面向多源异构丝路文化遗产数据的智能挖掘方法
2023-02-14杨寒淋周娅鹃安薇竹翁正秋宁灵舰
杨寒淋, 周娅鹃, 赵 丰, 徐 蓉, 安薇竹, 翁正秋, 宁灵舰, 金 宇
(1.中国丝绸博物馆 国际交流部,杭州 310002; 2.温州职业技术学院 人工智能学院,浙江 温州 325006;3.浙江理工大学 纺织科学与工程(国际丝绸学院),杭州 310018; 4.同方知网(北京)技术有限公司 浙江分公司,杭州 310018)
丝绸是丝绸之路的原动力,在跨文化传播中发挥着重要作用;丝绸之路是沟通中国与世界其他地区的交通路线,为世界文明的发展做出了巨大贡献。广义上的丝绸之路东达韩国、日本,西至地中海各国,通过海路途径柬埔寨、泰国,连通意大利、埃及等国家。2019年,在第二届“一带一路”国际合作高峰论坛上,习近平总书记提出要积极架设不同文明互学互鉴的桥梁,深入开展各领域人文合作,形成多元互动的人文交流格局。鉴于此,深入研究丝路文化遗产,弘扬丝路文化精神,能够更好地促进各国各地的文化、政治和经济交流。然而,现有丝路文化遗产呈现多源异构特征——地域广泛化、语言多元化、成果多样化,在互联网上表现为数据大量膨胀、分布极为零散、语言繁杂多样,使得当前文博领域利用传统的研究技术手段无法适应海量丝路文化遗产数据的智能研究,故利用人工智能手段挖掘丝路文化遗产愈发重要。总体而言,要对丝路文化遗产数据进行全面细致的统计和分析,面临着如下挑战:
1) 数据采集。需要采集的丝路文化遗产数据往往有不同的来源和模态,各数据之间的语言组成、平台架构、文档结构等因素,导致数据的格式差别巨大,呈现多源异构的特性,对数据采集效率和覆盖率都是极大的挑战。
2) 信息挖掘。在多源异构的复杂数据中,对爬取到的文本内容手动进行文章的语义提取与分类是不切实际的,需要智能化地进行自动标引、提取文摘与文本分类。
3) 数据清洗。由于挖掘得到的数据中含有大量相似的成分,冗余的信息会使得提取数据分析的精度和效率大幅降低。此外,部分文本内容仅提到了丝路,实质内容却与丝路无关,使得该部分信息作为噪声去除时极为困难。
