基于改进型CEEMDAN-Stacking集成学习的短期电力负荷预测
2023-08-04沈艳霞
李 翔,沈艳霞
(江南大学 物联网技术应用教育部工程研究中心,江苏 无锡 214122)
0 引 言
电力负荷预测作为电力系统部门的一项重要工作,对保证电力系统的合理规划与调度、提高经济效益具有十分重要的意义[1]。准确的电力负荷预测能够为电网规划提供更好的指导,有利于电力系统的安全稳定运行,使电能得到更充分的利用。
电力负荷预测中,传统的时间序列模型(如自回归滑动平均模型、Prophet、马尔科夫链等)对于数据波动性不大、平稳性较好的序列具有较好的预测效果,但是难以捕捉非平稳序列中复杂的时间依赖关系。人工智能领域的机器学习和深度学习算法也被广泛应用于负荷预测,常见的预测模型有支持向量机、极限学习机、长短期记忆(Long Short-Term Memory,LSTM)神经网络等[2,3]。文献[4]按照重要程度对输入特征进行筛选,并使用贝叶斯优化的极限梯度提升(eXtreme Gradient Boosting,XGBoost)模型进行负荷预测。文献[5]对原始负荷数据进行经验模态分解,建立了基于注意力机制的门控循环单元网络并对各分量预测,将各预测值叠加形成最终的预测值。通过对原始序列进行分解处理,降低了原始序列的非平稳定性和复杂性。此外,对分解后的子序列进行建模预测,有效提高了模型的预测精度。然而,单一模型难以全面挖掘数据之间的变化规律,也限制了模型的泛化性。文献[6]基于特征选择的方式,采用Stacking集成学习融合多种算法进行负荷预测。文献[7]通过Stacking 算法融合多层门控循环单元网络实现风电功率预测。文献[8]利用改进的萤火虫算法优化核岭回归模型中的参数,通过Stacking 算法融合各核岭回归模型对风速序列进行预测。集成学习方式可以结合多个模型的优势,整体提升了模型的预测性能。
由于以上文献均采用传统的Stacking 模型,忽略了基学习器在交叉验证时所形成的不同模型之间的差异性,影响了模型的预测精度。文献[7]和文献[8]均使用了Stacking 进行建模,但并没有对原始序列进行分解处理,仍未降低序列的非平稳性和复杂性。基于此,对滑动窗口处理后的负荷序列进行自适应噪声完备集合经验模态分解(Complete Ensemble Empirical Mode Decomposition with Adaptive Noise,CEEMDAN),并重构其模态分量[9]。根据Stacking 集成学习模型中不同学习器的预测精度,对其在测试集上的预测结果分配权重,利用改进的Stacking 模型融合LSTM神经网络、XGBoost、K 最邻近(K-Nearest Neighbor,KNN)模型以及多层感知机(Multilayer Perceptron,MLP)实现短期电力负荷预测。
1 基于滑动窗口的CEEMDAN 分解与重构
1.1 滑动窗口处理
考虑到电力负荷数据较强的时序关联性,对数据集中的负荷数据按滑动窗口方式进行处理(见图1),将特征负荷序列x(i)和目标负荷序列y(i)分别作为模型的输入和输出。其中,x(i)表示过去i天的历史负荷序列,y(i)表示第i+1 天的负荷序列。

