基于深度学习的日间逐小时地表PM2.5浓度反演
2023-07-17徐成康陈斯婕董长哲徐文韬
徐成康,陈斯婕,董长哲,徐文韬,刘 东
(1.浙江大学 光电科学与工程学院,浙江 杭州 310027;2.上海卫星工程研究所,上海 200240)
0 引言
PM2.5即空气动力学直径小于2.5 μm 的细颗粒物,又被称为可入肺颗粒物,是空气污染雾霾危害中的主要成分之一,对气候、环境和人类健康有极大的危害[1]。目前,我国已形成系统化的地面空气质量监测体系,能够对PM2.5、PM10、一氧化碳、二氧化硫、二氧化氮和臭氧等主要污染物进行实时精确监控。但地面监测站点缺乏区域覆盖能力,且分布不均,无法对各类污染物的分布及相互作用过程进行有效的追踪分析和预测,而星载遥感观测具有全天时、高覆盖等独特优势,在大气状态监测领域中被广泛应用。如美国航空航天局(National Aeronautics and Space Administration,NASA)的TERRA 和AQUA 两颗卫星上的中分辨率成像光谱仪(Moderate Resolution Imaging Spectroradiometer,MODIS),在全球气溶胶观测上取得了巨大成功[2]。
目前已经有相关研究将星载传感器反演的气溶胶光学厚度(Aerosol Optical Depth,AOD)通过经验或半经验统计、地理加权回归、化学传输模式算法等方法反演地表PM2.5浓度[3-5],但仅通过被动遥感数据反演PM2.5精度较低。星载被动遥感手段能够进行超大范围颗粒物柱总量探测,但一定程度上受限于其垂直探测能力及光照条件,导致观测结果较粗糙,而地面空气质量监测体系具有全天时高效探测近地表颗粒物浓度的能力[6]。因此,本文通过神经网络结合星载遥感数据、地表测量数据和其他辅助数据来反演估计PM2.5,能够提高观测范围和预测能力,为相关科研目标及政策实施提供便利。随着卫星平台和遥感观测仪器的高速发展,使在卫星上搭载的先进遥感仪器进行宏观大气状态观测和源汇分析是必然的趋势。
1 研究区域与数据来源
1.1 研究区域
