K近邻方法在信用环境评价中的应用
2023-03-17李忆萍
□文/李忆萍
(西安财经大学统计学院 陕西·西安)
[提要] 信用环境是一种普通的经济关系,一个城市信用环境较好,经济也将快速发展,足以看出城市信用环境的重要性。本文采用统计学中的预测分析方法对城市信用环境状况进行预测,对后期的信用环境改善起到指导性的作用。
引言
我国信用评级行业是在改革开放和市场化进程的背景下产生的,我国信用管理第一部制度产生于2005年。随着信用制度和体系的逐渐完善,个人信用记录作为进行贷款业务的衡量标准,中国人民银行建立了信用信息记录,并实现了信息共享、全国联网,许多省市建立了地方信用监督平台,开展信用服务和监督工作,为我国经济发展和良好信用环境提供保证。
随着社会经济的不断发展,交易方式发生了翻天覆地的变化,从现金支付到线上支付。近年来,“贷款买车”“贷款买房”“蚂蚁花呗”“分期付款”等字眼到处可见,这就对信用评价有了更高的要求,若大量的银行贷款逾期无法收回,将会给金融系统带来严重的风险,对社会经济生活造成严重危害。信用秩序混乱将会阻碍经济的发展,所以良好的信用环境对推动一个国家经济发展至关重要,构建一个诚信、友好、和谐、健康的信用环境是时代所需要的。
一、文献汇总
刘昕雨、彭含月、郭永娜对十堰市郧西县店子镇北山沟村的金融精准扶贫信用环境进行分析与研究,采用调查问卷方式了解精准扶贫的信用状况,再基于联机分析处理和SPSS卡方检验的信用环境评价,分析当前存在的问题,并提出优化信用环境的对策。叶陈毅、陈依萍等以国家政策和大数据为背景探讨构建京津冀信用环境评价指标,根据实地调研选择指标,从区域经济、金融体系、文化教育、信息技术、行政管理五个方面进行指标构建,利用因子分析法得到了三个主成分,分别为经济行政因子、信息教育因子、经济金融因子,进而进行了信用评价并提出合适的建议。解恒鑫首先针对山东省数据建立了评价体系,再分别采用层次法和因子分析法进行信用状况排序和关键因素提取,得出一个地区的信用环境状况与经济发展、社会环境、人文素养、地理位置有着密切的关系,再根据分析结果对构建良好信用环境提出建议。
