基于双向特征融合的露天矿区道路障碍检测
2023-05-22阮顺领李少博顾清华
阮顺领,李少博,顾清华,江 松,毛 晶
(1.西安建筑科技大学 资源工程学院,陕西 西安 710055;2.西安建筑科技大学 西安市智慧工业感知计算与决策重点实验室,陕西 西安 710055;3.西安优迈智慧矿山研究院有限公司,陕西 西安 710055)
露天矿区无人驾驶逐渐成熟并落地,环境感知作为矿卡车实现无人化的关键环节之一,对于露天矿无人驾驶的实现有着重要意义。然而露天矿区非结构化道路相较于城市结构化道路,除了常规的车辆、行人等行车障碍,还存在着一些难以检测的困难样本,如坑洼、尖锐碎石等,容易造成陷车或轮胎夹石。同时露天矿区环境复杂恶劣,这对障碍检测算法可靠性提出了更高的要求,因此亟待对露天矿区道路障碍的高效、可靠检测方法进行研究。
基于机器视觉的无人驾驶车辆障碍检测可以分为传统的图像处理方法和深度学习方法。基于二维图像处理的障碍检测算法通常分为以下步骤:①
图像增强,如直方图均衡化法、同态滤波法,暗通道去雾算法等;②
图像边缘检测,如张金波[1]针对灰度图像边缘检测的特点,提出的快速边缘检测算法,FERNANDO等[2]提出的基于强度函数的数字图像边缘检测方法;③
图像分割,如聚类算法[3]、阈值分割算法[4]等,同时针对特定应用场景,国内外学者提出了基于弱标注信息的语义分割方法[5]、交互式图像分割方法[6]等。二维图像处理技术容易受到各种不利因素的影响,尤其是在光照不足的非结构化道路,因此一些学者提出了立体视觉的障碍物检测方法,如STANTANA等[7],ZHANG等[8]。
随着深度学习的发展,PRABHAKAR[9],SANIL[10]等使用卷积神经网络去解决无人驾驶车辆障碍检测问题,获得了更好的检测精度和速度。基于深度学习的障碍检测方法往往由以下3个结构组成:① 用于提取图像特征信息的骨干网络,如复杂骨干网络VGG[11]、ResNet[12]、DenseNet[13]、EfficientNet[14],轻量型骨干网络MobileNet[15]、ShuffleNet[16]、GhostNet[17]等;② 将不同尺寸特征图进一步融合的特征金字塔模块,如FPN[18]、PANet[19]、NAS-FPN[20]等;③ 对特征图进行分类去预测的Head,如一阶段算法的SSD[21]、YOLO[22]、RetinaNet[23]、FCOS[24],两阶段算法的Faster R-CNN[25]、R-FCN[26]、Mask R-CNN[27]等。针对非结构化道路障碍检测,蔡舒平等[28]提出了基于改进YOLOv4的障碍物实时检测方法,通过对模型进行轻量化改进并使用了逆残差方法,使得模型拥有较好的自适应性和鲁棒性。卢才武等[29]基于Mask R-CNN网络,提出了融合目标检测的露天矿行车障碍预警,达到了较好的检测精确度和7.35 fps的检测速度。然而其针对露天矿区障碍物检测还不够全面,虽然精度较高但缺少坑洞、尖锐碎石等困难样本的检测,同时检测速度较慢难以满足实时性要求。因此露天矿区道路障碍检测模型需要在以下3个方面具备较好的能力:① 在光线和纹理复杂情况下,拥有高效的特征提取能力;② 对于坑洼等负向障碍,拥有良好的多尺度检测性能;③ 对于行人和尖锐碎石等障碍,有着良好的小目标检测性能。
鉴于以上分析,针对露天矿区复杂环境下道路障碍物多尺度和小目标特征,笔者提出一种基于深度学习的露天矿区道路障碍检测模型。由于RepVGG网络对复杂环境信息有着优良的特征提取能力和高效的推理速度,比较适合于露天矿区道路障碍的检测,但同时该网络使用大量3×3卷积导致其感受野较小,对小目标特征提取不充分[30],因此提出在特征提取阶段采取优化的RepVGG+骨干网络;并使用双向特征融合金字塔模型进一步提升多尺度检测性能;通过对损失函数和分类预测模块进行优化进一步提升模型的检测精度和速度,为复杂环境下露天矿区无人矿卡提供高效的障碍检测方法。
1 露天矿区障碍检测模型
露天矿区非结构化道路的背景信息复杂多变,各类障碍物尺寸跨度与特征差异较大,同时过于依赖自然光照条件。而在露天矿开采区道路多为临时修建,道路信息经常变换,这导致了露天矿区障碍检测具有挑战性,如图1所示。

