利用属性条件偏好推理的在线服务群体选择
2023-07-15梁菁霞付晓东刘利军
梁菁霞,付晓东,2,岳 昆,刘 骊,刘利军,冯 勇
1(昆明理工大学 信息工程与自动化学院,昆明 650500) 2(昆明理工大学 云南省计算机技术应用重点实验室,昆明 650500) 3(云南大学 信息学院,昆明 650091)
1 引 言
服务提供者以互联网为载体,向用户提供的服务称为在线服务[1].随着信息技术和通信技术的发展,用户之间的交流越来越方便.服务提供商面向的用户从个体转向群体的情况越来越多,在线服务群体选择就是为用户群体选择其感兴趣的在线服务.主要应用在团建活动、拼团活动等多人活动情境下.例如拼多多的拼团活动(1)https://www.pinduoduo.com,飞猪的酒店团购活动(2)https://tuan.fliggy.com,携程的私家团游(3)https://vacations.ctrip.com/privategroup,美团的多人休闲娱乐活动(4)https://cq.meituan.com/xiuxianyule/c21193/等等.为群体选择服务时,考虑群体中个体用户的偏好,用聚合策略将用户的偏好聚合,得到群体的在线服务选择结果.面对大量在线服务,在线服务群体选择方法能够有效地为群体选择在线服务,为用户节省时间和精力.
在线服务群体选择方法根据聚合策略将个体用户对服务的偏好进行聚合,得到群体对服务的选择结果.在线服务群体选择分两步:首先,对个体用户的偏好建模,获取个体用户对服务的偏好;然后聚合个体用户的服务偏好,得到群体的服务选择结果.个体用户的偏好建模、推理是在线服务群体选择中的一个基础工作[2].在服务选择的场景中,用户不仅考虑对服务的偏好,通常还会考虑对服务的多个属性的偏好.用户更喜欢用定性的方式而不是定量的方式来表达自己的偏好.例如,当用户在团购平台订购酒店时,会考虑酒店的位置、装修风格和是否提供餐饮等属性的偏好.用户通常用“在酒店位置临近购物中心时,相比于提供餐饮的酒店更喜欢不提供餐饮的酒店”来描述偏好.考虑服务的所有属性的偏好,其结构比较复杂.给定服务属性的有限值域上的笛卡尔积称为服务在属性值上的组合结构[3],也称服务的属性值组合空间.若酒店3个属性的取值都有3个,那么组成的备选服务属性值组合方案有33=27种.在有条件偏好的属性组合结构背景下,导致经典决策理论中的效用函数难以对所有的服务属性进行建模[4],也无法根据已有的属性偏好对未体验服务偏好进行推理.序数偏好是根据用户对服务各全面综合考虑,给候选服务排序的偏好表示方式.序数偏好对用户的要求非常高,并且面对未体验服务无法直接进行排序,需要借助其他方式来预测用户对其偏好.采用协同过滤等方法对未体验服务进行偏好预测,预测结果与用户真实偏好会产生偏差,在聚合过程中影响群体对服务的偏好.现有在线服务群体选择模型中,没有根据属性条件偏好对服务偏好进行推理的方法.此外,聚合策略需考虑个体用户的偏好建模方式,以及平衡群体中个体用户的偏好以达成群体共识.
考虑上述问题,提出了一种利用属性条件偏好推理的在线服务群体选择方法.方法使用条件偏好网络[5](Conditional Preference networks,CP-nets)的顶点表示服务属性数据,根据用户对属性的偏好和条件依赖关系构建条件偏好表(CPT),有效解决服务属性值有组合结构情况下,用户表示偏好困难,以及无法根据属性偏好对服务偏好进行偏好推理的问题;在此基础上使用社会选择函数Ranked Pairs[6]对个体用户的选择结果进行聚合,形成群体的在线服务选择结果.
