基于YOLOv5 和U-Net3+的桥梁裂缝智能识别与测量
2023-06-03余加勇刘宝麟尹东高文宇谢义林
余加勇,刘宝麟,尹东,高文宇,谢义林
(1.湖南大学 风工程与桥梁工程湖南省重点实验室,湖南 长沙 410082;2.湖南大学 土木工程学院,湖南 长沙 410082;3.江苏省水利科学研究院,江苏 南京 210017)
截至2020 年末我国共有公路桥梁91.28 万座,其中特大桥梁6 444座,由于桥梁功能退化和结构损伤,我国公路桥梁的总体现状不容乐观,危桥数量高居不下[1].对桥梁结构进行外观检测是桥梁运维阶段的重要工作之一,近年来基于无人机、人工智能等新兴技术的桥梁结构外观智能检测方法得到迅速发展,克服了传统人工检测方法效率低、危险性高的缺点,大幅提高了桥梁外观检测的数字化、智能化水平,无人机桥梁裂缝智能检测方法已成为研究热点[2-3].由于桥梁结构表面裂缝形态各异、图像背景复杂、环境噪声干扰大等因素影响,采用传统数字图像处理方法识别桥梁裂缝效果不佳,难以满足工程需求[4].
深度学习被广泛应用于计算机视觉、自然语言处理等领域,将其应用于桥梁结构裂缝的检测,是一种理想的智能检测途径[5].相较于传统数字图像处理,深度学习算法避免了复杂的图像预处理过程,可有效应对形态各异、背景复杂的裂缝[6].此外,随着无人机在裂缝检测中得到越来越广泛的应用,深度学习算法具备强大的鲁棒性以及背景噪声滤波能力,足以有效应对由于环境条件影响而导致的无人机图像噪声干扰、模糊等问题[7-8].
基于深度学习的裂缝检测算法包括裂缝识别定位算法和裂缝分割算法两类.裂缝识别定位算法是通过矩形框或者掩膜输出图像中裂缝的定位及分类信息,主要包含以区域卷积神经网络(Region-Based Convolutional Neural Network,R-CNN)为基础的Fast R-CNN、Faster R-CNN、Mask R-CNN 等两阶段检测算法,及以YOLO 为代表的单阶段检测算法.两阶段检测算法首先通过区域生成网络(Region Proposal Network,RPN)对图像进行候选区域提取,然后进行分类以及边界框回归,实现裂缝识别定位;而单阶段检测算法YOLO 舍弃了区域提取步骤,将检测任务作为回归问题进行求解,直接得到图像中裂缝的位置及类别信息.相较于两阶段算法,基于YOLO 的裂缝检测算法速度更快[9],随着算法的不断改进,YOLOv2、YOLOv3、YOLOv4 等被相继提出,算法的检测精度得到巨大提升,被广泛应用于结构裂缝的智能识别.Majidifard 等[10]应用YOLOv2 与Faster R-CNN进行裂缝智能识别,试验表明YOLOv2 模型识别精度更高.Zhang 等[11]提出了一种改进的YOLOv3 模型应用于桥梁病害检测,通过引入焦点损失函数(Focal Loss)以及新的迁移学习方法,有效提升了病害识别准确率.目前,YOLOv5 是最新的YOLO 算法,其识别精度与效率以及网络的灵活性都得到大幅提升,可实现裂缝实时高精度检测[12].
裂缝图像分割算法是对图像每一像素进行二分类,分割出图像中的裂缝像素.图像分割算法主要包含全卷积神经网络(Full Convolutional Networks,FCN)、U-Net等.FCN是在VGG网络的基础上将全连接层转换为卷积层,并且通过转置卷积对特征图上采样,使特征图还原到原图大小,从而对图像每一像素进行预测,实现裂缝图像分割[13].而U-Net 是基于FCN 改进的图像分割网络,网络采用编码-解码的对称结构,并采用跳跃连接,融合低级语义特征与高级语义特征,极大地提升了模型分割精度,被广泛应用于医学图像分割.在裂缝图像分割方面,Liu 等[14]将U-Net 网络应用于混凝土裂缝检测,对比FCN 网络,U-Net 网络可通过更小的训练集达到更高的精度.U-Net 网络虽然在分割任务中取得了不错的效果,但网络仅连接了同尺寸特征图,并未融合多尺度的特征信息.因此,在U-Net网络基础上,U-Net3+对网络的跳跃连接方式、损失函数等进行了改进,相较于U-Net 或其他图像分割网络,U-Net3+分割精度与速率更高[15].
