基于Keras和卷积神经网络CNN的手写数字识别研究
2023-05-30赵亚腾孙钰
赵亚腾 孙钰


关键词:卷积神经网络;MNIST;手写体数字识别;Keras
1引言
数字识别巳经应用到了生活中的各个领域[1],如停车场停车按车牌号计费、交通电子眼抓拍违章、大规模数据统计、文件电子化存储等。作为一种全球通用的数字符号,阿拉伯数字跨越了国家、文化以及民族的界限[2],在我们的身边应用非常广泛。数字的类别数目适当,仅有10类,方便对研究方法进行评估和测试。研究基于深度學习的手写数字识别方法不仅对理解深度学习有很大的帮助和对实践深度学习理论有很重要的意义,而且在学习实践中积累的经验和教训可以应用到其他文字识别的领域[3]。正如“一千个读者心中有一千个哈姆雷特”,即使是只有10个阿拉伯数字,但是每个人写出来的也是万般不同,若要通过机器精准识别不同人的写法依旧困难重重,所以可知手写数字识别的研究在现代科技的应用中具有很广阔的前景和较大的探索价值[4]。
2卷积神经网络的模型
2.1卷积神经网络概述
简单来说,卷积神经网络(CNN)[5]是由一个多层神经网络组成的系统,其中每一层神经网络由多个二维平面组合而成,每个二维平面上又包含数个独立神经元。如图1所示。
一般来说,CNN由两层基础结构组合而成。其中,一层是卷积层(特征提取层)[6]。卷积层的工作原理是将其空间上的神经元与上一层的感受一一对应紧密相连,在运行过程中提取图像的局部特征。在提取局部特征的后,通过比对与关联即可与其他局部特征的位置关系关联起来;另外一层基础结构叫下采样层(功能映射层)。采样层的目的是实现样本的采样和计算,在计算的过程中依赖每个采样点上的多个要素图,要素图分布在计算层的平面,而神经元是等权重分布在要素图上的。
2.2卷积层
卷积层是卷积神经网络的核心部分,神经网络卷积中大部分的计算内容都由卷积层完成。卷积核其实就是通过各种滤波器集合而形成的,在卷积层上,卷积核只是占位空间很小的一部分,在深度计算过程中,通过计算分析输入数据来得到卷积结果。卷积核的体积大小设置通过输入参数,可以动态灵活性选择。卷积核的核心内容是全连接神经网络找出要更新的权值w,即训练神经网络进行深度学习的核心内容就是卷积核。训练的目的和过程就是最终找到反映训练数据整体特征的滤波器。如图2所示,左边作为卷积层的输入项图片(image),经过中间卷积核(filter)的处理,最终产生右边卷积后的特征图谱(featuremap)。
2.3子采样层
子采样层又被称为池化层,部分文献也将其称作采样层。加入自采样层的目的是控制输入数据量的大小,减小样本规模,减少网络中参数的数量,最终实现的效果是可以节省计算资源、加快训练速率、节省时间。采样层的另一大优势是可以实现对拟合出现的有效控制。实验中使用最频繁的采样方式一般有两种,即MaxPooling和MeanPooling。MaxPooling的保留方式是最终保留N*N数据样本中的最大值,经过实验验证,得出使用MaxPooling方式的效果更精准的结论。2*2样本的采样过程和结果如图3所示。
2.4全连接层
全连接层在卷积神经网络结构中处于最后一层,即输出层,它的目的和作用是解析输出数据。此外,还需要对数据序列中的元素进行分析提取,以达到元素和神经元分别对应的目的。经过层层对应,上下层的神经元也响应连接起来。全连接层则是将最终卷出来的训练模型进行转化,从而标记空间。所以,在实际的操作过程中,全连接层也是可以由卷积层实现的。
3应用CNN进行数字手写体识别流程
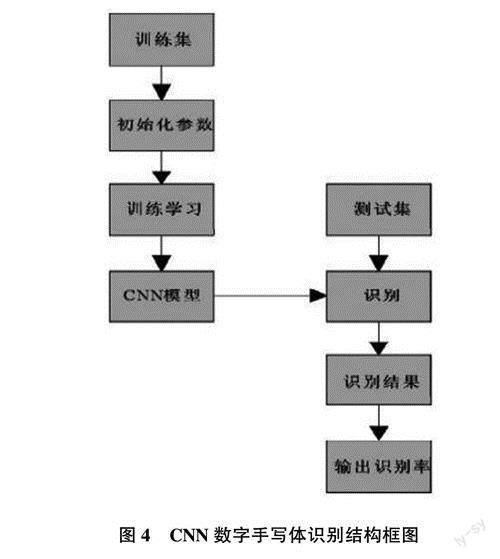
图4所示为利用CNN系统对手写体进行计算机识别的步骤过程。首先选取训练集,然后将初始化完成后的参数注入训练集,可以进行迭代形式的训练深度学习,经过反复的训练和学习后,当迭代次数达到最大且输入输出数据在合理范围内,最后可以生成一个完整的CNN模型。选用测试集后将测试数据套人模型进行识别测试,经过大量的测试集数据的输入及输出后,最终得到一个比较公正可信的文字识别率。
4实验设置与实验结果
4.1实验环境
使用的计算机硬件配置为Intel(R) Core(TM) i5CPU,其主频为2.67 GHz,内存为8 GB,操作系统为微软出品且一直在维护中的稳定版Windows 10系统。语言框架为keras,运行软件为Pycharm。
4.2MINIST数据集
本文采用MINIST数据集为样本库,该数据集库是一个专门为计算机数据集采集而成的数据集合,其中收集了超过70 000张手写数字图片,范围包含阿拉伯数字0~9,每张图片由28*28的像素点组成。
5实验结果与分析
本文使用的训练集是经LeCun手写后利用MINST构建出来的训练数据库。训练集数据1是根据MNIST数据库的格式从该数据库中分离出的部分数据,与测试集没有重叠部分。测试数据集2是由手写转化而成的图片,从0~9共100个数字,训练过程中CNN每次耗费75s进行一次迭代执行。模型训练结束后,经过对识别精确度的评测确认,不断修改参数,以提高识别准确率,最终达到精确度99%的效果。
6结束语
本文利用Python编程语言以及成熟可用的Keras框架,应用Keras框架深度学习的机制完成神经卷积网络的手写数字识别系统的研究和试验。实验最终实现了识别精准度99%的效果,但还是有一些不足。首先,实验的输入训练集神经卷积网络进行深度学习和训练,使用大量数据来模拟手写输入而实现机器一对一的识别。由于条件有限且硬件计算能力不足,导致本次卷积网络的计算层数比较少。其次,测试集由于使用的是MINST数据集,并没有较多真实手写的数据供测试,所以测试数据离真实手写还有一定差距。下一步的研究和进步方向主要对神经卷积模型进行优化,使之计算识别速率更快、准确率更高。同时,寻找更多现实生活中的图像作为测试集数据,进行更多的深度学习、模型优化,待模型成熟后,应用识别系统进行更加全面真实的识别测试,从而将研究成果更多地应用在工作及生活中。
