基于RVM 网络模型的人像分割程序
2023-05-29左毅博李心怡
左毅博,李心怡
(南华大学 计算机学院,湖南衡阳,421001)
0 引言
自2020 以来,随着新冠疫情的暴发,视频会议APP的下载量得到大量增长,而在会议软件中,为了保护用户的隐私,通常需要提供背景虚化以及背景替换功能,因此人像分割技术则是必须研究的重点及难点。视频人像分割算法是指将视频分成一帧一帧的图像,然后再将图像分割成若干个特定,具有独特性质的区域并将这些感兴趣区域进行提取的技术。它的本质是一个分类任务,区别于普通物体的区分,着重于每个像素点的分类。而抠图(Matting)则是一个回归任务,它的目标是求取每个像素点的透明度。目前在会议软件中,主要使用的还是分割算法,但是分割算法存在的最大问题就是在前景和背景交叉区域的边缘太明显,没有Matting 算法显得自然。但是目前Matting 技术也存在许多技术问题有待攻克,比如实时性、鲁棒性等问题。而本文则立足于现有的Matting 技术,基于健壮的视频抠图网络模型(Robust Video Matting,RVM),旨在提升会议视频中人像的分割效果,为该技术的后续发展起着积极促进的作用。本项目专注于快速的人像分割算法,主要目标为设计一个抠图算法且在不使用GPU 的环境下运行,在精细度、速度和模型大小上取得平衡,并完成模型的工程化,最终产出一个可执行程序,对视频或者图片进行抠图。
1 抠图算法简介
Alpha Matting 算法研究的是如何将一幅图像中的前景信息和背景信息分离的问题,即抠图。这类问题是数字图像处理与数字图像编辑领域中的一类经典问题,广泛应用于视频编辑与视频分割领域中。Alpha matting 的数学模型是:I=αF+(1-α)B。图像的前景和背景如图1 所示。

图1 图像的前景和背景
它由Porter 和 Duff 于1984 年提出[1]。他们首先引入了α 通道的概念,即它是一种前景和背景颜色的线性混合表示方法。一张图片包含前景信息、背景信息,将该图片看成是前景图和背景图的合成图,于是便有了以上的混合模型。前景α 为1, 背景α 为 0,α 的取值介于0-1 之间,表示前后背景图的线性组合。在大多数自然图像中,大多数像素点都属于绝对前景或者绝对背景,如何将其他混合点的α 值准确地估计出来是alpha matting 的关键。
给定一个输入图像,对于所有像素点,它的(F,B, α)都是未知的,需要进行估计,如果图片是灰度图片,每个像素点包含3 个未知数,这样的问题是一个欠约束问题。大多数抠图问题需要用户交互的先验条件,使得我们对已知输入图像的颜色统计有预先的估计和假设,从而能够更加准确的估计出未知量的值,常见的人工添加的约束条件有三区标注图(trimap)和草图(scribble)两种。
预先提供的约束条件(trimap 图或scribble 图)越精确,未知区域内的点就越少,更多前景和背景信息就更容易利用。然而,在实践中,要求预先输入非常准确的 trimap是一件异常繁琐的工作,不现实也不必要的,如何在预先提供的trimap 以及最终算法所求得的抠图结果之间寻求一个最佳答案,不同的抠图算法对于这个问题有着不同的阐述。
