一种基于YOLOv5 改进的动捕Maker 点识别方法*
2023-05-12李雅薇朱珈缘马媛媛
李雅薇 孟 娟 杜 海 朱珈缘 马媛媛
(1.大连海洋大学信息工程学院 大连 116024)(2.大连理工大学海岸和近海工程国家重点实验室 大连 116024)
1 引言
随着计算机水平与科技水平的不断提高,动作捕捉系统越来越多的出现在人们的日常生活和工作中。如影视游戏动画制作,机器人运动操控,虚拟角色互动,体育训练中捕捉运动数据,医疗康复训练中的运动障碍康复,人体实时连续健康监测等方面。目前,比较常见的动作捕捉方法主要可以分为两类:光学式和惯性式动作捕捉方法。本文主要探讨的是光学式动作捕捉方法。该系统更多地将光学球形标识物(Marker点)标记在运动的物体上,通过摄像机去确定光学标识物的空间位置进而去实现动作捕捉,从而获取该物体的运动轨迹。因此,圆形标记点的识别至关重要,对圆形标记的识别也就成为了现下热门的研究方向[1]。虽然目前市场上已有很多相关的动作捕捉系统,但基于简单特征Marker点的动作捕捉系统在复杂环境应用时,尤其是环境反光物体较多时,依然存在许多不足,有待完善。现有的研究大多集中在研究Marker 点3D重建数据[2]的精度和应用拓展方面,对于前期抗环境干扰、识别精度、速度以及稳定性方面仍需提高。识别的结果将直接影响到动作捕捉系统在后续动作的准确性,因此该项研究就变得尤为重要[3~6]。那么如何在较为复杂的背景中快速、准确、稳定地识别Marker点就成为了现在急需解决的问题。
动捕系统一般配备红外补光灯,在简单背景下,目标对比度较高,可在球形物识别算法中利用圆形特征来提取目标,如采用霍夫(Hough)变换检测方法。首先对图像进行图像增强[7]、边缘检测算子以及图像阈值化等预处理操作,再利用Xu 等提出的霍夫变换的基本思想进行圆形检测[8]。霍夫变换对于目标识别物体的边界存在噪声或者边缘连接的不够紧密时具有很好的鲁棒性和容错性。陈令刚等[9]通过对图像进行了Canny算子的边缘检测及阈值化处理,在一定程度上提高了在复杂背景中图像的识别率,但前期工作量较大,使用起来较为复杂;梁敏健等[10]利用HOG-Gabor 特征融合的方法去获取特征向量,再利用Softmax 分类器从而实现对目标体的识别。在一定程度上提高了对目标物体的识别准确率,但是相对于原模型降低了鲁棒性。随着计算机行业的飞速发展,虽然传统的目标检测方法也在不断完善改进,但是仍存在计算量较大以及操作复杂难度较高的缺点。
近几年随着卷积神经网络的快速发展以及运用,基于深度学习和机器学习的目标检测算法映入大众的眼帘,也逐渐地替代了传统目标检测的算法。在交通标志识别、人脸识别等常用的目标识别中,一般有用到RCNN 算法、SSD 算法、SPP 算法、YOLO 算法等。但在动作捕捉系统中,还未进行算法的应用与优化。通过对比上述算法的优劣发现,所需识别的圆形目标(Marker点)较小,可以考虑采用YOLO算法或者SSD算法。随着YOLO算法的不断改进,YOLO 算法也从v1 升级到了v5。其中YO⁃LOv3 算法不仅速度快,而且准确率高,检测小物体的能力也得到了很大的提升。邓天民[11]等通过改进Darknet53 网络结构进而减少迭代时的计算量,使其在检测识别中提高了检测速度,但也发现训练后的模型较大,不适合用于实际的动作捕捉系统中。YOLOv5 算法中的5s 其网络最小,AP 精度最低,并且识别速度可达到140FPS,线上分析效果可观,能够直接对单个图像,批处理图像,视频甚至网络摄像头端口输出进行有效推理,嵌入式设备也可以使用。
综上所述,本文针对动作捕捉在复杂背景下应用时的目标识别问题,提出一种半监督训练的圆形标记点识别方法,其中包括对YOLOv5算法的5s网络进行动捕应用适应性方面的改造(如CSP结构),以在保持计算负载不增加的情况下,提高特征提取能力。同时,对模型进行剪枝优化,实现模型轻量化。在最后实验环节,本文选用大连理工大学海岸和近海工程国家重点实验室所研制的非接触式六自由度运动测量系统中的数据集来进行测试,以此验证本文改进的算法的准确性和实用性。
2 基于半监督学习的圆形目标标记
传统的机器学习技术主要分为两大类:无监督学习和监督学习。无监督学习使用的是未标记的数据集,而监督学习则是使用已经标记的数据集。但在处理现实问题中,通常需要人工对数据集进行标记,需要耗费大量人工和时间,且只能得到小部分的带有标记的数据集。这就促使了使用标记样本和未标记样本的半监督学习技术的迅速发展。由于数据集较大,所以本文选择使用半监督学习中的伪标签标记法对数据进行标记。STAC[12]提出了一个基于Hard Pseudo Label 的半监督目标检测算法,如图1 可示。首先利用标记好的数据集训练出一个Teacher 模型生成伪标签,再将剩余没有标记的数据集输入到Teacher 网络中,得到大量的预测结果目标框。这时利用非极大抑制去消除所生成的冗余目标框,最后使用阈值来挑选高置信度的伪标签。最后利用图像增强的方法,将伪标签和未标记的图像相结合,计算出损失函数。本实验收集到数据集共有500 张图片,需要用YOLO-TXT 格式进行标记。首先利用labelimg 软件对小部分数据进行标记,即选择100 张图像来进行人工标记,标记结束后得到有标签的数据,利用有标签的数据进行线性训练,得到一个较理想的模型之后,在无标签数据上进行推理,得到伪标签,并使用阈值过滤掉分数较低的目标框,然后利用推理得到的伪标签与人工标记的标签进行合并,再次送入模型进行训练。训练结束后的模型在测试集上进行评估,同时利用此时的模型重新在伪标签数据集上进行推理,再重新生成伪标签并进行阈值的过滤,重复以上过程直到模型在测试集中的分数不再上升为止。这样就大幅度减少了人工标注的时间,同时也可以得到较好的标记数据集。