在阅读大量关于信用环境方面的文献后,发现信用环境对于经济发展起着至关重要的作用,国家必须重视起来。在信用环境应用的大量文献中,大多数研究人员利用因子分析来研究某一指标对信用评价的作用,再根据这些指标对城市信用环境提出合理的建议。但是,本文强调分类预测的重要性,如果提前预测将会发生的事情并进行改善,那么事情的结果就会不一样。
二、构建信用环境评价体系
(一)数据来源。本文选择训练数据和测试数据分别为中国31个省(区、市)2017年数据和2018年11个省市数据,数据来源于中国统计局官网以及各省的统计官网对应年份的统计年鉴。
(二)信用环境评价体系分解分析。(表1)本文从政治、经济、金融、文化、个人、企业这六个维度进行体系构建,共选择23个三级指标,评价体系分解如下:
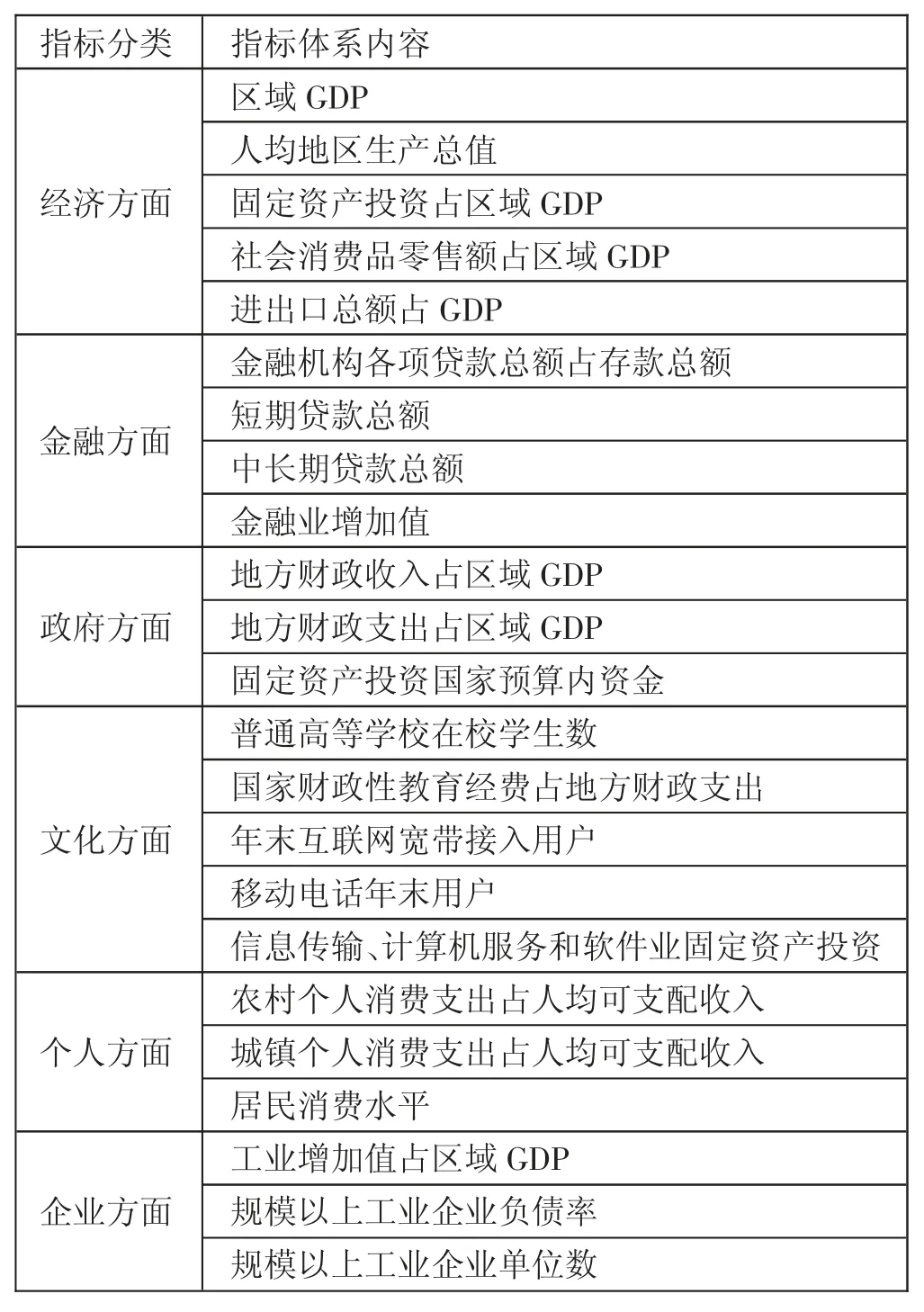
表1 指标体系汇总表
1、经济指标。评价一个地区的经济状况和综合实力都需要一定的经济指标。区域GDP是衡量城市经济状况的必要指标,所以选择区域GDP、人均地区生产总值;同时,还选取固定资产投资、社会消费品零售额、进出口总额指标,并分别计算与GDP的比值。
2、金融指标。金融借贷作为信用评价的重要方面,金融又是推动经济发展的核心产业,它的规模和结构可以反映出经济运行的状况。因此,分别选取金融机构各项贷款总额与存款的比值、短期贷款总额、中长期贷款总额、金融业增加值这四个指标。
3、政府指标。政治信用对社会信用影响程度较大,它将直接影响公共服务的质量。政府指标选择地方财政收入、地方财政支出、固定资产投资国家预算内资金,分别计算收入与支出占GDP比重。