针对上述挑战,本文提出面向多源异构丝路文化遗产数据的智能挖掘技术。首先,构建高覆盖率与高效的数据采集系统。其次,设计针对多源异构丝路文化遗产数据的自动标引、自动文摘与数据分类方法。然后,采用多维度融合聚类的数据清洗方法去除冗余和噪声数据。最后,整合所提出的关键技术形成《丝绸之路文化遗产年报》并进行开源发布(https://github.com/CarolineYeung/SilkRoadReport/)。本成果旨在向公众宣扬丝路文化遗产价值,激发大众对丝绸之路的关注度和兴趣,唤醒全社会对文化遗产的保护理念与意识,并有望为多源异构丝路文化遗产数据的智能挖掘提供理论与技术支撑。
1 信息的获取
对于丝路文化遗产数据有效信息的获取,现有的采集策略可分为以下3种:人工采集、文博机构提供和基于互联网的大数据信息采集。
人工采集是有目的地对相关领域信息进行手动查询,并从中获得参考数据和研究数据的方式。丝路文化遗产信息根据存储形态,可分为数字化信息与非数字化信息。对于可检索的数字化信息,一般会从搜索主题词、关键词入手,按照研究问题的操作化指标对收集到的相关信息进行人工录入标注、摘录,并建立表格进行数据管理。对于非数字化的信息,采集者首先从相关领域资料入手,利用滚雪球的方法,逐步积累、深化和细化。龙博等[1]结合历史文献人工调研和民间调查对多综提花装置的发展过程、提花原理和社会地位进行了综合详尽的分析。张晓斌等[2]利用互联网手动提取广东海上丝绸之路的时间架构,并在文化层面对广东海上丝绸之路的整体价值做出评估。程金城等[3]人工采集并分析“基质”“斑块”和“廊道”等景观生态学的数据,对丝路文化遗产中文学要素进行再发现。刘运娟等[4]采用人工田野调查法和传世实物分析法对泉州金苍绣进行了研究,为增强海上丝绸之路沿线国家的文化认同感做出了贡献。虽然人工采集数据在一定程度上可以获取到丝路文化遗产数据,但它只能获取极其有限的信息数量,其信息有效性和专业性仍有待考证,并且会耗费大量时间。在当今互联网信息的时代下,人工采集的方式或许过于保守,且缺乏数据信息的完整性与多样性。
