基于高斯过程建模的移动机器人学习预测控制方法
2023-02-09伍瑞卓张兴龙张昌昕
伍瑞卓,张兴龙,徐 昕,张昌昕
(国防科技大学智能科学学院,湖南长沙 410073)
1 引言
近年来,地面机器人广泛地应用在工业、服务业、医疗业和特殊危险行业,应用环境表现出多样化和复杂化的特征.相比于结构化道路环境,机器人在植被覆盖、铺有沙砾、结冰或高低起伏的地面上运动时,其底层动力学会因道路变化而发生变化,使得机器人跟踪控制面临环境不确定性和模型不确定性的挑战,因此,机器人在不同地形条件下的运动控制成为了一个重要研究问题.
强化学习作为一类能够求解序贯决策优化问题的机器学习方法,受到了广泛的关注和研究[1-3],研究人员通过算法设计使得智能体在环境中进行主动探索,并且获得“奖励”或“惩罚”,以此来学习和优化智能体在当前不确定环境中的运动策略.因为维数灾难问题,近年的强化学习工作主要围绕大规模连续空间MDP(Markov decision process)的值函数与策略逼近方法展开,可以分为基于值函数逼近的强化学习算法、基于策略梯度的强化学习算法和基于执行器-评价器的强化学习算法,其中基于执行器-评价器的强化学习算法,被用于求解连续空间中的最优控制问题[4].
基于执行器-评价器的强化学习算法通过构建执行器和评价器结构,并利用函数近似这两种结构,逼近动态规划方程中的性能指标函数和控制策略以满足最优性原理.Werbos[5]提出了两种经典的基于执行器-评价器的强化学习方法算法,分别是启发式动态规划(heuristic dynamic programming,HDP)和对偶启发式规划(dual heuristic programming,DHP).Xu 等人[6-7]在DHP 的基础上,提出了滚动时域强化学习算法(receding horizon reinforcement learning,RHRL),将无限时域下的优化问题转换为多个有限时域下的优化问题,该方法结合了强化学习和模型预测控制方法的优势,相比模型预测控制,滚动时域强化学习能获得优化策略的显式表达式,相邻预测时域的策略学习具有连续性;相比无限时域强化学习,滚动时域强化学习在复杂非线性系统优化控制问题上的求解效率高,可以实现在线优化.但由于要求已知系统模型信息,所以准确的系统模型是滚动时域强化学习算法保证性能稳定的关键.
近年来,学者们针对滚动时域强化学习算法开展了许多研究.文献[8]针对离散非线性系统设计基于滚动时域强化学习的控制器,将其用于求解非线性最优控制问题,有效降低计算代价.针对连续时间系统,文献[9]在预测时域内设计了一组与时间相关的执行器和评价器用于学习随状态改变的值函数和策略,有效提升优化控制性能.针对未知模型带约束的非线性系统优化控制问题,有学者提出了一种鲁棒的滚动时域强化学习方法以完成在线优化求解,并从理论上分析了该方法的收敛性和迭代可行性,以及闭环系统的鲁棒性和渐近稳定性,在仿真和实验中验证了有效性和优越性[10].文献[11]将滚动时域强化学习应用在智能车辆跟踪控制中,在城市测试道路和乡村起伏砂石道路中进行了实车实验,充分验证了该方法的有效性和适应能力.目前基于滚动时域强化学习的控制算法主要考虑在结构化道路上的情况,而在复杂地形条件下,移动机器人的运动控制会受到环境不确定性的影响,使得移动机器人的高精度控制仍然面临挑战.
高斯过程回归(Gaussian process regression,GPR)在基于模型的学习预测控制中也是一种常用的机器学习方法,可以用于设计机器人运动控制的预测控制器,例如地面移动轮式机器人[12]、小型飞艇[13]等,以提升机器人对不确定环境的自适应能力.目前在学习预测控制领域内,大多数研究是将高斯过程回归建模方法与MPC(model predictive control)方法结合.Kocijan等人[14]最早将高斯过程回归引入预测控制中,辨识完整的动力学系统,并使用MPC方法进行预测控制;Ostafew 等人[12,15]利用高斯过程回归和机器人非线性先验模型共同逼近真实模型,以实现基于学习的MPC方法,并在复杂地形条件下完成机器人控制实验验证,有效的验证了所提方法在环境不确定条件下的学习能力.高斯过程也被应用在强化学习中,包括基于值函数逼近的强化学习方法[16]和基于策略梯度的强化学习算法[17-19].此外,Chua等人[20]将高斯过程与神经网络结合,将其用于有模型的深度强化学习中,以提高样本的利用率.目前还没有高斯过程在基于执行器-评价器的强化学习算法中的相关研究.
