基于GA-机器学习模型的污水处理厂BOD软测量研究
2023-05-05姚怡帆王黎佳王丽艳黄黎明刘长青
苗 露,姚怡帆,王黎佳,王丽艳,黄黎明,刘长青
(1.青岛市团岛污水处理厂,青岛 266002;2.青岛理工大学 环境与市政工程学院,青岛 266525;3.青岛张村河水务有限公司,青岛 266100)
生物化学需氧量(Biochemical Oxygen Demand,BOD)反映水质中可生化降解的有机物质的含量,是水质净化过程中必不可少的监测指标。污水处理厂常用BOD5(5 d生化需氧量)表示可被微生物分解代谢的有机污染物含量,BOD5检测所得到的数值直接影响生化处理部分的药剂投加与鼓风曝气[1]。因此,及时准确地获取进水BOD5对污水处理厂评价进水有机污染物的水平、进行对应的工艺参数调整具有重要意义。
目前,常用稀释测定法与微生物电极法检测BOD5[2],因其检测数值重复性较好,准确度和精密度高,所以得到了广泛的使用。但这两种测定方法在指导污水处理厂工艺运行方面仍存在一定不足,例如稀释测定法的检测周期长、操作专业度较高;微生物电极法[3]虽可快速、便捷地获得大批量水质分析数据,但是其仪器的使用存在局限性,且微生物电极法的检出限也普遍高于稀释测定法[4]。因此随着污水处理厂工艺的提升,需要构建一种更高效、简便、精准的BOD5检测方式。
随着计算机及大数据相关技术的迅猛发展,机器学习作为模拟人类学习活动的一门人工智能学科应运而生。在环境领域,善于挖掘数据之间关系的机器学习进入科研工作者的视野,通过建立准确的数学模型对水质中某些重要的参数进行科学的软测量与预测,取得了一定的成果。ELIAS等[5]提出了一种集经验模态分解、深度学习和长短期记忆神经网络于一体的混合模型,通过此模型对养殖水质中的溶解氧、浊度、pH三项指标进行预测,数据展现了较高的预测精度,优于其他同类水质参数预测模型。WU等[6]利用极端梯度提升(Extreme Gradient Boosting,XGBoost)与麻雀搜索算法优化的LSTM模型进行长期与短期的溶解氧软测量,能够满足池塘溶解氧准确预测的实际需求。LIU等[7]在无线监测的基础上,采用支持向量算法预测总氮、总磷、氨氮等水质指标,并能够自动、实时地对流域水质进行监测。
如今,已有多种水质软测量的机器学习方法。OOI等[8]利用顺序特征选择方法进行特征选择,采用了多种机器学习方法预测湖泊水样BOD5值,最终选择预测结果稳定的多层感知器用于湖泊水质预警。以上软测量方法打破了实验操作误差的壁垒,突破了检测设备性能的局限。但是基础的模型预测效果各有差异,因此部分研究人员把方向聚焦在模型的参数优化上,仿生算法可有效解决参数组合优化问题,常见的仿生算法有遗传算法(Genetic Algorithm,GA)、粒子群算法(Particle Swarm Optimization,PSO)、蚁群算法(Ant Colony Algorithm,ACA)等。遗传算法借鉴了达尔文的进化论和孟德尔的遗传学说,在预先设置的参数区间内随机选取数据以形成初始种群,计算种群的适应度并对未达到理想适应度的种群数据进行选择、交叉、变异的操作[9],最终获得满足优化目标下适应度最高的参数组合。YAO等[10]利用反向传播(Back Propagation,BP)神经网络模型预测厌氧膜生物反应器的膜过滤性能,引入GA对仿真过程进行优化,克服BP局部极小化问题,使得预测相对误差进一步降低。乔俊飞等[11]采用基于PSO对神经网络输出权重进行调整训练,加强了对污水关键水质参数BOD5预测的有效性,能够有效实现污水处理闭环控制。
