1 引言
近些年软件缺陷预测成为了计算机领域研究者的热门课题[1]。目前提出的软件缺陷预测常用的机器学习方法有支持向量机(Support Vector Machine)、随机森林(Random forest)、决策树(Decision Tree)、DP-Transformer、代价敏感分类(Cost-Sensitive Classification)[2-5]等。对于软件项目,存在历史数据库丢失或者是损坏等一些原因,软件缺陷预测所需要的数据无法从软件项目自身的历史库中获取,因此有研究者考虑到跨项目缺陷预测。Abdul Ali Bangash等人[6]提出了跨项目缺陷预测模型,该方法主要是对过去的模型进行训练,而对将来的模型进行评估。娄丰鹏等人[7]针对迁移学习,提出了增加度量元的迁移学习跨项目软件缺陷预测,从源项目中提取知识并将其转移到目标项目的转移学习来提高预测性能。于巧等人[8]为了探究分类不平衡对软件缺陷预测模型性能的影响程度,设计了一种新数据集构造算法,将原不平衡数据集转化为一组不平衡率依次递减的新数据集,然后分别对构造的新数据集进行预测。对于公开数据集NASA,文献[9]提出了基于集成学习的软件缺陷预测方法与研究,针对数据集做特征选择选取每个数据集前15个最优特征。在所用数据集中特征向量维度分布在22-41,虽然利用前15个最优特征,但对向量维度为41的特征有部分重要属性被抛弃。
为充分利用数据集中的有效信息保证有效信息不被抛弃,本文提出基于特征优选的软件缺陷预测集成学习方法。主要是,对NASA中8个数据子集的45943条特征向量进行研究,通过SMOTE对少数类样本进行分析并根据少数类样本合成新样本添加到数据集中。然后,通过信息增益(Information gain,IG)分析数据集的特征属性,根据分析结果对特征属性进行选择。最后,使用集成学习算法Stacking构建学习器。结果表明,本模型有效提升了分类性能,与近年基于Stacking构建学习器的实验结果进行对比,Accuracy平均提升4.65%、F-Measure平均提升5.25%和AUC平均提升11.3%。本文第2节介绍特征优选的软件缺陷预测集成学习方法。第3节介绍集成学习方法具体实现细节。最后总结全文,并对下一步工作进行展望。
2 特征优选的软件缺陷预测集成学习方法
特征选择一直是软件缺陷预测研究的核心问题之一。通过特征能否直接区分,软件缺陷模块与非缺陷模块,直接决定模型的可行性。面对众多特征,如果不加筛选,而直接使用全部特征则会造成两方面问题:1)部分特征与软件缺陷预测无关,会严重影响软件缺陷的预测性能。2)部分特征存在冗余,会增加软件缺陷模型构建的时间。正因如此,如何选择合适的特征子集成为构建高质量数据集和软件缺陷预测模型的重要基础。
