相似度矩阵辅助遥感图像无监督哈希跨模态关联
2023-03-06李浩然熊伟崔亚奇顾祥岐徐平亮
李浩然,熊伟,崔亚奇,顾祥岐,徐平亮
(海军航空大学 信息融合研究所,烟台 264001)
0 引言
近年来,随着星载和机载等遥感探测手段的不断丰富,获取到的遥感数据类型更加多样、数据规模不断扩大,有力带动了遥感领域跨模态关联方法的发展。跨模态检索任务是指根据给定模态中的查询样本,然后从其他模态中检索出与其相关的数据,多模态数据通常包括图像、文本、视频、音频等[1]。而遥感图像和文本是情报信息的重要组成部分,遥感图像与文本信息之间关联关系的建立对多源情报数据的有效利用有着重要的意义,两者的相互印证有助于进一步提高获取情报信息的可靠性。
随着深度学习的不断发展,深度神经网络越来越广泛应用于获取不同模态的特征表示,实现将跨模态信息映射到同一特征空间中,有助于解决不同模态间的“异构鸿沟”问题。然而,现有的遥感图像文本跨模态关联方法多为基于实值表示学习,虽然关联效果较好但由于这类方法存储计算消耗大、效率低,故无法适应大规模快速检索任务的需求。
哈希方法实现检索速度快、效率高,随着当今遥感数据类型和规模的增长,在遥感跨模态领域受到越来越多的关注。近年来深度学习与哈希跨模态方法的结合,使得获取不同模态的特征表示更加高效,而且无监督的哈希跨模态关联方法无须标签信息就可实现关联,在解决跨模态关联问题上展现出更大的优势。但现有无监督深度哈希跨模态方法仍存在一些问题,通常分别对跨模态的相似度信息进行学习,而且没有标签信息辅助,会造成模型无法正确有效地获取不同模态之间的语义关联关系。此外,深度哈希方法大多通过深度神经网络获取的原始特征直接生成哈希码,生成的哈希特征难以获得令人满意的辨别性信息。
针对上述问题,本文提出了一种相似度矩阵辅助遥感图像无监督哈希跨模态关联方法,利用遥感图像和文本的原始特征和哈希特征分别构造对应的相似度矩阵,再通过矩阵损失函数的约束用原始特征构造的相似度矩阵来指导哈希特征相似度矩阵的生成,以捕获潜在的语义相关性尽可能保留与原始特征的语义相似性,减小生成哈希特征后的语义信息损失,并与无监督对比学习的方法相结合,增强学习特征表示的判别性,进一步了提高无监督哈希跨模态关联检索的性能。
1 相关工作
1.1 遥感图像跨模态关联
随着大规模多模态数据的不断丰富,跨模态关联检索方法在遥感领域的发展得到了更多关注[2]。文献[3]提出了一种用于遥感数据的新的跨模态信息关联检索模型,模型重于从不同的输入模式中学习统一的、有区别的嵌入空间,并可以用于单模态和跨模态信息检索场景。MAO Guo 等[4]提出了一种视觉-语音关联学习网络,并构建了用于图像和语音关联的数据集,验证了遥感图像与语音数据之间关联关系构建的可能性。文献[5]基于不同模态信息间潜在的语义一致性,提出了一种通用的跨模态遥感信息关联学习方法,通过共同空间的构建实现了多种模态数据的相互检索。也有很多学者开始关注遥感图像与文本之间的关联问题,文献[6]设计了语义对齐模块,通过利用注意机制以增强遥感图像和文本之间的对应关系,然后通过设计的门函数过滤尽可能多的不必要信息。针对遥感多模态检索任务中的多尺度性和目标冗余问题,文献[7]设计了一种非对称多模态特征匹配网络实现跨模态遥感图像检索。文献[8]一种基于融合的关联学习模型用于遥感图像与文本间的跨模态检索,通过跨模态融合网络的设计提高跨模态信息之间的语义相关度。现有的遥感图像跨模态检索方法可以根据特征表示学习的方法不同分为基于实值表示和二进制表示两大类[9],而上述模型大多为基于实值表示学习的跨模态关联方法。
1.2 哈希跨模态关联方法
哈希跨模态关联方法又可分为有监督和无监督两种,在计算机视觉领域对跨模态哈希关联方法的研究更为广泛,文献[10]提出了一种端到端深度跨模态哈希方法,将特征学习和哈希码学习集成到同一框架中。文献[11]提出了一种用于跨模态检索的多任务一致性保持对抗性哈希方法,通过利用标签信息学习一致的不同模态特征表示,用对抗性学习策略强化跨模态信息的语义一致性。文献[12]将矩阵分解和拉普拉斯约束结合到网络训练中,显式约束哈希码以保持原始数据的邻域结构,优化特征学习和二值化过程。文献[13]基于不同模态的邻域信息构建联合语义相似度矩阵,该矩阵同时集成了多模态相似信息,提出了跨模态检索的深度联合语义重构哈希法。文献[14]通过构造联合模态相似矩阵和基于分布的相似性决策和加权方法,充分保留了实例间的跨模态语义关联信息。文献[15]提出了一种用于无监督跨模态检索的多路径生成对抗哈希方法,该方法充分利用生成对抗网络GAN 的无监督表示学习能力捕获跨模态数据的底层流形结构,实现多种模态信息关联。由于不需要人工标注节省了大量人力物力,无监督方法越来越受到更多地关注,上述除了文献[10]和文献[11]为有监督哈希方法外,其他方法都为无监督方法。跨模态哈希方法在遥感领域的研究相对较少,文献[16]研究了基于哈希网络的SAR 与光学图像之间的遥感跨模态检索,通过引入图像转换的策略丰富了图像信息的多样性。文献[17]提出了一种新的无监督对比哈希算法用于解决遥感图像与文本间的跨模态关联问题,算法主要通过利用设计的一个多目标损失函数来进行无监督的跨模态表示学习。但无监督哈希方法在实值的二值化过程中会导致部分语义信息的损失以及原有结构被破坏[18],而且没有充分考虑模态内数据结构和模态间邻域结构的匹配关联,因此对不同模态间语义一致性的挖掘及优化计算等仍是目前研究的一个重要方向。
2 模型方法
本文所提方法的总体框架如图1 所示,分为处理遥感图像和文本数据的两个结构相类似的网络模型分支。对于各模态信息的处理,首先通过对应模态的特征提取深度神经网络模型(ImgNet、TxtNet)获得遥感图像和文本的原始特征表示(Original feature),再通过哈希模块(Hash module)学习得到相应的哈希特征表示(Hash feature)。为了在哈希方法学习过程中尽可能保持不同模态信息间的语义相关性,分别构造了原始特征和哈希特征的相似度矩阵,通过原始特征相似度矩阵指导哈希特征相似度矩阵的学习,减小哈希学习过程的语义信息损失,并与对比学习相结合以进一步挖掘不同模态信息间潜在的语义相关性。模型整体主要通过相似度矩阵损失(Similarity matrix loss)以及对比损失(Contrastive loss)的约束进行关联关系的学习,以进一步提高最终哈希特征模态间的语义相关性,实现对遥感图像文本跨模态信息之间关联关系的无监督学习。

