交互效应面板分位数回归模型的迭代估计
2023-07-21常金华童之瑶叶小青
常金华,童之瑶,叶小青,姚 乐
(1.中南财经政法大学 统计与数学学院,武汉 430073;2.中南民族大学 数学与统计学院,武汉 430074)
0 引言
分位数回归可以刻画因变量τ分位数与自变量的关系,对因变量在整体分布上的回归关系有了更为清晰的解释;在参数求解中,分位数回归的损失函数为误差项的绝对值加权之和,对异常值的敏感程度大大降低,回归结果更为稳健。自从Koenker 和Bassett(1978)[1]提出这一思想后,有关分位数回归的理论与实证研究迅速发展。
传统的分位数回归模型主要基于截面数据进行研究,研究主要集中于估计量的渐近分布、参数检验、置信区间的理论框架等[2]。具体来看,一是研究估计理论[3—5];二是研究非线性分位数回归模型[6—8];三是研究分位数回归模型的不同算法[9,10]。近年来,随着面板数据集的广泛使用,关于面板数据回归模型的文献大量涌现,面板模型最大的优点是可以控制不可观测的异质性。一般情况下,异质性被假定以加法形式引入面板分位数回归模型[11]。对于这类模型,王娜和任燕燕(2017)[12]针对具有随机效应的面板分位数模型提出了带有Copula 相关结构的极大似然估计法。Li 等(2019)[13]则在通过引入工具变量进行分位数回归来估计自变量的基础上,将该方法扩展到具有固定效应的动态面板分位数模型。罗幼喜和田茂再(2010)[14]通过蒙特卡洛模拟比较讨论了固定效应面板数据模型一阶差分、固定效应变换和惩罚分位数三种分位数回归方法,结果表明分位数回归方法是处理面板数据的一种有效手段。而两阶段(Two-Steps)面板数据分位数回归法对用数据转换方法来剔除面板分位数模型中的固定效应这一问题进行了补充。张元杰和田茂再(2015)[15]基于之前的研究提出了两阶段K步差分分位数回归方法,并推导了该固定效应面板数据模型分位数估计量的大样本性质。针对含有内生变量的面板模型,也有部分研究先消除个体效应项再引入工具变量。
