基于眼动轨迹分析的BPPV 诊断算法研究*
2023-05-12刘津铭蔡跃新曾俊波唐小武区永康叶伟杰叶鸿生熊彬彬
刘津铭 蔡跃新 曾俊波 唐小武 区永康 叶伟杰 叶鸿生 熊彬彬 黄 栋
(1.华南农业大学数学与信息学院 广州 510642)(2.中山大学孙逸仙纪念医院 广州 510120)(3.珠海市中西医结合医院 珠海 519020)
1 引言
眼动研究是医学、心理学等领域的一个重要研究方向,通过观察眼动可以很好地解释某种病症或人类丰富且杂乱的神经心理学过程[1]。目前大多数研究是在某个特定任务下(例如浏览图像、阅读文本、视觉搜索等)追踪眼球运动或借助人眼的注视点等信息对人类行为进行分析。在医学领域的眼动研究多用于疾病诊断,良性阵发性位置性眩晕(Benign Paroxysmal Positional Vertigo,BPPV)[2]又称为耳石症,患者发病时会产生头晕症状并伴有眼震,医生可以通过观察患者的眼动情况来进行诊断。
由于在眼动视频上进行直接观测与诊断容易对眼震特征不明显的患者造成漏诊或误诊,而当前对眼动轨迹的自动分析研究仍然非常匮乏,对BP⁃PV 诊断的相关研究工作缺少利用眼动轨迹潜在信息。对此,本文提出了一种基于时序轨迹的BPPV诊断模型,将基于深度学习的目标检测器和基于时序轨迹分析的分类器相结合,对眼动视频进行检测并提取眼动轨迹做分类与诊断,同时针对类别不平衡问题,结合数据增强对其进行应对,并在500 个病例数据的实验中对诊断结果进行了评估。实验表明,所提出的模型可以有效应对各种复杂情况下的人眼检测,并在保证检测精度的同时提升BPPV诊断的准确度。
2 基于时序轨迹的BPPV诊断模型
2.1 基于目标检测的眼动轨迹提取
通用目标检测算法是在给定图像中识别出目标的位置(object localization)的同时预测出类别(object classification),并用标有置信度的矩形边界框对检测目标进行标记[3]。目前通用目标检测算法主要可以分为两种类型。一种是两阶段(two-stage)检测算法,首先通过卷积网络得到候选区域,然后再对每个候选区域进行分类来得到预测的目标类别。另一种是单阶段(one-stage)检测算法,将目标检测转换成一个回归或分类任务,可以不预先单独得到候选区域,而是采用统一的框架直接确定边界框位置和目标类别,因此检测速度较快。典型的单阶段检测算法包括YOLO[4~5]和SSD[6]等。
本文采用YOLOv4[7]模型对眼动视频中的眼球虹膜进行目标检测。与YOLOv3[8]算法相比,YO⁃LOv4 的主干特征提取网络将带有跨阶段局部网络(CSPNet)[9]的Darknet53网络代替原来的Darknet53网络,同时也将Mish 激活函数代替原来的Leakey ReLU 函数。颈部网络不仅采用了多尺度特征融合的SPP(Spatial Pyramid Pooling)[10]以利用数据上下文特征,还在三个有效特征层的尾部添加PANet(path aggregation network)[11]用于特征的反复提取,头部预测部分的分类回归层继续沿用YOLOv3 的头部。实验表明,所训练模型可检测出多种人眼状态,在半遮挡情况下也能捕捉到虹膜区域,检测效果示例如图1 所示。值得注意的是,本文的目标在于捕捉眼球运动轨迹,由于YOLOv4 已经可以提供非常准确的眼球虹膜目标检测效果,采用更复杂目标检测模型的必要性较为有限。

图1 在眼动视频中的目标检测效果
本文在进行目标检测的同时,提取其眼动轨迹的时间序列。眼动轨迹的提取基于图像中的检测到的人眼区域,以检测框的中心作为虹膜中心,计算并记录视频每帧图像下左右眼检测框的中心值,由此得到双眼的眼动时序轨迹(如图2 所示)。由于眼震是眼球震颤,眼震的频率、幅度、方向、程度不同会导致眼球的移动位置在短时间内出现的变化不同,可能是细微的也可能是明显的。随时间变化的眼动轨迹可视化效果见图3。

