大规模RFID 系统中未知标签的快速可靠识别
2023-03-16郭凯敏马一杰李克秋
郭凯敏,谢 鑫,马一杰,齐 恒,李克秋
(1.大连理工大学 计算机科学与技术学院,辽宁 大连 116024;2.香港理工大学 计算机系,香港 100872;3.河南财经政法大学 民商经济法学院,郑州 450016)
0 概述
射频识别(Radio Frequency Identification,RFID)对于已经装备RFID 标签且有物品盘点、商品追踪、供应链管理等业务需求的公司及机构具有重要的应用价值[1-3]。相比于二维码一次识别单个目标的功能,RFID 技术具有识别效率高、长距离/多目标识别、非视距通信等优点[4-6]。未知标签识别是RFID 领域的基础问题之一。物品位置的错误放置可能带来难以预测的经济损失或安全隐患[7-8],比如有毒有害物品不慎混入食品储藏区,或由于温度、湿度、光照、人员管理疏忽等因素影响,导致有毒有害物品的挥发,给食品安全带来重大威胁。因此及时发现危险物品显得尤为重要,未知标签识别问题具有重要研究价值。
传统的未知标签识别协议的设计大多基于Aloha 协议[9-11]。阅读器向标签发送一个由多时隙组成的时间帧,标签随机选择其中一个时隙回应阅读器问询[12]。当有多个标签选择同一个时隙回应时,该时隙为冲突时隙,阅读器收到的信息是多个标签回应的缠绕信息,而阅读器不能从缠绕信息中提取任何一个标签回应信息。因此,在未知标签识别信息中,冲突时隙会被直接废弃[13-15]。但废弃的冲突时隙同样需要时间来验证冲突,导致冲突时隙的产生降低了未知标签的识别效率与时隙利用率。
在含有未知标签的RFID 系统中,已知标签的存在会影响未知标签的识别效率[16]。在未知标签识别协议执行前,每个已知标签所选响应时隙可以通过帧长、标签ID 以及哈希种子预测得到。如果预测一个时隙没有标签响应,但在协议执行时该时隙有标签响应,则可断定该响应标签为未知标签,且当该响应标签只有一个时,则该标签ID 可以被顺利读取。未知标签选择一个有已知标签响应的时隙时,未知标签不能被识别。因此,已知标签的存在严重制约未知标签的识别效率[17]。在传统未知标签识别协议中,已知标签灭活效率同样也是协议执行效率的重要衡量标准。
本文提出冲突分解法(Conflict Resolution Method,CRM)协议,通过引入区分码改进传统16 位随机数(16 bit Random Number,RN16),使RN16 不仅具备传统的冲突检测功能,而且具备冲突时隙内冲突标签区分功能。同时采用多哈希的方式,使冲突时隙内的标签得到区分的概率更大。
1 相关工作
现有的未知标签识别协议可以分为标签识别[18-19]、未知标签检测[20]、未知标签识别[21]3 类。这3类协议目前主要存在以下3 个不足:
1)标签识别旨在收集RFID 系统中标签ID 信息,通过对比收集到的标签ID 与服务器中存储的已知标签ID,即可发现未知标签。虽然这种协议可以实现未知标签识别,但需要收集所有RFID 系统中标签ID 信息,因此时效性较低。
2)未知标签检测协议意在检测RFID 系统是否存在未知标签,不必获取未知标签ID 信息,因此通常使用概率的方法来优化协议参数设置,但在检测中会出现假阴性错误,即未知标签的反馈信息被已知标签覆盖,导致未知标签检测失败。
3)未知标签识别协议旨在收集RFID 系统中未知标签ID 信息,但为了减少已知标签干扰,通常会把已知标签灭活,由于假阴性错误存在,未知标签可能会被误认为已知标签而被灭活。因此,减少假阴性出现概率成为未知标签识别协议中不可忽略的问题。