图1 露天矿区障碍物及其特征Fig.1 Obstacles and their characteristics in open pit mines
RetinaNet[23]作为一阶段检测法,具有良好的实时性和检测精度,其网络结构如图2所示。
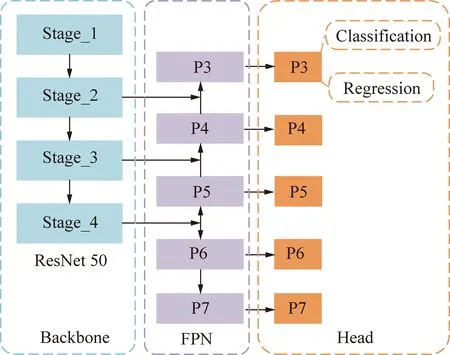
图2 RetinaNet网络结构Fig.2 RetinaNet structure
RetinaNet使用了ResNet50作为特征提取网络,在FPN中P3、P4、P5使用ResNet50的Stage_2、Stage_3、Stage_4的输出进行1×1卷积后归一为通道数256的特征;P6是经过Stage_4的输出进行步长为2的3×3卷积而来;P7则是通过对P6使用ReLU激活函数后再进行步长为2的3×3卷积,用来增强大目标的检测。在网络的预测分类的Head中,P3~P7每层的先验框面积从322~5122像素依次递增,先验框的长宽比为[1∶2,1∶1,2∶1],size为[20,21/3,22/3],这样每层的先验框数量为9。虽然先验框可以代表一定的框的位置信息与框的大小信息,但是其是有限的,无法表示任意情况,因此RetinaNet利用4次256通道的3×3卷积+ReLU和分类器的卷积结果对先验框进行调整。
由于RetinaNet用了5个不同尺寸的特征进行分类回归操作,使得网络各个anchor之间过渡更加平滑,提升网络的多尺度检测性能。当RetinaNet的输入分辨率为600×600时,在分类预测层中最大特征尺寸仅为75×75,使得露天矿区的小目标检测性能较差,同时多尺度检测性能和检测速度有待进一步提升。
基于上述讨论,为了解决露天矿区障碍物中小目标和多尺度问题,在特征提取阶段,提出了更加高效的RepVGG+作为骨干特征提取网络;在特征融合阶段,使用基于SimAM空间与通道注意力和跨阶段连接的双向融合特征金字塔(Bidirectional Feature Pyramid Network,B-FPN);在分类预测阶段,对Head结构进行进一步优化,降低特征冗余,并提高检测性能,其结构如图3所示。
1.1 骨干特征提取网络优化
露天矿区障碍检测需满足无人矿卡环境感知的实时性需求,因此采用了RepVGG[30]作为骨干特征提取网络,保证模型的检测速度与精度。
RepVGG的网络结构类似于ResNet,在VGG网络的基础上使用残差结构去解决深层网络的梯度消失问题,同时大量使用1×1卷积和Identity残差结构,使得网络更加简单高效。其训练和推理阶段的基本卷积结构如图4所示。
RepVGG在模型推理阶段首先将残差块中的卷积层和BN层进行融合,然后将具体不同卷积核的卷积均转换为具有3×3大小的卷积核的卷积,最后合并残差分支中的Conv3×3。将所有分支的权重W和偏置B叠加起来,获得一个融合之后的Conv3×3网络层。由于在模型推理阶段仅仅由3×3卷积和Relu激活函数堆叠而来,抛弃了残差结构,同时当前大多数推理引擎对于3×3卷积有着特定的加速,相较于ResNet骨干网络,更加易于模型推理和加速。
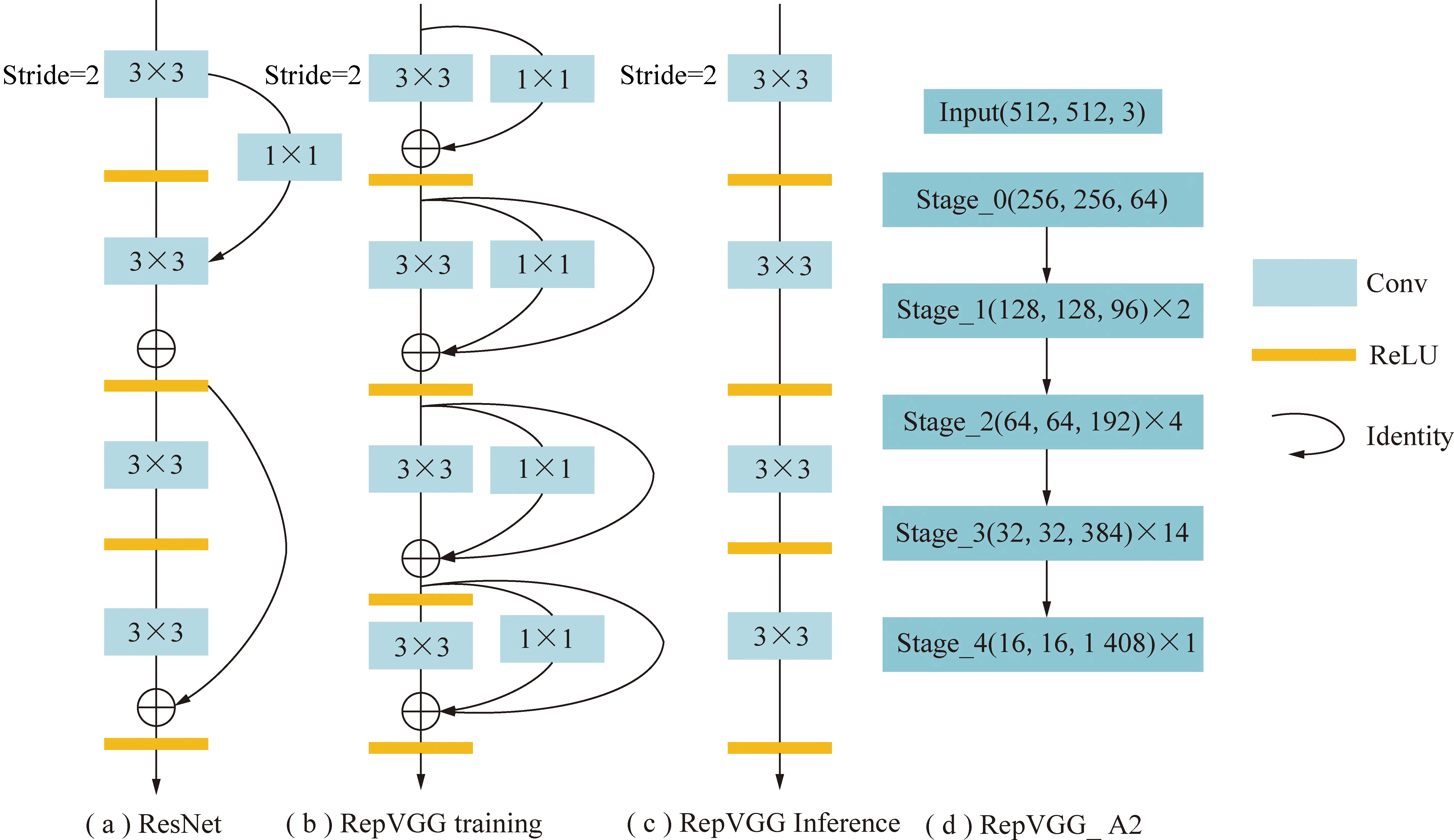
图4 RepVGG+结构Fig.4 RepVGG+ structure
虽然RepVGG在图片分类任务中取得了优异的性能,但其在目标检测任务中还有待优化。如图4(d)所示,RepVGG_A2的Stage4中只进行了一次基本卷积操作,并使用了1 408个通道,更大的通道数对于多分类任务会获得更好的性能。但是将RepVGG应用于目标检测时,由于其Stage4的特征卷积次数过少,使得16×16尺寸的特征,难以得到更加高层的特征信息。因此,本文提出了更加适应于目标检测任务的RepVGG+(图3),对Stage4模块进行2次基本卷积操作,同时将Stage4的通道数调整为768,降低参数量,保证检测精度与速度的平衡。使用大尺寸的卷积核可以扩大网络感受野显著提高网络性能,但越大的卷积核其计算速度越慢,因此本文提出在Stage4中使用金字塔池化结构(Spatial Pyramid Pooling,SPP)[31],如图3所示将RepVGG的Stage4_1特征层进行卷积降低通道数为384,然后进行13×13、9×9、5×5、1×1,4个不同尺度的最大池化操作,扩大感受野。将池化后的特征进行拼接,再次使用卷积批处理和激活操作使通道数还原为768。SPP通过使用大尺寸池化核增加神经网络的感受野并分离出显著的上下文特征,提升检测性能。
