基于视图互信息加权的多视图集成聚类算法
2023-07-03劳景欢王昌栋赖剑煌
劳景欢,黄 栋*,王昌栋,赖剑煌
(1.华南农业大学 数学与信息学院,广州 510642;2.中山大学 计算机学院,广州 510006)
0 引言
聚类分析(clustering analysis)是一类重要的无监督学习技术,其目标在于将一组给定数据点划分为若干小类,每一个小类称为一个簇(cluster),以期簇内数据点尽可能相似,不同簇的数据点尽可能不同[1]。传统聚类算法大多关注单视图数据,即数据集仅有一个数据源(或仅有一个特征集);而在现实应用场景中,数据来源往往多样化,同一个数据集也可能有多个数据源的特征集,由此构成多视图数据(multi-view data)。传统聚类算法[2-4]的单视图学习模式往往难以有效应对多视图聚类问题,如何充分利用多视图场景下不同数据视图之间的互补与一致信息提升多视图聚类性能,是近年来聚类分析领域的一个热点研究方向[5-17]。
近几年,国内外研究人员提出了许多行之有效的多视图聚类算法[5-12]。Tang 等[12]提出了一种基于跨视图相似图融合的多视图聚类算法,通过跨视图扩散,学习得到一个统一的图相似性矩阵,并在该统一相似性矩阵上进行谱聚类,生成聚类结果。Khan 等[11]提出了一种基于流形优化的多视图聚类算法,通过构造一个联合的拉普拉斯矩阵,以包含所有单视图去噪处理后的簇信息,再使用k均值(k-means)聚类和Stiefel 流形方法优化联合聚类目标,减少联合视图和单个视图之间的聚类信息分歧。Zhang 等[18]提出了一种新的单步共识多视图子空间聚类算法,构建统一学习框架以同时学习得到相似性矩阵、共识表示和最终聚类标签矩阵。
这些多视图聚类算法在聚类性能上取得了较大改进[11-12,18],但这些算法往往无差别对待所有视图,未充分考虑视图间的重要性差异,对于低质量视图也给予同等对待,可能导致低可靠度信息或噪声信息在计算过程中持续传播,对最终聚类结果产生负面影响,因此,多视图加权机制近年来越来越得到重视,许多具有视图加权能力的多视图聚类算法[19-23]也相继提出。Wang 等[20]提出了一种基于图的多视图聚类算法,通过多视图权值、单视图相似性和统一相似性三者之间的相互迭代更新,得到优化后的权值和统一图矩阵,再对统一图矩阵进行秩约束并得到最终的簇划分。Chen等[21]提出了一种基于多视图加权融合和离散化矩阵分解的多视图谱聚类算法,通过对不同视图加权学习得到统一相似性矩阵,对相似性矩阵进行特征分解得到一组特征向量,进而从特征向量中学习一个连续的聚类标签,将其离散化以建立最终聚类。Huang 等[22]提出了一种同时执行核空间多视图聚类任务和学习相似性关系的多视图聚类模型,可在构建准确的相似图、自动分配最优权重的同时得到最终聚类指示矩阵。这些算法对多视图聚类的加权机制进行了多角度的探索,但这些算法大多依赖于特定目标函数的迭代优化,且往往涉及一个或多个超参数的预设或精调,其目标函数的适用性及超参数设置的合理性均对实际应用有较大影响。如何自动、高效地得到多视图可靠度及其权值,构建鲁棒聚类结果,仍是目前多视图聚类研究的一个挑战性问题。
