基于改进Yolov5植物病害检测算法研究*
2023-02-04杨文姬胡文超赵应丁钱文彬
杨文姬,胡文超,赵应丁,钱文彬
(江西农业大学软件学院,南昌市,330045)
0 引言
农业是我国发展的重要产业,其中果蔬种植对于我国实现农业现代化具有重大意义。果蔬对于人类身体具有不可缺少的营养成分,同时还是我国经济的重要来源。然而果蔬在生产过程中,由于自身对病害的抵抗能力有限,从而使得果蔬感染病害。植物病害不仅会减少产量,甚至造成巨大的经济损失。植物病害主要发生在植物叶片,可以通过叶片病害特征判断出植物感染病害类型。尽早地检测出植物病害,能够极大程度上减少产量损失、经济损失。然而,人工检测需要耗费大量时间和人力成本,检测结果受人为主观意识影响,且依赖专业知识。其次,专门从事病害识别的人才紧缺,且难以满足市场需求,因此,需要用一种高效、快速的人工智能检测方法解决这一难题。
传统上的植物病害检测是依赖拥有专业知识的专家用肉眼对感染病害的植物叶片进行人为判断。然而,由于我国种植面积较大,这种方法过于依赖人工,不仅耗时费力,检测结果受人为影响较大,失去客观性。同时缺少大量的拥有专业知识的专家人才。
快速正确地检测植物病害对提高果蔬种植产业的发展十分重要,已成为近几年来农业发展的研究热点。在此背景下,人们研究了用各种光谱[1]和成像技术[2-3]来检测植物病害。Arnal等[4]考虑叶片和茎中可见症状,使用数字图像处理技术从可见光谱的数字图像中检测和分类植物病害。这种方法需要前期的辅助数据处理,不能对多种植物多种病害类别进行检测。
其次,该方法也需要精密仪器,不仅价格昂贵,体积过大不利于部署,同时检测效果不是特别好。随着硬件设备的快速发展,通过机器学习进行植物病害的自动检测逐渐应用广泛。Elangovan等[5]对植物病害图像进行加载、预处理、分割、特征提取、SVM分类等步骤,从而检测植物病害类别。支持向量机需要对数据进行复杂的预处理;并且该方法将检测分为多任务分别进行,使检测过程更加复杂。
