基于车辆信息的大数据分析系统设计与实现
2023-02-17张积存宋雪萍费继友
张积存 宋雪萍 费继友 王 凯
1(大连交通大学机械工程学院 辽宁 大连 116028) 2(东软集团(大连)有限公司 辽宁 大连 116085)
0 引 言
近年来,我国在公共安全信息化建设方面的投入飞速增长,其中视频监控系统是一个主要的发展方向。对视频的监控、追踪已经成为各级公安部门主要的破案手段。随着城市部署的车辆卡口点位越来越多,卡口数量增加,各地公安机关已经拥有大量的车辆卡口数据和视频图像资源[1-2]。以北京市为例,全市每日通过交通卡口采集的过车数据都达到千万级别的数据量。但是越来越多的视频资源带来帮助的同时,也给存储和分析造成巨大困难。
如何充分利用这些资源,结合现代化信息技术,为情报、刑侦、治安等不同警种服务,已经成为公安机关信息化建设的主要需求。然而目前已有的基于车辆的大数据分析系统[3-5]大同小异,多是基于对数据的查询,存在着分析数据种类单一、分析时间滞后、系统使用率低等问题。这类系统仅解决了“有”的问题,而不能满足“精”的需求。
为使车辆数据得到更充分的应用,分析更全面、更准确、更及时,以满足公安机关日益精进的信息化建设需求,本文在已经完成的视频结构化平台的基础上,设计并实现车辆大数据分析系统。本系统以平台提供的结构化数据为数据源,结合公安网中大量车辆信息、业务数据和图像数据,使用Kafka消息队列、Elasticsearch分布式引擎、Redis内存数据库和大量的模型算法,实现了海量数据的实时传输、存储、检索和分析,提供丰富的业务实战应用。
1 系统设计
1.1 系统架构设计
车辆大数据分析系统基于视频结构化平台,共包括采集层、存储层、服务层和应用层,并考虑安全保障体系和标准规范体系。系统软件架构设计如图1所示。