因此,本研究立足于利用机器学习模型进行BOD5指标的快速预测,选取支持向量机回归(Support Vector Regression,SVR)和XGBoost两种机器学习进行比对分析,并且引入GA进一步提升预测准确性,力求寻找一个快速并且准确的预测模型。
1 软测量模型构建
1.1 数据集
本研究所用数据来源为山东青岛某污水处理厂2021年1月1日至2021年12月31日的运行参数监测报表,数据以天为单位,包括5个水质指标(进水流量、COD、SS、pH和氨氮)的365条记录。通过使用污水处理厂实时自动检测的5个水质数据组成五维输入数据作为模型的输入变量。
1.2 数据预处理
对存在数据不完整的天数进行整条数据删除,排除原始数据中包含的波动较大的干扰数据和不完整数据,并对数据进行无量纲化和数据降维。
1) 剔除异常值。利用3σ准则(拉依达准则),以3倍测量列的标准偏差为极限取舍标准[12],假设数据只含有随机误差,计算数据的均值μ与标准差σ,筛选出于(μ-3σ,μ+3σ)范围外的误差数据,以排除污水处理厂在受气候、人口、经济等因素影响下出现的进水波动情况。
2) 数据无量纲化。按照式(1)进行数据归一化处理,可令数据服从正态分布并且收敛至[0,1]。由于不同辅助变量的数据大小、分布和单位各有差异,而该步骤可以削弱这类数据产生的影响,加快模型求解速度。
(1)
式中:xscale为辅助变量样本值进行无量纲化后所得数值;x为辅助变量样本值;xmax为辅助变量中的最大值;xmin为辅助变量中的最小值。
3) PCA数据降维。通过主成分分析(Principal Components Analysis,PCA),利用矩阵分解等一系列数学操作在数据总信息量不损失太多的条件下,将原始特征数据压缩到少数特征上,从而得出方便计算的新特征向量。丢弃信息量很少的特征向量噪音来达到减轻模型冗余计算的目的。
数据经过预处理之后,原有数据集的11条数据被剔除,构成新数据集。训练集与测试集由新数据集按9∶1的比例随机划分而成。
1.3 模型选择及参数优化
1) 支持向量机。支持向量机(Support Vector Machine,SVM)是一类基于统计学习理论的机器学习算法,既可以用于分类预测也可以用于回归预测。支持向量机回归(Support Vector Regression,SVR)是用于回归预测的一个强学习器,其原理是通过核函数φ(x)将原始数据映射至特征空间,寻求一个令原始数据在同一容许误差下距离最近的超平面,该超平面特征向量wT与输出向量f(x)满足回归方程f(x)=wTφ(x)+b,其中b为截距向量。本文使用的核函数类型为高斯径向基函数“rbf”,表达式为
φ(y,xi)=e-γ‖y-xi‖
(2)
式中:xi为原始数据向量;y为xi映射至特征空间的向量;γ为核函数次数。
假设容许误差为ε,则超平面存在于|f(x)-wTφ(x)-b|≤ε所形成的容错空间内。容错空间大,对数据拟合的包容性大;容错空间小,存在数据无法拟合的情况。为了权衡容错空间的大小,引入惩罚因子C,进一步保证所选取超平面的合理性。
2) 极限梯度提升算法。XGBoost是由CHEN[13]于2016年所设计的一种集成学习模型。其核心思想是梯度提升算法,构建多个弱评估器并汇总建模结果,组合弱评估器,不断迭代预测结果直到损失函数最小,从而构成一个强评估器。相比普通梯度提升算法,XGBoost运算更加快速,近年来被普遍认为是在分类与回归上都具有超高性能的先进评估器。其中,弱评估器数量N和提升树最大深度D决定评估器的个数与深度;学习率η决定迭代过程中误差减小的方向步长;正则项参数α与λ互相影响,共同调整弱评估器的权重以防止最终的模型过拟合或欠拟合。