图1 滑动窗口处理方式
1.2 CEEMDAN 分解
对滑动窗口处理后的电力负荷序列进行CEEMDAN 分解,分解算法的步骤如下。
(1)设原始电力负荷序列为x(t),第i次添加高斯白噪声后,新的电力负荷序列xi(t)为
式中:εk为第k个信噪比;ωi(t)为第i次加入的高斯白噪声序列。
(2)对xi(t)进行经验模态费解(Empirical Mode Decomposition,EMD),得到第1 个模态分量IMF1(t)和第1 个剩余分量r1(t)为
(3)对新的信号r1(t)+ε1E1[ωi(t)]进行EMD 分解,得到第2 个模态分量IMF2(t)为
式中:E1(·)为EMD 分解产生的第1 个模态分量的算子。
(4)重复步骤(3)的计算过程,得到第k+1个模态分量和剩余分量。
(5)当达到EMD 的停止条件时,分解结束,原始电力负荷序列被分解为若干个模态分量和1 个剩余分量。为了适应后续的预测模型,将需要得到的IMF 数量作为CEEMDAN 分解结束的停止条件[10]。
1.3 模态分量重构
为了降低模型在时间和计算上的复杂度,将各模态分量重构为高频分量和低频分量。假设电力负荷序列经过CEEMDAN 分解成m个不同的内涵模态分量(Intrinsic Mode Functions,IMF),本文将前m-1个分量重构为高频分量H,第m个分量为低频分量L,重构方式为
由于重构得到的高频序列和低频序列中负荷数据的传输方式相同,为了方便描述,将特征负荷序列用Xi表示,将目标负荷序列用Yj表示,其中Xi=(xi,xi+1,…,xi+N-1),则输入向量分别为(x1,x2,…,xN),(x2,x3,…,xN+1),(xn,xn+1,…,xn+N-1),对应的标签分别为(YN+1,YN+2,…,Yn+N)。
2 负荷预测模型
2.1 Stacking 集成学习框架
Stacking 集成学习框架通过对多种不同算法的融合,从整体上提升模型的性能。Stacking 框架由2 层学习器构建而成。第1 层中包含多个基学习器,第2层中包含1 个元学习器,如图2 所示。

图2 Stacking 集成学习框架
首先,将划分后的数据集输入第1 层的基学习器中,各基学习器分别预测并输出其预测值;其次,将输出的预测值及其对应的标签作为新数据集,以此训练第2 层的元学习器;最后,由元学习器输出最终预测值。
2.2 学习器选择
Stacking 框架中,第1 层基学习器采用LSTM、XGBoost 以及KNN。LSTM 网络可以很好地学习序列中的时间依赖关系,在时间序列建模上有一定的优势。KNN 算法训练时间快,算法复杂度较低。XGBoost 对上一步预测的残差进行拟合,可使模型训练更加充分。第2 层元学习器采用MLP,利用神经网络进一步拟合预测值和原数据集标签,从整体上提升模型的预测能力。
2.2.1 LSTM
LSTM 网络解决了循环神经网络(Recurrent Neural Network,RNN)中存在的梯度消失和爆炸问题,通过隐藏层不断地将上一时刻的信息传递至下一时刻,同时结合当前时刻的输入得到对应输出。设置本文模型中基学习器LSTM 的输入向量为Xi,输出向量为。
2.2.2 XGBoost
XGBoost 模型不同于大多数回归模型采用原始数据进行拟合,而是通过拟合上一步预测的残差不断逼近真实值,从而逐步提升模型的精度。
XGBoost 模型的预测值可以表示为
式中:表示预测值;K表示模型所用树的数量。
XGBoost 模型的目标函数为
目标函数中第1 项表示预测值y^i 和真实值yi的误差,第2 项表示所有树的复杂度之和。通过最小化目标函数的方式完成对函数集fk(x)的学习,最后通过累加K棵树的预测值实现负荷预测。设置本文模型中基学习器XGBOOST 的输入向量为Xi,输出向量为。
2.2.3 KNN
KNN 回归是一种监督学习算法,通过搜索历史样本中与预测样本最接近的K个样本,并根据平均属性值进行负荷预测。设置本文模型中基学习器KNN 的输入向量为Xi,输出向量为。
2.2.4 MLP
MLP 是一种全连接神经网络。数据由输入层传入隐藏层后,隐藏层中的神经元对数据进行分析和运算,并将结果传至输出层,由输出层对其处理后得到最终的输出。假设MLP 输入向量为X,经过运算得到
式中:W1、W2为权重;b1、b2为偏置。
第2 层学习器通过拟合训练集的预测值与其对应的真实值来训练MLP 模型,将测试集的预测值输入训练好的MLP 中,从而得到最终的预测值。
2.3 CEEMDAN-Stacking 模型中的数据传输
在CEEMDAN-Stacking 模型中,电力负荷数据的传输方式具体如下。
(1)经过CEEMDAN 分解与模态重构后,数据以滑动窗口的形式传入模型,输入为Xi,输出为Yj。将数据按一定的比例划分为训练集和测试集,分别记作Dtrain和Dtest。
(2)将训练集Dtrain划分为k份,对于每一个基学习器(以LSTM 为例),将其中的k-1 份合并为训练集,另1 份作为验证集。在k轮训练中均采用k-1组数据训练LSTM,再用训练好的LSTM 对验证集中的特征负荷序列Xi进行预测,输出对应的预测值,将其构成的集合记为M1。同理,将基学习器XGBoost 的预测值构成的集合记为M2,将基学习器KNN 的预测值构成的集合记为M3。(3)在每个基学习器中(以LSTM 为例),对于测试集中每个样本的特征负荷序列Xi,采用训练好的LSTM 模型进行预测,得到k个预测值,yi,2,…,yi,k。对预测值取平均得到=(yi,1+yi,2+…+yi,k)/k,将预测值构成的集合记为N。同理,将基学习器XGBoost 和KNN 的预测值构成的集合分别记为N2、N3。
(4)将上述M1、M2、M3组合成新的训练集M,将N1、N2、N3组合成新的测试集N。利用新训练集M训练元学习器MLP,基于训练完成后的MLP 模型对新测试集N进行预测,分别得到高频分量和低频分量的预测值,最后将二者的预测值叠加形成最终的预测值。
第1 层基学习器中以LSTM 为例,其他基学习器预测方式与LSTM 相同,Stacking 模型结构如图3、图4 所示。