但当存在截面相依性时,将异质性以加法形式引入可能会导致错误的结论,甚至是不一致的估计。如果自变量与导致截面相依性的未观测到的共同因素相关,那么传统的面板估计量可能是不一致的。带交互效应的面板数据模型能解决这一问题,因为与传统的面板数据模型相比,它可以更灵活地对不同个体和不同时间的异质性进行建模,并为截面相依性建模提供了一种有效的方法,而且这种模型设置也消除了偏差的来源。事实上,交互效应的因子结构具有足够的通用性,并使传统的个体和时间效应成为一种特例,例如,当Λi=(αi,1)′,Ft=(1,θt)′时,可得到Λi′Ft=αi+θt。交互效应的设定对现实拥有更强的解释能力,例如,在宏观经济学中,单个国家的经济增长率可能取决于世界范围内的供给冲击Ft(如石油冲击、技术冲击等),而共同的冲击通过不同的因子载荷Λi在各国之间产生异质性影响。在劳动经济学中的明瑟方程中,Λi是不可观测的个人特质向量,如天赋、技能,而Ft反映了个人特质的时间变化的回报。在教育经济学中,当考虑班级规模和社会经济阶层构成对教育程度的影响时,Λi可能与学生听课或阅读时的动机和吸收知识的能力有关,而Ft可以解释为教师质量[16]。
基于此,本文构建了带交互效应的面板分位数回归模型,并构建参数估计量。与本文最为相似的是Harding 和Lamarche(2014)[16]的研究,在Harding 和Lamarche(2014)[16]的估计方法的基础上,Kaplan(2022)[17]将工具变量分位数回归估计应用于带有个体和交互效应的面板数据模型中。相比其他方法,该方法的估计量具有偏差和RMSE小的优点,但是其估计量方差较大,一定程度上破坏了模型的适用性。此外,当处于个体效应与回归自变量相关的特定条件下时,该估计方法就会失效。
为了解决这一问题,本文提出了一种迭代方法来估计具有个体效应和交互效应的面板分位数回归模型,并且允许个体效应存在强内生性,即当Harding 和Lamarche(2014)[16]所提出的方法失效时,本文的估计方法依然可行。并用蒙特卡洛模拟检验本文提出的估计方法在有限样本中的表现,然后与其他估计方法进行比较。此外,利用该估计方法实证研究我国的房地产市场,进一步揭示高房价地区与低房价地区不同的规律特征[18,19]。
1 交互效应面板分位数模型及估计方法
1.1 模型介绍
考虑以下模型:
其中,Yit是因变量;Dit是K1×1 可观测内生独立自变量,其回归系数α(K1×1)未知;Xit是K2×1 可观测外生独立自变量,其回归系数β(K2×1)未知;εit具有误差因子结构;Ft(r×1)为r个共同因子,其载荷系数Λi(r×1)未知;uit是不可观测的异质性残差。该模型可以推广到更一般的具有异质性效应的面板数据模型。
