基于深度强化学习的多无人机协同防撞策略研究
2023-04-03李诗琪费思邈齐奂超胡正宇
霍 琳,李诗琪,费思邈,齐奂超,胡正宇
(1.沈阳航空航天大学, 沈阳 110135; 2.沈阳飞机设计研究所, 沈阳 110035)
1 引言
随着人工智能技术的发展,无人机的应用越来越广泛。在军事领域,无人化作战是未来战争的发展趋势。在民用领域,无人机已经被广泛应用于快递物流、农林植保、航拍作业等多种领域。随着应用场景的复杂化和多样化,无人机的防撞能力逐渐成为人们研究的重点。
由于动力和载荷的限制,单个无人机完成任务的能力十分有限,因此,常常需要多个无人机协同完成任务。不同于单个无人机防撞,在研究多个无人机协同防撞时,不仅要考虑每个无人机和环境中的障碍物的防撞问题,还要考虑执行任务的无人机之间的防撞问题。
纵观国内外的研究工作,无人机防撞策略的研究大致可以分为基于纯数学优化[1-3]、基于启发式算法[4-6]、基于人工势场[7-9]、基于几何制导[10-12]和基于机器学习[13-15]五类。应用前四类研究方法处理多无人机协同防撞问题时往往需要大量计算或是复杂的建模过程,很难满足多无人机自主实时防撞需求。基于机器学习的研究方法通过与环境交互学习到防撞策略,具有很好的实时性。主要可以分为基于深度学习、基于强化学习和基于深度强化学习3种。基于深度学习的研究方法就是应用专家飞行员的飞行经验数据等训练神经网络,使无人机能够正确选择飞行策略,从而实现防撞。这种方法可以处理复杂的连续空间上的问题,但十分依赖经验数据,当遇到没有学习过的场景时,无人机很可能因不知如何选择飞行策略而发生碰撞事故。基于强化学习的方法不依赖于经验数据,通过与环境交互获得反馈来学习防撞策略。但只使用强化学习通常难以处理复杂的连续空间的问题。因此,人们通常将深度学习与强化学习结合起来,应用强化学习代替经验数据来训练神经网络,这就是基于深度强化学习的研究方法。这种方法可以处理连续空间上的问题同时又不依赖于经验数据,因此被越来越多的应用于无人机防撞策略的研究中[16-18]。
在应用深度强化学习研究多无人机协同防撞问题时,通常将所有执行任务的无人机看作一个多智能体系统,然后采用多智能体强化学习方法来训练深度神经网络。
多智能体强化学习主要有集中式强化学习、集中式训练分布式执行、独立强化学习3种框架。
集中式强化学习就是将整个多智能体系统看作一个学习单元,认为智能体只能被动执行中央指令没有独立决策能力。这种方法在协同执行任务的无人机数量较多时,动作空间维度会很大甚至可能出现维度爆炸问题。集中式训练分布式执行是在训练时把多智能体系统看作一个整体,在执行任务时将每个智能体看成一个能够独立决策的个体。根据其集中式训练的方法的不同,大致可以分为两类:第一类[19-20]是直接对策略网络进行统一学习训练,这一类算法在集中式训练过程中使用统一的critic网络,同样,这种方法在协同执行任务的无人机数量较多时,也可能出现维度爆炸的情况。第二类[21-22]是应用值函数分解进行统一训练,假设每个智能体都是无私的,以集体利益为最先,将总体动作价值函数分解成多个子函数,统一进行训练。这种训练方法十分依赖值函数的正确分解,如何将值函数分解给每个智能体是很复杂的问题,在拆分的过程中往往还会引入很强的分解假设。独立强化学习,就是将单智能体强化学习方法直接应用于多智能体系统中。每个智能体都是独立的学习主体,它们分别学习对环境的响应策略和相互之间的协作策略,并根据自身所感知的环境状态选择一个获得回报最大的动作。这种方法不关心其他无人机的利益,能有效避免维度爆炸的问题。
本文基于独立强化学习框架,提出了一种多无人机协同防撞策略。首先,在设定的无人机协同任务背景下建立了无人机的碰撞模型、运动学模型并设定了完成任务需要满足的约束条件。然后提出了一种基于独立近端策略优化算法改进的多无人机智能体协同防撞决策方法。最后,通过仿真实验验证了该方法的有效性。
2 无人机协同防撞过程任务设定及建模
2.1 任务背景设定
本文中主要研究多无人机协同防撞过程存在的两类碰撞问题:一是与环境中的静态障碍物相撞,二是与其他无人机相撞。设定多无人机协同执行任务的背景是多架无人机在同一水平高度限定空域内协同飞向目标区域,限定空域内存在未知位置的静态障碍物。
为简化问题难度,在研究过程中,假设所有无人机的信息感知系统精确可靠且无延时,能够实时为每个无人机提供探测范围内的所有目标的信息。
2.2 无人机模型建立
在实际应用中无人机有很多不同种类的机型,本文中旨在研究一个通用的多无人机智能体协同防撞策略,因此假设所有无人机的碰撞模型都是以无人机质心为球心,以50 m为半径的球形包络,具体模型如图1所示。

