基于可变形密集卷积神经网络的布匹瑕疵检测
2023-03-21庄集超郭保苏吴凤和
庄集超,郭保苏,吴凤和
(燕山大学 机械工程学院,河北 秦皇岛 066004)
1 引 言
由于设备故障等影响,常在布匹上造成诸如破洞、油渍等瑕疵[1]。各类瑕疵会严重降低布匹质量,直接影响布匹等级测评[2],因此布匹瑕疵检测是必要的生产环节。但传统纺织制造仍依赖于人工检测,极易造成因视觉疲劳所致的错检、漏检。同时,不同批次的布匹具有不同的复杂纹理和花色,极大提高了瑕疵检测的难度。传统的布匹瑕疵检测方法主要包括5类:基于结构分析方法、基于频谱分析方法、基于模型分析方法、基于统计分析方法和基于学习方法。
(1) 基于结构分析方法的纹理图像是由骨架和纹理基元按照一定放置规则重复出现的组合,并通过阈值来检测缺陷[3,4]。Chen J H等[5]对纹理图像进行阈值分割后,将其映射到称为骨架表示的特殊数据结构中,并通过位置和长度直方图定义了统计测量方法,用以识别和定位纹理图像中的缺陷。
(2) 基于频谱分析方法将图像信号转换为频域信号,以凸显纹理的周期性特征,利用频域特征检测瑕疵点[6]。Tsai D M等[7]通过一维Hough变换检测Fourier域图像中的高能频率分量,并设定区分缺陷和正常模式的控制限值,然而该方法忽略了瑕疵在空间域的信息;Mak K L等[8]利用预训练的Gabor小波网络提取织物的重要纹理特征,利用所提取的纹理特征构造结构元素,用以分离瑕疵点。由于该方法所提出的缺陷检测方案需要多个滤波器,难以平衡组合。
(3) 基于模型分析方法通过判断待检测图像是否符合正常织物纹理模型,利用像素点间的关系,并通过计算局部像素的特征值来检测像素是否存在突变[9]。Zhou J等[10]充分利用织物纹理在水平和垂直投影下的周期性和方向性,并结合一维投影序列进行检测。
(4) 基于统计分析方法主要依据像素在空间分布情况来表达图像的纹理特性[11]。Banumathi P等[12]通过提取基于灰度共生矩阵的统计特征,并采用神经网络作为分类模型,利用所提取的特征作为神经网络的输入,对缺陷进行识别。