图1 STAC半监督目标检测算法示意图
3 YOLOv5模型框架
YOLOv5 模型[13~14]框架如图2 可示,主体部分由Backbone、Neck、Head 三个部分组成。按照网络深度大小和特征图宽度大小分为YOLOv5s、YO⁃LOv5m、YOLOv5l。

图2 YOLOv5模型框架
Backone 是YOLOv5 的骨干结构,主要采用的是Focus结构,CSPnet结构。Focus结构将输入的图像在纵向和横向间隔切片之后再进行拼接,跟在卷积下采样相比较,Focus 结构在输出深度方面提升了4 倍,这样就可以保留更多的图像信息。同时YOLOv5 也借鉴了CSPnet 的设计思路,在网络中设计存在两种csp 结构,一种是应用在主干网络中的csp1,一种是应用在Neck 中的csp2。CSPnet 使用跨阶段局部网络,缓解了以往需要大量推理计算的问题,增强了cnn 的学习能力,能够在轻量化的同时保持准确性,主要是通过将梯度变化从头到尾的集成到特征图中,在减少了计算量的同时可以保持准确率。随着卷积神经网络Backbone 不断展示出更强的多尺度表示能力,从而在广泛的应用中实现一致的性能提升。大多数现有方法以分层方式表示多尺度特征,这样就可以在运算量较小的情况下去识别目标物。
Neck 的核心部分为FPN(Feature Pyramid Net⁃works,特征金字塔)结构和PAN(Path Aggregation Net,路径聚合网络)结构。FPN和PAN两种结构充分的实现了高层特征与低层特征的融合与互补。其中FPN 结构是将高层的大目标的类别特征向低层传递,PAN 结构则是将低层的大目标的类别、位置特征和小目标的类别、位置特征向上传递,二者相互补充并克服各自局限性,强化模型特征提取能力。
传统的CNN 网络只是将最高层特征输入检测层中,这样就会导致存在小目标特征在多次传递后特征丢失,导致识别不准确的现象。而在YOLOv5中,Head 作为其检测结构部分,其具有三个检测头部分,分别对应小目标检测、中目标检测、大目标检测。这样就能有效地克服了特征局限性所带来的问题。
4 在运动捕捉应用中进行YOLOv5s算法优化
4.1 改进CSP结构
在自然场景中,许多视觉任务在多尺度上标示特征。在最新的进展中,基础的卷积神经网络展现了更强的多尺度表示能力,然而大多数现存的算法中主要是以分层的方式来表示多尺度特征。Res2net则是通过在一个单个残差块内构造分层的类残差连接来实现多尺度的特征获取功能,其更加精细的表示多尺度特征,并且增加每个网络层的感受野。这一特征可以使得动捕系统应用时,可以更加精准地获取目标点的特征信息,提高识别的稳定性。
上文所提到的csp1 中包含residual 组件[15](图3 所示),这不仅会导致计算量较大而且对于目标点的特征信息抓取能力不全面,所以本文提出使用res2net 结构对resnet[16]结构进行替换。Res2net[17]在一个单个的残差块内构造分层的残差类连接,为CNN提出了一种新的以更细粒度(granular level)去表达多尺度特征,在此基础上,再增加每个网络层的感受野(receptive fields)范围的构建模块Res2net。其主要利用一组更小的卷积核组来替换3*3 的卷积。具体来描述,首先需要将特征图分为几组,其中一组卷积核首先从一组输入特征图上提取特征,再将所输出的特征与此组输入特征图共同作为特征送入到下一组卷积核中。这样反复几次,直到所有输入的特征图都被处理。最后将所有的输出特征连接并通过1*1 卷积将信息所融合,这样就可以得到不同尺度的感受野,从而得到了更多的尺度特征。此外,Res2net 的结构还可以保持计算负载的负载不增加,这就对在多个尺度上表示特征的许多视觉任务中起到非常大的作用。

