基于层次梯度挖掘的数据智能调度算法仿真
2023-05-31周晓晶
周晓晶,谷 钰
(长春工业大学,吉林 长春 130012)
1 引言
互联网技术和数字化进程的日益发展,数据开始呈爆炸式趋势增加,传统计算模式已经无法满足当前的处理需求。同时在上述背景下,各种商业化计算模式已经出现,全部应用程序和数据的IT资源应用较为广泛,结合网络服务方式为用户提供便利。虽然用户能够实时访问大量的数据和资源,但是,获取适配的资源和数据配置难度较大。用户如何合理有效利用这些资源成为当前研究的主要内容,其中包括数据调度[1,2]问题。
在此背景下,相关专家给出了一些较好的研究成果,例如王晓雷等人[3]优先构建虚拟网络功能调度模型,将功能链的服务时间最小化。同时通过Q-learning动态调度算法,优化虚拟网络功能的调度顺序和虚拟机选择问题,最终实现优化调度。聂黎等人[4]通过染色体编码和解码方案以及适应度函数,提出一种新的博弈调度模型,通过博弈调度求解算法获取模型的最小纳什均衡,实现优化调度。
但是由于上述两种方法未能在实际研究过程中应用层次梯度挖掘方法,导致资源负载不均衡,执行费用较高、调度所需时间较长。设计一种新的层次梯度挖掘的数据智能调度算法。优化资源负载的均衡性,挖掘数据局部频繁项。根据数据挖掘结果,构建数据智能调度模型,可优化资源负载的均衡性,降低调度的耗时。利用自适应遗传蚁群优化算法对模型求解,最终实现数据智能调度的择优,选择费用最低的调度方案。
2 算法设计
2.1 数据层次梯度挖掘步骤
1)设定数据源为D=(O,I),其中,O和I分别代表数据对象和属性的有限集合,其中数据属性即一个项目,可以表示为I={i1,i2,i3,…,in}。数据对象可以被称为事务,主要采用通过不同的属性值[5]进行标识。
2)在数据源D中,含有大量项目集X的数目也可以称为X的绝对支持数,表示为X.sup 。
3)在D中,假设X.sup|D|≥minsup ,其中,|D|代表数据源记录总数,项目集X为频繁项,这种动态变化的最小支持度阈值也称为层次梯度,将其表示为LadderDegree(L),L代表挖掘深度。在本次研究过程中,LadderDegree(L)代表一个深度函数。
4)数据库是通过不同的层次概念建立的,各个数据库中不包含1-频繁项目X,全部都是由1-频繁项目X后面的全部项目构成,数据库即层次业务数据库。
5)在数据源D中,抽取全部含有挖掘主题的数据记录,进而构成全新的挖掘主题数据库。
6)通过挖掘主题形成主题数据库。然后层次梯度的概念进行搜索,直至深度搜索结束,形成局部最大的频繁项目集[6,7]。同时统计出最大频繁项目集在D上的统计数,最终形成关联规则。
7)主站点通过Web Services捕获各个异构站点数据形成全新的频繁项主题数据库。通过弱化熵模型,分析全部数据,最后获取所需要的关联规则,通过关联规则得到最终的数据挖掘结果。
2.2 数据智能调度模型构建
作为一种全新的计算模式,数据的相关体系框架一定能够完成数据集合分布处理。全部需要完成调度的任务均是由无数个任务模型构成的,一般能够划分为两种类型,独立任务和工作任务。对于各个独立任务而言,需要结合任务粒度将各个独立任务进行分割,使其满足分布式处理需求。同时,各个独立任务之间存在密切的联系。
对于工作流任务而言,节点也是通过分布式进行处理,确保各个节点满足相互作用的关系。
为更加详细描述不同数据之间的关联性,需要将不同的工作任务进行全面融合,其中采用的任务模型如图1所示。T0~T9为任务序号。

