不完备多视图的在线反向图正则化聚类*
2023-08-31邓万宇耿美娜李建强
邓万宇 耿美娜 李建强
(西安邮电大学计算机学院 西安 710121)
1 引言
现今,随着信息技术、计算机技术以及互联网技术的迅速发展,获取数据的方式越来越多,人们已经进入了大数据时代。大数据在国内外已经如火如荼的发展起来,在各个领域都在渗透,近年来,人们对于数据信息价值性和可靠性都有着较高的要求,在大数据的时代背景下,每天都会产生各种形式的数据,包括文字、图片、视频以及音频,这些数据优势是规模大、种类多、要求实时性强。
在当今大数据时代,同一数据对象往往可以在不同的视图下进行描述,所获取的数据常常可以由多个特征集合进行表示,不同视图下的观测揭示了事物的不同属性,这类数据通常被称为多视图数据[2]。多视图数据的学习主要是在聚类这个背景下被研究,对于此类多视图的研究被称为多视图学习[3],目前,多视图学习在机器学习、数据挖掘、人工智能等不同领域得到了广泛的研究[4~6]。在这些视图中,每一个视图可以满足于特定的数据分析任务需求,不同视图之间通常包含互补的信息。类似于我们所倡导的多视图看问题的思维,机器学习如何综合利用多视图数据建立性能更为有效的学习模型,从而服务于人类的生活和工业生产,具有重要的理论意义和广泛的应用前景。
在多视图的聚类中,存在一些实际问题,往往假设这个数据是完整的,然而在实际应用中,可用的多视图数据是不完备的,即意味着缺少某些视图的功能,这对多视图聚类带来了很大的困难。如何处理不完全多视图数据并从中挖掘到该类数据的共享信息,利用多视图数据的一致原则以及互补原则完成多视图聚类任务,已经引起机器学习领域研究人员的广泛关注。如果对于这类不完备多视图数据直接进行聚类分析,则会丢失很多的信息,因此,首先要对不完备多视图数据进行分析处理,再对数据进行聚类。显然,现有的多视图聚类方法无法将不完备视图的多视图数据聚类,因为无法学习通用相似图或者所有视图的低维表示。此外,多个视图之间由于缺少配对视图可用的补充信息,因此视图非常有限。这些因素使得不完备多视图数据的研究成为一个挑战。对这类不完备多数图数据集上进行聚类称为不完备多视图聚类[7~12]。因此,本文的研究对象是不完备的多视图数据,关注如何能够更好地处理的不完备的多视图数据,聚焦不完备多视图技术的相关技术。
同样,在上述中解决的不完备多视图数据都是离线的,没有考虑到大规模的一些数据问题,其不能直接存放在内存中,并且很难离线处理。对于这个问题的处理,到目前为止,针对此问题已经提出了两种解决方法[13~14]。
对于处理这种大规模的不完备多视图数据,本文提出了一种基于非负矩阵分解[15~20]的在线反向图正则化算法(Nonnegative matrix factorization algorithm based on online inverse graph regularization:IMC_OIRG)方法。
本文提出的IMC_OIRG 算法,主要具有以下优点:
1)当数据太大而不能放入内存中时,依旧可以处理不完备多视图数据,即可以最小化不完备多视图数据对聚类结果的影响。
2)对于这种数据过大的数据,依旧可以将不同特征空间的各种视图进行组合,根据其一致性和互补性,能够使得可以获得更好的聚类结果。
3)将非负矩阵分解与反向图正则化进行结合,保证多视图局部结构的一致性,使得不完备多视图数据能够进一步对齐,使得能够得到更好的公共潜在特征表示。
2 相关工作
2.1 问题描述
对于不完备多视图聚类,简要描述问题的表述,假定给出一个有N个样本nv个视图的数据集,在本文中定义一个指示矩阵B∈Rnv×N。
其中,B的每一行代表一个视图的存在。若多视图数据是完备的,每个视图包含所有的实例,则B为一个全1矩阵,即=N,k=1,2,…,nv。若多视图数据是不完备的,数据矩阵X(k)将有许多行缺失,即指示矩阵表示为<N,k=1,2,…,nv。本文的目标为将不完备多视图数据的N个实例聚类成K个聚类。
2.2 相关工作
OPIMC[14]为解决不完备多视图聚类问题提出了一个框架,借助于正则化矩阵分解和加权矩阵分解,将数据矩阵X(k)∈Rdk×N分解为两个矩阵G(k)∈RDk×K和F(k)∈RN×K,同时令,为了考虑到不同视图之间的一致性信息,假设不同的矩阵,共享相同的矩阵F。同时还考虑到实例的缺失信息,借助加权矩阵分解来处理每个视图的不完备性。对于大量的不完备多视图数据,假设每个视图都是通过块获得的,并且块的大小为s,最终目标函数表示为是第k个视图的第t个数据块,Ft是第t个对角数权据重块矩的阵聚。类权指重示矩矩阵阵,被是定第义为t个数据块的