本文对经典数据集美国国家航空航天局(NASA)MDP[10]中的8个项目的特征进行分析,着重关注软件模块的冗余特征和无效特征,在对比了实验结果之后总结得出最优特征。
2.1 信息熵
通过对数据集中的特征进行分析,首先确定了以软件的代码度量作为支撑基础,为NASA中的每个项目的度量标准建立提供了切实的理论依据。同时,代码度量标准通常从软件自身特点出发,受限于项目本身的具体情况、开发语言和组织等因。因此,从NASA数据集特点考虑,由于数据集种类繁多,其规模较大,可能存在的软件缺陷也越来越多。为保证软件质量,本文考虑将软件质量的度量纳入数据集度量标准的组成中。
有关软件质量和软件质量评价的标准已经存在多年,国内开展软件度量和评价的专业研究也取得了较多成果,于2006年发布了国际GB/T 16260.1《软件工程产品质量》[11]。但是并没有得到广泛应用和推广,目前实际工程项目中开展软件全面质量的成功范例较少。因此对软件进行代码度量、特征选择以及软件缺陷预测具有重要的作用。文献[12],指出信息增益是最有效的特征选择方法之一。因此在本文中特征选择使用的是信息增益,信息增益体现了特征的重要性。熵是IG中一个非常重要的概念,表示任何一种能量在空间中分布的均匀度,能量分布越均匀,越不确定,熵就越大。香农[13]将熵应用于信息处理,对信息进行量化度量,因此为了衡量一个随机变量取值的不确定程度,就此提出“信息熵”的概念。信息熵的计算公式

(1)
在式(1)中P(Ci)代表的是数据中i类出现的概率,共有k类。信息熵体现了信息的不确定性程度,熵越大表示特征越不稳定,对于此次的分类,越大表示类别之间的数据差别越大。
条件熵的公式
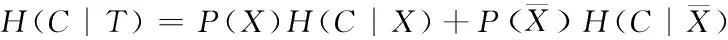
(2)
其中
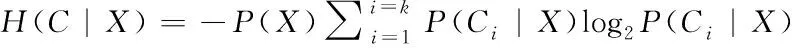
(3)

(4)

信息增益计算公式
IG(X)=H(C)-H(C|T)
(5)
由式(5)可知,信息增益=信息熵条件熵,显然某个特征项的信息增益值(Information gain value,IGV)越大,表示其贡献越大,对模型分类也就越重要。因此在特征选择时,选取信息增益值大的特征向量有益于分类结果。
2.2 不平衡处理方法
