一种基于异步联邦学习的安全聚合机制
2023-07-01秦宝东杨国栋马宇涵
秦宝东,杨国栋,马宇涵
(1.西安邮电大学 网络空间安全学院,陕西 西安 710121;2.长安大学 信息工程学院,陕西 西安 710064)
近年来,人工智能技术迎来了暴发式发展。数据孤岛和数据隐私保护是人工智能技术最主要的两个挑战[1],一方面,行业顶尖的巨头公司垄断了大量的数据信息,小公司很难得到这些数据[2],使得企业与企业之间形成了一个个数据孤岛,导致企业间的差距不断拉大。另一方面,中国在2017年6月起实施的《中华人民共和国网络安全法》中指出网络运营者不得泄露、篡改和毁坏其收集的个人信息,意味着企业与企业之间在没有用户授权的情况下不能交换数据。欧盟在2018年5月发布了《通用数据保护条例》(General Data Protection Regulation,GDPR)以加强对用户数据的隐私保护和对数据的安全管理。为了有效应对数据孤岛和数据隐私安全保护问题,联邦学习(Federated Learning,FL)技术应运而生,为人工智能发展带来了新的希望[3]。
联邦学习是2016年由谷歌提出的一种保护隐私的机器学习框架[4],其主要思想是在客户端上进行本地模型的训练并将更新后的模型参数发送给服务器,然后服务器聚合客户端发送来的模型参数,以达到更新全局模型的效果[5]。由于所有本地模型都是根据存储在本地客户端的数据进行训练,因此客户端只需上传模型参数,无需上传本地数据,就可以得到全局模型[6]。这使得跨企业的模型训练在保证模型准确率的同时保证了数据安全[7]。上传和下载模型参数的过程可以看作是通信过程,在每一轮通信中,只有属于参与方的客户端才会从服务器下载中心模型参数,并作为本地模型的初始值。一旦本地训练完成,参与的客户端将更新后的参数上传给服务器,服务器通过聚合局部更新参数更新中心模型参数[8]。在此过程中,局部模型可以是任何类型的机器学习模型。然而,随着机器学习技术的发展,深度神经网络(Deep Neural Networks,DNN)被应用于许多复杂问题的解决,包括文本分类、图像分类和语音识别等[9]。因此,联邦学习中广泛采用DNN作为局部模型,但DNN模型复杂、节点众多,训练时间一般相对较长,在服务器与客户端通信时,也会导致通信开销过大等问题[10]。
目前,联邦学习的隐私保护受到了广大研究者们的重视,很多学者将联邦学习技术与秘密分享[11-13]、差分隐私[14-19]、安全多方计算和同态加密[20-21]等技术相结合,从而得到安全高效的联邦学习方案。然而,这些方案主要基于同步模型,虽然训练的模型参数精度较高,但是服务器与客户端之间的通信开销也较高。为了应对联邦学习中DNN模型在更新时通信开销过大的问题,Chen等[22]提出了一种分层异步更新模型技术。在异步学习过程中,将DNN的不同层分为浅层和深层,分别对其进行异步更新,提高了中心模型的精度和收敛性[23],该方案在通信代价和训练精度方面优于同步更新模型。为了有效解决异步联邦学习本地训练速度差异对聚合参数造成的负面影响,陈瑞峰等[24]提出了基于指数滑动平均的联邦学习方法,但该方案并不能抵御服务器与客户端的推理攻击。