基于注意力机制的二进制标注事件抽取方法
2023-05-05徐洋
徐洋
(江西理工大学 信息工程学院 江西省赣州市 341000)
作为自然语言处理技术中的重要任务,信息抽取在知识获取中扮演着十分重要的角色。Grishman[1]将信息抽取定义为:从自然语言文本中抽取指定类型的实体、关系、事件等事实信息,并形成结构化数据输出的文本处理技术。而面向非结构化文本的事件抽取[2-4]是信息抽取领域中的关键任务和重要研究方向。
1 相关工作
目前事件抽取按照研究方法可分为三大类:基于模式匹配的方法和基于机器学习和基于深度学习的统计学习方法。根据两个子任务学习方式的不同,事件抽取模型可以分为两大类:管道式模型和联合学习模型。
1.1 基于管道式模型的事件抽取方法
研究者们最先将深度学习的方法应用在基于管道式模型的事件抽取任务中。PLMEE[5]还使用了两种模型,分别采用触发词抽取和元素抽取。元素抽取器使用触发词抽取的结果进行推理。通过引入BERT[6],它表现良好。MQAEE[7]将事件抽取视为多轮问答,从而将抽取任务转换为一系列阅读理解问题,但错误的触发词识别结果也会影响事件分类。直观上,如果第一步触发词识别有错误,那么元素识别的准确性就会降低。因此,在使用管道式模型抽取事件时,会出现级联错误和任务拆分的问题。直至现在,这些依然是研究者们需要解决的问题。
1.2 基于联合学习模型的事件抽取方法
为了解决管道式模型存在的缺陷,联合学习模型由此而生。所以,研究者们不断尝试利用不同的联合学习模型来提高事件抽取的效果。在使用深度学习对事件抽取任务进行建模之前,联合学习模型已经在事件抽取中进行了研究。Li 等[8]研究了基于传统特征提取方法的触发词抽取和元素抽取任务的联合学习,并通过结构化感知器模型获得最优结果。He and Duan[9]提出基于条件随机场(conditional random field,CRF)的多任务学习的事件抽取联合模型,他们依据事件类型分别构建了7 个标注任务,从而解决了事件元素角色重叠问题。
综上所述,尽管目前在事件抽取方面出现了大量的研究工作,但是它们只是聚焦于解决事件抽取的部分问题,鲜有工作能够同时处理引言中提到的所有问题。因此,本文提出了一种端到端的事件抽取方法,该模型不是利用触发词来识别事件元素,而是采用二进制标注方法,利用BERT 作为编码器,使用多头注意力机制,利用事件类型同时识别触发词和事件元素,总的来说,本文的贡献在于以下三点:
(1)提出了一种端到端的序列标注模型实现触发词分类和事件元素角色分类任务,此模型同时识别触发词和事件元素,避免了触发词识别错误对事件元素提取的影响。
(2)解决了事件抽取中存在的触发词重叠问题和元素重叠问题。
