基于随机森林和梯度提升决策树的高血压分析预测
2023-05-14沈赛拉钟锋梁兴陈思悦沈诗钰陈璐静
沈赛拉 钟锋 梁兴 陈思悦 沈诗钰 陈璐静
摘要: 为进行高血压的危险因素分析与预测,提出一种基于随机森林和梯度提升决策树的模型。首先基于体检报告数据进行缺失值处理、one-hot编码、归一化、数据初步聚类等预处理;然后针对数据样本不均衡的特性,利用SOMTE算法进行重采样,基于随机森林得到特征重要性评分并进行特征选择;最后基于排名前20的特征值,利用梯度提升决策树算法产生预测模型。模型分析结果显示了高血压的危险性因素。经数据集交叉验证,模型准确率可以达到84.51%,具有较高的应用价值。
关键词: 慢性病; 高血压; 随机森林; 梯度提升决策树
中图分类号:TP391 文献标识码:A 文章编号:1006-8228(2023)05-15-05
Analyze and predict the risk factors of hypertension based on the Random
Forest and Gradient Boosting Decision Tree
Shen Saila1, Zhong Feng1, Liang Xing2, Chen Siyue1, Shen Shiyu1, Chen Lujing1
(1. Department of Computer Science and Technology, School of International Business, Zhejiang International Studies University, Hangzhou, Zhejiang 310023, China; 2. Lejian Health Technology Group Co., Ltd)
Abstract: To analyze and predict the risk factors of hypertension, a model based on the Random Forest and Gradient Boosting Decision Tree is proposed. Firstly, the missing value handling, one-hot encoding, data normalization and data cluster methods are applied for data preprocessing based on the medical examination report data. Then, the SOMTE resampling algorithm is used to solve the imbalanced class problem, and the feature evaluation and selection are realized through the Random Forest. Finally, the prediction model is training by the Gradient Boosting Decision Tree based on the top 20 features. The analysis result shows the risk factors of hypertension. The accuracy of the model can reach 84.51% by the cross validation of the dataset. It has a good value in application field.
Key words: chronic disease; hypertension; Random Forest; Gradient Boosting Decision Tree