图3 Stacking 第1 层结构

图4 Stacking 第2 层结构
2.4 Stacking 模型的改进方式
传统Stacking 模型通过取平均的方式得到测试集的预测结果,忽视了各模型之间不同的预测效果,没有将预测效果好的模型凸显出来,同时预测效果差的模型也同等程度地参与其中。此时,应该赋予预测效果好的模型更大的权重,同时削弱预测效果差的模型带来的影响。改进传统Stacking 模型中对测试集的预测值取平均的方式,具体的权重分配机制如下。
(1)在训练集中记录预测值和真实值Ytrue的平均相对误差(Mean Absolute Percentage Error,MAPE),分别记作MAPE1,MAPE2,…,MAPEk,计算
(2)根据k个不同模型的预测效果确定对应的权重α(q=1,2,…,k),则
(3)输出测试集中各样本最终的预测值=α1yi,1+α2yi,2+…+αkyi,k。
(4)对其他基学习器采用同样的改进方式,综合计算后得到测试集的最终预测值。
以基学习器LSTM 为例,改进Stacking 模型中的权重分配机制如图5 所示,其他基学习器与之相同。

图5 改进Stacking 模型中的权重分配机制
2.5 短期电力负荷预测
短期电力负荷预测流程如图6 所示。

图6 短期电力负荷预测流程
(1)将原始电力负荷序列按滑动窗口的方式处理,分成若干段特征负荷序列和目标负荷序列。
(2)对滑动窗口处理后的负荷序列进行CEEMDAN 分解,将分解后的各分量重构为高频分量和低频分量。
(3)将重构后的高频分量和低频分量均采用改进Stacking 模型进行预测,得到高频分量和低频分量的预测值。
(4)叠加高频分量和低频分量的预测结果,得到最终的电力负荷预测结果。
3 算例分析
3.1 数据集预处理及预测评价指标