2 项目概述
2.1 需求描述
将图像人像与背景分割开,追求主体边缘清晰性和精准性,具体要求如下(输出结果如图2 所示):

图2 原图与算法mask
边缘分割准确——边缘分割的准确度一直是业内衡量分割效果好坏的重要指标。本项目希望能够在前景和背景对比度低、背景复杂、主体形状复杂等各种复杂环境下,依然能保证主体边缘的精准分割。
在边缘分割时,需注意以下几点:
主体部分区域被非主体遮挡时,只需精准地分割出视觉中主体与非主体的可见区域,不需要“脑补”主体被遮挡的部分;
对于主体上毛发或类毛发、复杂结构的边缘分割,应做到越精准越好。在无法保证绝对精准时,建议剔除少量复杂边缘部分,不要为了保留全部主体内容而使得主体部分残留过多背景;
对于手持物也需要抠,手持物的大小如手机、平板电脑、杯子、笔则都要抠出。如果有遮挡大部分的身体、如箱子、电脑屏幕,等大型物体,则不需要抠出。
2.2 特色综述
(1)目前的实时视频人像分割技术仍然使用的语义分割算法,matting 技术运用较少且不成熟。而本项目系统地研究了matting 技术,并将其进行使用与完善,可为后续的相关任务提供宝贵的借鉴经验。
(2)针对模型在cpu 或者移动设备上运行效率低下的问题,对网络的结构进行优化,使用更加轻量级的解码器,有效提升模型推理速度。并且根据目前会议视频的使用特点,对模型的推理结果进行进一步处理,使该项目能满足多种运用场景,如背景虚化、背景替换等功能。
(3)本项目模型主要借鉴RVM 网络模型,包括编码器和环解码器,在Unet 网络模型中加入了ConvGRU 结构,可有效利用视频帧中的时间信息,有助于得到更好的分割效果。
2.3 项目开发环境
基于 VisualStudio2019 开发C++程序;基于 pytorch 1.9.0 进行模型训练融合;基于 openCV 创建程序;使用openvino 框架进行推理。
3 模型介绍
本项目模型主要借鉴RVM 网络模型,包括编码器和环解码器,如图3 所示。该网络模型的实质其实是借鉴了Unet 网络模型,只是在其中加入了ConvGRU 结构,可有效利用视频帧中的时间信息,有助于得到更好的分割效果。我们的架构包括一个提取单个帧特征的编码器、一个聚合时间信息的循环解码器,以及一个用于高分辨率上采样的深度引导滤波器模块。RVM 网络模型的架构如图3 所示。
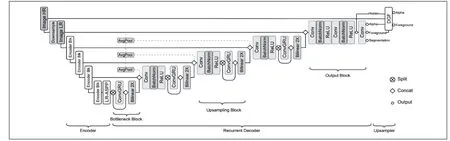
图3 RVM 网络模型
(1)特征提取编码器
RVM 编码器模块遵循最先进的语义分割网络的设计,因为准确定位人体对象的能力是Matting 任务的基础。我们采用MobileNetV3 Large 作为我们的有效主干,然后是MobileNetV3 提出的用于语义分割任务的LR-ASPP 模块。但MobileNetV3 的最后一块使用了扩展的卷积,而没有降低采样步长。编码器模块对单个帧进行操作,并为循环解码器提取1/2,1/4,1/8 和1/16 标度的特征。MobileNetV3 的核心架构如图4 所示。
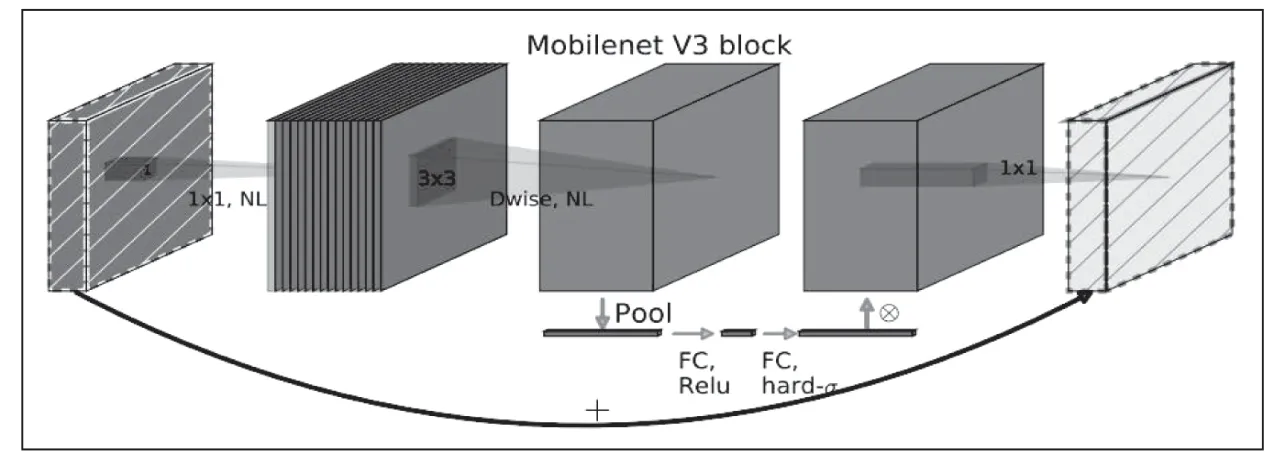