4、文化指标。文化是衡量国家软实力的指标,地区人民的文化程度越高,信用评价也会越高,所以本文选取教育和信息两个方面进行指标构建,选取的指标有:普通高等学校在校学生数、国家财政性教育经费占地方财政支出比重、年末互联网宽带接入用户、移动电话年末用户和信息传输、计算机服务和软件业固定资产投资。
5、个人指标。每个公民都应该为构建良好信用环境共同努力。我国经济具有显著的城乡二元特点,应立足于农村和城镇两个方面考虑指标。选取的指标有:农村个人消费支出占人均可支配收入比重、城镇个人消费支出占人均可支配收入比重和居民消费水平。
6、企业指标。国家的经济发展离不开企业,并且企业的信用直接影响城市信用,因此它是构建信用环境评价的重要部分。企业真实的信用状况可以通过信用评价的高低直接反映,为决策部门提供可靠的依据。则选取的指标为:工业增加值、规模以上工业企业资产总额和工业负债总额以及规模以上工业企业单位数。
三、原理综述
(一)K均值聚类法。K均值聚类法是一特殊的非谱系过程,又称为“快速聚类法”。这种聚类方法的思想是把每个样品聚集到最近均值类中。实际上是一种人为指定凝聚点,采取就近原则来进行分类。此方法的特点是通过K的数值来将数据进行快速分类。
此过程由三步组成:将样品粗略的分成K类;逐个分派样品到最近均值的类中,这里采用欧式距离来计算,并且要不断计算接受和失去样品类的均值;一直重复,直到无元素改变。
算法的决策:给定一个n个m维的数据集X和要分的类别数K选取距离作为相似度指标,聚类目标是使得各类的聚类平方和最小,即:
最小化,在迭代时,聚类中心尽可能不改变。
(二)K近邻算法。K近邻算法是常见的分类算法之一,K近邻法的输入为特征向量,输出为类别,它是当给定一个训练数据,对新的输入数据,在训练数据中找到与输入的最近的K个数据,这K个实例属于某一类,则就把该输入数据分为这个类。模型最基本的三个要素为:距离度量、K值选择和决策规则。
