预训练模型辅助的后门样本自过滤防御方法
2023-02-05张天行陆小锋吴汉舟毛建华孙广玲
刘 琦,张天行,陆小锋,吴汉舟,毛建华,孙广玲
(上海大学 通信与信息工程学院,上海 200444)
0 引 言
随着人工智能的不断进步,深度神经网络也实现了飞速发展。深度神经网络模型已经在计算机视觉[1]、语音识别[2]、自动驾驶[3]等多个领域都表现出优越的性能。神经网络的大规模应用为用户带来便利的同时,也衍生出一些安全风险[4]。神经网络模型缺乏可解释性和透明性是其得到更广泛推广的重要阻碍,尽管许多学者通过设计特定的结构[5]来探究深度模型的本质或是通过可视化手段[6]来强化模型的可解释性,但目前仍无法对深度模型的行为给出合理的解释。攻击者可以通过这一缺陷对模型造成危害,对抗攻击首先证明了模型的脆弱性,在测试阶段,只要将精心设计的对抗扰动附加在测试数据上,就会使网络产生错误分类[7]。
另一方面,深度学习模型的优越性很大程度依赖于大量的训练数据和计算资源。受到实际条件的制约,个体用户通常没有用于训练大型复杂模型的计算资源[8],也无法获取高质量的训练数据集[9],因此会将训练任务外包至第三方计算平台以降低计算成本。这意味着用户将在一定程度上失去对数据集和训练过程的控制权。后门攻击就是一种主要的存在于训练阶段的安全风险[10],Gu等人[11]通过毒害深度学习模型的训练数据集,首次将后门触发植入到深度模型中。具体而言,攻击者将训练集中的部分样本进行中毒(向样本中添加触发器并修改其标签为目标类别),使模型中的某些神经元对特定的后门模式产生强烈响应,以达到篡改模型的目的。添加的后门触发器可以小到只有一个像素点[12],或是物理世界中的墨镜[13]。在测试阶段,当输入带有特定触发模式的后门样本时,这些后门样本会激活模型中的后门,使模型产生定向的错误分类,分类到攻击者指定的目标类别,而模型在干净样本的分类工作中仍保持良好的性能,这种特性使得用户很难检测模型中后门的存在。以交通标志识别任务为例,攻击者在一些“停车”标识图像上添加后门触发器,并将这些样本的标签更改为“限速”标识,这会导致用户在使用通过该数据集训练得到的模型完成自动驾驶任务时产生错误判断,造成难以挽回的损失。
如上文所述,后门攻击是一种存在于训练阶段的更加复杂、破坏力更大的潜在性威胁。攻击者可以通过以下三种场景植入后门:(1)攻击者仅提供后门数据集,模型训练过程完全由用户掌握;(2)攻击者不仅提供后门数据集,还掌握训练过程;(3)攻击者向网络开源数据库中提供的公共模型中嵌入后门,通过网络将后门模型分发给用户。这些丰富的应用场景及其特有的隐蔽性为后门防御任务带来了严峻的挑战。近期的许多研究试图在不同场景下减轻后门攻击带来的威胁,包括用户在无法控制训练过程的前提下,诊断一个模型是否携带后门触发[14]并利用剪枝等操作移除对后门模式有特殊响应的异常神经元[15]。然而,这些方法都不能彻底地清除后门模型中的后门触发,且会对模型在正常样本分类任务的性能造成影响。当用户使用攻击者提供的后门样本自行训练模型时,通过基于样本过滤的防御方法[16]过滤后门样本,但在现实场景中该方法也存在一定的局限性。
