基于正交拉丁方多位纠错算法的数据可靠性存储设计
2023-03-15郝学元周帅文朱友康宁晨旭徐星亮
郝学元,周帅文,朱友康,宁晨旭,徐星亮
(南京邮电大学电子与光电工程学院,柔性电子(未来技术)学院,南京 210000)
地震勘探数据[1-2]采集点多、数据量大,存储这些海量信息时,动态存储器 SDRAM以其掉电非易失性,存取速度快、低功耗等特性作为地震数据的存储介质首选。随着技术的发展,存储器设备尺寸增加,芯片上的器件变得更小,存储容量得以扩展,同时也出现一种软错误行为[3]。
一方面,存储芯片受到电磁干扰,会影响其可靠性[4]和稳定性,这些干扰来自太阳或射线辐射,很低的能量就能产生干扰,会导致单个存储位自发地翻转到相反状态;另一方面,由于工艺尺寸逐渐变小,一旦出现单个带电粒子就有可能影响几个连续的带电粒子,这使得相邻的多单元干扰(multi unit upset,MCU)发生的概率增加。除了单事件扰乱(single event upset,SEU),多单元干扰(MCU)控制电路中的单事件中断(single event functional interrupt,SEFI),会导致整个数据阵列发生损坏。在现有商用DDR3 SDRAM 设备上进行的辐射实验表明,存储器器件对SEFI的敏感性更高。存储器的稳定性直接左右着系统的性能表现。
存储过程中还有一些传输误码,在数据源与存储器发生读写操作时,其传输路径上常出现码元错误,而这些误差超出了系统设计的能力;随着器件的老化、温度的影响,还会出现一些硬误码无法纠正,因此设计一套合适的地震数据纠错算法显得尤为重要。在集成电路环境中通常用ECC(error correction codes)纠错算法保证数据的正确性。较为经典的有循环冗余校验、汉明码[5],用于一位数据纠错,BCH码[6]、RS码[7]、DS码[8]均可用于多为纠错但功耗较大,而拉丁方码[9]相对功耗较低。各种算法经过优化,在可靠性[10]、译码效率上[11]都有提升。在存储器内部互联的纠错加固上拉丁方码已得到诸多实际使用[12],基于拉丁方码的进一步优化在低功耗方面特别有优势。随着片上系统的发展,片上存储系统可以对各种算法进行优化验证,大容量数据及高复杂度算法均得以实现。
针对地质勘探系统,大容量数据的低功耗运转是系统的重要指标之一,所设计的正交拉丁方码(orthogonal Latin square code,OLS)多位纠错算法以系统级加固为基础,利用线性分组码结合多位纠错对输入的信息进行编码校验,在读取信息时使用译码器对外界对存储器产生的干扰进行错误纠正,可实现30天超长待机下的数据可靠传输。
1 软错误行为分析
图1为双稳态触发结构式的存储器,该结构中A和B作为敏感节点,最易受到软错误辐射,当A存储1,B存储0时,带电粒子在n2管漏端节点处聚集,大量电子空穴对会在电离径迹附近处产生,由于A点处存储的是1电平,所以n2管漏端节点电势为高,由于电场中的漂移作用,产生的电子会朝着n2管的漏极端移动,并在漏极不断累积,当累积的电荷超过临界点时,则n1管导通,A点存储数据状态变为0,B点存储数据的状态变为1[13]。

p1、p2为PMOS管;n1、n2为NMOS管;Vdd为芯片的工作电压;Vss为接地点
在电场中的高能离子或者质子直接冲击相邻的单元,入射的中子在一定的角度下与杂质发生反应,形成很强的二级粒子,导致多比特位错误,质子、中子以及原子核之间发生反应生成二级粒子,正是这些次生的二级粒子具有很强的电离作用,使得SRAM内部爆发大量的电子空穴对,当累积到存储器的翻转的临界值时,就会导致发生位翻转现象。不同工艺尺寸对应着不同的翻转位数[13],表1中显示了不同工艺尺寸下的翻转位数情况。