可观测内生变量Dit可以被表示为:
其中,ηit为独立同分布随机序列,且与uit相互独立。该生成方式表明,Dit与外生变量Xit和交互效应相关。
先考虑最简单的随机系数模型,其表示形式为:
其中,τ为分位数,位于(0,1)区间内;QYit(τ|Dit,Xit,Ft)为给定Dit、Xit和Ft条件下的Yit的第τ分位数。
再考虑当Ft=(ft′,1)′和Λi=(λi′(τ),ui(τ))时,上述模型可以退化为具有个体效应和交互效应的分位数回归模型。可得:
其中,ui为个体效应。
1.2 模型估计方法
当N较大时,包含大量未知参数的优化问题,往往计算十分麻烦,甚至难以解决。对此,Galvao和Wang(2017)[21]提出对每个个体进行分位数回归,并针对固定效应面板数据模型建立了一个最小距离分位数回归估计量。在带个体效应和交互效应的分位数回归模型中,由于每个个体的λi和μi不同,导致需要估计的参数更多,因此,对该模型的估计本文借鉴序列分位数回归的方法。同时,将面板数据转换为N个时间序列的估计方法也简化了个体效应和迭代效应的识别,本文借鉴Chen 等(2021)[20]提出的PC方法来估计共同因子。
给定对(τ)和Ft的估计量,对每个i的α和β的个体估计量为:
其中,ρτ(u)=u(τ-I(u≤0))是标准分位数损失函数,为使用个体i时间序列数据的序列分位数回归估计值。
给定ft,Ft的估计为=(,1)′,其因子载荷Λi=(λi′(τ),ui(τ))的估计量为最小化标准分位数损失函数的解:
给 定(τ) 和,通 过 更 新 矩 阵W来 更 新{(τ),(τ)} 和。给定更新后的,进一步通过式(8)更新(τ)。重复上述步骤,对式(6)和式(8)进行迭代,直到(τ)收敛。
注意到式(6)进行迭代的第一步需要对个体效应和交互效应进行初始赋值,本文采用了Bai(2009)[22]的研究中的迭代方法,将均值回归的个体效应和交互效应估计值作为初始值。
迭代结束后,可获得对Λ(τ)Ft的一致估计。最后,α(τ)和β(τ)可通过最小化标准分位数损失函数来估计:
在给定条件分位数QYit(τ|Dit,Xit,Ft)时,参数α(τ)和β(τ)可识别,并且当N,T→∞时,估计量为一致估计量。
为了进一步通过迭代最小化式(9)的目标函数,通过W更新,基于更新(τ):
重复上面的步骤,在式(9)和式(10)的基础上进行迭代,直到收敛。最后一步迭代是为了提高效率,减少该估计量的方差。
