自适应邻居和图正则的表示学习
2023-03-06杨鹏飞张忠帅陈永旭
杨鹏飞,陈 梅,张忠帅,陈永旭
(兰州交通大学 电子与信息工程学院,兰州 730070)
1 引 言
聚类研究的是如何仅利用数据自身的特征将数据分割成有意义的簇的问题.通过聚类划分,实现簇内数据高相关性,簇间数据高差异性,从而为后续过程提供决策,聚类分析是最具应用价值的技术之一.
由于聚类分析所具备的优势,其被广泛应用于图像检测[1],疾病治疗[2]和文本归档[3]等领域.常见的聚类算法有k-Means聚类[4]、基于层次的聚类[5]、基于密度的聚类[6]和谱聚类[2].但由于数据的维度越来越高,在特征空间中的分布也越来越复杂,前3种聚类方法往往难以取得很好的聚类结果.由于谱聚类算法对高维数据进行了低维表示,且该低维表示往往具有更高的鉴别性,因此谱聚类算法相较于其他算法能够获得更好的聚类结果.然而,谱聚类算法的结果往往取决于算法构建的表示图结构,所以学习一个高质量的表示图是谱聚类算法的核心.因此,可将谱聚类算法看作一种基于图嵌入的算法,其图中元素指的是数据间的关系.
近几十年来,研究人员提出了许多方法来寻找更优的表示图结构.具有代表性的3种图表示方法为:Roweis等人提出的基于数据近邻信息和表示信息构建的局部线性嵌入图[7];Elhamifar等人提出的基于数据的竞争表示特点构建的稀疏表示图[8]以及Liu等人基于数据的低秩表示构建的低秩表示图[9].虽然上述方法均取得了不错的结果,但是还存在以下两个不足:1)构建的表示图不具备适于聚类的连通结构,因此聚类结果往往敏感于输入的数据类别数;2)未充分利用原始数据信息来学习表示图或无法识别数据中的噪声与离群点.针对这些不足,许多改进模型被陆续提出.Nie等人通过引入秩约束确保学习到的表示图具有适于聚类的连通结构[10,11],提高了聚类准确率,但是对数据集中的噪声和离群点不具有鲁棒性;Wen等人通过在低秩表示模型上引入基于距离信息的局部保持约束和非负图约束学习一个同时具备数据的全局和局部信息的表示图[12],但是模型优化过程中时间复杂度较高;Liu等人根据数据集自身的分布特点确定每个样本的近邻数,进一步构造样本的相似矩阵[13],但是模型不具有适于聚类的连通结构.
为了解决上述问题,本文提出一种基于自适应邻居和图正则的表示图学习(RLANGR)模型.RLANGR首先利用数据的近邻信息来学习一个距离正则项,然后引入一个误差矩阵来识别数据中的噪声与离群点,最后对学习到的表示图的拉普拉斯矩阵施加秩约束,使得学习到的表示图具备适用于聚类的连通结构,能够从一个包含c个类的数据集中学习一个恰好具备c个连通分量的表示图.相较于模型[8,9],RLANGR引入了数据距离信息,可以获得包含数据真实结构信息的表示图;相较于模型[10,11],RLANGR引入了误差项,对噪声和离群点具有更好的鲁棒性,可以获得更优的表示图;相较于模型[12],RLANGR使用Frobenius范数而非核范数,具有更低的计算时间复杂度;相较于模型[13],RLANGR引入了秩约束,使学习到的表示图具备更适于聚类的结构.
本文主要贡献如下:
1)学习到的表示图能够捕获数据的真实结构信息;
2)表示图对噪声和离群点具有更好的鲁棒性;
3)表示图具备更适于聚类的连通结构.
本文符号说明:‖i‖1表示向量i的L1范数,‖i‖2表示向量i的L2范数,‖M‖F表示矩阵M的Frobenius范数,‖M‖1表示矩阵M的L1范数,‖M‖*表示矩阵M的核范数,I表示一个单位矩阵,1表示一个值全为1的列向量,1=[1,1,…,1]T,Tr(M)表示矩阵M的迹,MT表示矩阵M的转置.
2 相关工作
稀疏子空间聚类(Sparse Subspace Clustering,SSC)[8]和低秩表示(Low-Rank Representation,LRR)[9]在图表示学习领域中已经取得了广泛的应用.其中,SSC利用矩阵的稀疏表示技术,基于数据之间的竞争表示特性,在联合表示中自适应地选取若干个最有可能与被表示样本来自于同一类的样本进行表示.LRR基于数据通常近似分布于联合子空间的假设,通过在表示矩阵上施加低秩约束,能够同时求取所有样本的表示系数来构建一个反映数据全局结构的表示图.近年来,基于上述两种算法,许多改进算法被提出.潜在的低秩表示方法(Latent Low-Rank Representation,LatLRR)[14]通过子空间分割和特征提取,构造了一个由观测数据和隐藏数据组成的字典.拉普拉斯正则化的低秩表示方法(Laplacian regularized LRR,LapLRR)[15]和图正则的紧凑低秩表示(Graph Regularized Compact LRR,GCLRR)[16]期望相似的样本具有相似的表示向量,其使用拉普拉斯约束项来利用数据的局部信息.非负稀疏超拉普拉斯正则的低秩表示(Non-Negative Sparse Hyper-Laplacian Rregularized LRR,NSHLRR)[17]综合了SSC和LRR的优点,其在模型中同时引入了稀疏表示项和低秩表示项,能够同时挖掘数据的局部与全局结构.低秩局部切线空间嵌入子空间聚类(Low-rank local tangent space embedding for subspace clustering,LRLTSER)[18]根据样本的切线空间与其邻域的关系修正了局部线性嵌入的系数,以处理复杂结构的数据.其中,SSC和LRR的模型分别如式(1)和式(2)所示:
(1)
(2)