本文针对复杂地形条件下机器人高精度控制受到环境和模型不确定性影响的问题,提出了基于高斯过程建模的学习预测控制方法,所提方法能够在复杂地形条件下实时学习环境和模型不确定性,不需要精确的机器人模型,并可以在线学习最优控制策略,有效提升移动机器人在复杂地形条件下的适应能力.该方法结合了高斯过程建模泛化能力强、计算效率高和滚动时域强化学习算法求解效率高的优势,利用高斯过程建立机器人系统误差状态模型,以学习得到环境和模型不确定性的表征,并将其用于滚动时域强化学习中,通过在线迭代优化学习在该环境下的最优策略,从而减小环境和模型不确定性对机器人运动控制的影响,有效提升控制性能.
2 问题描述
本文的研究对象为轮式机器人,定义状态向量为x=[x y θ]T,x ∈Rn;输入向量为u=[v w]T,u∈Rm;当前时刻为k;ϱ为采样间隔.移动机器人运动学模型为
因为移动机器人底层动力学会随着外部环境的变化而产生变化,以及移动机器人系统具有非线性性,所以导致机器人运动过程中实际状态与理想状态之间存在偏差,可以用ϵ表示该偏差,ϵ=[εxεyεθ]T,由此得到实际状态的表达式为
除去扰动部分,参考轨迹与上述运动学模型具有相同的形式,定义参考状态向量为xr=[xryrθr]T,参考控制量为ur=[vrwr]T,由此得到参考轨迹的状态方程为
轮式机器人及其与参考轨迹的关系如图1所示,由于本文针对侧向控制问题,所以令速度v=vr.根据文献[21],定义误差xe=[xeyeθe]T,其满足

图1 轮式机器人和参考轨迹示意图Fig.1 Diagram of wheeled robot and reference trajectory
通过式(4)旋转坐标框架得到误差状态模型为
中间部分化简时令θe(k)+εθ(k)近似等于θe(k).
轮式机器人的运动学模型(1)在参考轨迹点的误差状态方程为
可以发现实际误差状态方程(5)与运动学模型得出的误差状态方程(6)仅相差扰动项.将坐标旋转矩阵记为D(k),即
将式(6)代入式(5)得到
定义误差状态扰动为ϵe=[εexεeyεeθ]T,那么ϵe与状态扰动ε的关系为
在已知k时刻的状态扰动ϵ(k)后,即可通过式(9)计算得到k时刻的误差状态的扰动ϵe(k),则式(8)可化简为
误差状态模型可以拆分为标称误差状态模型和扰动模型两个部分,标称误差状态模型是考虑扰动不存在的理想模型,扰动模型是根据实际的环境建立得到的模型.该混合模型既考虑了机器人固有的先验模型,避免了构建纯数据驱动建模的黑箱模型,又引入扰动模型以考虑环境和模型不确定性对机器人动力学的影响.并且在运动过程中,通过不断更新数据集样本的方式,可以完成扰动模型的实时学习,从而适应复杂地形.
而后,在预测时域内采用该误差状态模型学习近似最优策略.
3 基于高斯建模的移动机器人学习预测控制
3.1 整体框架
本文提出的基于高斯建模的移动机器人学习预测控制方法的整体框架如图2所示,该方法分成模型学习和策略学习两个部分.
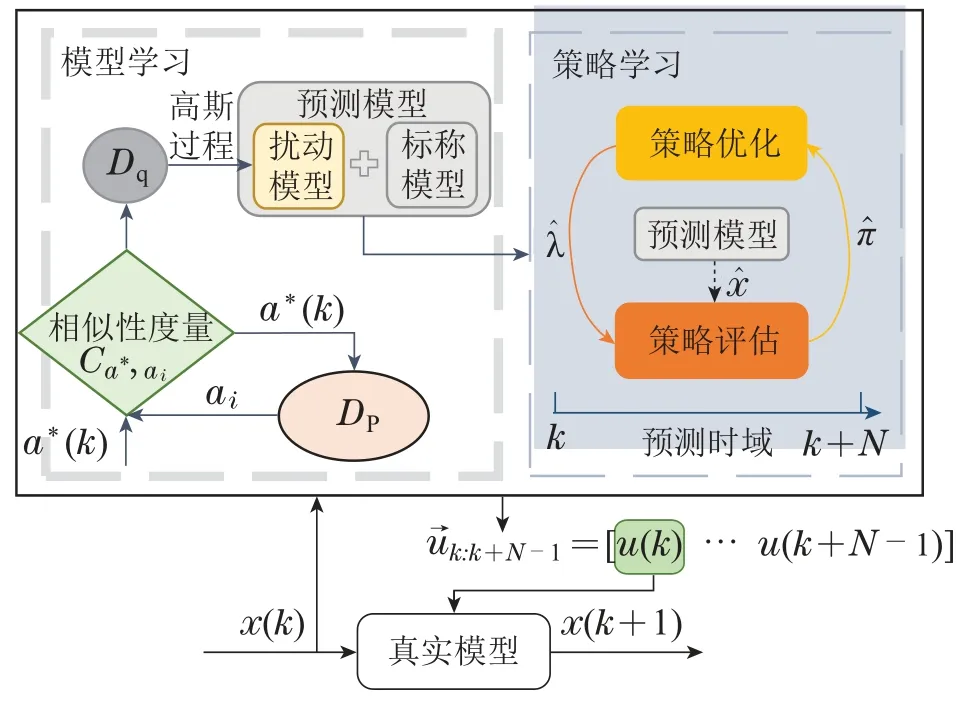
图2 高斯-RHRL方法框架Fig.2 The framework of GP-RHRL