图1 本文方法框架Fig.1 The structure of the proposed model
2.1 特征提取
各模态特征提取过程首先通过深度神经网络分别获取遥感图像和文本信息的原始特征表示,然后再进一步输入到哈希模块中学习相应的哈希特征表示。在本文提出的基准方法中,遥感图像的特征表示通过使用卷积神经网络模型Resnet-18[19]提取,最后经全连接层得到输出维度与文本特征表示相同的遥感图像特征表示向量,文本的特征表示采用自然语言处理领域的BERT[20]模型,将输出的最后四层隐藏状态求和得到最终的文本特征表示,特征向量的维度为768 维。在哈希网络模型的学习训练阶段,遥感图像和文本特征提取网络模型的权重保持冻结,而且用于这两种模态的特征提取模型可以灵活替换。得到跨模态原始特征表示进一步输入到哈希模块中进行哈希特征的学习,通常方法的转化过程会使用符号函数将特征转换为“-1”和“+1”的形式,但这会造成神经网络模型在反向传播过程出现梯度消失的问题,导致模型无法训练。因此在训练过程中,本文方法在哈希模块由两层全连接层构成并采用反正切函数作为最后一层的激活函数[21],使得最后输出类哈希编码的形式的哈希特征表示。哈希模块的目的是通过哈希函数的学习从遥感图像和文本原始语义特征信息生成准确的哈希特征表示,在这过程中不同模态中语义信息相似的实例能够表示成相似的哈希码。
2.2 相似度矩阵构造
无监督跨模态哈希方法无法通过标签获得不同模态间的关联信息,但从深度神经网络中提取的特征中包含着丰富的语义信息。文献[12,22]已经证明,学习保留原始特征数据邻域结构的二进制码能够有效改进深度哈希网络的无监督训练,哈希特征相似度矩阵反映了哈希码在汉明空间中的邻域结构。所以本文分别利用原始特征表示和哈希特征表示构造相似度矩阵,通过原始特征之间的相似度与哈希特征之间的相似度的语义对齐来辅助增强不同模态语义信息间的相关性,提高无监督哈希方法的关联效果。
对于每个批次样本,遥感图像和文本对分别经ImgNet、TxtNet 获得相应的原始特征表示,进一步经正则化处理后表示为I,T,其中遥感图像特征表示文本特征表示。然后采用计算余弦相似度的方法来构造这两种模态特征表示模态内以及模态间的相似度矩阵,用于描述遥感图像与文本的原始邻域结构信息及跨模态间的语义关系。遥感图像模态内的相似度矩阵表示为文本模态的相似度矩阵为两种模态间的相似度矩阵为,其中的定义分别为
不同模态的相似度矩阵通常互为补充,通过将遥感图像相似矩阵、文本相似矩阵以及两模态间的相似度矩阵SF融合成一个模态间联合相似矩阵,以获得对不同模态实例之间语义关系的准确描述。表示为
式中,α,β,γ为权衡参数,α+β+γ=1,α,β,γ≥0,用于调节不同模态邻域关系的重要性。
同样,对于遥感图像与文本经哈希模块得到的哈希特征,采用与原始特征表示构建相似度矩阵同样的计算方式,可以获得对应模态内及模态间哈希特征相似度矩阵,能够描述不同模态信息哈希特征间的相关关系邻域结构。如模态间的哈希特征相似度矩阵表示为SH=cos(HI,HT),其中的元素由遥感图像i和文本j对应的哈希特征计算
通常二进制哈希码对应的语义描述往往会偏离特征的语义描述,导致模型效果的下降。通过构造的联合模态相似矩阵来指导哈希相似度矩阵的生成,学习原始数据邻域结构,使得到哈希特征具有较高的实例间原始语义相关度,最终的二值哈希码能够尽可能保留更多地语义信息,可有效改进深度哈希网络模型的无监督训练[12]。
2.3 损失函数
为了有效地进行无监督跨模态哈希学习,本文设计了一个新的损失函数组合,通过对比损失与相似度矩阵损失的相互结合,增强哈希表示的判别性,提高了模型关联检索的准确性。
对比损失可以有效提高无监督表示学习能力,在本文模型中,采用归一化温度尺度交叉熵目标函数[23-24]进行对比损失的计算。在对比损失中主要考虑遥感图像文本对模态间的对比损失,匹配图文对的特征表示在共同特征空间的距离尽可能近,不匹配的图文对距离尽可能远离,通过使用对比损失来使匹配的遥感图像和文本之间的语义信息对齐。模态间对比学习能够使遥感图像和文本之间的互信息最大化,进一步发掘跨模态信息潜在的关联关系,使模型学习到的特征更具判别性增强模型表征学习能力。模态间的对比损失可定义为
式中,S(u,v)=exp(cos(u,v)/τ),cos(u,v)=为余弦相似度,τ为温度系数,M为批次大小。
相似度矩阵损失通过利用构造的相似度矩阵,同时考虑模态内以及模态间哈希特征的相似度信息与原始特征的相似度信息语义对齐。通过最小化原始特征与哈希特征相似度矩阵之间的重构误差来学习原始特征的邻域结构,发掘模态内及模态间潜在的语义相关性,以弥补转化为哈希特征后语义信息的不足。本文所提方法的相似度矩阵损失设计为
式中,η为权衡参数,其设置能够使相似度矩阵间的语义对齐更加灵活。通过模态内及模态间相似度矩阵的语义对齐,尽可能学习保留遥感图像文本原始特征的邻域结构关系,充分挖掘潜在语义相关信息,更好地建立不同模态间的关联关系。
最终的总体损失函数是对比损失函数和相似度矩阵损失的加权和为
式中,λ,μ为平衡两损失之间关系的超参数。
3 实验结果与分析
3.1 数据集与实验设置
在本文实验 中,使用UCM 数据 集[25]和RSICD 数据集[26],RSICD 数据集 包含31 类共10 921 幅 遥感影像,每幅影像包含5 句对应的文本描述,UCM 数据集包含2 100 张21 类遥感图像,每张图像同样有5 句相关的文本描述。两个数据集中遥感图像及对应文本描述的部分样例如图2 中所示。在训练过程中,每张图片只使用一个随机选择的文本描述,输入图像的大小为224×224,遥感图像的特征提取采用预训练的Resnet-18,文本描述的特征提取使用预训练模型‘bert-base-uncased’提取。批大小设置为256,学习率设为0.000 3,共训练100 次,训练时采用Adam 优化器。损失函数中超参数分别设置为α=0.25,β=0.25,γ=0.5,η=1.5,λ=0.001,μ=0.1。实验在PyTorch 框架下进行编译,模型在搭载一块GeForce RTX 2080Ti GPU 的工作站上运行。

