基于BP神经网络的车辆跟驰模型研究*
2023-03-01王天方刘学渊
王天方 , 刘学渊 ,2
(1.西南林业大学机械与交通学院,云南 昆明 650224;2.云南省高校高原山区机动车环保与安全重点实验室,云南 昆明 650224)
0 引言
随着人们生活水平和购买力的不断提高,每个家庭拥有一辆车似乎已经成为一种标配,因此,我国的机动车保有量每年都在大幅增加。然而,汽车在改善人们生活品质的同时,也会带来相应的交通问题和环境问题。机动车保有量的逐年增加,给有限的道路交通资源带来了极大的压力,导致交通事故频发、道路拥挤等一系列交通问题。特别是在早晚上下班这个特殊时间段,堵车已经成为一种常态化现象。除了交通问题,机动车尾气排放也对环境造成了严重的破坏,主要原因是汽车排放物是污染物的一个主要来源。《中国移动源环境管理年报(2021)》[1]显示,2020年,全国机动车四项污染物排放总量达到了1 593万t。无论是交通问题还是排放污染问题都与人们息息相关,如何应对这些问题已成为社会各界关注的焦点。
跟驰行为是城市交通中常见的车辆行驶状态,其特性对交通和环境有重要影响,所以对车辆跟驰行为的研究,对解决交通问题和排放问题具有很重要的现实意义。早在1950年,人们就开始对跟驰行为进行研究,并提出了一系列模型,如刺激-反应模型[2-3]、安全距离模型[4-5]、心理-生理学模型[6-7]等。虽然这些模型能够很好地模拟跟驰场景,但是这些模型都是建立在准确的数学公式之上,所以传统的跟驰模型在实际应用中会受到很大的限制。随着科学技术的发展,能够获取的跟驰数据更多,并且精度更高,使得数据驱动类跟驰模型[8]的研究在近年来得到了一定发展,而且很多学者都对其进行过相关的研究。例如,Zhou等[9]提出了一种基于递归神经网络的跟驰模型,该模型能够预测和捕捉交通震荡。孙倩等[10]提出了一种基于长短期记忆神经网络的跟驰模型,基于该模型进行交通仿真并研究驾驶员的记忆效应影响因素。蒋华涛等[11]将最小安全距离模型与灰色神经网络结合,提出了灰色神经网络跟驰模型,该模型能够提前预知前车未来车速和制动迹象。Hao等[12]提出了一种不包含数学分析的人工智能跟驰模型,该模型能够精准地模仿人类驾驶员。
在智能化技术高度发展的今天,将跟驰行为融入智能化辅助驾驶系统,对于减轻人们的驾驶压力并保障交通安全有重要意义。实现这一过程需要准确的数学模型来支撑,但是,在实际驾驶过程中驾驶员受到的影响因素并不唯一,如驾驶员经常会同时受到交通信号、其他车辆和行人的影响。对于这种比较复杂的情况,不能用单一的数学模型进行建模,要使用人工神经网络等方法来描述。因此,课题组以实际采集的实验数据为基础,建立BP神经网络跟驰模型。
1 实验过程与数据采集
在本次实验过程中,使用两台实验车辆,一辆作为前导车,一辆作为跟驰车,在前、后车辆上都安装全球定位系统(Global Positioning System, GPS),然后通过实验设备获取实际道路车辆的跟驰行为数据。实验道路为昆明市的北京路。选择的实验路段为主干道,整体车流量较大,在实验过程中,为了保证跟驰的真实性,驾驶员将会按照自己在日常生活中的驾驶习惯正常驾驶实验车辆。跟驰行为数据主要由GPS获取,GPS可以获取车辆速度、经纬度、海拔等数据。
2 建立跟驰模型