记当前时刻为k,预测时域的长度为N,N ∈N+,数据集DP中的样本是由真实模型在过去时刻产生的.在模型学习中,首先将当前时刻k下的状态a*(k)与数据集DP中的数据进行相似性度量,相似度高的数据组成Dq,相似度较低的放入数据集DP中以更新样本池.而后在每一步策略学习前通过高斯过程回归建立公式(10)中的扰动模型,得到扰动预测量;在策略学习中,采用滚动时域强化学习求解优化控制问题,在预测时域[k,k+N]内进行策略优化和策略评估,通过迭代优化以实现在线近似最优策略的学习,从而获取预测时域内的控制序列将第1个控制量u(k)作为输入施加到真实模型中,得到的下一时刻状态x(k+1)用于学习下一预测时域内的控制策略,以此类推实现在线滚动优化机制.
3.2 基于高斯过程的移动机器人建模
假设数据集DP中g(ai)都源于一个零均值的高斯过程,如式(13)所示:
其中s(·,·)为核函数,本文使用多元二次核函数,如式(14)所示,因为多元二次核不仅是各阶可微分的,满足了后续对高斯过程求偏导数的要求,并且计算代价小于高斯核函数,可以提升算法速度,即
其中:S ∈Rp×p为协方差矩阵;(S)ij=s(ai,aj).
记超参数为Ψ=[σp σn σm ς]T,基于已有数据集的似然函数为
最优超参数可以通过最大化似然函数得到,即
将待预测的输入向量定义为a*,对应的预测输出定义为g(a*).下一步将构建训练样本a,g(a)和预测样本a*的联合高斯先验分布为
根据文献[22-23]的第9.4小节可知,在微分线性算子的作用下,高斯过程的微分依然是高斯过程,可以获得其偏导数.因为滚动时域强化学习仅需要下一时刻误差状态对当前时刻误差状态和动作的偏导数,所以只计算高斯过程回归预测分布的均值µ对预测样本a*的偏导数,不考虑方差的偏导数.
则有均值对误差状态的偏导数为
其中:i ∈{n+1,2n},j ∈{1,n},以及均值对动作的偏导数为
其中:i=2n+m,j ∈{1,n}.因为微分是线性算子,故有
又因为本文中使用的多元二次核函数是可微的,所以可以得到∇s(a*,ai),如公式(24)所示:
将∇s(a*,ai)代入式(23)后,便可以计算出均值对预测样本的偏导数∇µ,再根据式(21)-(22)分别得到均值对误差状态和动作的偏导数.
高斯过程建模中涉及核矩阵的求逆计算,完整的高斯过程回归时间复杂度为O(p3),这导致完整高斯过程回归在实时性要求较高的问题中难以得到应用.为了减小计算量,目前衍生出多种可延展高斯过程回归方法,可以分为全局近似和局部近似两种类型[24].数据子集法属于全局近似方法,其思想是利用训练数据的一个子集(子集中数据量为q)来近似整个高斯过程,其优势是将时间复杂度从O(p3)降为O(q3),且原理简单易实现.所以本文采用数据子集法进行高斯过程回归预测.
将对预测样本a*和数据集中的样本ai进行相似性度量来完成数据子集的提取.根据文献[25]可知,针对高维数据,采用距离和角度度量能更加有效的区分样本,如式(25)所示:
通过高斯过程回归建模得到误差状态模型后,便可以采用学习预测控制算法在线迭代优化得到控制量,下一小节将详细介绍基于滚动时域强化学习的预测控制算法.
3.3 基于滚动时域强化学习的预测控制算法
为了研究第2小节中的控制问题,需要将其转化为优化问题.定义目标函数为
根据贝尔曼方程可知当前状态的值函数取决于下一个状态的值函数以及当前状态采取的动作所得到的即时奖励,式(26)可写成如下形式:
定义代价函数为
其中:R ∈R+为正数;Um为控制量的最大值;ρ=UmR,H是一类连续可微单调递增的奇函数,且满足‖H(·)‖2≤1;H-1为其反函数,该式可对系统输入进行软约束,本文采用双曲正切函数,H(·)=tanh(·).定义终端代价函数为
其中P为正定矩阵.