YOLOv5 算法虽然可实现快速高精度的裂缝识别定位,但无法从图像中提取出裂缝进而获取宽度等信息[16];而U-Net3+算法虽然能够精确提取裂缝像素,但由于是对图像每一像素进行二分类,因此相较于YOLOv5,裂缝分割算法计算成本更高且耗时更多[17].为此,结合YOLOv5 裂缝识别定位算法与UNet3+裂缝分割算法,将YOLOv5 算法识别的裂缝图像作为U-Net3+算法的输入,充分发挥YOLOv5算法快速、高精度的优势,同时避免U-Net3+算法对不包含裂缝的图像进行分割,可极大地降低模型计算成本并提升检测效率.基于此,本文集成YOLOv5 目标检测算法、U-Net3+图像分割算法以及八方向搜索裂缝宽度测量法,提出了一体化的桥梁结构裂缝智能检测方法,并将其应用于大跨桥梁结构裂缝检测.
本文首先以深度学习YOLOv5 与U-Net3+算法为基础,构建了包含桥裂缝识别定位、裂缝分割、宽度测量模块的桥梁裂缝智能检测算法,并采用Python3.7 编写模块程序;然后采用4 414 张和908 张有标记信息的图像分别进行裂缝识别定位模型和裂缝分割模型训练;最后以无人机航拍的桥梁索塔裂缝图像为测试对象,采用上述深度学习算法进行裂缝智能检测.
1 裂缝智能检测算法与实现
桥梁结构裂缝智能检测算法主要包括裂缝识别定位、裂缝分割、宽度测量三部分,如图1 所示.首先通过YOLOv5 裂缝识别定位模型检测测试图像是否包含裂缝;然后针对包含裂缝的图像,通过U-Net3+裂缝分割模型提取裂缝像素,输出裂缝二值图像;最后通过图像去噪,裂缝骨架图与边缘图提取以及八方向搜索裂缝宽度测量法,获取裂缝形态及宽度信息.
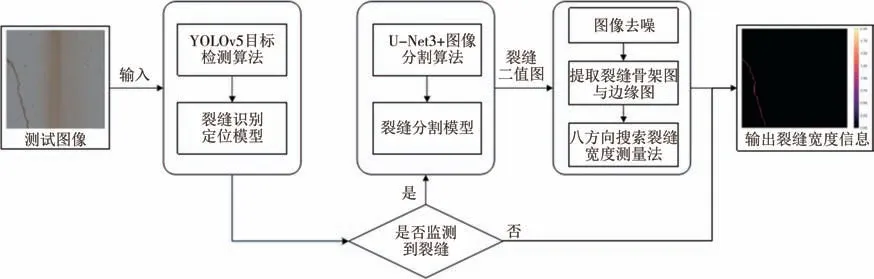
图1 集成YOLOv5和U-Net3+的裂缝智能检测算法Fig.1 Crack intelligent detection algorithm with Integrated YOLOv5 and U-Net3+
1.1 YOLOv5裂缝识别定位算法
YOLOv5 是最新的YOLO 算法,本研究采用编程语言Python3.7 以及Pycharm 平台搭建YOLOv5 裂缝识别定位模型,并且通过优化宽度参数与深度参数来增加模型深度以及特征图通道数,提升模型特征提取能力.同时采用DIoU-Loss[18]对网络边界框损失函数进行改进,进一步提升模型识别精度.YOLOv5裂缝识别定位模型由骨干网络、颈部网络、预测端三个部分组成,网络结构如图2所示.
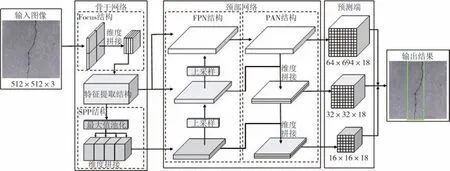
图2 YOLOv5裂缝识别定位网络结构Fig.2 Network structure of crack identification and location based on YOLOv5
骨干网络是模型的特征提取部分,首先通过 Focus 结构对图像进行“切片”,将输入图像长宽两个维度的特征信息叠加至通道维度,实现图像下采样,同时减少图像特征信息丢失.然后利用CSPDarknet构建模型的特征提取结构,获取图像特征信息.最后采用SPP 结构通过四个不同大小的核分别对输出特征图进行最大值池化操作,再进行拼接,获取图像多尺度特征信息,从而提升模型精度.