高胜等[25]为了解决异步联邦学习中存在的单点失效与隐私泄露等问题,一方面将区块链技术与异步联邦学习结合起来,保证其可信性,另一方面为了均衡数据隐私与模型效用,利用差分隐私中的指数机制选择模型参数,但在准确率上有明显下降。准确率表示联邦学习模型在收敛时达到的精度。基于同步模型的文献[13]和文献[20]方案,准确率分别为95.91%和98.5%,基于异步模型的文献[24]和文献[25]方案,准确率分别为92.74%和91.93%。不难发现,基于同步模型的参数准确率基本高于异步模型。因此,基于异步联邦学习的模型收敛精度有待进一步提升。
联邦学习中攻击者能够根据共享的模型参数间接获取用户的敏感信息。共享的模型参数是由用户的隐私数据训练得到,也就是说隐私数据被编码到模型参数中。通过构造相应的解码器,可以针对用户的模型参数逆向推理出用户的隐私数据,这种攻击方式称为推理攻击。联邦学习受到的推理攻击主要包括成员推理攻击和属性推理攻击两种方式。成员推理攻击是根据给定的一条记录判定是否在训练数据中,属性推理攻击是获取数据的属性信息。然而,现有研究[26-28]表明,异步联邦学习在隐私安全方面仍存在缺陷,模型参数信息会泄露用户的隐私数据,攻击者可以通过客户端上传的模型参数间接推出标签信息和数据集的成员信息。Carlini等[29]从训练用户语言数据的递归神经网络中提取出了用户的敏感数据,如特定的银行卡号。Fredrikson等[30]研究了如何从模型信息中窃取数据隐私,并通过药量预测实验实现了对线性回归模型的反演攻击,获得了患者的敏感信息。
为了提升模型收敛精度并抵抗推理攻击,拟提出一种基于异步联邦学习的安全聚合机制。在异步联邦学习的基础上结合秘密分享和同态加密等技术,保证异步联邦学习的安全性,并且在诚实但好奇的服务器下,对其客户端不公开的更新参数进行安全聚合,从而得到正确的聚合结果。
1 预备知识
1.1 联邦平均算法
联邦平均算法可以被用于DNN中的非凸目标函数[31],适用于任何形式的有限和目标函数,其计算表达式为
(1)
式中:ω为DNN的权重参数;n为数据点的个数;fi(ω)=l(xi,yi;ω)表示以ω为参数在样本(xi,yi)上的预测损失。
假设在联邦学习系统中有K个参与方,Pk是第k个参与方的数据索引集合,第k个参与方有nk个数据点,则第k个参与方根据自身样本数加权后的加权损失函数为
(2)
通过加权每个参与方的加权损失函数和数据点,得到平均损失函数
(3)
采用联邦平均算法协同训练各个服务器模型和客户端模型。服务器执行流程如图1所示。

图1 服务器执行流程
服务器具体执行步骤如下。
步骤1初始化参数ω0和T。ω0为初始全局DNN的权重,T为迭代次数。
步骤2选择客户端集合K,确定整个联邦学习系统中有|K|个客户端。
步骤3进入迭代轮,并随机选择参与方的集合m。m表示所有客户端集合K中,因主动或被动退出学习后的客户端集合,且|m|=Max(C|K|,1),C表示每一轮执行的客户端比例。


步骤6判断模型是否收敛,若模型收敛,即得到最终的全局权重;若不收敛,进入下一轮,直至模型收敛为止。
客户端执行流程如图2所示。

图2 客户端执行流程