图1 任务模型
数据主要利用虚拟技术将不同资源对应的节点转换为虚拟集群[8],并且结合数据的属性信息对数据进行统一化处理,将其全部传输至数据中心完成处理和调度。
数据任务调度就是将各种不同的任务利用任务列表传输至对应的虚拟机进行调度处理。当全部数据完成分配工作后,利用虚拟机进行调度。其中,衡量调度方案优劣的标准即在数据调度过程中各种开销的取值。利用对M个虚拟机和N个调度任务所在环境的计算,即可获取MN中的分配调度策略;分别对数据的属性和虚拟机的属性等进行组合目标优化,在MN种调度方案中获取满足调度需求的最优解。当任务完成分配,调度方案就会被数据中心代理转交至数据中心进行对应的数据智能调度处理。
有关于数据智能调度模型的描述如下所示:
1)对应任务的列表位置为T={t1,t2,t3,…,tm},对应该任务的数据总量位置为Numi。
2)VM={m1,m2,…,mn}为虚拟机列表,将各个虚拟机的处理能力设定为Mips,各个虚拟机的价格为Pricev。
3)执行时间
数据任务的总执行时间为
totaltime=max(timeVM1,timeVM2,…,timeVMm)
(1)
式中,totaltime代表总执行时间。
单一虚拟机的执行时间为

(2)
式中,timeVMi代表单一虚拟机[9]执行任务所需要的总时长;size代表虚拟机的任务总数;Mips代表第i个虚拟机的处理能力。
4)执行费用
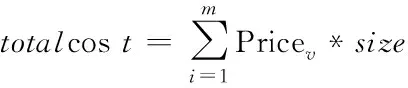
(3)
式中,Pricev代表虚拟机的价格。
5)负载均衡值
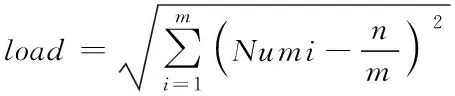
(4)
式中,load代表负载均衡值。当虚拟机执行任务的规模增加时,负载也会相应增加;反之,如果任务分配越均匀,则系统的负载也就越均衡。
由于数据智能调度是付费模式的,所以用户在进行数据调度的过程中不需要考虑分布式处理地详细细节,只需要将提交的任务数据传输至数据中心进行分布化处理即可,但是用户更加关注的是任务提交的总时长和执行费用的高低,即totaltime和totalcost两个目标函数的取值为最小,而负载均衡方差越小,证明系统越稳定;则数据智能调度模型的目标函数为

(5)
2.3 模型优化
1)编码设计
在遗传算法中,可行任务分配策略是由单一染色体表示,以下主要使用资源-任务的间接编码方式进行编码,使其能够获取更加理想的调度结果。
2)适应度函数
适应度函数[10]即目标优化函数,优先对两个目标函数进行联合优化处理,但是由于任务执行费用和时间两者之间的数量级差异比较明显。为了确保两者统一,需要对其进行标准化处理,同时加入加权求和方法展开适应度函数设计。
1)执行时间函数可以表示为

(6)
式中,totaltime(i)代表虚拟机i在执行调度任务所花费的时间。其中,totaltime(i)的取值越小,则说明对应的函数值越大。
2)执行费用函数能够表示为
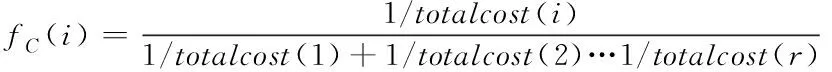
(7)
式中,totalcost(i)代表虚拟机i在执行调度任务时所花费的成本。其中,totalcost(i)的取值越小,则说明对应的函数值就越大。
当目标函数经过标准化处理之后,取值范围为[0,1]。利用式(8)给出适应度函数的具体表达形式
F(i)=ωfT(i)+(1-ω)fC(i)
(8)
3)选择算子
将轮盘赌法设定为选择算法,所谓轮盘赌法,即比例选择算法。如果种群规模为G,则个体i被选中的遗传概率为