颈部网络是模型的特征融合部分,其结合FPN结构与PAN 结构,通过对骨干网络的输出特征图进行上采样,同时将不同层的特征图进行通道维度拼接,更好地融合了图像的高层与低层语义信息,从而增强模型特征提取能力.
预测端是模型的预测输出部分,YOLOv5沿用了YOLOv3的多尺度预测策略,采用三个尺度的特征图分别做独立检测,优化多尺度目标检测效果.同时利用非极大值抑制方法对冗余的目标预测边界框进行筛除,输出最佳的目标边界框预测结果.
1.2 U-Net3+裂缝分割算法
U-Net3+是基于U-Net 改进的深度学习分割网络,网络结构如图3 所示.本研究采用编程语言 Python3.7 搭建U-Net3+裂缝分割模型,模型沿用了U-Net 网络的编码-解码的对称结构.编码器通过包含3×3 卷积层,批量归一化层以及ReLU 激活函数的卷积操作,提取图像语义特征,并进行2×2 最大值池化下采样,减小特征图像大小.解码器采用全尺度的跳跃连接方式,将编码器同尺度及大尺度特征图与解码器小尺度特征图进行结合,充分利用多尺度的特征信息.同时对特征图进行上采样,将其还原至原图大小,从而输出图像每一像素的分类结果.此外,为了排除其他对象的干扰,模型通过在编码器最后一层添加预测输出模块,判断输出图像是否有目标对象,避免出现过度分割现象.同时将解码器每一部分的分割结果,输入混合损失函数,对解码器输出进行监督优化,进行全尺度的深度监督,进一步提升模型分割精度.
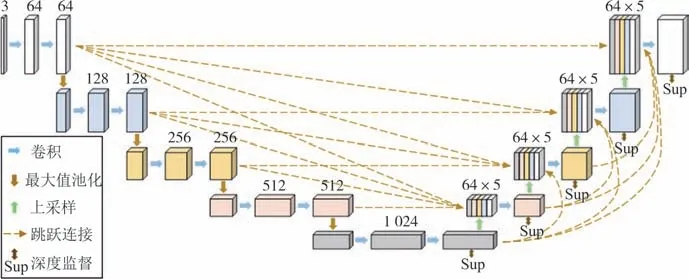
图3 U-Net3+网络结构Fig.3 U-Net3+network structure
1.3 八方向搜索裂缝宽度测量法
如图4 所示,八方向裂缝宽度测量法主要包括图像去噪、裂缝骨架及边缘提取、裂缝宽度测量三个步骤,均通过编程语言Python3.7 进行编写实现.首先通过连通域去噪删除像素数小于预设置阈值的连通域,去除干扰像素,保留真实的裂缝信息;然后通过形态学处理将裂缝细化,获取单像素的裂缝骨架,同时采用Canny 边缘检测算法,通过计算裂缝二值图像灰度梯度,寻找图像边缘及获取裂缝边缘图;最后利用八方向搜索法计算裂缝宽度.