数据集采用EMC 公司提供的电力负荷数据集,电力负荷数据颗粒度为30 min,即一天包含48 个电力负荷数据点。本实验将2020 年2 月1 日—2021 年8 月31 日的数据作为训练集,2021 年9 月1 日—10月31 日的数据作为验证集,2021 年11 月1 日—11月30 日的数据作为测试集,利用过去7 天的数据预测未来1 天的电力负荷。为了便于后续模型的训练,对数据进行归一化处理,归一化公式为
式中:xnew为归一化后的数据;xmax为数据中的最大值;xmin为数据中的最小值。
采用均方根误差(Root Mean Squared Error,RMSE)、 平均绝对误差(Mean Absolute Error,MAE)、MAPE 来评价模型误差,即
式中:yi表示i时刻的实际值;表示i时刻的预测值。
3.2 负荷序列的CEEMDAN 分解与重构
对滑动窗口处理后的负荷序列进行CEEMDAN分解,发现当分解层数为5 时,CEEMDAN 分解取得不错的效果。通过CEEMDAN 分解后的各模态分量表现出较好的平稳性,各个模态之间差异明显且无模态混叠现象。随机选取其中一段序列,分解结果如图7 所示。实验中将前4 个分量重构为高频分量H,后1 个分量为低频分量L,采用最终的预测模型对重构后的各分量进行预测。
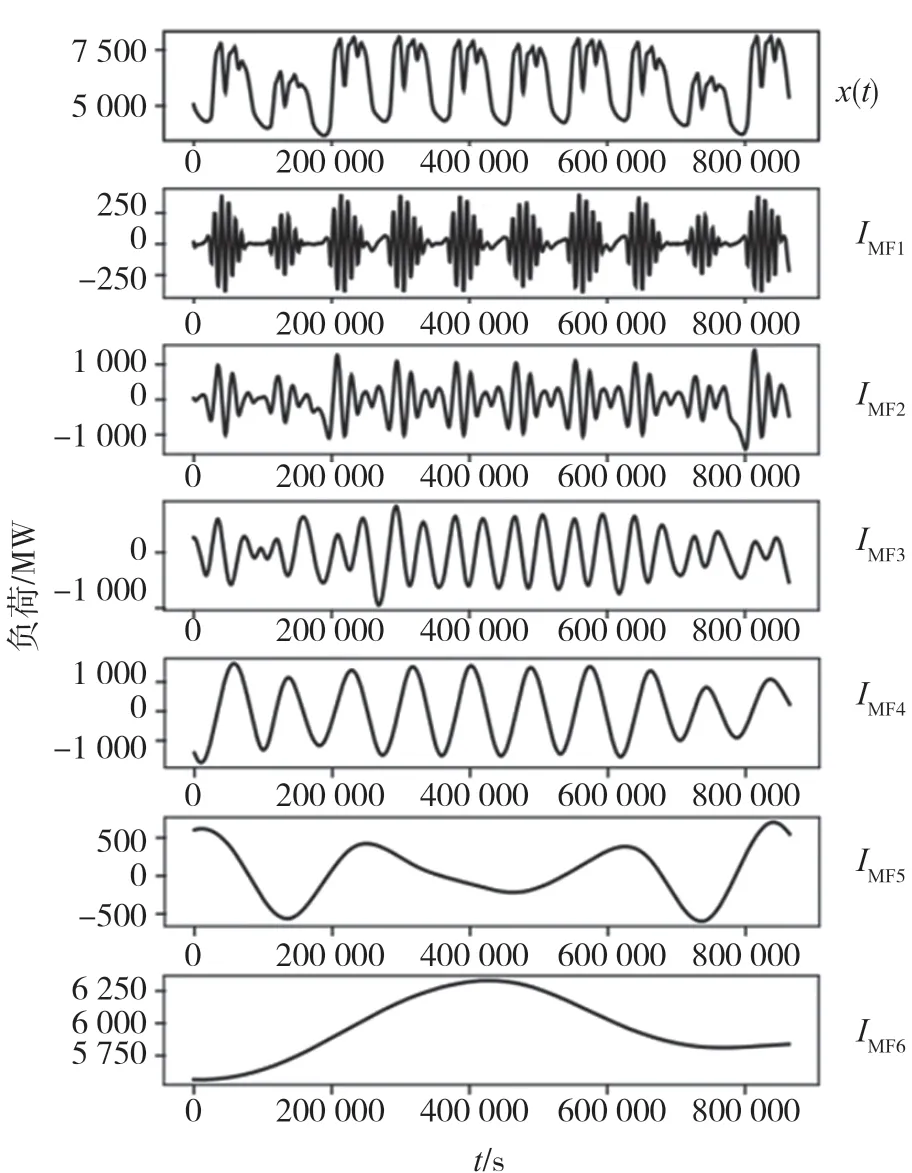
图7 CEEMDAN 分解结果
3.3 模型参数设置
模型中基学习器采用LSTM、XGBoost、KNN,元学习器采用MLP。设置LSTM 堆叠层数为2 层,学习率为0.001,优化器为Adam。XGBoost 中的n_estimators 设置为36;KNN 中的n_neighbors 设置为30。元学习器MLP 中隐藏层为1 层,隐藏层中神经元数量为256 个。
3.4 模型预测效果分析
3.4.1 CEEMDAN 分解后的Stacking 模型与单一模型对比实验
不同模型的预测精度对比结果如表1 所示。