客户端具体执行步骤如下。
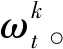
步骤2每个参与方k把本地的数据集Pk划分为批量大小为B的小批量数据,总共被划分为E份。

步骤4在全局模型权重更新的第t个回合被选中的第k个参与方会计算gk=Fk(ωt),即在当前参数为ωt的模型下,用本地数据得到平均梯度,然后服务器根据聚合梯度,其中η为学习率。
步骤5服务器将更新后的模型参数发送给各个参与方。
1.2 分层异步模型更新
降低联邦学习通信成本的最本质要求是在不影响中央模型性能的情况下上传/下载尽可能少的数据[32]。在文献[33]和文献[34]中,通过微调DNN发现两个主要特征:1)DNN的浅层学习适用于不同任务和数据集的一般特征,这意味着DNN中相对较小的一部分参数,即较浅层的参数代表了不同数据集的一般特征。2)DNN的深层学习与特定数据集的特定特征相关,并且大量参数关注特定数据的学习特征。在联邦学习中,较浅层的参数数量相对较少,且对中心模型的性能更关键。相应地,较浅层的更新频率应该比较深层的更新频率高。因此,模型中浅层和深层的参数可以异步更新,从而减少服务器和客户端之间发送的数据量。这种更新方式称为分层异步模型更新,其主要思想便是通过对以上两个特征的观察得出,通过只更新本地模型的一部分参数,减少上传或下载的数据量,从而降低联邦学习的通信成本。
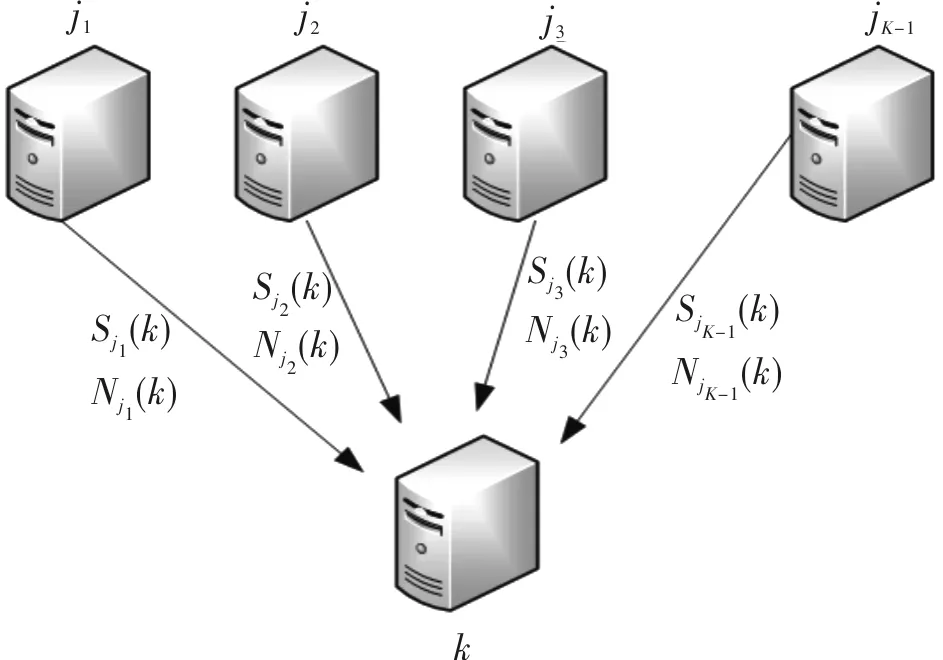
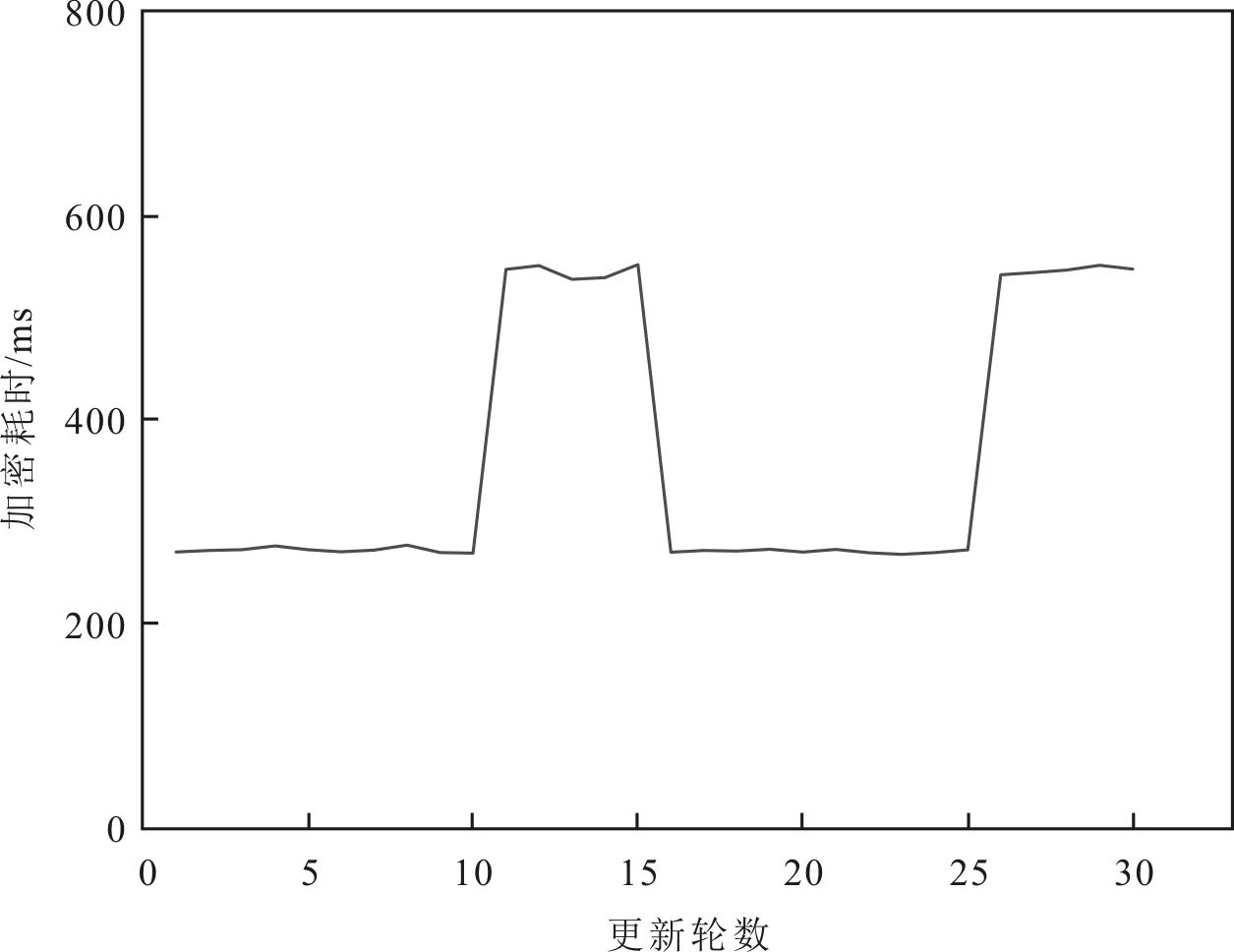
将整个DNN分为浅层学习一般特征和深层学习特定特征,分别记为ωg和ωs,ωg和ωs的大小分别为Sg和Ss,通常情况下Sg 图3 DNN浅层与深层 在异步学习策略中,浅层ωg的更新和上传/下载频率高于深层ωs。假设整个联邦学习过程被划分为多个循环,每个循环有F轮模型更新。在每个循环中,ωg将在每一轮中更新和传播,而ωs将只在f轮中更新和传播,其中f 秘密分享是一种分发、保存和恢复秘密的方法,是密码学和安全多方计算中的重要工具[35]。 假设有n个参与者,p是一个大素数,秘密空间与份额空间均为有限域GF(p),则基于该有限域进行秘密分发和秘密重构的计算过程如下。 1)秘密分发。随机选择一个GF(p)上的k-1次多项式f(x)=a0+a1x+…+ak-1xk-1,使得a0=S,在Zp中选择n个互不相同的非零元素x1,x2,…,xn,并将这n个元素发送给n个参与者,n个参与者分别计算 (4) 式中,f(xi)只有参与者i自己知道。(xi,f(xi))为参与者i的秘密份额。 2)秘密重构。考虑到至少需要k个参与者参与重构,因此假设恰好有k个参与者参与重构,根据拉格朗日插值公式 (5) 重构出秘密S,即S=f(0)=a0。 如果k-1个参与者想获得秘密S,可构造出由k-1个方程构成的线性方程组,其中有k个未知量。对GF(p)中的任一值S0,设f(0)=a0,这样可得第k个方程,并由拉格朗日插值公式得出f(x)。因此,对每个a0∈GF(p)都有一个唯一的多项式满足式(4),所以已知k-1个参与者并不能恢复出秘密S的任何信息。 