0 引言
健康是人類最普遍最根本的需求,人民健康是民族昌盛和国家富强的重要标志[1]。据国家卫健委发布的《中国居民营养与慢性病状况报告(2020)》,2019年我国因慢性病导致的死亡占总死亡的88.5%,其中,心脑血管病、癌症、慢性呼吸系统疾病死亡比例为80.7%。高血压、糖尿病、慢性阻塞性肺疾病患病率和癌症发病率与2015年相比有所上升[2]。
高血压是常见且容易被忽略的慢性疾病,长期罹患高血压易导致视网膜、肾脏、心脏及脑部血管的并发症,尤其对心脏与脑部血管的影响最常见[3]。通过对高血压慢性病相关因素分析,可以发现并排查其他体检指标与高血压患者高度相似但血压测量正常的体检者,这部分人可能也具有高血压潜在风险,对其预测具有重要意义。
1 样本数据预处理及初步分析
1.1 样本数据预处理
首先对样本数据进行预处理[4]。
⑴ 删除缺失值过多数据和无效数据,主要是收缩压或者舒张压有缺失值的数据。
⑵ 将数据随机打乱。由于数据是按时间排序的,数据打乱后分出的训练集和测试集更有代表性。
⑶ 缺失值填充。缺失字段采用众数填充的方法补充缺失值。
⑷ 如果数据特征值类型个数少于等于6个,转换为one-hot编码;如果数据特征值类型个数大于6个, 转换为小数类型。one-hot编码可以有效解决分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用。它的值只有0和1,不同的类型存储在垂直的空间。
⑸ 归一化处理。有利于提高数据精度,让各个特征对结果的做出的贡献相同。
1.2 样本数据初步分析
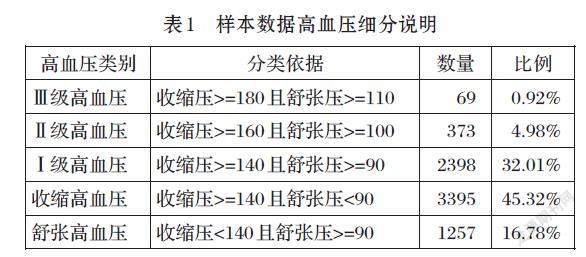
本项目采用脱敏体检报告数据共计57427条,除去无效数据10689条(收缩压或舒张压数据有缺失),有效数据共计46738条。经过初步分析,有高血的数据样本为7492,占比16.03%,正负样本比例1:5.24,属于不均衡数据。对高血压样本进行进一步分析,Ⅰ级高血压和单纯性收缩期高血压占了正样本绝大部分,比例为77.33%,具体数据如表1所示。
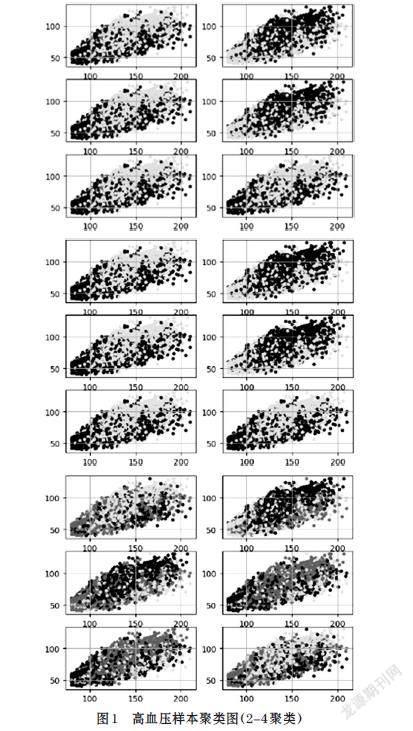
根据样本特征预测样本类型,通过尝试聚类进行初步探索分析[5],验证高血压的传统分类是否具有可行性。我们使用样本数据中除血压(收缩压)、血压(舒张压)外的体检项目指标对样本进行聚类分析,尝试聚为2-4类,并观察类别的血压分布,结果如图1所示。
结果发现,k=3时聚类效果较好,两条分类界线大致为140/90的传统分界线和数据分布主轴(主轴两侧是高脉压差和低脉压差)。结合医学背景知识,根据收缩压-舒张压=50将高血压细分为高脉压差高血压和低脉压差高血压,得到最终的因变量表2。
2 高血压慢病体检指标相关性与预测
2.1 研究框架
根据研究两种模型的特性,随机森林鲁棒性好,但上限低;梯度提升决策树对训练集较敏感,但上限高。本案例将数据做预处理后用随机森林进行特征评价,再次做预处理后用梯度提升决策树进行分类。算法流程图如图2所示。
⑴ 采集体检报告数据,每个样本包含脱敏体检人信息7个和体检项目信息1209个(即体检项目总数)。根据血压(收缩压)、血压(舒张压)两个项目给样本做分类,删去这两个项目,其余信息称为特征。
⑵ 删除无效数据记录和缺失值过多的特征,对缺失值进行众数填充,特征值进行转换和归一化处理。共得到有效数据46738条,每条数据具有有效特征数目128个。
⑶ 对样本进行初步聚类分析,结合高血压慢性病自身分类规则,对样本进行初步三分类。
⑷ 针对数据正负样本比为1:5.24的特点,文章在样本的采样上选择SMOT过采样技术进行处理。
⑸ 利用随机森林算法产生预测模型,同时得到特征重要性评分打分。根据特征值分值权重,我们选取前20个作为正式模型训练特征。