以实际跟驰行为数据为基础,选取一个典型且连续的跟车过程,运用BP神经网络构建跟驰模型。在进行BP神经网络的设计时,首先需要一个样本训练数据集,然后确定模型的输入输出参数。将实际道路采集到的跟驰行为数据作为训练样本,然后根据获取的数据提取前车车速V1(km/h)、相对距离Rs(m)、前车对后车的相对速度RV(km/h)和后车车速V2(km/h)作为输入,后车下一时刻的速度V(t+1)(km/h)作为输出。输入、输出确定之后,需要从以下几个方面对神经网络结构进行设计。
2.1 网络层数
BP神经网络的层数设计可以根据自己的需求而定,一般单层的网络就可以满足大部分的应用,因为只需要增加神经元节的个数就可以完成任意的非线性映射。但是,样本的数量较多时,可以选择增加一个隐含层,能够减少网络规模并提高输出精度。所以,本文将建立双隐含层的BP神经网络跟驰模型。
2.2 输入和输出层节点数
对于BP神经网络而言,输入层神经元节点数一般为输入参数的个数,因为本文选择的输入参数有4个,所以输入层的神经元个数为4。输出层节点数和输入层类似,根据输出参数个数确定,因此输出层的神经元个数为1。
2.3 隐含层节点数
隐含层节点数一般是根据试凑法得出选取范围,然后根据训练时不同神经元对模型的影响,选出最佳个数。确定神经元个数的主要公式如下:
式中:n为输入层神经元个数,m为输出层神经元个数,M为隐含层神经元个数,a为[0,10]之间的常数。公式(1)是比较常用的经验公式,第一隐含层根据试凑法确定神经元个数为6;第二隐含层神经元个数等于输出节点数时,模型的预测效果较好[13],因此第二隐含层神经元个数设置为1。BP神经网络跟驰模型的结构为4-6-1-1。
2.4 传递函数和学习算法
BP神经网络的传递函数可以使用线性函数或Sigmoid函数,文中隐含层的传递函数选择Sigmoid函数,输出层选择线性函数,因为如果输出层选用Sigmoid函数会限制输出数值的范围。
标准的BP网络使用的学习算法是最速下降法,也称为梯度下降法,采用最速下降法对网络的权值进行调整的过程,是一个沿着网络逐层反向调整的过程,具体为先对输出层和隐含层的权值进行调整,然后再对隐含层与输入层之间的权值进行调整。在实际使用最速下降法训练的过程中,会存在收敛速度慢的问题,针对最速下降法的这个缺点,提出了LM(Levenberg Marquardt)算法。LM算法是在最速下降法的基础上改进而来的,同时具有拟牛顿法的局部收敛特性和最速下降法全局特性,因此在本次建模过程中,选用LM算法作为学习算法。LM算法调整网络权值的公式为:
式中,J是雅克比矩阵,I是单位矩阵,μ是比例系数,且μ>0。
在确定了上述参数之后,将需要训练的数据进行归一化处理,然后输入模型中进行学习和训练。
3 跟驰模型的优化
利用遗传算法(Genetic Algorithm, GA)来优化BP神经网络,即优化神经的初始权值和阈值,可以避免BP神经网络在训练时容易陷入局部最优的缺点,同时提高网络对样本的预测能力。许多研究者都使用了遗传算法优化BP神经网络,如郭艳君等[14]利用遗传算法优化BP神经网络跟车模型,表明GA在优化神经的初始权值和阈值方面有较好的效果;王志红等[15]利用GA优化BP神经网络排放预测模型,也取得了较好的预测效果。GA的具体操作步骤如下。
1)初始化种群[16],种群规模为40。采用浮点编码对个体进行编码,因为浮点编码能够解决二进制编码中编码串过长的问题,计算得到编码长度为38,计算公式如下:
式中,n为输入层神经元个数,m为输出层神经元个数,M1和M2分别为第一、第二隐含层神经元个数。
2)适应度函数。适应度函数表示预测输出与期望输出之间的误差绝对值,公式如下:
式中,yi为i节点的期望输出,xi为i节点的预测输出,n1为节点数,a为系数。
3)选择操作。本文使用经典的轮盘赌法,根据个体适应度大小,对个体进行选择操作,每一个个体被选择的概率计算公式如下:
式中,fi为个体i的适应度值,m1为种群中个体总数。
4)交叉。从选择好的个体中对其进行基因互换,即交叉操作,产生下一代。交叉概率控制着个体之间发生交叉概率的大小。一般交叉概率为0.4~1,本文设定的交叉概率为0.8。
5)变异。对交叉之后的个体以一定的概率使其发生变异,从而产生新的个体。其中,变异概率决定变异发生的可能性,变异概率一般为0.001~0.1。本文设定的变异概率为0.02。
6)当算法运行结果达到最大的精度要求或者最大的迭代次数时,结束遗传算法操作过程,然后需要把优化好的权值和阈值带入BP神经网络进行训练[17]。
4 模型结果分析
4.1 评价指标
以标准均方根误差(NRMSE),平均绝对百分误差(MAPE)和决定系数(R2)作为评价指标。NRMSE反映了模型输出值与实际值之间的差异性;MAPE是衡量预测模型精度的一个重要指标;R2代表模型的非线性拟合性和预测精度。计算公式如下:
式中,yi表示实验值,表示模型输出值,表示实验值的平均值,N为测试集样本数量。
4.2 模型结果
将从实验中采集到的数据分别输入到上述建立的BP神经网络和遗传算法优化后的BP神经网络跟驰模型中进行训练和预测,结果分别如图1和图2所示。

图1 BP神经网络模型
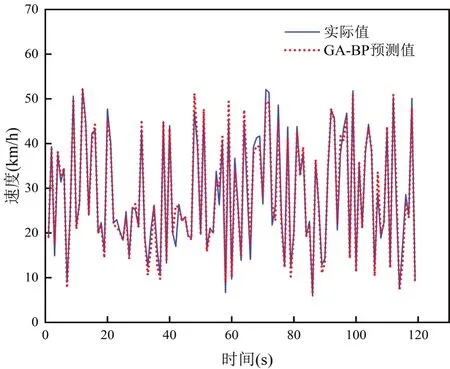
图2 GA-BP神经网络模型
从图1和图2中可以看到,BP神经网络模型和GA-BP神经网络模型的预测值基本都能捕获实际值的变化趋势,虽然在图中可以发现极值点部分预测可能相对较差,但是整体趋势预测依然准确。对比BP神经网络模型和GA-BP神经网络模型,从图中可以明显看到GA-BP神经网络模型具有更好的预测性能,预测值与实际值的误差也相对较小。由此可见,利用遗传算法对BP神经网络的权值和阈值进行优化,能够使模型达到更好的预测效果[18-19]。
为了进一步分析模型预测偏差,根据模型预测的结果计算模型性能的评价指标值,具体结果如表1所示。从表中可以看到GA-BP神经网络的评价指标NRMSE、MAPE和R2都优于BP神经网络模型,具体为NRMSE和MAPE分别降低了20.83%、37.83%,R2提高了3.16%,表明GA优化了BP神经网络的效果。

表1 模型性能评价指标
4.3 模型误差分析
为了对模型的预测偏差进行分析,把实际值减预测值定义为模型的误差。在实验中,用实际值减去BP神经网络模型和GA-BP神经网络模型的预测值,结果如图3所示。
从图3中可以看到,GA-BP神经网络模型相比BP神经网络模型,误差更加集中分布在零误差线左右,偏移相对较小。由此可知,建立的GA-BP神经网络模型比BP神经网络模型拥有更好的泛化能力和预测性能,能较好地对跟驰行为进行预测。
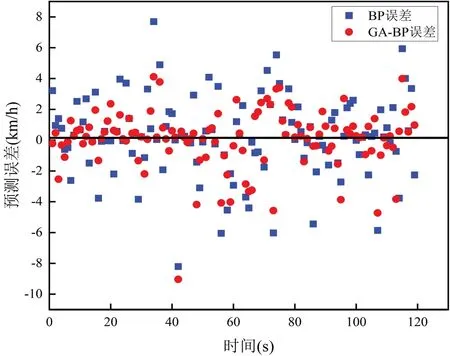
图3 预测误差对比
5 总结
课题组以真车实验采集到的数据为基础,先使用BP神经网络构建跟驰模型,然后再使用GA对BP神经网络跟驰模型进行优化,结果表明,构建的GA-BP神经网络模型性能的评价指标、预测误差都要优于BP神经网络跟驰模型。所以,利用GA优化BP神经网络模型,能够有效地提高BP神经网络跟驰模型预测结果的准确率。