如果能通过PC 方法一致估计ft,最小化式(6)和式(8)可以被看作是没有时间效应的时间序列的标准分位数回归。在这种情况下,加上条件分位数Quit(τ|Dit,Xit,λi,Ft)=0 的假设可以识别每个时间序列的参数。而且当T →∞时,每个个体i 的分位数因子载荷(τ)都可以被一致地估计。此外,估计量也是一致的。因此,进行式(9)的最后一步,在给定Λ(τ)Ft的一致估计时,根据条件分位数Quit(τ|Dit,Xit,λi,Ft)的限制,识别参数{α ,β} ,并且当N,T →∞时,该估计量是一致的。
需要注意的是,本文对于交互效应的估计参考了Chen 等(2021)[20]的设计,需要遵循一个重要假设,即所有的共同因子都可以通过PC 方法提取出来。但由于PC 方法只能估计为均值漂移的共同因子,所以该估计方法要求使Y 的分位数变化的共同因子也是Y 的均值漂移,因此必须为渐近满秩的。例如,如果Λri(wit)为零,或者服从零均值的t分布,本文的迭代估计方法会因为PC方法不能估计第r 个因子而失败。
总体而言,本文方法的创新点有:(1)本文与Harding和Lamarche(2014)[16]的研究的本质区别在于,估计交互效应的方法不同。对于因子ft,Harding 和Lamarche(2014)[16]选择了CCE估计方法,而本文使用了PC估计方法;对于因子载荷,Harding 和Lamarche(2014)[16]一次估计了包含所有个体的(τ)矩阵,而本文依次估计了各个体的Λ^i(τ),因此本文不需要假设Λi独立同分布,所以本文方法的适用性更强。(2)由于(τ)包括了个体效应,与Harding 和Lamarche(2014)[16]的研究相比,本文的迭代算法能允许多种形式的个体效应,并且允许个体效应具有内生性,方法的适用范围更为广泛。(3)在传统的交互效应假设中,当Λi的元素为常数时,(τ)就等于Λi。此时,估计量(τ)实际上是Λi的估计。而Harding 和Lamarche(2014)[16]在利用(τ)对Λ 的第τ 个分位数进行估计时,实际上忽略了个体之间的异质性。因此,本文方法更适用于交互效应面板分位数回归模型,在有限样本中的表现也更好。
2 蒙特卡洛模拟
通过对本文的迭代估计量与Harding 和Lamarche(2014)[16]的估计量进行对比,进一步明晰迭代估计量的创新之处与优势所在。
