基于改进型K-means算法的高校研究生成绩画像研究
2023-07-11罗鑫帅高洋
罗鑫帅 高洋


[摘 要]成绩画像对研究生培养具有重要参考价值,以某师范大学某学院某专业学位硕士研究生近5年成绩为数据基础,通过K-means算法对研究生考试成绩进行分析,获得代表研究生群体的成绩属性特征。本文运用手肘法确定K值后,选取K个欧式距离最远点为初始中心建立改进型K-means算法模型,描绘出客观的研究生成绩画像,并从研究生入学教育、学风建设等方面给出具有参考价值的工作建议。
[关键词]成绩画像 K-means 研究生 学风建设
本项目受助于陕西师范大学研究生思政精品项目(YGYB2114)、教育部高校思想政治工作创新发展中心(武汉东湖学院)2022年度专项研究课题(编号:WHDHSZZX2022075)以及陕西高校网络思想政治工作第二批实践项目(编号:2022WSYJ100083)。
引 言
学业成绩作为研究生培养质量的重要参考指标之一,在一定程度上反映了研究生的学习状态、学习效果和学习能力。随着大数据技术的发展,用较为科学的方法分析数据,给予高校研究生教育管理的参考方案,对高校研究生教育管理工作具有重要意义。数字赋能,能够辅助升级高校教育管理模式,精准开展各类教育工作,丰富大数据技术背景下的典型教育案例。目前越来越多的科研工作者围绕学生画像构建进行探索研究,在研究对象方面,针对校园一卡通的消费记录、学生成绩和学生上网时长等方面进行聚类分析与关联研究。姜楠和许维胜基于校园一卡通的刷卡记录,利用K-means聚类算法梳理了学生校园消费习惯,并用Apriori关联规则算法与学生学习行为进行关联分析;陶婷婷也利用了类似的方法,进一步分析了一卡通数据、学生在线学习时长与学生成绩之间的关系;郭鹏基于一卡通数据,对学生消费水平、消费行为、上网情况和借阅图书情况进行了系统聚类,并对关联算法进行改进。在研究技术方面,根据研究对象的差异化以及数据的多样性,改进型K-means聚类算法得到越来越广泛的应用。凌玉龙等提出了基于马氏距离的改进型K-means算法;何选森等提出了用有效性评价函数的最小值确定K值的方法;许智宏等运用DPCA方法改进了K-means初始聚类中心的选择问题;于莉佳和汪涛通过模糊K均值聚类算法分析了高校网络用户行为;张云和张轶分别用加权K-means算法对高校学生成绩和高校贫困生进行了聚类分析。在研究架构层面,冯广等对学生画像系统的技术架构和应用场景进行了分析;黄炜等基于“五育融合”的综合素质评价构建了学生数字画像。在研究价值方面,黄文林基于学生画像技术对高校精准思政探索进行了阐释。
由上述研究可以看出,高校教育管理工作越发精细化与科学化,在学生精准资助、学业成绩分析、校园行为研判等方面均有数据化的依据作为科学决策的有力保障,如何将数据有效处理,提供科学决策依据,也是高校教育管理工作面臨的重要问题。本文结合研究生考试成绩数据量度特点,通过算法选择欧式距离最远的K个点作为初始中心,运用K-means聚类算法对研究生考试成绩进行分析,做出有效分类,针对成绩有困难的研究生群体进行重点关注与帮扶,针对成绩优秀的研究生群体进行示范宣传与经验分享,为研究生培养工作提供参考依据。通过对近5年相同专业研究生成绩进行纵向对比,检验教师的教学效果及研究生学习效果,探索该专业研究生教育的一般规律,对研究生教育引导和学风建设工作提供参考建议。
算法介绍
K-means算法是在给定分类簇数和初始簇中心的前提下对样本数据进行分类分析的方法,它属于一种无监督、迭代的学习算法,可以将同一样本簇的距离尽可能缩小,不同样本簇之间距离尽可能远离,从而达到划分数据、有效分析的目的。在K-means算法中随机选择样本点作为初始中心,不断计算每个样本点与初始中心的欧式距离,选定距离最近的初始中心为一簇,并对簇的中心进行重新选取,重复上述过程,直至各个簇中心位置不再发生变化,样本数据也完成划分,算法结束。本文以研究生成绩为样本,对数据进行聚类,直到寻找出最终聚类中心样本,这一研究生成绩样本也就能够反映出该群体研究生的成绩属性特征。在算法执行过程中,确定簇的数量与初始中心的位置是完成K-means算法的关键,本文运用手肘法确定簇的数量,运用算法遍历选择出欧式距离最远的点作为初始聚类中心。