文博机构提供相关信息资源是获取丝路文化遗产数据的另一种渠道,博物馆、图书馆、科研所、研究中心等机构通过建立合作交流平台[5-8]的方式提供领域相关数据,由研究人员对这些数据进行梳理与整合[9-12]。于凤静等[9]联合博物馆和研究中心,探索中国海洋文化理念里的中国传统文化精髓,实现与丝路精神的相契相合。马建春等[10]通过与文博机构的合作,建设相应的文化创新区与数据库,挖掘海上丝绸之路历史资源,梳理文化遗产。吴娅妮[11]是在丝绸之路背景下,探索图文传播与雕版印刷之间的关系及对社会文化发展起到的推动作用,其中引用了诸多博物馆中的记载文献。柴冬冬[12]则是列举相关文博领域中的文献资料,通过文化间性的置入,探究丝路文化在时间和空间的多维认同度。相较于传统人工采集的模式,上述方法能更加有效地获取专业信息。然而,此类多渠道多途径汇总的原始数据量庞大,并且有较高的重复率,增加了后续分析的困难度。此外,特定文博机构提供的丝路文化遗产数据在广度与深度上也有局限,不能保证覆盖所有的信息。
尽管人工采集与相关文博机构提供的方式对数据获取有所帮助,但无法确保其完整性和有效性,故亟须利用大数据技术从多源异构数据中提取关键信息。然而,目前的相关工作仅利用大数据技术来进行丝绸文化变迁的相关研究,缺少对自动高效获取准确丝路文化遗产数据方面的探讨。例如,王镜等[13]研究了丝绸之路与重游意愿影响关系,通过大数据查询来获取旅游地区历年游客数量,并将其设置为调节变量进行分析。海波[14]则是以丝绸之路为视阈,研究河西走廊附近的佛教文化,其中应用到了基于互联网的数据采集技术。若要全面采集并分析丝路文化遗产领域的专业资讯信息,需要结合数据挖掘技术,主动发掘相似数据之间的内在联系,并做出快速精准的响应。本文利用数据挖掘技术对丝路文化遗产数据进行自动化搜索和采集,并对其进行分类、排重、去噪等挖掘处理,确保数据采集的完整性和数据分析的高效性。
2 研究方法
2.1 方法概述
本文提出的研究方法有别于文化领域的传统研究方法。它通过数据采集、数据整理方面具体技术的应用,实现更全面的数据研究;同时依靠大数据智能分析技术,实现对过去一年丝路文化遗产数据的统计和多维度分析。流程主要分为3部分:数据采集、信息挖掘分析,以及数据清洗与数据审核,如图1所示。