(9)
式中,F(i)代表个体适应度;
4)交叉操作

(10)
式中,favg代表种群的平均适应度;fmax代表种群的最大适应度取值;f代表各个交叉个体的适应度值。
5)变异操作
当算法进行变异操作时,种群开始呈多样化。其中,在种群交叉完成后,各个中间群体的基因值会随着变异概率Pm的变化而变化。所以,当Pm取值较小时,信息发生丢失的概率就越大,同时无法恢复。当Pm取值较大时,会将遗传算法转换为随机搜索,有效避免上述问题的形成。利用式(11)给出变异操作概率Pm的计算式为
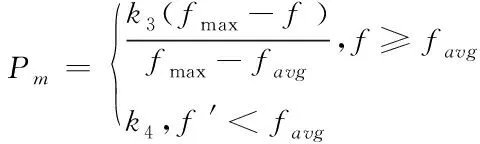
(11)
式中,k3和k4为任意常数,取值范围在[0,1]。
为了有效改进遗传算法的弊端,将遗传算法和蚁群算法两者相结合,这样不仅能够更好实现数据智能调度,同时也能够加快全局搜索。为了更好从遗传算法跳转至蚁群算法,需要进行如下设置:
1)设定遗传算法中的最大迭代次数Gmax和最小迭代次数Gmin。
2)在算法进行迭代时,设定群体的最小进化率为Gg-min。
3)在遗传算法的搜索阶段[12],如果子代群体的进化率小于Gg-min,则说明遗传算法的进化能力开始下降,此时需要结束遗传算法,然后跳转至蚁群算法。
其中,种群进化率计算式为:
1994年《学术月刊》发表杨春时的文章《走向后实践美学》,历数实践美学的十大缺陷,推出超越美学。超越美学(也被实践中心主义学术场统称为后实践美学)主张超理性、超现实,推崇精神追求,要求生存个性化。超越美学延续了康德美学思想,注重情感,追求非功利性的纯精神享受。与日益崛起的大众文化相对照,超越美学过于高雅而曲高和寡,表现出了乌托邦式的审美梦幻。但正是物以稀为贵,保持精英、砥柱姿态的超越美学,以纯净的清流力量不断引发社会价值底线的重新设定,其效用虽小,却在持续坚韧地澄清血液,成为现代人伦道德僵化的清凉解毒剂。
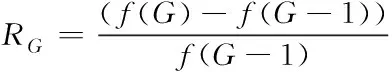
(12)
式中,G代表种群规模。
在上述分析的基础上,通过自适应遗传蚁群算法对构建的数据智能调度模型进行优化求解,进而获取最佳调度方案,实现数据智能调度。
3 仿真研究
为了验证所提的数据智能调度算法的综合有效性,通过以下实验对其整体性能进行分析研究。
利用表1给出实验过程中使用的主要参数和具体取值范围:
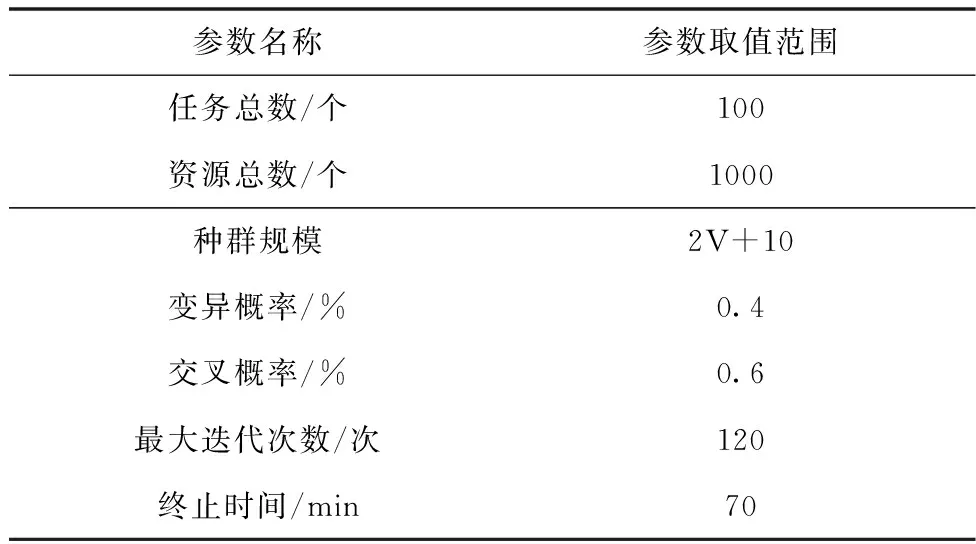
表1 实验参数设置
为了全面验证负载均衡效果的好坏,实验重点从以下三个方面展开研究:
1)执行费用/元
在不同任务规模下,各个算法所消耗的成本如图2所示。