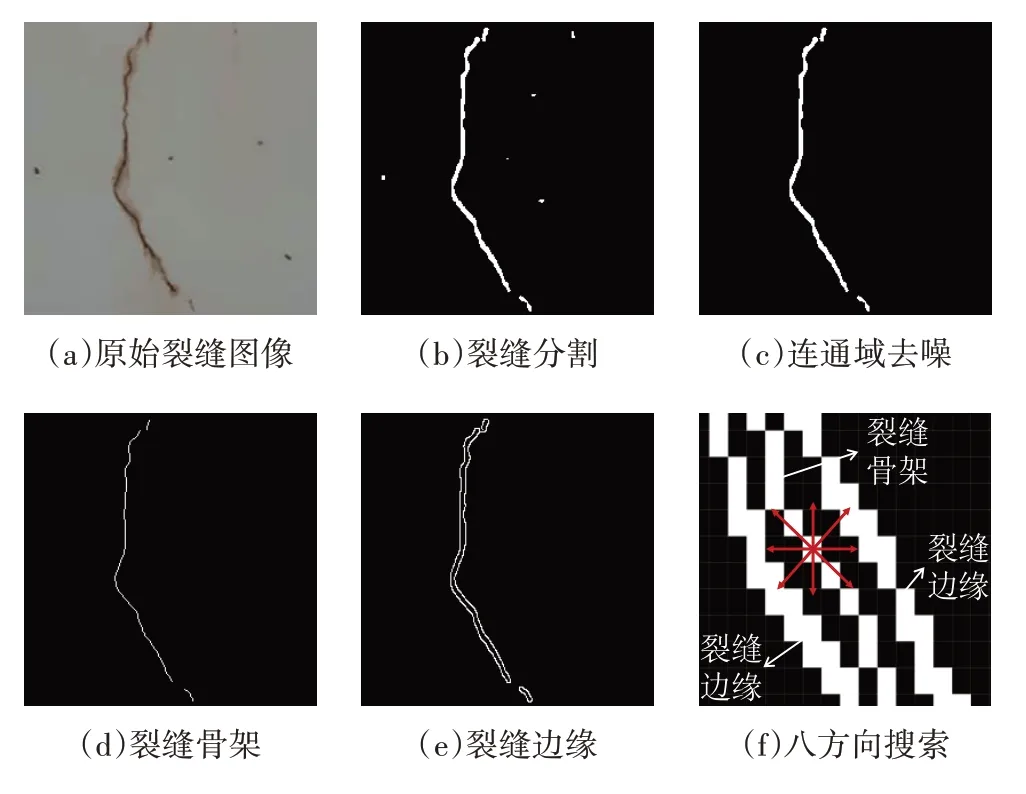
图4 裂缝宽度测量Fig.4 Crack Width Measurement

图5 裂缝检测模型构建流程Fig.5 Process of developing crack detection Model
八方向搜索法以裂缝骨架图的每个裂缝像素为起始点,在裂缝边缘图上从水平0°开始,间隔45°逆时针旋转,从八个方向搜索裂缝边缘像素,统计各方向起始点与裂缝边缘像素之间的像素数量,记为ni(i=1,2,…,8),如图6(f)所示.计算0°和180°、45°和225°、90°和270°、135°和315°四个直线方向的裂缝宽度di(i=1,2,3,4):

图6 裂缝识别图像样本Fig.6 Crack identification image sample
取d1,d2,d3,d4的最小值dmin为裂缝骨架上该点的裂缝像素宽度.重复上述步骤,最终获取裂缝骨架每一裂缝像素的宽度信息.并且根据每像素对应的物理尺寸,计算裂缝的实际宽度,计算公式如下:
式中:D为裂缝实际宽度;J为每像素代表的实际物理尺寸.
2 裂缝检测模型训练
裂缝检测模型训练首先需要建立裂缝识别定位数据集与裂缝分割数据集,同时将数据集划分为训练集和验证集并采用数据增强处理后输入网络,最后利用Google Colab 云GPU计算平台,设置好训练参数,进行模型训练,如图5 所示.模型通过卷积运算学习裂缝数据集特征,利用反向传播方法不断优化网络参数,最小化训练集上的误差,达到裂缝识别定位与分割的目的.
2.1 YOLOv5裂缝识别定位模型训练
本研究通过网络共享数据集,共收集4 414张不同背景裂缝图像,用于制作裂缝识别定位数据集.数据集包括大小为512×512 pixels的裂缝图像824张和大小为256×256 pixels 的裂缝图像3 590 张,并以4∶1的比例将数据集分为训练集和验证集,即3 531张图像作为训练集,883 张图像作为验证集.数据集利用LabelImg 图像标注软件注释上述全部图像所包含的裂缝信息,如图6 所示.为提高模型泛化能力,增强鲁棒性,利用图像亮度与对比度调整及添加运动模糊等数据增强手段,对数据集样本数量进行扩充.
裂缝识别定位模型训练基于Google Colab 云GPU 计算服务平台,并采用迁移学习方法,将在COCO 数据集预训练完成的YOLOv5 模型作为初始模型,优化模型训练速度,并设置训练批量大小为32 张、输入图像512×512 pixels、最大训练轮数为 2 000 次.模型整体训练时间为30 h,同时为防止训练过程出现过拟合现象,本研究采用网络输出的最佳训练权重来构建裂缝识别定位模型.