图2 数据集中遥感图像及对应的文本描述Fig.2 Remote sensing image and corresponding captions from the datasets
为有效评估所提出的方法,在实验中进行了遥感图像检索文本以及文本检索的关联检索任务,采用均值平均准确率mAP 作为模型的评价指标,mAP 是评价模型关联检索性能的常用指标,其定义为
式中,N是查询集的大小,ri是与查询样本i相关的项数,k是数据库中的样本数。
在本文实验中,采用前20 个检索到的样本的均值平均准确率(表示为mAP@20)作为模型的评价指标,Top-k 的准确率P(k)是通过按与查询样本的汉明距离排序的返回前k个样本的准确率计算,定义为
式中,rel(i)是一个样本相关性指示符,如果查询和检索到的样本相匹配,则该指示符等于1,否则为0。汉明距离是由两个二进制码中不同位的个数定义的,汉明排序用于哈希值的排序,它根据查询和检索样本之间的汉明距离对检索到的样本进行排序。这里P(k)较大的值对应更好的检索结果。
3.2 对比实验结果
为了验证所提方法的有效性,在数据集RSICD 和UCM 上将其与文献[17,28]中的方法DUCH 以及几种不同的跨模态哈希基准方法进行了对比,分别为CPAH[11]、DJSRH[13]、JDSH[14]。为了保证对比的公平,对比实验数据划分与文献[17]保持一致,数据集通过随机选择分为训练集、查询集和检索集(分别为50%、10%和40%),在相同的实验设置下训练模型。表1 和表2 分别展示了本文方法在RSICD 和UCMerced 数据集上使用mAP@20 评估图像到文本和文本到图像检索两种任务与上述基准方法的对比结果,实验对比了四种不同哈希码长度B=16,32,64,128。