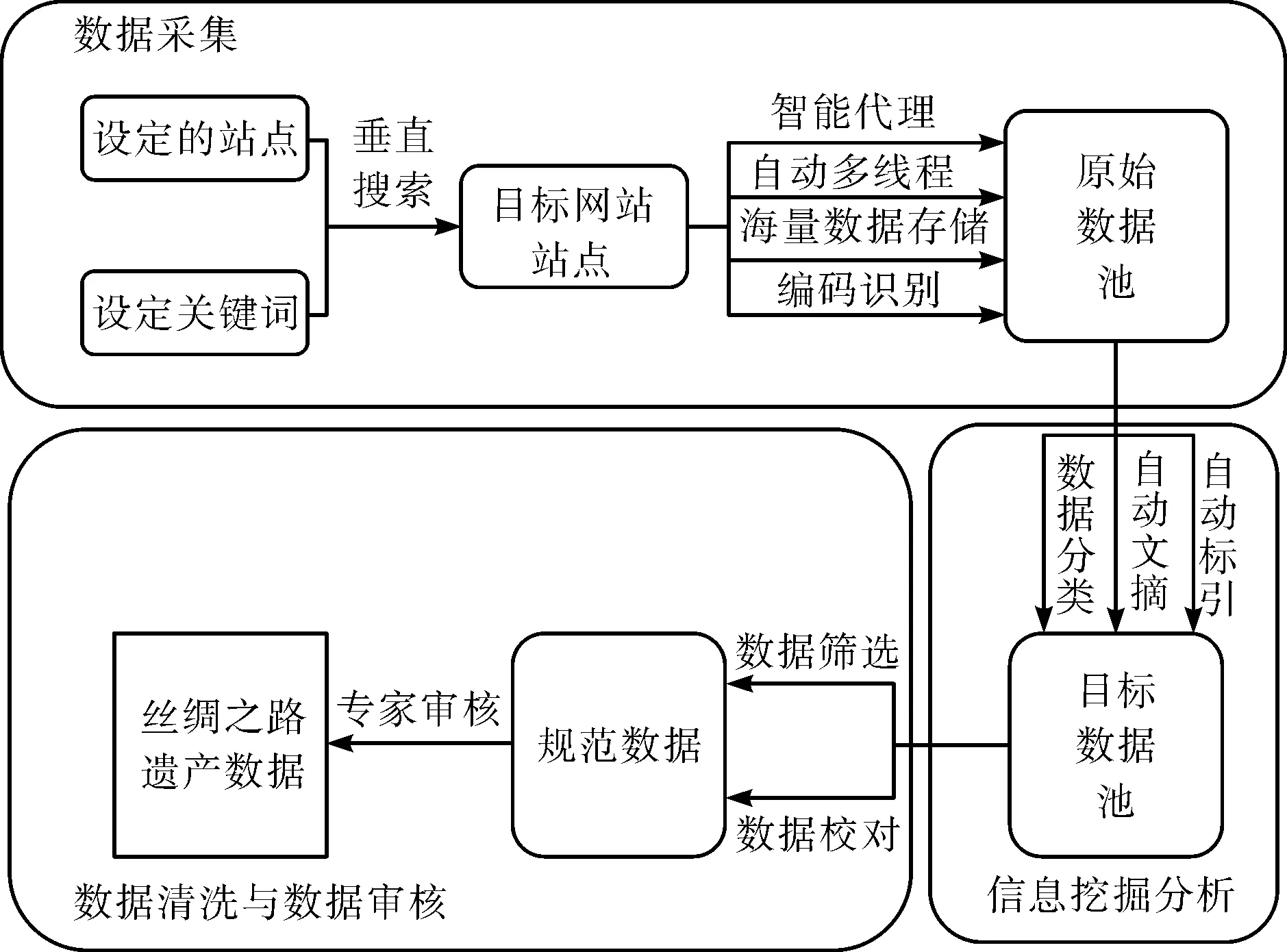
图1 面向多源异构丝路文化遗产数据的智能挖掘技术流程Fig.1 Intelligent mining technology process for multi-source heterogeneous Silk Roads cultural heritage data
2.2 数据采集
在数据采集方面,本文提出一个集网络数据采集、分析、存储、管理功能于一体的网络信息资源整合系统——垂直搜索引擎系统。通过预先设定的站点及可变的关键词进行定向数据采集,目的是收集网络上分散的ppt、word、pdf等各类形式的文档。利用垂直搜索引擎对各种文献、资讯进行阅读,并理解其基本涵义,然后进行核心知识点摘取,保存为统一格式的摘要数据后转存至数据库中,其过程共包含以下4个步骤。
2.2.1 智能代理系统建设
本文采用集成多种智能信息处理算法,基于先进的语义规则技术进行浅层语义分析,从信息海洋中准确、及时地筛选出研究者所需的信息,并自动分类;运用自定义分类体系,为研究者提供多种方式定制所需的主题。
2.2.2 自动多线程高效采集
为了快速、全面、准确地从Internet及专业数据库中获取数据,本文对所有脚本进行多线程并行采集,实时动态监控特定目标,灵活定制采集策略,确保信息全面采集。对于采集规模较大的时间段,采用集群式蜘蛛[15]来抓取,确保抓取速度。同时为了实现各个模块的解耦合、子模块的独立性,在本系统中使用了蜘蛛集群与智能代理集群,同时对服务器进行智能调度,从而子系统可以随时断开与连接,且不会影响到整个系统运行。
2.2.3 海量数据存储和全文检索
建设支持海量非结构化数据存储管理的系统,以及成熟的全文检索技术。与此同时,运用智能相似检索系统,以百万级文献量毫秒级响应速度实施数据检索工作。
2.2.4 主流中文编码识别和跨国语言支持
对主流中文编码进行精准识别,系统在不同编码之间自动转换,持续运行;同时支持中文、英文、俄文、法文、日文5国语言。由应用服务器、蜘蛛、智能代理、转存器、发布系统、规则编辑器、图片Web服务器组成的7个分布式子系统,能够同时各自独立运行数据处理工作。