传统的机器学习方法需要通过复杂的数据预处理和特征提取步骤,大大地降低了病害检测的效率,且深度学习在计算机视觉取得了巨大突破,研究者开始转向基于深度学习的病害识别与检测研究。Mohanty等[6]使用深度卷积神经网络来识别14种作物物种和26种疾病。Sun等[7]提出基于改进神经网络的植物叶片病害识别,通过对卷积层的输入数据进行批归一化处理,以便加速网络收敛。Durmu等[8]测试了两个深度学习网络:AlexNet、SqueezeNet,检测十个类别的番茄叶片图像,取得了较好的效果。Fuentes等[9]将VGG网络和ResNet(残差网络)两种深度特征提取器相结合,并且提出一种局部和全局注释和数据增强方式,提高训练过程的准确性。Zhou等[10]针对水稻病害图像噪声、图片模糊、检测精度低等问题,提出基于Faster RCNN和FCM-KM融合的水稻病害检测方法。该方法虽然有一个较高的精度,但双阶段目标检测算法检测速度慢。
因此,本文提出一种基于改进Yolov5的植物病害检测算法。为了更好地提取病害特征信息,通过增加辅助主干网,将辅助主干网的深层特征与主干网的浅层特征进行融合,获得特征提取能力更强的复合主干网。同时还修改原网络的置信度损失函数,使用Varifocal Loss代替原来的Focal Loss。最后,将改进后的Yolov5检测算法对苹果、番茄常见病害进行检测,验证本文改进的Yolov5植物病害检测模型的有效性。
1 Yolov5目标检测算法
Yolov5网络结构是由Input、Backbone、Neck、Prediction组成,具体结构如图1所示。

图1 Yolov5s结构图
Yolov5的Input部分是网络的输入端,采用Mosaic数据增强方式[11],对输入数据随机裁剪,然后进行拼接。Backbone是Yolov5提取特征的网络部分,特征提取能力直接影响整个网络性能。Yolov5的Backbone相比于之前Yolov4[12]提出了新的Focus结构。Focus结构是将图片进行切片操作,将W(宽)、H(高)信息转移到了通道空间中,使得在没有丢失任何信息的情况下,进行了2倍下采样操作,具体操作如图2所示。

图2 Focus结构图
Neck是采用了FPN+PAN结构,FPN[13]是自顶向下,将强语义特征传递下来;PAN[14]则是将浅层的定位信息传递给深层,增强多尺度定位能力。
Prediction是网络的输出端,Bounding Box损失函数采用的是DIOU_Loss[15],在原来IOU_Loss的基础上增加了中心点距离作为惩罚项,DIOU_Loss如式(1)所示。
(1)
式中:ρ()——两个中心点的欧几里得距离;