在实际应用中,由于数据可能存在噪声污染和离群点,为了消除其所带来的负面影响,本文分别提出了更为鲁棒的改进模型:

(3)
(4)

在得到表示矩阵Z后,SSC和LRR均采用谱聚类的方式得到最终的聚类结果,即先对矩阵Z归一化;再根据公式W=|Z|+|Z|T计算,得到对应的表示图;最后使用图分割的方式对表示图进行切分,得到最终的聚类结果.
然而,图切分的结果往往敏感于学习到的表示矩阵Z的结构,若Z中恰好存在与样本类别数c相同的连通分量数,则往往能取得好的聚类结果.基于此,Nie等人提出了基于自适应邻居的聚类(Clustering and Projected Clustering with Adaptive Neighbors,CAN)[10]和拉普拉斯秩约束聚类(Constraint Laplacian Rank,CLR)[11]模型.这两个模型通过施加秩约束,使得学习到的表示图恰好具备c个连通分量,有效地提高了聚类结果.其中,CAN模型基于数据的局部连通性,定义任意两个数据点xi和xj的相似度为sij,通过求解下列函数自适应地得到每一个数据点的最优邻居:
(5)
为了从一个包含c个类的数据集中学习一个恰好具备c个连通分量的表示图,本文在式(5)的基础上施加了秩约束,得到如下改进模型:
(6)
其中,γ表示惩罚项参数,LS表示相似度矩阵S对应的拉普拉斯矩阵,rank(LS)表示拉普拉斯矩阵的秩.
3 自适应邻居和图正则的表示学习
3.1 图学习模型

(7)

在实际应用中,由于待处理数据可能存在噪声污染和离群点,而其会掩盖数据的真实结构.为解决此问题,提高模型的鲁棒性,本文参考式(3)和式(4),在式(7)中引入误差项约束ei,得到如下模型:
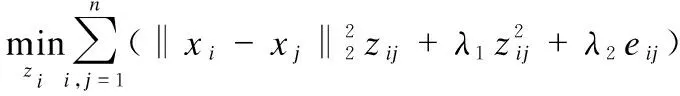
(8)
其中λ2为大于0的惩罚项参数,ei∈R1×n是一个向量,eij表示向量ei的第j个元素.
为了提高式(8)的实际表示意义,本文将任意两个数据点xi和xj成为邻居的概率zij推广到整个数据集Xd×n,得到如下模型:

(9)


由定理1可知,通过约束Lz的秩,可以得到一个具备c个连通分量的表示图.受此启发,本文参考模型(6),在模型(9)中引入秩约束,得到一个适用于聚类的表示图结构,模型如下:
(10)
模型(10)为本文所提出学习模型,秩约束rank(Lz)能够得到更适于聚类的表示图.由于得到的表示图已具备精确的c个连通分量,因此不需要再执行如k-Means等算法得到聚类结果,通过模型得到非负矩阵Zn×n后,使用标准化分割(Normalized cut,Ncut)[21]算法得到最终的聚类结果.
3.2 模型求解优化
由于拉普拉斯矩阵Lz是一个半正定矩阵,其所有特征值都为非负值,因此模型(10)的求解等价于当λ3取较大值时的下列优化问题:

(11)
其中,λ3为大于0的惩罚项参数,σk(Lz)表示矩阵Lz的第k个最小的特征值,σk(Lz)≥0.
若将表示图中每个节点看作是一个函数值fi∈R1×c,则问题(11)转化为:
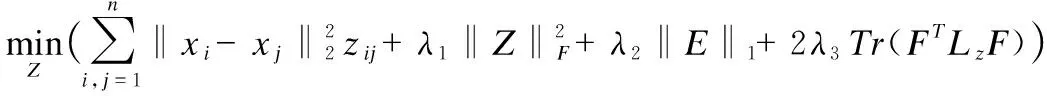
(12)

上述问题的求解是一个非光滑优化问题,常用的解决方法有交替方向优化算法(Alternating Direction Method,ADM)[22]和加速近端梯度优化算法(Accelerated Proximal Gradient,APG)[23].由于ADM算法的高效性,本文使用该算法对上述问题进行求解.
首先引入两个辅助变量P和Q,得到如下模型:
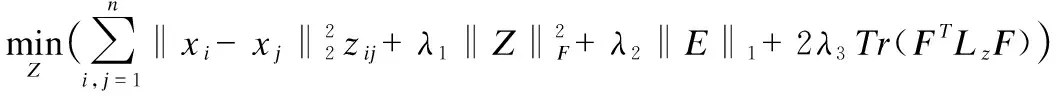
(13)
问题(13)的增广拉格朗日函数为:

(14)
其中,C1,C2,C3为拉格朗日乘子,μ为大于0的惩罚项参数,Ψ为约束项集合,Ψ={Z,P,Q,E,F}.
通过求解式(14)的极值,可得到式(10)的局部最优解.求解过程如下:
1)更新变量Z.假设P,Q,E,F为已知变量,则变量Z的求解问题转化为:

(15)
求式(15)对Z的导数,并令∂L(Z)/∂Z=0,可得Z的最小解值为:
(16)
2)更新变量P.假设Z,Q,E,F为已知变量,则变量P的求解问题退化为:
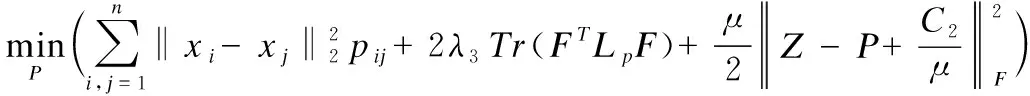
(17)
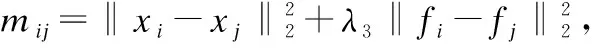
(18)
其中,pi,zi,mi分别表示矩阵P,Z,M的第i行向量.问题(18)的最优解为:
(19)
当采取公式(19)得到最优的矩阵P后,为保证P≥0,使用元素最大化操作P=max(P,0).由于P1=1,因此拉格朗日参数ψi的最优解为:
(20)
3)更新变量F.假设Z,P,Q,E为已知变量,则变量F的求解问题退化为:
(21)