⑹ 采用梯度提升决策树算法正式产生预测模型,结果为样本属于高血压类别的概率。
2.2 不均衡数据采样处理
大多数机器学习算法在模型的学习过程中要求正负样本数据比例相当,模型可以学习正负样本数据所有特性,才具有较为良好的效果。而实际数据往往分布得很不均匀,例如本文样本数据二分类正负样本比例为1:5.24,三分类样本比例为10.86:3.22:85.92。数据的不均衡给模型的学习带来了困难。
本文采用SMOTE过采样技术进行数据采样,它是基于随机过采样算法的一种改进方案。传统的随机过采样采取简单复制样本的策略来增加少数类样本,这样容易产生模型过拟合的问题。SMOTE算法基本思想如下。
⑴ 对于少数类中每一个样本X,以欧氏距离为标准计算它到少数类样本集中所有样本的距离,得到其k近邻。
⑵ 根据样本不平衡比例设置一个采样比例以确定采样倍率N,对于每一个少数类样本X,从其k近邻中随机选择若干个样本,假设选择的近邻为Xn。
⑶ 对于每一个随机选出的近邻Xn,分别与原样本按照如下的公式⑴构建新的样本。
[Xnew=X+rand(0,1)?X-Xn] ⑴
2.3 基于隨机森林的相关性与分析
随机森林模型(Random Forest)是一种高度灵活的基于Bagging的集成学习模型机器学习算法,它可以同时生成多个预测模型,并汇总模型的结果以提升分类准确率,结构见图3[6]。
随机森林集成了Bagging和随机选择特征分裂等方法的特点,基本克服了过拟合问题,能根据特征的重要性进行特征选择,且算法效率较高,被广泛应用在各种分类和回归问题之中。Bagging是早期组合树方法之一,又称自助聚集(bootstrap aggregating),是一种从训练集中随机抽取部分样本(不一定有放回抽样)来生成决策树的方法。
Bagging回归算法流程为:
⑴ 以相同概率从训练集中随机有放回地抽出m个子训练集;
⑵ 对每个子训练集分别训练,产生m个基模型;
⑶ 取各基模型的平均值作为最终结果。
随机森林包含了多个由Bagging训练思想得到的决策树,在输入待训练样本后,各个子决策树结果的均值就是模型的最终结果。建立随机森林的步骤为:
① 对样本集T进行N次抽样,形成新的样本集;
② 随机选取特征,形成特征子集;
③ 在新样本集和特征子集上,找到最佳分割属性,建立决策树;
④ 重复①、②、③步骤m次,构建m棵决策树;
⑤ 组合m棵决策树的结果,建立随机森林模型。
2.4 基于梯度提升决策树的预测模型
梯度提升决策树(Gradient Boosted Decision Tree,GBDT)是由Friedman等提出的一种经典的机器学习方法,属于boosting系列算法中的一个代表算法,是一种迭代的决策树算法,所有树的结论累加起来作为最终答案[7~8]。GBDT设计的目的是求解损失函数的优化,具体思路为对损失函数求梯度,以负梯度的方向代入模型的当前值,以当前值作为残差值的近似。它采用了加法模型,通过向着减小残差的方向收敛得到将输入数据分类或回归的模型。
GBDT的经多次迭代后收敛,每轮训练多个分类器,每个分类器基于上一次迭代得到的残差基础上进行训练。作为集成学习方法的一种,GBDT的基分类器属于弱分类器,要结构简单且满足低方差、高偏差的条件,这与GBDT的损失函数是基于降低偏差有关。通常来说,GBDT通常以CART TREE 作为基分类器,且每棵CART TREE的深度相对较低以保证基分类器的复杂度不会过高。最终将每轮训练得到的基分类器加权求和,得到总的分类器。GBDT训练过程如图4所示。
3 实验及结果
3.1 随机森林相关性指标分析
文章针对样本进行随机采样、欠采样、过采样和SMOTE欠采样与过采样结合四种方式进行数据集采样,然后使用随机森林模型对样本进行初步训练。
针对不同采样方式的实验结果显示:
⑴ 随机森林决策树数目(n_estimators)为50,最大深度(max_depth)为35,三样本类比重为1.5、1.5、1,用于拟合和预测的并行运行的工作数量(n_job)为3,模型初步训练结果最优。
⑵ 由于正样本比例过小,基于Smote_Tomek的过采样与欠采样结合的采样方式综合效果最佳。
根据随机森林训练模型对特征项打分结果,我们选取前20项为高血压相关重要指标,如图5所示。年龄权重非常大,体重指数、甘油三酯、谷草转氨酶、谷酰转氨酶、体重、谷丙转氨酶、碱性磷酸酶、葡萄糖等8项指标权重较大。
3.2 基于梯度提升决策树的模型预测
⑴ k折交叉验证
为了避免训练过拟合,文章采用k折交叉验证[9]。尝试利用不同的训练集/测试集划分来对模型做多组不同的训练/测试,来应对单词测试结果过于片面以及训练数据不足的问题。鉴于高血压异常样本较少的情况,文章将两个高血压类型合并,与“正常类型比较”。
图6为k值取值不同,算法正确率(Accuracy)、查全率(Recall)、查准率(Precision)指标曲线。K值取25,正确率为84.51%,查全率39.41%,查准率40.05%。采用随机森林进行特征向量选取后,基于梯度提升决策树进行预测,正确率相比随机森林算法提升0.44%,查全率下降0.49%,查准率提升0.74%。
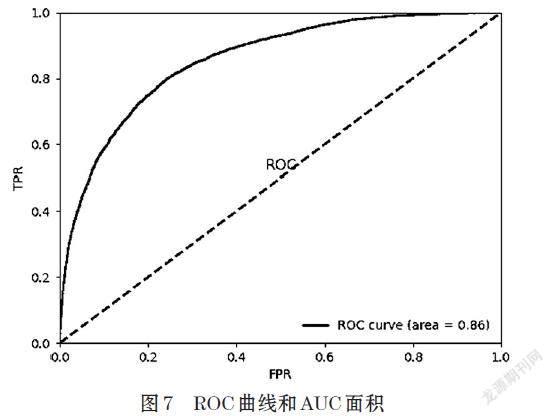
采用k=25折进行计算,对基于随机森林和梯度决策树的最终算法进行测试,绘制ROC曲线并计算AUC面积[10]。我们看到,ROC曲线均在对称轴之上,有较好的预测效果,AUC面积为0.86,模型效果较好。
4 结束语
本文基于体检报告数据,针对高血压风险进行分析与预测,提出首先利用随机森林进行特征选取,再基于梯度提升决策树进行预测的方法,最后利用K折交叉验证进行优化。
通过算法实验,我们得到以下结果:①K值取25时候的交叉验证,算法正确率为84.51%,查全率为39.41%,查准率为40.05%,为最优结果。此时,ROC曲线均在对称轴之上,有较好的预测效果,AUC面积为0.86,模型效果较好。②样本数据如果2分类正负样本比例为1:5.24为不均衡数据,虽然采用过采样欠采样结合进行取样后查准率和查全率有所提升,但是整体效果依然有限。
参考文献(References):
[1] 习近平:决胜全面建成小康社会 夺取新时代中国特色社会主义伟大胜利——在中国共产党第十九次全国代表大会上的报告[EB/OL].http://politics.gmw.cn/2017-10/27/ conent_26628091.htm.2017
[2] 国家衛生计生委疾病预防控制局.中国居民营养与慢性病状况报告(2020)[M].北京:人民卫生出版社,2022
[3] 张世宇,张晓东,邵彦铭,等. 国内外高血压管理模式研究进展[J].现代医药卫生,2021,37(23):4036-4040
[4] 郝爽,李国良,冯建华,等.结构化数据清洗技术综述[J].清华大学学报(自然科学版),2018,58(12):1037-1050
[5] 陈玉明,蔡国强,卢俊文,等.一种邻域粒K均值聚类方法[J].决策与控制,2022-02-07
[6] 曹桃云.基于随机森林的变量重要性研究[J].统计与决策,2022,38(4):60-63
[7] 郭靖.基于特征工程和高效梯度提升树算法的精准化混合推荐方法研究[D].硕士,武汉科技大学,2021
[8] 周杰英,贺鹏飞,邱荣发,等.融合随机森林和梯度提升树的入侵检测研究[J].软件学报,2021,32(10):3254-3265
[9] 褚荣燕,王钰,杨杏丽等.基于正则化KL距离的交叉验证折数K的选择[J].计算机技术与发展,2021,31(3):52-57
[10] 李子言.大数据背景下ROC曲线介绍与应用[J].科教导刊,2021(14):81-84