Bpre——预测框中心点坐标;
Bgt——真实框中心点坐标;
C——预测框和真实框最小外接矩形的对角线长度;
IOU——预测框与真实框的交集和并集的比值。
2 基于改进的Yolov5网络模型
改进后的Yolov5网络模型如图3所示。
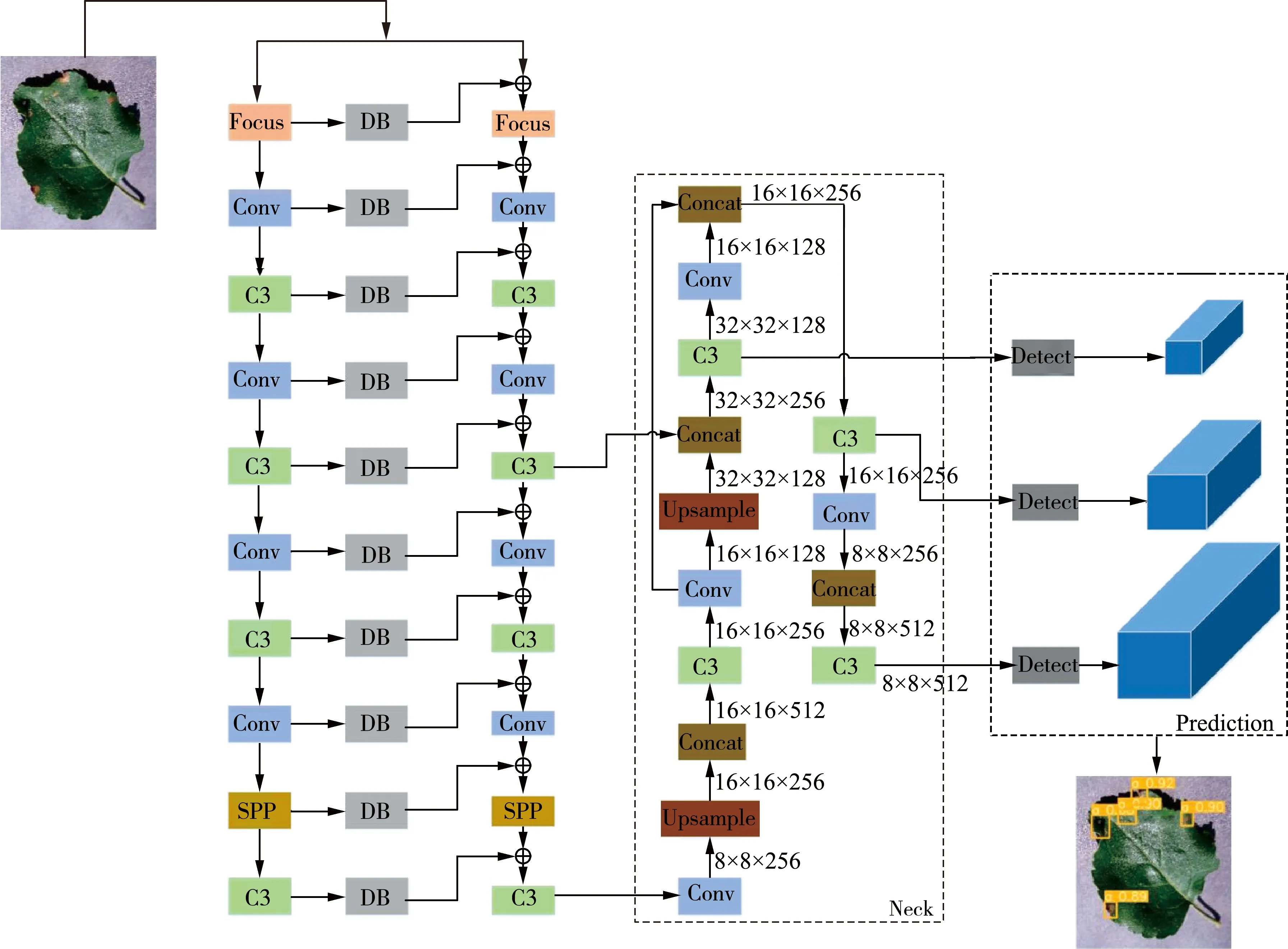
图3 改进后的Yolov5模型流程图
2.1 锚框重设
Yolov5采用的初始锚框是根据COCO数据集中物体真实框大小进行聚类生成。本试验的数据集小目标尺寸占据大多数。因此,初始的锚框大小不适合本数据集。为了提高对象框和锚框的匹配概率,本文采用K-means聚类算法[16]对数据集对象框大小进行聚类。对数据集进行聚类之后,可以为Yolov5的小、中、大三个尺度中分别都提供3个预设锚框,共9个预设锚框。具体生成锚框大小如表1所示。
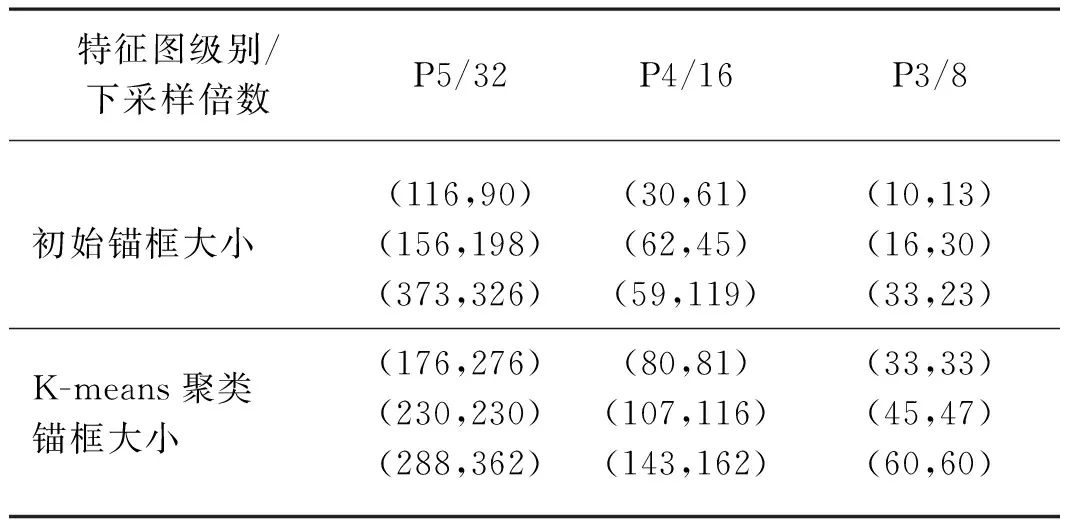
表1 植物病害数据集锚框大小对比Tab. 1 Comparison of anchor frame size of plant disease data set
K-means聚类算法主要分为3个步骤:首先,随机设置K个特征空间内的点作为初始聚类中心,本文设置K为9;其次,计算每个点到聚类中心点的距离,把每个点都聚类到离该点距离最近的聚类中心点;最后计算每个聚类中的所有点的平均值,并且将该平均值作为新的聚类中心点。然后不断循环第二步和第三步,直到聚类中心点不在移动为止。
2.2 Yolov5主干网结构改进
本文采用了复合主干网[17]的方法将Yolov5的主干网进行复合,增强主干网的特征提取能力,提升网络识别植物叶片病害的精度。
传统的卷积神经网络的主干网一般只有一个。然而复合主干网是将一个和原主干网相同的主干网进行连接,增加的主干网称为辅助主干网。原主干网设为B1,辅助主干网设为B2,主干网分为L1、L2、L3、…、Ln个模块。传统的主干网是将Ln-1层的特征图通过非线性变换H()输入到第Ln层,如式(2)所示。
FLn=HLn(FLn-1)
(2)
式中:FLn——第Ln层特征图,n≥1。
与传统主干网不同,复合主干网是以辅助主干网B2每个模块的输出作为原主干网B1中同级模块的输入。通过不断迭代将每个辅助主干网模块与原主干网进行连接,增强主干网特征提取能力。此操作可由式(3)表示。