本文旨在提升未知标签识别的时隙利用率以及识别效率。现有未知标签识别协议有UTI-SBF[9]、HUTI[10]、PUTI[11]、FUTI[16]、MUIP[17]、TIP[21]等,都 是基于标准Aloha 设计,均面临着冲突时隙不能被利用的问题。且由于已知标签灭活效率低,导致未知标签识别效率过低。ZHU 等[9]利用标签反馈的物理层信息判断一个时隙内标签响应的个数,再利用二次哈希的方式让冲突标签重新选择时隙,虽然这种方式将部分冲突时隙转化为有用时隙,但一个没有未知标签响应的冲突时隙不能被有效灭活,已知标签的干扰仍然是造成未知标签识别效率低的主要原因。未知标签识别效率仍有提升的空间,且在实验中利用USRP 获取标签响应的物理层信息,此种信息在商业RFID 设备中无法获取。LIU 等[16]利用多哈希方式构建过滤数组,过滤数组能高速过滤已知标签,使未知标签被识别的概率增大,然而针对全局的多次哈希运算要消耗大量的时间,冲突时隙也不可避免且无法被利用。LIU 等[17]基于标准Aloha 协议,快速灭活单一时隙中的已知标签,识别预测空时隙转变为冲突时隙的未知标签,但冲突时隙仍然无法被利用,这降低了未知标签的识别效率。总之,冲突时隙不能被有效利用仍是造成未知标签识别效率低的主要原因。
针对现有未知标签协议仍然存在的已知标签灭活效率较低及冲突时隙无法有效利用的问题,本文提出冲突分解法。CRM 协议能把大部分废弃的冲突时隙变为有用时隙,从而增大时隙利用率。通过多哈希的方式可以确定冲突时隙内是否有未知标签存在,如果不存在未知标签,则该时隙内的标签被全部灭活,这样不仅能提高已知标签的灭活效率,而且能减少已知标签对未知标签识别的干扰。此外,还可以有效检测冲突时隙内的未知标签,并提取未知标签ID,提高未知标签识别成功率与效率。
2 问题描述与系统模型
2.1 问题描述
假设已知的标签组为S=(a1,a2,…,an),待检测标签组为T=(t1,t2,…,tN)。S和T的数量分别为n和N。n已知且S中的所有标签ID 均存储在后台服务器,阅读器可以访问后台数据库中已知标签ID 信息。N未知且N≥n,因此未知系统中出现的未知标签数量为u(u=N-n)。未知标签识别的目的是找出待测标签组T中包含的未知标签,并读取其ID 信息。在一个识别可靠度为ω∈[0,1)的RFID 系统中,至少需要识别出的未知标签数量为ω×u,也就是说未被识别的未知标签数量为m,且m≤(1-ω)×u。此CRM 协议的目的是最小化执行时间。
2.2 系统模型
一个典型的RFID 系统包含标签、阅读器和后台服务器3 个部分。每个标签拥有一个独一无二的识别ID(可被读/写),ID 的长度一般为96 位,且系统内所有标签均存储一个相同的哈希函数H(·)。后台服务器存储标签ID 信息,并可根据ID 信息实现多样化的业务需求。因此,标签根据其ID 是否被收录可分为已知标签和未知标签。阅读器可获取标签ID,是链接标签与后台服务器的高速通道,阅读器与后台服务器可统称为阅读器。单个阅读器的读取距离为5~12 m,因此,一个较大范围内的标签识别监控需要多台阅读器交叉协同工作,而每个阅读器都会收到1 个标签反馈数组,后台服务器对所有反馈数组进行位或运算,即可获取1 个融合反馈数组[6]。RFID 系统中所有阅读器均可以被看作1 个超强阅读器,如图1所示。所有标签均在此超强阅读器识别范围内,阅读器周期地询问、识别范围内的标签,并搜集标签反馈信息。
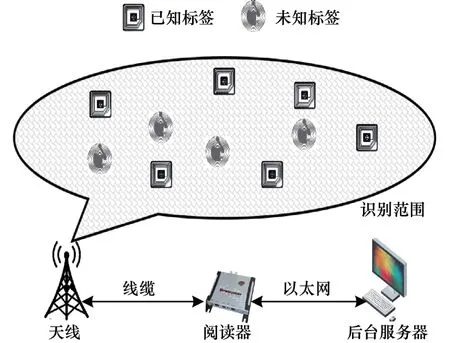
图1 RFID 系统模型Fig.1 RFID system model
2.3 标准ALOHA 协议
阅读器与标签的通信依然遵照标准帧槽Aloha协议设定[22],CRM 协议执行过程如图2 所示,其中未知标签检测过程包含多个时间帧,每个时间帧含有多个时隙。在每个时间帧开始时,阅读器向每个标签发送询问命令Query,并广播参数,其中f是每个时间帧中时隙的数量,r是一个随机的哈希种子。在接收到Query 命令后,每个标签依照哈希函数随机选择一个时隙响应,哈希函数为sc=H(ID,r)modf,其中sc为时隙计数器,H(·)为一个预先存储在标签中的哈希函数,ID 为标签识别码。因此sc∈[0,f)。此后,阅读器逐个询问时间帧中的时隙,当一个时隙询问结束时,阅读器向当前时隙发送slot end 命令结束访问并初始化下一个时隙,而当标签的时隙计数器sc收到命令后自动减1,当sc为0时,标签在接下来的时隙中向阅读器发送预定信息。

