一种基于关系模型的场景文本检测方法*
2023-08-02赵尔敦
陈 旸 赵尔敦 吴 靖
(华中师范大学计算机学院 武汉 430079)
1 引言
随着手机、平板等可拍照工具的普及,生活中包含文本的自然场景图片数量迅速增加,检测图片中的文本信息有着巨大的潜在价值。因此自然场景文本检测在商品推荐、自动驾驶、视觉障碍辅助等应用方向上受到越来越多的关注。相较于传统的印刷文档文本检测[1~2],自然场景文本检测存在背景复杂、文字与背景对比度低、光照不均、文字区域分布不一等问题,因此它仍然存在挑战。为此,许多学者提出了自己的研究方法。现有的自然场景的文本检测方法大致可以分为两大类,基于传统特征的方法[3]和基于深度学习的方法[4]。
基于传统特征方法又可以分为两类:基于连通域分析的方法和基于滑动窗口检测的方法。基于连通域分析的方法之一是基于笔画宽度变化算法(SWT)[5],该算法主要根据文本的笔画宽度性质来获取文本候选区域。利用SWT 算法可以提取出多尺度多方向的文本候选区域,但是当图片边缘不明显或者图片场景复杂时其鲁棒性较差。另一种基于连通域的文本检测方法是最大稳定极值区域(MSER)方法[6],该算法的原理是对图像进行二值化处理,在一个全黑到全白的处理过程中,连通域面积随阈值变化很小的区域为最大稳定极值区域,该区域即为文本候选区域。在处理复杂的场景图片上MSER 方法有不错的文本检测性能,但是在处理低对比度图像时鲁棒性较差。基于滑动窗口检测方法[7]通常采用多尺度滑动窗口对图像进行扫描以获得文字候选区域,然后根据手工特征来对文字候选区域进行分类,判断是否为文本。
虽然这些传统的文本检测方法取得了一些效果,但是在自然场景下,文本图像通常具有遮蔽物多、文本背景对比度低、光照不一等特点,导致这些基于传统特征的方法存在检测能力不足、鲁棒性不够好的问题。因此,基于深度学习的文字检测方法近年来已经成为自然场景文本检测研究中的主要方法。
不同于传统的人工特征分类器方法,深度学习方法可以通过自主学习将低层特征组合成抽象的高层属性特征,这样避免了繁琐的人工提取特征的过程,而且提高了准确性。在基于深度学习的自然场景文本检测方法中,基于图像分割的方法和基于文字区域边框回归方法应用得十分广泛。在基于图像分割的文字检测方法中,常见算法是用全卷积网络(FCN)[7]在像素级别进行文字背景分类,然后经过复杂的后处理获得文本区域,该方法在检测多方向自然场景文本中效果显著,但是需要的计算量比较大。另一种主要的深度学习方法是基于文字区域边框回归的方法,这类方法一般在图象上提取很多文字候选区域,然后通过分类网络对文字候选区域进行分类,同时训练回归网络对候选区域位置进行精调,比较常见的如Faster R-CNN[8],CTPN[9],Text Box[10]等,这种方法在复杂的自然场景文本上能取得非常不错的效果。