1.簇的数量即K值选取
簇的数量即K值采用手肘法确定:
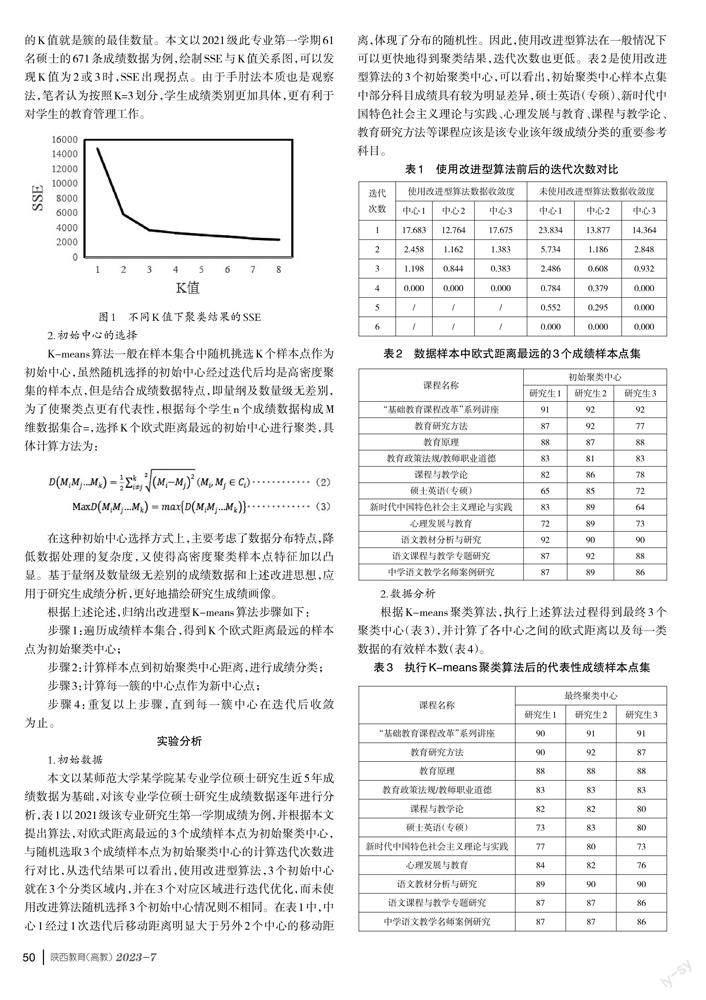
是随机样本点,是聚类中心,SSE是误差平方和,随着簇的数量即K值的精细划分,SSE会逐渐变小,当SSE与K值关系曲线出现拐点时,SSE不再随着K值增大有较为明显的变化,此时的K值就是簇的最佳数量。本文以2021级此专业第一学期61名硕士的671条成绩数据为例,绘制SSE与K值关系图,可以发现K值为2或3时,SSE出现拐点。由于手肘法本质也是观察法,笔者认为按照K=3划分,学生成绩类别更加具体,更有利于对学生的教育管理工作。
2.初始中心的选择
K-means算法一般在样本集合中随机挑选K个样本点作为初始中心,虽然随机选择的初始中心经过迭代后均是高密度聚集的样本点,但是结合成绩数据特点,即量纲及数量级无差别,为了使聚类点更有代表性,根据每个学生n个成绩数据构成M维数据集合=,选择K个欧式距离最远的初始中心进行聚类,具体计算方法为:
在这种初始中心选择方式上,主要考虑了数据分布特点,降低数据处理的复杂度,又使得高密度聚类样本点特征加以凸显。基于量纲及数量级无差别的成绩数据和上述改进思想,应用于研究生成绩分析,更好地描绘研究生成绩画像。
根据上述论述,归纳出改进型K-means算法步骤如下:
步骤1:遍历成绩样本集合,得到K个欧式距离最远的样本点为初始聚类中心;
步骤2:计算样本点到初始聚类中心距离,进行成绩分类;
步骤3:计算每一簇的中心点作为新中心点;
步骤4:重复以上步骤,直到每一簇中心在迭代后收敛为止。
实验分析
1.初始数据
本文以某师范大学某学院某专业学位硕士研究生近5年成绩数据为基础,对该专业学位硕士研究生成绩数据逐年进行分析,表1以2021级该专业研究生第一学期成绩为例,并根据本文提出算法,对欧式距离最远的3个成绩样本点为初始聚类中心,与随机选取3个成绩样本点为初始聚类中心的计算迭代次数进行对比,从迭代结果可以看出,使用改进型算法,3个初始中心就在3个分类区域内,并在3个对应区域进行迭代优化,而未使用改进算法随机选择3个初始中心情况则不相同。在表1中,中心1经过1次迭代后移动距离明显大于另外2个中心的移动距离,体现了分布的随机性。因此,使用改进型算法在一般情況下可以更快地得到聚类结果,迭代次数也更低。表2是使用改进型算法的3个初始聚类中心,可以看出,初始聚类中心样本点集中部分科目成绩具有较为明显差异,硕士英语(专硕)、新时代中国特色社会主义理论与实践、心理发展与教育、课程与教学论、教育研究方法等课程应该是该专业该年级成绩分类的重要参考科目。
2.数据分析
根据K-means聚类算法,执行上述算法过程得到最终3个聚类中心(表3),并计算了各中心之间的欧式距离以及每一类数据的有效样本数(表4)。
按照算法执行数据迭代后,从表3中可以看出,该专业21级61名专业硕士研究生的成绩特点:第一类研究生在公共必修课硕士英语(专硕)、新时代中国特色社会主义理论与实践考试中成绩偏低,其他科目成绩均良好;第二类研究生在所有科目的考试中均获得了较为理想的成绩;第三类研究生在公共必修课新时代中国特色社会主义理论与实践、专业课心理发展与教育及教育研究方法等考试中成绩偏低,其他科目成绩较为理想。从表4中可以看出,各聚类中心分布数据样本数量依次为18、34、9人,分别约占样本总数的三分之一、二分之一和六分之一,样本均为有效样本且分布数量均匀。并且三个聚类中心两两距离均在10~12之间,亦是数据高密度质心位置。因此从数据角度来看,聚类结果较为理想。