2.2 U-Net3+裂缝分割模型训练
裂缝分割数据集包括908张256×256 pixels裂缝图像,由两部分组成.第一部分为采用LabelImg 图像标注软件注释的200 张256×256 pixels 裂缝图像,如图7 所示;第二部分包括708 张256×256 pixels 裂缝图像,是采用大小256×256 pixels、重叠率50%的滑窗,对CFD 数据集中118 张480×320 pixels 裂缝图像进行切分而成.

图7 裂缝分割图像样本Fig.7 Crack segmentation image sample
裂缝分割模型训练基于Google Colab 云GPU 计算服务平台,训练参数设置:训练批量大小为4 张,学习率为1×10-4,最大训练轮数为300 次.模型训练时间为5 h,采用网络输出的损失最低时的权重来构建裂缝分割模型.
3 裂缝检测模型测试与评估
3.1 测试对象
模型测试以湖南省某斜拉桥索塔为对象,验证裂缝识别定位模型和图像分割模型的精度和效率.
试验采用大疆M210-RTK 无人机进行索塔图像采集.该无人机搭载Zenmuse X5S 云台相机以及 45 mm 奥林巴斯定焦镜头,并采用“弓”字形飞行路线由塔底向塔顶拍摄,如图8 所示.试验采用DJI GO4 软件控制无人机,利用无人机前视视觉传感器获取与索塔表面的距离,控制无人机航线两端与索塔表面距离为10 m,依据M210-RTK 精确定位信息使得航线与索塔表面平行,并设置镜头垂直于航线,无人机航向与旁向拍摄重叠率均为50%,具体飞行参数如表1 所示.最终获取485 张5 280×2 970 pixels索塔原始图像用于测试集样本制作.

表1 图像采集参数Tab.1 Image acquisition parameters

图8 测试图像采集Fig.8 Acquisition of test images
为了达到模型最佳检测效果,同时避免细小裂缝被切分,将索塔图像进行25%重叠率的重叠裁剪,裁剪图像大小为512×512 pixels.此外,模型测试采用Intel core i7-9 700f 处理器、NVIDIA GeForce RTX 2 060 6 GB显卡、64 GB内存的计算机硬件环境.
3.2 模型评估
裂缝识别定位模型评估旨在检验模型对于测试图像中裂缝准确识别定位的能力.真阳性(Ture Positive,TP)表示测试图像中的裂缝被成功识别与定位,假阳性(False Positive,FP)表示测试图像中的非裂缝目标被误识别为裂缝,假阴性(False Negative,FN)表示测试图像中的裂缝未被成功识别,真阴性(Ture Negative,TN)表示测试图像中非裂缝目标未被误识别为裂缝,如表2所示.

表2 裂缝识别定位模型评估矩阵Tab.2 Evaluation matrix of crack identification and location model
裂缝分割模型评估旨在检验模型对于图像每个像素精确分割的能力,因此需要首先采用LabelImg算法对测试图像的裂缝轮廓进行精确标记.由于人工手动标记的裂缝图像样本中非裂缝像素与裂缝像素之间存在过渡区域,因此与标记的裂缝像素相邻2个像素之内的分割像素均被视为正确分割.
本研究引入评价指标准确率(Precision),召回率(Recall),F1分数对裂缝识别定位模型、裂缝分割模型进行性能评估.将测试图像输入裂缝检测模型,并分别统计识别定位模型与分割模型测试结果的TP、FP、FN 数量,最终计算评价指标P、R、F1.P表示所有预测为阳性的样本中,被正确检测所占的比例.R表示所有实际存在的阳性样本中,被正成功检测的比例.F1分数是衡量模型性能的综合指标,被定义为准确率与召回率的调和平均数,F1分数越大表示模型性能越强.评价指标具体计算公式如下:
3.3 结果分析
将测试图像输入裂缝检测模型,首先通过本文训练的YOLOv5 网络模型进行裂缝识别定位,然后利用训练的U-Net3+网络模型进行裂缝分割,最终采用八方向裂缝宽度测量法获取裂缝宽度信息,示例结果如图9 所示.无人机检测未发现长宽裂缝,短小裂缝可能是混凝土表层劣化或涂层开裂的显现.