1.2 基于通道与空间注意力的双向特征融合模块
露天矿区障碍检测模型的多尺度和小目标检测能力还有待进一步提升,提升小目标检测常用的方法是扩大特征尺寸,使得网络在分类预测时可以获得更多特征信息。但是通过扩大输入分辨率会增加网络每一层的特征尺寸,进一步增加模型参数量并带来极大的计算开销。当输入分辨率为512×512时骨干网络的Stage1特征尺寸为128×128,包含了丰富的特征信息,因此本文将骨干特征网络的Stage1的特征作为特征金字塔模块P2层的输入,并取消用于大目标检测的P7层。但是Stage1特征信息具有较多的噪声,在分类过程难以直接被解析。因此本文提出B-FPN结构,进一步优化网络各层的特征信息使P2层使网络可以获得更加抽象高效的语义特征,同时提升多尺度检测性能。其结构如图5所示。

图5 基于SimAM通道与空间注意力和跨阶段连接的双向特征融合模块Fig.5 Bidirectional feature fusion module based on SimAM channels with spatial attention and cross-stage connectivity
将骨干网络的Stage1、Stage2、Stage3、Stage4_2的特征图进行1×1卷积获得通道数为96的P2、P3、P4、P5层,同时对Stage2的输出使用步长为2的3×3卷积获得特征尺寸为8×8的P6层用于检测大目标。在自下而上的融合过程中,P5层使用跨阶段连接卷积(CSPnet)[32]后进行上采样处理和SimAM注意力[33]进行特征增强,然后与P4的特征图进行横向连接,P3和P4层重复上述操作,使得每一层获得了骨干网络各层的特征信息,减少了P3层的噪声信息。在P3层之后使用SSH[33]结构进一步扩大特征图感受野,提升微小目标检测能力。在自上而下的融合过程中,P3、P4、P5、P6层则与上一层下采样之后的特征图相加后进行CSP卷积处理,达到特征网络双向融合,增强多尺度检测的目的。
网络的基础卷积模块为卷积+批处理+LeakyReLU,相较于ReLU激活函数,LeakyReLU当x≤0时使用λ系数调节梯度,使得神经元在取负值时也有微小梯度,可以有效改善神经元死亡问题,2者的数学表达为
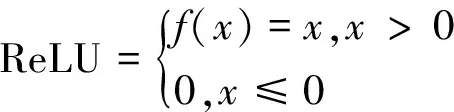
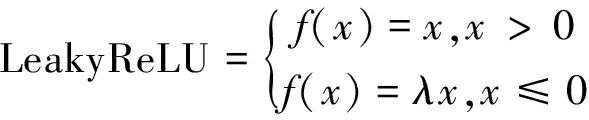
(1)
在特征融合模块中使用跨阶段连接结构(CSPNet)[32]提升不同特征层在横向连接后的特征信息。CSPNet的结构如图3所示,将输入拆分为相同通道数的稠密分支与稀疏分支,稠密分支进行多次卷积后与系数分支进行拼接,还原输入特征。CSPNet其原理是利用跨阶段特征融合策略和截断梯度流来增强不同层次特征的可变性,用于解决模型在训练中由于梯度冗余,而导致的特征提取效率低下以及模型推理速度较慢问题。
上采样的过程中,采用nearest插值方法会损失一定的局部特征图信息,为此引入了SimAM空间与通道注意力机制[33],挖掘通道间各个神经元的重要特征。在计算机视觉中现有的注意力模块集中在通道域或空间域,与人脑中基于特征的注意和基于空间的注意相对应。然而,在人类中,这2种机制共存,共同促进视觉处理过程中的信息选择。SimAM为每个神经元定义了以下能量函数:
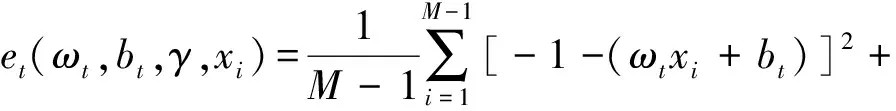
(2)
