基于多模态数据融合的跨系统用户信息补全算法
2023-07-14崔宸张俊琪刘彦松等
崔宸 张俊琪 刘彦松等


摘要:在某单位跨系统的应用场景中,用户的个人信息对于提高服务质量和用户体验至关重要。然而,因为各种原因,用户信息常存在不完整或者不准确的问题。为了解决这个问题,文章提出了一种基于多模态融合的跨系统用户信息补全算法。该算法利用用户在不同信息系统上留下的信息(如用户公开的邮件信息、操作记录等).通过多模态数据融合和信息匹配来补全用户信息。实验结果表明,该算法在某单位的跨系统用户信息补全任务上取得了优秀的效果。
关键词:多模态;数据融合;跨系统;补全
中图法分类号:TP391 文献标识码:A
1 引言
在信息化时代,个人信息成为信息系统应用的重要组成部分。然而,现实世界中存在许多问题导致系统中用户信息不完整或者不准确,如在某单位的实际应用场景中,用户可能会误输入信息或输入不正确的格式,信息系统可能会出现编码错误或数据库错误,管理人员可能会疏忽或者误操作,网络原因也可能会导致信息传输不畅或者传输失败。
近年来,随着社交网络的发展,为了提高服务质量和用户体验,用户信息的自动补全成了一个重要的研究问题,受到了越来越多的关注。王铮等[1] 提出了一种基于随机森林的大数据补全方法,用于填补运营商大数据中用户的缺失信息,从而提高数据分析的准确性和可靠性,但该方法缺乏捕捉非线性特征的能力,无法充分学习用户特征;裴杨等[2] 提出了一种基于node2vec 的社交网络用户属性补全攻击方法,首先使用node2vec 算法构建社交网络的图模型,将社交网络中的用户属性补全攻击转化为在社交网络图模型中寻找最佳路径的问题,通过深度学习的方法捕捉了用户的非线性特征;张亚楠等[3] 提出了一种考虑全局和局部信息的科研人员科研行为立体精准画像构建方法,采用深度学习技术,考虑了局部信息与全局信息,同时利用长短时记忆网络捕捉了用户的时序信息,但是没有利用用户在多个平台之间的信息;余敦辉等[4] 首先构建了一个跨平台的知识图谱,用于捕捉用户之间的跨平台关系,然后基于知识图谱进行用户间的关系挖掘,从而得到跨平台的用户关系图,通过跨平台信息补全用户属性。
本文提出了一种基于多模态融合的跨平台用户信息补全算法MPC,通过融合用户在不同平台上留下的多种信息来实现用户信息的自动补全。该算法首先构建多模态用户信息补全模型,将用户在不同平台上的信息(如文本、图像、视频等)进行融合,使用深度学习技术捕捉用户的非线性特征,从而实现用户信息的自动补全。另外,该算法还利用了生成对抗网络[5]
以捕捉用户之间的跨平台关系,从而实现用户属性的补全。
2 技术背景
用户信息补全是指在用户注册或使用某产品或服务时,为了更好地了解用户,从而收集用户的基本信息,完善用户的个人信息。用户信息补全有助于更好地了解用户,以及为用户提供服务,满足用户的需求,并进行市场营销。例如,在电商平台上,用户信息补全可以帮助电商公司更好地了解用户,根据用户的年龄、性别、职业、收入水平等信息,向用户推荐更符合用户需求的商品,从而增加用户的购买意愿,提高电商的销售额。同时,用户信息补全也可以帮助企业更好地管理用户,如可以根据用户的收入水平、职业等信息,将用户分类,从而更好地了解用户的需求,以及进行市场营销,并为其提供服务,进而提高企业的效率和收益。另外,用户信息补全还可以帮助企业更好地实现数据分析,如可以根据用户的性别、出生日期、收入水平等信息,对用户进行分析,了解用户的消费习惯,从而更好地实现市场营销。总之,用户信息补全是企业更好地了解用户,并为其提供服务,最终进行市场营销的重要手段,是企业发展的重要基础。
现阶段,由于社交网络的发展,用户信息补全的相关研究受到越来越多的关注,为了提高数据质量,王铮等提出可以利用全国日志留存系统,设计完整的数据模板样库,使用随机森林算法来补全数据并优化模板样库,构建数据补全子系统,从而提升数据质量,满足数据处理和挖掘的要求,提升运营商数据的价值;裴杨等提出了一种针对社交网络内容安全的攻击方法,即通过属性推断补全获取用户私密属性,文章指出传统的无监督学习和监督学习属性补全方法未能有效结合结构相似性和同质性,并提出了一种基于隐式表达的用户属性补全攻击方法,该方法利用NODE2VEC 算法将社交网络中的用户节点映射为向量,并通过聚类方法计算节点所在的社区,构建分类模型并预测用户缺失属性;张亚楠等提出了一种考虑全局和局部信息的科研人员行为画像方法,利用长短时记忆网络自动提取高度抽象特征,提取科研人员局部画像,结合全局信息构建科研人员的立体精准画像,考虑了科研人员的信息更新行为;余敦辉等提出了一种基于知识图谱和重启随机游走的跨平台用户推荐方法,使用改进的多层循环神经网络(RNN)在目标平台图谱和辅助平台图谱的相似子图中预测候选用户实体,并结合拓扑结构特征相似度和用户画像相似度筛选出相似用户,并计算用户之间的兴趣相似度,从而实现用户推荐。