由此,有限时域滚动优化求解最优策略可以描述为
下一时刻状态对当前时刻动作偏导数记作d(u(τ)),即
假设瞬时代价r(τ)只与当前状态a(τ)和动作u(τ)相关,与下一状态无关,同时根据Bellman最优原理,最优值函数作V*(τ)在策略π满足如下离散HJB方程:
最优动作u*(τ)满足
对最优状态值函数求取最优动作的偏导,使其等于零可以得到最优动作解析表达式为
为了提升求解效率,引入Actor-Critic结构与值函数逼近进行预测时域的策略学习.在预测时域τ ∈Ω内,值函数和策略是根据当前状态改变的,所以采用N组时间相关的神经网络逼近预测时域内的Actor-Critic,如图3所示,网络结构为采用3层的反向传播神经网络,表示为Critic网络逼近最优状态值函数的协状态λ*(τ),可以将其命名为Critic(k),Critic(k+1),···,Critic(k+N-1),Actor 网络逼近最优动作u*(k),可以将其命名为Actor(k),Actor(k+1),···,Actor(k+N-1).
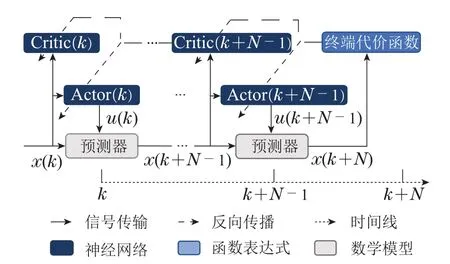
图3 滚动时域强化学习算法结构Fig.3 The structure of receding horizon reinforcement learning algorithm
记i ∈N+为预测时域内在线学习的迭代次数,在第i次迭代中,将当前策略下的值函数记作V(i)(τ),网络输出的协状态和动作记作λ(i)(τ)和u(i)(τ).
网络Critic(τ)的学习目标为极小化如下时域差分误差:
采用时域差分算法更新每次迭代的评价器网络权值,其更新规则可以表示为
网络Actor(τ)的学习目标为极小化如下误差函数:
在实际应用中,由于计算机算力的限制和应用中系统实时性的要求,迭代次数数i →∞一般难以实现,所以提出策略学习终止的判别条件.
收敛条件1网络权值收敛.
收敛条件2预测时域内性能指标收敛.
其中ΔW和ΔV是判断评价器和执行器网络收敛的阈值.收敛条件1和2可以同时使用,也可以根据实际情况选择任一收敛条件.
4 仿真验证
为验证本文所提出的基于高斯过程建模学习预测控制方法(Gaussian process RHRL,GP-RHRL)的有效性,本节以轮式机器人为例,采用Webots-MATLAB联合仿真进行跟踪轨迹为椭圆形和8字形的侧向跟踪控制仿真,并与未采用扰动模型的滚动时域强化学习方法(RHRL)、未采用扰动模型的非线性模型预测控制方法(nonlinear model predictive control,NMPC)和采用扰动模型的非线性模型预测控制方法(Gaussian process NMPC,GP-NMPC)进行对比,进一步验证了所提方法的优越性.GP-RHRL和GP-NMPC均采用高斯过程回归预测扰动,但不同的是,GP-RHRL还在迭代优化的过程中考虑了预测扰动对误差状态的偏导数和对动作的偏导数影响,而GP-NMPC仅将误差状态扰动的预测值与当前误差状态相加,如式(11)所示,并没有在模型中使用偏导数信息.
4.1 典型场景搭建与数据采集
在Webots 中可以通过其给出的物理模块节点(uneven terrain)生成一片不平坦地面,其大小为12 m×12 m,高度分布是基于Perlin梯度噪声生成的大小为50×50的矩阵,其可视化如图4所示.而后选择该物理模块的表面纹理为沙地(Sandyground),由此得到一片模拟户外环境的地面.
图4 地形图Fig.4 Topographic map
机器人则采用多功能户外先锋机器人(Pioneer 3-AT)行进最大速度为0.7 m/s.图5展示了的部分参数.机器人的位姿数据通过仿真环境中的位置节点获得,分别是位置信息[PxPyPz]和以轴角表示的姿态信息[AxAyAzAangle].