3 算法模型
在本节中,提出了IMC_OIRG 算法,处理大规模的不完备多视图数据,利用动态权重学习推断缺失的视图,同时,利用反向图正则化进一步对齐视图,学习局部特征,来实现有效的公共表示学习。
3.1 算法提出与模型构建
给定nv个视图,N个样本的不完备多视图数据,使用非负矩阵分解的模型进行分解,将X(k)∈分解为两个矩阵G(k)∈和F(k)∈,分别表示为第k个视图的基矩阵和潜在特征矩阵。其中,K表示为聚类的目标数,目标函数可以写成如式(4)所示。
在此基础上,由于不完备多视图数据的特点,目标函数无法直接进行优化,简单的填充实例不能很好地解决这个问题。因此,本文利用加权非负矩阵分解的思想,引入一个对角权重矩阵P(k)∈RN×N,其中,表示为第k个视图的第i个实例,同时,对于在视图中出现的实例权重赋予1,对于视图中缺失的实例赋予较低的权重。因此,目标函数式(5)表示为
本节的目标为找到每个视图的潜在特征矩阵和一个共同的共识,这个共识矩阵表示了所有的视图的综合信息。因此,目标函数式(6)可以被重新写为
其中,λ1(k)表示为重建误差与学习到的第k个视图的共识一致性不一致之间的权衡参数。
在上述式(6)中,不仅对于不同的视图分配了不同的权重,而且表示出了一致的共识矩阵,对于不完备视图的性质,为了加强潜在特征矩阵的稀疏性,仍添加一项l1范数。同时对潜在特征矩阵添加范数限制后,对于噪声和异常值是鲁棒的。
其中,‖ · ‖1表示l1范数,λ2(k)表示为第k个视图重建的稀疏性和准确性之间的折衷参数。
对于不完备多视图数据,由于所有视图的可用实例数都小于总样本数,获取数据的局部流行结构是不可能的,因此,使用反向图进行学习,如式(8)所示。
其中,其中,1 是一个全1 的向量。其次,令Pi,:1=1,是为了防止任何实例与其邻居不相连的平凡解。rank(LW)表示为LW的秩。通过反向图正则化,保证了多视图间的一致性流形结构,进一步对齐所有恢复的不完整视图。
3.2 目标函数
最终,对于不完备多视图数据,根据上述学习,形成了一个学习模型,得出解决不完备多视图数据的算法的目标函数,如下。
在实际的应用过程中,数据矩阵由于过大,因而无法直接放入内存中。对于此问题,本章采用以低计算和存储复杂性的在线方式来解决此问题。将输入的数据在时间t时分成块,s表示为数据块的大小,也就是实例的大小。因此,输入的数据矩阵为,最终的目标函数表示为式(10)。
对于目标函数式(10)中引入的权重矩阵,和之前用平均特征值进行直接填充的方法不同,不完备多视图数据,本节研究的多视图数据太大而不能放入内存,平均特征值不能直接进行计算,对此,引入一个动态权重矩阵,即当读入一个新的数据块时,采用动态(最新)平均值来填充,不是采用全局的平均特征值来填充缺失的实例。
可利用的实例中可以被动态设置为
3.3 优化
对于目标函数式(10)的求解问题,可以发现,对于每一个t,需要对和{T},然而,目标函数不是联合凸的,因此采用交替迭代的方法来更新求解。
1)更新G(k),固定其他变量,关于G(k)的最小化目标函数为
对G(k)取 一 阶,ℒ导(t)对数于G,(k其)的 梯中度,为令
因此,ℒ(t)(G(k))相对于G(k)的Hessian矩阵为
使用二阶的投影矩阵下降法,在时间t更新G(k)的方程为
其中,z表示迭代的次数,γz表示步长,∇ℒ(t)(G(k))表示目标函数对G(k)的一阶导数。对于选取合适的步长γz,本章考虑使用简单而有效的Armijo的投影规则,令γz=ηφz,φz是第一个非负整数。
3)更新W,固定其他变量,关于W 的最小化目标函数为
对式(21)进一步进行简化:
式(22)的封闭形式可以通过(Nie et al.2016)提出的有效算法来实现。
4)更新T,固定其他变量,关于T的最小化目标函数为
其可以通过对应于最小二乘的前c个最小特征值的一组特征向量来优化。
在式(24)中,假设λ1(k)为正,对其求一阶导数并使其为0:
在算法1 中总结了IMC_OIRG 的整个优化过程:
算法1:IMC_OIRG
Input:不完备多视图数据{X(k)} ,聚类数K,数据块大小s,参数{λ1(k),λ2(k),λ3(k),λ4(k)} .