Harding 和Lamarche(2014)[16]提出的估计量简称为QRIIE 估计量,且已通过蒙特卡洛模拟说明了QRIIE 估计量远远优于其他现有方法,所以本文旨在对迭代估计量(Iterative Estimator for Quantile Regression,简称为IEQR)与QRIIE进行比较。数据生成过程与Harding和Lamarche(2014)[16]的研究类似。
其中,β1=β2=1 ,ρf=0.90,ρη=0.25,h 表示内生变量dit系数的标准差,xit是外生变量。误差项uit,vit,ηit和ejt均为相互独立的高斯随机变量,ςit~N(1,1)且与其他所有变量均参考Harding 和Lamarche(2014)[16]的设定,因子载荷λ1i和λ2i服从N(1,0.2)。在所有模拟设计中,设定π1=0.3;内生变量dit与外生变量xit、因子载荷λi、共同因子ft和交互效应λift均相关,且设定π2=π3=π4=0.1。
模拟过程中,个体固定效应和个体随机效应两类应均有涉及。设计1至设计3为包含个体随机效应和交互效应的分位数回归模型,而设计4至设计6则为包含个体固定效应和交互效应的分位数回归模型。个体随机效应μi服从标准正态分布。蒙特卡洛模拟重复次数设定为1000次。
设计1:类似于Harding 和Lamarche(2014)[16]的设定,令h=0.1,因此β1表示一个位移尺度漂移。
设计2:令h=0.5,此时,与设计1 相比,内生变量dit系数的方差更大。
设计3:令uit~exp(1),即内生变量dit系数服从指数分布而不是高斯分布。
除了个体效应被设定为固定效应外,设计4 至设计6与设计1 至设计3 一致。个体固定效应μi的数据生成过程为:
其中,令γ=2,且个体效应与内生变量dit相关。
下页表1 展示了在个体随机效应下,设计1 至设计3中斜率系数β1估计量的偏差和均方根误差(RMSE)。设定τ={0.25,0.90},N={200, 500}和T={10,30,50} ,IEQR为本文的估计结果,而QRIIE 为基于Harding 和Lamarche(2014)[16]的方法的估计结果。
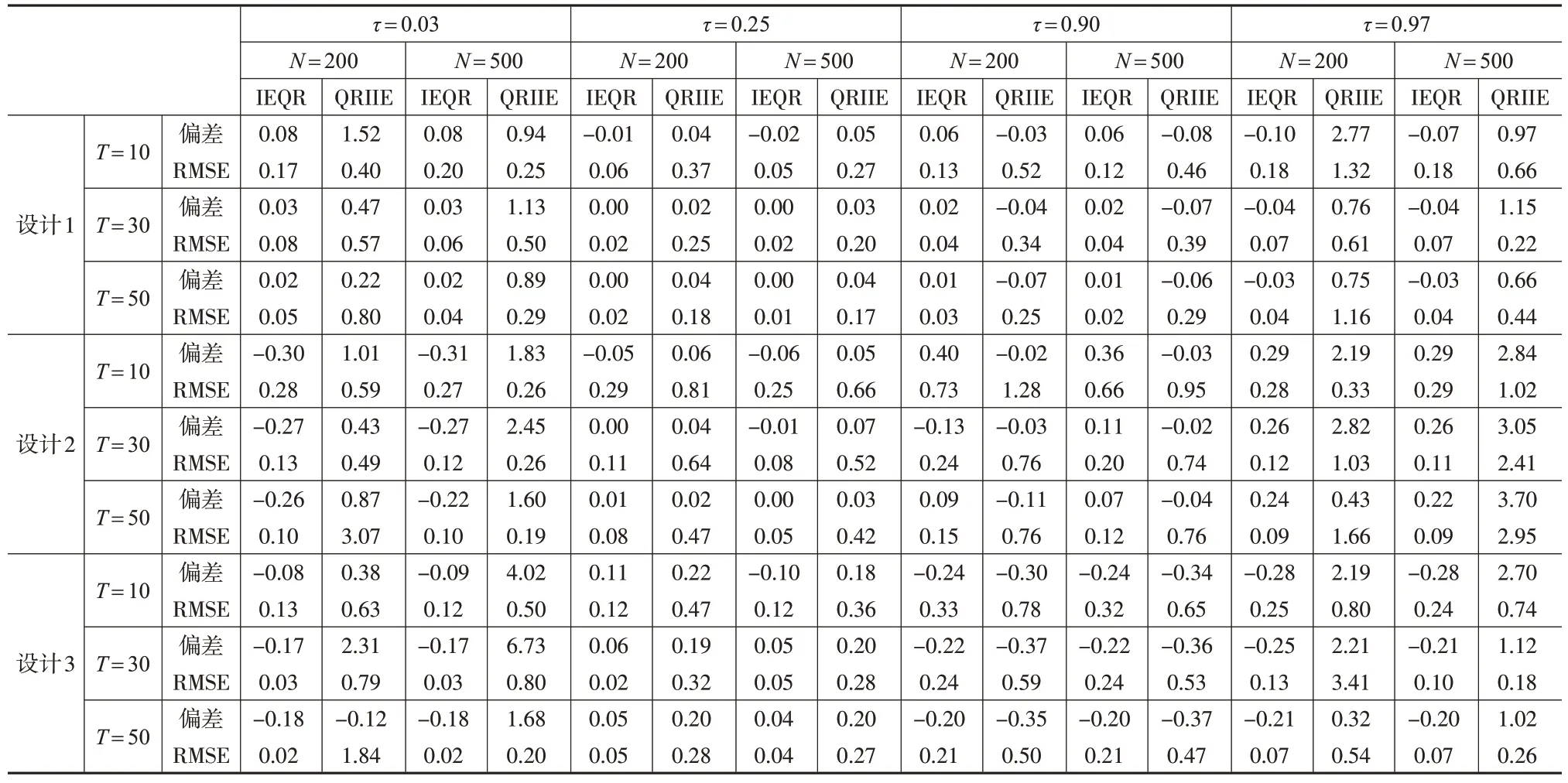
表1 具有个体随机效应和交互效应的分位数回归模型