图2 以矩形边界框的中心作为虹膜中心提取轨迹

图3 眼动轨迹可视化
2.2 基于眼动轨迹分析的分类模型
时间序列由根据时间顺序测量和排列的数值组成[12],时序数据复杂且包含大量与时间属性相关的隐藏信息,即数据内部相邻时刻的信息通常情况下具有某种相关性,属于流数据,对时序数据的分析和挖掘已经成为大数据分析领域的热点。时间序列分类和预测应用在智能交通、智慧金融、智慧医疗等领域,意义重大,影响深远。对于时间序列分类(TSC)[13],相似性度量是其关键。相比于常规数据,时序数据往往存在长度不等的问题,传统的欧氏距离往往不能适用。对此,本文采用基于动态时间归整(Dynamic Time Warping,DTW)的时间序列相似性度量[13]。
值得注意的是,在基于DTW 的时间相似性度量下,传统支持向量机(Support Vector Machine,SVM)[14]、深 度 神 经 网 络(Deep Neural Network,DNN)[15]等分类器因缺少相同长度的向量化特征而无法适用。对此,因其能够以样本相似度作为算法输 入,本 文 将 采 用k 近 邻(k-Nearest Neighbor,k-NN)[16]作为眼动时序数据的分类器。k-NN 算法可基于相似性度量,在训练集中找到若干个与给定的测试样本最相近的训练样本,然后使用“投票法”进行预测,预测的类别在k 个样本中类别标记出现最多[17]。眼动轨迹记录了依时间为序排列的眼球移动位置,且由于眼动视频时长不等长导致时间序列不等长,本文分类器选择基于DTW 相似性度量的k-NN分类器进行训练和预测。
在上一节的处理中,每段视频可分别提取出左眼和右眼的眼动轨迹。因此,在眼动轨迹分析过程中,可对三种情况进行分析(亦将进行对比实验),分别是:仅用左眼轨迹进行测试诊断,若测试样本被预测为眼动异常,则判定这是个患有BPPV 的患者;仅用右眼轨迹进行测试诊断,若测试样本被预测为眼动异常,则判定这是个患有BPPV 的患者;使用双眼轨迹进行测试诊断,若测试样本的左右眼两条轨迹同时被预测为眼动异常,则判定这是个患有BPPV的患者。
3 实验结果与分析
在本节中,本文将在“眼动视频”数据集上进行实验,在进行目标检测的同时提取眼动轨迹,并进行数据增强操作,最后对诊断结果进行对比与分析。
3.1 实验设置
本文实验采用的操作系统为Linux 系统,显卡是用24GB 显存的英伟达3090,深度学习框架为Pytorch,Torch 版 本 为1.7.0,Cuda 版 本 为11.0,Cudnn 版本为v8.0.5。
在训练检测模型之前随机选取了10 个眼动视频,并从每个被选出的视频中每隔10 帧获取一张图片作为一个检测数据,最终手动标注了608 张图片,并按照8:1:1 的比例划分训练集:验证集以及测试集。令初始学习率为0.001,Epoch 为150,Minibatch size 为32。在本文实验中,主要的检测类型分为两类:cross(十字形记号)、eye(眼睛),依据eye 类别的矩形边界框提取轨迹。
在训练分类模型之前,从眼动轨迹数据集的两种类别中分别随机选取80%作为训练集,剩下的20%作为测试集,将被选中作为训练集的训练样本的左右眼轨迹一起输入分类模型中训练,并只对训练数据做数据增强操作。在第3.7 节中,本文将进一步进行实验测试所用的诊断模型在不同k 值下的性能(见表5)。
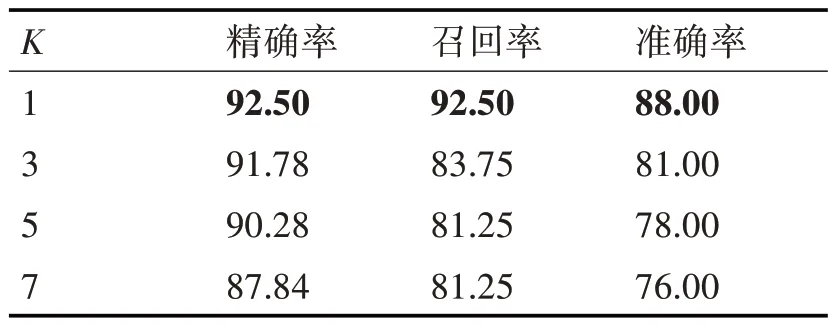
表5 不同k值的性能影响(%)(最高得分以粗体表示)
3.2 实验数据集与评价指标
本文实验将在“眼动视频”数据集上进行,数据集包含两种类别,分别是眼动正常(normal)和眼动异常(abnormal)。这些初始数据均为视频格式,各类数据的具体情况如表1所示。