图1 系统软件架构设计视图
(1) 应用层。基于Vue.js框架开发的Web平台,针对不同警种的需求提供相关的应用功能。平台的应用功能包含智能检索、异常排查、一车一档、布控告警、统计分析和17种技战法(包括异常停留、快速离城、区域徘徊、遮挡面部、昼伏夜出、频繁夜出、频繁过车、首次入城、首次出现、重点车辆分析、无牌车、套牌车、隐匿车辆挖掘、时空碰撞、同行车[6]、落脚点、相似车牌串并)。
(2) 服务层。服务层包括模型算法服务、应用服务、Elasticsearch实时全文检索服务。基于存储层的数据,为上层应用提供算法分析、模型训练、智能检索等服务。包括:算法集、模型库、分布式计算中心和分布式数据检索引擎。
(3) 数据资源层。基于ES(Elasticsearch)分布式搜索引擎平台,对海量过车数据进行存储,为数据分析提供支撑。Redis内存数据库保证算法集群获取数据的实时性。业务库采用MySQL数据库,存储各业务功能相关数据。
(4) 采集层。使用视频结构化平台提供的标准化数据对接接口,从各类平台采集海量的卡口数据,并使用Kafka作为消息总线进行数据的实时传输。
1.2 系统逻辑处理设计
车辆大数据分析系统在实际工作中,依托于视频结构化平台采集接口提供的结构化数据,数据进入卡口监视消息总线后,一方面供给ES(Elasticsearch)检索引擎,满足前端的实时检索;另一方面存入Redis内存数据库,并与人员专题库数据、车驾管数据一起提供给模型算法模块,由算法模块实现自动化标签、一车一档、布控告警等功能供前端调用。系统逻辑结构图如图2所示。
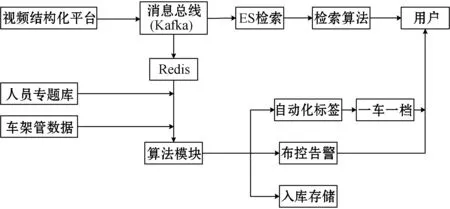
图2 系统逻辑处理结构视图
1.3 系统部署运行
(1) 系统部署:各模块均采用集群部署,随着业务规模扩展,数据接入增多,各服务节点也可以平滑横向扩展,保证服务的高可用性。在测试环境下,可处理日均400万的过车数据。系统部署运行如图3所示。系统部署配置情况如表1所示。
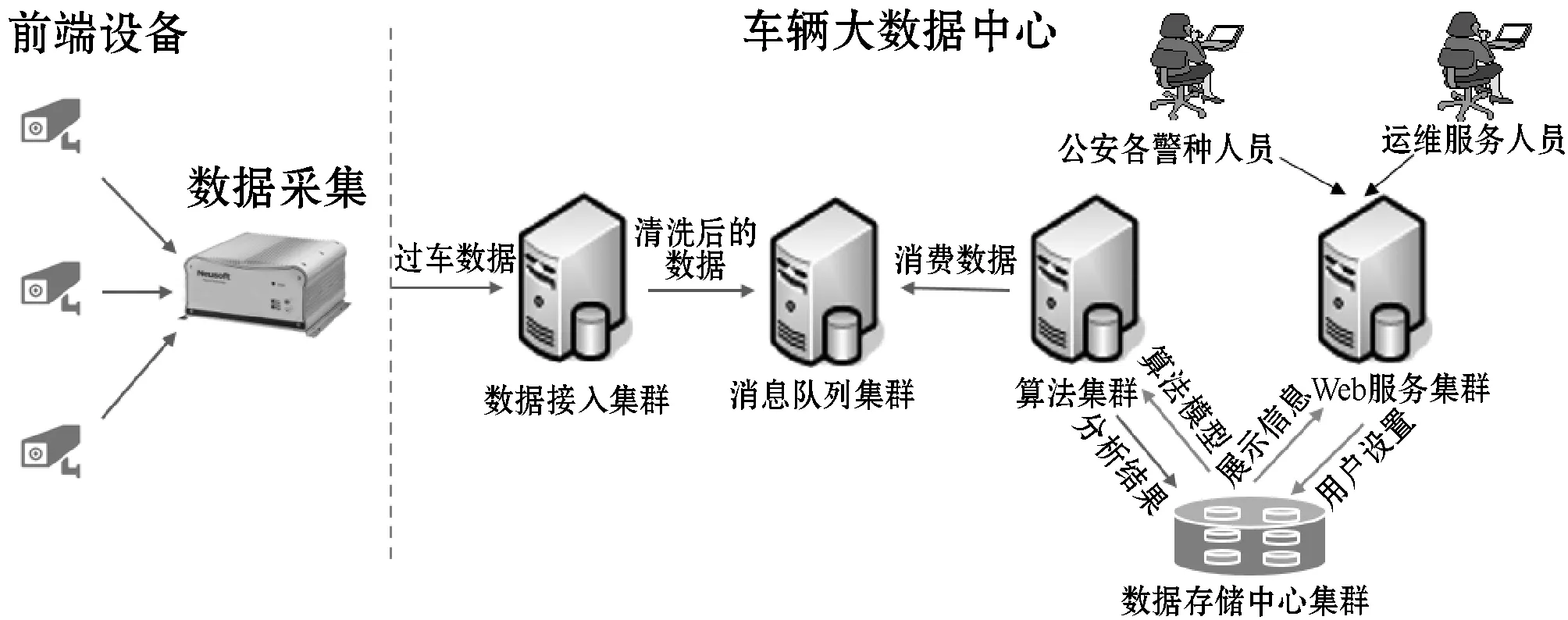
图3 系统部署运行图

表1 系统部署配置
(2) 通信传输:前后端基于HTTP协议进行消息通信,后端的数据传输基于Kafka消息队列。
(3) 存储:原始过车数据索引到Elasticsearch中,分析结果存储到MySQL中,过车数据经预处理后,缓存到Redis中,以备算法可以快速读取。
(4) 灾备:数据存储采用主从模式,集群部署,即使部分服务宕机,也可保证数据正常存储。Elasticsearch中的数据会自动创建副本,即使部分节点宕机,也可保证数据的完整性。系统定期将数据备份到数据中心,使用RAID5硬盘存储,保证数据可恢复。
(5) 系统运行:系统算法由数据采集事件驱动,使用实时消息队列进行数据传输,高性能内存数据库Redis进行数据缓存,算法基于缓存的数据进行分布式运算,从而保证计算结果的准实时性。
2 关键技术及系统实现
2.1 关键技术
2.1.1Kafka消息队列
Kafka是一种高吞吐量的分布式发布/订阅消息系统。即使非常普通的硬件Kafka也可以支持每秒数百万的消息吞吐量。
本文利用Kafka分布式消息队列技术[7-10]处理海量请求,支持高吞吐量的消息发布和订阅。利用Kafka集群作为系统的消息总线,当采集接口、其他平台订阅等多种生产者产生数据时,Kafka集群将消息发布给ES引擎和算法等多个消费者模块,从而实现海量数据的实时传输,图4为Kafka消息总线的结构图。