从表1中可以看出,这两个估计量在有限样本中均表现良好,而且随着N 和T 变大,偏差和RMSE 均显著降低,这意味着在大样本下这两种方法均适用。然而,通过比较QRIIE 与IEQR 的偏差和RMSE 可以看出,本文提出的估计量的偏差要小得多,这可能是因为IEQR 估计的是Λi(τ),而不是Λ(τ)。
根据下页表2,当个体效应与回归自变量相关时,本文估计量IEQR 的RMSE 依然随着N 和T 的增加而显著减小。然而此时QRIIE估计失效,随着N 和T 的增加,估计偏差只略微减小。除此之外,设计5和设计6的模拟结果表明,IEQR 估计并不依赖于其系数的分布,说明IEQR估计方法不需要满足系数对称分布的假设。从模拟结果可以看出,在极端分位数下,相对于QRIIE,IEQR 的偏差和RMSE均更小,进一步体现了本文迭代算法有更好的有限样本性质,适用性更强。
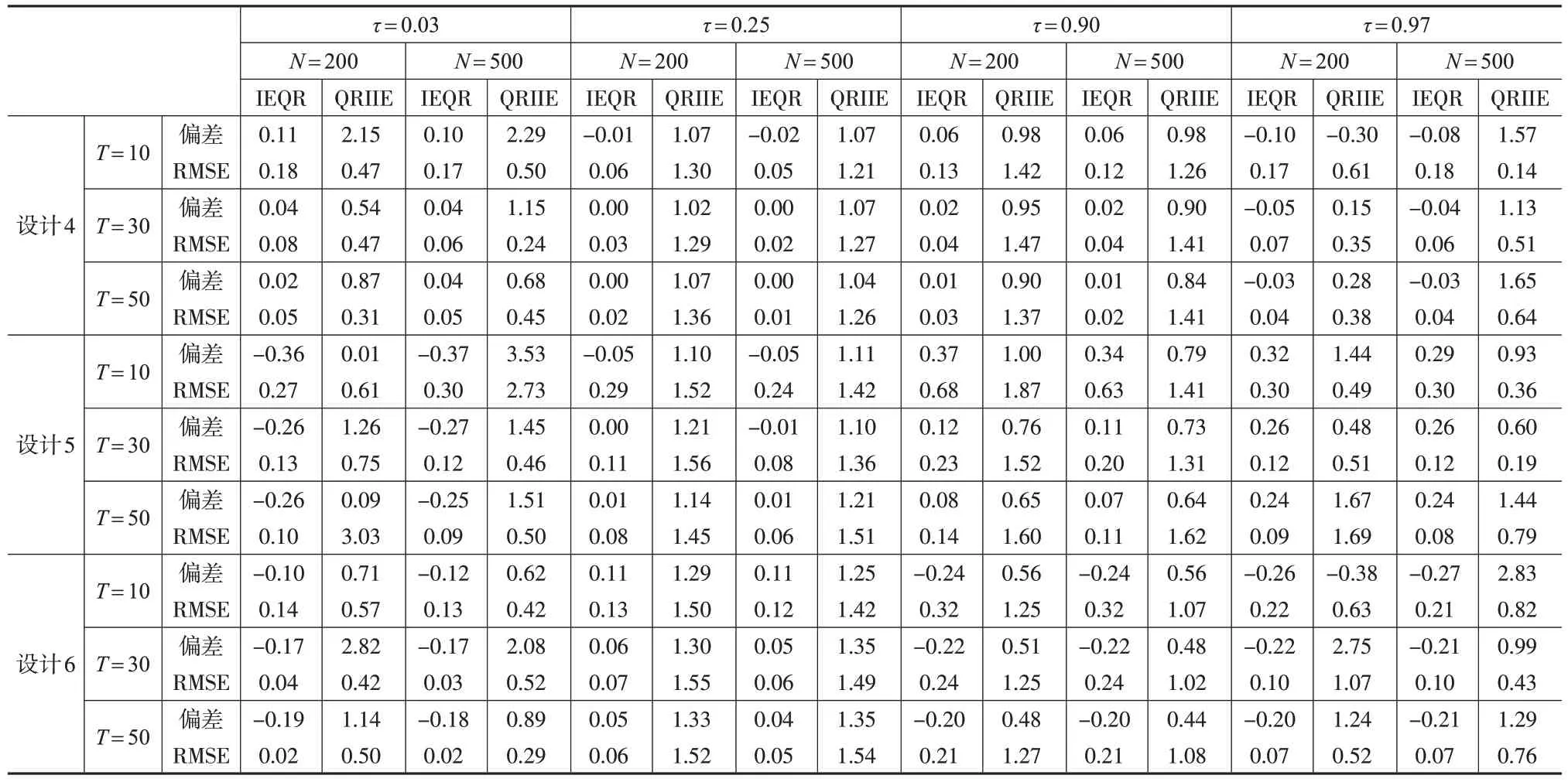
表2 具有个体固定效应和交互效应的分位数回归模型
本文进一步验证设计1中IEQR系数的估计量是否具有与标准正态分布一致的偏度和峰度,为此进行Jarque-Bera检验,结果如表3所示。

表3 Jarque-Bera检验结果
从统计结果可以看出,对比情景1和2、3和4可得,当N增大的时候,JB 统计量的值减小了;对比情景1 和3、2和4 可得,当T增大的时候,JB 统计量的值减小了。综合来看,可以发现JB 统计量的值随着N和T的增大而减小。这表明:随着样本量的增加,估计量服从正态分布的原假设越来越不能被拒绝。JB统计量的值随着样本量的增加而减小,说明了估计量分布的渐近正态性。
3 实证分析:房价的影响因素
3.1 模型构建
本文以房价问题为例,实证检验各影响因素对不同城市房价的影响程度,以便为不同发展阶段的城市的房价调整政策提供依据。
本文选取了我国的264个城市,利用其2008—2019年的房价(pri)数据对影响中国房价的因素进行实证分析。参考洪勇(2020)[23]的研究,本文考虑从房地产市场的供给和需求两个方面来选择房价决定因素。在需求方面,考虑陈艳如等(2021)[24]提出的三个主要因素:经济发展水平(gdp)、人民生活水平(inc)和人口数量(pop)。在供给方面,考虑洪勇(2020)[23]选择的两个主要因素:房地产投资(inv)和货币条件(loa)。针对以上指标,本文中采用GDP 来衡量经济发展水平,用人均可支配收入来衡量人民生活水平,用人口密度来衡量人口数量。此外,用住房建设投资来衡量房地产投资,货币条件则用贷款余额来衡量。