针对前述问题,本文提出一种基于视图互信息加权的多视图集成聚类(Multi-view Ensemble Clustering based on View-wise Mutual Information Weighting,MEC-VMIW)算法。该算法可分为视图互加权阶段和多视图集成聚类阶段两个阶段。在视图互加权阶段,首先对数据集进行多次随机降采样,在单次降采样的数据集中对每个视图构建一个聚类结果,利用多视图的降采样聚类集合评价每个视图内的聚类结果,再取它们的平均得分,得到各个视图的一个评价分数;然后,将此降采样、构建降采样聚类、视图评价过程重复T次,可得各视图的T个评价分数,以它的最终平均得分作为视图权值。在多视图集成聚类阶段,借助集成聚类的思想[24-30],在各个视图中构建多个基聚类(base clusterings),再将多个基聚类结果建模至二部图(bipartite graph)模型,进而作高效二部图分割以得到最终聚类结果。
1 本文算法
1.1 视图互信息加权机制
本文提出视图互信息加权机制,在无监督情况下可用来评价多视图数据中不同视图的可靠度并对它赋予相应权值。为降低运算规模,同时提升多次运行时的多样性,首先对原始数据集进行随机降采样,采样比例γ∈(0,1];在具体实现中,令γ=0.5,即每次降采样时保留一半数据点。进一步地,在降采样所得的数据点中,计算它们的欧氏距离,并以高斯核函数将它们映射至相似度,再取它们的K近邻(K-Nearest Neighbors,KNN),构建一个稀疏的K近邻相似性矩阵,其中,高斯核函数的带宽参数(bandwidth parameter)设置为K近邻图距离的平均值。在得到相似性矩阵的基础上,通过谱聚类(Spectral Clustering,SC)算法[2]分别得到每个视图的一个聚类结果。
然后,借助归一化互信息(Normalized Mutual Information,NMI)[31]对每个视图的聚类结果与其他视图的聚类结果进行相互评分。对于任意的两个基聚类πi和πj,计算公式如下:
通过多个视图的降采样聚类结果以NMI 进行相互评分,可以对不同视图之间的聚类结果一致性或认可度进行评价,并将获得其他视图认可(得分)更高的聚类(及其对应视图)视作具有更高可靠度,由此确认视图间权重。针对单次视图互评可能存在的偶然性,本文将前述过程重复T次,得到平均互评得分。
在单次视图互评的基础上重复运行T次,可得每个视图的平均评价分数,将它作为视图权重。令Wv表示为第v个视图的T次互评平均得分(即权重),计算如下:
由此,通过视图互信息加权机制,可以得到各个视图间的权重W={W1,W2,…,WV},其 中Wv表示第v个视图 的权重。
1.2 视图基聚类生成策略
集成聚类的目标在于融合多个基聚类结果的信息以得到一个更优、更鲁棒聚类结果[27]。常规集成聚类往往以k均值聚类算法生成基聚类集合,虽然k均值聚类算法具有计算简单、效率高等优点,但聚类结果对质心选取的依赖程度高且难以有效应对非线性可分数据集。谱聚类与k均值聚类算法相比,可生成任意簇形状的聚类结果,有效应对非线性可分数据集,因此本文采用谱聚类算法生成多视图基聚类。