对于上述4类方法研究,瑕疵特征的提取与分类是两个分离的过程,检测精度严重依赖于所提取的特征集,且后续难以提高精度,不易进行迁移学习。同时,分类器亦是影响算法精度的重要因素,其参数调整需要通过大量的对比实验确定,难以提高实验的泛化性。
(5)基于学习方法通过在网络训练过程中,利用多次卷积运算融合边缘细节,逐步提取瑕疵特征,并利用SoftMax函数对瑕疵类型进行预测。Li Y等[13]基于Fisher准则的叠层去噪自编码器将织物图像有效地分为有无缺陷类型;针对织物缺陷样本数量分布不均问题,卷积神经网络可结合生成对抗网络以生成缺陷织物图像,扩充样本数量[14];Liu J等[15]提出通过学习现有的织物瑕疵样本,可在不同的应用阶段自动适应不同织物纹理;Jing J等[16]提出了一种基于改进AlexNet的织物瑕疵点分类方法。然而,上述多数研究仅针对几类常见的瑕疵,无法扩展至小目标瑕疵类型。同时,传统卷积方式是单一尺度的窗口检测[17],无法全面提取尺度变化大,面积占比小的瑕疵特征,并随着网络层数增加,网络梯度消失越严重,易致使模型崩溃。
为解决上述问题,本文提出了一种可变形密集卷积神经网络的布匹瑕疵检测方法以实现布匹瑕疵的识别与定位。采用特征重用方式缓解梯度消失和保持特征信息,并利用可变形卷积增强瑕疵特征的提取能力。实验结果表明:所提出的方法相对于其他模型具有更高的检测精度和更强的特征提取能力。
2 特征提取
本文采用了一种多尺度的卷积操作提取布匹的瑕疵特征。
2.1 可变形卷积
可变形卷积通过在常规的卷积网格位置中加入二维偏移量以实现采样网格自由变形,如图1所示。二维偏移量通过在卷积层的特征图中进行训练学习,并利用改变偏移量来控制卷积采样位置。相对于标准卷积,可变形卷积增加了偏移学习的参数和计算,并且可以采用反向传播进行端到端训练。可变形卷积的采样视野得到了极大增加,且其感受野具有不规则的形状,可极大覆盖不同尺度的瑕疵。从图1(a)中可以发现,标准卷积的感受野是固定的区域,与瑕疵的轮廓形状并不匹配,导致无法完全提取瑕疵特征,从而影响模型性能。相反,可变形卷积因其灵活的感受野,所覆盖的区域更大,更匹配瑕疵的形状,进而改善卷积效率,见图1(b)。