研究区域为长三角地区,以杭州市国家基准气象站为中心,地理位置如图1 所示。长三角地区远离中国西北部的天然沙尘源,地势平坦植被多,基本不存在沙尘长距离传输[7]。从地理上看,长三角(30°~33° N,119°~122° E)是长江与钱塘江形成的天然冲积平原,工农业十分发达,且人口稠密,上海、南京、杭州等特大城市均位于该区域。图1 中标注了杭州市国家基准气象站的位置,本研究使用的雾霾层高度(Haze Layer Height,HLH)由该站点的地基微脉冲激光雷达(Micro-Pulse Lidar,MPL)数据计算得到。图1 同样标注了该区域内空气质量指数(Air Quality Index,AQI)站点的位置分布,是PM2.5实测数据的数据来源。在研究时间上,覆盖了从2017年1月—2020年5月共3.5a的时间。
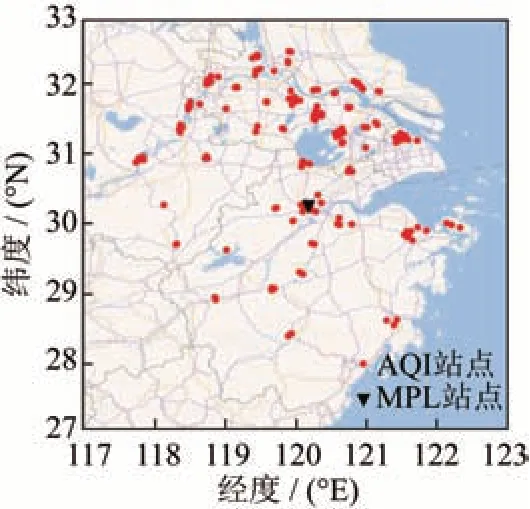
图1 研究区域及MPL/AQI 站点分布Fig.1 Studied area and the locations of the MPL/AQI stations
1.2 地基数据
本文使用的PM2.5浓度数据来自于AQI 站点,在研究区域内共计有182 个站点,所采集的数据包括站点每小时及24 h 滑动平均的PM2.5浓度数据,HLH 数据从杭州市国家基准气象站点数据中计算得到。在将AOD 通过经验公式转化为PM2.5浓度的过程中,混合层高度(Mixing Layer Height,MLH)作为转换中的比例因子是一个关键参数。AOD 是垂直方向的气溶胶光学总量,MLH 是近地面的气溶胶混合高度,在没有上层传输的情况下(且绝大部分为细颗粒物),可以认为AOD 和PM2.5成正比,HLH 的高度和PM2.5浓度成反比[8]。在理想状态下,边界层高度(Boundary Layer Height,BLH)可视为混合层高度,但实际中气溶胶并不是总局限在边界层以内,且在边界层内分布也不均匀,因此使用BLH 替代MLH,将柱AOD 转化为地表PM2.5会有显著的误差,需要合适的校正方法来提高PM2.5浓度估算的准确性[9-10]。已有相关研究使用梯度法从微脉冲激光雷达廓线中计算BLH 并转换为HLH,该方法充分考虑了边界层以上的气溶胶,能够有效校正偏差,提高反演准确性[11-13]。