该文的主要贡献如下:
(1)借助于预训练模型,采用k近邻算法检测目标类,并依赖于模型自身的分类能力,实现后门样本的自过滤。
(2)在模型迭代学习与更新的机制中,逐步增强对正常样本的分类性能,也提高对后门样本的过滤能力。
(3)面向多个图像数据集的分类任务和多个攻击模式,以端到端和微调两种方式展开实验验证,并与其他方法进行比较,表明了所提方法的可行性和具备的优势。
1 相关工作
1.1 后门攻击方法
Gu等人[11]率先发现并定义了后门攻击,为这一方向的研究提供了重要参考。此后基于后门触发的后门攻击从触发器是否可见的角度可以分为两类:可见后门攻击和不可见后门攻击。以BadNets为代表的可见后门攻击通过在部分良性图像x上覆盖一个局部的像素块(后门触发器)得到中毒图像x',并与目标标签yt相关联得到后门样本(x',yt),用中毒后的数据集训练网络模型,得到的模型将带有后门能力。虽然可见后门攻击通常能达到较强的攻击效果,但触发模式的隐蔽性较差。Chen等人[12]首先讨论了后门模式不可见性的要求,在这之后,一系列致力于探究更隐蔽的后门触发器和更先进的后门添加方式的攻击方法被提出。Zhu等人[17]提出了一种图像隐写技术,可以将信息通过隐写的方式嵌入图像,将此技术应用于后门攻击中,通过向图像中写入特定的触发器使图像在中毒前后难以区分,同时具有较好的攻击效果[18]。
1.2 后门防御方法
为了抵御来自后门攻击的威胁,研究者们也提出了众多防御方法。这些方法由攻击者不同的权限导致防御进入的时间点不同,可以分为两类:第一类方法针对攻击方只拥有控制数据集的权限,但后续的模型学习由防御方控制的场景。此场景中防御方可通过模型学习之前过滤训练集中潜在的后本样本[16];或在模型学习的同时,基于特殊的训练策略,消除或减弱后门样本对于模型的影响[15]。第二类是针对攻击方同时拥有数据集和模型学习控制的权限的情况。防御方只能面对一个潜在的后门模型开展防御,可试图通过移除模型中的隐藏后门以修复模型或只给出模型诊断的结论[19];也可以在测试阶段,事先过滤可能的测试后门样本,以切断后门模型对其的响应[20]。
所以在史铁生笔下,死亡,并不可怕,它同样是生命的另一种存在形式。我们常常体会到作家对死亡感受到无比的亲切,甚至把死亡作为无上的福祉:“他常和死神聊天儿。他害怕得罪了死神,害怕一旦需要死神的时候,死神会给他小鞋穿”(《山顶上的传说》)。“我常常希望,有一个喝醉酒的司机把我送到一个安静的地方去”(《绿色的梦》),“有一年我也像盼望放年假一样盼望过死……”。
当攻击方仅拥有数据集的控制权限时,防御方可以通过观察输入数据的潜在特征表示来筛选异常样本。Tran等人[21]观察到后门样本会在特征表示的协方差频谱中留下异常,他们通过其特征表示协方差矩阵的奇异值分解来过滤后门样本。Chan等人[22]充分利用了后门样本和正常样本输入梯度的主成分分布差异,有效地将后门样本从目标类中过滤。