一种基于集群负载均衡的Kubernetes资源调度算法
2023-04-06黄志成
黄志成

关键词: Kubernetes; 资源调度; 负载均衡; 容器技术; 资源监控
当前Kubernetes调度策略是一个比较热门的研究方向,我们的应用向Kubernetes请求资源之后,Kuber?netes会进行容器调度,现有的Kubernetes调度器是根据用户请求的资源去分配节点的,没有考虑到用户可能申请了很多资源但是实际使用资源很少的情况,这时Kubernetes不会去做资源的重新分配,会造成很大的资源浪费[1]。另外调度器在选择节点的时候是根据用户请求的CPU和内存数量去分配节点的,没有考虑节点自身的负载情况,将Pod调度到本身已经高负载的节点上会造成集群中某些节点资源利用率很高,出现性能不稳定的情况[2]。针对Kubernetes默认调度器的不足,对其进行优化是本文的研究方向。
1 相关工作
国内外学者对于资源调度也有非常多的研究,Menouer等人[3]提出了一种新的Kubernetes容器调度策略,简称为KCSS。这个策略考虑了六个关键因素,分别是每个节点CPU利用率、每个节点的内存利用率、每个节点的磁盘利用率、每个节点的功耗、每个节点中运行的容器数以及用户传输镜像到容器的时间。然后通过TOPSIS 算法选择排名最高的节点来运行Pod。Mao等人[4]提出了一种推测性容器调度器,通过将速度缓慢节点上的资源迁移到其它节点上来提升系统性能,主要包含以下三个步骤,确定速度缓慢的节点、选择合适的新节点、迁移重新平衡节点。浙江大学的杨鹏飞[5]基于ARIMA和神经网络两种模型组合的方案,提出一种资源动态调度算法,每一轮调度都由一个动态资源管理器去计算所有的节点实例,然后根据用户的资源请求数量去分配一个节点。该方法没有考虑集群节点本身的负载情况,每一轮调度都要遍历所有节点去计算资源情况,时间复杂度过大。华南理工大学的魏饴[6]提出一种基于节点CPU和磁盘I/O 均衡的动态调度算法,该方法通过监控节点的CPU和磁盘IO使用情况为节点进行打分,能够解决默认调度器只考虑用户请求的CPU和资源情况。但是该方法没有考虑内存影响的因素,并且使用Sched?uler Extender实现的调度方法会有性能问题。电子科技大学的唐瑞[7]提出了一种基于Pod优先级的抢占策略,在集群资源不足的情况下,选择将一部分低优先级的Pod资源回收。但是该特性在v1.14版本的Ku?bernetes中就已经支持了。
2 基于集群负载均衡的Kubernetes资源调度算法
2.1 资源监控设计
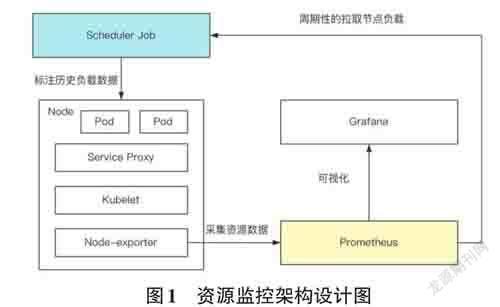
为了改进Kubernetes的默认资源调度算法,本文需要额外采集CPU、内存和磁盘的历史负载情况,用于调度策略的优化,本文采用Node-exporter + Pro?metheus + Grafana的技术对指标进行采集、存储与展示。如图1 所示,主要实现两个组件,分别是Pro?metheus 和Scheduler Job。在Prometheus 中实现一个自定义指标采集策略,对历史负载情况进行采集和存储。具体实现方式为在配置规则文件中编写采集指标的PromQL语句,然后通过Node-exporter 定期采集期望获得的数据并进行存储。在Scheduler Job中周期性地拉取各个节点的负载数据,计算其历史负载情况,并以注解的方式标注在节点上。在后续的资源调度算法需要获取节点自定义负载数据时,调度器无需请求Metrics Server API,只需要直接查询节点上的注解信息,就能获取到节点最近的负载情况,这样可以减少HTTP请求所花费的时间,极大提高调度器的调度性能。
2.2 资源模型
本文提出一种基于集群节点负载均衡的调度方法,通过监控节点近期CPU、内存、磁盘的情况,周期性的将这些指标以注解的方式标注在节点中,在调度器的预选和优选阶段根据监控到的指标数据对节点进行过滤和打分。本方法主要关注以下指标:1) CPU最近5分钟的平均利用率。2) CPU最近1小时的最大利用率。3) 内存最近5分钟的平均利用率。4) 内存最近1小时的最大利用率。5) 磁盘最近5分钟的平均利用率。6) 磁盘最近1小時的最大利用率。
2.3 调度算法
本文通过Scheduler Framework 实现一个自定义的调度器,在Filter 和Score 这两个扩展点进行扩展实现,同时保持其余扩展点的Kubernetes 默认策略不变。