2.3 信息挖掘分析
2.3.1 自动标引
利用词频-逆向文件频率(TF-IDF)[16]从文本中自动抽取能够高度有效表达文本主题和内容的词汇。主要过程如下:1) 统计分析文本标题、摘要、正文等部分;2) 对照禁用词表或者统计的词分布规律表,删除高频的语法功能词和低频词汇;3) 对保留候选词汇进行加工,英文词汇要去掉后缀(或前缀),将每个词还原到其词根;4) 利用TF-IDF计算候选词汇的权重;5) 选择权值大于特定阈值的词作为标引的关键词。
2.3.2 自动文摘
根据目前国际前沿的自然语言处理思想,通常将词的线性序列组成句子,将句子的线性序列组成文本。其中具体流程分4个步骤进行:1) 计算词的权值;2) 计算句子的权值;3) 对所有句子按权值高低降序排列,权值最高的若干句子被确定为文摘句;4) 将文摘句按照它们在原文中的出现顺序输出。计算权值的依据是文本的6种特征:词频、标题、位置、句法结构、线索词和指示词短语。
2.3.3 数据分类
数据分类的关键在于在向量空间中找到一个具有最大边界的决策平面,这个决策平面能够在某种评价指标上最好地分割两个类别的数据点。决策平面可以写作g(x)=ω·x+b=0,其中x是要分类的任意数据点,ω和常数b通过训练获得。支持向量机(SVM)[17]可以在高维空间找到离各类别数据距离最大的决策面,本文采用SVM来进行数据的分类。
2.4 数据清洗及数据审核
2.4.1 数据清洗
利用文本聚类技术对数据内容进行自动分类和指纹索引,通过基于数据内容的相似度计算(Profile模板差异计算方法[18]),将相似度超过临界值的内容进行自动删除,仅保留路径初始版本或权威来源版本,并根据聚类得到的离群点进行二次分析,以便去除无关的噪声文本。
2.4.2 数据审核
在专家指导下,对全部数据进行审核,确保数据关键要素(时间、地点、参与人、摘要)的正确性。审核完成后进行数据发布。
3 实 验
3.1 数据挖掘设置
本文从丝路文化遗产入手,以中国知网海量与“丝路文化遗产”相关文献为样本进行文本挖掘,按照陈列展览、考古发现、文化事件、学术成果4个维度,利用数据智能挖掘技术、机器学习技术和数据清洗技术,进行数据的深层次搜集和处理。将采集到的13.4万条丝路文化遗产机器数据作为实验测试样本,进行分类、排重、去噪及整理。