Paillier同态加密是Paillier在1999年提出的,其是半同态加密算法中的加法同态加密算法,也是目前最常使用的同态加密算法之一。该加密算法包括秘钥生成、加密、解密和加法同态性等4个阶段。 c=Enc(m,r)=dmrN(modN2) (6) 3)解密阶段。密文c对应的明文为 (7) c1c2=Enc(m1,r1)Enc(m2,r2)=dm1+m2(r1r2)N(modN2) (8) 式(8)的解密结果为m1+m2,即密文的积的解密结果等于明文的和,即 Dec(c1c2)=Dec(Enc(m1,r1)Enc(m2,r2)(modN2))=m1+m2(modN) (9) 密文乘积时含有的明文是在指数上相加的,所以解密后可以得到明文相加的和。该算法的安全性建立在大整数分解问题上,即无法将大整数N进行分解得到两个素数因子p,q。该算法的正确性由模N2构成的有限循环群的性质决定,具体可参考文献[36]。 基于异步联邦学习的安全聚合机制给出了一个多客户端异步模型更新的安全聚合方案。在诚实但好奇的服务器下,允许多个用户在参与异步模型更新中进行安全的参数聚合。 每个客户端k选择自己的秘密ak,0和本地数据点数nk,并随机选择秘密参数ak,j,其中,1≤j≤h-1。根据所选秘密和秘密参数分别构造多项式 Sk(x)=ak,0+ak,1x+…+ak,h-1xh-1 (10) Nk(x)=nk+ak,1x+…+ak,h-1xh-1 (11) 式中:x为每个客户端k的身份标识号码(Identity Document,ID);h为门限值。 系统中K个客户端之间相互广播。即客户端j向客户端k发送Sj(k)和Nj(k),且Sj(k)和Nj(k)只有客户端k知道[37]。客户端之间进行广播示意图如图4所示。 图4 客户端之间相互广播 每个客户端k收集其他客户端j发送的Sj(k)和Nj(k),可分别计算得到 (12) (13) S(k)和N(k)即为客户端k得到的秘密份额Sk和总数据点数份额Nk,且Sk和Nk只有客户端k知道,对于其他客户端是保密的。客户端k将秘密份额Sk和Nk发送给服务器。服务器接收到所有客户端的Sk和Nk后,根据客户端的ID,由拉格朗日插值法恢复出总秘钥和总数据点数分别为 (14) (15) 安全聚合机制分为在客户端上执行和在服务器上执行两部分。下面将详细描述在客户端上的执行过程,具体流程如图5所示。 图5 安全聚合机制的客户端执行流程 客户端具体执行步骤如下。 步骤6若L被标记为‘否’,则直接结束。 客户端具体加密步骤如下。 (16) (17) 在服务器上的执行流程如图6所示。 图6 安全聚合的服务器执行 服务器具体执行步骤如下。 步骤1服务器首先对参数ω0和T进行初始化。ω0为DNN模型的初始权重参数,经过T轮模型收敛。 步骤2选择客户端集合K,确定整个联邦学习系统中有|K|个客户端,然后进入迭代轮。 步骤3随机选择参与方的集合m,m表示所有客户端集合K中,因主动或被动退出学习后的客户端集合,且h≤|m|≤K,若|m| 步骤4当前轮数模上R,若结果属于Q集合,则把L标记为“是”,否则把L标记为“否”。R为更新轮数的分组,Q为每组更新轮数中指定深层DNN更新的集合。