(3)在中文金融事件抽取数据集FewFC 上进行实验,实验结果验证了模型的有效性。
2 结合注意力机制的二进制标注模型
为了解决触发词重叠和元素角色重叠问题,本文提出了一个结合注意力机制的二进制标注网络模型BinaryEE,其架构如图1所示。
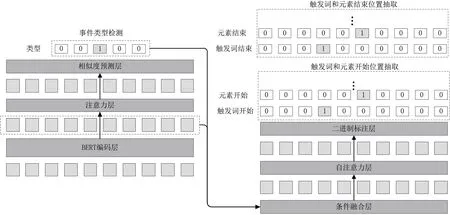
图1:BinaryEE 模型框架
BinaryEE 采用共享的BERT 编码器来捕获文本特征,并使用两个模块进行事件类型检测、触发词和元素抽取。
2.1 输入和编码层
BERT 是一种基于Transformer 架构的双向语言表示模型,能够生成具有丰富语义信息的上下文表示,BERT 编码由式(1)所示。
其中,X为输入句子x的序列,Wt和Wp分别为可学习的词嵌入矩阵和位置嵌入矩阵,N为12,Hi表示输入句子在第i层BERT 网络的输出。
2.2 事件类型检测模块
为了解决触发词重叠问题,本文通过预测句子中存在的事件类型,来抽取对应的事件触发词。本文设计了一种事件类型检测模块,来预测事件类型。
每种类型的事件通常由一组特定的词触发,称为事件触发词。因此,事件触发词是这个任务的重要线索。然而,这个信息在本文的任务中是隐藏的。受Liu 等[10]的启发,本文采用注意力机制来模拟隐藏的触发词,继而检测事件类型,为每种可能的类型捕获最相关的上下文。
最后,本文通过相似度函数δ衡量自句子表示sc和类型嵌入c的相关性来预测事件类型。那么,就得到了句子中出现的每个事件类型的预测概率,由式(3)所示。
其中σ表示sigmoid 激活函数。本文选择的事件类型作为结果,其中是一个标量阈值。句子x中所有预测类型组成事件类型集合Cx。是模块可学习参数。
2.3 结合注意力机制的触发词和元素抽取模块
为了识别具有不同事件类型的重叠触发词,本文以特定类型c∈Cx为条件来抽取对应类型的触发词和事件元素。这个模块包含一个条件融合函数、一个自注意力层和一对用于触发词和事件元素的二进制标注器。
为了模拟类型检测和事件抽取之间的条件依赖关系,本文设计了一个条件融合函数,将条件信息集成到文本表示中。具体为,本文通过将类型嵌入c并入到词表示hi中,来获得条件词表示,由式(4)所示。
其中,可以通过拼接、加法运算符或门机制来实现。为了在统计方面充分生成条件表示,本文引入了一种有效且通用的机制,条件层归一化LN[11],以实现。LN主要基于众所周知的层归一化,但可以根据条件信息动态生成增益γ和偏置β。给定一个条件嵌入c和一个词表示hi,LN 表示由式(5)所示。
因为注意力机制能一步捕捉到全局的信息,可以更加全面地获取句子的特征,所以,为了进一步细化用于事件抽取的表示,本文在条件词表示上引入注意力机制[12],注意力机制的定义由式(6)所示。