利用地基站点的监测数据来验证AOD-PM2.5的估算准确率,并使用HLH 标准化来代替传统的AOD/BLH 标准化,进一步改善估算的结果。如图2(a)所示,无法直接从AOD 与PM2.5浓度变化中提取两者的关系,因此通过计算皮尔逊相关系数平方(R2)来计算特征相关性,进一步分析HLH 的相关性及相较于BLH 的进步。比较图2(b)、图2(c),分别对应AOD/BLH 与PM2.5的浓度相关性及AOD/HLH 与PM2.5的浓度相关性,同时考虑相对湿度(Relative Humidity,RH)对PM2.5浓度探测的影响,通过计算吸湿增长因子f(RH)进行PM2.5校正,校正后两者的R2分别为0.17 和0.41,明显提升。
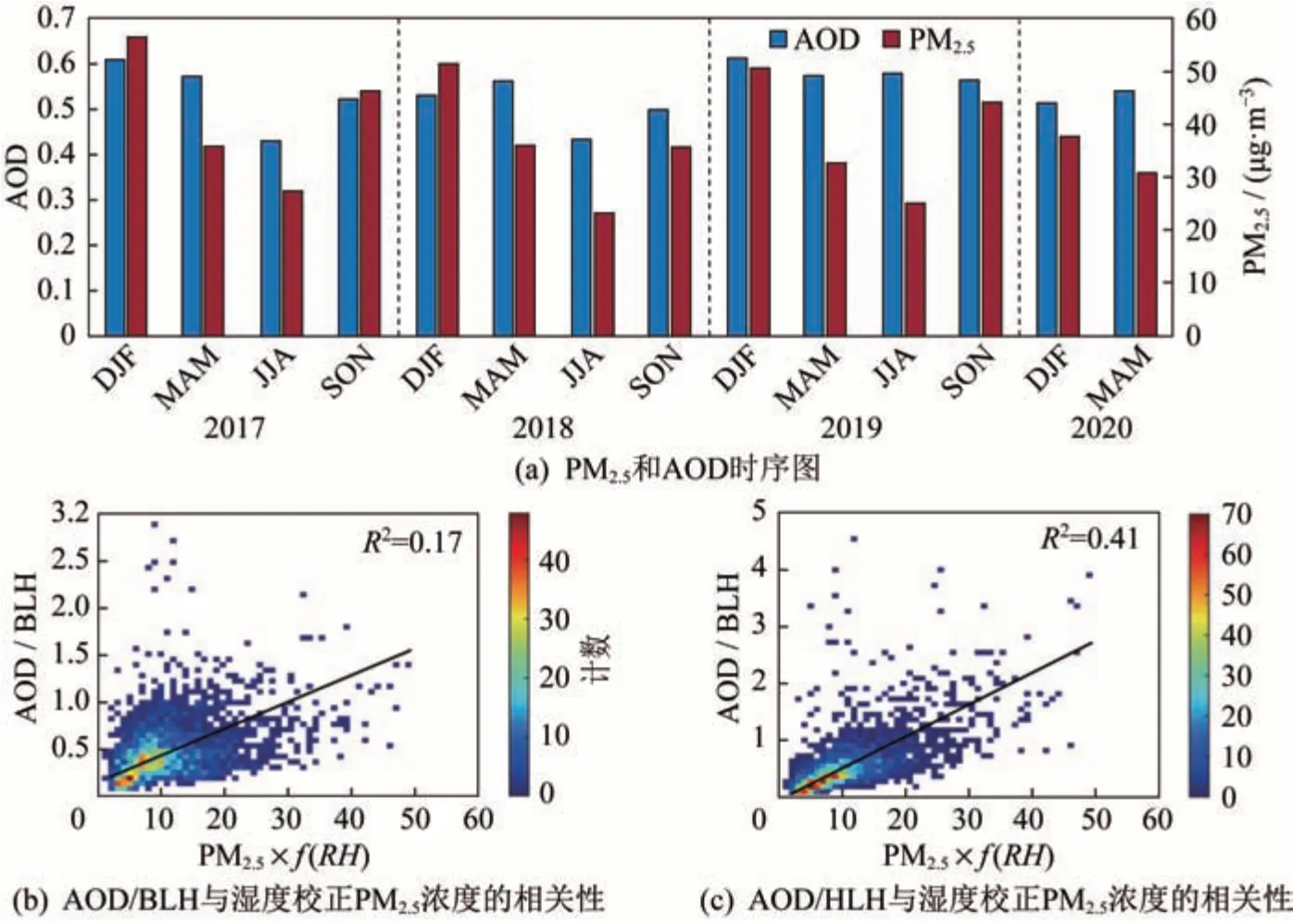
图2 AOD 和PM2.5时序图及相关性比较Fig.2 Time-series diagram and correlation comparison of AOD/PM2.5
1.3 AOD 与气象数据
遥感AOD 数据来自NASA 的MODIS 传感器公开数据。MODIS 是搭载在TERRA 和AQUA两颗卫星上的MODIS,覆盖了0.4~14.4 μm 光谱范围,分辨率最高达250 m[14]。本研究使用的数据产品为MODIS 多角度大气校正算法(Multi-Angle Implementation of Atmospheric Correction,MAIAC)产品,编号MCD19A2。MAIAC 产品为MODIS 观测结果通过算法反演得到的1 km 空间分辨率的AOD 数据,使用了改进的光谱表面反射算法来确保AOD 反演的准确性[15]。
由于星载AOD 数据受到云和地表特征的影响,存在较多无效值,需要模型AOD 数据辅助,并通过神经网络对MAIAC AOD 数据进行填补。采用的AOD 模型数据来自于为戈达德地球观测系统(Goddard Earth Observing System Model,GEOS)模型,数据产品为GEOS5 FP 2 d 时间平均初级气溶胶诊断(Time-Averaged Primary Aerosol Diagnostics)空间分辨率为0.25°×0.312 5°,时间分辨率为3 h[16]。其他气象数据来自于欧洲中期天气预报中心(The European Centre for Medium-Range Weather Forecasts,ECMWF)的再分析数据(ECMWF Reanalysis v5,ERA5),该数据库提供了从1979 年起,大气、陆地和海洋气候变量的每小时估计值[17]。本文主要使用了ERA 5 数据库中的单层和气压分层数据中的地表温度、湿度、压强、风速和边界层高度数据,其空间分辨率为0.25°×0.25°,时间分辨率为1 h。