为了便于后续仿真,取R=15,Q={11,12,13,14,0}。 步骤6每个客户端k在本地独立地执行模型参数更新,对更新结果进行加密,并发送给服务器。 步骤7当属于m集合的客户端均更新结束后,服务器对所有K个客户端的更新结果进行安全聚合。不属于m集合的客户端使用上一轮的更新结果进行安全聚合。 步骤8若L为‘是’,则先对深层DNN参数进行安全聚合。最后统一对浅层DNN参数进行安全聚合。 步骤9根据聚合结果更新中央模型参数,并进入下一轮模型更新,直至模型收敛。 服务器具体解密步骤如下。 步骤2若L为‘是’,则先对深层DNN参数密文进行聚合,得到密文的聚合结果 (18) 若L为‘否’,则直接跳到步骤6,对浅层DNN参数密文进行聚合。 (19) 步骤4服务器用所有客户端秘密份额Sk恢复出来的总秘钥S对掩盖的聚合参数进行抵消,得到抵消结果,即明文的聚合结果为 (20) 步骤5服务器对聚合的结果除以恢复出来的总数据点数N,得到深层DNN参数的安全聚合结果 (21) 步骤6对浅层DNN参数密文进行聚合,聚合方式与深层DNN参数密文聚合方式相同,服务器便可得到安全聚合浅层DNN的参数ωt+1,g。 安全聚合机制的设计目标是出于对异步更新模型的参数保护,保护每个客户端本地更新的参数不被其他客户端以及服务器知道。在此条件下,服务器还可以通过聚合每个参与方客户端的密文参数,然后解密得到明文的聚合参数。在此目标前提下,对基于异步联邦学习的安全聚合机制进行如下安全性分析。 客户端k选择自己的秘密ak,0,并和K个参与模型更新的客户端协商生成属于自己的秘密份额Sk,然后将秘密份额Sk发送给服务器。服务器使用至少h个客户端的ID和Sk恢复出总秘钥S,此时的总密钥S为K个客户端的秘密的和。客户端k使用秘密ak,0对明文参数进行掩盖,然后使用Paillier加密,进一步对掩盖的明文参数进行加密,将加密结果发送给服务器。若攻击者与服务器不共谋,则有以下结论。 定理1假设攻击者与服务器不共谋,则客户端的更新密文满足语义安全性。 证明由于Paillier加密方案具有语义安全性,即给定任意两个长度相等的消息m0和m1,任意概率多项式时间攻击者区分密文c0=Enc(m0,r0)和c1=Enc(m1,r1)的概率是可忽略的,所以对于任意攻击者(与服务器不共谋)从客户端密文中获取训练参数的任何信息的概率是可忽略的。 通过定理1可以看出,对客户端而言,可以获取的信息有Paillier加密的公钥、每个客户端的ID,以及自己的秘密和秘密份额。假设存在恶意客户端k,想通过已有信息分析出其他客户端训练参数的明文信息。由于其他客户端都使用了Paillier加密,所以,即使客户端k截获了其他客户端发送给服务器的参数密文,仍然无法解密得到其他客户端的参数明文。 定理2若攻击者与服务器和部分客户端共谋,并且合谋的客户端数量少于门限值h时,攻击者无法获取其他客户端训练参数的任意信息。 证明根据门限秘密共享的性质可知,对于一个秘密S的(h,n)门限秘密共享方案,当参与恢复秘密的用户数量少于门限值h时,通过用户的秘密份额无法得到S的任何信息。也就是说,对于这些用户而言,S在信息论意义下是随机的。因此,对于任意消息m,掩盖后的消息m+S满足一次一密安全性。