图1 无人机碰撞模型
设定限定空域为水平正方形区域,以限定空域西南角为坐标原点,正东方向为x轴正方向,正北方向为y轴正方向对无人机进行运动学建模。得到无人机二维运动学简化模型如下:
(1)

(2)


图2 无人机运动模型示意图
2.3 任务约束
综合任务设定和无人机碰撞模型,在无人机执行任务过程中需满足以下约束:
1) 在完成任务过程中每架无人机与静态障碍物及限定空域边界的距离不能小于50 m。
2) 在完成任务过程中每架无人机与其他无人机距离不能小于100 m。
3) 无人机只能探测到与其距离小于等于其探测距离的障碍物和其他无人机。
3 独立近端策略优化算法的应用与改进
3.1 近端策略优化算法
近端策略优化算法[23](proximal policy optimization algorithms,PPO算法)是由John Schulman对信赖域策略优化算法[24](trust region policy optimization,TRPO算法)进行改进而得出的策略梯度方法(policy gradient methods)。
TRPO算法为了解决传统策略梯度方法更新步长不好确定的问题,给目标函数加上了约束,使得目标函数在策略更新幅度的约束下最大化,避免策略更新过快而错过最优策略。在实际操作过程中,TRPO算法虽然效果很好,但往往实现复杂。John Schulman去掉其目标函数的约束,转而施加一个自适应惩罚因子(Adaptive KL Penalty)β,得到了PPO算法。这种方法几乎保留了TRPO算法的所有好处,并且更容易实现:
其目标函数如下:
L(θ,φ)=

(3)

γT-t+1rT-1+γT-tVφ(sT)
(4)

(5)
Ifd>dtarg×1.5,β←β×2
(6)
3.2 独立近端策略优化算法
独立近端策略优化算法就是将单智能体近端策略优化算法直接应用于多智能体系统中。每个无人机智能体不考虑其他智能体的利益,独立的使用近端策略优化算法优化自身的策略。
在本文中设定的任务中,每个无人机都要在不相撞的条件下飞向目标区域。如果他们都以自私的方式优化自身飞行策略保障不与其他无人机和环境中的障碍物相撞并飞向目标区域,那么就会体现出整体的相互之间防撞、集体的避障以及完成任务的行为。因此,本文采用独立近端策略优化算法进行策略训练。并应用深度神经网络拟合独立近端策略优化算法中的策略函数和价值函数。
3.3 基于独立近端策略优化算法的策略构建
根据任务背景设定,所有无人机智能体的任务目标都是在不发生碰撞的情况下到达目标区域且所有无人机结构相同,因此,所有无人机智能体采用同一种策略(相同结构的策略网络和价值网络),但每个无人机智能体的输入及输出不同。策略的输入是每个无人机所观测到的不同信息,输出是每个无人机x方向速度矢量和y方向速度矢量。在决策时,所有无人机智能体同步独立选择动作。
3.4 问题分析及观测空间改进设计
虽然使用独立近端策略优化算法进行策略训练可以解决策略更新步长不好确定和维度爆炸等问题,但当协同执行任务的无人机较多时,如果观测探测范围内所有目标(其他无人机和障碍物)信息,神经网络的输入将会很大,此时训练神经网络十分困难。因此,本文对无人机观测空间进行处理,设计无人机只观察探测范围内部分最近目标并按照距无人机智能体自身距离由近及远的顺序将这些目标的信息输入神经网络。观测空间具体设计流程如图3所示。

图3 观测空间设计流程框图
此外,如果静态障碍物位置固定,无人机很容易对一种场景过拟合,即学不会防撞策略而是只针对某一场景选择特定路径。因此,设定在每回合训练开始前,静态障碍物的位置是随机产生的。
3.5 算法流程
根据以上设定,算法具体训练流程如下:
步骤1定义无人机智能体策略网络π(a|s),价值网络V(s),初始化经验池。
步骤2初始化仿真环境,随机产生n个位置不同的障碍物。
步骤3根据当前环境状态s以及前文观测空间设计流程确定不同无人机智能体观测空间信息。将计算后的信息输入每个无人机智能体策略网络和价值网络,策略网络输出当前动作概率分布,价值网络输出当前状态得分。