图5 Pioneer 3-AT尺寸图Fig.5 Dimension figure of Pioneer 3-AT
4.2 椭圆轨迹
椭圆轨迹的半长轴a=5,半短轴b=2,长度单位为m,其期望速率变化如图6所示.NMPC,GP-NMPC,RHRL 和GP-RHRL 的控制参数相同,控制时域长度N=6,Q=diag{10,800,30},R=1,P=Q,采样间隔ϱ=0.05 s.在初始时刻,数据集DP中的样本对数量为30个,而后将每一时刻生成的样本放入DP中,以实时更新DP,如果样本数量达到最大值600,则从第1个样本开始舍弃,使得DP中样本总量始终保持为600个,相似性度量后得到的数据集Dq中的样本对数量为30个.
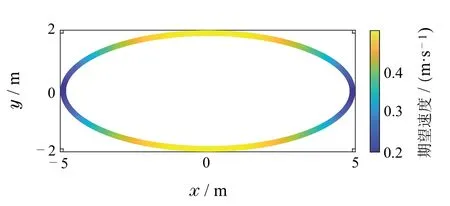
图6 椭圆参考轨迹和期望速度示意图Fig.6 Diagram of reference trajectory and expected speed in an elliptic trajectory
椭圆轨迹中机器人Pioneer进行过程中的俯仰角和翻滚角的变化如图7所示.机器人从标识①出发,以逆时针方向行进.标识①至④处的俯仰角和翻滚角由黑色实线指出.整段椭圆轨迹中,俯仰角在-30°~12°间,翻滚角在-30°~30°间.
扰动的预测情况如图8所示.在该环境下扰动的变化曲线并不平滑且无规律,更多呈现出的锯齿波和脉冲波形状.但高斯的预测基本符合实际情况,航向角误差和纵向误差预测基本与真值重合,侧向误差的预测均较为准确.
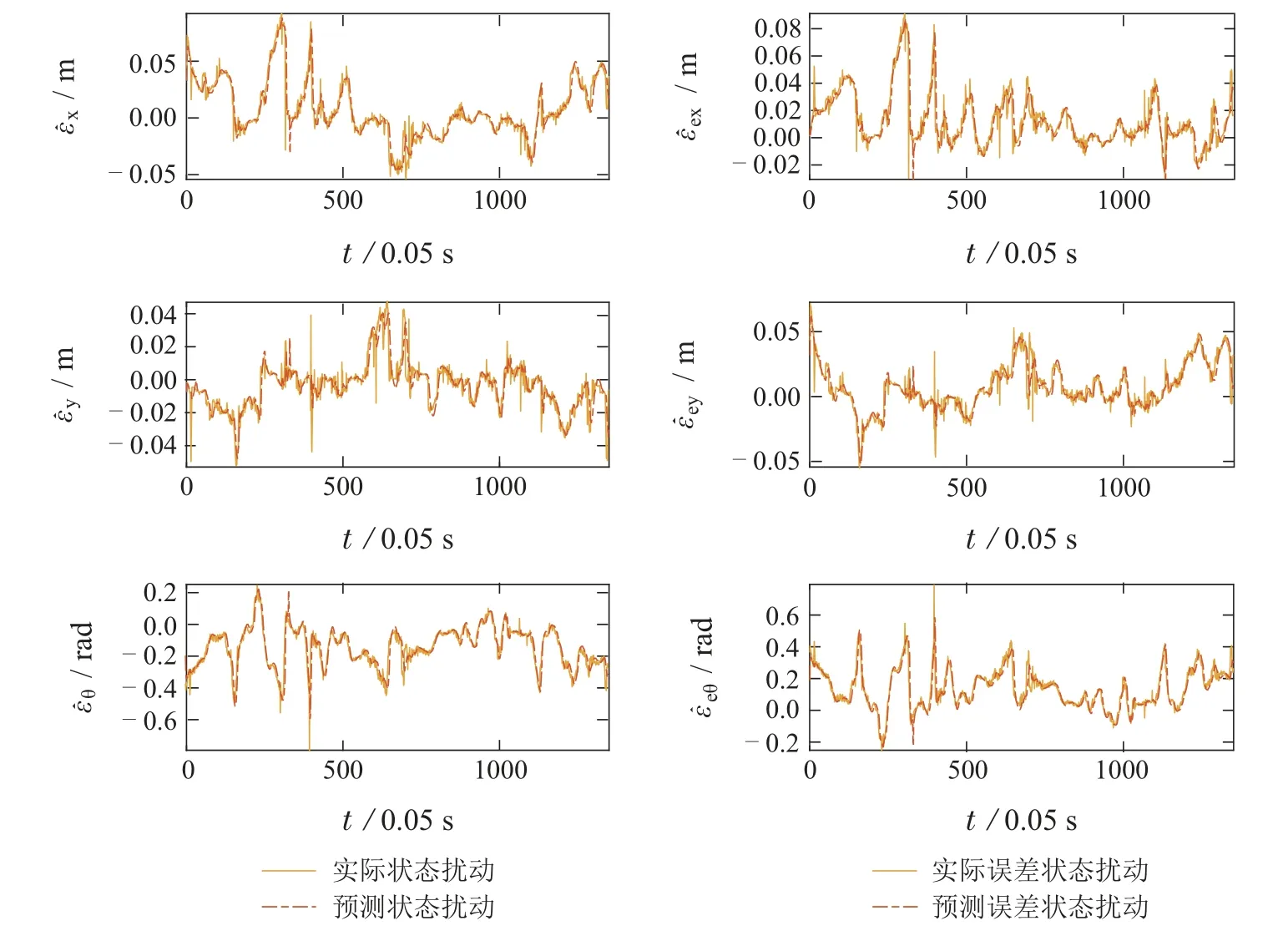
图8 Webots中椭圆轨迹下扰动ϵ和ϵe的预测结果Fig.8 Prediction of disturbance ϵ and ϵe in an elliptic trajectory in Webots