特征空间中的距离就是来反映其接近程度,一般使用的距离为欧式距离。K值的选择会对K近邻的分析结果产生很大的影响,K值的减少容易出现过拟合现象。在应用中,K值取比较小的数值,通常采用交叉验证法来选取最优的K值。
K近邻分析的分类决策规则往往采用多数表决,多数表决规则如下:
分类函数为:
则误分类的概率是:
误分类率是:
要使误分类率最小,就要使式子中最后一部分最大,所以表决规则就是风险最小化。
四、实证分析过程
(一)K均值聚类在模型中的应用。本文在使用K-means聚类时,使K=3进行数据分类。将采用SPSS软件进行分析。聚类分析方法在模型中应用是将31省(区、市)的数据进行信用好坏分类,为下文K近邻算法打基础。在SPSS中运算输出结果,如表2所示。(表2)
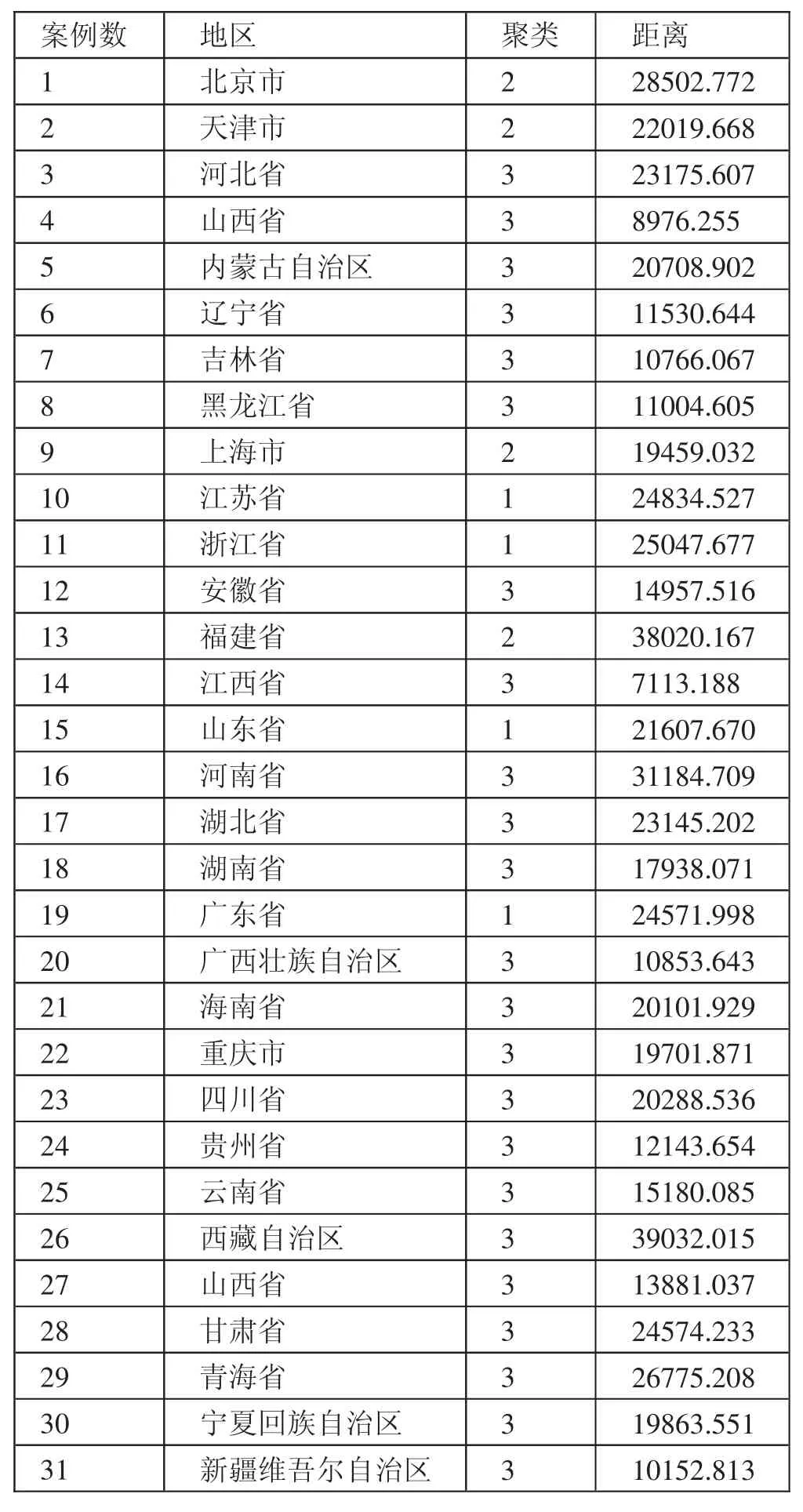
表2 聚类成员一览表
由分析结果可以得出:第一类的省市有4个(江苏省、浙江省、山东省、广东省);第二类有4个省市(天津市、上海市、北京市、福建省);第三类有23个。
由表3中可以看出,CEI排名前十位的为:烟台市、金华市、惠州市、佛山市、宿迁市、温州市、廊坊市、珠海市、日照市、苏州市,他们分别属于山东省、浙江省、广东省、江苏省、河北省。这个数据是全国各城市的排名,比全省市较为精细,但可以看出聚类结果与此结果较为吻合。因此,第一、第二、第三类分别为信用较好、一般、不好的省市。(表3)
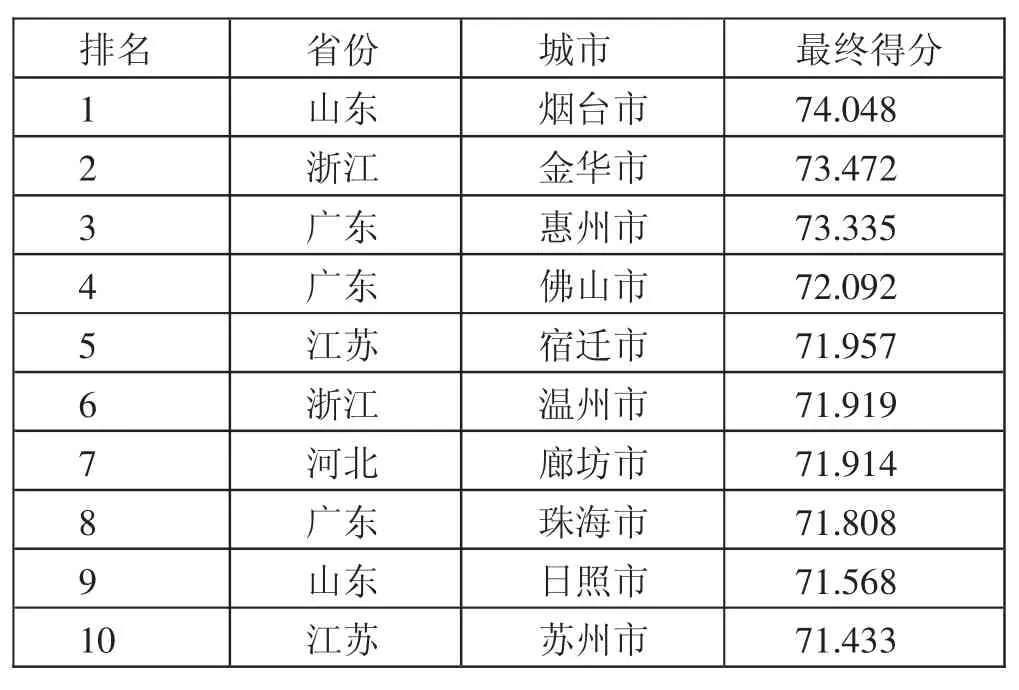
表3 2017年度中国地级城市商业信用环境指数排名一览表