图2 CRM 协议的执行流程Fig.2 Implementation process of CRM protocol
当协议执行完毕后,所有的时隙可以分为3 种状态:1)空时隙,没有标签选择该时隙;2)单一时隙,仅有一个标签选择该时隙并回复阅读器询问;3)冲突时隙,有且多于一个标签选择该时隙并回复阅读器询问。
图3 所示为标准ALOHA 协议与CRM 协议的对比结果,其中图3(a)是标准Aloha 协议中,阅读器对于不同状态的时隙采用不同的执行过程。对于空时隙,阅读器发送Query 命令后,等待T1+T3,当没有标签响应时,阅读器终止该询问并访问下一个时隙。对于单一时隙,当阅读器发送Query 命令后,标签回复一个16 位的随机数RN16,阅读器返回标签一个包含该RN16 信息的ACK 命令,当标签收到ACK 命令中的RN16 与自己发送的RN16 信息一致时,此标签回复预设信息并返回阅读器,阅读器接收信息完毕。如果此单一时隙的标签为已知标签,则阅读器发送kill 命令,并开始访问下一个时隙,如果此单一时隙为未知标签,则阅读器收集标签ID,收集结束后开始询问下一个时隙。对于冲突时隙,标签向阅读器发送RN16,RN16 中包含循环冗余校验码(Cyclic Redundancy Check,CRC),然而此时阅读器接收到的RN16 是多个RN16 的融合,CRC 校验错误,则认为此时隙为冲突时隙。在标准Aloha协议中,一个单一时隙、空时隙、以及冲突时隙所消耗的时间分别如下:

图3 标准ALOHA 协议与CRM 协议的对比Fig.3 Comparison between standard ALOHA protocol and CRM protocol
本文假设阅读器与标签通信是在无干扰的条件下进行。根据C1G2 协议[22],阅读器向标签发送数据的速率为26.5 Kb/s,而标签向阅读器发送数据的速率为53 Kb/s,即阅读器向标签发送1 bit 数据所用的时间为12.5 μs,而标签向阅读器发送1 bit数据所用时间为6.25 μs。阅读器与标签通信的参数设定如表1 所示,文中变量所表示的含义如表2所示。

表1 基于C1G2 的仿真参数设定Table 1 Simulation parameter setting based on C1G2

表2 主要符号及其注释Table 2 The main notations and their annotations
3 协议设计
在标准Aloha协议中,冲突时隙以及空时隙被废弃,直接降低了时隙利用率,导致未知标签识别效率较低。为解决该问题,本文设计了CRM 协议,其不仅能有效灭活冲突时隙中的已知标签,而且能识别冲突时隙中的未知标签,把冲突时隙变为可用时隙,大幅提高已知标签灭活效率及未知标签识别效率。
本节将详细介绍CRM 协议的执行过程,并具体分析CRM 协议的执行优势,介绍区分码的设计以及区分码在未知标签识别中发挥的作用。
3.1 V-RNx 的设计与引入
在CRM 协议中,本文引入了V-RNx 的规则,与传 统的RN16 相 比,V-RNx 由Vk以及RNx 组成,其中Vk被称为区分码,RNx 被称为随机码。为尽可能地减少对标准Aloha 协议的改变,V-RNx 与传统RN16都由16 位数据构成,因此k+x=16。RN16 是标签内部随机数生成器生成的16 位伪二进制随机数,具有冲突检测功能,随机数个数为216,假如有两个标签选择同一个时隙,冲突被检测出来的概率为1-16/(216)2,数值接近于1。