图3 CSP结构图
图4 (a)为CNN 网络架构的基本组成结构,图4(b)为Res2Net 模块的基本组成结构。我们可以观察到,与原模块相比,新模块具有更强的多规模特征提取能力,但计算负载量与左侧架构相似[18]。右图展示出了瓶颈块和Res2Net 模块之间的区别。在1×1 卷积之后,本文将特征映射均匀地分割成N组特征映射子集,由xi表示,其中i∈{1,2,…,n}。与输入特征图相比,每个特征子集xi具有相同的空间大小,但具有1/s 的信道数。除xi外,每个xi都有相应的3×3卷积,由Ki()表示,同时用yi表示Ki()的输出。特征子集xi加上Ki−1()的输出,然后馈入Ki()。为了在增加n 的同时减少参数,本文省略了xi的3×3卷积。因此,yi可以写成:

图4 CNN和Res2net的基本结构
这里需要注意,每个3×3 卷积运算符Ki()可能从所有特征分割{xj,j≤i}接收特征信息。每次特征通过3×3卷积算子分割xj时,输出结果可以具有比xj,更大的接收场。由于组合爆炸效应,Res2Net模块的输出包含不同的数量和不同的接收尺度的组合。
综上,本文采用res2net结构来替换YOLOv5 所使用的resnet 结构,其本质上就是利用一个较小的3×3 过滤器取代了过滤器组,这样就可以同时将不同的过滤器组以层级残差式风格连接。这样不但可以保证在动捕应用时地的识别能力,也不增加其计算负载量。
4.2 检测头部分修改
由于YOLOv5 对模型架构的修改使用的是yaml 外部配置文件[19]进行的,根据YOLOv5 模型框架图可知其具有三个检测头,分别对应小目标、中目标、大目标。在动捕系统中,主要将Marker 点附着在运动的物体上再去进行识别,并通过重构计算来获取运动物体的轨迹,所以应用时目标点均为小目标物。根据这一应用特点,本文进一步对算法进行剪枝操作,在算法中删除了后两个中、大检测头,只保留小目标检测头,就可以使模型进行轻量化,从而满足动捕对分析速度的要求。与此同时,模型轻量化可以更加容易地投入生产中,比原算法更适合应用于动捕系统中目标点的识别。
5 实验结果与分析
5.1 实验准备
本文采用了由大连理工大学海岸和近海工程国家重点实验室所研制的非接触式六自由度运动测量系统捕获的数据集进行试验。数据集为五个小球移动过程中利用高速照相机所拍摄运动照片。为了在YOLOv5 中对数据进行训练,采用上文所介绍的半监督学习方法对图像进行标注。为了显示方便,本文将样本中所有目标标记点的图像位置统一放置在一幅图像中,其分布如图5所示。