图4 Kafka消息总线示意图
2.1.2Elasticsearch分布式搜索引擎
本文通过搭建ES(Elasticsearch)分布式搜索引
擎来实现海量数据的实时存储及检索。ES是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便地使大量数据具有搜索、分析和探索的能力。它可以近乎实时地存储、检索数据,而且具有良好的扩展性,可以扩展到上百台服务器,处理PB级别的数据[11-15]。
ES的实现原理主要分为以下几个步骤:
(1) 首先用户将数据提交到Elasticsearch数据库中。
(2) 通过分词控制器将对应的语句分词,将其权重和分词结果一并存入数据。
(3) 当用户搜索数据时候,根据权重将结果排名、打分,再将返回结果呈现给用户。
2.1.3数据实时分析
Redis是一个开源的,内存中的数据结构存储系统。它可以用作数据库、缓存和消息中间件,支持多种类型的数据结构(如字符串、散列、列表、集合、有序集合)与范围查询。为了保证效率,Redis的数据保存在内存中,并且支持一定的持久化功能,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用,这保证了高并发场景下数据的安全性和一致性。其性能极高,读的速度可以达到110 000次/s,写的速度可达81 000次/s。并且支持集群、分布式、主从同步等配置,原则上可以无限扩展,让更多的数据存储在内存中。
本文使用Kafka消息队列作为消息总线保证数据实时传输,利用Redis的超高性能保证数据实时读写。
当新增数据产生时,一方面发布到ES引擎进行存储,另一方面发布到Redis内存数据库,供给模型算法模块进行实时分析。系统的算法模块包含十余种业务相关的算法模型:异常停留、套牌车、同行车、落脚点、区域徘徊、时空碰撞等。这些算法模型服务分布式运行在两台配置为CPU:E5-2630 V4×2;内存:16 GB DDR4×2的机器上。Redis的高性能读写能力允许各算法模型同时读取数据,通过运行各类算法实时地为车辆数据标记各类异常行为标签,同时将标签化的数据存储在MySQL数据库中作为模型中间库以供查询检索使用。实时分析流程如图5所示,系统7×24小时不间断地对产生的每条过车记录进行实时算法分析,生成实时的车辆异常行为数据标签,对每一辆通过交通卡口的车辆都动态建立档案,用于大数据分析碰撞。系统根据车辆异常行为标签以及异常行为出现的频率,会自动进行预警,并将预警信息推荐给Web平台。平台使用者能在第一时间发现有异常行为的车辆,从而提前采取布控等措施,极大地提高事前预判、预防、预警能力。
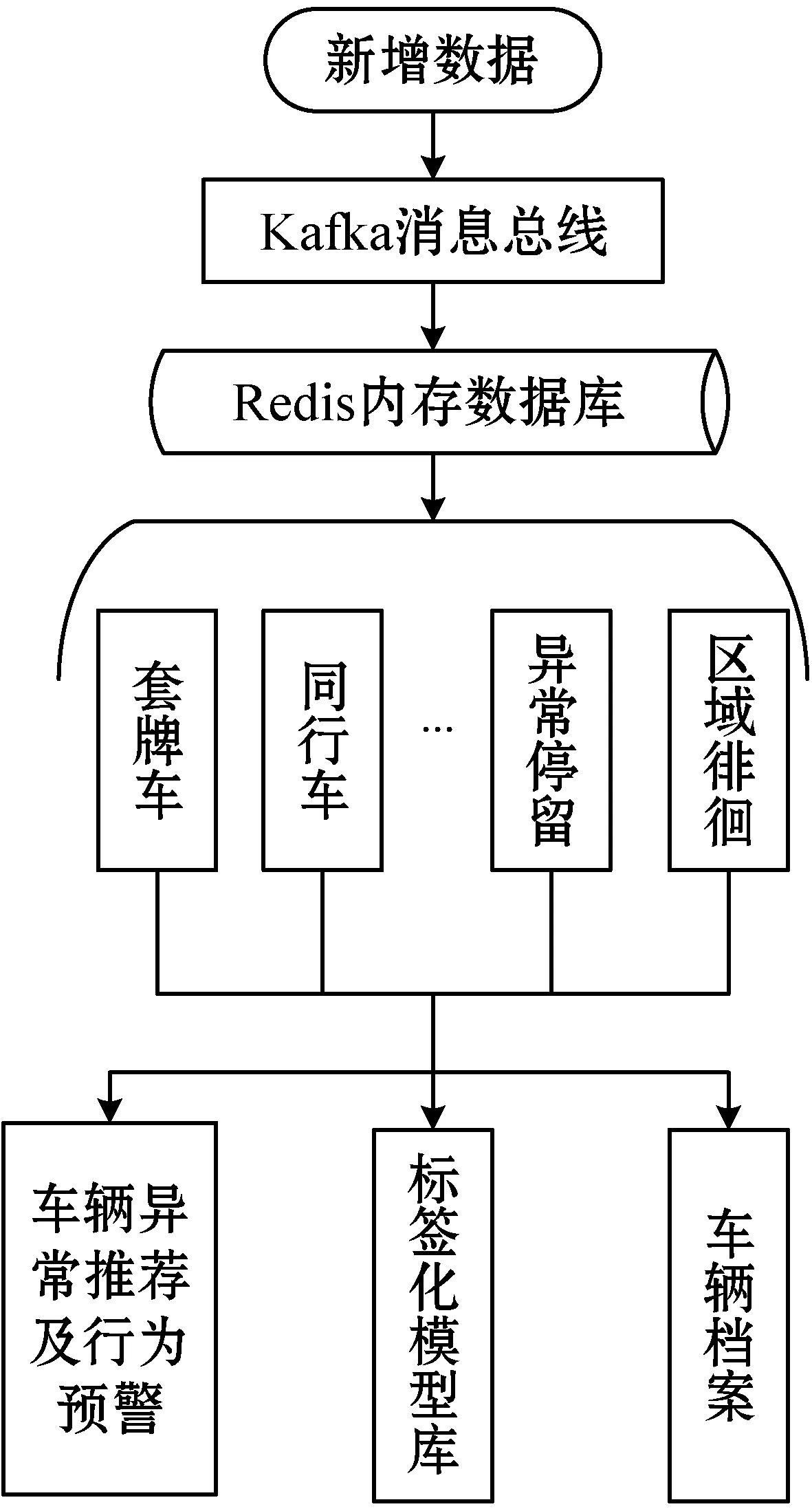
图5 实时分析流程
2.1.4数据融合分析
系统提供接口对接、人工录入、批量导入等多种形式,将其他与车辆关联的数据(车驾管、人员专题库数据、盗抢车辆等)融入到车辆研判算法中,为车辆研判提供更多的有价值的线索,提升数据价值,提高办案效率。图6是车辆布控告警流程,系统通过融合车架管数据,获取到车辆车牌号码信息,从而达到以人找车,进行布控告警的目的。图7是完整轨迹的数据融合分析流程图。通过融合人脸识别数据、酒店住宿数据、出行数据等,再结合交通卡口的车辆信息,就能够刻画出布控目标完整的人车轨迹,用于案件的深度大数据研判分析,提高侦破率。