在软件缺陷预测的研究领域,数据集的不平衡问题非常常见。对于正常的软件项目来说,有缺陷的模块远比无缺陷的模块要少,若直接使用原数据进行实验,会造成结果预测不准确。面对这一问题,必须进行数据类不平衡处理,在数据类不平衡处理中,有两种常用的方法分别是,过采样(Oversampling)[14]和欠采样(Undersampling)[15]。过采样是复制少数类,也就是复制有缺陷模块的实例。欠采样是减少多数类,也就是减少无缺陷模块的实例。欠采样可能会导致关键的数据丢失,模型无法很好的进行学习。

2.3 集成学习方法
在构建学习器时,本文选用集成学习(Ensemble Learning,EL)[17]方法,EL目前广泛用于分类和回归任务。其基本思想是:使用不同的方法改变原始训练样本的分布,从而构建多个不同的分类器,也就是组合多个弱监督模型以期望得到一个更好更全面的强监督模型。潜在思想是,即便某一个弱分类器得到了错误的预测,其它的弱分类器也可以将错误纠正回来,也就是将这些分类器线性组合得到一个更强大的分类器,来做最后的决策,本文选用集成学习方法中的Stacking方法。
Stacking是一种集成学习的算法,也是一种重要的结合策略。Stacking第一次训练的模型叫做初级学习器,第二次训练的模型叫做次级学习器。Stacking把训练得到的初级学习器作为次级学习器的输入,进一步训练学习得到最后的预测结果。stacking的算法伪代码如下:
输入:训练集
D={(x1,y1),(x2,y2),…,(xm,ym)}
初级学习算法:ξ1,ξ2,…,ξT
次级学习算法:ξ
过程:
1)for t=1,2,…,T do
2)ht=ξt(D)
3)end for
4)D′=∅
5)for i=1,2,…,m do
6)for t=1,2,…T do
7)Zit=ht(Xi);
8)end for
9)D′=D′∪((Zi1,Zi2,…,ZiT),yi);
10)end for
11)h′=ξ(D′)
输出:H(x)=h′(h1(x),h2(x),…,hT(x))
由伪代码可知:
1-3:训练出来个体学习器,也就是初级学习器;5-9:使用训练出来的初级学习器来得预测的结果,这个预测的结果当做次级学习器的训练集;11:用初级学习器预测的结果训练出次级学习器,得到最后训练的模型。在算法集成上,本文使用了下面三种算法:
算法1:逻辑回归(Logistic Regression,LG)[18]是一个广泛使用的二分类算法,形式简单,模型的可解释性非常好、训练速度较快,分类的时候,计算量仅仅只和特征的数目相关、资源占用小,尤其是内存,因为只需要存储各个维度的特征值、方便输出结果调整,逻辑回归可以很方便的得到最后的分类结果。因此本文选用LG算法作为Stacking的初级学习器。