3.2 数据挖掘过程
3.2.1 关键词梳理
本文利用文本挖掘技术,在中国知网海量文献库中分析与丝路文化遗产相关文献,以文献中与丝路文化遗产相关关键词出现的“频次”“突现率”“节点度”和“中心度”等维度智能推荐关键词,并辅助以人工对关键词进行筛选,共形成关键词346个(每个关键词包含中、英、俄、法、日5国语言)。将各个关键词进行不同组合,利用布尔检索关系的检索式,对互联网和数据库进行信息搜索。截取部分关键词,如表1所示。
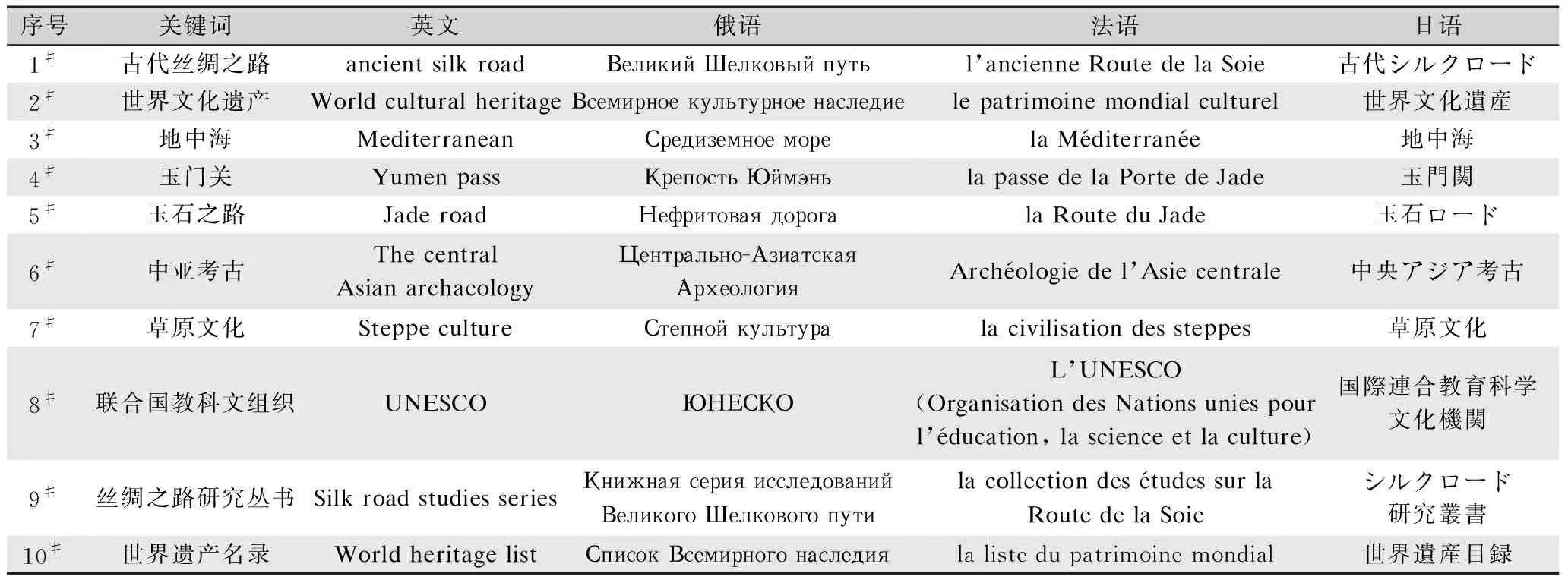
表1 “丝路文化遗产”关键词表部分截取Tab.1 Partial interception of the keyword table of “Silk Roads Cultural Heritage”
3.2.2 站点搜集及整理
通过互联网信息采集软件分析出与“丝路文化遗产”高度相关的网站(包括国内和国外),并对这些站点进行统一资源定位器分析,形成初始信息来源网站清单,由相关领域专家人工补充并完善与“丝路文化遗产”相关信息的网站,形成包含汉语、英语、俄语、法语、日语5种语言的信息来源网站清单。最终整理得到符合本文检索范围的网站站点,主要有:联合国教科文组织丝绸之路网站、世界十大博物馆网站、丝路沿线全部国家的国家博物馆网站、中国全部省级及以上级别博物馆网站、中国全部省级及以上文物局网站、SCI数据库、中国知网数据库、百度搜索、谷歌搜索等知名公共搜索引擎等,包括368个中文站点,373个外文站点,共计741个站点。截取部分网站站点数据来源,如表2所示。
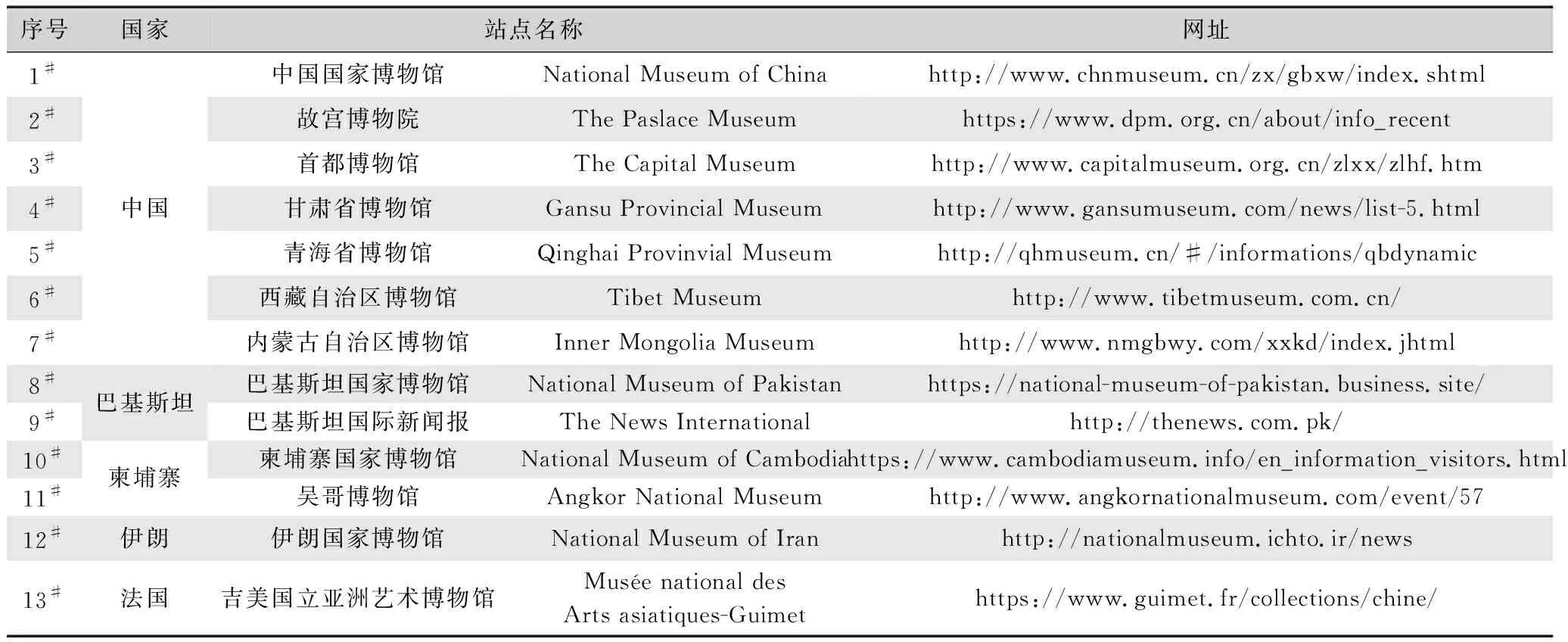
表2 网站站点数据来源部分截取Tab.2 Partial interception of the website data source
3.2.3 互联网信息定向抓取与分类