表1展示了4种方法的性能指标对比,其中GP-RHRL方法获取了最低的性能指标Jx,表明所提方法相比其他对比方法能有效降低跟踪误差,而在性能指标Ju上GP-RHRL所取得的数值是最大的,表明在复杂地形条件下机器人受到外界影响后,所需的控制器介入量更大,才能有效对跟踪性能进行改善.在侧向误差的均方根指标上,GP-RHRL相较RHRL性能提升19.9%,较NMPC提升35.7%,较GP-NMPC提升25.0%.

表1 Webots中椭圆轨迹性能指标对比Table 1 Comparison of performance indexes of elliptic trajectory in Webots
图9进一步展示了侧向误差ye和航向误差θe的变化情况,可以明显看出,GP-RHRL在侧向误差上优于其他3种方法,GP-NMPC方法在侧向误差快速增大时,对其的修正过程更加迟缓,此外NMPC方法的航向误差也常常大于RHRL,说明RHRL对不确定性的适应能力更强.后而在航向角误差上,虽然4种方法的区别不明显,仍然可以从时间步600至800这段曲线中看出GP-RHRL对于航向角误差的改善效果更好.
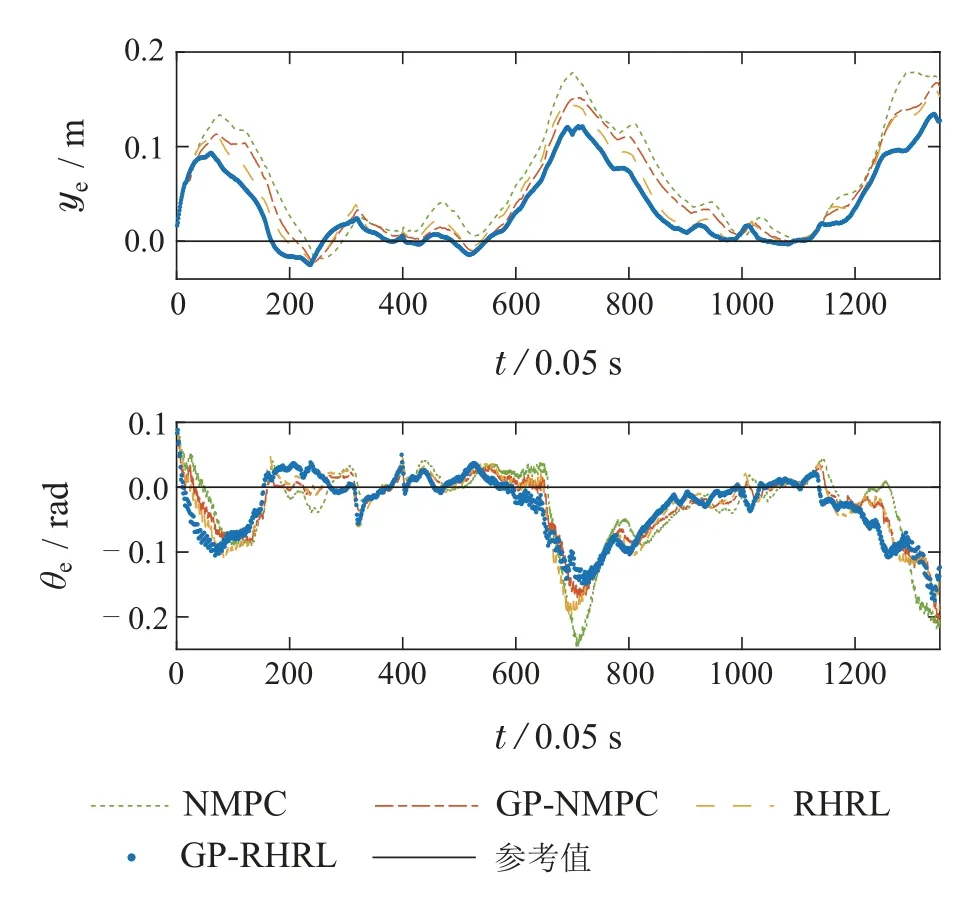
图9 Webots中椭圆轨迹跟踪侧向误差ye和航向误差θe示意图Fig.9 Diagram of lateral error ye and heading error θe for elliptic trajectory tracking in Webots
4.3 8字形轨迹
8字形轨迹的的期望速率如图10所示.NMPC,GPNMPC,RHRL和GP-RHRL的控制参数相同,控制时域长度为N=6,Q=diag{10,600,30},R=1,P=Q,采样间隔ϱ=0.05 s.数据集DP中的样本更新规则与上一小节相同.

