基于汉明权重分组的自适应查询树算法
2023-01-31侯培国张小贺田昊玮
侯培国,张小贺,田昊玮
(燕山大学 电气工程学院,河北 秦皇岛 066004)
0 引 言
射频识别(radio frequency identification,RFID)技术是一种以空间电磁波为传输媒介的自动识别技术[1-3]。但是在RFID系统中,由于所有的标签在传输数据时都是通过同一信道,极易发生标签之间的碰撞,进而导致阅读器无法正确地读取标签信息[4]。因此设计一种有效的防碰撞算法,高效、精准识别标签是当前RFID系统急需解决的问题。
目前,主要有基于ALOHA的概率性算法[5,6]和基于二进制树的确定性算法[7,8]用于解决标签的碰撞问题。基于二进制树的确定性算法,可以很好解决ALOHA算法出现的标签“饥饿”现象,具有100%的识别率[9],其中,最典型的方法就是查询树算法及其改进算法,如文献[10]提出的IACT算法结合了二叉树和四叉树算法的优点,有效减少了查询过程中产生的空闲时隙,但会增加碰撞时隙;文献[11]提出的PACT算法通过自适应方法和并行匹配机制减少了消耗的总时隙数,但对空闲时隙没有优化;文献[12]提出的BAT算法通过设计基于特征值的分组规则,提高了系统效率,但仍存在空闲时隙;文献[13]在文献[14]的基础上,结合ALOHA算法和查询树算法,提出的CF-AMTS算法是将标签映射到不同的时隙中,然后根据不同的碰撞因子调整搜索方法,从而减少查询过程中产生的空闲时隙,提高系统吞吐量;文献[15]提出的GMQT算法则是将标签均匀分为4组,然后利用分组后的碰撞信息对标签前缀进行预测,从而减少空闲时隙的产生。
本文在上述算法的基础上,针对如何减少空闲时隙进一步研究,提出了基于汉明权重分组的自适应查询树(adaptive query tree based on Hamming weight grouping,HAQT)算法,该算法只关注3个连续比特中的碰撞比特位,首先阅读器根据碰撞比特位的个数自适应地选择不同的查询机制,然后依据不同查询机制中的碰撞位特征推断标签可能存在的查询前缀,最后通过构建标签集识别系统中未被识别的标签。
1 算法描述
1.1 设计思想