其中,t和xi分别为输入特征X∈C×H×W的目标神经元和其他神经元;i为空间维度上的索引;M=H×W为在该通道上的神经元个数;ωt、bt为加权与偏置转换。求解上述方程得到关于ωt和bt的快速封闭形式解:
(3)
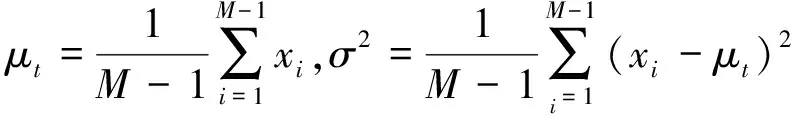
(4)
其中,
式(4)表示能量越低,神经元t与周围神经元的区别越大,重要性越高。因此,神经元的重要性可以通过1/e*得到,最后使用sigmoid对特征进行增强处理:
(5)

为了进一步增强P2层特征,提升微小目标检测性能。在P2层进行特征融合之后,使用SSH[34]模块处理,其结构如图6所示,通过引入5×5、7×7卷积核提高感受野,从而引入更多的上下文信息,同时为了减少大尺寸卷积核带来的计算量提升,使用多个3×3卷积层进行拼接代替5×5、7×7卷积层。本文在3×3卷积模块之后还加入了批处理层改善梯度消失问题,同时将激活函数由ReLU更换为LeakyReLU,优化模型结构如图6所示。
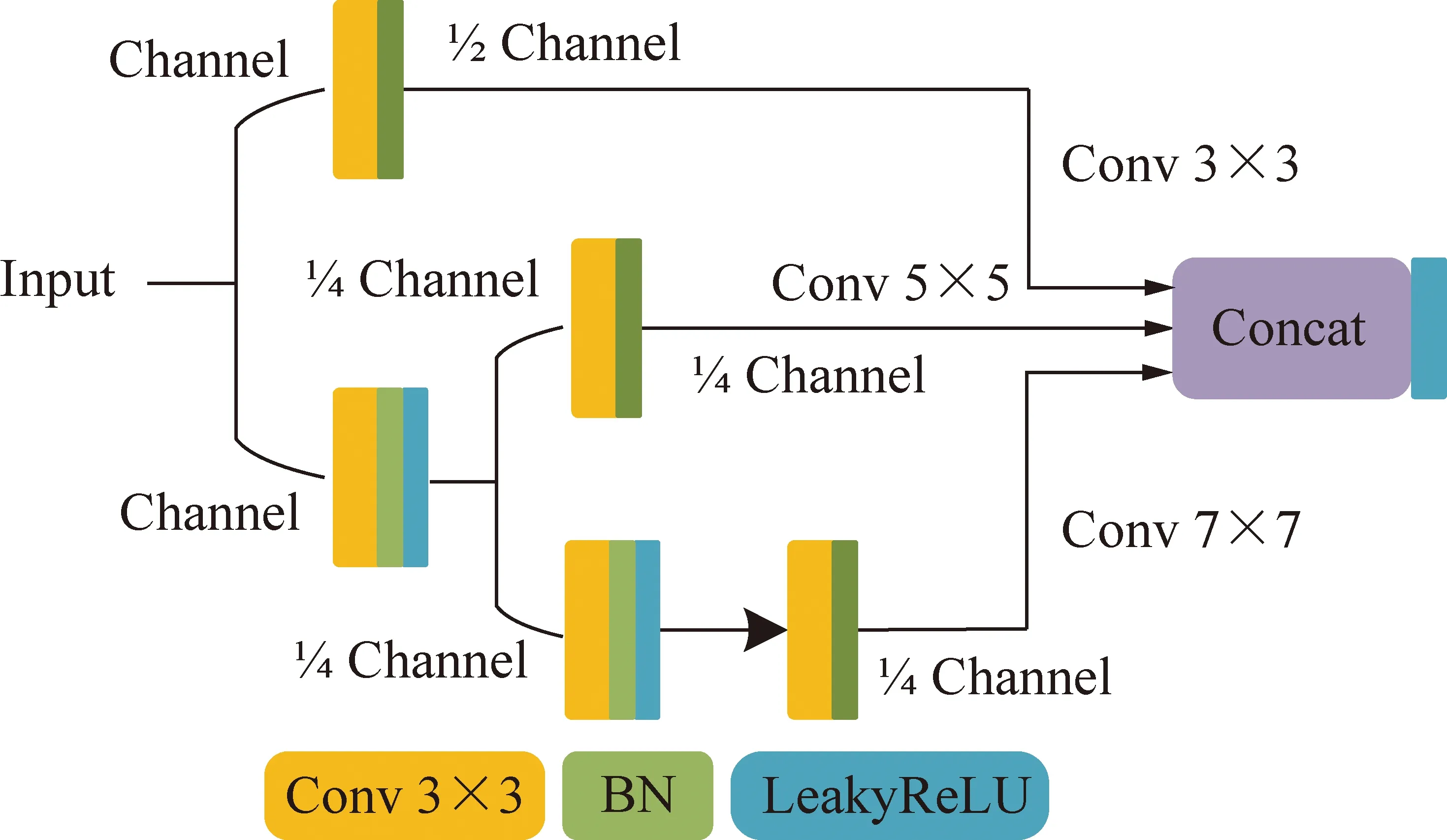
图6 SSH模块,使用多个3×3卷积层进行拼 接代替5×5、7×7卷积层增强感受野Fig.6 SSH module,using multiple 3×3 convolutional layers for stitching instead of 5×5 and 7×7 convolutional layers to enhance the perceptual field
1.3 分类与边界框预测分支优化
露天矿区障碍检测网络的分类子网预测9个先验框和K个类别在每个空间位置出现对象的概率,如图7(a)所示,RetinaNet使用了4个3×3卷积层,每层都有256个过滤器,并在后面加入ReLU激活函数,最后使用带有K×9个过滤器的3×3卷积层后,使用Sigmoid激活函数预测每个空间位置的二进制输出。边界框回归分支与分类子网并行,将每个先验框的偏移量还原到真实对象。其设计与分类分支相似,对于每个先验框使用tx、ty、tw、th四个变量输出预测其与真实框之间的相对偏移量(其中,tx、ty为先验框的中心点坐标(x,y)的相对偏移量;tw、th为先验框的宽高(w,h)的相对偏移量)。

图7 分类与边界框预测分支Fig.7 Classification and bounding box prediction branch
如图7(b)所示,由于本文提出的模型在特征融合阶段已经进行了高效的卷积,因此本文模型通道数和过滤器调整为96,并进行2次3×3卷积和与LeakyReLU激活,减少计算量和特征冗余。同时由于本文模型使用了更大的P2层的特征图,删除了P7层的特征图,因此将P2~P6层先验框的面积调整为162~2562,并针对露天矿区障碍物的特殊性将先验框的长宽比重设为[0.7∶1.4,1∶1,1.4∶0.7]。
1.4 损失函数优化
露天矿区道路障碍检测模型的损失函数包括分类损失和边界框损失2部分。在分类损失函数方面,针对露天矿区的复杂背景易导致障碍图像正负样本比例失衡,RetinaNet提出了Focal loss[23]优化交叉熵损失函数优化正负样本不均衡问题,其数学表达式为
(6)
式中,γ为调整难、易分类样本之间的权重;α为调整正负、样本之间的权重;p为模型分类后得到的概率。
为应对训练过程中某些易样本的过拟合,导致的难样本置信度偏低引起的精度下降,本文在分类损失函数中引入了标签平滑正则化(label smooth regularization)[35],通过减少易样本真实样本标签的类别在计算损失函数时的权重,增加难样本权重抑制过拟合。因此本文的分类损失函数为
(7)
式中,Csmooth为经标签平滑处理后的类别数组;e为平滑因子,本文取e=0.01;δ为标签的真实类别数组;δ0为与δ维度相同的全1数组;S为每层特征图尺寸;Z为先验框数量;本文取γ=2。
在边界框损失方面RetinaNet采用Smooth L1 loss,其数学表达式为
(8)
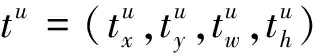
IoU可用来衡量2个边界框的相似性,IoU的计算公式为