据此建立的房价决定模型如下:
其中,μi是个体效应,Yit表示房价,Xit为各影响因素,β衡量的是Xit中各变量发生变动时对房价Yit产生的影响,uit表示除了自变量之外的其他影响房价且无法观测的因素。
3.2 样本数据
由于大多数城市在2008 年之前的房价数据无法获得,因此本文的样本起始年份为2008 年。为减少异方差的影响,对原始数据取自然对数。房价数据来自城市住宅数据库,而其余指标数据均来源于国泰安数据库。gdp、inc、inv、loa指标均已按2008年的价格进行了平减。
表4 展示了各变量的描述性统计结果。房价的差异十分显著,房价最低为每平方米1700元,而最高为每平方米63500 元。此外,房价的0.90 分位数为10000 元/平方米,表明只有少数城市的房价偏离了平均水平6100 元/平方米,说明房地产市场上可能存在非理性行为。尽管如此,由于分位数回归对非正态分布与高偏度具有稳健性,因此这些性质并不影响模型设定。
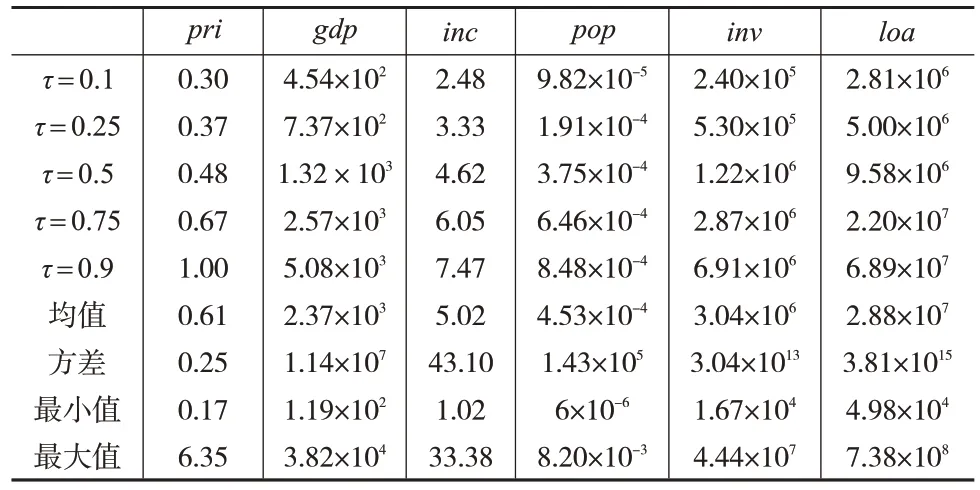
表4 主要变量的描述性统计
3.3 实证分析
在进行回归前,先进行面板单位根检验,结果如表5所示。

表5 Levin-Lin-Chu面板单位根检验结果
根据表5 可知,所有的变量均是平稳的,因此可进行分位数回归。回归结果如表6所示。
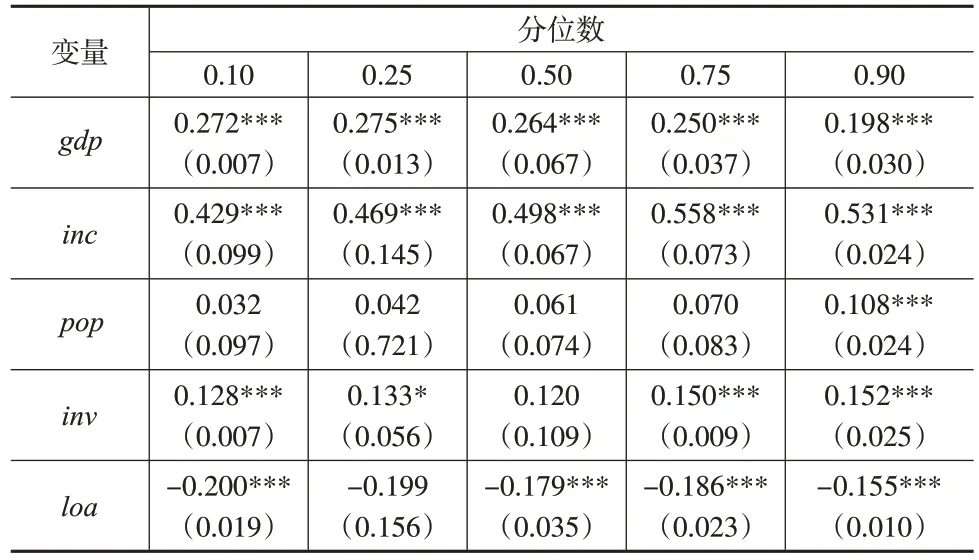
表6 房价的决定因素
表6 展示了在0.10、0.25、0.50、0.75、0.90 分位数的回归估计值。其中,0.10分位数与0.25分位数代表的是房价相对较低的情况;0.50分位数的房价代表了所有城市房价的平均水平;0.75 与0.90 分位数则代表了房价较高的情况,分位数回归结果反映了不同位置各因素对房价的边际影响。例如,当房价处于低水平时,GDP、人均可支配收入、人口密度、住房建设投资的增加均会导致房价上升,其中人均可支配收入的增加对房价上涨的促进作用最为显著。在0.50分位数上,GDP与住房建设投资的影响明显下降。而在高房价地区,住房建设投资会推高房价。