假如有w个标签选择同一个时隙,冲突被检测出来的概率为1-16/(216)w,数值无限接近于1。然而在已知标签识别协议以及未知标签检测/识别协议中,在识别效率最高时f=N,此时空时隙的概率为36.8%,单一时隙在f个时隙中所占比例为36.8%,有2 个标签选择同一时隙的概率为18.4%,有3 个标签选择同一时隙的概率为6.13%,因此,在一个时隙中标签数量少于4 个的概率为98.13%。也就是说,在优化后的识别协议中,选择同一个时隙的标签数量很少,利用16 位随机数来检测冲突会造成很大的资源浪费,过多的数据量发送也会导致识别效率下降。V-RNx 把RN16 分成两部分,长度分别为k和x,长度为k的部分为区分码且全部初始化为0,长度为x的部分为随机码,由标签内部随机数生成器生成长度为x的二进制随机数。假设x的数值为8,如果有2 个标签选择同一时隙,则冲突能被检测出来的概率为1-8/(28)2,其值接近于99.99%,当有w个标签选择同一时隙响应时,冲突能被检测出来的概率为1-8/(28)w,该值无限接近于1。剩余的8 位区分码数据可以用作分解冲突标签。
V-RNx 中长度为k的部分用于分解冲突标签。在CRM 协议执行过程中,假设标签已经接收到阅读器的Query 命令以及参数,其中哈希种子统称为r,此时,标签除了选择自己所在时隙外,还要生成自己的区分码以及随机数。区分码初始化为k位0 二进制字符串,标签利用接收的哈希种子ri(i≤λ)再次进行哈希运算,计算式如式(4)所示:
其中:c为标签标志位,也就是区分位,当运算完成后,区分码中第c+1 位变为1,其余位仍然保持为0。这样,在冲突时隙中,每个冲突标签都有自己的标志位,当冲突标签标志位不同时,冲突标签就能得到区分。当区分位只有一个标签选择时,称之为单一区分位,当没有标签选择时,称之为空区分位,当有多个标签选择时称之为冲突位。假设在V-RNx 中k的值为8,当有2 个标签选择同一时隙时,两个标签能够区分的概率为87.5%,当有3 个标签选择同一时隙响应时,至少一个标签能被区分的概率为98.4%,也就是说,当有w个标签选择同一时隙时,任意一个冲突标签能被区分的概率为,w个冲突标签能被分解出来的标签数量为。
3.2 CRM 协议的执行过程
单轮的协议执行无法满足系统需求,因此,CRM 协议需要执行多轮,且每一轮CRM 的执行过程都包括已知标签响应时隙选择以及区分位预测、未知标签识别、已知标签灭活共3 个部分。CRM 协议的执行过程如图2 所示。
3.2.1 已知标签响应时隙选择以及区分位预测
3.2.2 未知标签识别
使用CRM 协议识别未知标签时,在单一时隙和空时隙上的处理与标准Aloha 协议相同,然而,在冲突时隙的处理上与标准Aloha 协议差别较大。期望映射中区分码表示为Q。在CRM 协议中,阅读器首先发布参数,在标签收到参数后,根据函数sc=H(ID,r1)modf选择自己所在时隙,并依据函数c=H(ID,ri)modk,(i≤λ)生成自己的区分码,将实际映射中的区分码表示为A,如图4 所示。多哈希种子的使用目的是尽可能把未知标签从冲突位中区分出来。

图4 区分码识别未知标签的示意图Fig.4 Schematic diagram of discriminant code identifying unknown tags
在CRM 协议中,时隙的状态包括空时隙、单一时隙、冲突时隙3 种。
1)空时隙中没有任何标签回应阅读器的Query指令。
2)单一时隙有且仅有一个标签回复阅读命令,且在V-RNx 验证通过后,标签可以向阅读器发送特定数据,如果单一时隙是已知标签,则该标签会被灭活,不会参与下一轮的未知标签识别过程。如果该时隙的标签为未知标签,则向阅读器发送标签ID。
3)冲突时隙有多个标签同时选择同一时隙。