图6 布控告警流程

图7 完整轨迹流程
2.2 系统实现
根据数据性质的不同,分别采用MySQL、Redis、Elasticsearch三种不同的数据库来进行数据存储和管理。数据库实现如图8所示,三种数据库特性比较如表2所示。

图8 数据库实现框图

表2 数据库特性对比表
(1) 应用层的用户、角色、权限管理、字典表管理以及算法结果使用Mysql进行存储。
(2) 过车数据的预处理结果,用于算法的实时计算,采用内存数据库Redis进行缓存。
(3) 离线算法需要实现对机动车过车记录的高性能搜索,可支持查询、统计、聚合,所以选择当前主流的Elasticsearch存储机动车过车记录。
服务层采用java语言开发,系统为Windows系统。应用层为基于Vue.js框架的Web平台。图9为系统主界面,共包含各统计分析,智能检索、车辆追踪、异常排查等的功能入口按钮。图10为技战法分类界面,共包含17中技战法。图11-图13为部分功能界面运行效果。
图9 系统首页
图10 技战法界面

图11 车辆档案

图12 技战法—区域徘徊

图13 车辆追踪
3 系统测试
本文使用北京某区域交通卡口三个月过车数据进行系统功能测试及性能测试。测试数据量大于一亿条。
3.1 系统功能测试
系统功能测试主要是利用Cypress E2E(end to end) Web 测试框架通过对应用层Web平台进行UI自动化测试并保存每次服务端的返回结果生成txt文件进行业务验证,以检测系统各功能是否实现以及运行效果。表3为Web模块各项功能列表。