表1 多位翻转与单粒翻转比
静态存储器加固翻转方法[14-17]主要版图级加固、器件级加固、单元级加固核系统级加固。各种加固技术都是通过算法校验、检测等达到纠错的目的。通常的奇偶校验法、BCC异或校验法、LRC纵向冗余校验以及CRC循环冗余校验等,多对错误检测有效而对纠错的实现不占优势,且CPU资源占用率高[18-19]。
2 纠错设计
ZYNQ-7000片上系统(SoC)提供了向DDR3内存添加16位ECC(error correction codes)的可能性,利用ECC代理的方式通过ZYNQ7000的PL端访问DDR3内存,并添加ECC代码。为了降低解码器的复杂度,使用正交拉丁方(OLS)编码,此种编码是一种大数逻辑可解码(OS-MDL),当每个位都有一组在该位上正交的奇偶校验方程时,使用该编码方式实现可扩展纠错能力的数据校正方式。所设计的代码通过在每个原始16位的数据添加了16个奇偶校验位。它允许在16个数据位中恢复简单和双重错误,并且能够在发生SEFI时从其他内存芯片的信息中检索内存芯片的内容,在SEFI错误的情况下,能够纠正其他设备中的附加SEU。
2.1 ECC错误行为处理
在ECC校验计数出现之前,内存中使用最多的校验方法就是奇偶校验法(Parity)。在数字电路中使用最小单位0和1表示数据的电平,一个字节代表8位,奇偶校验就是在8位数据后面再加一个校验位来实现校验功能,如果8位上的值相加为奇数就是奇校验,反之为偶校验,无法准确找出哪一位上出现了错误。
奇偶校验的校验位是成倍增加的,16位的数据使用2位校验位,32位数据时使用4位校验位,这对内存是极大的消耗,对于海量数据量的处理数据出错概率大大增加,此时需要一种新的内存奇数,就是ECC校验方法。ECC校验具有发现错误和纠正错误的能力,是用于存储器中的容错技术,但是与奇偶校验不同的是当数据位是8位时,需要5位ECC校验位,当数据位增加到16位时,ECC校验位只需要增加一位,变成6位,32位时校验位为7位,以此类推,数据位增加一倍,ECC校验位只需要增加一位,这就有效节省了数据空间,不会因为数据的成倍增加导致校验位的大量增加。ECC纠错方法可以少占资源,以较高的速度运行,拥有更强的纠错能力,硬件实现方便,适用于海量地震数据的纠错。
对于不可纠错的ECC错误,不存在通过中断或AXI(advanced eXtensible interface)相应发出的错误信息;对于出现可以纠正的ECC错误的情况时,控制器将返回给AXI总线一个相应的SLAVERR的错误请求,在这两种情况下,相关的错误信息,如行列错误、地址错误和错误字节等都会被记录在控制寄存器中。当控制器记录侦检测到相关可以被纠正的ECC错误时,将进行图2所示的操作。

图2 ECC错误行为判断
2.2 Xilinx中ECC纠错设计分析
XilinxZYNQ7000配置了32位的DDR3存储器[20-21],在16位的半总线宽度数据宽度配置中可选ECC支持,即外部要求DRAM DDR设备26位,数据16位,ECC 10位,另外的6位为可选位数。每个数据字节使用一个独立的5位ECC字段。该模式提供单次纠错和双次检测功能,ECC位与数据位和未使用的位交错,如表2所示。

表2 ECC数据位分布
常见的ECC编码是 SECDED 汉明码,允许纠正单比特错误和检测双比特错误。启用后,写操作程序计算并存储ECC校验码与数据,读操作根据存储的ECC码读取并检查数据。为了避免读未初始化的内存位置时发生ECC错误,所有数据写操作应发生在读取之前。由于ECC是通过字节解析计算和检查的,因此对只有该字节已初始化的16位位置,且16位位置的第二个字节未初始化的进行一个字节的读取才不会导致ECC错误,控制器只对已读取的字节进行校验,只有ARM处理器和ACP接口可以访问最低512 KB的DDR,使用DMA设备在DDR控制器初始化和卸载CPU来避免CPU写入整个DDR DRAM耗费大量时间。
2.3 ECC代理设计
采用设计ECC的代理IP,可实现该IP与处理器的互联,其系统框图如图3所示。

图3 ECC代理框图
代码设计时需要将ECC码添加到DDR映射的地址范围内,向每个AXI事务添加字节级的ECC。数据经过ECC Proxy IP后会对字节级的数据添加上1个ECC字节从而使得读取或写入数据量翻倍,这样有效内存带会减少,在进行SDK设计时,需要将DDR数据加载到 L2 缓存中,同样经过刷新后读取的数据才会加在到外围器件中但是不影响整体性能,因此受ECC代理保护的事务将增加延迟。
为了针对上述访问DDR延迟的问题,从L2 控制器到DDR控制器有专用端口,用于减少访问外部DDR存储器的延迟,需要将连接在L2-cache控制器上的APU的所有连续访问都通过Snoop控制单元。为了能增加数据的读写速率,进出 DDR 的数据将通过高性能从HP端口进行。
将DDR内存区域划分为非ECC区域和ECC区域,图4中给出了地址映射框架示例,对于任何非