步骤5重复步骤3、步骤4直到仿真回合结束。
步骤6重复步骤2、步骤4直到达到最小样本数。
步骤7从经验池中采样小批量数据多次更新策略网络π(a|s),价值网络V(s),更新完成后清空经验池,用更新后的策略代替采样策略。
步骤8重复步骤2—步骤7直到累积奖赏值收敛或达到规定次数。
4 仿真实验
4.1 仿真实验任务设定
为了验证本文中设计方法的有效性,以25架同构无人机在100×100 km的正方形限定空域内完成协同飞向目标区域并停下的任务为例进行仿真实验。具体任务想定如下:
25架同构无人机在限定空域内由西向东协同飞行,每个无人机自主选择飞行策略,不规定无人机智能体特定的飞行方向。无人机探测距离为5 km,当无人机探测到障碍物时,需进行规避,规避后继续向目标区域飞行。此外,在飞行过程中,所有无人机需要全程自主防止机间碰撞并且不能离开限定空域。设定任务完成的条件为超过80%的无人机智能体到达目标区域并安全停下。
本文中采用每个无人机智能体为一个独立决策个体的无中心式协同决策控制模式,即每架无人机智能体根据自身的探测结果自主决策自身的飞行速度矢量。目标区域以点(80,50)为圆心,辐射周围13.5 km的圆形范围(白色区域)。黄色区域为可能存在障碍物的区域,每一仿真回合内,在黄色区域(东西方向40~65 km,南北方向3~97 km)会随机产生5个不同位置的静态障碍物。想定任务场景如图4所示。

图4 任务设定示意图
4.2 单个无人机智能体马尔可夫决策过程构建
根据任务背景和问题分析,所有无人机智能体需要自我学习出以下策略能力:相互之间的防撞能力;避免与障碍物相撞的能力;飞向目标区域并停下来的能力。
综上,对每个无人机智能体的观测空间、动作空间、状态转移和奖赏函数设计如下:
观测空间:对于每个无人机智能体来说,策略输入是其自身的观测量,均为一个19维的矩阵,主要包括探测范围内5个最近目标按照其与无人机智能体自身的距离由近及远排序后的位置坐标及存活情况(如果范围内目标数量不够,则全部用0补齐)。目标包括无人机和静态障碍物,静态障碍物默认一直存活不存在死亡情况。此外还包括无人机智能体自身的位置坐标,目标区域中心位置坐标。每个无人机智能体的策略模型输入如表1所示。

表1 策略模型输入Table 1 Policy model input
动作空间:本文中研究的是连续动作空间上的动作问题。因此,对于每个无人机智能体来说,策略的输出是其所做的动作,是一个2维矩阵,分别是东西方向的速度和南北方向的速度。
状态转移:由于本文中动作空间为2个方向上的速度,因此状态转移方程可以直接用运动方程表示,构建一个三列的矩阵维护所有无人机智能体的状态,这个矩阵是全局性的,前两列代表每个无人机智能体的实时位置坐标,第三列是无人机智能体存活情况,每一行表示一个无人机智能体。每一个决策周期都维护此矩阵。
奖赏函数:由于所有无人机智能体的任务目标均相同,因此所有无人机具有一样的奖赏函数。具体描述如表2所示。

表2 奖赏描述Table 2 Reward description
4.3 网络结构设计
由于观测空间是19维的固定向量,所以在网络结构设计时,输入层使用全连接层即可。策略网络的隐藏层采用3层128个神经元的全连接层,每一层神经网络都是用ReLU作为激活函数并进行批标准化。价值网络的隐藏层由3层128个神经元的全连接层构成,不设置激活函数也不进行批标准化。策略网络和价值网络共用一个输入层,策略网络输出动作概率分布,价值网络输出价值网络对当前状态的评价值。具体网络结构如图5所示。