2 研究方法与模型
2.1 机器学习模型
支持向量机(Support Vector Machine,SVM)常用于处理机器学习中的分类问题,对于分类问题,SVR 是在特征空间中寻找一个曲面,使得不同特征之间的间隙最大,而离该曲面最近的特征向量,则被称为支持向量。支持向量回归(Support Vector Regression,SVR)是SVM 方法的扩展,简单的线性回归是要找出一条残差最小的线,而SVR 则是找出一个超平面,使得所有的样本点离超平面的总偏差最小,主要用于处理回归问题[18]。
随机森林(Random Forest,RF)是典型的多模型联合的机器学习模型,其通过组合一系列决策树的结果来进行联合预测。具体算法流程为:先对原始训练数据集进行随机采样,用于训练第一个决策树,之后进行重新采样训练下一个模型,重复训练N个模型,采样使用随机子空间法,确保决策树之间的低相关性;训练完成后,输入测试数据能够得到N个预测输出,通过多数投票或者求取平均值的方法得到最终的预测结果[19]。
多层感知机(Multilayer Perceptron,MLP)是一种神经网络模型,由输入、隐藏层和输出层构成,层与层之间全连接,即每一个节点都与其上下层的所有节点有连接,每一层的输出传入到下一层直到生成最终的结果。MLP 使用如Tanh 或Sigmoid 等激活函数,通过给神经元引入非线性因素来克服线性模型的限制,增强网络的适用性[20],在分类与回归问题中有广泛应用。
2.2 ADRN 与集成学习
由于MAIAC AOD 观测结果存在大量缺失现象,很难使用基于卷积神经网络的深度学习方法,因为卷积神经网络需要完整的图像或具有有限随机缺失值的图像进行训练,而MAIAC AOD 则通常是因为云层以及地理条件等原因产生缺失,这种缺失过程并不随机。本文使用的深度学习网络为基于自动编码器的深度残差网络(Auto-encoderbased Deep Residual Network,ADRN)及集成算法,算法结构及流程如图3 所示。ADRN 具有对称结构的编码和解码层,能够对多个协变量特征进行监督学习,通过中间层潜在地学习有效的数据特征,提高学习效率[21]。