图4 地址空间映射示例
ECC访问,软件必须使用0x0000_0000~0x0FFF_FFFF的地址范围。对于ECC访问,软件必须使用0x88000000~0x9FFFFFFF的地址范围。软件还将DDR地址范围0x10000000~0x3FFFFFFF标记为不可寻址范围。M_AXI_GP1的地址空间在DDR内存中以1 MB的粒度0x8800000~0x9FFFFFFF地址映射到0x10000000~0x3FFFFFF。此ECC保护区域在物理系统地址空间中定义。从映射架构可看出DDR ECC保护区域地址扩展为M_AXI_GP1 ECC保护区域的2倍,因为额外的 ECC字节与数据字节一起写入,也就是说通过M_AXI_GP1接口写入的每个字节都会得到扩展。因此,DDR 中完整ECC保护区域的1/2用于ECC保护数据,1/2用于字节级ECC存储。
3 多位纠错设计
汉明码支持一位的纠错,双位的检错,当需要纠正多个错误时,为了降低解码器的复杂性,需要利用新的纠错编码技术。现有的多位纠错码有RS码、BCH码和LDPC码等,在编码设计时,需要计算对应的生成多项式,需要大量计算,系统性能开销很大,最终得到的生成矩阵也不唯一,这些问题都增加了设计的难度。正交拉丁方(OLS)[22-24]码与前面介绍的多位纠错码相比较不仅具备大数逻辑译码的译码性能,还能在纠正多个错误的同时,通过模块化的设计方式灵活调整编码时的纠错能力,并且增加的模块对现有的模块和编译码没有影响。
3.1 OLS码编码规则
存储器的多位翻转错误可以依靠自身的纠正能力实现错误修正。由于要靠自身实现多位纠错,设计编码矩阵时要更多关注性能上是否满足解码需求。OLS码的奇偶校验矩阵具备正交性和模块性两大特性,正交性在应用OLS编码时适用一步大数逻辑,可以完成并行译码,增加译码速度,减小译码延迟;模块性是指可以在低能力的纠错码的基础上扩展为高位数的纠正误码的能力。纠错力度t时需要满足如下两条原则。
(1)当设计2t+1个数的编码信息时,需要先进行2t+1次信息位拷贝,和信息关联的奇偶校验方程组成了2t数目的信息,另外的一个是译码的信息位自身。
(2)奇偶校验矩阵由h个正交拉丁方变换得到,在H矩阵中,各列都存在2t=h+2数目的1,因为存在的h个正交拉丁方的原因,所以经过正交变换后的H矩阵使得2t个数的奇偶校验方程分别对应各个信息位,可达到使用一步大数逻辑译码的先决条件。
基于以上原则,正交拉丁方每个行与列是m维的,且均由0,1,…,m-1组成,如果两个m维的矩阵中对应位置上的元素不相同,可以类比为数独的概念,每行每列上不会有相同的元素。利用OLS可以设计纠错m×m位宽的存储器错误码。假设纠错力度为t时,OLS码具有2tm的校验位数,变量m和t共同决定了OLS码奇偶校验矩阵H,可表示为
(1)
式(1)中:I2tm为2tm×2tm的单位矩阵,对应2tm个校验位;Mi(i=1,2,…,2t)为一系列m×m2矩阵,进一步可表示为
(2)
M2=[ImIm…Im]m×m2
(3)
(4)
式(1)构造的H矩阵使用h个正交拉丁方,对m阶正交拉丁方变换可以得出V1,V2,…,Vm,当定义的m阶矩阵可以通过正交拉丁方L=[lij]m×m得到,有
(5)
(6)


(7)
拉丁方的正交性质,决定了每个拉丁方之间都是正交的,子矩阵只有唯一的1存在于列向量中,在同一行中只有一个1可能是分数两个列。所以根据以上分析,OLS的特性可表述为:相同的列向量肯定不属于相同列,参与计算的任意两个数据位和一个校验位顶多一次可能情况;2t个校验位计算时都将遍历所有数据位。纠错t个数的随机错误码对应的数据位为m2。根据上述步骤分析,OLS码的任意两个码字之间的最小距离d=h+3,m和h之间的关系如表3所示。