算法2:J48决策树(J48 decision tree)算法[19],对决策树采取了贪婪和自上而下的方法。该算法用于分类,根据训练数据集标记新数据。决策树归纳始于数据集(训练集),该数据集在每个节点处进行分区,从而导致分区较小,因此遵循递归的分而治之策略。因此本文选用J48算法作为Stacking的初级学习器。
算法3:朴素贝叶斯(Naive Bayesian,NB)[20]是使用最为广泛的分类算法之一,在贝叶斯算法的基础上进行了相应的简化。NB的思想基础可以这样理解:对于给出的待分类项,求解此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。因此本文选用NB算法作为Stacking的次级学习器。
2.4 评价指标
每一个样本在进行预测之后,可能会产生四种不同的预测结果。可能的结果用混淆矩阵定义如表1所示。

表1 混淆矩阵
四种可能的结果为:TP(True positive)、FN(False negative)、FP(False positive)和TN(True negative)。利用这四种结果可以得到:Accuracy、Precision、Recall、AUC、F-measure等评测指标,在本实验中使用的评测指标有Accuracy、F-Measure和AUC(Area Under The Curve)。
Accuracy:表示模型的准确率,准确率是预测正确的结果占总样本的百分比,公式如式(6)所示

(6)
F-Measure:在查准率和召回率的基础上定义 F-Measure 值,表示查准率和召回率的加权调和平均,结合查准率和召回率的结果,得出对软件缺陷预测模型综合性能更好的评价,公式如式(7)所示

(7)
AUC:为了权衡召回率和假阳率,在实验中采用ROC(receiver operating characteristic)曲线,ROC曲线是召回率和假阳率之间折中的一种图形化方法。AUC值为 ROC 曲线下方的面积,面积越大,表示预测模型越好。
3 特征优选的软件缺陷预测集成学习方法构建
3.1 学习模型
经过对集成学习和软件缺陷预测相关模型的学习和总结,本实验将结合过采样、特征选择、Stacking集成学习构建软件缺陷预测模型,通过十折交叉验证验证模型的准确性。实验过程主要分成两个阶段,分别是数据预处理、Stacking集成学习。
第一阶段:数据预处理。在原始的NASA MDP数据集中,有缺陷的数据占总数据的比例从0.41%~19.32%,导致了数据的极度不平衡问题,这样也会导致准确度下降,为了解决这个问题,在本文中使用SMOTE进行数据的不平衡处理。其次通过观察特征值,发现存在无关特征和冗余特征,故使用信息增益来选择优质特征。