在空时隙与单一时隙的执行效率上,CRM 协议与标准Aloha 协议没有任何区别。然而标准Aloha协议无法解决多标签信号重叠问题。因此为提高Aloha 协议识别未知标签的效率,冲突时隙会被直接跳过。但在CRM 协议中,由于区分码的引入,CRM协议能够把绝大部分冲突时隙转变为可用时隙,从而增大时隙利用率,提升已知标签灭活效率及未知标签的识别效率。冲突时隙的分解过程如图3(b)所示,假如k值为4,在期望映射中,标签区分码为1000,而在实际映射中标签区分码为1001,也就是说Q为1000,A为1001。该冲突时隙里既有已知标签,也有未知标签。CRM 协议执行时首先检测期望映射中该时隙区分码的A~Q中各位是否全为0,如果全为0,则计算中A~Q中各位的情况,如图3 所示,此时标签只回复阅读器DACK 命令,其中DACK 的长度为k,RNx2 的总长度为k×(λ-1)。如果A~Q位不全为0,则表明未知标签被区分出来,只需检测对应非零位的未知标签是否为单一标签。如图3(b)中的(2)~(3)所示,如果该标签是单一标签,则该未知标签ID 可以被顺利收集,否则,该区分位不作处理,将继续检测下一非零区分位。
在CRM 协议中,被识别的未知标签不参与下一轮协议执行,以下4 种情况的未知标签能被识别:
1)当期望映射中的空时隙转变为单一时隙时,说明有且仅有一个未知标签响应阅读器询问命令,未知标签可以在reply 中回复标签ID。
2)当期望映射中的空时隙转变为冲突时隙时,说明有多个未知标签选择同一时隙回应阅读器询问命令,当CRM 协议分解冲突时,如果有单一区分位,即有且仅有一个标签选择该区分位,则该标签能够被识别,否则对应的未知标签不能被识别,不能被识别的未知标签将参与下一轮未知标签识别。
3)当期望映射中的单一时隙在实际映射中变为冲突时隙时,可以确定该时隙有未知标签,如果λ个哈希种子生成的区分码A~Q不全为0,且存在单一区分位,则对应的未知标签能被识别。
4)当期望映射中的冲突时隙在实际映射中仍然为冲突时隙,但两个冲突时隙区分码不同时,则未知标签分布在A~Q中,如果在A~Q中有单一区分位,则该区分位所对应的标签为能够被识别的未知标签,否则为不能被识别的未知标签。
3.2.3 已知标签灭活
已知标签的存在严重干扰未知标签的识别,当已知标签与未知标签选择同一时隙时,会造成未知标签的假阴性,而区分码可以降低假阴性的概率。因此在实际映射的冲突时隙中,如果λ个哈希种子A~Q中各位全部为0,则可断定此时隙中的标签全为已知标签,阅读器发送kill 命令将其直接灭活。
在CRM 协议中,被灭活的已知标签不参与下一轮未知标签检测,减小下一轮协议执行时已知标签对未知标签识别的干扰,有两种情况已知标签能被灭活,如图3 中已知标签灭活部分:
1)当期望映射中的单一时隙在实际映射中仍为单一时隙时,说明有且仅有一个已知标签选择该时隙,阅读器可以向标签发送kill 指令,直接灭活该标签。
2)当期望映射中为冲突时隙,在实际映射中仍为冲突时隙,且当λ个哈希种子产生的区分码A-Q中各位全为0 时,则表明该时隙中的标签全为已知标签,则直接执行kill 命令。
4 参数优化
4.1 参数k 的优化
V-RNx 的长度与标准RN16 保持一致,在协议执行过程中V-RNx 的长度不会对未知标签识别协议的执行效率产生影响。但V-RNx 由区分码和随机码两部分构成,区分码的长度为k,随机码的长度为(16-k),区分码的长度决定了冲突标签能被区分的概率大小,而随机码的长度决定了阅读器是否能够准确识别冲突时隙,如果把冲突时隙辨认为单一时隙,阅读器就会收到错误的未知标签ID,或者把未知标签误认为已知标签灭活。在标准Aloha 协议中,如果有w(w>1)个标签选择同一个时隙,冲突被检测出来的概率为1-16/(216)w,即同一时隙标签越多,冲突检测越容易。因此,至少要保证2 个标签的冲突时隙能够被准确识别。在V-RNx 中,此种冲突时隙能被准确识别的概率为1-(16-k)/(216-k)2,2 个标签能被区分的概率为(k-1)/k。当k=8 时,两个标签的时隙能被准确识别为冲突的概率为99.99%,两个标签能被区分的概率为87.5%。为满足冲突检测以及冲突标签区分的需要,本文在优化f时将k值设为8。
4.2 哈希种子数量λ 及帧长f 的优化