表1 不同模型预测精度对比
由表1 可知,CEEMDAN-Stacking 模型相比CEEMDAN-LSTM 模型、CEEMDAN-XGBoost 模型以及CEEMDAN-KNN 模型,其RMSE、MAE 以及MAPE均达到了最低,说明Stacking 模型综合了LSTM 模型、XGBoost 模型以及KNN 模型各自的优势,从整体上提升了模型的预测精度[10,11]。
3.4.2 CEEMDAN-Stacking 与Stacking 对比实验
分解后的模型预测精度对比如表2 所示。

表2 分解后模型预测精度对比
CEEMDAN-Stacking 模型相对于未经过分解处理的Stacking 模型,其RMSE、MAE、MAPE 均有所降低,证明了负荷序列经过CEEMDAN 分解处理后可以有效提升模型的预测精度。
负荷预测曲线如图8 所示。

图8 CEEMDAN-Stacking 与Stacking 模型预测结果对比
未经过分解处理的Stacking 模型虽然能够预测负荷的变化趋势,但是其对真实负荷序列的拟合能力较弱[12]。经过CEEMDAN 分解处理后,Stacking 模型对电力负荷的预测值与真实值更为接近,模型的预测能力得到了较大的提升。
3.4.3 改进型CEEMDAN-Stacking 与CEEMDANStacking 对比实验
改进后的模型预测精度对比如表3 所示。

表3 改进后模型预测精度对比
由表3 可知,改进型CEEMDAN-Stacking 模型相对于CEEMDAN-Stacking 模型,其RMSE、MAE、MAPE 均有所降低。负荷预测曲线如图9 所示。

图9 改进型CEEMDAN-Stacking 与CEEMDAN-Stacking 模型预测结果对比
在大多数时间段内,改进型CEEMDAN-Stacking模型对真实负荷序列的拟合能力更强。改进型CEEMDAN-Stacking 模型根据学习器不同的预测效果赋予其相应的权重,优化了第2 层元学习器的输入,从而得到更加准确的预测结果。
4 结 论
改进型CEEMDAN-Stacking 负荷预测模型以电力负荷时间序列为主线,对滑动窗口处理后的负荷序列进行CEEMDAN 分解并重构其模态分量。在预测模型部分,结合LSTM 算法、XGBoost 算法、KNN算法以及MLP 算法的优点,采用Stacking 集成学习模型将其融合,并通过精度赋权的方式对传统Stacking 模型进行改进,进一步提升了模型的预测性能。相较于CEEMDAN-LSTM 模型、CEEMDANXGBoost 模型、CEEMDAN-KNN 模型、Stacking 模型以及CEEMDAN-Stacking 模型,改进型CEEMDANStacking 模型具有更高的预测精度和工程实用价值。