普通的前向反馈神经网络(Feedforward Neural Network,FFNN)在用于回归预测时,会随着隐藏层的增加而发生梯度饱和以及精度下降的现象,因此ADRN 在编码层和解码层引入残差连接以提高学习效率[22],实现在广区域内稳健估算AOD 数据。
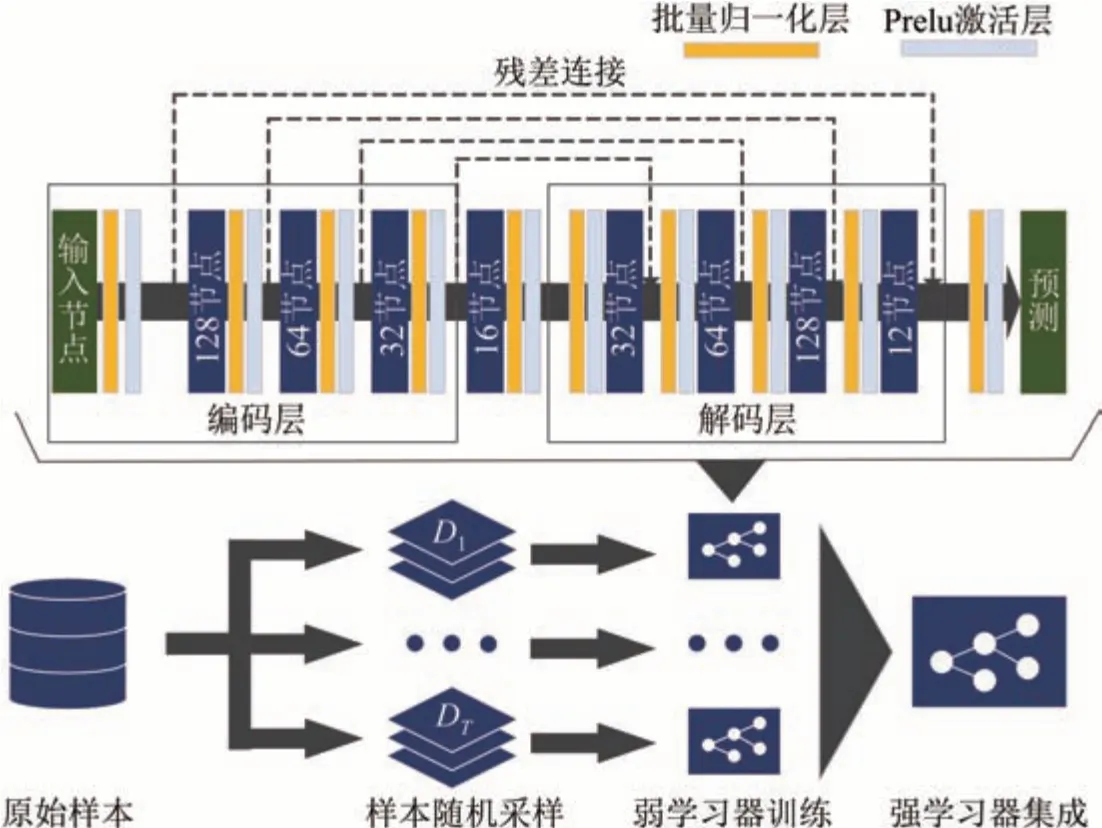
图3 ADRN 模型结构及集成学习流程Fig.3 ADRN model structure and the integrated learning process
模型训练时使用了集成装袋(Bagging)算法,该算法被广泛应用于回归和分类应用中,上文提到的RF 算法就是一种典型的集成算法。由于使用的数据集涵盖地时间跨度较大(3.5 a),且数据分布离散,训练单个模型受数据集的影响较大,因此预测效果较差。而Bagging 算法通过将原始训练集进行随机取样,构建并训练多个独立的弱学习器,之后将弱学习器结合形成强学习器来完成学习任务。Bagging 算法能够有效减小预测的偏差和协方差,提高精度,避免过拟合[23]。本文使用ADRN 模型作为集成算法的基础模型。
2.3 数据预处理
由于使用各类数据的空间分辨率不一致,存在MAIAC AOD 和ERA5 气象数据的大区域覆盖数据,也有类似HLH 和PM2.5浓度的点数据,为了便于制作模型训练集,首先需对各类数据进行时空间匹配。遥感观测数据中空间分辨率不足1 km 的参数,会使用双线性插值法插值到1 km 分辨率;然后以MAIAC 观测时间为基准,与其他气象参数进行时间匹配;AQI 站点的PM2.5数据则与1 km 网格上的最近距离点进行匹配。匹配完成后进行标准化去除特征之间的相关性并使特征具有相似分布,提高模型训练效率。
3 结果与分析
3.1 MAIAC AOD 填补
AOD 填补模型的输入包括经度、纬度、地表高程、时间、地表湿度、温度和压强、东西风速、南北风速、边界层高度、GEOS AOD 等特征,3 年时间的MAIAC 数据量太大,因此以周为单位进行数据集采样和模型训练。