针对现阶段研究没有考虑文本、图像、视频等多重信息互补的问题,本文提出了基于多模态融合的跨平台用户信息补全算法,利用卷积神经网络捕捉图像信息,结合自然语言处理方法提炼文本信息,并利用生成对抗网络实现用户信息补全。生成对抗网络(Generative Adversarial Networks,GANs) 是一种无监督学习方法, 它包含2 个神经网络, 即生成器(Generator)和判别器(Discriminator)。生成器的任务是从随机噪声中生成新的数据样本,而判别器则试图区分真实数据和生成器生成的数据。2 个网络通过反复博弈的方式进行训练,直到生成器能够生成足够逼真的数据,使得判别器无法准确区分真实数据和生成的数据。本文算法还利用了Doc2vec[6] 、卷积神经网络[7] 、Video2vec[8] ,其中Doc2vec 是一种无监督算法,可将变长文本(如句子、段落或文档)转换成固定长度的特征表示。它也称为Paragraph Vector 或Sentence Embeddings,可以获取句子、段落和文档的向量表达。Doc2vec 不需要固定句子长度,可以接受不同长度的句子作为训练样本。卷积神经网络(Convolutional Neural Network,CNN)是一种经典的深度学习神经网络,常用于图像识别和计算机视觉任务。与传统神经网络相比,卷积神经网络在处理具有网格状结构(如图像)的数据时拥有更好的表现。卷积神经网络的核心思想是卷积操作,它可以提取输入图像的局部特征。卷积神经网络由多个卷积层、池化层和全连接层组成。在卷积层中,卷积核对输入的局部区域进行卷积操作,产生一个特征映射。池化层可以对特征映射进行下采样,以降低数据維度和计算量。全连接层将池化层输出的特征向量映射到输出类别上。卷积神经网络还可以使用多个卷积层和池化层来提取多级抽象特征,从而提高模型性能。同时,还有一些常用的改进方法,如残差网络、批归一化等,进一步提升了卷积神经网络的性能。Video2vec是一种视频片段的语义和时空信息嵌入方法。它利用视频作为语义连续的时序列帧来表达视频的高层特征。该方法使用卷积神经网络特征提取器和2 个门控循环端元(GRU)编码器[9] 来学习视频的文本信息。视频的彩色图像序列和光流序列被嵌入相同尺寸的表征向量中,然后使用一个多层感知机将图像序列的表征向量和语义文本向量嵌入到一起。
4 对比方法
(1)RF:该方法基于随机森林算法,在预处理、模型构建、预测和结果分析等方面进行了详细研究和探索,并对随机森林算法在运营商大数据补全中的应用进行了实证分析。
(2)Node2vec:该方法利用了node2vec 能表达节点同质性和结构相似性的特点。其将社交网络中的节点映射到低维空间,以训练出来的向量作为分类器的输入,使用k?means 算法进行聚类,然后使用kNN 算法对节点的缺失信息进行补全。先聚类再分类能够节省程序运行时间,同时该方法本质上是一个有监督的分类问题,适用于社交网络中的用户属性补全。
(3)TSP:该方法使用主题模型和长短期记忆网络在科研人员画像构建中处理全局及局部科研行为数据,分别提取静态和动态特征。主题模型用于处理全局数据,长短期记忆网络则用于提取科研人员的局部动态变化的科研行为。
(4)RCCP?KG:该方法基于知识图谱实现辅助平台用户信息补全到目标平台图谱中,从而更全面地描述用户行为,发现不同平台间的潜在用户关系,并实
现更准确的相似用户推荐。
5 实验
本文以本单位内部用户多平台信息作为数据集,用于验证本文模型的效果。本文采用均方根误差(RMSE)、均方误差(MSE)以及平均绝对误差(MAE)来评估实验结果。均方根误差是预测值与真实值之间差的平方的平均值的平方根。RMSE 的数值越小,表示预测误差越小,模型的预测能力越好;均方误差是预测值与真实值之间差的平方的平均值。MSE 的数值越小,表示预测误差越小,模型的预测能力越好;平均绝对误差是预测值与真实值之间差的绝对值的平均值。MAE 的数值越小,表示预测误差越小,模型的预测能力越好。
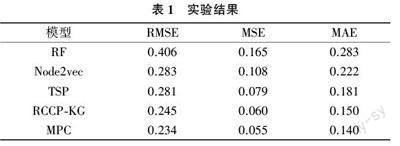
4 种对比方法的实验结果如表1 所列。
表1 列出了RF, Node2vec, TSP, RCCP?KG 和MPC 5 个模型使用RMSE,MSE 和MAE 3 个指标评估的结果。从表1 可以看出,MPC 在所有3 个指标下的表现都优于其他4 个模型。它的RMSE 为0.234,MSE为0.055,MAE 为0.140,表明它的预测结果与真实结果之间的差异较小。而在其他4 个模型中,RF 表现最差,它的RMSE 为0.406,MSE 为0.165,MAE 为0.283,这体现出传统机器学习方法在学习用户跨平台信息时难以充分利用现有信息。Node2vec 的RMSE为0.283,MSE 为0.108,MAE 为0.222,以及TSP 的RMSE 为0.281,MSE 为0.079,MAE 为0.181,说明通过深度学习的方式能够有效提升捕捉用户跨平台信息的能力。RCCP?KG 的表现也较为优秀,其RMSE为0.406,MSE 为0.165,MAE 为0.283,这表明了考虑用户跨系统信息的重要性,通过用户在不同系统中的信息互补,可以有效提升用户信息补全效果,但与MPC 相比,仍然存在差距,这也体现了本文提出的基于多模态数据融合的跨系统用户信息补全算法的优异性,证明了用户的多模态信息之间可以有效互补以提升用户的信息补全效果。