本文利用表2所示网站站点频道信息,以及事先设置的关键词(表1),结合智能代理、自动多线程、海量数据存储和编码识别等方式对网站站点进行定向信息抓取。随后,将筛选得到的数据通过自动标引、自动文摘得到某报道/文献的摘要,最后利用机器学习技术(SVM)对文摘进行自动分类,分为陈列展览、考古发现、文化事件、学术成果4大类。在SVM中,训练样本为1 000条人工标注的4大类文摘(其中800条用于训练,200条用于测试,模型准确度达到99%),训练好的模型能够自动对剩余的数据进行分类。
对本次741个站点进行数据采集,共采集丝路文化遗产相关数据13.40万条,机器对采集得到的全文进行分类,共得到:“丝绸之路陈列展览”数据约4.10万条,“丝绸之路考古发现”数据约0.40万条,“丝绸之路文化事件”数据约7.40万条,“丝绸之路学术成果”数据约1.50万条。
本次数据采集工作网站配置与数据采集共耗时约15 d,采集数据大小约为110 GB。
3.2.4 数据整理
对采集和分类后的数据进行整理,包括数据清洗与数据审核。为确保质量,数据整理工作通过人机结合的方式实施,对打上分类标签的数据进行人工筛选审核,将筛选后的数据规范化,并提供中英2种语言的评审材料,以确保信息的准确度,即不能出现任何丝绸之路相关事件发生日期、发生地点、主要内容的错误。对于专业程度较高的工作内容,由本专业领域的专家指导完成。
3.3 数据挖掘结果
数据挖掘结果如表3所示,显示的所有数据条数均为相关步骤处理完成之后的数量。由前文分析可知,在经过数据采集和机器学习分类之后,共得到丝路文化遗产相关数据13.40万条。由于分类后的数据中会包含重复数据和噪声数据,需要对其进行清洗:包括数据排重,即对全文内容重复率高于90%的条目进行去重,仅保留最早发布的文章;去噪,即剔除与丝绸之路文化不相关数据。清洗后剩余数据约1.10万条,其中:“丝绸之路陈列展览”相关数据约0.30万条,“丝绸之路考古发现”相关数据约0.10万条,“丝绸之路文化事件”相关数据约0.60万条,“丝绸之路学术成果”相关数据约0.10万条。在数据清洗之后,需要利用人工对摘要内容进行审核以进一步去除无关的信息、并修改误分类的内容所属标签及摘要内容,处理完成后得到数据约0.37万条,其中:“丝绸之路陈列展览”相关数据约0.11万条,“丝绸之路考古发现”相关数据约0.08万条,“丝绸之路文化事件”相关数据约0.09万条,“丝绸之路学术成果”相关数据约0.09万条。