图9 桥梁裂缝智能检测示例Fig.9 Examples of intelligent detection of bridge cracks
(1) 裂缝识别结果分析
如图9(b)所示,YOLOv5 识别定位模型通过边界框进行裂缝定位并标记类别与概率信息.模型对于横向裂缝和纵向裂缝的准确率、召回率、F1分数均在90%以上,网状裂缝识别准确率、召回率、F1分数分别为91.67%、84.62%、88%,如表3 所示.由于测试图像网状裂缝较少,且网状裂缝训练样本不足,因此网状裂缝召回率偏低.模型的总体准确率、召回率和F1分数分别为91.55%、95.15%和93.32%.因此,YOLOv5目标检测算法可实现高精度的裂缝识别定位.

表3 YOLOv5裂缝识别结果Tab.3 Results of Crack Identification using YOLOv5 %
(2) 裂缝分割及宽度测量结果分析
将被YOLOv5 网络模型成功识别的裂缝图像输入U-Net3+裂缝分割模型,模型通过将图像裂缝像素值设置为255,非裂缝像素值设置为0,对裂缝图像进行分割,如图9(d)所示.经统计,U-Net3+裂缝分割结果的总体准确率、召回率和F1分数分别为93.02%、92.22%和92.22%,模型三项评价指标均超过90%.因此,U-Net3+裂缝分割模型可以准确从图像中提取裂缝像素,实现裂缝精确分割.
最终通过八方向搜索裂缝宽度测量法对UNet3+裂缝分割图像进行去噪处理,提取裂缝边缘与骨架,计算裂缝宽度与长度.然后,根据所测得的裂缝各点宽度信息,计算裂缝平均宽度与最大宽度,裂缝宽度可视化结果如图10所示.

图10 裂缝宽度信息可视化图(单位:mm)Fig.10 Visualization of Crack Width Information(unit:mm)
(3) 裂缝检测方法对比分析
本文集成YOLOv5 以及U-Net3+算法进行裂缝检测,裂缝识别与分割准确率分别为91.55%、93.02%,均高于文献[19]中改进YOLOv3 方法的裂缝识别准确率(89.16%)以及文献[20]中CrackUnet方法的裂缝分割准确率(91.45%).此外,在本试验的测试环境下,YOLOv5裂缝识别定位模型平均检测一张512×512 pixels 测试图像的时间约为20 ms,可实现裂缝实时识别.而U-Net3+裂缝分割模型的平均处理时间约为2 805 ms,处理效率远远低于裂缝识别定位模型.因此,对于经过重叠裁剪后被切分为91张测试图像的索塔图像来说,若包含裂缝的测试图像约为30%,则采用集成YOLOv5 与U-Net3+的裂缝检测方法可比仅采用U-Net3+裂缝分割模型进行裂缝检测节约70%的处理时间.
4 结论
1)本文集成YOLOv5 目标检测算法、U-Net3+图像分割算法及八方向搜索裂缝宽度测量算法,提出了桥梁裂缝智能化检测方法,可实现桥梁裂缝高精度识别、分割与测量的一体化,同时有效提升了裂缝的检测效率.
2)对YOLOv5 网络宽度及深度参数与边界框损失函数进行优化调整,训练并构建了裂缝识别定位模型;引入结合深度监督策略及预测输出模块的UNet3+算法,训练并构建了裂缝分割模型;同时结合连通域去噪、边缘检测、形态学等建立了八方向搜索裂缝宽度测量方法.
3)以无人机采集的索塔图像为测试对象,对模型性能进行评估.裂缝识别准确率、召回率及F1分数分别达到91.55%、95.15%和93.32%,裂缝分割准确率、召回率和F1分数分别达到93.02%、92.22%和92.22%.测试结果表明,所提出的裂缝检测方法可对图像中的裂缝进行快速精确地识别与分割,并获取裂缝宽度信息.无人机检测未发现长宽裂缝,短小裂缝可能是混凝土表层劣化或涂层开裂的显现.
4)本文构建的深度学习裂缝检测方法成功应用于高耸桥梁索塔裂缝检测,可以继续丰富模型训练集的样本数据,提高模型泛化能力,进而推广应用于高层建筑、风电结构等领域的裂缝智能检测.