为了得到更优聚类结果,本文将对多视图数据的多个基聚类进行集成,构造簇与数据点之间的二部图结构,然后以高效图分割算法得到最终的聚类结果。该二部图中,包含数据集的所有样本点。若使用降采样的方式得到具有部分样本的基聚类,将不能构造具有正确权值的二部图。为此,与视图互加权阶段使用降采样数据集不同,基聚类生成过程使用的是完整数据集。为充分挖掘各视图信息,本文为每个视图生成M个基聚类,由此为多视图数据集得到总计M×V个基聚类。在每个视图中,本文基于欧氏距离与高斯核函数映射构造数据点的相似性矩阵,进而构建其K近邻相似性图,然后利用谱聚类算法对其进行划分。对于所有的基聚类,如果它们的簇数均相同,可能得到的基聚类集合较为单调。对于每一个基聚类,如果簇数偏离真实的簇数过大,则可能得到准确性较差的基聚类。为了使所构建的基聚类集合具有多样性,对每个基聚类的簇个数在随机选取,其中y表示该数据集的真实类别个数。对于V个视图,在每个视图中生成M个基聚类,将第v个视图所生成的基聚类集合记作:
其中视图v的第i个基聚类表示为,令nv,i表示簇个数,则有:
值得注意的是,在1.1 节中基于视图互信息加权机制已经得到各个视图的权重W={W1,W2,…,WV},进一步将之与各个视图的基聚类集合相结合,即得到基聚类权重,即在视图v的基聚类集合Πv内的基聚类对应获得视图v的权重Wv。
1.3 二部图建模与多视图集成聚类
在构建多视图基聚类集合Π的基础上,将对多个基聚类的信息进行融合,构建最终的多视图聚类结果。本文采用二部图结构对多基聚类的集成过程进行建模。在基聚类集合中,每个基聚类包含若干个簇,将全体基聚类所包含的簇集合表示为:
其中NC表示簇的总数。显然,全体基聚类的簇个数等于各个基聚类簇个数之和,即NC=
具体地,以簇集C和数据点集X为节点集,将集成聚类问题构造为加权二部图模型。所建立的加权二部图结构如图1 所示。当两个节点同为簇节点或者同为数据点节点时,两节点之间没有边的连接;当且仅当一个节点为数据点节点、另一个节点为簇节点且该簇中包含了这个数据点时,两个节点之间才有边的连接,两者之间连接边的权值由该簇隶属的基聚类权值所决定。
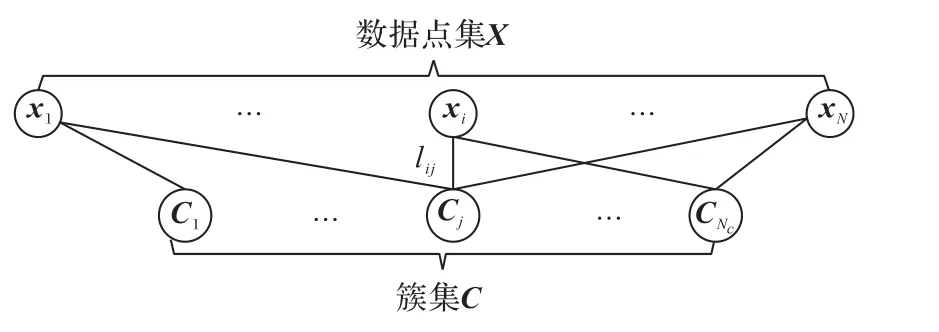
图1 加权二部图G示意图Fig.1 Schematic diagram of bipartite graph G
该二部图结构表示如下:
其中:X和C表示二部图G的两部分节点集合,L为图G的边集合。对于任意的两个节点xi和Cj,边的权值定义如下:
其中:xi是数据点节点,Cj是簇节点。xi隶属于Cj且xi所在的基聚类隶属于视图v的基聚类集合Πv,则xi与Cj之间的权值由视图v的权值所决定。基于二部图的结构特点,可使用迁移分割(transfer cut)算法[32]将该二部图结构高效划分为若干互不相交的节点子集,将每一个节点子集中的数据点视作一个簇,得到最终的多视图集成聚类结果。
2 实验与结果分析
本章在6 个多视图数据集上进行实验,并将本文提出的基于视图互信息加权的多视图集成聚类(MEC-VMIW)算法与谱聚类算法及4 个多视图聚类算法对比分析。
2.1 数据集与对比算法
本节实验将在6 个多视图数据集上展开,分别是3Sources、Notting-Hill、Reuters、Mfeat、Caltech-7、Caltech-20,具体信息如表1 所示。
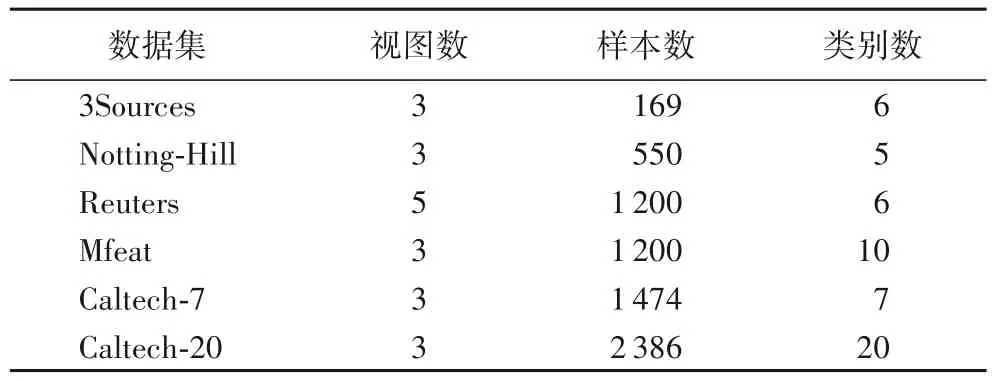
表1 实验数据集Tab.1 Experimental datasets