表1 RSICD 数据集上不同方法的mAP@20 比较Table 1 The mAP@20 comparison of different methods on the RSICD dataset

表2 UCM 数据集上不同方法的mAP@20 比较Table 2 The mAP@20 comparison of different methods on the UCM dataset
通常哈希码位数越多模型效果越好,因为其可以存储的语义信息更丰富。在RSICD 数据集上,除在B=64 时图像检索文本任务的mAP@20 低于基准方法的DUCH 方法,在其他情况下均优于其他对比算法,而且在哈希位数少的情况下模型的优势更明显,例如当B=16 时与DUCH 方法相比,在两种检索任务上mAP@20 分别提升了2.4%、3.9%,而当B=128 时对应提升分别为0.3%、2.4%。在UCM 数据集上,除了当B=64,128 时图像检索文本任务的mAP@20 低于DUCH 方法外,在其他情况下本文方法在不同哈希码长度下的两种检索任务上与无监督的方法DJSRH,JDRH,DUCH 相比均取得了最好的mAP@20 分数,而且优势相对比较明显。而与有监督方法CPAH 相比,在哈希吗位数为16 和32 时本文方法优于该方法,尤其在哈希码长度为16 时优势更为明显,但在哈希码位数为64 和128 时与方法CPAH 还有一定差距。分析两个表中数据可以得出,在哈希码位数较少时本文方法的优势相对更明显,这更好地说明的本文方法的有效性,哈希码位数较少时其能够存储的信息有限,因此在哈希码转化过程中位数较少时的语义信息损失可能会更严重,哈希码位数较多时其本身可存储的语义信息更加丰富,所以模型对其提升效果相对有限。而本文模型的设计能够使得到的哈希特征中尽可能保留更多的语义信息,减少原始特征转化为哈希特征时的语义损失,使得生成的哈希码中可保留更具辨别性的语义信息,且在哈希码位数少时更有效,使得关联结果更加准确,更适于大规模遥感图像文本间的准确关联检索任务。
对比算法文献中仅把数据集的50%用作模型训练学习可能不够充分,为充分学习遥感图像文本间的关联关系并进一步检验本文模型的有效性,我们对数据集划分比例进行了优化。进行优化后数据集训练集与测试集的比例为7∶3,并在相同的实验条件及划分下与遥感领域最新提出无监督跨模态哈希关联检索方法DUCH 进行了对比,实验结果对比如表3 所示。此外,我们将遥感图像原始特征提取采用的预训练Resnet-18替换为预训练的vit[27]后进行模型效果的对比,一方面能够验证模型的灵活性及有效性,另一方面也可进一步探索遥感图像特征提取网络模型对最终关联检索效果的影响。