为了消除查询过程中产生的空闲时隙,提高系统效率,HAQT算法对空闲时隙进行了优化。整体思路是通过调整标签的分组情况,在不增加新查询命令的基础上,自适应选择不同的查询机制,从而根据标签的碰撞信息实现对标签前缀的准确预测,最后通过构建标签集判断标签是否全部识别完成。
在查询过程中,阅读器每次仅关注3个连续比特中的碰撞比特位,然后依据碰撞比特位的个数决定采用何种查询机制,并根据不同查询机制中的碰撞位特征实现对当前标签前缀的准确预测。在该算法中有3种不同的查询机制,如下所示:
Type1:当从最高碰撞位开始只有一个碰撞比特位时,阅读器直接将碰撞位置为0和1,即可得到新的前缀。
Type2:当从最高碰撞位开始有两个碰撞比特位时,阅读器将这两个碰撞位提取出来,并执行式(1)~式(4),将碰撞位映射成一个4位且汉明权重为1的识别码,由于映射后的识别码和标签是一一对应的,因此阅读器只需要根据映射码的碰撞位就可以推断出标签的前缀组合
y1=x1&x2
(1)
(2)
(3)
(4)

Type3:当从最高碰撞位开始有3个碰撞比特位时,即XXX,则阅读器按照汉明权重原则对标签进行分组,并根据标签识别码中非0字符的数目计算汉明权重,然后将具有相同汉明权重的标签分为一组,于是得到标签识别码碰撞比特位的分组情况见表1。在标签分组完成后,阅读器首先判断标签的二进制组号是否发生碰撞,若组号发生碰撞,则将返回的分组信息进行映射,并根据映射后的碰撞信息确定标签前缀对应的组号;若组号没有发生碰撞,则阅读器可以直接判断出标签的组号;当组号确定后,将组号存入堆栈S。由于在00组和11组中的标签识别码只有一个,所以当存在00组和11组的标签时,阅读器根据组号就可以推断出存在的标签前缀为000和111;然而在01组和10组中存在多个标签识别码,所以当组号确定后,还需再次进行检测,在01组中比特1的个数只有一个,而在10组中比特1的个数有两个,因此阅读器根据01组和10组中标签识别码的组号和具体碰撞信息,就可以推断出相应的前缀组合。例如,在RFID系统中存在的标签是001和010,标签向阅读器发送自身识别码和组号RGC,阅读器接收到标签发送的信息为0XX和RGC=01,由于当RGC等于01时,汉明权重为1,即该标签的前缀中只有一个比特1,因此阅读器只需将碰撞位置为比特0和比特1,就可以推测出当前的标签前缀为001和010。