表3 Web模块各项功能
系统进行了6次全功能测试及10余次随机UI测试。整个测试过程未发现崩溃性和严重性错误,并且生成的结果文件通过业务验证满足业务需求,可以证明系统在功能上满足用户需求。
3.2 系统性能测试
(1) 典型业务场景测试。使用三辆已知号牌的车辆作为测试的目标车辆,按照规划的测试路线行驶,形成伴随关系,并按计划进行停留,通过不同的卡口位置,共历时7天。结合3个月时间采集到的约1亿2千万条卡口实际过车数据进行共30余项业务场景测试。以智能检索、同行车、落脚点、布控告警为例说明测试结果。
① 智能检索:根据起止时间、车牌号、车牌颜色、车辆类型、车型车款、车身颜色、车内饰品、是否系安全带等条件进行车辆检索,达到快速捕捉目标车辆的目的。测试以三辆已知号牌车辆为目标车辆,自由组合各项检索条件进行多次测试。
测试结果表明:从开始分析到结果显示平均耗时约为55 ms,并准确找到测试目标车辆。
② 同行车:融合FP-groupth算法以及车辆轨迹对比分析算法进行同行车、伴随车挖掘与分析。测试分别以其中一辆已知号牌车辆为目标车辆,分析并找出其同行车。
测试结果表明:从开始分析到结果显示平均耗时约为430 ms,并准确找到同行的测试车。
③ 落脚点:以起止时间、车牌号、车牌颜色为条件(不同车牌类型存在有相同车牌号的情况,如绿牌车和蓝牌车可以有相同车牌号),使用改进的Optics聚类算法进行目标车辆的落脚点挖掘。以三辆已知号牌车辆为目标车辆进行测试。
测试结果表明:从开始分析到结果显示平均耗时约为245 ms,并准确找到目标车辆的落脚点。
④ 布控告警:以一辆测试车辆为目标车辆,模拟布控告警实时测试。系统显示布控车辆已有的过车记录,刻画行车轨迹。当布控目标车的过车数据再次被系统检测到时,进行报警并显示目标车的位置。
测试结果表明:从过车数据采集入库到推送给UI响应,数据平均延迟时间约为550 ms,符合布控告警对实时性的要求。
(2) 大数据下的系统性能测试。系统性能测试是在进行UI自动化测试的同时,监控系统各模块的响应时间;在产生新数据时,监控各算法模型的计算时间来验证系统各模块性能。表4为UI测试时系统各模块的平均响应时间。表5为新增数据时各模块平均响应时间。

表4 UI测试各模块平均响应时间 单位:ms

表5 新增数据时各模块平均响应时间
测试结果表明,本系统在车辆数据达亿级时,各功能的响应时间均在秒级。在新增数据达到每秒2 000条,即每天新增1.728亿条车辆数据时(目前一般除特大型城市外,一个大中型城市,每天卡口车辆数据在千万条级别,测试数据已超过一个城市每日实际产生的卡口车辆数据),各模块的传输、存储和运算时间也都达到秒级响应。性能上近乎可以做到实时分析和实时查询,能够满足当前用户的需求。将来随着城市车辆保有量的增加以及车辆卡口采集点位的不断建设,每日新增的数据量也将持续增加,可以考虑通过硬件扩容的方式,增加Kafka和ES节点,通过集群部署的方式,提升系统的负载能力,从而满足系统实时性的使用要求。
4 结 语
本文设计开发了基于车辆信息的大数据分析系统。相比于已有的相关大数据系统[16-18],本系统具有时效性高、实用性强、推荐结果精准、分析全面等优点。总结归纳为以下三个方面:
(1) 分析手段:区别于现有的大数据系统主要基于规则查询的手段,本系统建立了大量业务相关的模型库,算法库用以分析、挖掘数据价值。
(2) 时效性:相比于现有的大数据系统多是事后查询分析,本系统可以进行实时分析,做到事先预警、及时布控。
(3) 实用性:相比单纯的过车数据,本文结合人员专题库数据进行融合分析,人车一体,分析更全面。
目前本系统已经在北京、甘肃等多地正式投入使用。使庞大的过车数据得到充分利用,为公安机关布控预警、异常排查、重点车辆管控等工作提供更全面、更准确、更智能的应用服务。