表6的结果显示,经济发展水平越高,房价就越高,但随着分位数的增加,经济发展水平对房价的影响先增强后减弱,其原因是在经济发展水平较低的地区,房地产行业也未得到充分的发展,居民对住房的需求没有得到满足,因此随着经济发展水平的提高,GDP对房价的影响逐渐增大,而当经济发展达到一定水平之后,居民对住房的需求已经得到保障,此时,经济发展水平虽然对住房价格仍然有促进作用,但影响力明显降低。人均可支配收入的提高也会促进人们对住房的需求,从而导致房价上涨,与经济发展水平类似,随着分位数的增加,人均可支配收入对房价的影响先上升后下降。
与预期的系数方向一致,人口密度的增加会导致房价上涨,且随着分位数的增加,人口密度对房价的影响逐渐增强。这表明,房价从低到中高水平,人口密度都对房价起着促进作用,这一结果也符合供需规律,即人口数量的增多会导致住房需求增加,而需求的增加会拉动房价上涨。对于住房建设投资,其数值的增加也会导致房价上涨,且从低房价到中高水平房价的地区,住房建设投资对房价上涨的促进作用逐渐下降。然而在房价较高的情况下,投资对房价的影响系数又上升到0.152。这与在我国房地产市场上观察到的市场追逐现象一致——在房价较高的地区,投机需求相对较高。
贷款余额对房价存在负向效应,即贷款余额的增加会导致房价下跌。一种解释为:一般贷款余额的增加说明此时为宽松的货币政策,融资成本相对较低,因此房价也会相对下降。此外,随着房价分位数的上升,这种影响会逐渐减弱。
综上所述,高房价地区的房地产市场表现出与其他地区不同的特点。在房价高的地区,经济发展水平和人均可支配收入对房价的影响下降,而住房建设投资对房价的影响却相对上升。为保持房地产市场的健康发展,应采取一定的政策,抑制投机因素,防止房价飙升。
4 结论
本文提出了一种迭代方法对具有个体效应和交互效应的面板数据模型进行分位数回归估计,创新点在于,本文考虑的是带交互效应的面板分位数回归,能反映不同个体对共同因子的敏感度差异,而且本文提出的方法允许个体效应和交互效应与自变量相关,更好地解决了个体效应的内生性问题。蒙特卡洛模拟结果表明,相对于目前最优的Harding 和Lamarche(2014)[16]所提出的交互效应的分位数回归估计量QRIIE,本文的迭代估计量(IEQR)表现更好。值得注意的是,QRIIE在个体固定效应具有内生性时会失效,而本文的迭代估计量能解决这一难题,在个体固定效应具有强内生性时,IEQR 依然可以进行准确地估计。最后,用IEQR估计了房价决定因素的影响效应,发现房价决定因素的影响效应存在异质性。