2 相关工作
近年来,国内外学者围绕服务选择展开了一系列的研究,现服务选择方法已经较为成熟.目前的在线服务选择方法主要有:基于用户偏好的服务选择[7]、基于聚类的服务选择[8]、多标准决策服务选择[9]、多目标进化算法服务选择[10]等.与基于个体用户的服务选择方法相比,基于群体的服务选择方法研究较少,但基于群体的在线服务在生活中越来越多,逐渐受到了服务选择研究人员的关注.在线服务群体选择方法主要有:基于服务信誉的方法、基于协同过滤的方法和其他方法.
信誉是服务若干信用行为累积的结果[11].基于服务信誉的方法是计算群体对服务的信誉度来进行服务选择.郑苏苏等人[11]提出了一种基于Kendall tua距离的在线服务信誉度量方法,根据用户对服务的评分信息,计算群体的在线服务信誉度,从而进行在线服务的群体选择.VectorTrust[12]是一种基于信任向量的信任管理方案,它利用Bellman-Ford 的算法进行快速轻量级的信任评分聚合,具有本地化和分布式并发通信功能.
基于协同过滤的方法是寻找相似用户或相似群体,使用相似用户的偏好或相似群体的偏好来进行服务选择.Lee等人[13]根据成员组织的群相似性指标的组合,选择与新群体相似群体的协同过滤群体推荐方法.Bok等人[14]提出一种使用个体用户信息和社交网络协同过滤的群体服务推荐方法,利用与群体用户相似的其他用户的信息来为群体推荐服务.
此外,曾苏梦等人[15]根据个体用户对服务的优先级计算群体对服务的满意度,根据服务满意度进行服务选择.Xie等人[16]利用丰富的异构信息,提出了一种在异构信息网络中基于混搭群体偏好的服务推荐方法.考虑用户群体之间的准确性和公平性,Xiao等人[17]将概率模型与联盟博弈策略相结合提出一种新的服务群体推荐方法.Zhou等人[18]提出了一种专注于网络社会计算的模型,该模型将大规模群体决策集成到网络支持的在线服务社会推荐中.
上述在线服务群体选择研究使用评分信息和序数偏好来表示用户对服务的偏好,以及提取用户间的关系.评分信息和序数偏好都无法表示用户对服务各个属性的偏好,无法对未体验服务的偏好进行推理.借助协同过滤等方法得到的预测偏好与真实偏好有误差,预测偏好会影响群体对服务的偏好,从而影响群体的服务选择结果.考虑以上研究中存在的不足,本文充分考虑用户属性的条件偏好,提出一种利用服务属性条件偏好推理的在线服务选择方法.
本文的主要工作如下:1)使用CP-nets来对具有组合结构的服务属性进行偏好表示;2)通过CP-nets的语义和性质推导出用户对服务的偏好;3)使用社会选择函数Ranked Pairs将个体用户的服务选择结果聚合,最终形成群体的服务选择结果.此外,通过理论分析和实验验证了该方法的合理性和有效性.
3 问题描述
3.1 问题定义
用户对服务的各个属性有相应的偏好,根据用户对服务属性的条件偏好推导出用户对服务的偏好,即得到个体用户的服务选择结果.在线服务群体选择聚合策略将个体用户的选择结果聚合,得到在线服务的排序列表,作为群体的选择结果.以下对在线服务群体选择问题进行相关定义.
定义1.用户的集合为U={ui|i=1,2,…,n},在线服务的集合为S={sa|a=1,2,…,m}.其中,n表示群体中用户的数量,m表示在线服务的数量.