图5 目标在图像中的分布图
目标框长宽分布如图6所示。

图6 目标框长宽分布图
本实验的网络训练利用腾讯云服务器训练完成;模型框架为PyTorch;其评价指标:准确率Preci⁃sion、召回率Recall、平均精度均值(mAP)、GFLops作为目标检测模型的评价标准。公式如下:
其中TP 为正类判定为正类,FP 为负类判定为负类,TN 是负类判定负类。在Precision-Recall 曲线基础上,通过计算每个recall 值对应的Precision 值得平均,可以获得一个数组形式的评估即AP,AP计算公式为
其中r1,r2…rn 是按升序排列的Precison 插值段第一个插值处对应的Recall值。
所有类别的AP即为mAP,mAP计算公式为
5.2 训练结果及对比分析
从工程技术角度来看,动作捕捉系统在本质上是一种定位系统,通常需要在目标物上布置便于获取运动信息的定位设备进行追踪。光学动作捕捉系统主要是由高速摄像机、红外补光灯、光学镜头、动作捕捉软件、反光标识点和若干配件组成的。其中的反光标识点(Marker 点)就是为我们所要识别的目标物体。图7 为利用传统算法圆形度检测方法所得出的目标物体识别的分布图。
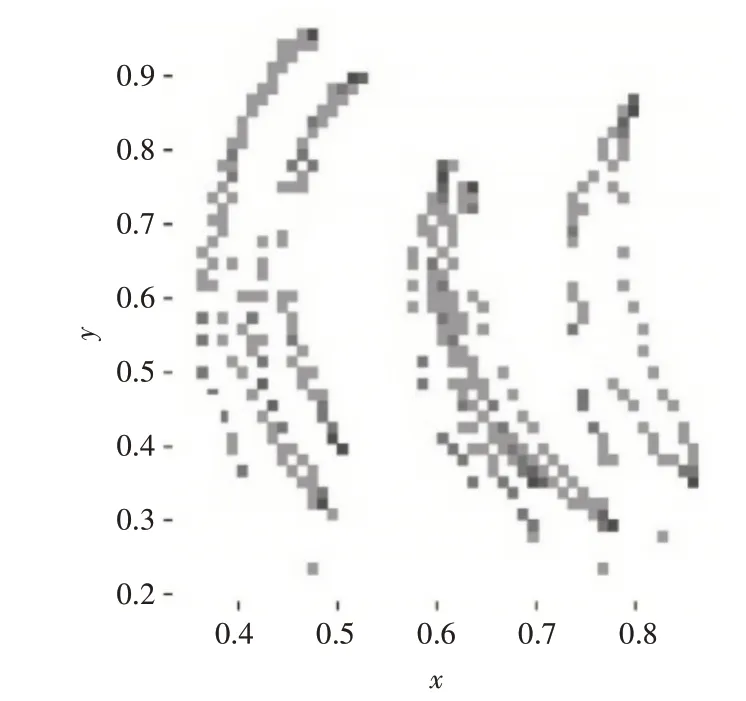
图7 目标物体识别分布图
通过观察可以发现最终的标记点轨迹图中有部分点缺失,这是因为Maker 点在运动过程中受到背景反光的影响而无法识别所产生的“丢帧”现象,这一问题所导致的数据缺失会严重影响后续对目标体运动的分析。因此,需要降低这种丢数据的情况,也就是说必须提高目标识别的稳定性。
采用深度学习的方式,在训练过程中,本文使用生成的伪标签数据作为训练集,将之前有标签的数据集作为验证集,使用teacher model 的权重当做预训练权重进行迁移学习,并对结果进行fine⁃tune。改进的YOLOv5算法的准确率与回归率的曲线图如图8、图9所示。

图8 算法的准确率

图9 算法的回归率
通过表1 中的对比数据可以清楚看出,通过对模型的更改,在替换了res2net 结构之后,模型的准确率与召回率有了一定的提升,并且GFlops从16.4下降到15.0,下降了1.4。在进行剪枝操作后,最终map0.5的值可以达到0.9961,同时GFlops也下降到了12.3,整体效果较为理想。将图7 和图11 相比较,可看出改进后的算法相对于传统的识别方法更加稳定,轨迹点丢失较少,基本可以稳定追踪目标点。

表1 改进算法与原始算法对比
为了再次测试算法改进的准确性,采取实验二将Marker点放置在复杂背景下进行运动测试,得出的具体测试结果数据如表2 所示。可以看出通过对模型的更改,map0.5 的值达到了0.9548,同时精确度提升了0.1484。

表2 改进算法与原始算法对比
综上所述,可以说明本文的改进方法对针对于动作捕捉系统中的圆形目标识别有明显的优化效果。

图10 改进后目标物体识别分布图
6 结语
本文为了解决动作捕捉系统在复杂背景应用时对圆形Marker 点识别稳定性较差的问题,基于YOLOv5 提出了一种改进的Maker点识别方法。首先通过利用半监督学习方法进行快速标记,之后在算法中选择res2net 结构和轻量化检测头进行改进。改进后的YOLOv5 算法在所有的数据集上进行训练测试对比原始的算法检测精度有了显著提高,且精度也较高,并在计算负载不增加的情况下,使模型更加轻量化,非常适合应用在实践当中。不足之处是对于本次应用的数据集,背景是静态的,在后续工作中将在各种环境中,包括更复杂的动态背景下,进行Marker点的识别准确率以及稳定性的测试。