为不完备多视图实例设置权重;repeat
for k=1:nv do
根据式(16)更新G(k).
根据式(22)更新W.
根据式(23)更新T.
直至收敛
3.4 收敛性分析
如算法1 所示,提出的IMC_OIRG 方法是通过交替迭代的来求解最优解的,通过此方法,可以收敛到一个局部最优解。
4 实验
4.1 数据集
数据集介绍如下,我们选取四个数据集,Handwritten Dutch Digit Recognition(Digit)、Web Knowledge Base(WebKB)、Reuters Multilingual Text Data(Reuters)、YouTube Multiview Video Games(You-Tube)。数据集总结见表1。
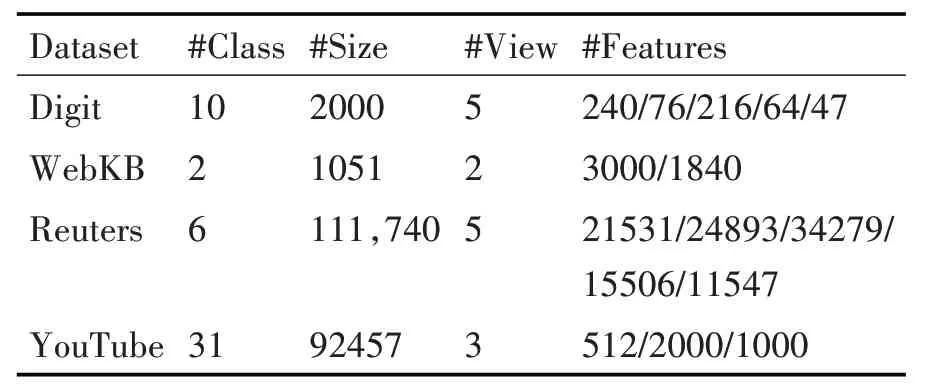
表1 所用基准数据采集系统的描述
4.2 对比试验
我们将本文提出的方法与几种之前的方法进行比较:IMC_OIRG 是本文提出的在线多视图聚类方法,为了便于比较,将所有视图的参数设置为相同。OPIMC 利用正则化矩阵分解和加权矩阵分解的单趟在线聚类方法;MIC 是OMVC 的线下情况,基于联合非负矩阵分解的聚类方法;OMVC 是提出的在线不完备多视图聚类方法;Multi NMF 是提出的一种经典的离线多视图聚类方法;ONMF 是一个在线的单视图文档聚类算法,为了应用ONMF,将所有规范化的视图连接在一起,形成一个大的单一视图。