图10 8字形参考轨迹和期望速度示意图Fig.10 Diagram of reference trajectory and expectedtrajectory speed in an eight-shaped
在该轨迹中Pioneer的俯仰角和翻滚角的变化如图11所示.机器人从标识①出发,先以逆时针方向行进,到达标识④处后以顺时针方向行进.标识①至⑤处的俯仰角和翻滚角由黑色实线指出.整段8字形轨迹中,俯仰角在-30°~30°间,翻滚角在-32°~35°间,机器人的姿态变化相较椭圆轨迹更加复杂.
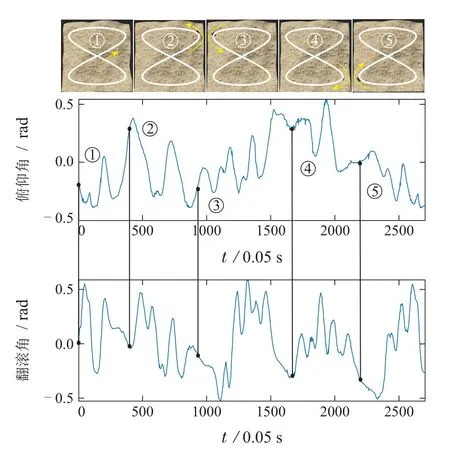
图11 Webots中8字形轨迹下俯仰角和翻滚角的变化曲线图Fig.11 Variation curve of roll angle and pitch angle in an eight-shaped trajectory in Webots
扰动预测情况如图12所示.侧向误差中,在时间步1600至2000间未能将部分脉冲状噪声有效预测,同时航向角误差和纵向误差预测则更加准确.表2展示了4种方法的性能指标对比,GP-RHRL方法在关键指标Jx上相比其他3个方法最小,可以看出在降低跟踪误差上GP-RHRL也最有效.在表4中的侧向误差在侧向误差的均方根指标中,GP-RHRL相较RHRL性能提升12.6%,较NMPC 提升28.0%,较GP-NMPC 提升20.5%.
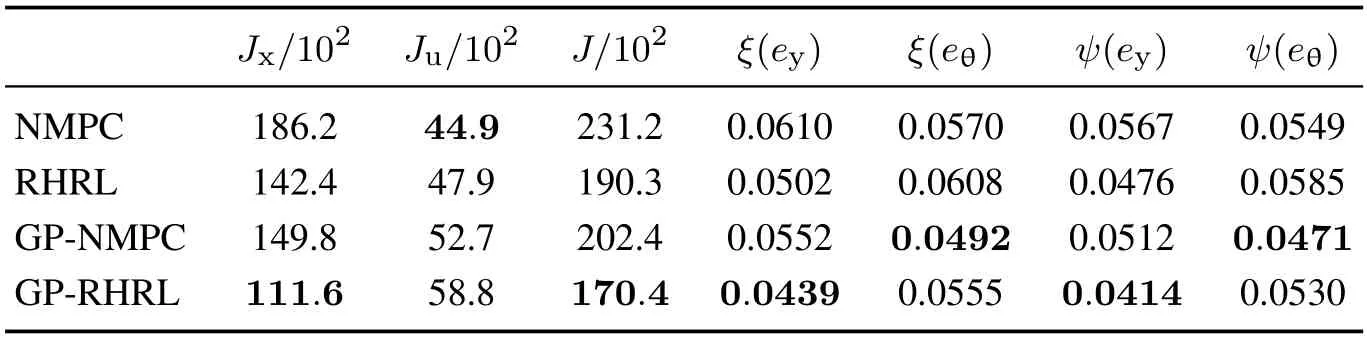
表2 Webots中8字形轨迹性能指标对比Table 2 Comparison of performance indexes of eight-shaped trajectory in Webots
图13展示了轨迹跟踪的侧向误差ye和航向误差θe.可以看出GP-RHRL 方法在侧向误差上的性能表现均优于其他3种方法.比较特殊的情况出现在时间步1600至2000,此时Pioneer机器人移动至图10中(5,5)位置附近,采用高斯建模预测不确定的方法(GPRHRL和GP-NMPC)较未改进方法(RHRL和NMPC)反而出现更大的侧向误差.在该时间段中,状态中的扰动ye呈现较急剧的波动,从而对扰动的预测准确度降低,所以造成了侧向误差变大的情况.在非常极端的环境下,如果高斯建模不准确,也可能会对机器人的运动造成负面影响.