所以,攻击者通过与服务器和部分客户端合谋,无法获取其他客户端训练参数的任何信息。 通过定理2可以看出,对于服务器而言(即攻击者仅与服务器合谋),可以获取的信息有Paillier加密的公钥和私钥,每个客户端的ID和秘密份额Sk。此时,服务器通过Paillier加密的私钥对客户端发送的参数密文进行解密,解密后只能得到被客户端秘密ak,0掩盖后的参数信息。服务器通过每个客户端的ID和秘密份额Sk,只能恢复出所有参与模型更新客户端的秘密和,并无法分析出每个客户端的具体秘密。只有服务器将所有参与模型更新的客户端密文进行聚合并解密之后,才能通过恢复出的客户端的秘密的和S对聚合结果进行抵消,得到正确的聚合结果明文。 如果部分恶意客户端与服务器进行合谋攻击,例如服务器把自己的Paillier私钥发送给部分恶意客户端,恶意客户端用服务器发送的私钥对截获的其他客户端参数密文进行解密,解密后只能得到其他客户端用各自秘密掩盖后的参数信息。由于恶意客户端的数量少于门限值,所以恶意客户端无法获得其他客户端的秘密,从而无法得到其他客户端的参数明文。同理,如果部分恶意客户端把自己的秘密发送给服务器,服务器用恢复出来的秘密和把部分恶意客户端的秘密剔除,此时服务器仍然无法分析出其他客户端的秘密。因此,服务器也无法得到其他客户端的参数明文。 根据定理1和定理2,尽管服务器可以获取客户端的训练参数之和,但是无法获取单个客户端的训练参数,从而能够抵抗服务器的推理攻击。也就是说,该机制保证了服务器以及部分恶意客户端无法得到每个合法客户端的明文参数的条件下,服务器依然能够从聚合的密文中恢复出正确的聚合参数。 下面主要讨论基于异步联邦学习的安全聚合机制的计算效率。实验中所使用的设备配置为Intel(R) 酷睿(TM) i7-6700HQ CPU @ 2.60 GHz。由于资源有限,实验使用了多线程的思想,即在同一台设备上创建多个线程模拟多个客户端与服务器之间的交互。 实验所使用的数据集从MNIST(Mixed National Institute of Standards and Technology)数据集中选择,MNIST数据集[38]包含60 000个训练数据样本和10 000个测试数据样本。为了模拟客户端在非独立同分布的数据集上训练的效果,首先将数据集按照数字标签排序并分为n份,然后通过调整用户之间的数据类型,得到非独立同分布的数据集。 实验中,客户端的总数为K,参与更新的最少客户端数量为h,K和h直接影响学习的效果。更新轮数的分组为R,每组更新轮数中指定深层DNN更新的集合为Q,R和Q直接影响异步模型更新的收敛性和精度。p、q和N的大小直接影响加密耗时。设置客户端数量为20个,每轮至少需要3个客户端参与更新,模型更新轮数以15轮分为一组,每组更新轮数中指定深层DNN更新的集合为{11,12,13,14,0},用于Paillier加密的大素数p和q均取512 bit,模N为1 024 bit。系统参数初始化如表1所示。 表1 系统参数初始化 为了分析异步联邦学习和同步联邦学习的准确率和效率,分别对异步模型更新和同步模型更新进行了仿真实验,结果如图7所示,其中每迭代一次意味着模型参数更新一次。 