为了预测触发词和事件元素,并识别具有不同角色的事件元素,本文设计了两组特定角色的二进制标注器。对于每个词xi,第一组用来预测它是否对应触发词和特定角色事件元素的开始位置;第二组用来预测它是否对应触发词和特定角色事件元素的结束位置,由式(7)所示。
其中σ表示sigmoid 激活函数。对于触发词t,本文选择作为触发词开始位置的词,作为触发词结束位置的词。对于每个角色r,本文选择作为事件元素开始位置的词,作为事件元素结束位置的词。其中是标量阈值。
为了获得触发词t,本文枚举所有的开始位置并搜索句子中最近的结束位置,开始和结束位置之间的标记就形成一个完整的触发词。这样,就可以在不同的阶段根据类型分别抽取重叠的触发词。句子x中预测的所有属于类型c的触发词t组成集合模块参数θte包括条件融合函数、自注意力层和二进制触发词标记器中的所有参数。
为了获得带有角色r的事件元素,本文枚举所有开始位置并搜索句子中最近的结束位置,开始和结束位置之间的标记就形成一个完整的事件元素。这样,重叠的事件元素可以根据不同的角色类型分别抽取出来。句子x中预测的属于类型c的触发词t的所有事件元素组成集合模块参数包括类型嵌入矩阵C、条件融合函数、自注意力层和二进制事件元素标注器中的所有参数。
2.4 模型训练
3 实验与分析
3.1 数据集和评估绩效
本文在中文金融事件抽取基准数据集FewFC[14]上进行了实验。本文以8:1:1 的比例分割数据用于训练、验证和测试。表1 显示了数据集的更多细节。对于评估,本文遵循传统的评估指标[5],并使用准确率(P)、召回率(R)和 F 度量(F1)进行结果分析。
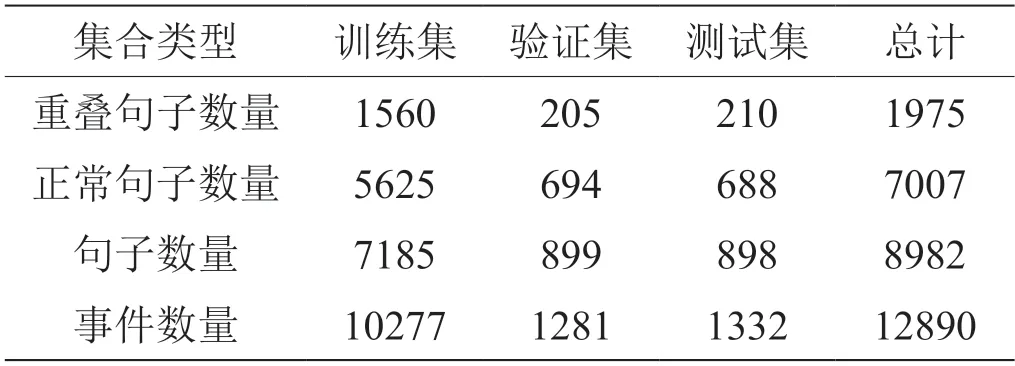
表1:FewFC 数据集统计
3.2 实验结果
虽然最近很多研究者为EE 开发了各种各样的模型,但很少有研究者研究解决重叠事件抽取问题。本文根据当前的解决方案采用以下基线进行实验对比。
联合的方法。这种方法大多将事件抽取转化为序列标注任务。BERT-normal[6]采用BERT 学习文本表示,并使用隐藏状态对事件触发词和元素进行分类。BERTCRF 采用条件随机场(CRF)来捕获标记之间依赖关系[15],BERT-joint 借鉴了实体和关系的联合抽取思想[16],采用可以称之为B/I/O-type-role 的类型与角色的联合标签。
管道式方法。这种方法以流水线方式解决事件抽取。PLMEE 通过根据触发词抽取角色特定元素来解决元素重叠问题。MQAEE 首先预测具有类型的重叠触发器,并且然后根据类型的触发器预测重叠的元素,称为MQAEE。
所有方法在FewFC 数据集上的表现如表2所示。从表中可以看出:
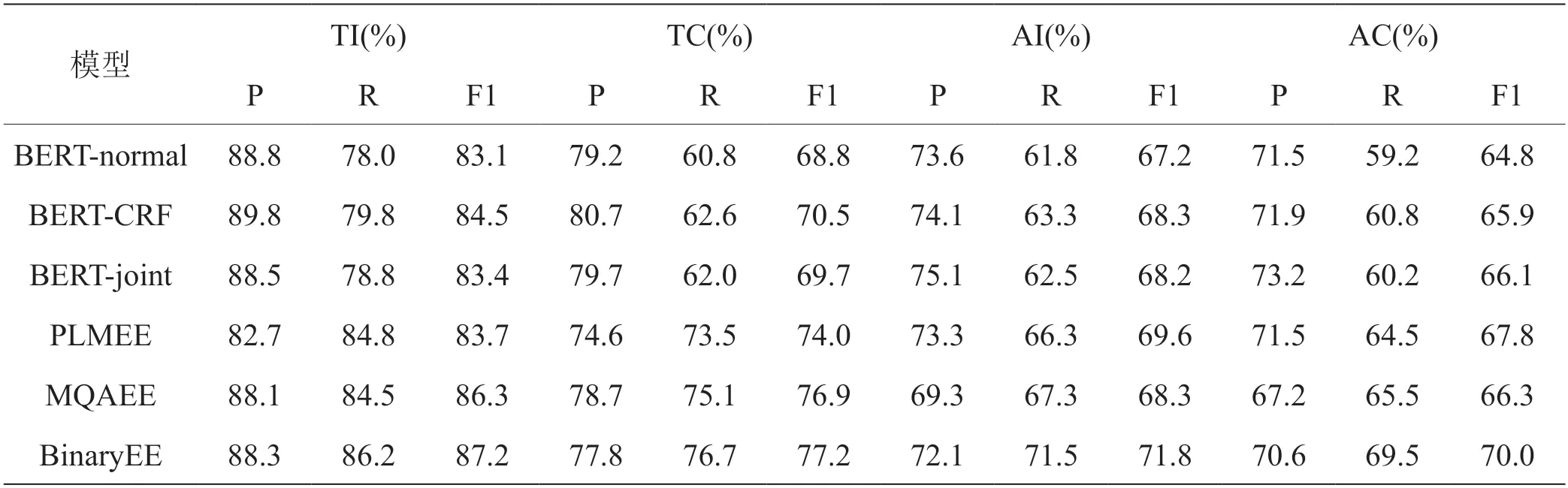
表2:FewFC 数据集上不同模型的实验结果
(1)与联合序列标注方法相比,BinaryEE 在F1得分上取得了更好的表现。具体来说,BinaryEE 在AC的F1 分数上分别比BERT-CRF 和BERT-joint 分别提高了4.1%和3.9%。此外,BinaryEE 在评估指标的召回率产生了更高的结果,原因在于这些序列标注方法有标签冲突,对于那些多标签标记只能预测一个标签。这样的结果证明了BinaryEE 在重叠事件抽取上的有效性。
(2)与管道式方法相比,本文的方法在F1 分数上也优于它们。与PLMEE 相比,BinaryEE 在TC 和AC 的F1 分数上分别实现了3.2%和2.2%的提升,表明了解决事件中的重叠触发词问题的重要性。另外,BinaryEE 与强大的基线MQAEE 相比在AC 的F1 分数上提高了3.7%。原因可能是BinaryEE 利用注意力机制学习触发词和事件元素的文本表示,在它们之间建立有用的联系。结果表明BinaryEE 优于上述管道式基线。
3.3 实验分析
在重叠句子上的性能。如表3所示,本文的方法在重叠句子上的性能明显优于以前的方法。与以往联合学习的方法相比,这可能是本文针对特定类型的触发词抽取方法和特定角色的元素抽取方法避免了标签冲突的属性;与以往管道式的方法相比,本文的方法避免了子任务之间可能存在的错误传播。
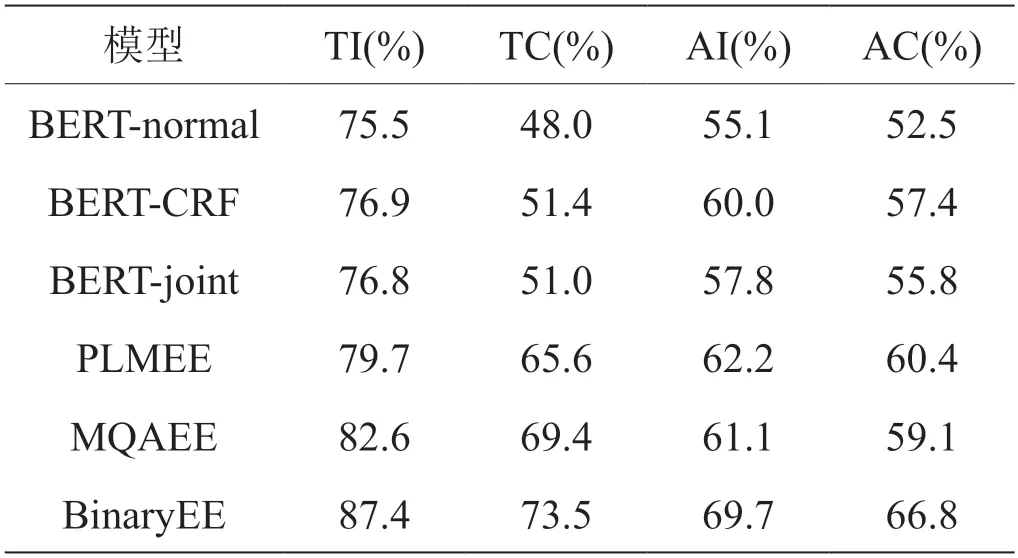
表3:重叠句子上不同模型的F1 值
在普通句子上的性能。如表4所示,其它联合学习方法在触发词抽取上的结果相似,但在元素抽取上的结果相对较好,这是因为它们避免了管道式方法在子任务之间的潜在的错误传播。在其它管道式的方法中,MQAEE 预测的触发词更准确,原因可能是它用事件类型联合预测触发词,使得元素抽取结果类似于BinaryEE。即便如此,与其它模型相比,BinaryEE 在正常句子上的性能仍然可以接受。
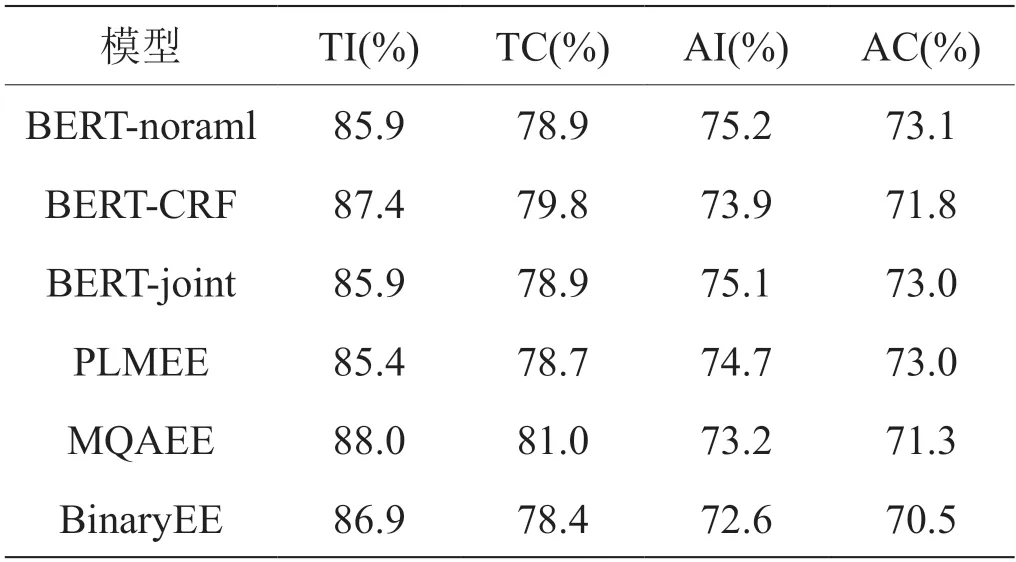
表4:普通句子上不同模型的F1 值
4 结语
本文提出了一种用于重叠事件抽取的联合学习模型,使用预训练语言模型作为文本的编码器,融合事件类型作为条件信息,采用注意力机制对同时对事件触发词和事件元素进行二进制标注,解决了事件抽取中存在的触发词重叠和元素重叠问题,同时也避免了传统管道式方法存在的错误级联和任务割裂的问题。在公共数据集上的实验表明,本文的模型在重叠事件抽取方面取得了良好的效果。然而,目前的方法只适用于句子级别的事件抽取任务,如何利用联合学习的模型从篇章级文本中抽取结构化的事件信息是下一步的主要研究方向和内容。