另外,由于MIC 和MultiNMF 都是离线方法,因此将所有的数据都考虑在内,通常可以获得比在线方法更好的性能。
4.3 实验设置
在本次实验中,采用两个广泛使用的评估指标,准确性(AC)和归一化互信息(NMI),用来横量聚类性能。同时,对于每个数据集扫描十遍(Pass)并汇报每一次的NMI和AC。实验结果如图1所示。
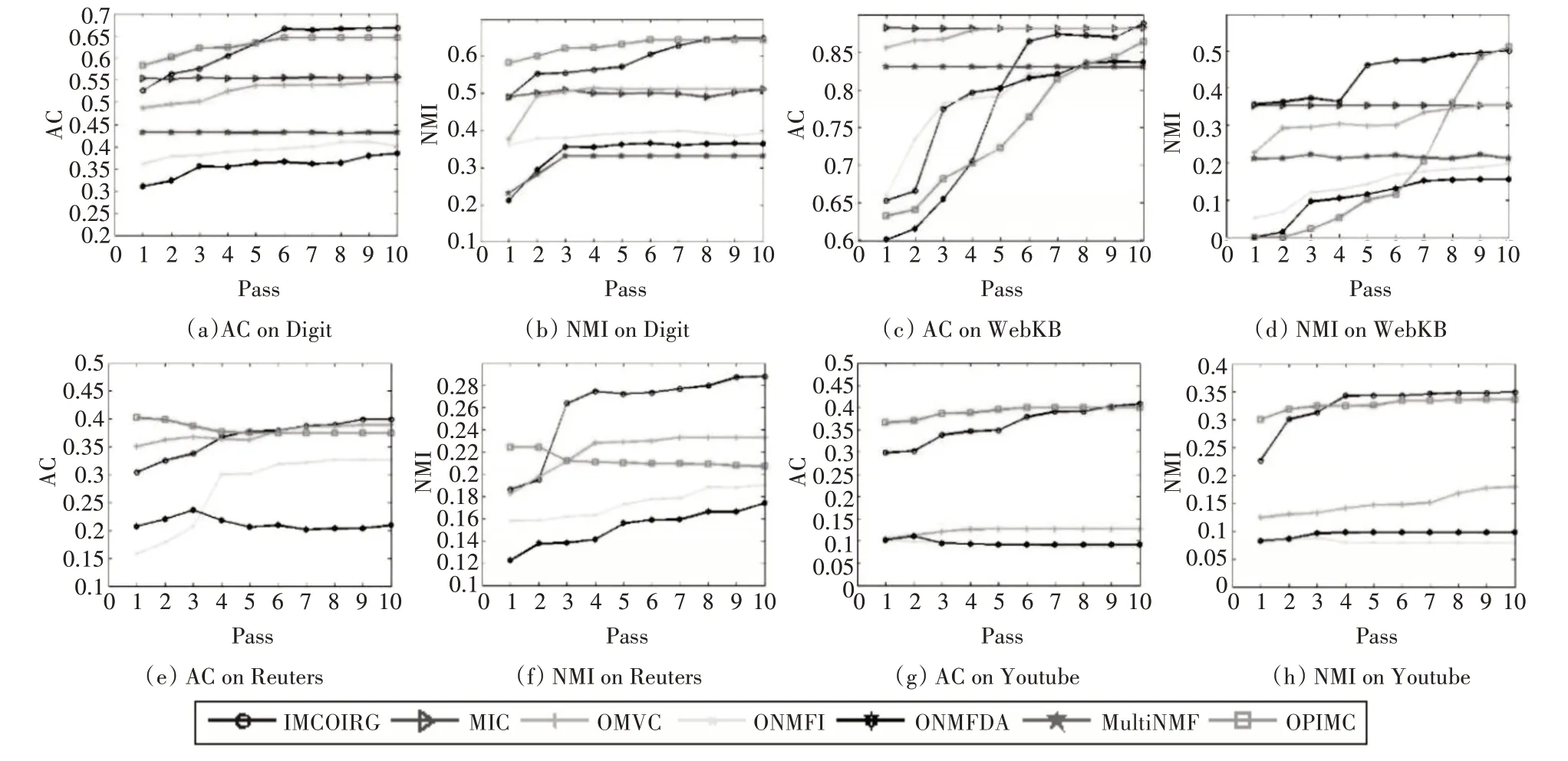
图1 实验结果
本文选取的四个数据集都是完整的,为了模拟不完备多视图的情况,在每个视图中令缺失度为0.4。对于数据块的设计,将小数据集s 为50,大数据集为2000。由于在对比方法中,除ONMF以外所有方法都有几个参数设置,因此对比较方法中的所有参数进行网格搜索,并且给出最佳结果。另外,MultiNMF、ONMF-I 和ONMF-DA 无法处理不完备多视图的视图,为了应用这些方法,本文用平均特征值填充缺失实例。在评价中,本文采用K-means从一致性潜在特征矩阵中得到聚类解。
4.4 结果分析