4)更新变量Q.假设Z,P,F,E为已知变量,则变量Q的求解问题退化为:
(22)
令G=Z+C3/μ,gij为矩阵G的i行j列元素,则问题(22)的优化问题可转化为:
(23)
由问题(23)可推出qij的最优解为:
(24)
5)更新变量E.假设Z,P,F,Q为已知变量,则变量E的求解问题退化为:
(25)
由于L1范数不可微的特点,所以采用收缩运算求得问题(25)的最优解为:
E=τλ2/μ(X-XZ+C1/μ)
(26)
其中τ表示收缩算子.
6)更新变量μ,C1,C2,C3.上述参数的更新公式分别为:
μ=min(ρμ,μmax)
(27)
C1=C1+μ(X-XZ-E)
(28)
C2=C2+μ(Z-P)
(29)
C3=C3+μ(Z-Q)
(30)
其中,ρ和μmax是常数.
上述内容为本文所提出模型的具体优化过程,通过交替迭代更新上述变量,可得到变量的最优解.算法1对上述过程进行了总结.
算法1.
输入:数据矩阵X∈Rn×d,参数λ1,λ2,λ3,簇类数c.
输出:有精确的c个连通分量的表示图Z∈Rn×n.
1.初始化:构建X的一个k近邻图作为Z的初始图.使用公式(21)构建初始化矩阵F,令Z=P,Z=Q,E=0,C1=C2=C3=0,μ=0.01,ρ=1.2,μmax=109.
2.while not converge do
使用公式(16)对Z进行迭代.
使用公式(19)对P进行迭代.
使用公式(21)对F进行迭代.
使用公式(24)对Q进行迭代.
使用公式(26)对E进行迭代.
分别使用公式(27),公式(28),公式(29),公式(30)对μ,C1,C2,C3进行迭代.
end while
4 实验与结果分析
4.1 实验环境
本文实验使用MATLAB 2019a软件,操作系统为Windows 10,内存为128GB,处理器为Intel(R)Xeon(R)Gold 5222 CPU @ 3.80GHz.
4.2 实验数据集
为了验证本文所提出算法的有效性,本节选取4个图像数据集和3个非图像数据集共7个真实数据集进行聚类分析.各数据集信息如表1所示.
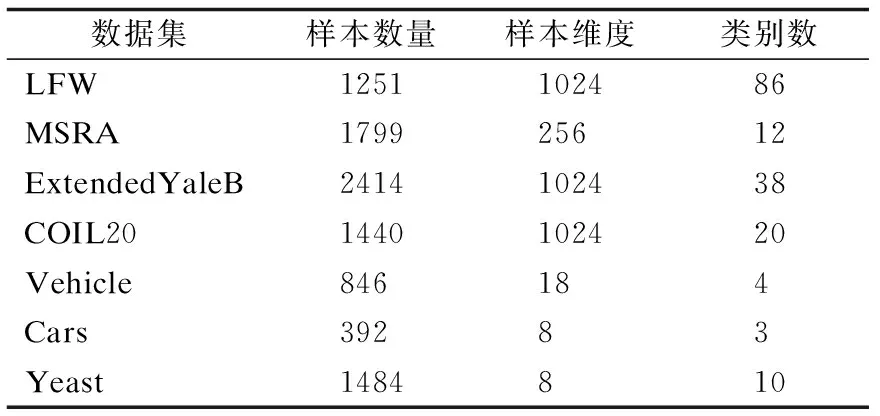
表1 实验数据集信息Table 1 Experimental datasets information