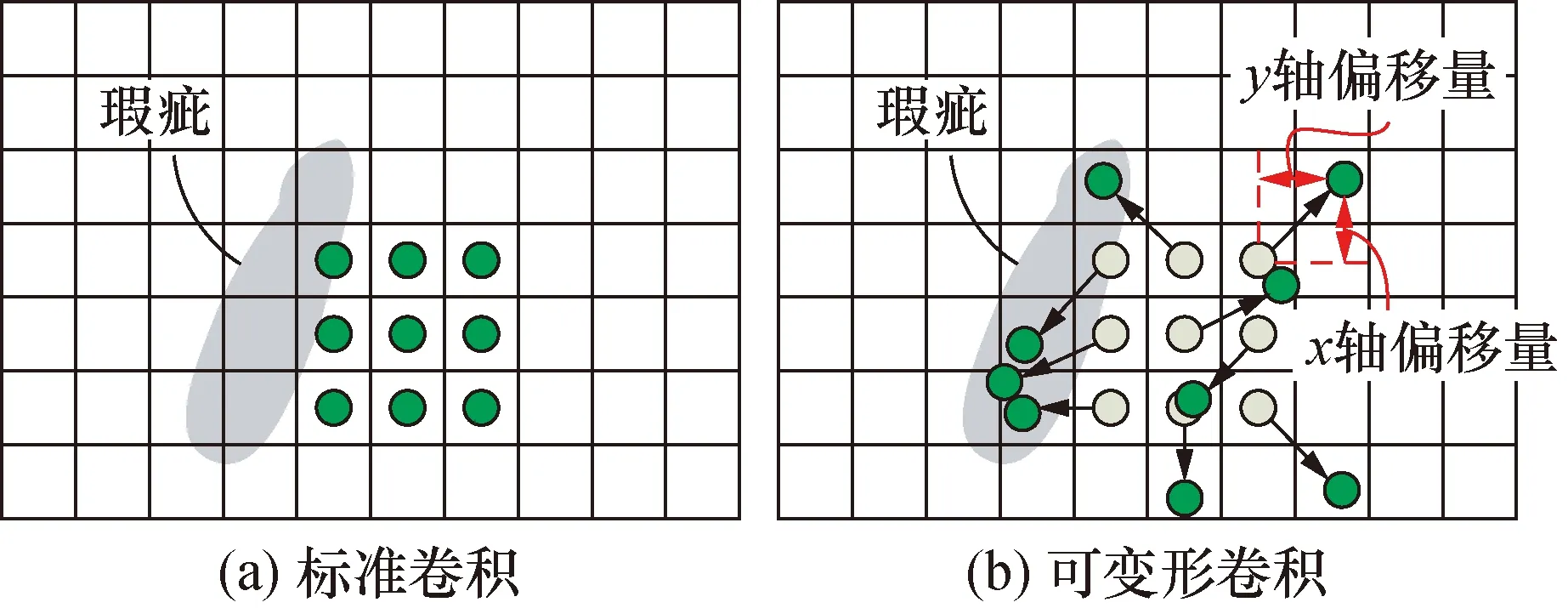
图1 卷积操作Fig.1 Convolution operation
设置一个偏移层,通过偏移层输出通道数,控制学习x和y方向的偏移量,如图2所示。假设3×3卷积网格位置R={(-1,-1),(-1,0),…,(0,1),(1,1)},对于所输出的特征图y上每个位置的数学描述如下:
(1)
式中:Pn表示R中的位置;w表示卷积权重。
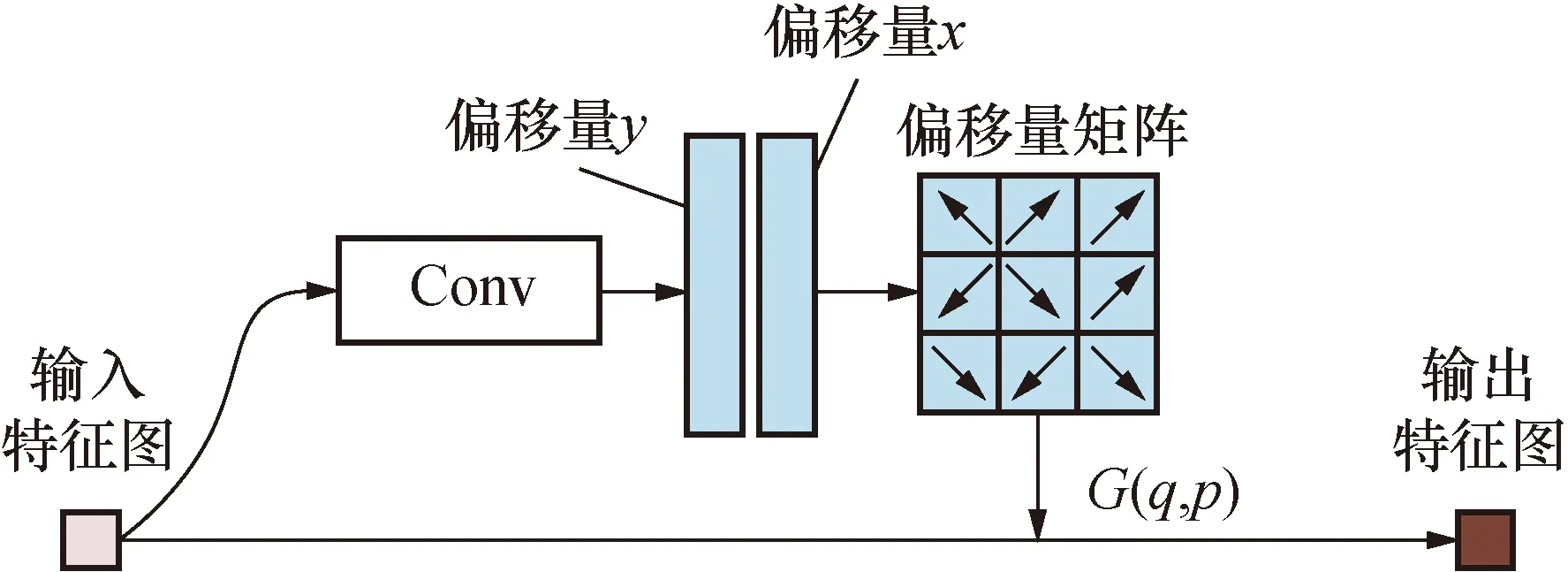
图2 可变形卷积Fig.2 3×3 Deformable convolution
在可变形卷积中,通过在网格位置R增加偏移量{ΔPn|n=1,…,N},N=|R|,其数学描述如下:
(2)
从而实现在不规则网格位置上进行偏移位置为Pn+ΔPn的卷积采样。由于偏移量ΔPn通常为分数,通过双线性插值将式(2)转换为:
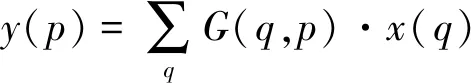
(3)
式中:p为任意位置;q是特征图y中的所有积分空间位置;G(q,p)表示为双线性插值内核。
2.2 密集连接
为了确保网络层之间的最大信息流,并使其保持前馈特性,提出一种特征可重用的特征提取方法。每个层从前面所有层获取额外的输入,并将特征映射传递给后面所有层,从而实现特征的重用。
通过设计多个单元,使特征信息流在单元内任何两层之间均有直接连接,即单元内每层的输入均是前面所有层输出的并集。前面所有层所学习的特征图也会被直接前馈至其后面所有层,并作为其输入,如图3所示。
假设X0为输入,H是批正则化、卷积、ReLU激活函数和可变形卷积的综合层,X1为H0的输出和
H1的输入。每个单元的最终输出如下:
Hl=Hl(Xl-1)=Hl([X0,X1,…,Xl-1])