第二阶段:Stacking集成学习。在该算法中使用J48和LR作为实验的初级学习器,然后使用NB作为实验的次级学习器,组合得到一个更强大的分类器,来做最后的决策。
本文构建的软件缺陷预测模型如图1所示。

图1 模型流程图
3.2 数据预处理
3.2.1 不平衡处理结果
原始数据集的特征见表2,本模型采用MDP中的8个数据子集分别是:CM1、JM1、KC3、MC1、MW1、PC2、PC4、PC5,经过SMOTE进行类不平衡处理后达到平衡,在本模型中h值设置为5,在表中缺陷率%字段四舍五入保留两位小数。
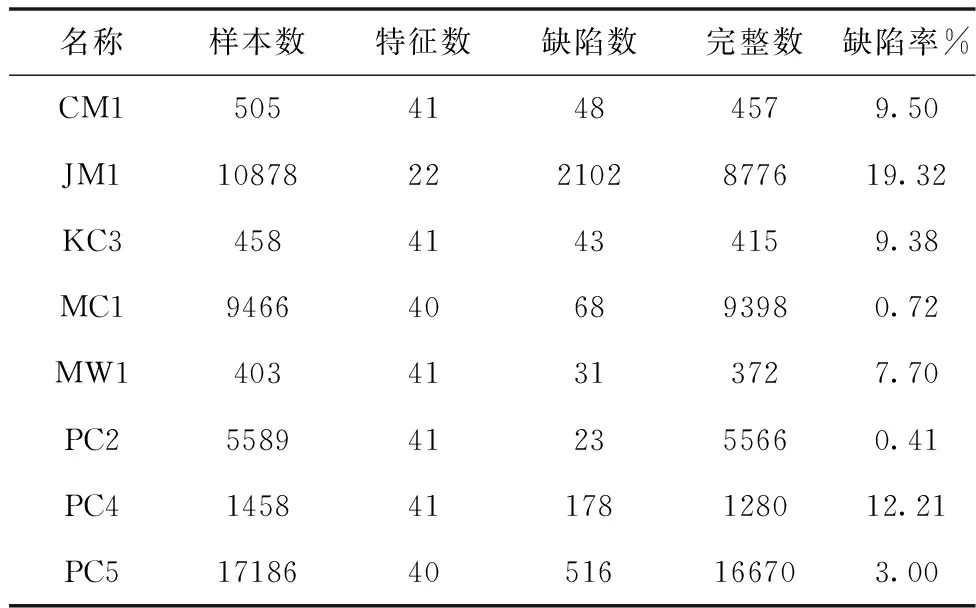
表2 缺陷数据集
3.2.2 特征选择结果
从四个维度进行特征选择,进行实验对比,分别是:信息增益值靠前的15个特征、信息增益值靠前的20个特征、信息增益值大于等于0.15的特征、信息增益值大于等于0.20的特征。选择特征最优的前15和前20原因是,为和文献[9]进行对比;选择IGV大于等于0.15或0.20的特征原因是,这部分特征IGV较小,和整体特征属性相关性不大,在不破坏整体数据集的情况下,可以优化数据集。经过信息增益值(IGV)特征选择之后的CM1、JM1、KC3、MC1、MW1、PC2、PC4和PC5的数据集,每一个特征的信息增益值都不同,使用Ranker降序排序。在表3中以PC4为例,显示了PC4的属性以及信息增益值(IGV),从表中可以看出不同属性的IGV不同,在实验中使用以上所述的四个维度进行特征选择,和原始特征进行对比,以确定最合适的特征优选结果。
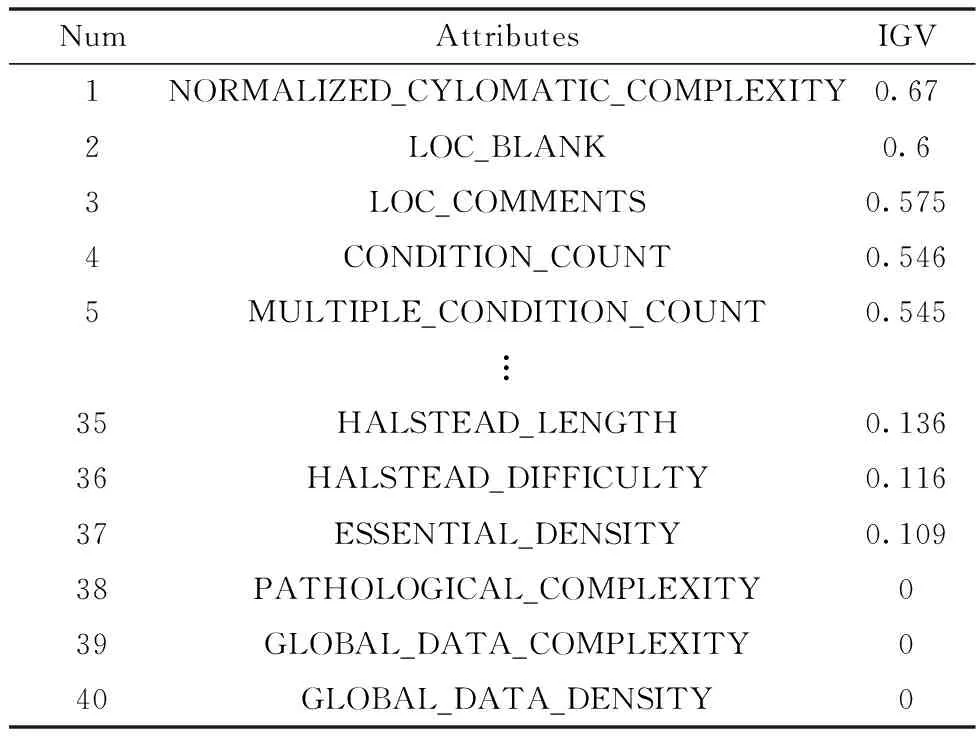
表3 PC4的属性和信息增益值
3.3 结果与分析
3.3.1 模型性能评估
本实验中,在数据进行预处理之后,使用Stacking集成学习构建学习器。本模型选择的是经过类不平衡处理和特征选择后的数据集CM1、JM1、KC3、MC1、MW1、PC2、PC4和PC5进行实验,综合每个数据集在Accuracy、F-Measure和AUC评价指标下,分别从原特征、IGV前15、IGV前20、IGV≥0.15和IGV≥0.20不同的特征选择对实验结果的影响。实验结果如图2所示。
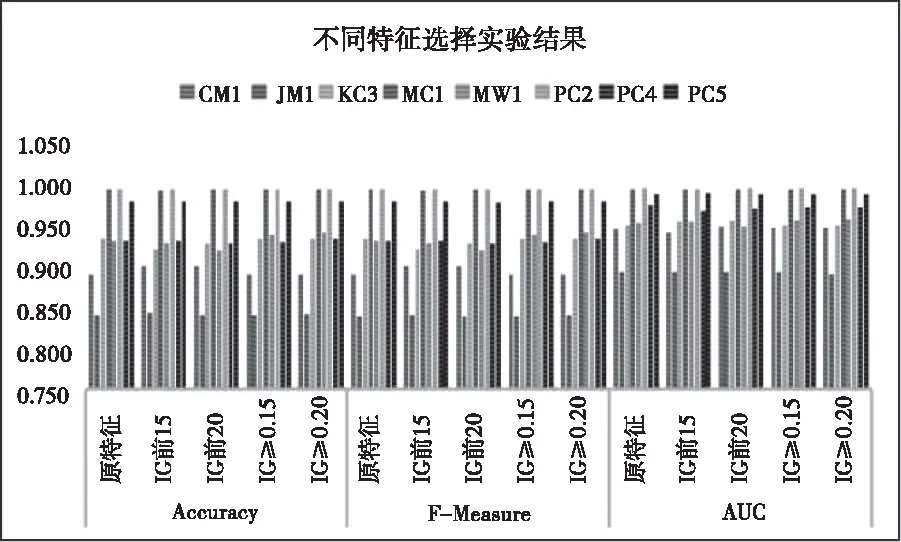
图2 不同特征选择实验结果
为方便查看不同特征选择对实验结果的影响,取实验的平均值进行对比,如表4所示:

表4 评价指标对比表