然而以上这些深度学习方法都忽略了候选文本区域之间关系,因而未能把文本区域的关系特征加入到检测网络中。文献[11]中提出了一种不改变其他层,可以方便插入基于注意力的目标关系模型,使关系模型能够被方便应用于其他网络中。Han Hu[12]等的论文在多目标检测中也证明了将目标间关系引入网络模型中会对目标检测产生直接的增益效果。
本文针对场景文本检测问题,在深度学习方法的基础上,结合注意力机制中的关系模型,提出了一种基于关系模型的自然场景文本检测方法。本方法先利用自动设置锚检测的卷积神经网络来提取文字候选区域的特征,然后利用关系模型结合文字候选区域之间的关系,从而可以准确提取文字区域。该方法在ICDAR2013 和ICDAR2015 数据集上的实验结果表明,与其他方法比较,本文提出的算法能取得更好效果,并表现出优良的鲁棒性。
2 基于关系模型的自然场景文本检测
本文设计的基于关系模型的深度学习网络结构如图1所示。
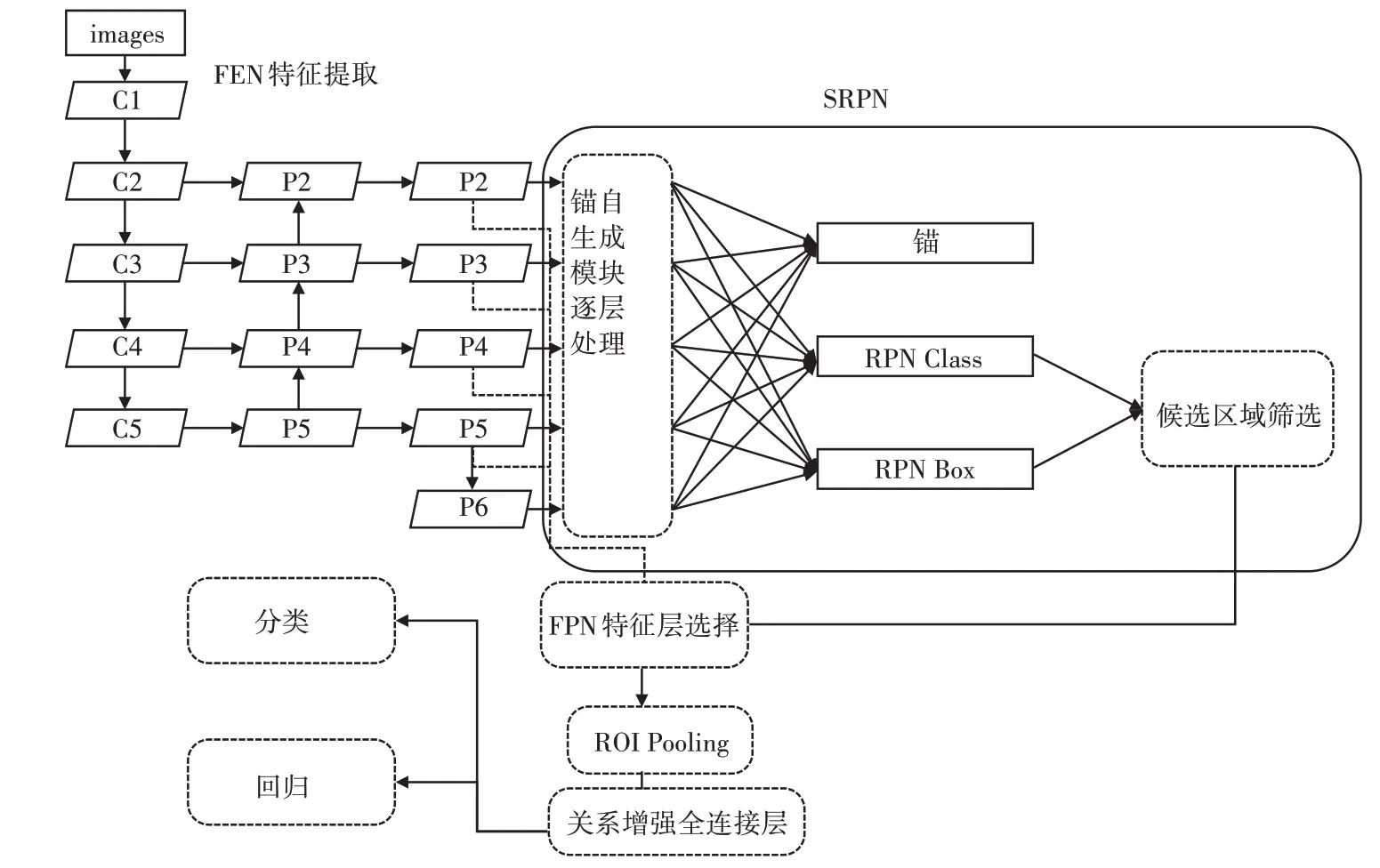
图1 自然场景文本检测网络结构图
该模型主要包括如下四个部分:
1)特征提取网络(FEN):本模型采用Resnet[13]结合FPN网络结构为基础网络来提取图像特征图。
2)候选区域生成网络(SRPN):用特征提取网络提取的特征图作为输入,通过锚自生成网络学习配置锚,然后通过候选区域生成网络检测生成文本候选区域。
3)感兴趣区域池化(ROI pooling):通过ROI 策略将上一步得到的对应候选区域的特征转为固定宽高,提供给后续网络进行分类和回归。
4)基于关系模块的增强全连接层:用来增强输出特征,通过训练关系模型得到关系模型权重,然后融合关系模型得到的特征和图片原有特征,最后输入分类和回归网络中,得到最终文本区域。
2.1 特征提取网络(FEN)
本文的特征提取网络使用ResNet101 作为骨干网络结合FPN[14]特征金字塔来提取特征图,如图1 所示。首先,通过ResNet 网络可以输出特征金字塔{C2,C3,C4,C5},它们的尺寸与输入图像尺寸的比例为{1/4,1/8,1/16,1/32}。把高层特征进行两倍上采样(最邻近上采样法),然后将其和对应的前一层特征结合(前一层要经过1 * 1 的卷积核才能用,目的是改变channels,和后一层的channels相同),结合的方式是做像素间的加法。例如在C5上进行1 * 1 卷积降通道得到P5。将P5 两倍上采样结果与C4 的1*1 卷积对应特征图结合(对应像素相加)得到P4。将迭代融合产生的特征图P1-P5再进行3*3 卷积消除上采样效应得到了特征金字塔{P2,P3,P4,P5}。然后,P5 经过MaxPooling 得到P6,这仅用在SRPN 中应对尺度特别大的情况。这样能针对不同尺度的特征图进行处理,获取结合了底层特征和高层特征的特征图。因此,可以适应不同尺度文本候选区域。