(9)
其中,A、B分别为预测框和真实框。由于目标检测任务以IoU作为是否检测到任务的判定标准,因此训练时使用Smooth L1 loss作为位置回归损失这2者并不等价,尤其当预测框与真实框的L1和L2范数相近时,与IoU差异过大。如图8所示,当使用IoU作为损失函数时,当预测框与真实框没有重合时,IoU无法衡量2者之间的差异,这导致损失函数梯度为0而无法优化网络之间的权重。

注:红色表示预测框,绿色表示真实框,黑色表示2者的最小闭合框。图8 预测框与真实框的不同情况Fig.8 Different cases of prediction frame and real frame
GIoU[36]充分利用了IoU具有尺度不变性的优点,加入了预测框与真实框之间的最小闭合框作为损失计算参数,其数学表达式为
(10)
其中,C为包含2者的最小闭合框。如图8(c)、(d)所示,黑色框范围即为C的表示区域。GIoU克服了IoU在预测框与真实框不重合时的不足之处,能够更好地反映预测框与真实框的重合情。因此本文模型的边界框损失函数为
(11)
综上所述,本文模型的损失函数为
(12)
2 露天矿区障碍数据集构建
本文中的数据采集于2019年2月到2021年4月间在大型露天矿开采现场,使用canon EOS 80d 数字相机采集,检测目标包括大型运载卡车、行人、挖机、汽车、道路坑洞、道路积水和尖锐碎石7类。在不同季节与不同光照条件下,总共采集2 081张图像数据。其中坑洞和积水作为负向障碍,位于路面下方且尺寸形状各异,同时行人和尖锐碎石往往占据像素面积极少,这导致了本文数据集存在大量多尺度特征和小目标障碍。随机选择1 581张图片作为训练集,其余500张图片作为测试集,图像原分辨率是4 032×3 024,在输入网络时将图像大小调整为512×512。
本文数据集的训练集过少,难以使网络达到很好的拟合状态,因此通过数据扩增取进一步丰富数据集。通过对原始数据进行变换,进一步增加数据量、丰富数据多样性、提高模型的泛化能力。在传统扩增方法中,本文对图片进行了90°、180°、270°旋转、改变亮度、灰度化,使样本扩增为原来的6倍。同时由于尖锐碎石在图像中占据很少的像素比例,处于道路中间,与道路的背景信息差异较小,导致其检测难度很大。而在本文数据集中尖锐碎石样本较少,这导致了训练样本的不均衡,会进一步增加碎石的检测难度。为此本文针对尖锐碎石较小,样本量较少难以检测的问题,使用了一种小目标增强方法,其具体流程为
(2) 将小目标(尖锐碎石)图像进行缩放;
(3) 根据缩放生成边界框标签文件,由于小目标往往处于路面之中,同时本文采集的照片,道路信息大多存在于图片下半部分,因此对小目标的边界框位置进行过滤,删除部分位置错误的标签文件;
(4) 与原始标签文件进行交并比计算,防止尖锐碎石图片生成的位置与原始图片中的目标重叠;
(5)将生成的小目标(尖锐碎石)图像,使用泊松融合(Poisson blending)[37]方法与原始图片相融合。泊松融合实质为求取梯度向量场引导下的影像插值,其数学表达如下:
定义二维图像平面为S(S∈R2)上的闭合区域为Ω,其边界为∂Ω,V为定义在Ω上的梯度向量场,f为定义在S上的标量函数,已知f在∂Ω上的取值为f*,则f在Ω内取V引导下的插值函数,即求解

(13)
其中,∇f为f*的梯度,由于其求解构成泊松方程,因此可化为
护理本科生的社会价值体现,社会地位要求,薪酬待遇和职称要求等,不是仅仅靠国家政策、学校改革、医疗体制改革等措施能够充分满足和不断完善,更重要的是,护理本科生要提高自身素质,提高专业知识和护理技能水平,提高护理科研水平,促进护理事业健康、长足发展。这样,护理本科生的社会价值自然会得到社会各界的认同,本科护生自身也会由内而外,提高对护理职业的认同感,从而热爱护理事业,为护理事业的蓬勃发展贡献力量。
Δf=divV,f|∂Ω=f*|∂Ω
(14)
式中,Δ为拉普拉斯算子;div为散度算子;f|∂Ω=f*|∂Ω为狄利克雷边界条件。
对于图像融合应用,式(13)的离散化形式为
(15)
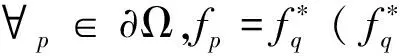