将MEC-VMIW 算法与5 个单视图和多视图聚类算法进行对比,对比算法分别是:SC 算法[2]、RMSC(Robust Multi-view Spectral Clustering)[33]、AWP(multi-view clustering via Adaptively Weighted Procrustes)[9]、MCGC(Multi-view Consensus Graph Clustering)[34]和CoMSC(Multiview Subspace Clustering via Co-training robust data representation)[17]。
在这些对比算法中,SC 算法是单视图聚类算法,SC-Avg表示SC 算法在所有视图取到的平均得分,SC-Best 表示SC 算法在所有视图中取到的最高得分;RMSC、AWP、MCGC 和CoMSC 是多视图聚类算法。
2.2 参数设置与评价指标
为了实验的公平性,在所有对比实验中,首先将数据集进行归一化处理。在各个数据集的实验中,每个算法均重复运行20 次,取其平均得分及标准差作为评价标准。
在MEC-VMIW 算法中,构建K近邻相似性矩阵所采用的近邻个数设置为K=10,视图互加权过程中降采样次数设置为T=10,基聚类生成过程中每个视图的基聚类个数设置为M=10。值得一提的是,本文算法对不同参数设置具有很好的鲁棒性,可在所有数据集中使用相同参数配置。在各个对比算法中,本文采用对应论文中的参数设置。
在评价指标上,本文采用归一化互信息(NMI)[31]和调整后兰德指数(Adjusted Rand Index,ARI)[27]这两个常用指标评价聚类性能,其中:NMI 的取值范围为[0,1],ARI 的取值范围为[-1,1],NMI 与ARI 的得分越高,表示所得聚类结果与真实类标越契合,即聚类性能越好。
2.3 与其他算法的对比实验
本节将在6 个多视图数据集上对MEC-VMIW 算法与5个对比聚类算法进行对比分析。各个聚类算法在数据集上的NMI 与ARI 分数分别如表2、3 所示。

表2 本文算法与其他聚类算法的NMI得分 单位:%Tab.2 NMI scores of the proposed algorithm and other clustering algorithms unit:%
如表2 所示,本文算法在4 个数据集上取得了最高NMI得分,并且MEC-VMIW 算法的平均NMI 得分为60.80%,显著高于其他对比算法。除本文算法之外,AWP 算法取得了第二高分的平均NMI 得分,仅为54.16%。
如表3 所示,本文算法在ARI 得分方面也表现出类似优势,平均ARI 得分为53.61%,显著高于取得次高的平均ARI得分45.20%。AWP 算法虽然在Caltech-7 和Caltech-20 等两个数据集上ARI 得分小幅高于本文算法,但它在3Sources、Notting-Hill、Reuters 等数据集上的ARI 得分均显著低于本文算法,特别是在Reuters 数据集上AWP 算法的ARI 得分仅为2.42%。相较于其他对比算法,本文所提出的多视图集成聚类算法也表现出更为鲁棒的聚类性能。

表3 本文算法与其他聚类算法的ARI得分 单位:%Tab.3 ARI scores of the proposed algorithm and other clustering algorithms unit:%
2.4 参数分析
本节将在6 个多视图数据集中对MEC-VMIW 算法的参数K、M的敏感性进行分析,验证MEC-VMIW 算法在不同参数配置下的聚类鲁棒性。