2.2 候选区域生成网络
2.2.1 锚自生成模块
候选区域生成网络(SRPN)的具体流程是将FEN 中输出的特征图先进行3 * 3 扫描,然后使用两条并行的1 * 1 卷积操作,分别用于产生前背景分类和框位置回归。前背景分类与框位置回归是在锚(anchor)的基础上进行。先定义一些框,然后在SRPN 中基于这些框进行调整。Faster R-CNN通常会预设不同尺度,不同宽高比率的锚来密集地扫描全特征图,进行后处理获得候选区域,但是存在一些问题。
为此,很多学者针对锚的设置进行了研究,文献[15]提出了一种在目标检测中能预测非固定、任意形状锚的方法,并证明其在目标检测中具有增益的效果。本文的候选区域生成网络也是通过加入锚自生成模块,能获取稀疏的、更符合文本特征宽高比例的锚,借此用来获取候选文本区域。
本文设计的锚自生成模块参照文献[15],如图2 所示。锚自生成模块分为两个分支,一个是锚生成分支,用来预测锚的位置和大小,另一个是特征映射分支,用于生成配置锚的检测文本候选区域的特征图。
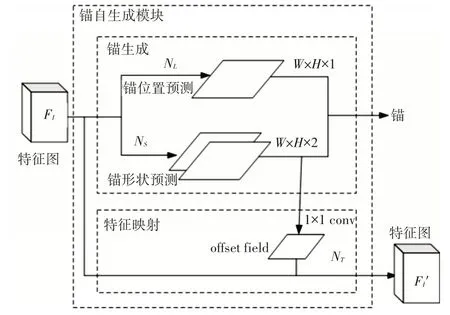
图2 锚自生成模块设计
锚自生成分支中又分为了两个子分支,一个锚位置预测子分支NL,对输入大小W×H的特征图经过1*1 的卷积得到W×H×1 的目标得分图,然后经过Sigmoid函数,可以得到每个位置的置信度,其值代表目标物的中心位于该位置的概率,用于预测锚的中心区域。另一个为锚形状预测子分支NS,输入特征图通过一个1*1 的卷积网络输出同分辨率的双通道特征图,预测锚的宽度w 和高度h。在特征映射分支NT中,首先用锚形状预测分支中获得的锚宽和高,通过1×1 卷积对每个位置预测宽高偏移量offset,形成一个偏移场。然后根据该偏移场offset field 进行3×3 的可变形卷积[16],利用原始的特征图结合offset 获得了锚自适应映射特征图【Fl'】。
SRPN 网络模型(图1)的训练损失由四部分构成,锚自生成模块中锚位置预测子分支损失(αLloc),锚自生成模块中锚形状预测子分支损失(βLshape),RPN Class 部分分类损失(Lcls),RPN Box部分回归损失(Lreg),其总体损失构成如式(1)所示:
2.2.2 RPN Class网络与RPN Box回归
在区域建议网络RPN(Region Proposal Net-work)Class 网络中,对得到的候选区域进行正负样本的分类,与Faster R-CNN 相同。正样本包括:与训练标签中的ground truth 框之间的交并比(IOU)最大的锚对应候选区域且与任意ground truth框交并比大于0.7的候选区域。负样本则包括其他候选窗口中与ground truth 框交并比小于0.3的锚对应候选区域。其他剩余的候选区域则直接排除。