本文使用图像旋转扩增障碍物的多尺度特征,通过调整亮度和灰度化增强不同光照条件数据,使数据集扩增为原始数据集的6倍,同时针对尖锐碎石的样本量偏少,使用了小目标增强算法,使其样本数量增加到1 028个(表1)。
3 实验与分析
3.1 实验环境配置及评价指标
本实验采用的计算机配置为Intel© CoreTMi7-7800X CPU,NVIDIA GeForce 3090 (24G) GPU,本实验的网络模型基于Pytorch 1.7,Python3.6,Cuda11.1框架搭建,实验的各项参数集合见表2。
由于本文数据集较少导致模型难以拟合,因此训练采用了迁移学习方式,骨干网络RepVGG使用了Imagenet海量数据集训练的权重,本文目标检测模型作为下游任务,对骨干网络权重进行裁剪,删除不必要分类分支,并在VOC2007+2012数据集上进行预训练,得到迁移学习的VOC数据集权重;然后基于VOC数据集权重,对权重的分类分支进行修改以契合本文类别数目,并采取分段式训练方法,首先冻结骨干网络权重进行冻结训练,使网络骨干在训练初期只参与特征提取并不对权值进行更新,防止训练初期网络随机性过大破坏初始权值;训练20个Epoch后,解冻骨干网络权重参与整个网络训练,并进行50个Epoch的训练。

表1 数据增强前后样本分布
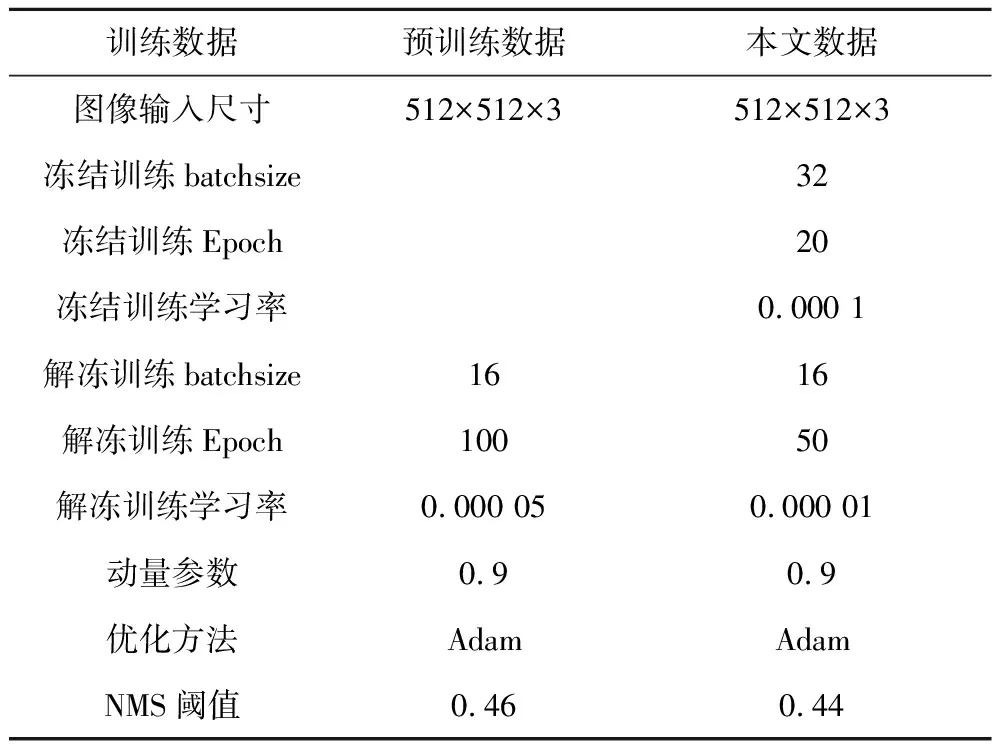
表2 实验各项参数设置
实验采用精确度(Precision,P)、召回率(Recall,R)、平均精度(Average Precision,Pave)和平均精度均值(Mean Average Precision,Pmap)四个指标作为模型精度评价的标准:
式中,TP为正确检测出的目标;FP为将背景错误检测为目标;FN为未能检测出的目标;n为目标检测的类别;N为检测到的障碍物数量;Pave为衡量模型对负障碍目标检测的准确性;Pmap为所有Pave的平均值,用来衡量整个模型的检测准确度。
在模型的推理速度和计算量方面采用了参数量(Pparams)和浮点运算数(Fflops),Fflops作为评价指标,Pparams和Fflops的计算方法为(以卷积层计算为例):
Pparams=KhKwCinCout+Cout,
式中,Kh、Kw为卷积核高度和宽度;Cin为输入通道数;Cout为输出通道数;H′、W′为输出特征图尺寸高度和宽度。
3.2 障碍检测模型实验与性能分析
如图10所示,本文所提出的露天矿区障碍检测模型在密集目标、光线不理想、复杂背景等情况下都有着良好的表现。在大尺寸物体的检测上边界框定位精准,物体置信度均高于0.9,在小目标的检测中,对于行人和尖锐碎石的检测性能较好,对于多尺度特征的负向障碍也能做到更加准确的检测和精确定位,可以满足露天矿区无人矿卡在封闭、低速环境下的安全驾驶需求。
如表3所示,本文模型与主流的目标检测网络进行了对比分析,所有训练均使用迁移学习方式,由于网络特性不同,SSD,Faster-RCNN,RetinaNet,本文模型均采用了VOC2007+2012作为预训练数据集,YOLO4,YOLOX,EfficintDet使用了COCO2017数据集作为预训练数据集。
本文模型达到了91.76%的Pmap取得了最好的检测精度,检测速度、参数量和Fflops分别达到了56.74 fps、28.2 MB和39.4 GB,有着最好的综合性能。其中anchor free的代表网络,YOLOX在面对多种任务时都有着良好的表现,取得了87.75%Pmap,anchor base的EfficintDet-d3也取得了88.01%Pmap,由于预训练时YOLOX,EfficintDet-d3采用COCO数据集对于小微目标中的行人、汽车时有着良好的检测效果,但是YOLOX,EfficintDet-d3在检测碎石的Pave分别为59.70%、76.24%。

图10 露天矿区障碍物检测结果Fig.10 Obstacle detection results in open pit mine

表3 不同网络模型对比