Chen等人[16]提出了一种基于激活聚类(Activation Clustering,AC)的方法来检测数据集中的后门样本,通过对每个假定的目标类使用主成分分析法(PCA)[23],获得类内样本特征层激活的降维表示,并使用k-means (k=2)[24]进行聚类计算轮廓系数(Silhouette Score)以区分目标类。防御方也可以通过在训练过程中采用特殊的训练策略,有效地减弱注入后门的强度。Levine等人[25]将训练集划分为多个不交叠的子集来训练多个基分类器,利用多数投票机制将模型聚合,使得后门样本不会显著地影响多数投票的结果。Hong等人[26]发现利用基于差分隐私(Differential Privacy)的优化机制可以减弱后门。DP-SGD[15]通过在训练过程中裁剪噪声梯度,成功地防御了后门攻击,但当攻击者采用较强的后门模式时,该策略的有效性将会降低。RE方法[27]提出了基于优化的逆向工程防御,首先通过逆向工程恢复触发器,进而准确识别目标类,并根据生成的触发器检测后门样本。
如攻击方不仅拥有控制数据集的权限还能控制模型的学习过程,防御方则可以通过将疑似的后门模型进行重构以移除后门。Liu等人[19]观察到后门模型中某些特定的神经元对于后门样本有强烈的响应,于是将这些与后门相关的神经元进行修剪以去除模型中的后门。Wang等人[28]提出了一种基于合成触发器来消除隐藏后门的方法,通过异常检测器与反向工程合成后门触发器,用绝对中值差(Median Absolute Deviation)来计算合成触发器L1范数的异常值,基于合成的触发器对模型做剪枝和再训练,以对模型中的后门进行修补。但这些方法并不能从根源上去除后门,甚至会较大程度地影响模型对正常样本的识别性能,且所需的计算成本也非常高昂。防御方也可以通过在测试阶段过滤后门样本,以避免激活模型中的后门。如Subedar等人[29]利用模型不确定性来区分待测试的良性样本和后门样本。Gao等人[20]通过输入叠加各不相同的后门触发以观察预测结果的随机性来过滤携带后门触发的测试样本。
2 预训练模型辅助的后门样本自过滤方法
2.1 方法概述
图1展示了该方法的框架,包括目标类检测和后门样本自过滤两个部分。在目标类检测阶段,首先利用预训练模型提取样本的最后一层隐藏层的输出作为特征并通过k近邻算法(k-nearest neighbor,kNN)[30]预测样本类别,显然预测结果与提供的样本标签并非总是一致,据此可以计算每一类样本的分类错误率,若最高错误率低于阈值,认为此数据集为良性数据集,后续完成常规模型学习,反之认为错误率最高的类别是目标类,进行后续的过滤处理。在后门样本自过滤阶段,首先使用目标类之外的N-1类样本训练部分分类网络FN-1,根据FN-1对样本的分类置信度熵值从目标类中第一次过滤后门样本,由于第一次过滤结果不够精确,所以需要对完整数据集进行后续过滤,即依赖模型自身的分类能力鉴别后门样本并过滤,同时将目标类中的正常样本保留,以训练完整分类模型,具体方法如下:以第一次过滤后的数据集学习完整网络,之后每训练K个轮次对模型进行一次更新,然后根据当前模型自身的分类能力,对完整数据集的目标类样本进行一轮预测,如果预测结果与其标签不一致,则判别为后

图1 方法框架