对该专业近5年研究生成绩进行分析,从图2中可以看出,“基础教育课程改革”系列讲座、心理发展与教育等专业课平均成绩较为稳定;教育研究方法、教育原理及课程与教学论等专业课平均成绩稳步提升。“基础教育课程改革”系列讲座是研究生取得高分较容易的科目,而心理发展与教育相对其他科目近5年考试成绩均较低,从数据角度来看,该门专业课难度较大,应引起足够重视。硕士英语(专硕)、新时代中国特色社会主义理论与实践公共必修课成绩较为稳定,且平均成绩低于专业课考试成绩。
针对聚类结果和近5年成绩曲线图可以看出,研究生教育管理工作者应该对硕士英语(专硕)、新时代中国特色社会主义理论与实践、心理发展与教育、课程与教学论等进行重点引导。
一是加强公共必修课重视程度。专业型硕士研究生公共必修课为硕士英语(专硕)和新时代中国特色社会主义理论与实践两门课程,从该专业近5年研究生学习效果来看,公共必修课成绩低于专业课成绩。在课程安排较多的情况下,许多研究生对公共必修课的重视程度不够,投入学习精力有限,部分研究生出现重视专业课而轻视公共必修课的学习现象。因此,在研究生教育管理过程中,要加强日常学习管理与考前动员工作,提醒研究生重视公共必修课。
二是加强重难点专业课学习指导。从近5年研究生专业课考试成绩来看,该专业研究生在教育研究方法、教育原理及课程与教学论等专业课学习中均有较为明显的进步,也说明研究生学习能力越来越强,对专业课程的掌握情况越来越好。但是心理发展与教育这门课程,该专业研究生在近5年内考试成绩低于其他课程,也说明这门课程难度较大,并且根据聚类结果,该专业21级的研究生学习掌握程度也有差异,9名研究生(约占总人数的六分之一)成绩较低。在日常学习过程中,建议研究生教育管理工作者主动摸排并关心专业课学习有困难的研究生,邀请授课教师或者高年级研究生进行学习经验分享,提升学习效果。
结 语
K-means算法适用于研究生考试成绩样本分析场景,根据考试成绩分析场景使用改进型K-means算法可以降低算法迭代次数,更快地得到聚类结果,该算法可以更好地分析研究生成绩特点,描绘研究生成绩画像,为研究生教育管理工作者提供一定参考价值,帮助研究生教育管理工作者科学高效地掌握研究生分类特点,因材施教,更加精准地开展研究生学风建设等相关工作。
参考文献:
[1]郭鹏.基于校园一卡通数据的学生消费行为与成绩的关联性研究[D].杨凌:西北农林科技大学,2019.
[2]陶婷婷.基于校园一卡通和云课堂数据的消费与学习行为分析[D].武汉:华中师范大学,2017.
[3]姜楠,许维胜.基于校园一卡通数据的学生消费及学习行为分析[J].微型电脑应用,2015,31(2):35-38.
[4]凌玉龙,张晓,李霞,张勇.改进k-means算法在学生消费画像中的应用[J].计算机技术与发展,202,31(10):122-127.
[5]何选森,何帆,徐丽,等.K-Means算法最优聚类数量的确定[J].电子科技大学学报,2022,51(6):904-912.
[6]许智宏,李彤彤,董永峰,等.基于改进K-means算法的学生用户画像构建研究[J].河北工业大学学报,2022,51(3):19-24.
[7]于莉佳,汪涛.基于模糊K均值聚类的高校网络用户行为分析[J].智能计算机与应用,2022,12(10):200-202.
[8]张云.基于改进的K-means聚类算法的学生成绩分析[J].安徽开放大学学报,2022,(3):92-96.
[9]张轶,高雪冬,郭亚伟,赵丙贺.加权k-means算法及其在高校贫困生判别中的应用[J].产业与科技论坛,2022,21(19):40-44.
[10]冯广,何雅萱,贺敏慧.基于校园大数据的学生画像系统应用研究[J].软件,2020,41(8):40-42.
[11]黄炜,张治,胡爱花,等.基于“五育融合”的学生数字画像构建与实践分析[J].教育发展研究,2021,41(18):44-51.
[12]黄文林.基于学生画像分析的高校精准思政探索[J].东北大学学报(社会科学版),2021,23(3):104-111.
(罗鑫帅:陕西师范大学党委研究生工作部;高洋:西安外国语大学英文学院)