图4 MobileNetV3核心架构
(2)循环解码器
由于视频的特殊性质,RVM 使用循环架构,而不是关注或者简单地将多个帧作为额外的输入通道进行前馈。循环机制可以学习在连续的视频流中自己保存和忘记哪些信息,而其他两种方法必须依赖固定的规则,在每个设定的间隔内删除旧信息并将新信息插入有限的内存池。自适应的保留长期和短期时间信息的能力使循环机制更适合我们的任务。
通过修改网络,使其可以一次给定T 帧作为输入,每一层在传递到下一层之前处理所有T 帧。在训练期间,这允许批量标准化计算批次和时间的统计数据,以确保标准化是一致的。在推断过程中,T=1 可用于处理实时视频,T>1可用于利用非重复层的更多GPU 并行性,作为一种批处理形式,前提是允许缓冲帧。我们的循环解码器是单向的,所以它可以用于直播和后处理。
(3)深度引导过滤模块
我们采用中提出的深度引导滤波器(DGF)进行高分辨率预测。在处理4K 和HD 等高分辨率视频时,我们在通过编码器-解码器网络之前将输入帧的采样率降低了一个因子s。
然后将低分辨率alpha、前景、最终隐藏特征以及高分辨率输入帧提供给DGF 模块,以生成高分辨率alpha 和前景。对整个网络进行端到端训练。请注意,DGF 模块是可选的,如果要处理的视频分辨率较低,编码器网络可以独立运行。
4 模型训练
4.1 求解过程
出于以下几个原因,RVM 同时使用Matting 和语义分割目标来训练网络:
首先,人体抠图任务与人体分割任务密切相关。与基于trimap 和基于背景的抠图方法不同,我们的网络必须学习从语义上理解场景,并在定位人体对象时保持稳定。
大多数现有的Matting 数据集只提供地面真实阿尔法和前景,必须与背景图像合成。由于前景和背景的光线不同,这些构图有时看起来是假的。另一方面,语义分割数据集以真实图像为特征,其中人类主体包含在所有类型的复杂场景中。使用语义分割数据集进行训练可以防止我们的模型过度拟合合成分布。
有更多的训练数据可用于语义分割任务。我们额外收集了各种公开可用的数据集,包括基于视频和基于图像的数据集,以训练健壮的模型。
4.2 数据集
我们的模型是在VideoMatte240K、Differentions-646和Adobe Image Matting 数据集上训练的。VM 提供484个4K/HD 视频剪辑。我们将数据集划分为475/4/5 个片段,用于train/val/测试分割。D646 和AIM 是图像抠图数据集。同时只使用人类的图像,并将它们组合成420/15 个训练序列/val 分段进行训练。为了进行评估,D646 和AIM 分别提供了11 张和10 张测试图像。
对于背景,数据集提供适用于Matting 合成的高清背景视频。这些视频包括各种各样的动作,比如汽车经过、树叶晃动和摄像机的动作。我们选择3118 个不包含人类的剪辑,并从每个剪辑中提取前100 帧。图像中有更多的室内场景,如办公室和客厅。