服务sa包含所有服务属性,集合S中的服务sa在集合Ω中有唯一的服务属性值组合ot与之对应.

定义5.Pi=oσ(1)≻ioσ(2)≻i…≻ioσ(t)表示用户ui对集合Ω中所有服务属性值组合的偏好.其中,oσ(1)≻ioσ(2)表示用户ui认为服务属性值组合oσ(1)优于oσ(2),σ(t)表示属性值组合的序号.
定义6.根据Pi对集合S中的服务排序,得到用户ui的在线服务选择结果,将其记为Li=sσ(1)≻isσ(2)≻i…≻isσ(1).其中,sσ(1)≻isσ(2)表示用户ui认为服务sσ(1)优于sσ(2),l=1,2,…,m,σ(l)表示服务的序号.群体的在线服务选择结果记为LG.
根据上述定义,本文将为集合U中的所有用户组成的群体从集合S中选择适合群体的服务排序作为群体的服务选择结果.首先根据用户ui对属性Xj的偏好,对其进行推理得到用户ui对服务属性值组合的偏好Pi,从而得到用户ui对服务的偏好Li.然后通过聚合策略Ranked Pairs将用户对服务的偏好Li聚合得到群体的服务选择结果LG.
3.2 问题示例


表1 用户对酒店属性的偏好Table 1 Users′ preference about hotel attributes

表2 酒店-属性值组合Table 2 Combination of hotels-attribute values
如表2所示,酒店有3种属性,每种属性拥有相对应的属性值.酒店与其属性值组合相对应.以表2中的属性值组合为基础,根据用户对属性值组合偏好关系Pi对表2中的酒店进行排序,得到用户的酒店选择结果Li.聚合3位用户的Li可获得由三个用户组成的群体的酒店选择结果 .
用户在对服务进行选择时,会根据自身的需求对服务的属性有不同的要求和偏好.上例中用户对酒店的首要需求是位置要靠近购物中心.那么用户面对两家其他条件相同而位置不同的酒店时,用户优先选择位置更符合他们期望的一家酒店.若用户对酒店位置的要求不严格,那么他们对是否提供餐饮、装修风格也有不同的偏好.根据用户对属性的偏好来进行服务选择,更契合用户的偏好.
现有服务群体选择方法中对用户的偏好表示和建模的方式主要有数值评分、序数偏好和效用函数.以上方法中效用函数对具有组合结构的服务属性偏好表示困难,其他方法没有考虑到服务属性的偏好.此外,若用户未体验过部分服务,无法直接对未体验服务进行评价,现有方法也不能对其未体验服务的偏好进行推理.为了解决以上问题,需要考虑服务本身属性的偏好外,还需要结合属性的偏好来对服务的偏好进行推理.本文提出的利用属性条件偏好推理的在线服务群体选择方法,不仅能够准确表示用户对服务属性的偏好,还可以根据属性偏好对服务的偏好进行推理,使得群体选择结果更符合大多数用户的偏好.
4 利用偏好推理的在线服务群体选择
基于以上分析,使用CP-nets表示个体用户对服务属性的偏好,根据CP-nets的语义和特征对服务属性值组合的偏好进行推理,得到用户对服务属性值组合的偏好关系,以此构建CP-nets的导出图结构,根据导出图的拓扑排序对服务进行排序,得到个体用户的在线服务选择结果.然后,使用社会选择函数Ranked Pairs聚合个体用户的服务偏好,得到群体的选择结果.
4.1 用户偏好表示
用户对于自己的偏好表达更擅长于用定性而不是定量的方式.例如,用户在选择酒店时,某用户表示:“若在其他条件相同的情况下,相比于临近旅游景区的酒店,我更喜欢临近购物中心的酒店.”某女士在预订机票时表示:“在非工作日,相比于东航更喜欢南航.”在进行服务选择时,用户更擅长于表示服务属性的偏好.在数量庞大的在线服务背景下,为了能够简洁地表示服务属性的偏好,本文使用CP-nets[5]来表示用户的偏好.
CP-nets以一种自然、清晰方式来表示条件偏好.从结构上看CP-nets是一个有向图,使用图结构来表示用户偏好具有很强的逻辑性和紧凑性.在有向图中,顶点表示服务的属性,有向边表示属性之间的依赖关系,每个顶点所对应的条件偏好表表示用户对每个属性在不同取值下的偏好.CP-nets也是通过稀疏的属性依赖关系来表达属性值组合之间的占优关系[19].CP-nets的相关定义如下所示.
定义7(CP-nets[20,21]). CP-nets是一个三元组(Φ,CE,CPT),结构上是一个有向图,将条件偏好网络记为Ni(i=1,2,…,n).其中:
1)Φ表示CP-nets的顶点集,也是在线服务的属性集.Dom(Xj)表示服务属性Xj上的有限值域.
2)CE={
3)顶点Xj对应一个条件偏好表,用CPT(Xj)表示.若Pare(Xj)=Xj′,则CPT(Xj)的含义为属性Xj的父属性Xj′在不同取值下,用户对CPT(Xj)中属性值的偏好排序.
例2. 根据定义7和表1中用户的偏好,对用户构建CP-nets,如图1所示.