表1 实验数据表
为对比在类别不平衡情况下数据增强的性能,本文采用了三种常用的评价指标,分别是精确率(precision)、召回率(recall)和准确率(accuracy)[18]。本文实验的精确率、召回率针对患者类别进行计算。
3.3 数据增强方法
类别不平衡(class-imbalance)[19]是指在分类问题中某些类别的训练样本显著多于其他类别的情况。针对类别不平衡问题以及时序数据的特点,本文运用了三种数据增强[20]方法对眼动轨迹进行扩充,但只针对训练集进行,分别是翻转(flip),剪切(crop)和抖动(jitter),以达到增加训练样本和提高诊断准确率的目的。我们在图4 中举例说明了时间序列进行数据增强后的变化。
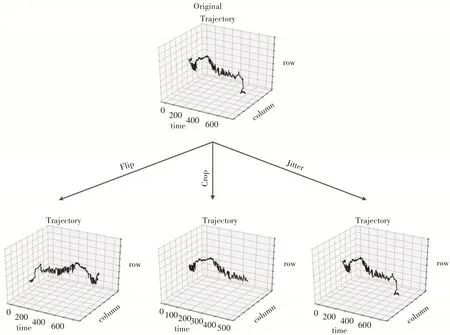
图4 时间序列数据增强图示
翻转(flip)是通过首尾翻转原始的时间序列x1,…,xS得到新的时间序列,其 中。在本文实验中,首尾翻转后新序列的标签与原始的时间序列保持一致。
剪切(crop)[21]是一种提取子样本的方法,原理是从原始时间序列中随机裁剪片段,可设置片段的长度,一般不与原始时间序列等长,片段的标签与原始时间序列保持一致。
抖动(jitter)是指轨迹的理想时序与实际时序之间的偏差。在本文实验中,通过对原始样本做轻微的小幅度数值调整得到新序列,达到扩充数据的效果,新序列样本的标签仍然与原始的时间序列保持一致。
3.4 数据增强次数对非平衡类别的性能影响
本节实验在k=1 的情况下对非平衡类别在不同数据增强次数下进行性能对比(使用双眼轨迹进行测试)。实验对比包括:(A1)正常样本无增强,异常样本无增强;(A2)正常样本剪切增强4 次,异常样本无增强;(A3)正常样本剪切增强4 次,异常样本翻转增强1 次;(A4)正常样本剪切增强5 次,异常样本翻转增强1次。其中(A3)为对照组。
如表2 所示,并非增强次数越多模型的诊断性能越好。当只对正常样本剪切增广4 次时,效果不佳。而当正常样本剪切增强5 次,异常样本翻转增强1 次时,准确率和对患者诊断的精确率和召回率都不如(A3)。当正常样本剪切增强4次,异常样本翻转增强1 次时,模型在不降低准确率的前提下对患者诊断的精确率提高到了92.5%,召回率不低于90%,因此(A3)的增强组合优于其他增强次数的组合,能得到较高的精确率和召回率。