图1(a)~(d)显示了本文提出的方法在数据集Digit 和WebKB 的性能,从图中可以观察到,对于Digit 数据集,在第六次之后,算法达到了相似的结果,同时,比其他的方法效果要好一点。对于Web-KB数据集,前几次的效果不是很好,造成这个现象的主要原因可能是因为设置的缺失度与设定的块的尺寸不合适,导致公共潜在特征矩阵学出较难,经过多次Pass之后,聚类性能提升。
图1(e)~(h)显示了本文提出的方法在数据集Reuters 和Youtube 的性能,从图中可以观察到,对于Reuters数据集,第五次Pass之后,慢慢达到了较好的结果,对于Youtube数据集,直接就能看出来比较其他方法比较有效,聚类性能明显有效。
4.5 复杂性分析
在本文提出的算法中,使用平均损失来进行IMC_OIRG方法的收敛性实验,在每次读取数据块t之后,平均损失被定义为
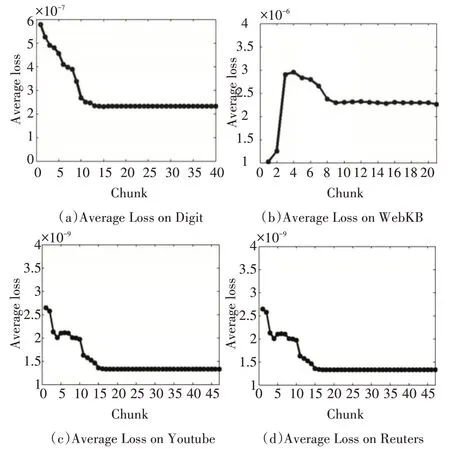
图2 平均损失值
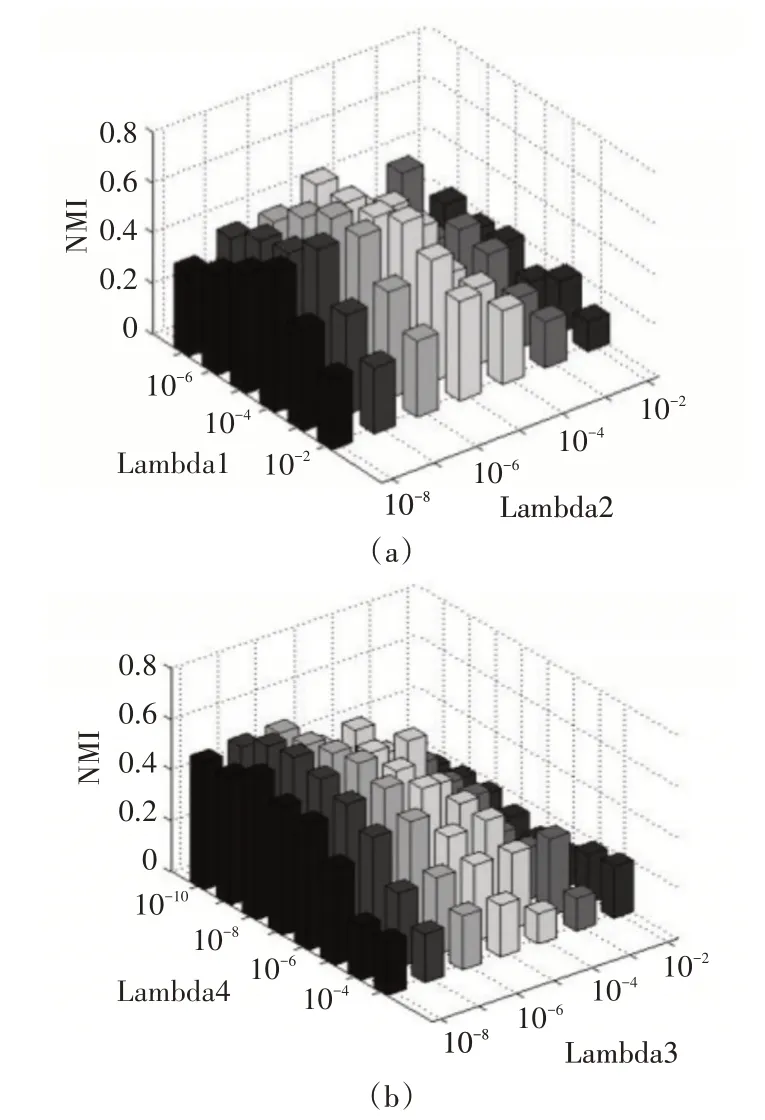
图3 Digit参数
4.6 参数敏感度分析
在本文中利用Digit 数据集对四个参数{λ1(k),λ2(k),λ3(k),λ4(k)} 进行分析,当参数分别位于范围[10-6,10-1],[10-8,10-2],[10-8,10-2],[10-10,10-3]内时,可以看到有一个好的效果,在实验中,利用网格搜索策略来寻找四个最佳的参数。从图中3 可以看出,当{λ1(k)=10-3,λ2(k)=10-7,λ3(k)=10-7,λ4(k)=10-8}时效果是最佳的。