(4)
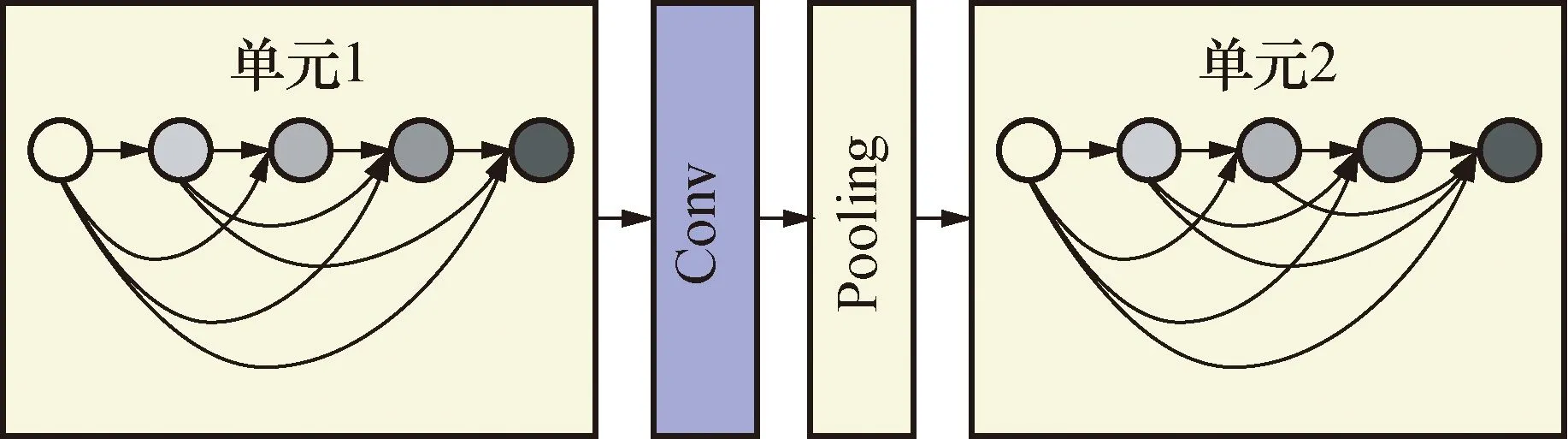
图3 单元连接Fig.3 Unit connection
所提出的模型中设置了4个单元,每两个单元之间采用批正则化、卷积和平均池化进行连接,如图3所示,用以降低特征图维度和提高模型的计算效率。
3 可变形密集卷积神经网络
3.1 网络结构
网络内每个单元的内部连接如图4所示,其中经过试验初步确定,将可变形卷积模块放置在单元内的最后输出,可最大幅度提高模型的性能。所提出的可变形密集卷积神经网络可分为6个步骤,每个步骤能学习到一个特征图,然后在每个特征图上进行边框回归和分类,如图5所示。瑕疵图像经过所提出的模型,利用密集连接的运算方式充分获取上一层与本层产生特征图的并集,其中可变形卷积操作可保证充分辨识不同尺度的瑕疵特征。最后在不同的特征图上获得的候选框。
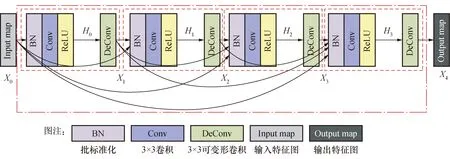
图4 单元结构Fig.4 Unit structure
在可变形密集卷积神经网络中,将单元3和单元4的输出分别作为前2个步骤,并将4个递减卷积层conv5、conv6、conv7、conv8作为其余4个步骤,其结构参数见表1,#号位置为空。将单元3、单元4与额外卷积层conv5、conv6、conv7、conv8的最终输出特征图输入至两层全连接层F1和F2,并在边框回归层FB中构造出6个不同尺度的候选框,最后分别对其进行检测与分类。同时,conv8的输出单独作为类别预测层FC的输入,从而进行瑕疵类别预测。对于多个不同的候选框,采用非极大值抑制方法[18]来剔除掉重叠或不正确的候选框,并生成最终的检测框集合。
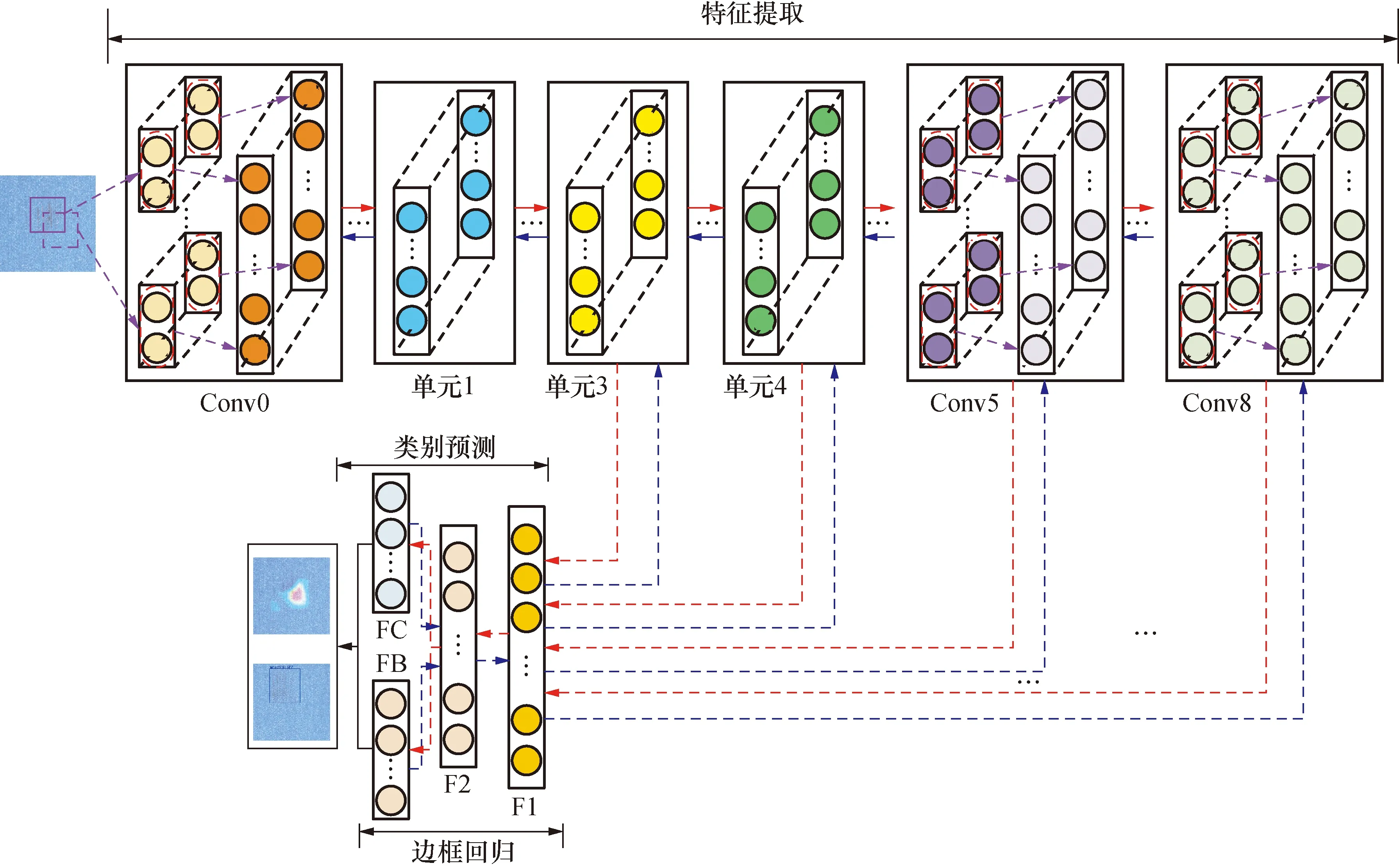
图5 可变形卷密集积神经网络Fig.5 Deformable convolution dense neural network
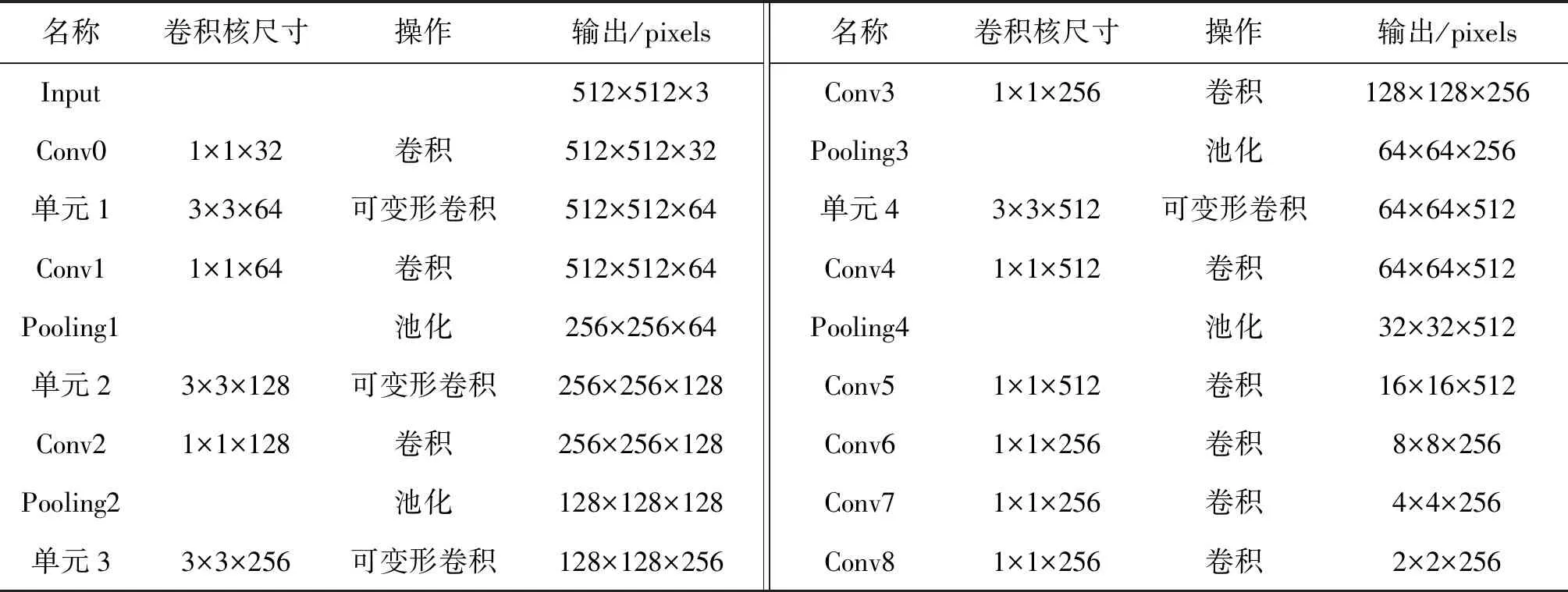