6 展望
随着大数据和深度学习技术的不断发展,基于多模态数据融合的跨系统用户信息补全算法已经成为一个非常有前景的研究方向。在这个方向上,未来可能会出现以下趋势。
多模态数据的应用范围将不断扩大。随着传感器
和计算机视觉等技术的不断进步,我们可以获取越来越多的多模态数据,如文本、图片、音频、视频等,这类数据可以在用户信息补全问题中得到更广泛的应用。
深度学习技术将成为主流。深度学习技术在图像、语音、自然语言处理等领域取得了重大的突破,未来将更多地应用于多模态数据融合的用户信息补全问题中。
跨系统用户信息的挖掘与融合。跨系统用户信息的融合涉及多个系统、多个数据源之间的信息集成和交互,因此需要在用户信息补全算法中引入数据挖掘技术和信息融合技术,从而实现跨系统用户信息的高效补全。
可解释性和隐私保护。在用户信息补全算法中,需要考虑数据的可解释性和隐私保护问题,这些问题将成为未来算法设计中的重要考虑因素。为了确保算法的可靠性和用户的隐私安全,需要开展更多的相關研究。
综上所述,基于多模态数据融合的跨系统用户信息补全算法在企业用户信息管理中具有重要价值,可以提升企业的工作效率以及企业用户的用户体验,并帮助企业开展智能化管理工作。
7 结束语
本文介绍了一种基于多模态数据融合的跨系统用户信息补全算法,旨在解决用户信息不完整的问题,即当用户在使用不同的系统时,其个人信息可能会有所不同,从而导致信息不完整。该算法结合了多种数据源,包括用户填写的文本信息、用户上传的图像以及用户上传的视频,通过多模态融合的方式来补全用户信息。
实验证明,本文算法表现优秀,相较于传统的基于机器学习的方法与当前基于深度学习的主流方法,该算法在用户信息补全的准确性上显著提升。另外,该算法的应用还有一定的实际意义,如可以用于社交媒体平台中的用户信息补全,提升用户体验和社交媒体平台的精准营销效果。
参考文献:
[1] 王铮,任华,方燕萍.随机森林在运营商大数据补全中的应用[J].电信科学,2016,32(12):7?12.
[2] 裴杨,瞿学鑫,郭晓博,等.基于node2vec 的社交网络用户属性补全攻击[J].信息网络安全,2017 (12): 67?72.
[3] 张亚楠,黄晶丽,王刚.考虑全局和局部信息的科研人员科研行为立体精准画像构建方法[J].情报学报,2019,38(10):1012?1021.
[4] 余敦辉,张蕗怡,张笑笑,等.基于知识图谱和重启随机游走的跨平台用户推荐方法[J].计算机应用,2021,41(7):1871.
[5] GOODFELLOW I, POUGET?ABADIE J, MIRZA M, et al.Generative adversarial networks [J]. Communications of theACM,2020,63(11):139?144.
[6] LE Q,MIKOLOV T.Distributed representations of sentencesand documents [ C] ∥ International conference on machinelearning,PMLR,2014:1188?1196.
[7] 常亮,邓小明,周明全,等.图像理解中的卷积神经网络[J].自动化学报,2016,42(9):1300?1312.
[8] HU S H,LI Y,LI B. Video2vec:Learning semantic spatio?temporal embeddings for video representation[C]∥2016 23rdInternational Conference on Pattern Recognition ( ICPR),IEEE,2016:811?816.
[9] CHO K, VAN MERRI?NBOER B, GULCEHRE C, et al.Learning phrase representations using RNN encoder?decoderfor statistical machine translation[J].arXiv preprint,2014.
作者简介:崔宸(1996—),硕士,助理工程师,研究方向:大数据与数据挖掘。