使用的深度学习框架为PYTORCH,训练使用NVIDIA TITAN XP 显卡,通过网格搜索寻找模型适合的超参数,最终ADRN模型参数设定如下:学习率为0.001,批量大小为512,训练100 轮;采用学习率衰减策略,当监测到当前损失函数在10 个轮次内没有下降时,学习率缩小至1/2,以减小训练时的参数震荡,使得模型结果更接近最优解;使用Adam 优化器进行参数更新,在学习过程中自适应地迭代更新学习率和权重,相比随机梯度下降有更好的效果。训练完成后,模型的验证结果R2为0.97。AOD 填补效果如图4 所示,图4(a)为实际MAIAC AOD 观测结果,由于云层与地表因素影响,有较多区域无法反演得到AOD,存在大范围空缺,图4(b)、图4(c)为模型填补后的AOD 分布。通过比较可以看出,填补的AOD 与原始MAIAC AOD 分布一致,且数据无明显突变,分布连续,该填补模型能够有效提高被动遥感数据的可用性。
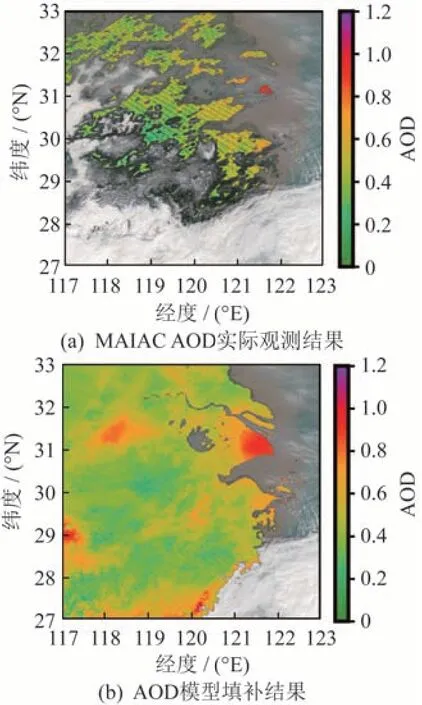
图4 2017 年1 月13 日MAIAC AOD 填补效果Fig.4 MAIAC AOD interpolation result on January 13th,2017
3.2 PM2.5浓度逐小时估算
在AOD 填补模型的基础上,将填补后的MAIAC AOD 作为特征,与地基站点的PM2.5数据进行匹配后结合其他气象数据形成PM2.5的训练集,并利用机器学习算法与集成学习进行训练测试。MLP 模型训练超参数如下:3 层隐藏层,节点数分别为12、24 和12,迭代次数1 000 次,学习率为0.001,激活函数为RELU,批量大小为512,使用Adam 优化器。SVR 模型训练超参数如下:使用RBF 核函数,gamma 为0.06,训练容差为0.001。RF模型训练超参数为:最大随机采样率为50%,即每次随机采样样本数占总训练集的50%,最大树深度20,决策树数量500。集成学习的流程如下:首先对原始训练数据集进行有放回地随机采样得到100 个样本集,之后基于每个样本集训练基础模型,得到100 个相互独立的基学习器;其次进行实际PM2.5浓度估算时,将所有模型的输出取平均作为集成模型的估计结果,ADRN 基础模型的超参数与AOD 填补模型一致。