表1 结构参数Tab.1 The structure parameters
3.2 边框回归
模型使用6个不同尺度的特征图在SoftMax分类器进行瑕疵类别预测,并通过在不同大小的特征映射中以不同大小和纵横比的候选框对不同尺度的瑕疵位置进行回归,如图6所示。
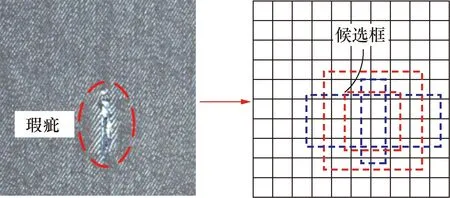
图6 候选框Fig.6 The candidate box
最底层的特征图的尺度smin=0.2,最高层的尺度smax=0.95,其余各层尺度为
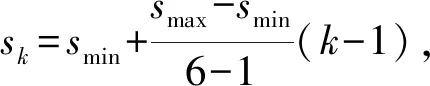
(5)
正方形候选框的最大-最小值尺寸为:
min_size=sk
(6)
(7)
式中:min_size和max_size分别表示正方形候选框最小和最大尺寸。
长方形候选框的尺寸为
(8)
(9)
式中:w表示长方形候选框的宽;h表示长方形候选框的高;α表示比例系数,α∈[1,2,3,1/2,1/3]。
3.3 损失函数
模型中每个输出可被视为将前一层的输出向量xi∈D,D=C×H×W,乘以权重系数wi+1,最后添加偏差值bi+1,其定义如下:
αi+1=f(wi+1xi+bi+1)
(10)
式中:wi+1∈K×D表示具有K个特征的权重矩阵;bi+1∈K表示偏差。
整流线性单元激活的数学描述如下:
f(x)=max(0,x)
(11)
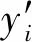
(12)
(13)
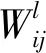
卷积神经网络的权重是采用损失的反向传播算法[19]进行更新,所提出模型的损失包括目标类别和相应位置回归的损失,其数学描述如下:
(14)
式中:N表示匹配到目标的候选框数量;Lconf表示目标类别损失;Lloc表示位置回归损失;αt表示比例系数,用以调整两个损失之间的比例,默认为1。
目标类别损失采用Focal Loss[20]数学描述:
(15)