在调度的Filter 阶段,从候选节点的注解中读取历史负载数据,并根据这些数据对负载较高的节点进行过滤。如图2所示,步骤如下:
1) 判断需要调度的Pod类型,如果是Daemonset类型,说明所有的节点都需要运行这个Pod,不过滤该节点,直接结束流程。如果不是Daemonset类型,将继续进行第2步。
2) 遍历该节点上的所有注解。每一个注解都代表一项自定义指标数据。
3) 对于每个注解,将其与配置文件中初始定义的阈值进行比较。只要有一项指标的实际利用率超过其对应的阈值,那么这个节点将被过滤,代表该Pod无法调度到该节点上,结束流程。如果所有指标的实际利用率都小于或等于设定的阈值,那么这个节点在预选阶段筛选通过,不过滤该节点,结束流程。
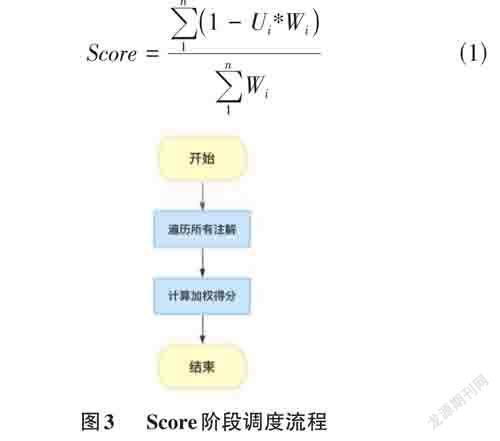
在调度的Score阶段,基于节点注解上的指标数据进行打分,最终得分是这些指标值的加权和。如图3所示,步骤如下:
1) 遍历节点上的注解,得到历史负载指标数据。
2) 计算节点的加权得分。假设节点中的资源负载指标集合为Usage = {U1,U2,U3, ... ,Un },资源负载指标对应的权重集合为Weight = {W1,W2,W3, ... ,Wn }。根据式(1)计算节点的分数。
3) 每一个节点计算完成之后,最终得分返回给调度器,由调度器挑选得分最高的节点部署Pod。
3 实验分析
3.1 实验设计
本实验在4台安装了Centos7.9的虚拟机上部署Kubernetes集群,其中Master节点1台,Node节点3台,其中Master节点和两个Node节点CPU为2核,内存为2G,另一个Node节点CPU为4核,内存为4G,安装的Kubernetes版本号为v1.23.10。
本次实验分为两组,分别为实验组与对照组,实验组使用本文实现的调度器,对照组使用Kubernetes默认的调度器,各种指标的采集频率、阈值与权重如表1所示。
整体实验分为以下几个步骤:
1) 先使用Kubernetes默认调度器,使用kubectl客户端向Master节点的API Server发起创建Pod的命令,每次创建10个Pod,每隔6小时创建一次,一共创建50个Pod。
2) 记录各节点资源使用情况,在初始时记录一次,然后在每次创建完Pod后30分钟记录一次,频率也为6小时一次。
3) 所有Pod创建完成之后,计算集群的负载均衡度stdScore,计算公式如式(2) ~式(4),Scorei 代表第i个节点的得分,Ucpu 代表当前节点的CPU利用率,Umem代表当前节点的内存利用率,Udisk 代表当前节点的磁盘利用率。Wcpu、Wmem、Wdisk 分别为各指标的权重,本实验设置为50、40、10。
3.2 实验结果与分析
整体实验过程中Pod分布情况如表2所示,从测试结果可以看出,在刚开始的时候,两次实验每个节点上分布的Pod数量基本一致,由于刚开始每个节点的负载都较小,调度器会平均分配Pod对象。在实验中后期,实验组会倾向于把Pod分配给node3节点,因为此节点的CPU和内存更大,这样可以尽可能的保证集群之间的负载均衡。相比之下,默认的调度算法只考虑了节点当前的CPU和内存的利用率情况,没有考虑历史的负载情况以及磁盘利用率情况。
各个阶段Pod部署完成之后集群的负载均衡度如图4所示,可以看出实验组的负载均衡度要低于对照组的负载均衡度,因此使用本文所提出的资源调度方法后,Kubernetes集群整体的负载情况要优于使用默认的调度方法。
4 结束语
本文设计了一种资源监控的架构,该架构借助开源框架Prometheus将集群中节点的负载情况记录下来。并提出了一种基于集群负载均衡的资源调度方法,该方法考虑节点自身的负载情况,并使用最新的Scheduler Framework技术实现了该方法,从而实现集群之间的负载均衡。最后搭建实验环境,设计实验步骤并进行实验,对本文提出的资源调度方法与Kuber?netes默认资源调度进行了对比和分析,通过分析可以得出本文所提出的基于集群负载均衡的资源调度方法相比默认调度方法更有优势。但是本文的资源调度算法只考虑了CPU、内存、磁盘的利用率情况,后续还可以考虑网络I/O、磁盘I/O的影响。另外由于成本问题,本文的测试集群只有四台主机,测试用例也比较有限,在条件允许的情况下,后期可将资源调度算法在大规模集群上进行测试。