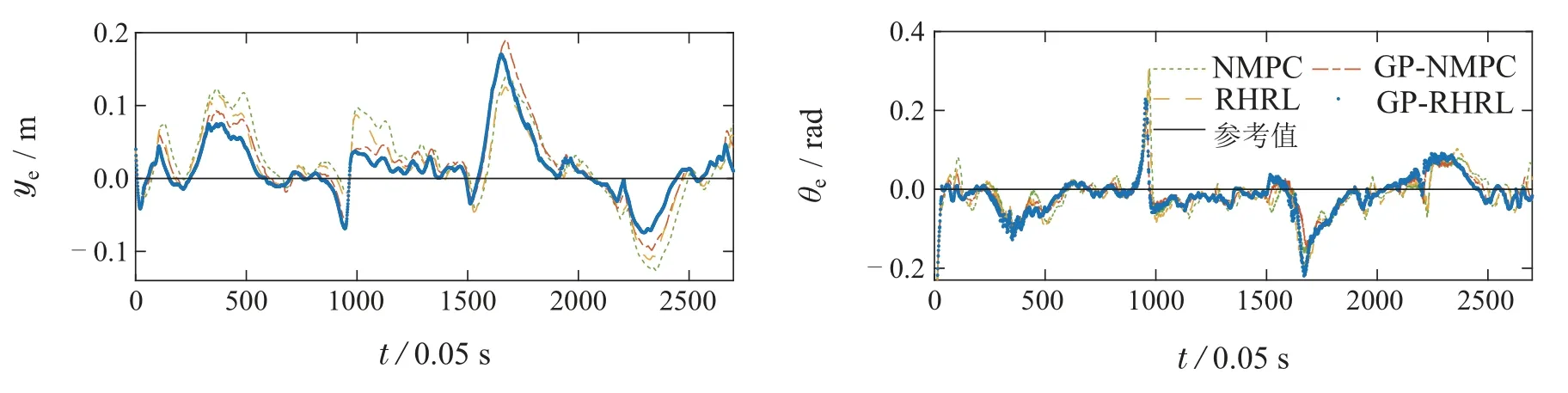
图13 Webots中8字形轨迹跟踪侧向误差ye和航向误差θe示意图Fig.13 Diagram of lateral error ye and heading error θe for eight-shaped trajectory tracking in Webots
由此可知,在未对该地形进行数据采集时,仅凭机器人运动中实时采集的少量数据难以对变化剧烈的扰动进行准确预测.所以本文所提方法在运用少量实时数据的情况下,无法解决强不确定性带来的性能退化问题.针对这个问题,在后续研究中也将考虑机器人在相同或类似环境下进行重复运动时,进行多轮数据采集,学习该类环境的特征和参数,并将之用于高斯过程建模中,从而使得高斯过程预测更加准确,提升算法性能.
仿真验证中所使用的处理器为英特尔酷睿i7-11700K@3.60 GHz,操作系统为Windows 11,显卡为英伟达3060Ti,算法通过MATLAB 2020a 进行计算,虚拟环境和物理引擎由Webots 2021b提供.在求解时间上,NMPC 方法的单步平均求解时间为24.6 ms,RHRL方法的单步平均求解时间为4.9 ms,GPNMPC单步平均求解时间为460.2 ms,GP-RHRL单步平均求解时间为42.9 ms,小于50 ms的采样间隔,满足实时性要求.可以看出相比MPC,采用强化学习进行迭代求解可以节省大量计算时间.同时GP-NMPC所需的求解时间远高于GP-RHRL,是因为NMPC采用的模型不断变化,使得优化过程非常耗时.
5 结论
本文提出了基于高斯过程回归建模的学习预测控制方法,首先,利用实时采集的状态扰动样本,通过高斯过程回归建模方法对环境和模型的不确定性进行建模.其次,根据状态和误差状态的关系推导得出误差状态模型.而后,在滚动时域强化学习中采用该模型进行迭代优化,以学习得到考虑环境和模型不确定性的近似最优策略,从而改善控制器性能.最后,以椭圆轨迹和8字形轨迹的侧向跟踪为例验证了该方法的有效性.在后续的工作中,可进一步在建模中充分利用先验信息,提高建模准确性和控制性能,并在实际平台开展控制方法验证.