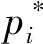
位置回归损失采用SmoothL1Loss,其数学描述为
(16)
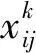
SmoothL1Loss的数学表达如下:
(17)
4 实验与分析
4.1 评价标准
在实验验证中,选用平均检测精度(mean average precision,MAP)和交并比(intersection over union,IOU)评价指标[21]。
(1) MAP主要用于评价算法在多目标检测的性能。其数学描述如下:
(18)
(19)
(20)
(21)
式中:AP表示单类目标检测精度;TP表示正确识别目标数目;FP表示非目标识别的数目;FN表示未识别目标的数目。
(2) IOU主要用于度量两个检测框的叠加程度,其数学描述如下:
(22)
式中:Bp表示预测的边框;Bg表示目标的实际边框。
4.2 数据预处理
在原始图像的基础上,对数据进行适当的改变,以增加数据样本的数量。随机选取图像进行随机旋转和图像擦除。图像尺寸越大,其纹理和上下文信息越多,模型越容易能捕获特征。但当图像过大时,模型的分类性能反而会变差,甚至出现过拟合现象。由于原始布匹图像的实际尺寸为2 446×1 000 pixels,为了在后续模型训练过程中,保证模型训练的速度,同时保留缺陷信息,需要对图像进行分割处理。本文采用滑动分割方法进行布匹图像分割处理。
具体操作如下:
以512×512 pixels的滑动窗口,在原始图像中沿行和列进行移动,每次移动的步长为256 pixels,如图7所示;每次移动2 446×1 000 pixels的布匹图像中提取的512×512 pixels的图像块,进而从一个原始布匹图像数据中可提取出24张子图像。对10类布匹瑕疵进行检测,瑕疵类型包括毛粒、断经、轧痕、污渍、结头、百脚、跳花、浆斑、破洞和云织。
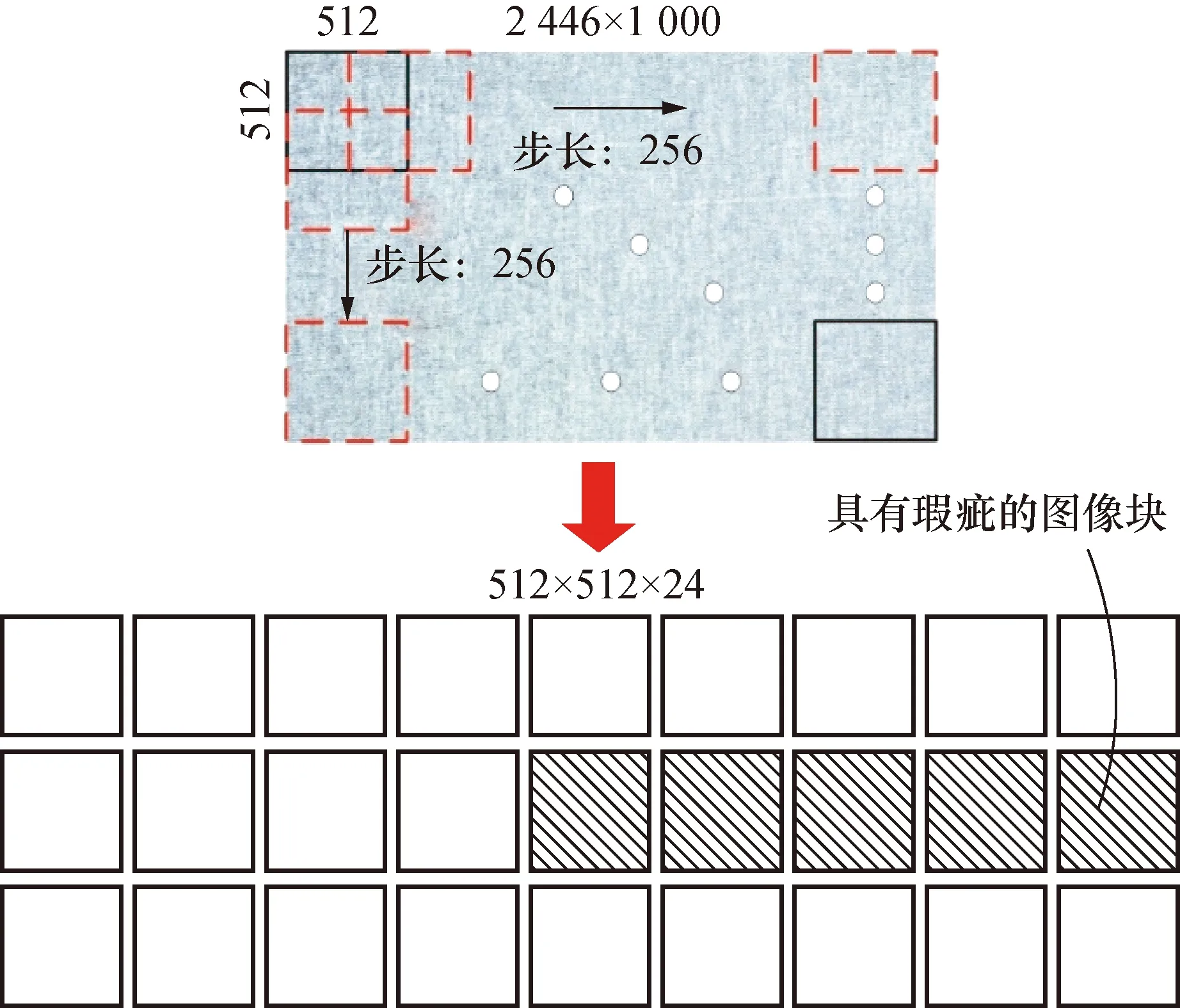