门样本并从数据集中删除,当对目标类样本完成一轮预测后,用当前过滤后的数据集继续训练模型。后门样本自过滤阶段,“后门样本过滤”和“模型学习”以交替方式多次计算,当计算次数达到指定T时,结束训练,最终在过滤后门样本的同时也得到良性模型。
2.2 利用预训练模型和kNN的目标类检测
目标类的检测方案基于以下依据:后门数据集的目标类样本由正常样本与后门样本组成,其中后门样本由来自其他类别的正常样本添加后门模式并修改标签得到。对于后门模式为局部触发器的攻击或是隐蔽性较好的触发器不可见攻击,由正常模型提取后门样本的特征表示应与其源类(后门样本中毒前的真实类别)样本的特征更相似,而与目标类别样本的特征呈现较大差异。预训练网络拥有强大特征提取能力,能够提取样本丰富的高维特征,该文采用基于对比学习的自监督训练框架得到的ResNet-50模型[31]作为预训练模型(下文统称为PTM)。为了更进一步优化和凸显样本在特征空间中的分布,通过非线性数据降维t-SNE方法[32],将PTM提取得到的高维特征降维至2维空间中。如上分析,目标类中的样本必定会在2维空间中展现出比其他正常类样本更分散的类内特征分布。然而仅通过类内的特征分散程度并不能稳定检测目标类别,因此,使用kNN算法检测目标类别。
图2展示了包含4个类别的部分ImageNet数据集经过PTM提取特征和t-SNE算法降维可视化后所有样本的2维空间特征分布示意图与kNN分类过程。图2(a)中攻击方式为BadNets[11],不同符号代表不同类别的样本特征,其中class0代表中毒的目标类,其他为正常类,class0(class1)、class0(class2)、class0(class3)分别表示源类为class1、class2、class3的后门样本。分布示意图显示,正常类别的样本特征分布比较集中,而目标类的样本分布则更分散,特别是目标类中的后门样本均分布于其源类周围,该结果与上文分析一致。
kNN算法通过以某样本在特征空间中最相邻的k个样本中(此处k=5)多数样本的所属类别作为该样本的分类结果。因此,基于“后门样本在特征空间中近邻样本多为其源类样本”可知,用kNN算法预测后门样本的类别大概率是其源类,但该后门样本的给定标签为攻击者指定的目标类,如图2(b)“分类错误”,待测样本的给定标签为class0,其多数近邻样本标签为class3,因此该样本经过kNN的分类结果为class3,产生分类错误。与此相反,正常样本的多数近邻样本标签与该正常样本的给定标签一致,如图2(b)“分类正确”,待测样本的给定标签为class0,其多数近邻样本标签为class0,因此该样本经过kNN的分类结果为class0,分类正确。由以上分析不难看出,由于目标类混入了相当比例的后门样本,这导致kNN给出的分类错误率将高于非目标类的错误率,此规律即为目标类检测的依据。

(a)后门数据集样本特征分布 (b)kNN分类过程 图2 ImageNet中存在后门样本的数据集通过t-SNE降维后2维空间特征分布示意及kNN分类过程
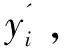
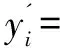