3) 参数优化。为了使模型获得更好的预测效果,本文利用如下2种方法寻找SVR模型和XGBoost模型最优参数组合,其中两类模型的参数类型、性质和取值范围见表1。

表1 各模型的参数类型、性质和取值范围
方法1:利用网格搜索法对单一参数在设置的参数取值范围内进行穷举,首先使用较广的搜索范围和较大的步长,观察全局最优参数可能存在的位置;然后逐渐缩小搜索范围和步长,获得循环遍历后表现最优的参数作为最终的结果。
方法2:利用GA在全局范围进行搜索,对需优化的参数进行编码,令编码在一定的概率下进行交叉和突变的遗传操作,计算每组编码的适应度,最终在参数取值范围内求得适应度最高的参数取值。
1.4 模型搭建平台与模型评价指标
本文采用python语言在Pycharm平台进行编译,利用David Cournapeau于2007年针对机器学习应用而开发的Scikit-learn项目库所提供的API接口对模型进行开发[14]。
如式(3)、式(4)所示,采用均方误差EMS和均根方误差ERMS函数来检测模型的预测值和实测值之间的偏差。如式(5)所示,采用决定系数(R2)评价回归模型的拟合度,观察模型拟合效果,确定是否适用于模型预测。
(3)
(4)
(5)
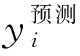
2 结果与讨论
2.1 支持向量机回归模型的参数优化
采用穷举方式进行网格搜索,依次对SVR模型中的惩罚因子C、核函数参数γ和容错度ε进行训练,采用交叉验证方法对结果进行评价,从而得到最优的参数,继而可据此利用R2,EMS和ERMS进行模型评估。
对于惩罚因子C,取值越大模型越易过拟合,因此令C取值范围为[0.5,19.5],假设步长为1,则C值有19种取值方式,作K折交叉验证下拟合度(R2)随C的变化趋势曲线,其中取K=5。由图1(a)可以看出,C最佳取值为6.5,模型得最大R2为0.78。同理,核函数参数γ和容错度ε取值范围分别为[0,1]和[0,0.24],对应步长为0.1和0.02。将γ与ε对R2的影响进行可视化分析,如图1(b)(c)所示,经比较后选择最高R2对应的参数,分别是γ=0.7,ε=0.02。
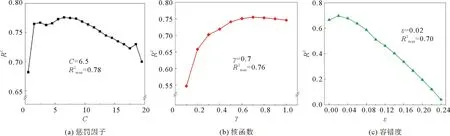
图1 SVR模型下R2随不同参数取值的变化趋势
因为模型参数较多且参数之间互相影响,若参数选择不当,会影响模型的精度与复杂程度,模型太简单或太复杂都会导致预测结果欠拟合或过拟合,故使用GA对SVR模型进行参数优化。其中,种群个数设为10,最大进化迭代次数设为300,交叉率为0.9,突变率为0.5。C,γ和ε的取值范围与网格搜索法一致。最终得到最优参数C=4.48,γ=0.05,ε=0.12。
2.2 极限梯度提升模型的参数优化
采用网格搜索法依次对XGBoost模型中的弱评估器数量N、提升树最大深度D、学习率η、正则项参数α、正则项参数λ5项参数进行最优选择,采取与SVR模型相同的方式进行模型训练与评估。D和λ作单独参数调整时,模型波动并不明显,因此D和λ取默认值,即D=6,λ=1。
设置参数N,η和α的取值范围分别为[10,60],[0.02,0.2]和[0,5],步长分别为4,0.01和0.5。由图2可以看出,随着N值的增加,R2先逐渐增加后趋于平缓,当N取34时,R2取得最大值0.76。同理最大R2下η值取值为0.12。λ与前两者趋势相反,R2随λ值的增加显著降低,因此最优参数α=0。
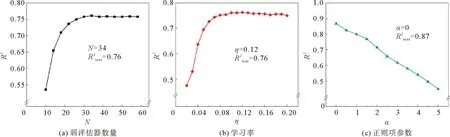