图7 滑动分割Fig.7 The sliding segmentation
4.3 模型训练
在模型训练中,训练集和验证集的比例为8:2,数据的批处理大小为64,并设置批处理归一化。Adam的学习率为0.01,并设置学习率衰减为1×10-4,训练的Epoch为200,并设置保存200次Epoch内最优Loss值模型为最终的模型。
图8展示了网络200次Epoch训练的网络损失曲线。随着Epoch次数的增加,训练损失在25次Epoch时,已经趋于稳定,且损失值在0.5以下。验证与训练的Loss曲线逐渐趋向拟合收敛,说明网络训练未出现过拟合现象。验证精度在119次Epoch时取得最小Loss值,并保存该Epoch的模型参数。
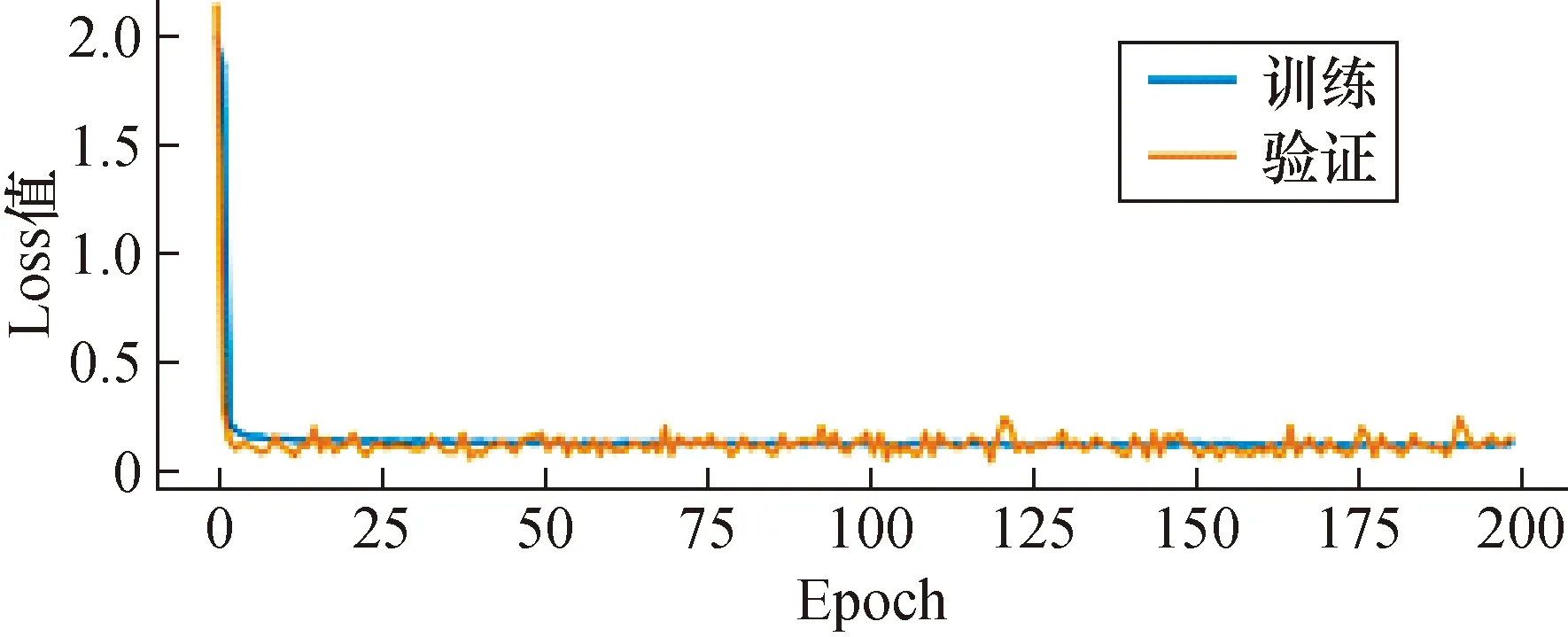
图8 损失曲线Fig.8 The loss curve
4.4 结果可视化
类激活图是经过权重加权的特征图集重叠而成的,用以进一步对表示每个位置对该类别的重要程度进行可视化。图9展示了各类瑕疵图像的类激活可视化,其中红色部分为重点权重大的区域,蓝色为权重最小的区域。可以看出:对于小目标瑕疵区域,如结头,毛粒等瑕疵,网络赋予了较大权重。对于经过扩展后的图像瑕疵区域,网络也实现了该区域的识别,图像随机扩展后,可极大提升网络的泛化性能。对于存在2个或者3个瑕疵的图像,网络也实现了检测,并取得了令人满意的识别效果,这可归因于可变形卷积表现出更强的灵活视野。
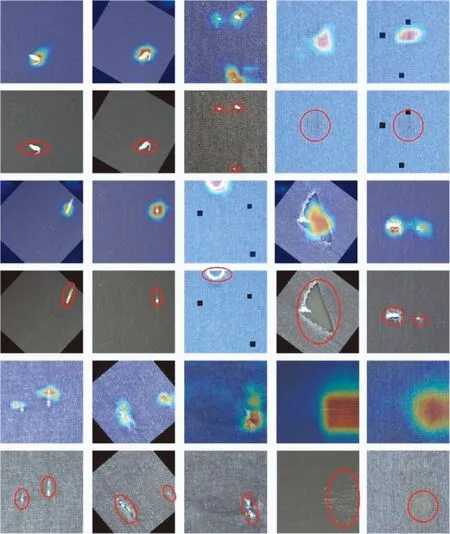
图9 瑕疵类激活图Fig.9 Defect class activation maps
模型通过分类预测和边框回归可针对瑕疵图像分别输出瑕疵类型、预测概率和检测方框,用以可视化模型的最终输出,如图10所示。

图10 瑕疵识别与定位Fig.10 Defect identification and Location
可视化结果表明:所提出的模型表现出较强的判别特征性能,可从瑕疵图像中自适应地学习尺度变化大的瑕疵特征。