j=1,2,…,m
(1)

(2)
由于目标类中的后门样本特征上更接近源类,所以kNN对目标类样本的预测错误率高于正常类别,根据这个规律,设置合适的阈值,检测后门数据集中的目标类。
2.3 后门样本自过滤
假设数据集的类别数量为N,检测到目标类之后,用除目标类以外的N-1类样本训练FN-1分类网络。由于FN-1没有学习目标类样本的特征,所以对目标类的正常样本没有分类能力。不难推测,对于目标类中的正常样本,FN-1给出的所有分类节点的置信度趋彼此接近,且都较低。相反,后门样本均来自于其他正常类别,且FN-1对正常类别样本已具备较强的特征提取能力,故对于后门样本,FN-1将在其源类的节点上给出较高的置信度。此处借助信息熵的概念,通过下式以表征这种区别:
(3)
式中,x表示输入样本,C(x)表示在模型分类层中所有节点的置信度的集合,Ci(x)表示第i个节点的置信度,E(x)表征了分类结果的不确定性。根据以上分析并结合信息熵的基本结论可知,后门样本的平均E(x)将低于正常样本的平均E(x),从而可根据此特征确定阈值,以实现后门样本的第一次过滤,随后从剩余的正常样本集中,学习初始的完整分类网络FN。
在第一次后门样本的过滤过程中,不可避免会误留下一些后门样本,同时也会错误地过滤掉部分正常样本,从而对模型的性能产生影响。因此,需要迭代更新模型,以逐步增强模型对正常样本的分类性能,同时也提升对后门样本的过滤能力。设计了如下规则:每训练K个轮次后更新模型,然后对目标类中的样本进行预测,如果预测结果不是目标类,则认为是后门样本并从数据集中删除。所有目标类样本预测结束后,得到过滤后的数据集,开始新的K个轮次的模型学习。这样,“后门样本过滤”和“模型学习”以交替的方式,迭代进行T次,得到最终的完整分类模型。从以上过程可以看出,第一次后门样本过滤是依赖于FN-1自身的分类能力,而在后续的迭代计算中,也是依赖于不断增强的模型自身分类能力,逐步提升对后门样本的过滤能力。
3 实验结果与分析
3.1 实验设置
3.1.1 数据集与模型
为了充分验证本方法的有效性,分别使用ImageNet[33]、GTSRB[34]和Oxford-IIIT Pets[35]三个数据集以及端到端训练和微调两种训练方式进行实验,它们分别包含1 000、43和37个类别。对于ImageNet与GTSRB数据集,实验中随机选择12个和14个类别进行实验,以端到端的方式分别训练DeseNet-121与ResNet-34分类网络;对于Oxford-IIIT Pets数据集,在ResNet-50预训练模型(通过对比学习的自监督训练方式[31]得到)的基础上,替换适应本下游任务的分类层后微调分类器。以上数据集均按照8∶2划分为训练集和测试集。同时在GTSRB上模拟了小样本数据集,从43类样本中每类随机选择30个左右样本组成训练集,每类100个样本组成测试集,并采用与Oxford-IIIT Pets任务相同的模型和训练方式微调分类器。实验中,所有图像尺寸均为224×224,详细实验设置如表1所示。
3.1.2 攻击设置