FLn=HLn(FLn-1+G(FLn-1))
(3)
式中:G()——一种复合连接模块,由一个1×1的卷积层和上采样操作构成,其中卷积层的目的是用来减少通道数。
本文采用复合主干网来增强Yolov5网络模型,提高模型对植物病害特征提取能力,修改后的主干网,如图4所示。
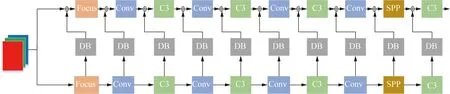
图4 Yolov5复合主干网
2.3 Yolov5损失函数改进
目前Yolov5计算类概率和目标得分的损失函数采用的是平衡交叉熵损失函数,同时可以调用Focal Loss损失函数[18]来计算损失,并且通过设置gamma值的大小,对损失函数进行调整。平衡交叉熵损失函数改善了样本不平衡问题,尽管平衡交叉熵损失改善了正、负样本间的不平衡,但由于其缺乏对难易样本的区分,因此没有办法控制难易样本之间的不均衡,平衡交叉熵损失函数如式(4)所示。
BCE(Pt)=-αtlog(Pt)
(4)
然而,Focal Loss损失函数可以调节正、负样本与难、易样本。为了改善正负样本的不均衡,引入了αt权重,提升精度;引入(1-Pt)γ用于调节难易样本的权重,从而降低了一个框被错误分类所带来的影响。Focal Loss损失函数公式如式(5)所示。
FL(Pt)=-αt(1-Pt)γlog(Pt)
(5)
本文针对苹果、番茄叶片病害斑点分布密集的特点,引入VarifocalNet[19]中的Varifocal Loss代替原本的Focal Loss来训练具有密集叶片病害区域的病害数据集。Varifocal Loss损失函数公式如式(6)所示。
(6)
这里的p表示预测得分,q是目标IOU分数。对于训练过程中的正样本,将q设为bbox和gt box之间的IOU值。然而,负样本的q则设为0,通过对缩放因子γ的调整,来减少负样本的影响。
3 试验结果与分析
3.1 试验环境
试验使用一台安装了Intel i7-9700k CPU@3.60 GHz,显存为11 GB的NVIDIA RTX2080Ti显卡,64 GB内存的Win10系统的电脑。软件环境包括Pytorch1.7.0、CUDA11.0、torchvision0.8.1。