图1 用户u1的CP-netN1Fig.1 CP-net N1 of user u1

4.2 个体用户在线服务选择
CP-nets作为表示在线服务属性条件偏好的工具,需要对其进行推理,得到用户对服务属性值组合的偏好关系.然后根据用户对服务属性值组合的偏好,得到用户对服务的偏好关系.在此之前需要了解属性值组合之间存在的关系,相关定义如下.

定义9(导出图[23]). 设N为CP-net,则有向图N′=(Ω,IE)称作N的导出图,其中Ω是属性值组合空间,IE是诱导的边集合,也称作翻转关系集合.


图2 N1的偏好导出图Fig.2 Induced preference diagram of N1

算法1建立了一个迭代方案,每经过一次迭代,就根据用户ui对属性的条件偏好构建CP-netsNi,并根据Ni对服务偏好进行推理,得到用户对属性值组合的偏好关系Pi,以此得到用户的在线服务选择结果Li.进行n次迭代,每次迭代结束返回用户的在线服务选择结果Li.
算法1.个体用户在线服务选择
输入:用户的条件偏好cpi
输出:用户的在线服务选择结果Li
1.CPT=[],Ω=[],IE=[]
2. FORi=1 tonDO:
3. CPT.append(cpi)
4. FORj=1 topDO:
5. 计算所有翻转关系
6. Ω.append(o1)
7.IE.append((o1,o2))/IE.append((o2,o1))//将翻转关系添加到边集中
8. END FOR
9.N′i.append(Ω)
10.N′i.append(IE)
11.Pi=对N′i进行拓扑排序
12.Li=根据Pi对S排序
13. RETURNLi
14. END FOR
算法1描述个体用户服务选择的全过程,首先根据用户的条件偏好构CP-nets,构建条件偏好网络的时间复杂度为O(n·p).其次,进行偏好推理,通过翻转关系并构建偏好导出图的时间复杂度为O(npq·qp+2).最后,对导出图进行拓扑排序,其时间复杂度为O(nmqp).综上,算法1的时间复杂度为O(npq·qp+2+nmqp),对其影响最大的是服务属性数量以及服务属性值的数量.
4.3 个体用户选择结果聚合
根据个体用户对服务的偏好关系,需要使用聚合策略将所有个体用户的偏好聚合,得到群体对服务的选择结果.社会选择函数Ranked Pairs[6]是社会选择理论中的经典方法,满足社会选择性质较多,且出现平局概率低.因此,使用Ranked Pairs来聚合用户的服务选择结果.聚合过程分为4个步骤:
步骤1.根据Li进行成对比较.建立用户-服务偏好关系矩阵PRi=[prab]m×m(i=1,2,…,n;a,b= 1,2,…,m;a≠b),计算方法为:
(1)
式(1)中,若服务sa和sb在服务选择列表Li中的偏好关系为sa≻sb,则prab=1.同理,若sa~sb,prab=0;sasb,prab=-1.
步骤2.计算群体对服务的偏好关系.构建群体服务-服务比较矩阵CM=[cmab]m×m(a,b=1,2,…,m;a≠b)表示群体的服务偏好关系,为计算方法为:
(2)
(3)
式(2)中统计所有个体用户中服务对(sa,sb)两两比较时的优先服务,若认为服务sa优于服务sb的用户数量多于认为服务sb优于服务sa的用户数量,那么服务sa为优先服务,同理,若两者数量相同,那么两个服务没有优先级,若前者数量少于后者,那么服务sb为优先服务.式(3)中,当sa在群体中为优先服务时,统计服务sa的排名比服务sb的排名靠前的用户数量作为cmab的值,统计服务sa排名比服务sb的排名靠后的用户数量取负数作为cmba的值.当sb为优先服务时,计算cmba的值和cmab的值.当服务对(sa,sb)中没有优先服务,则忽略.