在本实验中,分别对每个数据集中的部分样本用BadNets[11]和隐写[17]两种方式植入后门,图3展示了三组不同的后门样本,其中BadNets的后门触发器为右下角图像尺寸为7×7的像素块,隐写攻击则通过隐写的方式将此像素块嵌入图像。

图3 样本示例
根据表1的设置,使用BadNets和隐写攻击分别训练后门模型用于评估本方法的效果,并在良性数据集上训练基准模型作为比较。如表2所示,BA (Benign Accurate)表示对正常样本的分类准确率,ASR(Attack Success Rate)表示攻击成功率。实验结果表明,两种攻击方法都能在后门模型上达到较高的攻击成功率,且对正常样本的分类性能与基准模型接近。表2也相应列出了相应的后门样本注入率。
3.2 目标类检测性能评估
针对表2中的不同情况评估了本方法的性能,并与AC[16]和RE[27]方法进行比较。本方法下,kNN算法中的参数k设为5,错误率阈值设为20%。AC首先使用后门数据集训练得到后门网络,用该后门网络对每一类样本提取特征并用k-means(k=2)聚类方法和轮廓系数检测目标类。由于轮廓系数的值与数据集分布和模型结构密切相关,通过实验发现,将此阈值设为0.45时,检测性能最佳。RE方法对潜在的源-目标对进行反向工程生成触发器以检测目标类。表3展示了三种方法的检测结果,⊙表示能正确检测中毒的目标类,⊗表示不能检测到目标类或检测错误。由此结果可见,AC方法在很多情况下无法检测到目标类,RE虽然能检测出部分BadNets攻击,但对隐写攻击无效,而本方法能够稳定地检测出目标类,总体表现优于AC和RE。

表1 实验设置
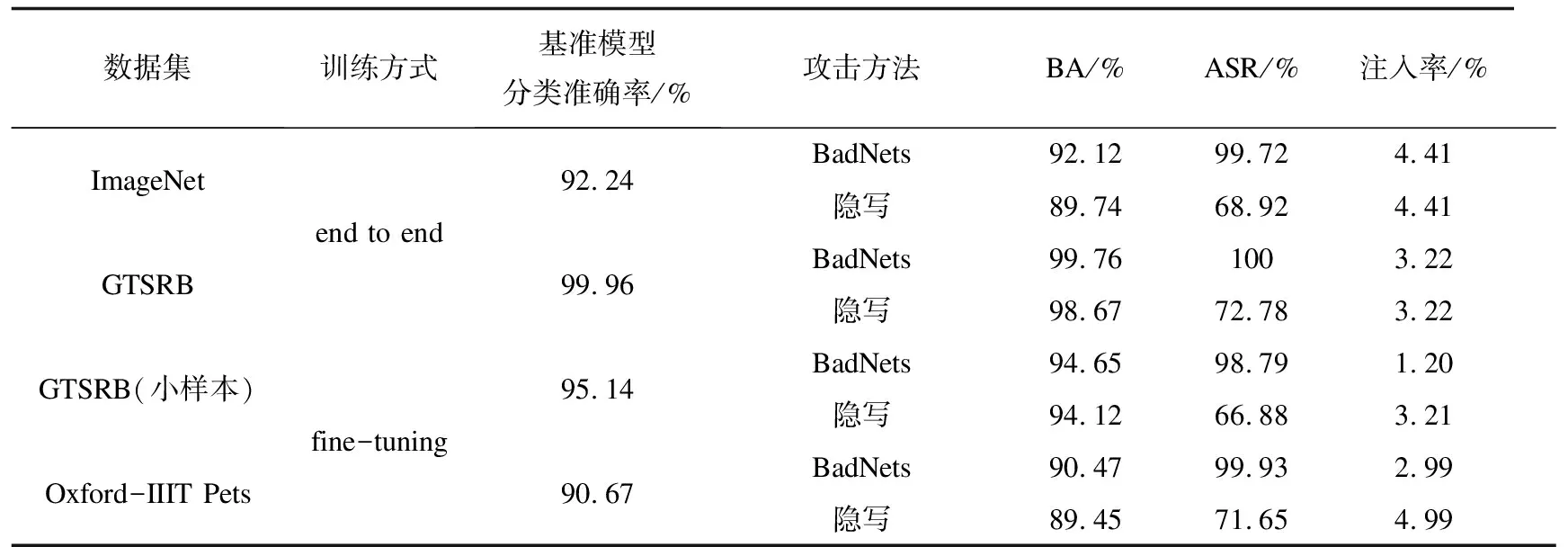
表2 基准模型和后门模型的基本指标
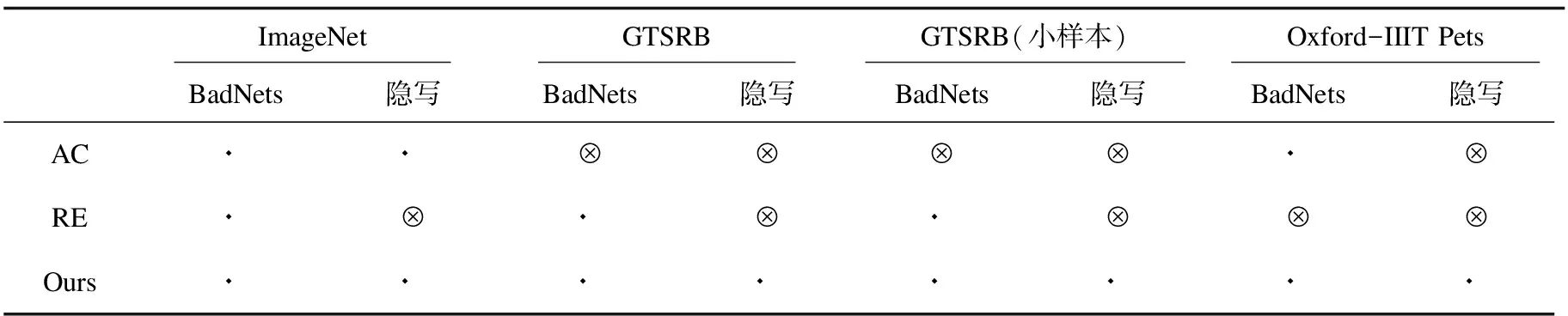
表3 目标类检测结果
3.3 后门样本自过滤性能评估
实验中,将参数K设置为3,T设置为15,即规定每训练3个轮次更新模型并过滤后门样本,以此方式迭代15次。表4使用真阳性率(true positive rate,TPR)与假阳性率(false positive rate,FPR)作为评价指标展示了最终结果,并与第一次过滤、AC过滤结果比较,其中TPR表示数据集中所有正常样本被正确识别的比例,FPR表示后门样本中被误识别为正常样本的比例。在第一次过滤时,以2.3节中的分类不确定度E(x)作为依据,对于GTSRB数据集,将阈值设为0.02,表4中第一次过滤结果可以看出,GTSRB的第一次过滤并不精确,需要进一步改善;对于ImageNet和Oxford-IIIT Pets数据集,阈值设为1.0,在最终过滤之后,TPR与FPR都得到了一定改进。AC方法在目标类检测阶段并不能全部检测成功,这对后续的过滤是无意义的,因此,本实验假设AC在测试的所有情况下,都能正确检测出目标类,进而做后续的样本过滤。RE方法的数据过滤依赖检测阶段反向生成的触发器,因此,此处只对RE方法检测成功的后门数据集进行后门样本过滤作为比较实验。
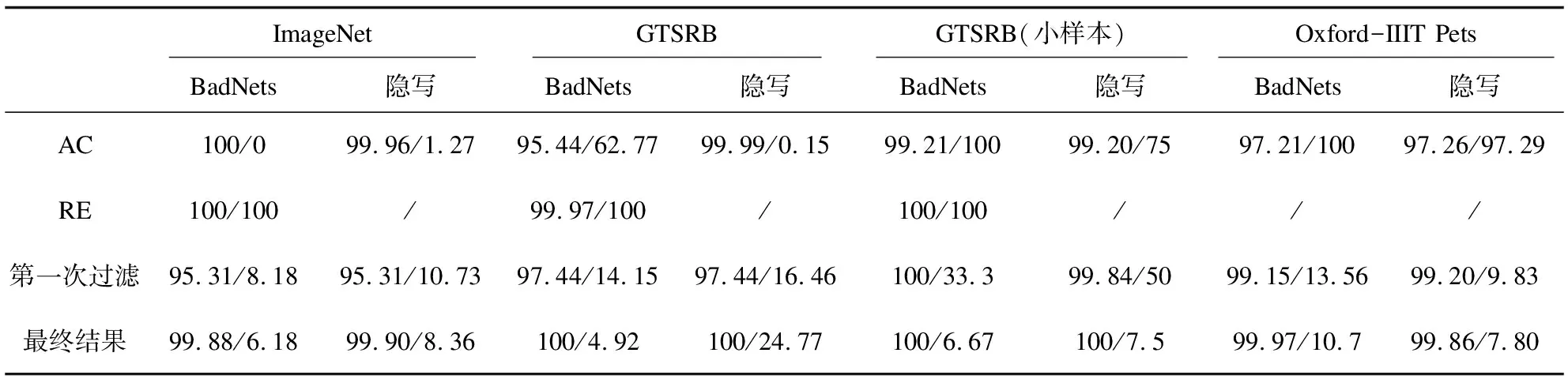