网络训练过程中,网络模型的学习率设置为0.01,权重衰减设为0.000 5,以16张图片为一个批次进行300轮训练,采用动量为0.937的SGD优化器对参数进行优化,Focal Loss的参数γ设为1.5,热身次数(warmup)设置为3,预热初始偏差为0.1。
3.2 数据集制作
为了能更早地检测植物病害,及时减少植物病害带来的经济损失。本试验的数据集是从2018 AI Challenger比赛中的农作物病害检测数据集中用python程序提取总共7种常见病害的早期感染图像,共计1 395张图像。其中包含苹果三种常见病害,分别是黑星病(apple scab)、灰斑病(apple frogeve spot)、雪松锈病(cedar apple rust);番茄四种常见病害,分别是早疫病(tomato early blight fungus)、晚疫病(tomato late blight water mold)、叶霉病(tomato leaf mold fungus)、斑枯病(tomato septoria leaf spot fungus),如图5所示。本试验使用Labelimg工具对数据图像进行标注,标记叶片病害感染区域和类别信息,具体标注过程如图6所示。然后通过翻转、镜像、亮度调整、高斯滤波、旋转、缩放、平移等数据增强的方式,解决数据集不足的问题,增强训练效果。最终增强后的数据集共有7 326张图像,再按照6∶2∶2的比例划分为训练集、验证集、测试集。

(a) 苹果灰斑病 (b) 苹果黑星病 (c) 苹果雪松锈病

图6 植物叶片病害标签
3.3 评价指标
为了评价目标检测算法的性能,本试验采用了P、R、AP、mAP指标来进行综合评估。精确率P反应预测为正的样本中占有真正的正样本比例,可以间接评价模型误检率,如式(7)所示。召回率R反应检测出来的正样本占总的真样本的比例,可以间接评价模型漏检率,如式(8)所示。AP表示某一个类别的平均精确率,如式(9)所示。mAP表示所有类别的平均准确率,如式(10)所示。
(7)
(8)

(9)
(10)
式中:TP——模型预测为正的正样本;
FP——模型预测为负的负样本;
FN——模型预测为正的负样本。
3.4 试验结果分析
为了验证本文模型对苹果、番茄病害的有效性,将模型在提供的数据集上进行训练。改进Yolov5网络和对照网络训练结果如图7所示,最终训练好的改进模型各病害识别精度如表2所示。