其中,LFW、MSRA、ExtendedYaleB为人脸数据集,LFW的人脸数据采集自网络,即获取数据的设备与环境不同,其包含86个人共1251张图像.MSRA含有12个人共1799张图像.ExtendedYaleB数据集每一类的人脸图像采集自不同的光照强度下,其包含38个人共2414张图像.COIL20是一个包含20个物体在72种不同角度下的物体图像数据集,共1440张图像.实验中去除了所有图像的背景并将图片裁剪为32×32.其余3个非图像数据集均来源于UCI机器学习库(1)M.Lichman.UCI Machine Learning Repository[http://archive.ics.uci.edu/ml],2013..
4.3 实验方法
为验证本文所提算法的性能,本文选取k-Means聚类算法,比率分割(Radio cut,Rcut)[24],Ncut[21],SSC[8],LRR[9]和其相应的两种改进算法:LatLRR[14]和LapLRR[15],综合了SSC和LRR特点的改进算法:NSHLRR[17],以及3种基于秩约束的方法:CAN[10],CLR[11]和LRR_AGR[12].
上述对比算法中,除k-Means方法是直接利用原始数据在特征空间的分布上进行聚类外,其余所有算法都是先学习表示图再进行聚类.其中,Rcut和Ncut首先均使用高斯核计算表示图中的元素值,构建一个基于近邻的表示图.然后Rcut对表示图的拉普拉斯矩阵直接进行特征分解,得到最终聚类结果;Ncut首先对拉普拉斯矩阵进行一次归一化处理,然后再进行特征分解,得到最终聚类结果.SSC、LRR、LatLRR、LapLRR、NSHLRR、LRR_AGR以及RLANGR均先使用不同的约束条件构建表示图,然后使用图分割方法得到最终聚类结果.CAN和CLR直接使用构建的表示图得到最终结果.
4.4 参数设置
由于上述算法均包含一到多项人工调节的惩罚项参数,为了更加公平地对比这些算法,本节首先使用不同参数进行网格寻优,然后选取算法在最优参数下的结果作为对比试验.例如k-Means算法,由于其初始化时的敏感性,本文运行20次该算法,将得到结果进行均值处理;Rcut和Ncut算法使用不同的参数列构建其初始近邻个数与高斯核参数,选取最优结果;CAN和CLR算法使用作者建议的构建方式学习初始的表示图;其余所有算法均使用网格寻优的方式,得到最优参数所对应的聚类结果,作为对比试验.
4.5 算法时间复杂度分析
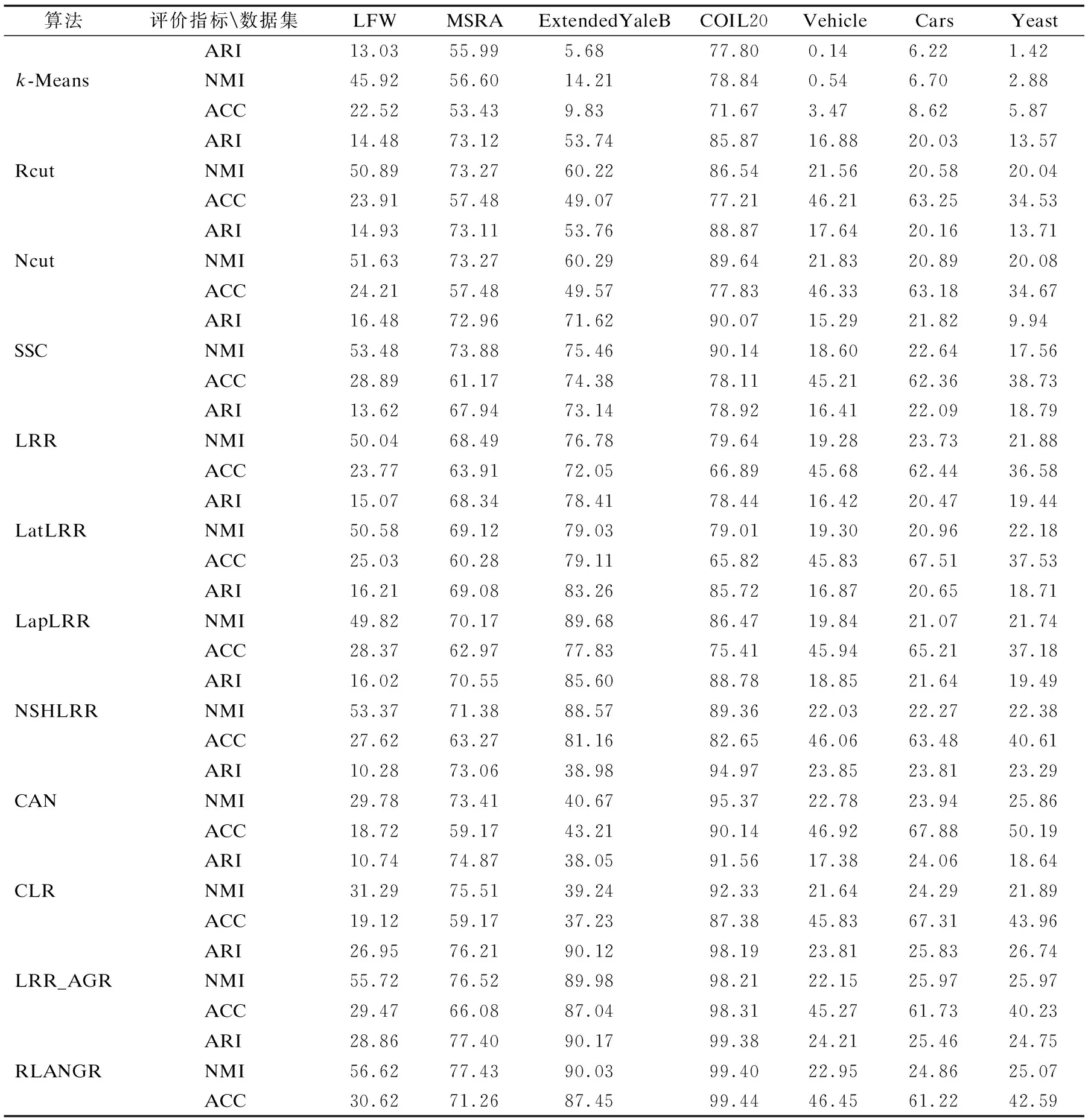
由算法1可得,时间复杂度最高的过程分别为步骤1中求矩阵的逆矩阵和步骤3中的特征值分解.在忽略矩阵基本运算的前提下,对于一个n×n的矩阵,求逆矩阵和特征值分解的时间复杂度分别为O(n3)和O(rn2),其中r(r 本文所提算法相较于SSC、LRR、LatLRR和LapLRR 4种算法,主要贡献为引入了距离正则项约束.