步骤3.根据CM计算服务对的排序.将服务对排序列表记为ST,计算方法为:
(4)
式(4)中,c=1,2,…,m;a≠b≠c.在矩阵CM中比较cmab和cmac的大小,如果cmab>cmac,表示在服务对排序列表中服务对(sa,sb)排在(sa,sc)前面;如果cmab (5) 当|cmba|<|cmca|时,服务对(sa,sb)排在(sa,sc)前面;当|cmba|=|cmca|时,服务对(sa,sb)和(sa,sc)不分先后顺序;当|cmba|>|cmca|时,服务对(sa,sb)排在(sa,sc)后面. 步骤4.根据服务对排序列表ST构建以服务为顶点,以服务对为边的有向图.对有向图进行拓扑排序,得到群体对服务的排序列表LG,将其作为群体的在线服务选择结果. 根据本文提出的利用服务属性条件偏好推理的群体选择方法,设计了实验方案并进行实验分析.所有实验都在Intel Core i7 CPU,64位Windows 10 操作系统,PyCharm 2019.2.3,Python 3.6.5环境下进行. 由于基于奇异值分解(SVD)的方法是推荐方法中的经典方法[24],并且现有方法大多都用协同过滤的手段来解决服务未评价问题,因此本文将SVD作为个体用户选择结果的对比方法.文献[25]中提出了Average、Least Misery、Most Pleasure等几种常见的聚合策略.由于以上方法是聚合策略的经典方法,为了测试本方法的聚合效果,实验与上面几种聚合策略进行比较.本文从3个方面设计实验:首先,本方法与对比方法的聚合效果进行比较;其次,实验验证社会选择理论相关性质;最后,对性能的影响因素分析.本文所有的准确性及有效性数值结果实验都进行10次重复实验,并取平均值作为实验的最终结果. 实验数据集来源于Rafael等人提供的餐厅&消费者数据集[26],该数据集是一个对餐厅评分的数据集,用户对餐厅的服务、环境以及食物口味等进行综合打分,不同的评分分值表达了用户对餐厅的不同喜好程度.餐厅部分的数据集包含每个餐厅所拥有的性质,比如价格,位置等.餐厅&消费者数据集包含177个用户对130个餐厅的1161条评分数据.在进行实验之前,先对数据集进行预处理,删除缺失价格,位置等信息的餐厅数据,进行实验的数据集包含133个用户对113个餐厅的1059条评分数据. 根据餐厅&消费者数据集的餐厅部分数据,提取出餐厅的7个重要属性,例如价格,氛围,位置以及是否可以抽烟等.其中,属性值的数量为2到3.例如,价格分为“高”、“中”、“低”3个属性值.113家餐厅分别以0,1,…,112进行编号.随机选择数据集的20%的数据作为测试集,剩下的80%作为训练集. 5.2.1 评价指标 根据方法介绍,首先对用户的偏好进行学习和推理,得到用户对服务的选择结果;然后对个体用户的服务选择结果进行聚合,得到群体选择结果.实验分为2步:首先,从数据集中构建每个用户的CP-nets,并对其进行推理,得到用户对在线服务的选择结果;然后,选择数据集中的用户组成群体,根据每个用户的服务偏好对该群体进行服务选择. 本文使用准确率来评估个体用户的选择结果算法的效果.准确率表示服务选择结果排序中正确的样本数占总样本数的比例,Precison值越大表示个体用户选择结果越准确: (6) 式(6)中,R(ui)表示测试集中用户ui的总样本偏好数量,T(ui)表示用户ui通过CP-nets推理后得到的服务偏好. 