帧长f过大将产生过多的空时隙,影响未知标签识别的效率,然而当f值过小时,会产生大量的冲突时隙。在冲突时隙中,当未知标签与已知标签产生相同的区分码,则未知标签会被认为是已知标签而被灭活,产生假阴性的问题。为提高未知标签的识别效率及降低假阴性产生的概率,选择合适的f值至关重要。为此,要保证冲突时隙足够多,且冲突时隙中标签数量足够少。
假设一个冲突时隙中有z个已知标签,y个未知标签,则当y值为1 时,产生假阴性的概率最大;当y值变大时,假阴性反而变小。因此,当y值为1 时,假阴性的概率如式(5)所示:
假阴性产生的概率随z值增大而递增,当z为3时,假阴性的概率为33%;当z为8 时,假阴性的概率为66%。
如果设z的值为3,也就是说,在绝大部分的单个实际时隙中,已知标签的数量小于等于3。然而,此时单个时隙的假阴性概率仍然无法满足系统需求,多次区分码的哈希运算可以增大已知标签的灭活效率及未知标签识别概率。冲突时隙中的未知标签被识别的概率如式(6)所示:
其中:当λ值为3 时,z值为3;当y值为1 时,假阴性的概率为3.6%。则在一次实际的冲突分解法执行未知标签识别协议中,有z个已知标签,1 个未知标签选择同一时隙的概率表达式如式(7)所示:
当假阴性概率为0 时,未知标签被识别的数量最多,则能被识别的未知标签数量最大值的表达式如式(8)所示:
其中:max 为实际映射中z的最大值,设为3;k值为8;pzy为时隙中有z个已知标签,y个未知标签发生的概率,当y值为1 时,假阴性发生的概率计算式如式(9)所示:
4.3 执行时间T 的优化
为保证CRM 协议识别未知标签的可靠度,协议需要执行多轮。在保证未知标签识别效率的前提下,优化的参数fop可以有效降低假阴性的比例。在每一轮协议执行中,预测时隙包含空时隙、单一时隙、以及冲突时隙,它们的概率计算式分别如下:
在未知标签选择时隙时,同样会产生空时隙、单一时隙以及冲突时隙3 种时隙状态,它们出现的概率分别如下:
在实际时隙中,空时隙的概率如下:
当某一时隙预测为单一时隙,而在实际映射中该时隙仍是单一时隙时,说明该时隙所对应的标签为已知标签,此类时隙的概率计算式如式(17)所示:
当预测时隙为冲突时隙时,经过CRM 协议分解,A~Q中各位全部为0,则可判定在该时隙内无未知标签,标签可以被灭活,该类时隙所占比例的计算式如下:
当z值设为3 时,执行一次冲突分解法,能够灭活的已知标签数量如下:
灭活这些已知标签所用时间如下:
空时隙检测所用的时间如下:
如果某一时隙在预测时隙中是单一时隙,而在实际时隙中变为冲突时隙,则可断定有未知标签选择该时隙,此类时隙的概率(0 <y≤2)计算式如下:
能被识别的未知标签数量如下:
所需要的执行时间如下:
如果空时隙转变为非空时隙,则可说明该时隙所对应的标签全为未知标签,则该时隙的概率计算式如下:
能被识别的未知标签数量如下:
所需执行时间如下:
从冲突时隙中分解出未知标签,则相应的时隙所占比例分别如下:
则被识别的未知标签的数量如式(36)所示:
分解此部分时隙所需时间如下:
则在CRM 协议执行时,未知标签被识别的总数如式(38)所示:
CRM 协议执行一轮的时间如下:
T0为上述未包含的时隙执行所需要的时间,此类时隙包括z>3,y>2 的时隙,以及其他冲突分解失败的时隙,由于此部分时隙所占比重较小,在以上表述中未提及,但在实际仿真实验时,总的执行时间包括此类时隙执行所需时间。因此,灭活一个已知标签及识别一个未知标签所用时间分别如下:
4.4 未知标签数量的估计
5 CRM 协议的其他应用
在传统基于时隙的Aloha协议中,冲突时隙不可避免,CRM 协议不仅可以用于解决未知标签识别问题,而且可以提高多种基于时隙的Aloha 协议的应用效率,包括标签识别效率、丢失标签检测/识别效率等。
5.1 标签识别
传统的标签识别协议只是利用时间帧中单一时隙搜集标签ID,冲突时隙被直接废弃。然而,CRM协议可以使冲突的标签再次选择自己的区分位,通过区分位辨别冲突标签,有效减少冲突标签的数量,提高时隙利用率和标签识别效率。
5.2 丢失标签检测与识别