表3 方法优化后实验结果对比(mAP@20)Table 3 The mAP@20 comparison of different methods after optimization
从表3 可以看出,当仅对数据集划分比例优化后模型对各模态特征表示的学习更充分,而本文方法与DUCH 方法的效果对比提升也更加明显,且在两个数据集上不同任务下的mAP@20 指标均优于DUCH 方法,说明了改变后模型学习到的语义信息更加丰富,也进一步验证了本文方法的有效性。本文方法同样在B=16 和32 时的效果提升最为显著,再次说明本文所提方法能更好地保留原始语义相关性,能够在哈希学习过程中减小语义损失,实现更准确的关联检索。此外,当遥感图像特征提取模型采用预训练的vit 时,所提方法在两种任务的各个指标上都会有更进一步的提高,模型整体性能都有进一步提升,说明了原始特征提取模块对模型效果同样有重要影响,同时也验证了本文模型的灵活性及可扩展性,可根据需要设计替换相关模块,使模型在应用时能够灵活调整。
3.3 消融实验
为了验证本文模型中各损失函数设置发挥的作用,进行消融实验对不同损失函数的有效性进行检验。我们在不同哈希码长度下都进行了模型简化实验,以充分检验所提模型的整体性能,在本文中两种数据集划分比例上的实验结果如表4 和表5 中所示,其中,“Lm+Lc”表示本文的完整方法,采用对比损失与相似度矩阵损失的加权组合(λ=0.001,μ=0.1);“Lm”表示模型仅使用相似度矩阵损失(λ=0,μ=1);“Lc”模型只采用对比损失(λ=1,μ=0)。

表4 消融实验结果(50%训练)Table 4 Ablation experiment results(50%training)
分析模型的消融实验结果可以看出,在仅使用一种损失的情况下,虽然在部分任务中的指标可以达到较好的效果,但由于部分语义信息的损失造成模型的整体性能并不理想。同样这在哈希码长度较小时表现得更为突出,而本文模型中通过相似度矩阵损失与对比损失的加权结合,使得模型在哈希学习过程中能够保留更多模态内及模态间的语义相关信息,且能够使学习的哈希特征更判别性,提高了模型整体关联检索的性能,实验验证表明本文所提方法是有效的。为更直观的对比分析模型简化实验,将表4 和表5 中的实验结果分别绘制在图3 和图4 中。

表5 消融实验结果(70%训练)Table 5 Ablation experiment results(70%training)

图3 消融实验结果(50%训练)Fig.3 Ablation experiment results(50% training)

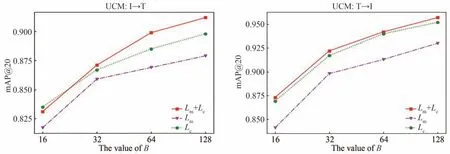
图4 消融实验结果(70%训练)Fig.4 Ablation experiment results(70% training)
3.4 参数分析实验
本小节主要对损失函数(式(8))中的两个平衡参数λ和μ进行分析,以探究不同参数设置对算法性能的影响。我们在数据集RSICD 上(50%训练)分析两个超参数对关联效果的影响,先将μ的值固定为0.1,λ的取值分别为0.1,0.01,0.001,0.000 1 时,在不同哈希码长度得到的实验结果如图5 所示,从结果可以看出当λ=0.001 时模型的效果最好。同样,将λ的值固定为0.001,μ的取值分别为1,0.1,0.01,0.001 时,在不同哈希码长度得到的实验结果如图中所示,可以看出当μ=0.1 时模型的性能达到最佳。因此,在μ=0.1 且λ=0.001 时,两种损失能够更好地结合,使得本文方法达到最优的关联效果。

图5 不同参数设置下的模型性能(mAP@20)Fig.5 Model performance under different parameter settings(mAP@20)
4 结论
本文提出了一种相似度矩阵辅助遥感图像无监督哈希跨模态关联方法,通过构建相似度矩阵损失来对齐哈希特征与原始特征的语义信息,并与对比学习方法相结合,以增强最终哈希特征的语义相关性,减小哈希码转化过程的语义信息损失。损失函数采用相似度矩阵损失与对比损失的加权和,两者的结合有效提高了无监督跨模态哈希关联的准确性,更适用于大规模跨模态遥感图像关联检索任务,而且在遥感领域的两个基准数据集上验证了所提方法的有效性。但模型原始特征提取模块的设计对各模态的语义信息丰富性考虑不够充分,相似度矩阵的计算方式相对较简单,将来工作可以作进一步改进以提高关联的准确性。