本文使用nDCG(Normalized Discounted Cumulative Gain)[25]对用户服务偏好聚合策略进行评估,用户u关于a(a=1,2,…,m)个在线服务选择结果的DCG和nDCG定义为: (7) (8) 5.2.2 准确率 为了实验的可行性和准确性,需在数据集上构建用户的CP-nets.并对用户的服务偏好进行推理,得到用户对服务的选择结果.为了验证构建CP-nets得到用户对服务偏好的准确率,从数据集中分别选择80%和20%数据作为训练集和测试集,与SVD方法预测用户服务偏好的准确率进行比较.改变用户数量记录准确率,实验结果如图3所示. 图3 用户对服务偏好的准确率Fig.3 Accuracy of user preference for services 从图3中可以看出构建CP-nets得到的用户对服务偏好的准确率在0.57到0.7之间,随着用户数量的增加,准确率趋于平稳.两种方法都随着用户数量的增加呈上升趋势,随着用户数量的改变,构建CP-nets得到的用户对服务偏好的准确率比SVD方法预测用户对服务的偏好准确率都要高.此外,本方法相比于SVD方法更稳定. 5.2.3 聚合效果 在得到用户对服务偏好的基础上,比较了本方法与Average、Least Misery和Most Pleasure的聚合效果.实验得到群体中每个用户关于群体选择结果的nDCG,将所有用户nDCG的平均值作为用户所在群体的群体选择结果有效性评估指标.通过改变用户数量,记录不同方法的nDCG值,观察nDCG的变化趋势,实验结果如图4所示. 图4 聚合效果Fig.4 Aggregation effectiveness 图4显示了上述聚合策略在不同用户数量组成的群体上的聚合效果.本方法的nDCG在0.875到0.9之间,其他方法的nDCG值在0.731到0.86之间.可以看出本方法的聚合策略要优于其他聚合策略,并且本方法的聚合效果不会随着群体中用户数量的增加而产生剧烈变化,其效果较稳定. Average方法将每个用户在服务评价过程中的作用视为相同,不能公平对待群体用户.Least Misery聚合策略的特点是小部分不喜欢某些服务的用户群决定了群体的选择,Most Pleasure方法是小部分特别喜欢某些服务的用户决定了群体的选择,两者都是由小部分用户来决定群体的选择,这使得用户能够轻易进行恶意操纵行为.由于以上聚合策略的特性,使得以上聚合策略的聚合效果存在一定的劣势.本方法不仅能够满足大多数人的偏好,通过偏好推理提高了学习用户偏好的准确率,此外,本方法在一定程度上能避免个别用户的恶意操纵行为.因此,本方法的聚合效果要比其他方法更好. 5.3.1 孔多赛性 孔多赛性反映了大多数用户的最优结果是群体的最优结果.如果存在服务sa与其他任意服务sb成对比较时,都有一半以上的用户认为服务sa优于服务sb,那么sa为孔多赛候选服务[6].从个体用户的服务选择结果中统计可知有28名用户认为服务29优于任意其他服务,服务29为孔多赛候选服务.为了验证本方法的孔多赛性,从28名用户中选择n名用户,从剩下的85名用户中选择n′名用户组成群体进行6轮实验,其中n>n′.记录不同方法得到的群体选择结果的最优服务,如图5所示. 从图5可以看出,本方法在不同用户数量下的群体选择结果中的最优服务都是服务29,与候选服务一致,满足孔多赛性;Least Misery方法在不同用户数量下的群体选择结果中最优服务都是服务109,但与候选服务不一致,不满足孔多赛性;Average方法和Most Pleasure方法在不同用户数量下的群体选择结果中最优服务与候选服务不一致,因此,都不满足孔多赛性. 