4.5 对比分析
为了进一步说明本文所用方法的有效性和可行性,与经典算法进行了对比验证,4种方法各类瑕疵的AP值见表2。
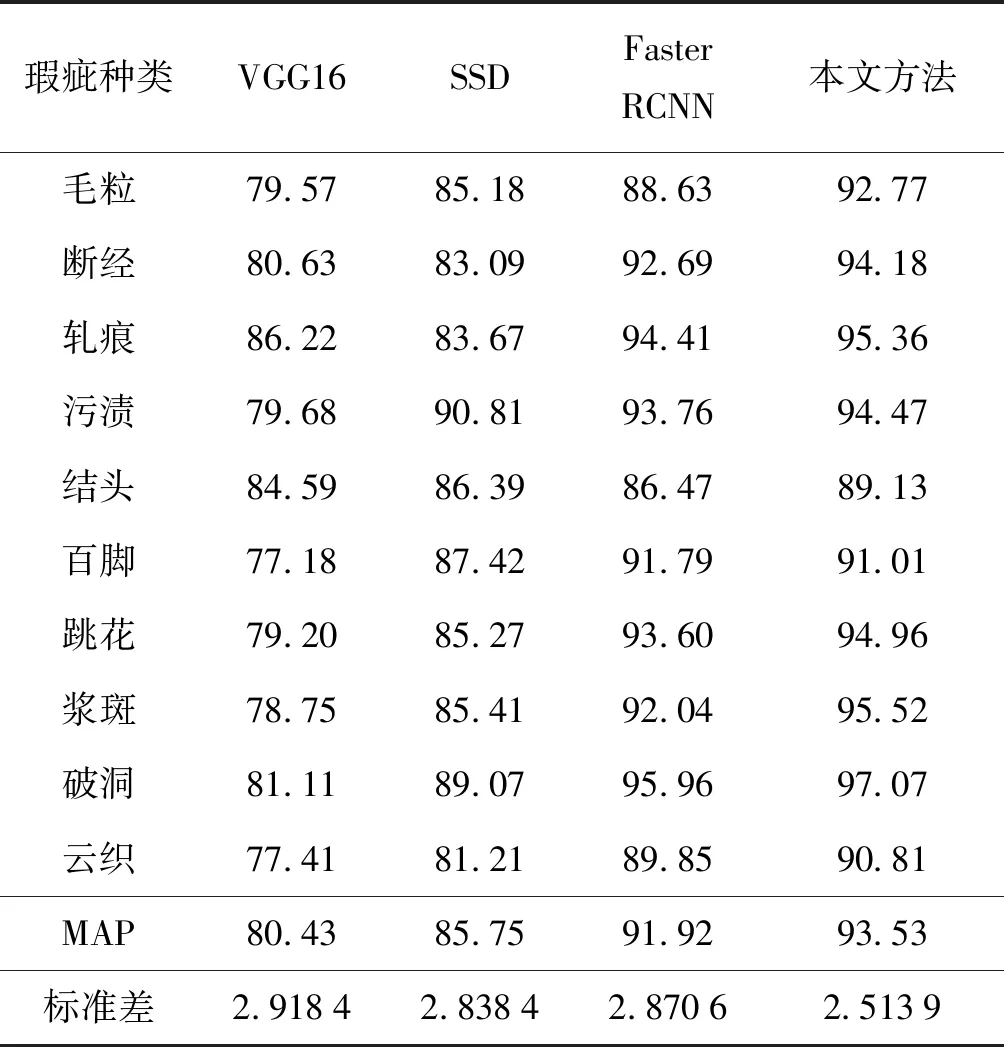
表2 4种方法各类瑕疵的AP值Tab.2 Metric values of each defect for four methods (%)
图11展示了4种方法的IOU值。
相比于SSD和Faster RCNN,本文所用方法具有更好的检测性能,其平均检测精度为93.53%。本文方法在IOU取得了0.718的最佳性能值,各类瑕疵检测精度的标准差为2.513 9,说明本文所用方法具有更精准的瑕疵定位能力,能够有效识别各类瑕疵。其中,SSD的识别性能是最差的,这可归因于特征提取网络无法胜任提取瑕疵特征,甚至出现过拟合。在检测时间上,Faster RCNN取得了最快的检测效果,但其检测精度次之。本文方法的fps(frame per second,画面每秒传输帧数)平均为11帧/s,检测时间已满足实时性检测要求。
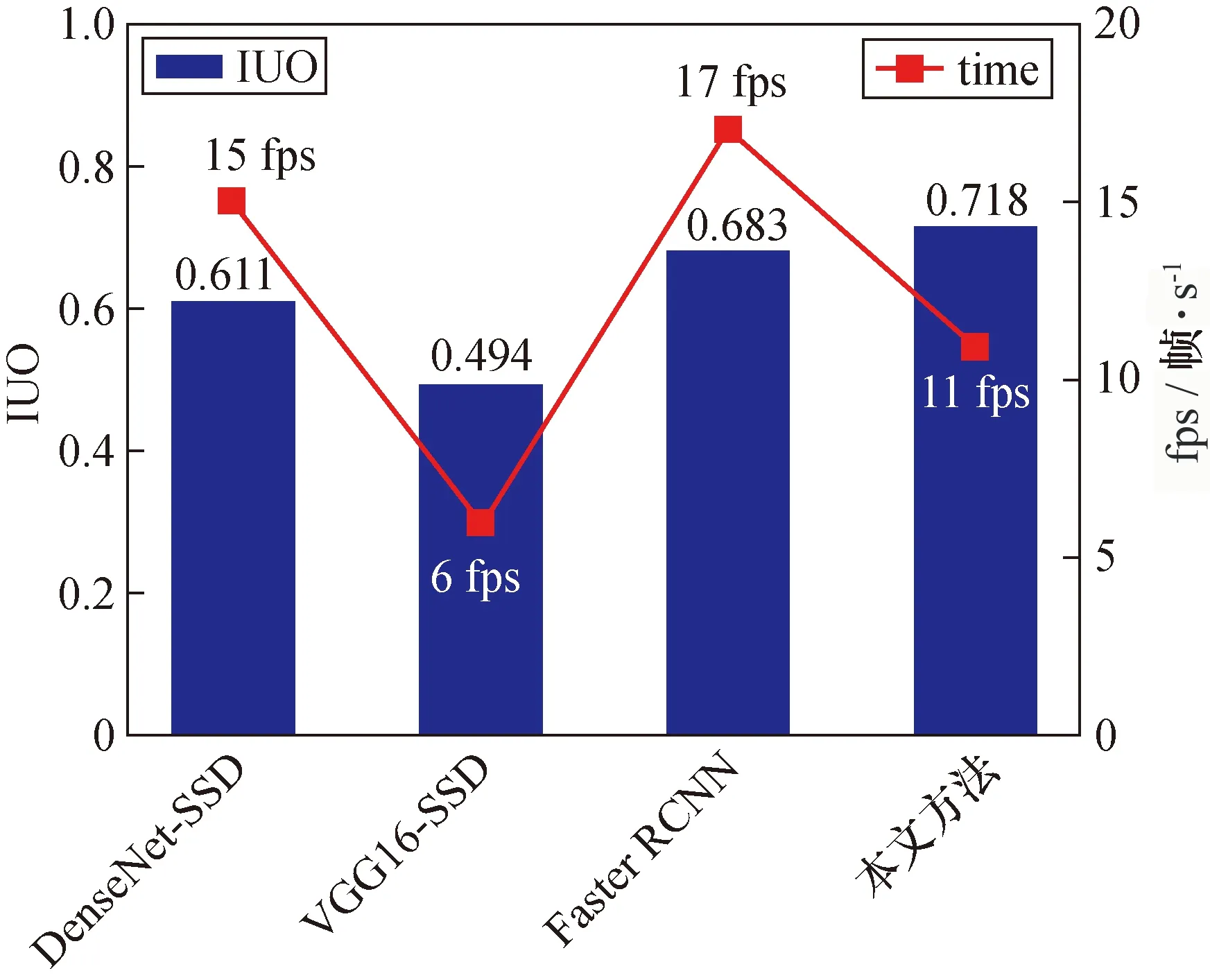
图11 4种方法的IOU和fpsFig.11 IOU and fps of four methods
5 结 论
本文提出了一种基于可变形密集卷积神经网络模型用以对瑕疵进行识别与定位检测。采用可变形卷积机制,用以在局部特征上补充卷积操作无法获得的一些信息,构建起图像中两个有一定距离像素之间的联系。使模型对不同尺度的瑕疵具有自适应的特征提取能力,使其感受野具有不规则的形状,实现自适应覆盖不同尺度的瑕疵。采用密集连接方式实现了特征信息流重用的最大化。最后,结合类别预测和位置边框回归,从而实现瑕疵的识别与定位,并与其他经典方法进行了对比 分析。所提出的方法取得了更好的检测性能,能够对瑕疵特征具有自适应学习能力。实验结果表明:模型的平均检测精度和单类目标检测精度标准差分别为93.53%,2.513 9,相比于其他方法更具有检测优势。