表2 在k=1的情况下非平衡类别在不同数据增强次数下的性能表现(%)(最高得分以粗体表示)((A1)无增强;(A2)Crop4次+Flip0次;(A3)Crop4次+Flip1次;(A4)Crop5次+Flip1次)
3.5 数据增强类别的性能影响
在本节实验中,本文将在k=1 的情况下对比眼动轨迹时间序列在不同增强方法下的性能(使用双眼轨迹进行测试)。实验对比包括:(B1)正常样本剪切增强4 次,异常样本翻转增强1 次;(B2)正常样本翻转增强4 次,异常样本翻转增强1 次;(B3)正常样本剪切增强4 次,异常样本剪切增强1 次;(B4)正常样本抖动增强4 次,异常样本抖动增强1次。(B5)正常样本增强4 次,异常样本增强1 次,每次增强从抖动和剪切两种增强方法中随机二选一;(B6)正常样本增强4 次,异常样本增强1 次,每次增强从抖动和翻转两种增强方法中随机二选一;(B7)正常样本增强4 次,异常样本增强1 次,每次增强从剪切和翻转两种增强方法中随机二选一。
表3 给出了时间序列在不同增强方法下的精确度(%)、召回率(%)和准确率(%)得分。如表所示,无论是单独使用一种增强方法还是每次增强随机选择增强方法,准确率以及对患者诊断的精确率不如(B1)。因此(B1)的增强组合优于其他增强类别的组合,能得到较高的精确率和召回率。

表3 在k=1的情况下数据增强类别的性能影响(%)(最高得分以粗体表示)((B1)Crop4次+Flip1次;(B2)Flip4次+Flip1次;(B3)Crop4次+Crop1次;(B4)Jitter4次+Jitter1次;(B5)每次Jitter、Crop二选一;(B6)每次Jitter、Flip二选一;(B7)每次Crop、Flip二选一)
3.6 使用单眼轨迹与双眼轨迹的性能影响
在本节实验中,本文将对正常样本剪切增强4次与异常样本翻转增强1 次后在k=1 的情况下对比单眼轨迹与双眼轨迹的性能。如表4 所示,使用双眼轨迹对患者诊断的精确率优于仅使用单眼轨迹,精确率和召回率越高,漏诊或误诊的情况越少。

表4 在k=1的情况下使用单眼轨迹与双眼轨迹的性能影响(%)(最高得分以粗体表示)((C1)使用双眼轨迹;(C2)仅使用左眼轨迹;(C3)仅使用右眼轨迹)
3.7 不同k值的性能影响
在k-NN 算法中,k 值的大小会直接影响模型的性能。如表5 所示,给出了对正常样本剪切增强4 次与异常样本翻转增强1 次后在k=1、k=3、k=5 和k=7 情况下使用双眼轨迹测试的性能对比。值得一提的是,将k=1 和动态时间规整距离结合起来可以得到较优的诊断性能。当k=1 时,对患者诊断的的精确率和召回率都优于其他k 取值,这表明在眼动轨迹的分类时最近邻可以给出较为可靠的信息。因此,对正常样本剪切增强4 次与异常样本翻转增强1次、使用k=1进行训练,使用双眼轨迹进行诊断能(在测试集上)得到最佳的诊断性能。
4 结语
本文在BPPV 的诊断问题上,提出了一种基于眼动时序轨迹分析的BPPV 诊断模型。本文利用基于深度学习的目标检测器和基于时序轨迹分析的分类器相结合的方法,对捕捉到眼震特性的眼动轨迹进行数据增强和分类,实验证明其在对BPPV的诊断上取得了较佳诊断性能,可以辅助医学诊断,增加诊断效率,减少只用裸眼观察造成的漏诊或误诊。在未来研究工作中,本文的眼动轨迹分类模块一方面可以探索更多针对时间序列的数据增强方法,另一方面也可将其他处理时间序列的深度或非深度模型应用到该任务上,以进一步提升BP⁃PV诊断的准确性。