在构建K近邻相似性矩阵过程中,参数K表示近邻个数。为验证近邻个数K对MEC-VMIW 算法的聚类性能影响,本文令K的取值在{5,10,15,20}变化,得到在不同的K值下MEC-VMIW 算法的NMI 与ARI 得分,如图2、3 所示。由实验结果可以看到,MEC-VMIW 算法在不同的近邻数K下表现出相当稳定的聚类性能,在同一个数据集中,得到的结果的NMI 和ARI 的表现的波动趋势较为一致。MEC-VMIW 算法在3Sources、Mfeat 和Caltech-20 等数据集中,随着K的增大,得到的NMI 值呈单调递增/递降趋势,但均在K=10 之后逐渐收 敛。在Notting-Hill、Reuters 和Caltech-7 等数据集中,K∈[10,15]时得到的分数最高。由于在K=10、15、20 的得分较为稳定,不妨将K设置在[10,20]区间,可对不同数据均为较好的鲁棒性。在本文实验中,对所有数据集均采用K=10的统一设置(从结果来看,取K=10 和取K=15 的性能差不多,甚至K=10 更好;结合运算时间成本,由于K越大需要的计算时间越多,所以选择K=10 更为合理)。

图2 不同K值下MEC-VMIW算法的NMI得分Fig.2 NMI scores of MEC-VMIW algorithm at different K values

图3 近邻个数K的不同取值下MEC-VMIW算法的ARI得分Fig.3 ARI scores of MEC-VMIW algorithm at different K values
在基聚类生成过程中,M表示每个视图基聚类个数。为验证单个视图基聚类个数M对MEC-VMIW 算法的聚类性能影响,本文也令M的取值在{5,10,15,20}变化,得到在不同的M值下MEC-VMIW算法的NMI与ARI得分,如图4、5所示。

图4 每个视图基聚类个数M的不同取值下MEC-VMIW算法的NMI得分Fig.4 NMI scores of MEC-VMIW algorithm at different M values

图5 每个视图基聚类个数M的不同取值下MEC-VMIW算法的ARI得分Fig.5 ARI scores of MEC-VMIW algorithm at different M values
需要注意的是,在具有V个视图的多视图数据中,单视图基聚类个数为M则意味着多个视图的总基聚类个数为M×V。如图4、5所示,本文算法在不同M取值下表现出较稳定的聚类性能,其中M∈[10,15]是它在不同数据集下的建议取值。在本文实验中,本文对所有数据集均采用M=10的统一设置。
3 结语
本文提出了一种基于视图互信息加权的多视图集成聚类(MEC-VMIW)算法,主要过程可分为视图互信息加权和多视图集成聚类这两个主要阶段。在视图互信息加权阶段,所提算法首先对数据集进行多次随机降采样,在每次降采样数据集中构建各视图聚类结果,并以其聚类结果互评价策略得到各视图评分,进而将此降采样、构建降采样聚类、视图评价过程重复若干次以得到最终平均得分,并将之作为视图权值。在多视图集成聚类阶段,本文借助于集成聚类的思想,在各个视图中构建基聚类集合,进而将其建模至二部图结构,再以高效二部图分割算法得到最终多视图聚类结果。在多个数据集上的实验结果验证了本文所提出多视图集成聚类算法的有效性与鲁棒性。在未来研究工作中,可继续探索本文方法在缺乏多视图数据、大规模多视图数据上的进一步扩展。