图2 XGBoost模型下R2随不同参数取值的变化趋势
研究GA对XGBoost模型参数的影响时,设置最大进化迭代次数、突变率分别为100和0.1,种群个数与交叉率同GA-SVR模型。各个参数的取值范围与网格搜索法一致,最终得到最优参数N=270,η=0.025,D=8,α=1.39,λ=1.98。
2.3 模型评估
表2为使用网格搜索法-SVR、GA-SVR、网格搜索法-XGBoost和GA-XGBoost 4种模型运行结果评估。可以看出,GA进行参数优化模型的预测效果优于网格搜索法参数调优,且GA-SVR的模型的预测效果更优于GA-XGBoost,R2可达0.918。令预测值与实测值之差的绝对值为模型的绝对误差,经计算,GA-SVR模型的最小绝对误差为0.06 mg/L,最大绝对误差为25.36 mg/L。

表2 模型运行结果
相对于SVR模型,XGBoost模型利用GA提升模型预测准确度效果更加显著。与网格搜索法-SVR模型相比,使用GA-SVR模型预测BOD5,预测值的拟合度由0.898提高至0.918,ERMS由13.93降低至12.44;与网格搜索法-XGBoost模型相比,使用GA-XGBoost模型预测BOD5,预测值R2由0.757提高至0.891,ERMS由21.48降低至14.32。比较不同类型模型之间的区别,可以发现从模型角度分析,SVR类模型的EMS与ERMS均小于XGBoost类模型,且预测精度更高。但从优化角度分析,经遗传算法优化后,SVR类模型的EMS与ERMS分别降低了20.28%,10.70%;XGBoost类模型的EMS与ERMS分别降低了55.54%,33.33%,可见XGBoost类模型受遗传算法影响优化效果更加显著。
使用以上4种模型对污水处理厂进水水质参数BOD5进行软测量预测,在测试集中选取任意20组运行结果通过作图进行对比,由图3、图4可以看出经过GA优化的模型更加逼近BOD5实测值。

根据以上实验结果分析可知,经过GA优化过的模型在BOD5数值的预测精度优于网格搜索法模型,其中R2(GA-SVR)>R2(网格搜索法-SVR);R2(GA-XGBoost)>R2(网格搜索法-XGBoost),JIANG等[15]研究也证明了GA更有利于SVR模型获得最优参数从而提高预测性能。结果表明,GA-SVR模型的预测效果优于GA-XGBoost模型,因此,GA-SVR模型具有较好的模型预测性能和泛化性能,可以满足污水处理厂进水BOD5实时监测的需求。从模型优化效果角度分析,XGBoost模型比SVR模型受GA参数优化影响更大。这可能是因为SVR模型的原理相较于XGBoost模型的原理更加简单,能影响模型预测的参数较少,因此通过优化参数来提升SVR模型的回归能力有一定的限度。而XGBoost模型涉及参数较多,模型复杂,参数互相影响互相制约的现象更加显著,GA可以充分考虑参数间的影响,激发XGBoost潜力,优化预测效果。
3 结论
通过比较两类机器学习模型(SVR模型与XGBoost模型)经过GA优化后的预测效果,发现各组模型的R2均得到了提高,同时数据显示ERMS也得到了下降,其中SVR模型与XGBoost模型分别下降10.70%和33.33%。根据实验结果可知,两类模型在预测污水处理厂进水BOD5数值上,可以使用GA从而提升模型精度。其中SVR模型更加精确,有较好的实用性,而XGBoost模型更加敏感,有较广的研究前景。从污水处理厂日常运营来看,GA-SVR对BOD5的精准软测量可为污水处理厂制定处理方案、合理规划能耗提供科学依据。