由于这4种算法的公式主干都仅采用稀疏约束或低秩约束来学习,忽略了数据距离信息的贡献,因此无法学习原始数据的内在结构,从而无法得到最优的聚类结果.NSHLRR算法可视为SSC算法和LRR算法的结合,其模型虽引入了距离正则项约束,但该假设为原始数据中距离假设在约束条件下的一种映射,所以该算法仍忽略了原始数据中距离信息的贡献.CAN和CLR算法主要利用原始数据中样本的距离信息结合秩约束来学习一个恰好具备c个连通分量的表示图,但由于其模型中没有考虑噪声和离群点的影响,因此若原始数据中包含大量噪声信息,这两种算法将无法得到最优的聚类结果.并且由于真实数据往往分布在非线性流形空间中,若仅通过欧氏距离进行度量,则难以得到一个最优的表示图结构.LRR_AGR算法通过引入低秩表示约束项对CAN和CLR算法的缺点进行了改进,解决了非线性流形空间中数据的表示问题.但是由于低秩约束的求解是一个NP难的问题,在模型计算中往往通过核范数的方式进行松弛求解,而‖M‖*≥‖M‖F当且仅当M为一维向量时二者相等,其中‖M‖*表示M的核范数,且学习到的表示图对应的矩阵Z显然是一个非负矩阵,所以从模型优化的角度出发,即求解问题(9)的过程中使用‖Z‖F有着更好的效果.而且从物理意义角度来说,‖Z‖F能够直接反映出样本来自同一类的概率,具有更好的解释性. 如表2所示,在图像数据集和非图像数据集上,RLANGR都能取得较好的聚类结果,具有一定的普适性,可应用在多种数据集上. 表2 不同算法在各数据集上的聚类结果对比(%)Table 2 Comparison of results(%)of different clustering methods on datasets 通过对上述实验结果进行分析,本文可以得出如下结论: 1)本文所提出算法在图像数据集上的聚类指标高于其他算法,而人脸数据集的样本维度均大于非人脸数据集,说明文本所提算法能够更好的学习一个高维数据的表示图,得到更好的聚类结果. 2)对比CAN、CLR和RLANGR,可以看出在高维数据的聚类任务中,仅使用样本距离度量无法得到合理的聚类结果;而在低维数据的聚类任务中,仅使用样本距离度量便可得到不错的聚类结果,这是因为低维数据往往具有线性流形空间的分布结构,使用距离度量能够学习到一个结构良好的表示图,因此可得到不错的聚类结果.说明本文所提出算法更适用于处理样本特征信息丰富的数据集. 3)对比CAN、CLR、LRR_AGR、RLANGR和k-Means算法,可以看出在均使用距离信息度量的情况下,施加秩约束可以有效地提高算法的性能,说明将数据类别作为先验信息输入有利于学习一个具有真实结构信息的表示图,从而提高聚类正确率. 