图2 不同算法的执行费用对比结果
分析图2中的实验数据可知,当任务规模持续增加,各个算法的执行费用也开始明显呈上升趋势。但是相比另外两种调度算法,所提算法的执行费用明显更低一些,全面验证了所提算法的优越性。
为了更进一步验证所提算法的可行性,以下实验测试对比三种不同算法的负载均衡率,具体实验对比结果如表2所示:
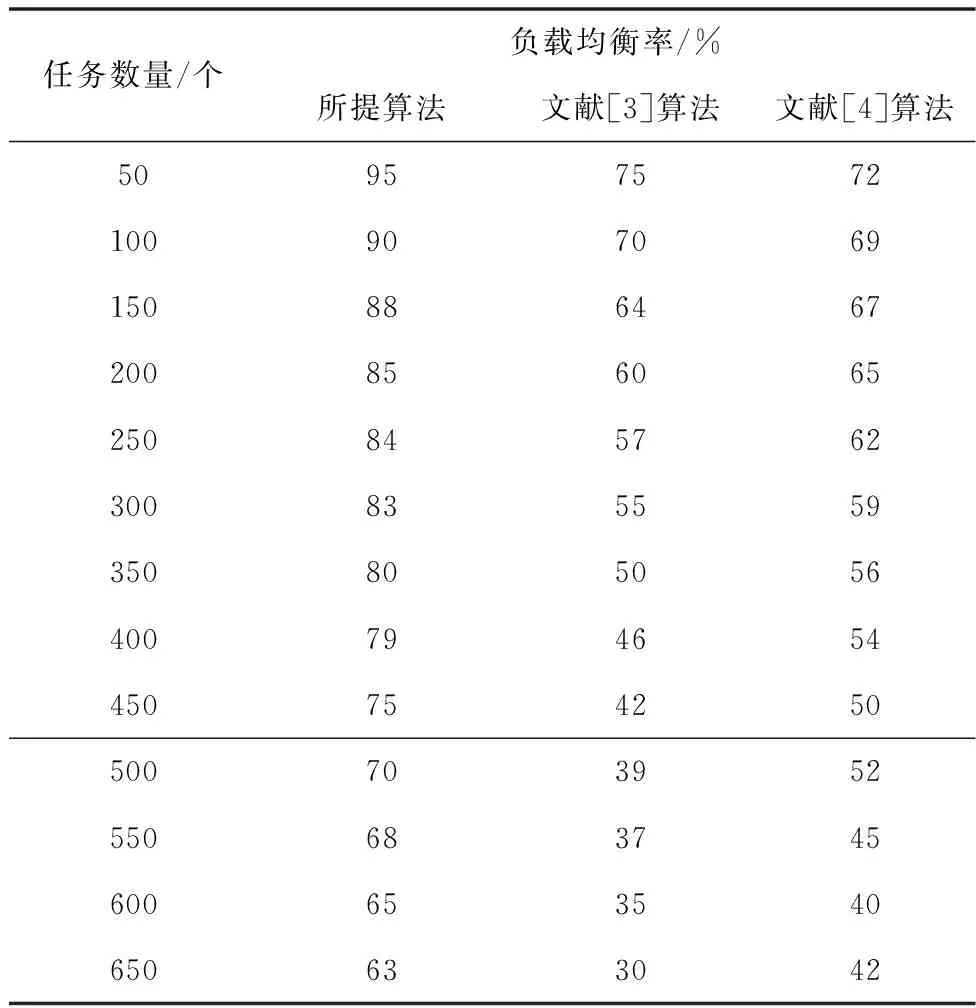
表2 不同算法的资源负载对比结果
分析表2中的实验数据可知,当任务数量较少时,各个算法的负载均衡率变化并不是十分明显。随着任务数量的持续增加,各个算法的负载均衡率变化开始越来越明显。相比另外两种算法,所提算法的负载均衡效果明显更好,同时也具有更强的全局搜索能力。
3)数据智能调度完成时间/min
为了更加全面验证所提算法的优越性,以下实验测试对比三种不同算法的数据智能调度完成时间,具体实验结果如图3所示。

图3 不同算法的数据智能调度完成时间对比结果
分析图3中的实验数据可知,由于所提算法在进行调度前期,在算法中加入了层次挖掘算法,通过该算法挖掘有利用价值的数据,简化调度过程,有效降低数据智能调度完成时间,同时使其明显低于另外两种算法。
4 结束语
1)针对目前已有调度算法的应用缺陷,结合层次梯度挖掘算法,提出新的数据智能调度算法。
2)经过具体的实验测试和分析可知,在任务规模不断增大过程中,所提算法的执行费用始终低于当前已有方法。且最高执行费用仅为25000元。当任务数量变化区间为50个~650个之间,所提算法的负载均衡率可保持在63%以上,数据智能调度时间低于25min,以上数据说明通过所提算法可获取最佳调度方案。
3)但在本次研究中,采用挖掘主题数据库和层次梯度两者构建层次业务数据库的有效性没有得以验证,数据库的构建质量也是影响数据调度的因素之一,日后会着重研究此问题。