由表4可知,针对每种评价指标,数值最高的用加粗字体进行标注,因此可以清晰的看到,在特征选择中,IGV≥0.20实验结果相对于其它四种特征选择,在评价指标Accuracy和F-measure中都有优势,在评价指标AUC上虽然只比IGV≥0.15高,但是并不比其它的特征选择低。因此整体上可以看出,IGV≥0.20实验的预测效果最好。
3.3.2 模型对比
通过文献[9],可知四种模型均使用Stacking进行实验,分别是LG+NN、LG+NB、J48+NN和J48+NB,在这四种模型中,初级学习器和次级学习器均只使用一种算法,其中“+”前是初级学习器算法,“+”后是次级学习器。本文汇总了另外四种模型的评价指标Accuracy、F-Measure和AUC并且和本模型进行对比,汇总数据见表5所示。
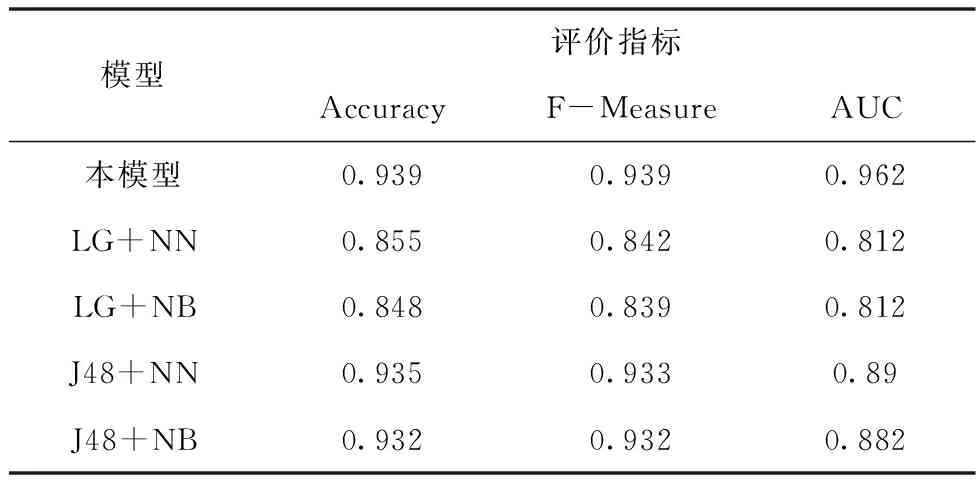
表5 模型结果对比表
在上面表格中,每一类评价指标的最大值用加粗字体进行标注。可以看出,本模型在评价指标Accuracy、F-Measure和AUC中均大于其它模型。通过计算LG+NN、LG+NB、J48+NN和J48+NB评价指标的平均值发现,本模型在Accuracy平均提升4.65%、F-Measure平均提升5.25%和AUC平均提升11.3%。为了更加直观对比不同模型的实验结果,绘制图3折线图:

图3 不同模型结果对比图
由图3可可知,本模型的各项指标均比LG+NN、LG+NB、J48+NN和J48+NB模型的实验效果要好。本文的主要贡献包括:
1)通过分析对比得出最优特征子集。
2)通过集成LG、J48和NB算法提高软件缺陷模型的分类性能。
4 结束语
为了提高软件缺陷预测的精确度,本文提出了基于特征优选的软件缺陷预测集成学习方法。通过Stacking集成不同的分类算法,在初级学习器上使用两种分类算法进行组合,相比于初级学习器只有一个分类算法的软件缺陷预测模型,在评价指标Accuracy、F-Measure和AUC上都有提升。因为80%的缺陷在20%的模块,所以导致缺陷模块类不平衡问题,采用 SMOTE方法解决类不平衡问题;使用IG进行特征优选;最后对模型进行十折交叉验证。本实验在此基础上,提高了软件缺陷预测性能,有利于对缺陷模块进行检测。
下一步的研究工作包括:集成学习的类别有三种,分别是Boosting、Bagging和Stacking,本文预测模型是基于Stacking方法。可以进一步研究Boosting和Bagging集成学习,然后和Stacking做对比,以得出更加适合的软件缺陷预测模型;本实验的Stacking集成学习中,初级学习器使用LG、J48,次级学习器使用NB。可以进一步研究在初级学习器中使用其它算法组合或者是单个算法,次级学习器也用其它算法,以提升软件缺陷的预测率。