我们在前景和背景上应用了运动和时间增强,以增加数据的多样性。运动增强包括仿射平移、缩放、旋转、透明、亮度、饱和度、对比度、色调、噪声和模糊,这些都会随着时间不断变化。运动应用了不同的缓和函数,因此变化并不总是线性的。这种增强还向图像数据集中添加了人工运动。此外,我们还对视频应用了时间增强,包括剪辑反转、速度变化、随机暂停和跳帧。其他离散增强,即水平翻转、灰度和锐化,将一致地应用于所有帧。
4.3 训练步骤
抠图训练分为四个阶段:
第一阶段:RVM 首先在VM 上以低分辨率进行训练,不使用DGF 模块,持续15 个时代,设置了一个短序列长度T=15 帧,这样网络可以更快地更新。MobileNetV3 主干使用预训练的ImageNet 权重初始化,并使用1 学习速率,而网络的其余部分使用2e-4,并对256 到512 像素之间的输入分辨率h、w 的高度和宽度进行独立采样。
第二阶段:我们将T 增加到50 帧,将学习率降低一半,并保留第一阶段的其他设置,以便为我们的模型再训练两代。这使我们的网络能够看到更长的序列,并了解长期的依赖关系。
第三阶段:我们连接DGF 模块,在VM 上使用高分辨率样本进行1 个历元的训练。由于高分辨率会消耗更多GPU 内存,因此序列长度必须设置为非常短。为了避免我们的重复网络过度拟合到非常短的序列,因此在低分辨率长序列和高分辨率短序列上训练我们的网络。
第四阶段:我们在D646 的组合数据集上进行训练,目标是5 代。我们将解码器学习率提高到5e-5,以使我们的网络适应并保持第三阶段的其他设置。
5 项目工程化
打包python 训练的模型得到xml+bin 文件后,编写C++的控制台程序,导入模型并编写其他与图片或视频处理的相关代码。
我们使用visual studio 2019 自带的项目生成功能生成exe 可执行文件,将文件夹中加入exe 可执行文件以及相关的dll 文件即可。
该软件无需安装,解压即可使用,使用cmd 窗口进入exe 文件所在路径,执行exe 文件并附带数据集文件夹路径即可。
6 数据实验与结果分析
针对不同的文件类型,我们进行了不同的测试,首先是对于图片,无论是证件照还是个人的自拍,我们都能将其中的人像准确抠出,并且在边缘有着较为精确的分割效果。证件照抠图如图5 所示,个人自拍抠图如图6 所示。
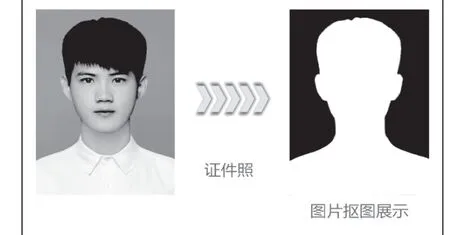
图5 证件照抠图
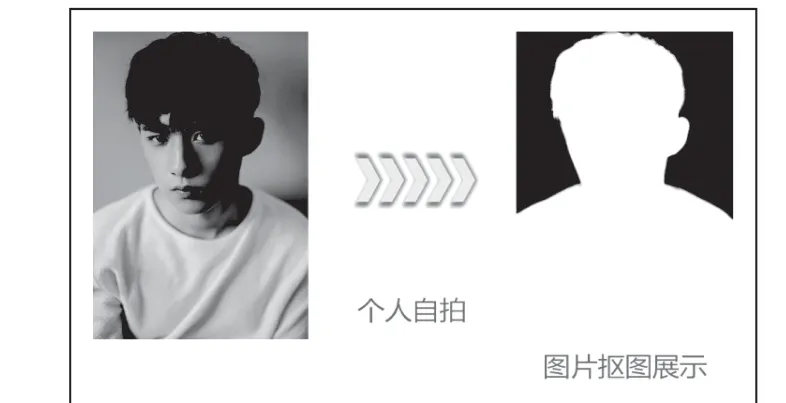
图6 个人自拍抠图
其次是对于视频的处理,我们在Cpu 为i7-9750H 的条件下处理1080p 的视频可以达到每秒40 帧的效果,同时对于视频中的人物轮廓有着良好的分割效果。视频抠图如图7所示。
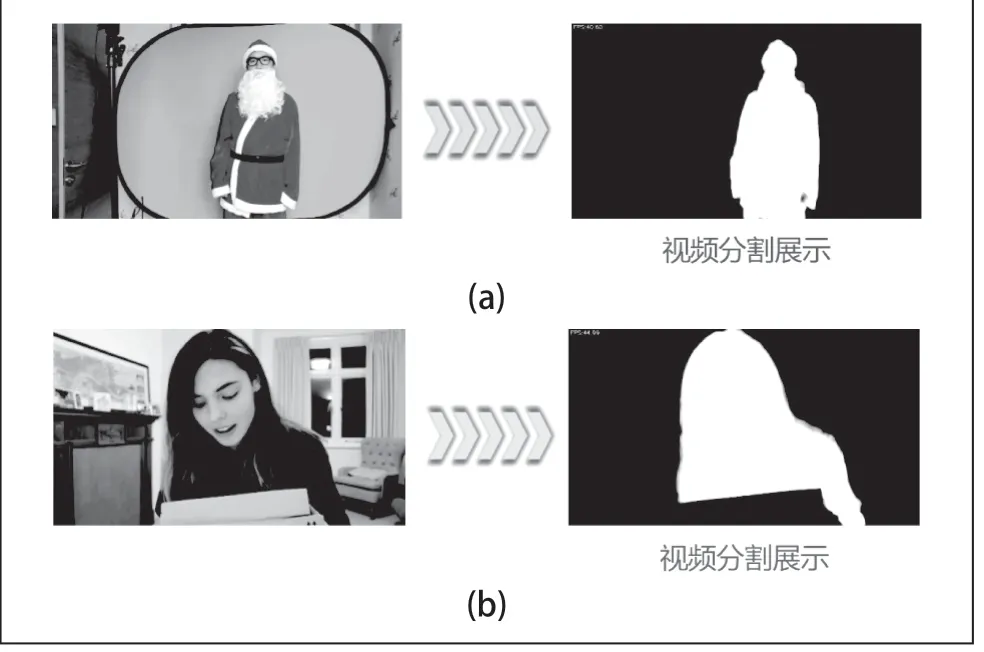
图7 视频抠图
7 结论
我们的软件可以对不同的图片或视频进行人像分割处理并输出mask,对于不同分辨率的图片我们都有着相当可观的分割效果,我们会根据图片原始的分辨率动态设置采样率,这样有益于我们对图片的分割效果;对于1920×1080的视频我们的处理速度可以达到40+ fps/s,并且我们的模型大小仅为16MB,对于会议场景的视频有着十分可观的分割效果,当然也可以用于其他各类场景的视频,分割效果与多种因素有关,但是整体效果良好。