(二)K近邻算法在模型中的应用。本文选取2018年11个省市(包括北京市、天津市、河北省、山西省、内蒙古自治区、辽宁省、吉林省、黑龙江省、上海市、江苏省、浙江省)的数据作为测试数据,而训练数据为聚类分析的数据,利用聚类分析的结果,将测试数据分为三类,确定其标签分别为1、2、3(1为信用环境较好、2为信用环境一般、3为信用环境不好),再用K近邻算法进行分类预测,得出11个省市的信用环境状况。
本文采用Python软件进行分析,分析步骤如下:
1、输入与准备阶段。首先导入Numpy数学运算库和Pandas数据分析包,Pandas里面容纳了大量库以及数据模型,它可以提供处理数据的函数与方法。其次使用Python中机器学习库sklearn,sklearn自带数据集,通常是选择相应的机器学习算法进行训练,本文选取的是KNeighborsClassifier。最后进行了数据的加载。代码如图1所示。(图1)

图1 数据运算准备代码
2、模型建立。首先定义数据集的特征以及对应的标签;然后将数据集分成两部分,分别为训练数据与测试数据;最后引进训练方法,再对训练数据进行拟合。Python代码实现如图2所示。(图2)

图2 模型构建代码
由图2可以看出,模型拟合的准确率为62.5%,这个数值较低,因此需要进行模型优化。
3、模型优化。此处利用网络搜索与交叉验证的方法进行模型优化。网络搜索法是搜寻网格中的每一对超参数,然后对其进行评估,得到评估指标,进行对比后得到最优超参数对,选出来进行模型训练。对于每一对参数对进行评估时使用交叉验证方法。其中,参数与特征相关,超参数是对模型的整体规划有意义的指标。模型优化代码如图3所示。(图3)
由图3代码可以看出:分析过程是将最近邻算法、KDtree的二叉树树形结构、balltree的球形树结构和暴力破解(brute-force)算法组合建立参数,再进行交叉验证五次,得到最佳模型。模型优化后的准确率为91.3%,证明模型良好,可以进行分类预测。