本节以聚类准确率(Accuracy,ACC)为例分析RLANGR算法与各参数之间的关系.从模型(12)可以看出,RLANGR算法主要含有3个参数λ1,λ2和λ3,分别用于调节模型中的距离正则化项、误差项和秩约束项.由于在单张图中无法同时得到ACC与3个参数之间的关系,因此在本节实验中,首先固定其中一个参数的值,然后调节其他两个参数值的组合,最终得到其与ACC之间的关系.为了更直观地反映出参数对于ACC的影响,本文将参数的初始值设定为{10-3,10-2,10-1,1,101,102},通过网格寻优的方式进行参数组合,在COIL20数据集上进行了实验,结果如图1所示. 从图1可以发现,在λ1≤0.01时,聚类准确率往往高于λ1≥1时的情况,这主要是因为参数λ1控制模型中的距离约束项,当该项贡献过大时,模型受原始样本间距离信息约束过强,算法可近似看作退化成k-Means算法.因此在实际应用中,λ1的取值范围应首先考虑设定为≤0.01.对于参数λ2,由于该项控制模型中的误差项,较大的λ2会造成噪声项过拟合,而较小的λ2会造成噪声难以被补偿,因此λ2的选取需要进行寻优.对于参数λ3,由于该项控制模型中的秩约束项,当该项贡献过大时,秩约束项在模型中将产生较大影响,这将会导致在学习表示图的过程中忽略数据的其他信息,仅从图分割的角度出发,从而无法得到合理的聚类结果;当该项贡献过小时,可视为模型忽略了秩约束项的作用,这将导致模型虽然能够得到一个恰好具备c个连通分量的表示图,但是由于模型中其他项的贡献过强,得到的表示图在分割成c个连通分量的过程中可能存在错误. 图1 在COIL20数据集上,固定一个参数(a)λ1(b)λ2(c)λ3,其他两个参数与聚类正确率之间的关系Fig.1 Accuracy versus the other two parameters by fixing one parameter of(a)λ1(b)λ2(c)λ3 on the COIL20 dataset 本文提出了一种自适应邻居和图正则的表示学习方法RLANGR.该方法在基于原始数据距离信息的前提下,首先引入了误差项对模型中的噪声和离群点进行补偿,能够自适应的识别出数据集中的噪声和离群点;然后引入了秩约束使学习到的表示图具备更适用于聚类的连通结构,从而使表示图对原始数据集的解释性更强.总之,RLANGR能够自适应地利用数据所携带的距离信息学习一个反映真实数据结构关系的表示图并得到一个不错的聚类结果.在4个图像数据集和3个非图像数据集上进行了广泛的对比实验,结果验证了本文所提出方法的有效性.4.6 与其他算法的联系
4.7 实验结果分析
4.8 参数敏感性分析

5 总 结