表3 正交拉丁方阶数和个数关系
3.2 构造OLS码
OLS码的码字之间最小距离为dmin=h+3,所以可以得出对于纠正能力为t的OLS码,在m阶拉丁方L=[lij]m×m的情况下,正交拉丁方的数量为λm(λm≤m-1),此时OLS码的纠错能力t与λm的关系可表示为t=[λm/2]+1。t为1时校验矩阵是M1、M2矩阵再加上单位阵I2 m组成,若改变纠错性能为Δt,根据式(3)~式(5)可得到新增加的行数为2mΔt。
设计信息位k为16位,阶数m为4阶,设置纠正能力t为2,当需要增加的位数为1的时候,行数变为2mΔt=8,所以在原M1、M2的基础上,(32,16)的OLS设计需要增加8行,由表3可知,设置阶数为4时对应拉丁方可表示为
对第一个拉丁方转化向量如下:



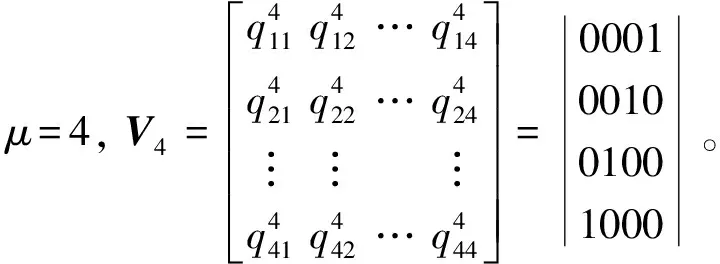
同理,可以得出第二拉丁方转化向量如下:




由式(3)、式(4)得出矩阵M3、M4。
(8)
(9)
将4个M矩阵合并,生成H矩阵为
(10)
式(10)为(32,16)正交拉丁码H矩阵。
4 OLS码多位纠错检测
设计16位数据位添加16位的奇偶校验位如图5所示,在4片存储芯片中分配数据,进行相应的故障注入。

d开头的为数据位;P开头的为校验位
图3所示的硬件架构框中,IP代理模块中添加Custom IP和ECC-SEFI IP这两个ECC代理IP核,IP与处理器之间通过AXI总线互联,其中ECC-SEFI带有两种模块解码器,一种用于解码和纠错,另一种用于SEFI恢复。
当CPU给出相应的写请求时,工作流程为:①ECC Proxy将通过OLS算法得出奇偶校验码,②后通过HP3高数据传输接口将数据和奇偶校验位发送到DDR3中,③向CPU发出写的响应。
当CPU发出读响应后,工作流程为:①ECC代理从DDR3中读取数据和校验位;②校正错误信息的数据;③通过AXI_LITE单事务接口将错误状态信号上报给处理器;④标记数据是否被更改过。
为测试系统纠错能力,将单、双、SEFI和带有SEU类型的SEFI 4种错误插入到DDR3内存中。在访问内存周期里,每种类型的错误都会被注入各个内存位置以测试每种可能的错误类型以及数据中错误位位置的变化。
发现错误的过程可概括为:①通过代理将32位置的数据0xaa55aa55写入到映射地址对应的内存中,并在4个内存中按图5分配信息比特;②在DDR3的地址范围内读取数据信息,分别得到信息位和ECC位;③检验读取后的数据和初始存储的数据是否一致,应用程序也会检查数据是否被更正。接着选择下一个内存地址重复上述步骤。
在ZYNQ7000系统板上设置4组AXI总线,DDR3内存和ECC代理之间的Memory to Ecc Proxy bus,ECC代理和CPU之间的Ecc Proxy to Cotex A9 bus,错误状态总线Error status bus,和ECC代理和内存之间的Ecc Proxy to memory bus。系统以50 MHz的速率运行65个时钟周期。仿真波形如图6所示。
图6中,由总线和控制信号组成四组波形,AXI四总线上的数据传输发生在VALID和READY同时有效时。第1组波形中,由于第3个芯片和第4个芯片分别存在SEFI和SEU而导致错误,波形中芯片3的内容被SEFI错误导致数据变为0x00,芯片4中的d13位受到了SEU影响导致错误变成了0x02。数据由ECC代理模块重新生成并发送到第2组的RDATA总线的处理器。处理器读取第3组RDATA总线来检查状态错误,图6中显示的0x00000001代码提示发生了SEFI错误。校正后的数据会被重新写到ECC代理处,并将校正后的数据和ECC位0x0a050a050a050a05写到DDR3内存的第4组信号的WDATA总线上,完成了多位数据纠错。
5 结论
基于在ZYNQ7000系统板上的设计与仿真,16位的数据位采用16个奇偶校正位,可以同时满足SEU和SEFI的错误保护,以及单双错误纠正。与原始设计成倍的内存消量相比,OLS码多位纠错算法只增加了40%的FPGA资源,其中LUT增加近30%,Register增加近50%,实现了在ZYNQ7000异常干扰情况下单双错误的纠正,有效解决了地震数据存储可靠性问题。