模型的测试结果如图5 所示,MLP、SVR、RF和ADRN 集成模型分别对应图5(a)~图5(d),相关性分别达到0.43、0.55、0.83 和0.87,在相关性和均方根误差(Root Mean Square Error,RMSE)上,ADRN 集成模型的表现最为优异。同时比较了使用BLH 和HLH 时模型的验证效果,结果见表1,使用HLH 特征对各模型的PM2.5的浓度估算结果都有明显改善,如SVR 模型的R2从0.42 提高到0.55,同时偏差绝对值从0.62 减小到0.12,而ADRN 集成模型的相关性与偏差等指标在2 种情况下都最为优异。
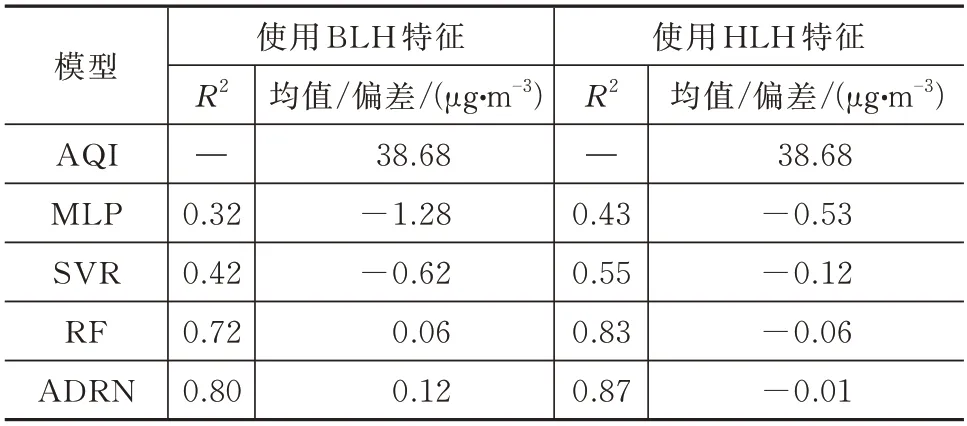
表1 使用 BLH 和 HLH 特征的PM2.5浓度估计结果Tab.1 Estimation results of PM2.5 concentration with BLH/HLH features
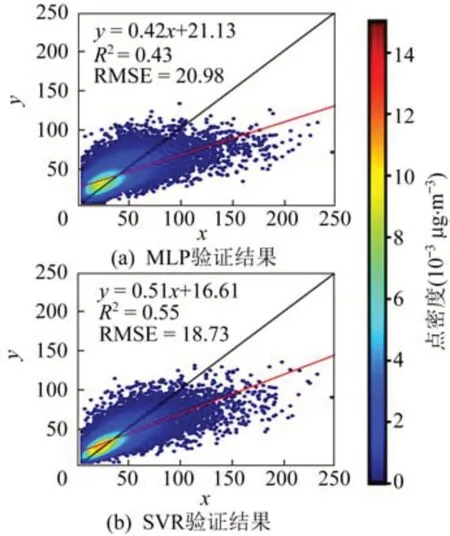
图5 PM2.5浓度模型估计散点Fig.5 PM2.5 concentration model estimation
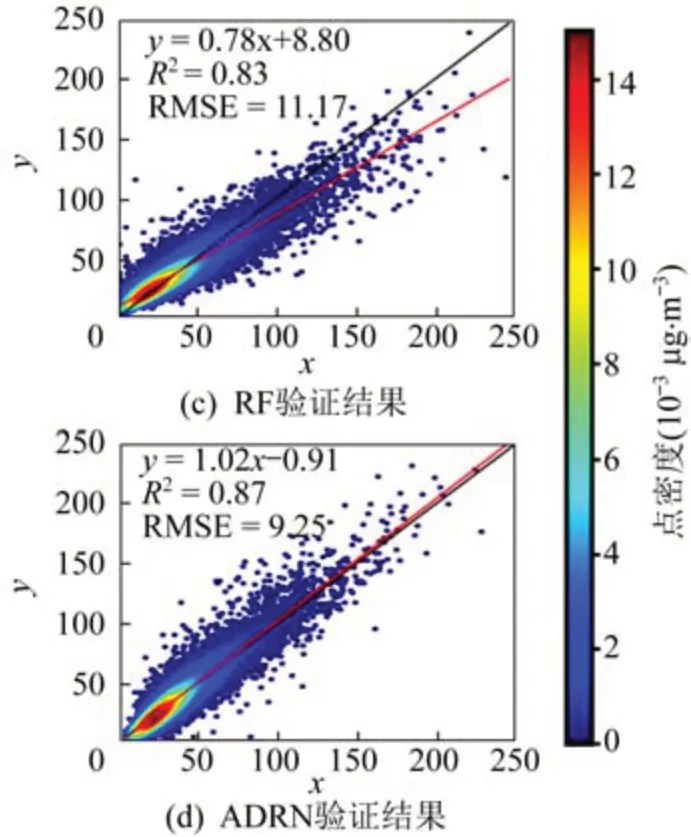
续图5 PM2.5浓度模型估计散点Continuous Fig.5 PM2.5 concentration model estimation
训练完成的ADRN 集成模型可用于估算研究区域在该3.5 a 时间内日间任意小时的PM2.5浓度分布,图6(a)~图6(d)展示了杭州市区2019 年12 月12 日在8:00、11:00、14:00 以及17:00 这几个时间点的浓度分布估算结果,图中的箭头代表该时刻的风向。早上8:00 时,正值早高峰,交通排放增加,PM2.5高浓度地区集中在市中心并沿主要道路分布,最高浓度超过了100 μg/m3,此时整体风向为东北风;中午11:00 时,PM2.5浓度有一定程度的下降,且东部地区下降幅度较大;14:00 时,风向为偏东风,PM2.5平均浓度继续下降,且东北部PM2.5浓度相比于西南角下降更多,东北风将高浓度地区的污染气体携带到西部;17:00 时,城区的PM2.5浓度保持在50 μg/m3左右。PM2.5的浓度分布与日间交通状况一致,且在交通干道周边浓度较高,说明日间交通排放是城市颗粒物的主要来源之一。进一步分析PM2.5浓度的日间每小时及季节变化,如图6(e)、图6(f)所示。
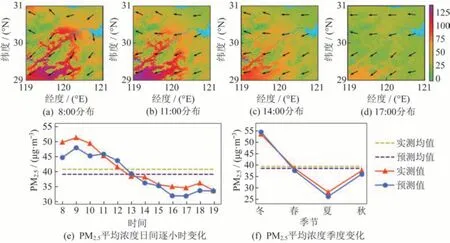