图7 两种模型准确率对比结果 从图7中可以看出,两种模型更新的准确率都随着迭代次数的增多而增加,异步模型更新在迭代30次之后趋于收敛,同步模型更新在迭代70次之后趋于收敛,趋于收敛时的准确率均达到95%以上。这说明异步联邦学习在效率方面优于同步联邦学习,而且准确率也与同步联邦学习相当。所提安全聚合机制基于异步联邦学习,因此在保证学习效率的基础上又保证了安全性。 客户端在模型训练的每轮都要独立的对训练结果进行加密。因此在实验中,模型更新一轮,即测试一次加密耗时。由于每个客户端独立训练,所以取本轮客户端中加密耗时最长的值,作为客户端本轮的加密耗时,实验结果如图8所示。 图8 客户端加密耗时 异步模型更新的每15轮中,前10轮只对浅层DNN权重参数加密,而后5轮既对浅层DNN权重参数加密,又对深层DNN权重参数加密。因此可以分析出每15轮更新,前10轮加密耗时较短,后5轮加密耗时较长。由图8可以看出,前10轮加密耗时大约在170 ms左右,后5轮加密耗时大约在350 ms左右,客户端每轮加密的平均耗时为226 ms。 同样地,模型每更新一轮,即测试一次解密耗时。服务器接收到所有参与训练客户端的上传密文后,开始进行安全的聚合操作,并测试对聚合结果进行解密所消耗的时间,实验结果如图9所示。 图9 服务器解密耗时 参与模型训练的客户端,在异步模型更新的每15轮中,前10轮只发送浅层DNN的权重参数密文,后5轮既发送浅层DNN的权重参数密文,也发送深层DNN的权重参数密文。因此,服务器在前10轮只需要对浅层DNN的权重密文进行解密,在后5轮要对浅层DNN权重密文和深层DNN权重密文进行解密,可以分析出每15轮更新,前10轮的解密耗时较短,后5轮解密耗时较长。由图9可以看出,前10轮解密耗时大约在220 ms左右,后5轮解密耗时大约在560 ms左右,服务器每轮解密的平均耗时为363 ms。 对异步模型更新的安全聚合,不可避免地增加了时间消耗,但是异步模型更新的最大优点就是降低服务器与客户端之间的通信开销,极大地提升了学习效率。通过实验仿真可以看出,加密和解密的平均耗时基本控制在0.2~0.4 s。因此,在较小的时间开销内,基于异步联邦学习的安全聚合机制换取了模型安全的聚合。 针对异步联邦学习中的推理攻击,利用秘密分享和Paillier同态加密等技术,提出多个客户端模型参数的安全更新与聚合方法,从而实现分层异步联邦学习的安全聚合机制,确保了客户端在不公开模型更新参数的情况下,服务器能够进行安全聚合,并得到了正确的聚合结果。安全性分析证明,该机制能够有效抵御来自服务器和用户的攻击。实验结果表明,该机制在学习效率和准确率方面表现优异,能够在较小的时间开销内,换取模型安全的聚合。
1.3 秘密分享
1.4 Paillier同态加密


2 安全聚合机制
2.1 秘密协商

2.2 客户端执行
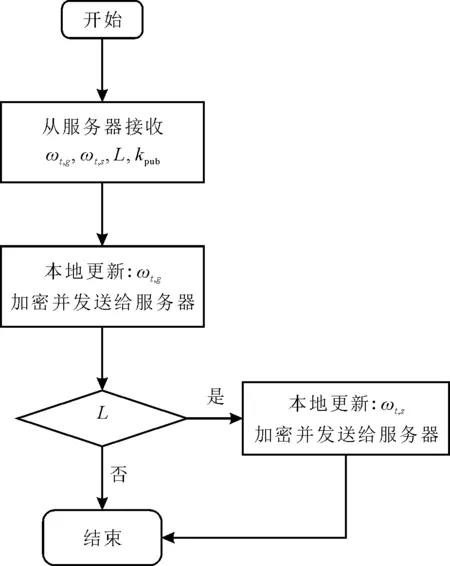

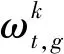






2.3 服务器执行





3 安全性及效率分析
3.1 安全性分析
3.2 效率分析



4 结语