图3 模型优化代码
4、模型预测。直接采用上面的最佳模型进行预测,预测结果直接导出Excel形式。代码如图4所示。(图4)

图4 模型预测代码
运用最佳模型进行分类预测,最后得到的分类结果如表4所示。(表4)
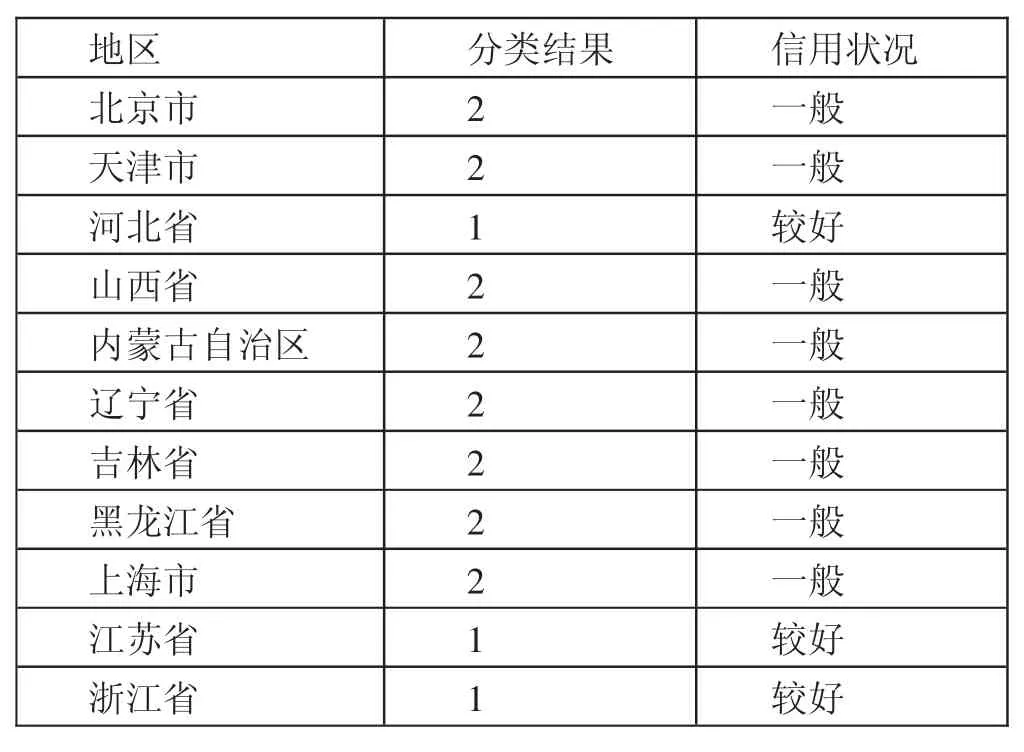
表4 分类预测结果一览表
由表4可以看出,在预测的省市中,信用较好的省市有3个,为河北省、江苏省、浙江省。然而,在2018年国家信息中心中经网发布的全国城市信用状况监测数据显示,5个省位位列第一梯度,分别为江苏省、浙江省、广东省、山东省、湖北省。由此数据可以看出,K近邻分析方法分类预测结果较好。
五、结果及建议
(一)采用K均值聚类分析方法,将K设置成3对2017年全国31个省(区、市)根据信用环境评价进行聚类,分类结果为江苏省、山东省、广东省、浙江省为信用环境较好城市。
(二)使用2018年11个省市的数据作为测试数据,再利用31个省(区、市)的数据作为K近邻分析方法中的训练数据,根据模型进行分类预测,得出:河北省、江苏省、浙江省为信用较好的城市。
(三)采用此方法可以提前进行分类预测,得出城市的信用环境状况,就此可以采取一系列的措施进行改善,以达到构建和谐信用环境的目的。
应进一步发挥信用环境状况较好城市的引领作用。等级落后的城市应积极向其他城市学习,制定适合自己城市信用发展的政策,而等级制度较好的城市,要起到带头模范作用,主动利用自身信用体系建设经验帮助其他城市,并积极主张建立一体化的信用体系;提倡预测信用环境,可以从各个方面对信用环境进行改善,确保经济稳步发展。建立健全数据开放共享机制。数据共享有助于学者进行信用环境评价的研究,对信用环境的评价提供科学理论的支撑。同时,数据的公开透明对信用环境具有一定的监督作用。