训练时,SRPN 中候选区域分类置信度损失函数采用二分类交叉熵,如式(2)所示,其中y 为标签0或者1,p为模型预测输出的置信度。
SRPN 的RPN box 回归损失采用的与Faster R-CNN一致,如式(3)所示:
2.3 感兴趣区域池化(ROI pooling)
SRPN 网络提取出的候选区域大小是变化的,而Faster R-CNN 后续的分类和文本边界框回归用的全连接层的输入必须固定长度,因此本文使用ROI Pooling来解决。ROI Pooling具体操作如下:
1)根据输入图像,将ROI映射到特征图对应位置;
2)将映射后的区域划分为相同大小的切片,切片数量与输出的维度相同;
3)对每个切片进行Max Pooling操作。
这样我们就可以从不同大小的候选区域得到固定大小的特征图,最后将固定尺寸的包含候选区域的特征图分别送入两条全连接层支路进行分类和回归。
2.4 基于关系模块的增强全连接层
本文采用如图3 所示的关系模型[11]来建立候选区域目标之间的关系,以提高文本检测的效果。关系模型以注意力形式将关系特征融合进原有的特征中,用于分类和回归。
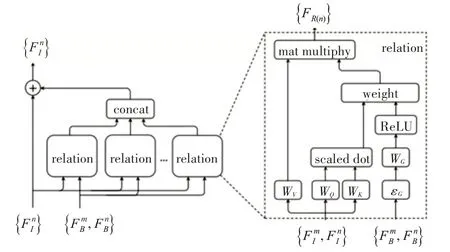
图3 关系模型示意图
目前注意力模型在自然场景文本检测中逐渐得到应用[18]。注意力机制(Attention)粗略来说是根据预设的查找(Query)和键值表(Key-Value Pairs),计算其相关程度(关系)来将Value映射到正确的输出的过程。Attention的计算过程如下:
1)计算比较Query 和所有假设n 个Key 之间的关系相似度f,这可以表示为点乘:
2)将得到的相似度进行Softmax 操作,归一化得到查询和对应键的权重:
3)针对计算出来的关系权重,对所有的Value进行加权求和计算,得到Attention Value向量:
Attention 机制采用Scaled Dot-Product Attention 模型和Multi-head Attention 模块[11]进行上述计算。
3 实验结果与分析
ICDAR2013 和ICDAR2015 是自然场景文本检测的常用数据集,本文在两种数据集上验证基于关系模型的场景文字检测方法。ICDAR2013 总共462张图片,分为229张训练图片,233张测试图,该数据集涵盖了不同尺寸,不同光照,不同颜色的文本图像。ICDAR2015 总共1500 张图片,分为1000张训练图片,500 张测试图,该数据集拍摄的终端不一,有相当部分来自于手机,分辨率非常低,背景十分复杂。本文在两个数据集上,对基于关系模型的深度学习网络模型进行了实验,部分检测效果如图4 所示,从视觉检测效果上看,本文的方法具有较好的检测结果。