图6 杭州市区2019 年12 月12 日估算PM2.5浓度的空间分布及浓度变化时序Fig.6 Distribution of the estimated PM2.5 concentration in Hangzhou on December 12th,2019 and the concentration time-series
观察到,日间不同时间的PM2.5浓度有明显的变化,早上8~10 点浓度最高,之后逐渐下降,下午5 点后又有小幅上升,与早晚高峰时间匹配。同时观察到,模型估计的PM2.5相较于站点实测数据更低,出现该现象的主要原因是AQI 监测点基本分布在居民区及道路周边,而居民区和道路周边由于人类活动导致PM2.5浓度相对更高,而模型估算结果考虑的是区域内整体的PM2.5浓度,因此实测浓度比模型估算浓度高具有可解释性。季节变化上,在冬季,12 月至来年2 月的浓度最高,夏季浓度最低。冬季空气干燥,降水较少,且存在逆温现象不利于污染气体排放,同时冬季燃煤量和汽车尾气排放加剧,这些因素共同导致冬季的PM2.5浓度居高不下;而夏季气旋活动较频繁,降水较多,有利于PM2.5的扩散和清除[24]。以上分析结果表明,以小时为精度的PM2.5浓度监测对空气质量的正确分级和有效管控有重要意义[25]。
4 结束语
本文提出了基于主被动结合和深度学习算法进行日间逐小时PM2.5浓度反演的方法:首先将从MPL 剖面计算得到的HLH 参数代替传统的BLH参数进行标准化;其次对MAIAC AOD、气象参数与PM2.5浓度的相关性进行分析,改进了PM2.5逐时估算的准确性;最后基于MAIAC AOD 填补结果,建立了高时空分辨率的PM2.5浓度估算模型。通过多种模型的对比试验,分析了HLH 对PM2.5浓度估算带来的性能提升。以杭州城区为例,对该地区PM2.5浓度的时空变化进行了研究分析。
本研究对在监测偏远地区空气质量与扩大PM2.5探测的时空覆盖范围有重要价值,而获得高精度、高时空分辨率的空气质量相关数据,是进行气象、气候、环境影响等诸多研究的必要基础,也是对污染源进行准确定位、对排放量进行长期观测,为有效的排查污染成因和制定治理政策提供参考的重要支撑[26]。在此研究基础上,后续可结合长短期记忆神经网络等循环神经网络进行PM2.5浓度预测等工作。