4.7 数据块分析
在本文所提出的方法中,设定的数据块s是一个重要的参数,为了学习不同s对于聚类结果的影响,选取Digit 数据集,缺失度为{1 ,0.2,0.4} ,令s={2 ,10,50,250} ,在表2 中,给出实验结果。可以观察出,本文所提出的方法,效果性能优于其他的方法,并且可以看出,当数据块大的比数据块小的效果好一些,原因在于,当数据块越大,其中可以利用的数据信息就会越多,其中,当s=50 或者s=250 时,效果更好。
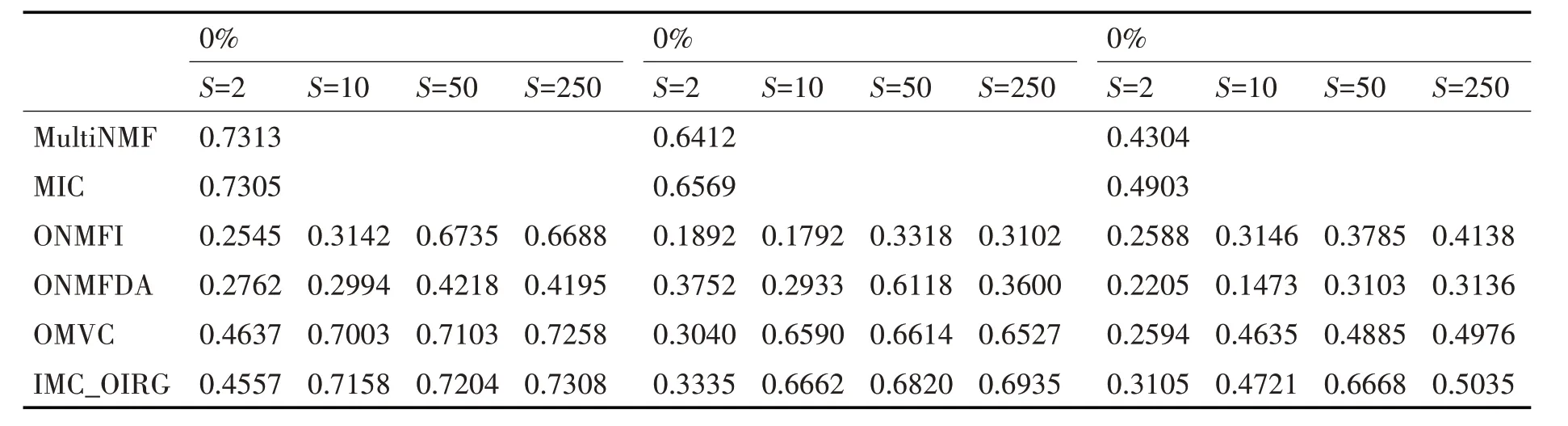
表2 Digit对于不同缺失率和不同数据块
5 结语
本文提出了一种解决不完备多视图数据的方法——不完备多视图的在线反向图正则化聚类(Online Reverse Graph Regularized Clustering for Incomplete Multi-view)。在加权非负矩阵分解的前提下,最小化潜在特征矩阵和共识之间的不一致,给缺失实例赋予动态权重,减少缺失实例的影响,学习反向图正则化,利用视图的局部信息,进一步对齐视图。同时,对于大数据的数据集,对其进行逐块处理。通过实验证明了本文所提出方法IMC_OIRG的有效性。