图5 网络结构示意图
4.4 策略训练对比及结果分析
训练过程中,操作系统为Windows 10,硬件信息为Intel i7-1065G7,NVDIA GeForce MX230。使用python作为编程语言、tensorflow2.3.0,ray0.8.7作为编程框架。
具体训练曲线如下图,黑色实线是本文中训练方法的训练曲线(只观察探测范围内最近的5个目标),黑色短划线是是其他参数及条件设定都相同,但观察探测范围内全部目标的训练曲线。本文算法训练的防撞策略在第150轮左右就已经能够稳定收敛并完成设定的任务目标,观察观测范围内所有目标的训练方法经过400轮迭代仍未能完成任务目标,训练的平均奖赏曲线如图6所示。
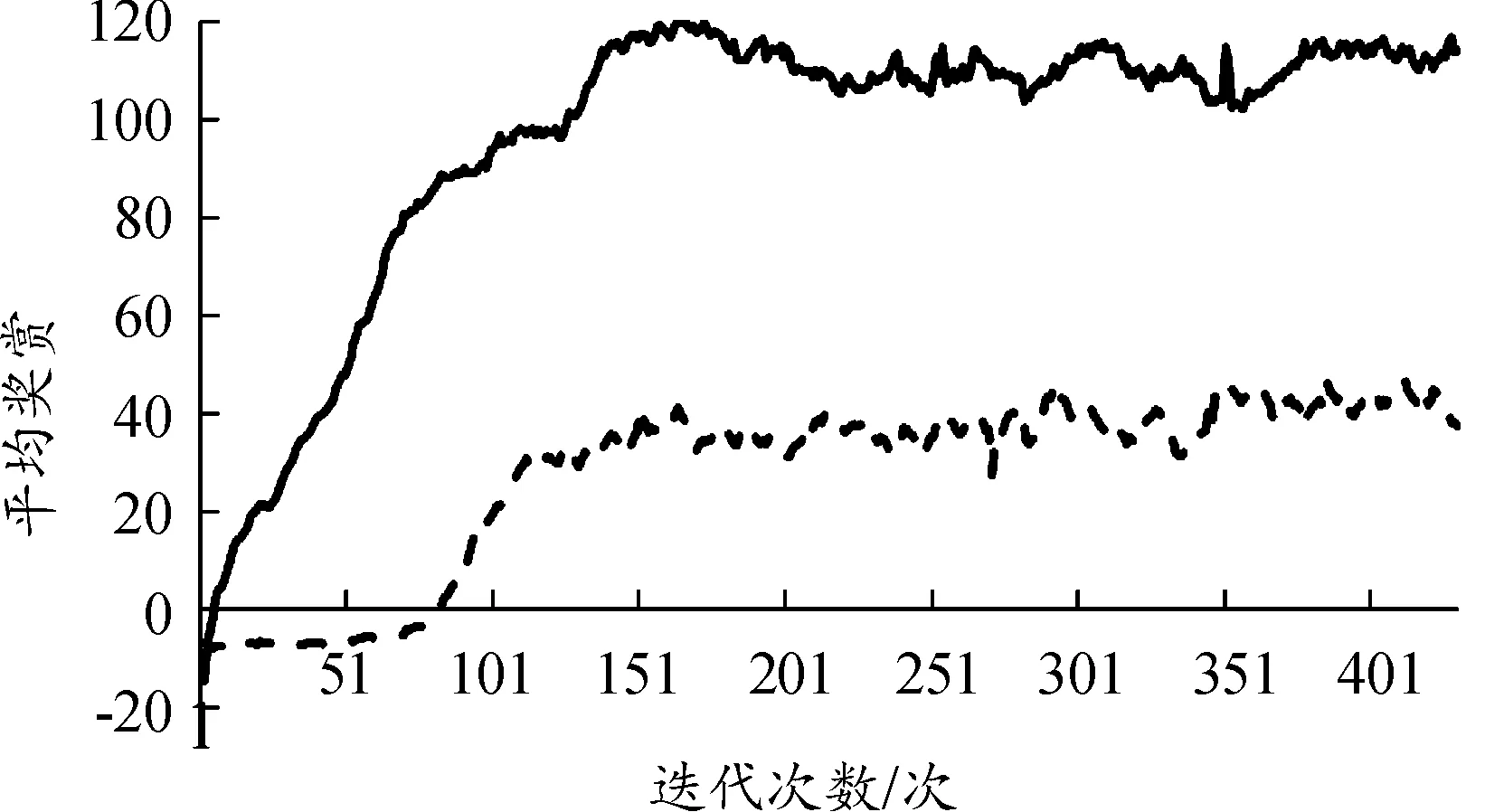
图6 平均奖赏曲线
为了验证算法效果,在关闭探索后,应用训练好的协同防撞策略进行了一千轮仿真实验,结果统计如表3所示。

表3 结果统计Table 3 Result statistics
从表3中可以看出,本文所训练的策略可以实现防撞任务目标。图7是其中一次仿真实验过程中的截图。

图7 仿真过程截图
5 结论
1) 提出一种解决多无人机协同执行任务过程中与静态障碍物和其他无人机相撞问题的方法,为多无人机协同防撞策略的研究提供了新的思路。
2) 基于观测空间设计的深度神经网络决策方法在实现无人机飞行过程中全程防撞的同时也能够保证协同任务的有效完成。
3) 仿真实验表明:所设计的方法仅需150回合左右便可实现设定的任务目标,具有较快的收敛速度和学习效率。
4) 经过验证,所训练的防撞策略在关闭探索后的一千回合仿真实验中,碰撞概率仅为9.5%,具有很好的防撞性能。
为了简化问题,本文假设所有无人机的信息感知系统精确可靠且无延时,未考虑通讯延时等问题;此外,由于条件限制,本文中未进行实物实验。未来将针对这两点问题继续研究。