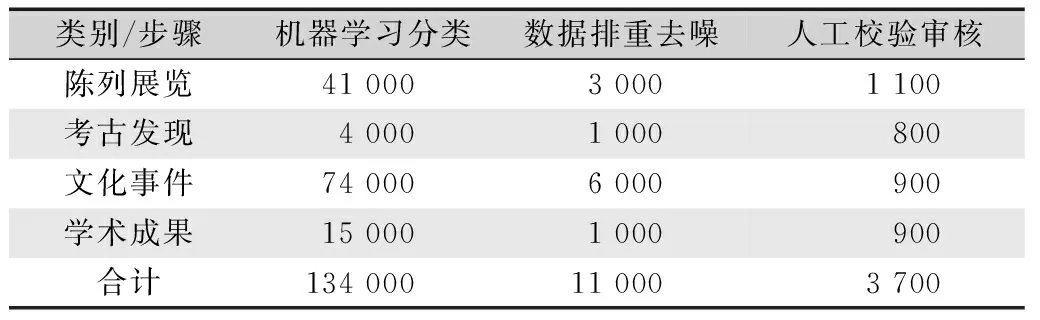
表3 丝绸之路相关的数据挖掘结果Tab.3 Data mining results related to the Silk Roads piece
人工校验审核之后的数据已经较为纯净,为提高数据质量,邀请联合国教科文组织世界遗产中心、中国古代史研究中心、中国社会科学院考古研究所等领域专家进行筛选,如表4所示。筛选完成后剩余数据426条,其中:“丝绸之路陈列展览”相关数据100条,“丝绸之路考古发现”相关数据100条,“丝绸之路文化事件”相关数据125条,“丝绸之路学术成果”相关数据101条。
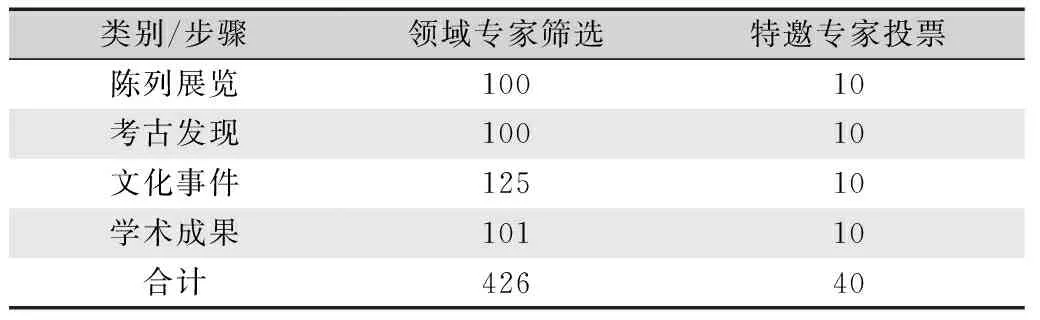
表4 领域专家筛选与投票Tab.4 Domain expert screening and voting piece
最后,特邀文博、考古、历史等领域的40位国内外权威专家分别对陈列展览、考古发现、文化事件、学术成果中的“十大”进行投票,形成《丝绸之路文化遗产年报》1份,年报内容包括:“丝路文化遗产十大陈列展览”“丝路文化遗产十大考古发现”“丝路文化遗产十大文化事件”和“丝路文化遗产十大学术成果”。
4 结 语
本文采用数据挖掘、机器学习、数据清洗等技术对多源异构丝路文化遗产数据进行智能分析和处理。在数据采集方面,使用智能代理、自动多线程、海量数据存储和编码识别构建高覆盖率与高效的数据采集系统;在信息挖掘方面,使用自动标引、自动文摘和支持向量机快速、精确地完成文本分类工作;在数据清洗方面,采用数据筛选、数据校对和专家审核对数据信息进行去重、去噪等清洗作业。最后,整合这些研究成果形成《丝绸之路文化遗产年报》并进行开源发布。实验结果表明,利用人工智能数据挖掘技术进行丝路文化遗产的数据研究能够有效保证数据的全面性、多维性和高效性,其成果对弘扬和传播丝路文化有着重要的现实意义与理论价值。

《丝绸》官网下载

中国知网下载