由于EfficintDet-d3的输入分辨率为896×896,使得其小目标预测分支的特征图尺寸为112×112,这使得它对于露天矿区障碍物数据集有着极好的精度,由于EfficintDet网络使用了大量的深度可分离卷积降低参数量这导致其参数量和Fflops仅为11.9 MB、23.15 GB,但其输入分辨率过大,网络结构复杂导致推理速度较慢,难以满足实时性要求。
传统的网络如SSD和Faster-RCNN的检测精度均不理想,但是SSD取得了112.96 fps的检测速度。而YOLO4由于输入分辨率仅为416×416对于小微目标难以取得良好效果。
3.3 障碍检测模型预训练影响因素分析
如上文所述,本文提出的目标检测模型作为分类骨干网络的下游任务,使用ImageNet 1K大规模图像分类数据集进行训练的RepVGG权重,作为迁移学习的基础权重。ImageNet 1K包含1 000个对象类,1 281 167个训练图像、50 000个验证图像和100 000个测试图像。为了验证迁移学习的必要性与骨干网络的选择,分别使用RepVGG、RepVGG+、ResNet三种骨干网络在VOC2007和2012数据集上进行训练,使用权重随机初始化与载入预训练权重进行对比。
如图11所示,通过对比网络是否使用ImageNet海量数据训练的权重,可以看出网络在loss收敛和每个epoch的Pap中都有着显著的差异性,图11(c)中,在不使用骨干权重时,网络在60个epoch时渐渐趋于拟合,此时模型精度仅为60%左右。而使用了预训练权重的网络,在20个epoch时网络已经逐渐趋于拟合,且精度为80%左右。在图11(d)中RepVGG作为骨干网络相较于ResNet有着近似的性能表现,可见使用了海量数据作为预训练的权重,在实验中,有助于加速模型的收敛,同时提升模型的精度。同时如图11(d)所示,本文所提出的RepVGG+,相较于ResNet和原始结构,有着更加优异的性能表现。
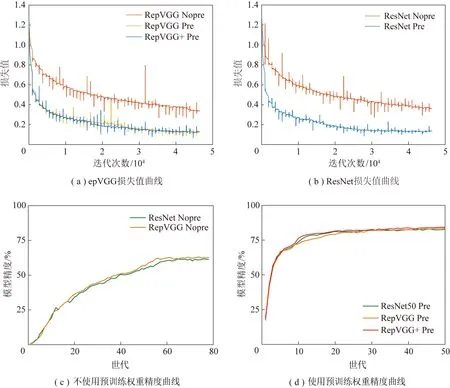
图11 RepVGG_A2、RepVGG_A2+、ResNet50骨干网络预训练结果Fig.11 Pre-training results of RepVGG_A2,RepVGG_A2+,and ResNet50 backbone networks
3.4 障碍检测模型有效性分析
3.4.1 RepVGG+网络性能分析
为验证提出的RepVGG+的有效性,针对露天矿区障碍检测模型的骨干网络消融实验对比,并分别在预训练的VOC数据集和本文数据集上进行测试。其结果见表4。
如表4所示,当本文按照常规的网络设计,提取骨干网络后3层作为FPN结构的输入时,由于Res-Net50相较于RepVGG A2的参数量更多,在VOC数据集和本文数据集中都比RepVGG A2更加优异,但RepVGG由于在推理时使用了层间融合等方法,推理速度显著优于ResNet50。RepVGG A0作为轻量型骨干网络参数量仅有7.03 MB,但精度也较低,RepVGG B2由于其网络更深,能够提取到更多的特征信息,在预训练中达到了82.45%Pmap,但是其参数量巨大,检测速度较慢。本文针对RepVGG在目标检测任务中的缺陷,所提出的RepVGG A2+结构,在扩增了Stage4的卷积层数并引入金字塔池化结构,使模型更加适应于小类别目标检测。如表4所示,使用RepVGG+骨干网络的模型在VOC数据集的精度超越了ResNet50,达到了81.94%的Pmap,同时增加了少许参数量,由于RepVGG作为轻量型骨干网络,其特征提取能力还稍显不足,在针对碎石等小目标时,难以获取更加抽象的特征信息,去分离背景特征,导致在本文数据集中相较于ResNet50低了0.58%的Pmap。
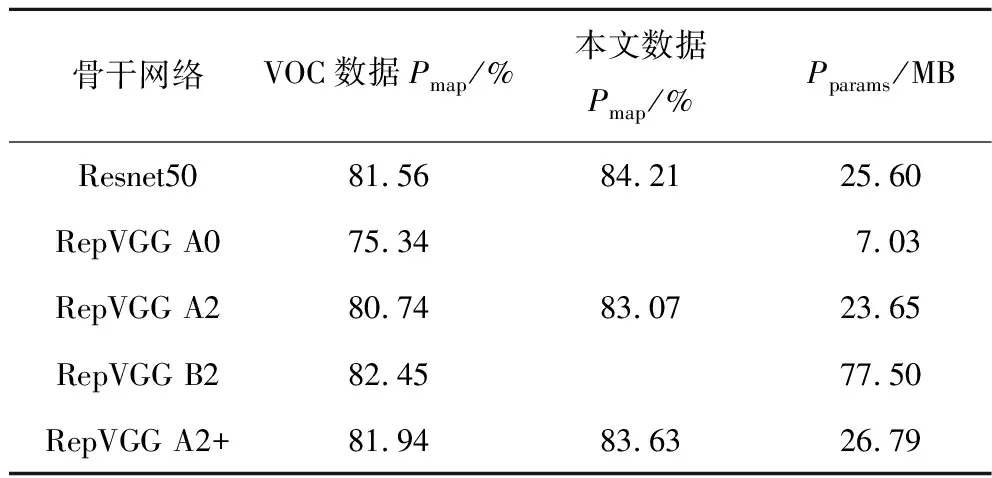
表4 不同骨干网络对于模型性能影响
3.4.2 注意力机制影响分析
为了改善模型在上采样过程中的特征信息丢失问题,在B-FPN中引入了SimAM注意力机制,见表5,相较于传统的通道注意力SENet[38]和通道与空间注意力CBAM[39],SimAM在不增加参数量的基础上有着更好的性能。