传统丢失标签检测/识别的工作大多依据时间帧中期望时隙状态与真实时隙状态的差别,以判断是否存在丢失标签。当期望中的单一时隙变为真实的空时隙,冲突时隙变为空时隙,冲突时隙变为单一时隙时,可断定RFID 系统中存在丢失标签。然而对于丢失标签的识别只能依据期望中的单一时隙和冲突时隙,如果他们对应的真实映射为空时隙,就可断定此时隙所对应的标签已丢失,从后台服务器中可以查询对应标签ID,完成丢失标签识别。
CRM 协议也可以实现丢失标签的检测与识别,且CRM 协议中的标签不仅能够依据期望的单一时隙和冲突时隙转变为空时隙,从而判断识别丢失标签,而且映射入冲突时隙的冲突标签可以选择自己的区分位进行二次判断,以识别丢失标签。当某一区分位期望状态为(1)2,而实际状态为(0)2时,则可断定对应标签丢失。CRM 协议不仅能使时隙利用率提高,而且可以有效避免假阳性问题,提高丢失标签检测/识别效率。
6 CRM 协议性能的评估
为凸显CRM 协议在未知标签识别中的优越性能,本文引入对比协议UTI-SBF[9]、HUTI[10]、PTI[12]、FUTI[16],从5 个方面分析各个协议的性能表现,分别为已知标签数量对未知标签识别效率的影响、未知标签数量对未知标签识别效率的影响、单个已知标签灭活效率、单个未知标签识别效率以及时隙利用率。在仿真实验中,默认已知标签的数量为10 000,未知标签的数量为1 000,ω的值为0.95。由于PTI[12]是标签识别协议,默认需要搜集所有标签ID,但为了突出对比效果,因此本文只搜集未知标签ID,已知标签同样被灭活处理。
6.1 已知标签数量对未知标签识别效率的影响
为研究已知标签数量对未知标签识别效率的影响,仿真设置已知标签的数量从10 000 到20 000,间隔为1 000。图5 所示为已知标签数量与未知标签识别效率的关系。
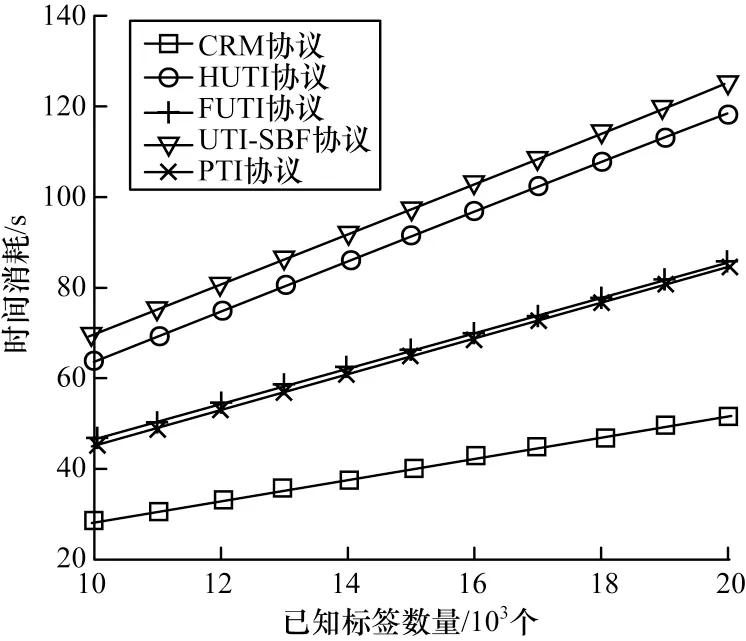
图5 已知标签数量与未知标签识别效率的关系Fig.5 Relationship between the number of known tags and recognition efficiency of unknow tags
由图5 可知:
1)已知标签数量越多,达到实验要求所需的时间越长,协议对未知标签的识别效率越低。
2)UTI-SBF 协议的性能最差,因为该协议把未知标签的识别分为已知标签灭活和未知标签识别2 个过程,已知标签灭活阶段造成时隙浪费,降低了未知标签识别效率。
3)PTI 协议与FUTI 协议的性能接 近,PTI 协议虽然能够把冲突时隙变为有用时隙,提高时隙利用率,但已知标签灭活效率仍然很低,且在解决冲突时隙时,造成时间延时。
4)CRM 协议的性能最优,当n值为20 000,u值为1 000 时,CRM 协议所耗费的时间为51.6 s,而HUTI、FUTI、UTI-SBF 以 及PTI 协议所用时间分别为118.8 s、85.8 s、124.9 s、85.2 s。CRM 协议的时间效率分别是HUTI、PTI 协议的2.3 倍、1.6 倍。
6.2 未知标签数量对未知标签识别效率的影响
未知标签数量也是影响未知标签识别效率的关键因素之一。在仿真实验中,未知标签数量从1 000到2 000,间隔100,图6 所示为未知标签数量与未知标签识别效率的关系。

图6 未知标签数量与未知标签识别效率的关系Fig.6 Relationship between the number of unknown tags and recognition efficiency of unknown tags
由图6 可知:
1)未知标签数量越多,未知标签的识别效率越低。
2)UTI-SBF 协议的效率最差,随着未知标签数量增多,UTI-SBF 协议所用时间增幅最快。
3)CRM 协议的性能最优,当u值为2 000 时,CRM 协议所用时间为33.1 s,而HUTI、FUTI、UTI-SBF以及PTI 协议所用时间分别为71.2 s、50.5 s、84.2 s、48.2 s。CRM 协议的识别效率是UTI-SBF 协议的2.5 倍,是PTI 协议的1.4 倍。