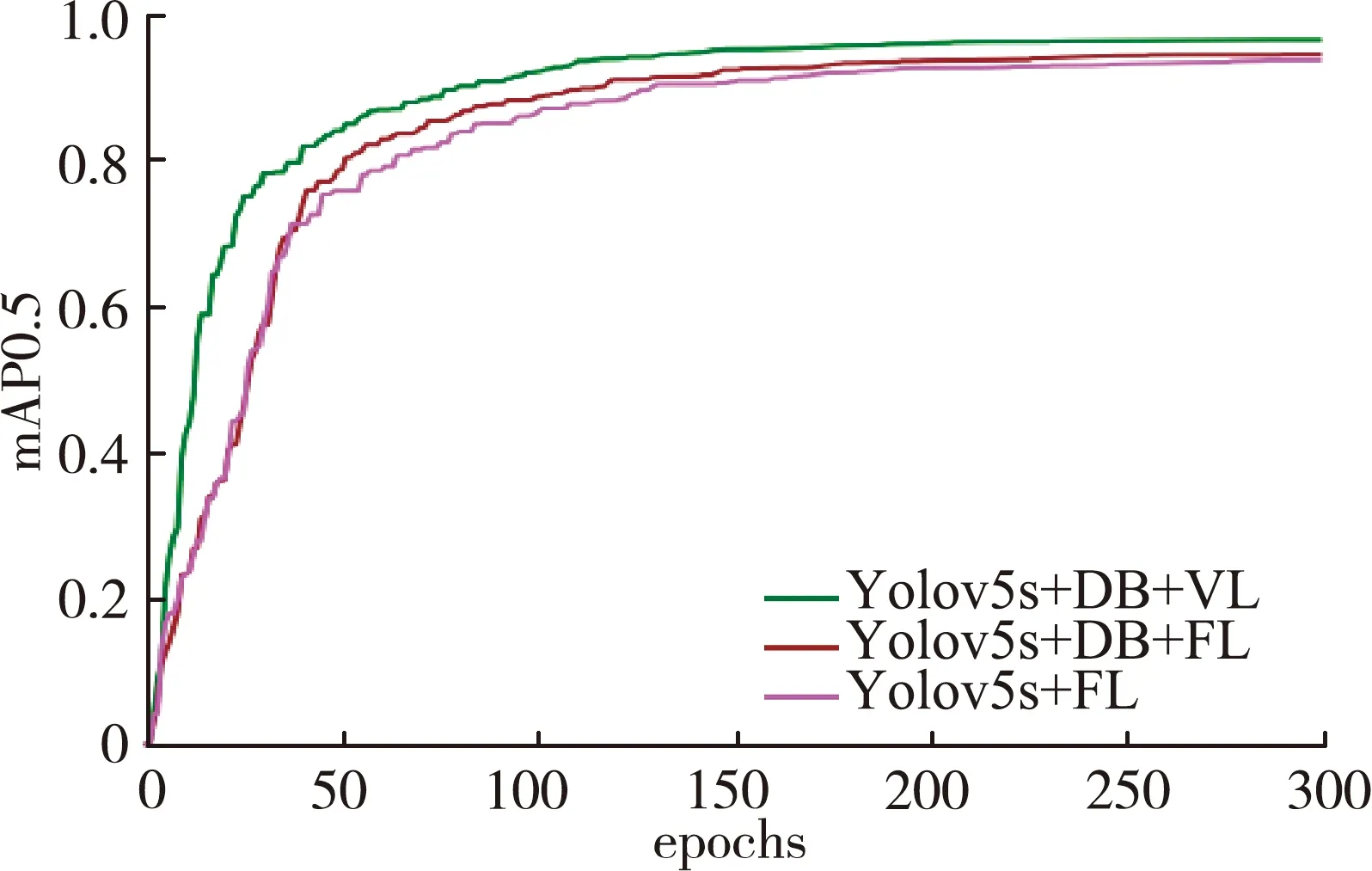
图7 改进网络训练过程对比

表2 不同病害的识别精度Tab. 2 Identification accuracy of different diseases
本文提出的改进Yolov5算法在主干网上采取复合主干网,增加了辅助主干网,将每个模块的输出作为主主干网同级模块的输入。复合主干网增强对病害特征的提取能力,与原网络对比实现精度提升,其对比结果如表3所示。

表3 引入复合主干网前后效果对比Tab. 3 Comparison of effects before and after the introduction of composite backbone network
由表3可得,加入复合主干网之后模型精确率比原来提高了0.5%,召回率从90.3%提升至91.0%,提高了0.7%,mAP@0.5提高了0.6%,mAP@0.5:0.95提高了3.6%。复合主干网有效的增强对叶片病害特征的提取能力,提高网络模型精度。这里mAP@0.5表示IOU的阀值取0.5,mAP@0.5:0.95表示IOU阀值从0.5到0.95每隔0.05取一次,计算不同阈值平均mAP。
Yolov5在置信度损失、分类损失采用的是Focal Loss,解决了样本不平衡问题。通过增加一个调制因子,减少易分类样本的影响,更加注重困难、分类错的样本。本文对置信度损失、分类损失进行改进,采用的是变焦损失函数(Varifocal loss),对正负样本的处理采用不对等的方式,使得训练过程中聚焦在高质量的样本。为了验证更换为变焦损失函数(Varifocal loss)的有效性,测试不同Loss函数的各项性能,如表4所示。

表4 损失函数效果对比Tab. 4 Loss function effect comparison
由表4可得,在复合主干网的Yolov5网络中引入变焦损失函数(Varifocal loss)可以使得网络识别精度得到较大的提升。复合主干网Yolov5的P从原来90.8%提升至94.0%,提高了3.2%;R从原来的91.0%提升至93.1%,提高了2.1%;mAP@0.5从原来的94.6%提升至95.7%,提高了1.1%;mAP@0.5:0.95从原来的67.7%提升至70.6%,提高了2.9%。结果显示,引入复合主干网对原模型性能具有一定的提升效果。通过添加复合主干网可以提升模型对病害检测效果。具体如图8所示,其中a和b分别表示苹果灰斑病、苹果黑星病。