图5 孔多赛性验证Fig.5 Verification of condorcet 5.3.2 多数准则 在线服务群体选择应满足大多数人的偏好,因此使用社会选择理论中的多数准则验证方法的有效性.多数准则是指如果认为服务sa优于服务sb的用户数量大于认为服务sb优于服务sa的用户数量,那么在群体选择结果中,服务sa优于服务sb.改变用户数量,在不同用户群体上测试在进行服务的成对比较时,记录本方法与比较方法满足多数准则的服务比较对的比例,如图6所示. 图6 多数准则验证Fig.6 Proportion of majority rule 在图6中可以看出,本方法在不同用户数量下满足多数准则的比例在0.86~0.98之间,都高于比较方法.比较方法都是基于评分的聚合策略,由于用户对服务表示同一喜爱程度的评分存在差异,因此会削弱或增高部分用户对服务的偏好,导致群体不能最大可能满足大多数人的偏好.本方法从用户对属性的偏好出发,对用户服务偏好进行推理,避免了评分不一致的问题.本方法多数准则比例无法达到百分百的原因是Ranked Pairs有孔多赛悖论[27]的存在.但本方法在不同用户数量下满足多数准则的比例都要比其他方法高. 5.3.3 抗操纵性 图7中的曲线14、19、…、100表示服务序号,如服务4随着不诚实用户的变化时,服务4的排名没有发生改变.从图7可以看出,当不诚实用户数量增时,排名靠前和靠后的服务的排名都未改变排名,说明排名靠前和靠后的服务具有很强的抗操纵性.排名在中间的服务抗操纵性较弱.这是因为受到CP-nets属性依赖性的影响,改变部分属性值的偏好,个体用户的服务选择结果排名在中间的服务更容易受到影响.综上分析,本方法得到的群体选择结果中,排名在中间的服务抗操纵性较弱,排名靠前和靠后的服务具有较强的抗操纵性. 图7 抗操纵性验证Fig.7 Verification of manipulation resistance performance 在餐厅&消费者数据集中,用户CP-nets的属性和属性值不变,依次选取20%,40%,60%,80%,100%的用户组成群体进行实验.记录本方法和其他3种比较方法在不同用户数量组成的群体中得到群体选择结果的运行时间,实验结果如图8所示. 图8 运行时间Fig.8 Runtime 从图8可以看出,在5个群体中,群体选择方法的运行时间随着群体中用户数量的增加都会随之增加.与其他方法相比,本方法由于考虑了服务属性以及属性值的数量和偏好,并根据用户对属性的偏好对服务偏好进行了推理,因此本方法的运行时间要更长,但对方法的实用性没有本质的影响. 本文针对用户对在线服务属性偏好建模困难,且现有方法无法对未评价服务进行偏好推理的问题提出了一种利用服务属性条件偏好推理的在线服务群体选择方法.方法根据CP-nets的语义对用户的条件偏好进行建模,并使用CP-nets的性质对用户服务偏好进行推理,从而得到用户对服务的偏好关系;最后,受到社会选择理论启发,使用社会选择函数Ranked Pairs将用户的服务选择结果聚合形成群体的在线服务选择结果. 实验结果表明,本方法相比于对比方法总体呈优,能够根据推理得到的个体用户偏好做出较优的在线服务群体选择.此外,实验验证该方法满足孔多赛性、多数准则、单调性和抗操纵性等性质.未来工作中,将探索降低推理用户偏好过程的时间问题,在此基础上结合其他聚合策略迅速获取群体的选择结果.同时,还需在此基础上探索该方法中用户服务属性偏好的变化与社会选择性质中变化趋势的关联性.5 实验与分析
5.1 数据集
5.2 聚合效果



5.3 方法性质


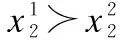

5.4 性能测试

6 总 结