表4 TPR/FPR过滤指标比较(左边数据是TPR,右边数据是FPR)
表4结果表明AC的过滤效果欠佳,而文中方法在不同数据集能有效地应对BadNets和隐写攻击。AC假设目标类的正常样本多于后门样本,将目标类样本按特征分布聚为两类后,认为数量较少的聚类以后门样本为主,进行删除。但在实际场景中,由于后门攻击需要一定的后门注入率及样本数量的不确定性,目标类的正常样本数量并不一定总是多于后门样本,如本实验中GTSRB小样本数据集和 Oxford-IIIT Pets数据集中后门样本数量均多于目标类正常样本,因此在该场景下AC会将以正常样本为主的聚类误删除。图4(a)~(d)展示了在BadNets与隐写攻击下,AC方法对上述两种数据集目标类样本的聚类结果,其中聚类1的大部分样本为正常样本,聚类2的大部分样本为后门样本,而且聚类1样本数量少于聚类2样本数量。AC方法认为样本数量较少的聚类以后门样本为主,因此误将正常样本删除,说明不能简单通过聚类后两簇样本的相对数量关系作为过滤后门样本的依据。RE方法的后门样本过滤依赖第一步中反向生成的后门触发器,根据结果可以看出,在此攻击设置下,RE方法并不能完美地反向生成触发器,因此FPR指标较差。
由表4数据可以看出,相比于第一次过滤,完成自过滤之后的TPR和FPR在大部分情况中都得到了进一步的改善。在GTSRB小样本数据集的BadNets和隐写攻击中,第一次过滤的TPR较为理想,但FPR高达33.3%和50%,完成自过滤之后,TPR、FPR都达到了理想水平。图5显示了GTSRB小样本数据集的两种攻击方法在迭代过程中的TPR、FPR变化趋势,图中横轴代表过滤次数,纵轴代表TPR、FPR。模型每训练3个轮次对数据集的目标类样本进行一次过滤。根据曲线可以看到,TPR一直保持在较高的理想范围,FPR则随迭代次数的增加而逐步下降,并在第3轮迭代更新后保持稳定。

图4 在BadNets与隐写攻击方法下,AC对GTSRB(小样本)与Oxford-IIIT Pets数据集的 目标类正常样本误删除示例
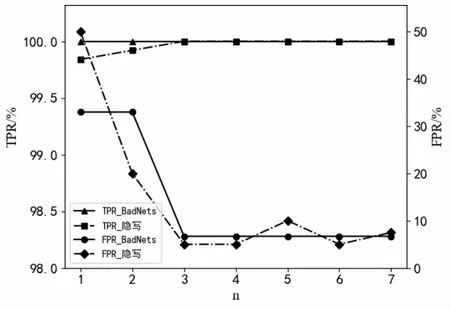
图5 注入BadNets与steganography后门样本的GTSRB小样本数据集,TPR/FPR随次数n的变化曲线
经过后门样本自过滤的模型的BA与ASR结果如表5所示。大部分情况中攻击力降到了1%以下,同时对正常样本的分类准确率与基准模型相近。经过后门样本自过滤的模型的BA与ASR结果如表5所示。大部分情况中攻击力降到了1%以下,同时对正常样本的分类准确率与基准模型相近。

表5 后门样本自过滤模型的分类准确率与攻击成功率
4 结束语
该文提出了一种预训练模型辅助的后门样本自过滤防御方法,实验在ImageNet、GTSRB和Oxford-IIIT Pets三个数据集和BadNets、隐写两种攻击上进行,并与AC和RE方法做了比较。结果显示,该方法能很好地过滤后门样本并最终得到正常分类模型,在目标类检测和后门样本过滤中具有更大优势,能有效抵御后门攻击。未来工作将尝试进一步研究如何防御更复杂的后门攻击。