表5 不同注意力机制对模型性能影响
如图12所示,笔者使用GradCAM++[40]方法对不同注意力机制进行了特征可视化。SENet基于通道维度对神经元进行增强,其效果并不显著,而基于通道与空间的注意力机制CBAM和SimAM都能很好地增强神经元信息,从而改善特征丢失问题。
3.4.3 消融实验与分析
为验证针对小目标和多尺度目标提出的特征融合机制、分类预测模块和改进Loss函数的有效性,设计了消融实验,针对露天矿区道路障碍物数据不足问题进行了数据扩增,见表6,由于扩增前模型处于欠拟合状态且训练样本极不均衡,通过数据集扩增后大幅提升了模型精度。对FPN模块进行了重新设计,提出了基于通道和空间注意力的SimAM注意力和跨阶段连接卷积的双向特征融合的B-FPN结构,针对小微目标,在最大尺度的特征图后加入了SSH卷积模块,扩大感受野,进一步提升其检测性能。如表6所示,提出的特征融合模块在加入了SimAM注意力机制和SSH后检测精度均得到了提升。同时由于双向FPN结构已经提取到大量的特征信息,如果在模型的Head中还是使用连续的4次卷积+ReLU会导致特征冗余,因此将Head优化为连续2次3×3卷积+LeakyReLU,使用改进的骨干网络+FPN+Head取得了更好的精度,在VOC数据集和本文数据集上分别达到了83.87%、86.35%的Pmap。

图12 基于GradCAM++的不同注意力机制特征Fig.12 Characterization of different attention mechanisms based on GradCAM++
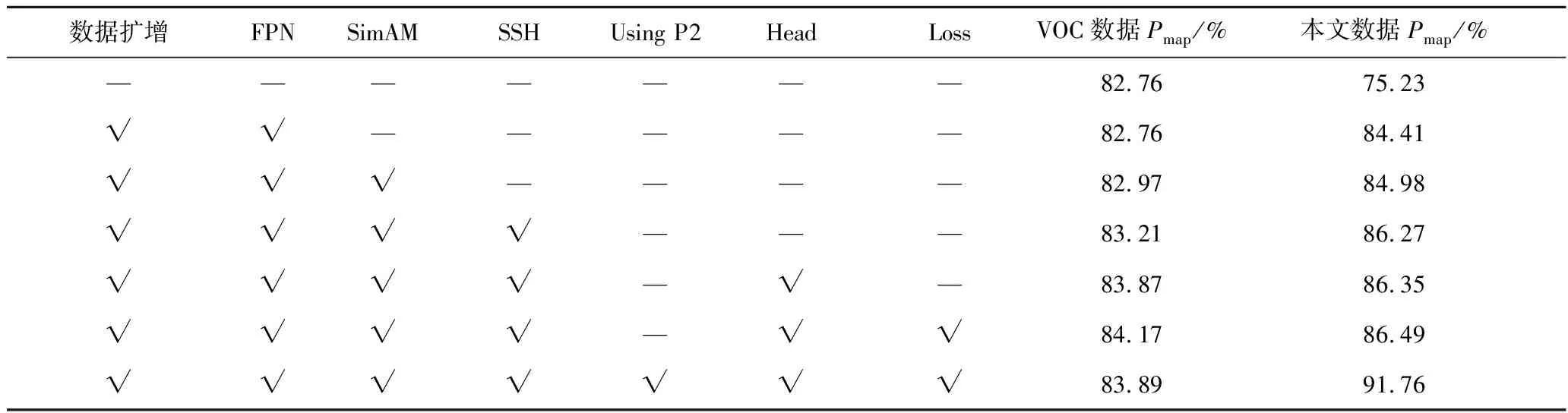
表6 消融实验

图13 Loss函数对模型检测效果影响Fig.13 Effect of Loss function on model detection effect
如图13(a)所示,在模型的实际验证过程中,取置信度为0.05时,发现同一目标有着大量的重合框与定位不准确问题,因此本文在训练过程中对Loss进行优化。
如图13(b)所示,改进后的Loss函数很好的抑制了这一问题,同时表6也表明,在引入改进后Loss函数模型在2个数据集的精度达到了84.17%和86.49%的Pmap。
但是本文模型针对露天矿区障碍物中的碎石检测仍然是个难点,在对网络的骨干网络、FPN、Head、Loss函数优化后,碎石的Pap只有63%,因此本文提取骨干网络的4层输出,进一步扩大网络预测小目标分支的特征图尺寸,使网络预测最大特征图从64×64,提升为128×128,极大地提升了小目标的预测能力,在本文数据集中达到了91.76%Pmap,其中尖锐碎石的Pap为85.38%。如表6所示,由于小尺寸特征图主要作用与大尺寸抽象目标预测,导致了本文模型在VOC数据集上的精度为83.89%Pmap,相较于3个骨干网络输出层的模型减少了0.27%。
4 结 论
(1)针对露天矿区无人矿卡行进障碍检测,提出了基于双向融合机制的露天矿区障碍检测模型,模型采用了改进的RepVGG A2+进行障碍特征提取,B-FPN对多尺度障碍特征进行双向融合,增强不同尺寸特征图的特征信息,对小微目标检测分支额外使用SSH结构增强感受野,提升尖锐碎石等障碍信息表达能力。
(2)针对分类预测模块进一步调整,删除冗余信息提升模型检测精度与速度。针对类别不均衡问题使用标签正则化优化Fcoal Loss,使用GIoU Loss优化边界框回归Loss。
(3)实验表明本文模型在多种情况下都有着良好的检测性能,达到了91.76%Pmap和56.76 fps的检测速度,满足无人矿卡准确快速检测需求,对比主流的目标检测网络也处于领先地位。
(4)通过实地采集与数据扩增建立了露天矿区障碍数据集,然而受限于采集数据的露天矿区较少以及规模较小,本研究仍有不足之处难以覆盖不同路况的露天矿区。此外,如何利用大量数据缺失标注的图像进行自动标注和对抗生成图像,去扩增数据集也有待进一步研究。