为验证本文改进Yolov5算法性能,选择原始SSD算法[20]、Retinanet算法[21]、EfficientDet算法[22]、Yolov3算法[23]和本文的改进Yolov5算法在苹果、番茄叶片病害数据集上进行6组测试,如表5所示。
由表5可得,本文提出的改进Yolov5检测精度得到了一定程度的提高,说明本文改进方法的有效性。与原始的Yolov5算法相比,虽然检测单张图片的时间仅仅只增加了0.012 s,与其他网络检测速度相比依然有一定的优势,但是本文提出的改进方法mAP得到了1.7%的提升。相比其他网络,改进Yolov5具有很大的优势。各算法检测对比如图9所示。

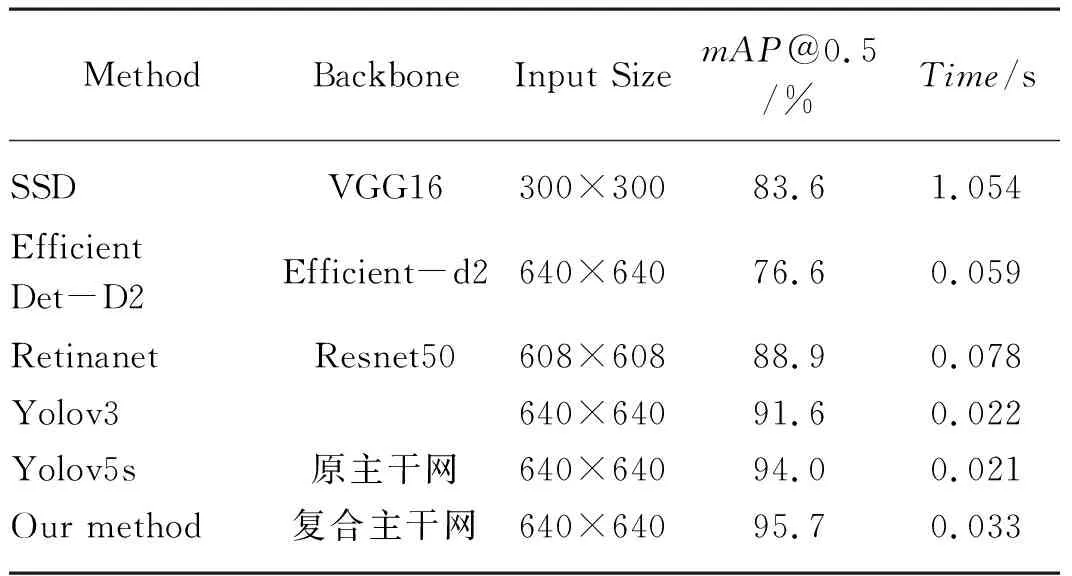
表5 各算法的mAP比较Tab. 5 mAP comparison of each algorithm

4 结论
本文提出一种基于改进Yolov5的植物病害检测算法,对苹果、番茄共7种常见病害区域进行检测。首先是采用复合主干网来增强网络对病害特征提取能力,然后在使用Varifocal Loss作为置信度损失函数。结果表明,本文方法能很好地检测苹果、番茄的病害区域,并且取得较高的检测性能。
1) 本文对Yolov5的主干网进行改进,增加与原主干网相同的辅助主干网,将辅助主干网各个模块的输出作为原主干网同级模块的输入,形成复合主干网,增强主干网对植物病害特征的提取能力。相比原来的网络结构,mAP提升了0.6%。
2) 本文在置信度损失、分类损失上将原来的Focal Loss替换为Varifocal Loss,对负样本进行衰减,对正样本的进行加权,使训练聚焦高质量的样本。结果表明,在复合主干网的Yolov5上,mAP进一步提高1.1%。
3) 本文提出的改进模型最终的检测结果mAP为95.7%,在原始模型的基础上提升了1.7%。在接下来的研究中,考虑叶片病害真实环境,对数据集进行扩充,减小网络模型的计算量,采用更加高效的网络结构,在轻量化的同时保证较高的准确率,利于部署移动设备。