6.3 单个已知标签灭活效率
已知标签灭活效率是未知标签识别效率的间接体现,且标签越少对未知标签识别效率的影响越小。图7 所示为不同协议对单个已知标签的平均灭活时间。

图7 单个已知标签的平均灭活时间Fig.7 Average inactivation time of a single known tag
由图7 可知:
1)在未知标签数量一定的前提下,已知标签数量增多,单个已知标签灭活时间减小,因为随着已知标签数量增多,未知标签所占比重减小,未知标签对已知标签灭活影响减小。
2)除了CRM 协议,其余协议单个标签的灭活时间都比理想标准Aloha 协议上单个标签的灭活时间长,比如当已知标签数量为20 000 时,PTI 协议的单个已知标签灭活时间为4.4 ms,而理想状态下灭活单个标签的时间为3.6 ms,CRM 协议平均灭活一个标签的时间为2.6 ms。
3)CRM 协议的表现最优,因为该协议可以灭活没有未知标签响应的冲突时隙内的已知标签,当已知标签数量为2 000 时,CRM 协议的单个已知标签的灭活效率是PTI 协议的1.6 倍,是UTI-SBF 协议的2.3 倍。
6.4 单个未知标签识别效率
单个未知标签识别效率是未知标签识别效率的直接体现。图8 为单个未知标签的平均识别时间。

图8 单个未知标签的平均识别时间Fig.8 Average recognition time of a single unknown tag
由图8 可知:
1)随着未知标签数量增多,单个未知标签识别所需的时间变短。因为当已知标签数量一定,未知标签数量增多时,未知标签占总标签的比重增大,相对来说,已知标签对未知标签识别影响减小。
2)所有未知标签识别协议对单个未知标签识别所用时间都比理论时间长,比如当未知标签数量为2 000 时,CRM 协议识别单个未知标签的时间为16.8 ms,而理想的识别时间为3.19 ms,已知标签对未知标签的识别造成了巨大延迟。
3)CRM 协议的性能最优,当未知标签数量为2 000,已知标签数量为10 000 时,CRM 协议识别一个未知标签所用时间为16.8 ms,而HUTI、FUTI、UTI-SBF 及PTI 协议所用时间分别为37.4 ms、26.3 ms、42.1 ms、24.9 ms,也就是说CRM 协议的单个未知标签识别效率是PTI 协议的1.4 倍,是UTI-SBF 协议的2.5 倍。
6.5 时隙利用率
时隙利用率也是衡量协议性能的关键因素之一。图9 为当未知标签数量一定,已知标签数量对时隙利用率的影响。
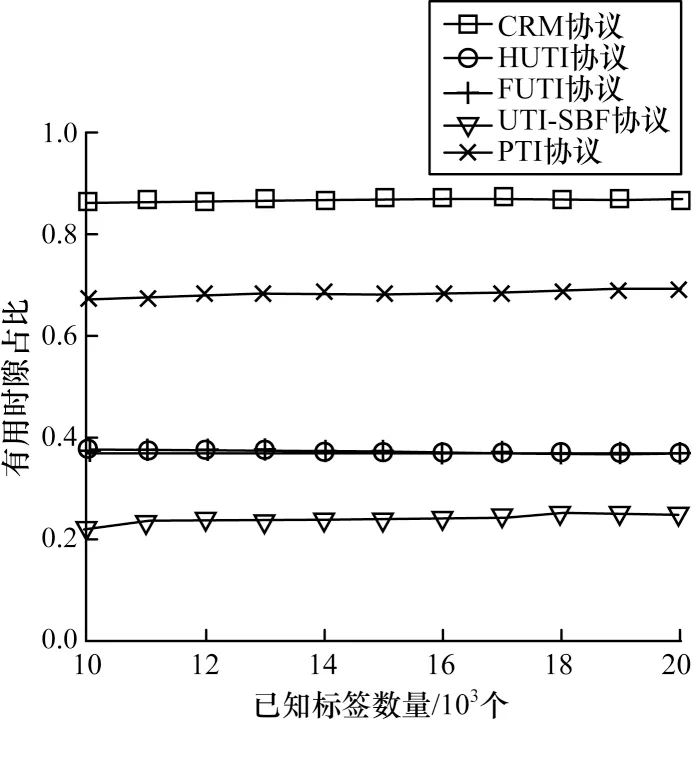
图9 已知标签数量对时隙利用率的影响Fig.9 Influence of number of known tags on utilization rate of slots
由图9 可知:
1)已知标签数量对时隙利用率的影响较小,当已知标签数量从10 000 增加到20 000 时,各协议的时隙利用率基本保持不变。
2)CRM 协议的时隙利用率最高,为86.5%,而HUTI、FUTI、UTI-SBF 及PTI 协议的时隙利用率分别为37.2%、36.7%、25%、68.8%。
7 结束语
现有的未知标签识别协议大多存在冲突时隙被直接废弃、时隙利用率低的问题,本文提出一种CRM 协议,通过引入区分码把冲突时隙转变为可识别未知标签的时隙,提高时隙利用率及未知标签的识别效率。实验结果表明,CRM 协议的未知标签识别效率是UTI-SBF 协议的2.3 倍。虽然CRM 协议的性能得到很大提升,但CRM 协议在解决冲突时隙时只对未知标签进行识别,无法灭活混合冲突时隙中的已知标签,因此下一步将研究快速分离混合冲突时隙中的已知标签问题,实现已知标签的快速灭活,提高未知标签的识别效率。