图4 基于关系模型的场景文本检测效果图
3.1 实验分析
本文在数据集上对本文提出的基于关系模型的检测方法和原始的Faster RCNN 进行对比,部分实验结果对照如图5所示。

图5 两种检测方法检测效果对比图
从图中可以看到,本文提出的基于关系模型的场景文本检测模型在文本区域检测效果上明显优于未加入关系模型的Faster-RCNN网络。
3.2 本方法与其他文献方法对比
本文在ICDAR2013 上与其他自然场景文本检测算法的对比结果如表1所示。
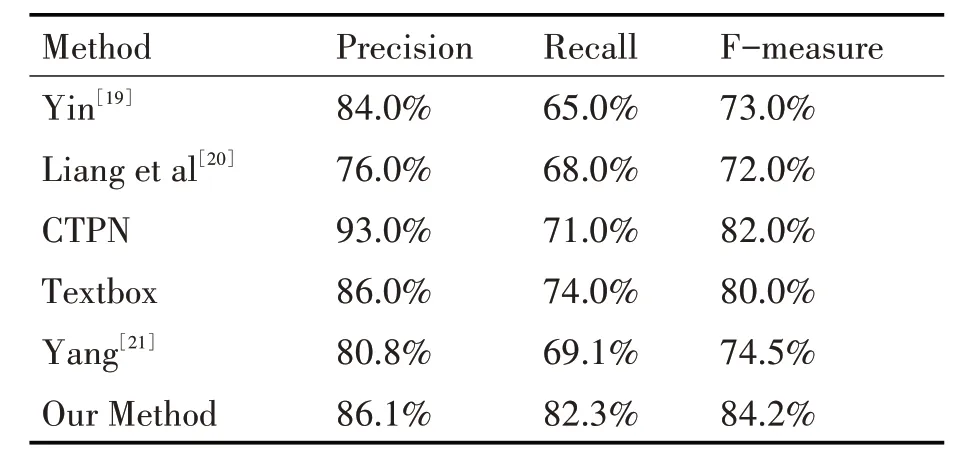
表1 Results on ICDAR2013 datasets
如表1所示,在ICDAR2013数据集上本文的文本检测算法Precision和Recall分别达到了86.1%和82.3%,F值达到了84.2%。与传统的自然场景文本检测方法如Yin[19]的自适应聚类方法,Liang et al[20]采用的MERS+SWT 方法相比,本文的检测方法Precision,Recall,F 值均得到了提升。与同样采用滑动窗回归的Textbox 相比,本文的检测方法的Precision,Recall,F 值也明显提升。与目前水平文本检测的流行算法CTPN 相比,本文的文本检测算在Recall 和F 值两项指标上提升,但是在Precision上还有一定差距。与Yang 的语义分割方法相比,本文的方法在Precision,Recall,F 值均得到了提升。从总体上来看,本文的检测方法在数据集上达到了较好的水平。
在ICDAR2015 上与其他自然场景文本检测算法的对比如表2 所示。本文检测算法的Precision和Recall 分别达到了77.3%和74.2%,F 值达到了75.7%。与Zhang et al[22]和CTPN 相比,本文的Precision和Recall,以及F值都得到了提升。本文算法与Seglink[23]相比,Precision 和F 值都有改进。本文算法和SSTD相比Recall更好,F值接近,Precison稍差。与Yang 的语义分割方法相比,本文的Recall接近,Precison 略低,F 值稍差。从总体上看,本文的算法具有较好的性能,可以视为一种自然场景文本检测的可行算法。

表2 Results on ICDAR2015 datasets
4 结语
本文提出了基于关系模型的场景文本检测方法,该方法利用加入锚自生成网络的区域生成网络获得文本候选区域,融合关系特征去准确提取文字区域。实验发现,与其他方法比较,该模型被用于自然场景文本检测时具有较好的检测效果,同时具有一定鲁棒性。在试验中我们发现虽然本方法提出的自然场景文本检测方法具备了不错的性能,进一步需要研究的问题包括:1)曲形文字检测;2)带方向的文本框表示方式等。