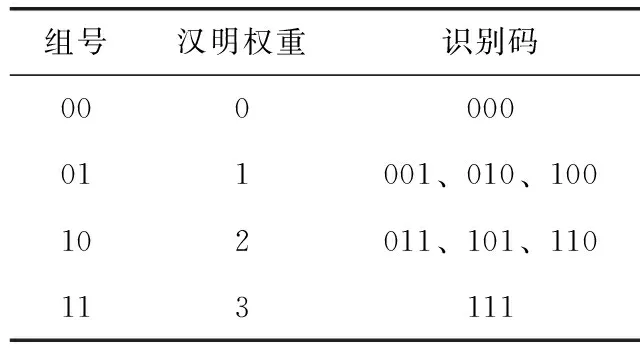
表1 汉明权重分组
1.2 相关指令
(1)Query(PRE)表示查询指令,PRE是标签前缀,阅读器发送Query(PRE)指令后,前缀与PRE相同的标签开始响应阅读器,并返回除前缀外的其余识别码信息;
(2)Query(PRE,RGC)表示查询指令,PRE是标签前缀,RGC是前缀组号,阅读器发送Query(PRE,RGC)指令后,前缀与PRE相同且属于RGC组的标签开始响应阅读器;
(3)PUSH(PRE)表示读写指令,发出此指令后阅读器将前缀PRE存入堆栈Q中;
(4)POP(PRE)表示读写指令,发出此指令后阅读器将前缀PRE从堆栈Q中弹出;
(5)‖表示位串联指令,将两组数据连接。
1.3 算法流程
HAQT算法的具体流程如图1所示。
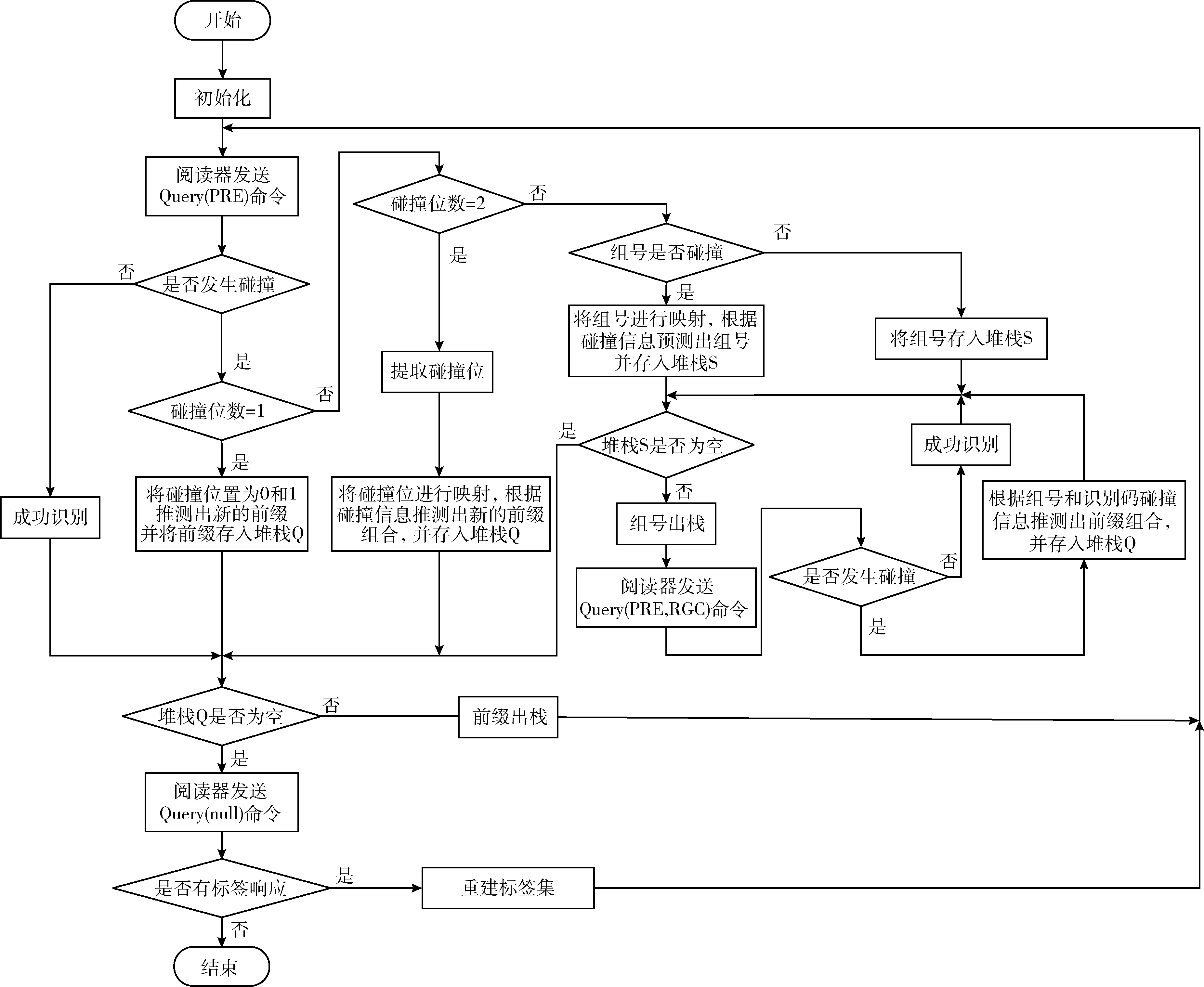
图1 HAQT算法流程
(1)初始化,将阅读器内部的堆栈Q和堆栈S置为空;
(2)阅读器发送Query(PRE)指令,标签接收该指令后,开始响应阅读器,由静默状态转向活跃状态,同时将自身的识别码发送给阅读器;
(3)阅读器判断标签是否发生碰撞,若发生碰撞,则执行步骤(4);若未发生碰撞,则说明标签识别成功,于是执行步骤(5);
(4)阅读器根据碰撞比特位的个数选择相应的查询机制推测标签的前缀pipi+1pi+2, 并发送PUSH(PRE‖pipi+1pi+2) 指令,将新产生的前缀PRE‖pipi+1pi+2存入堆栈Q,并跳至步骤(6);
(5)阅读器对标签的识别码进行读取,并将该标签置为静默状态,然后执行步骤(6);
(6)阅读器确定堆栈Q是否为空,若不为空,则阅读器发送POP(PRE)指令,将堆栈Q中的新前缀PRE出栈,并跳至步骤(2);若为空,则执行步骤(7);
(7)阅读器发送Query(null)指令,此时,若有标签响应,说明存在标签还没有被识别,于是重建标签集,并跳至步骤(2),继续识别未被识别的标签;若无标签响应,说明标签已经全部识别完成,则查询结束。
1.4 算法实例分析
下面分别通过一个实例来介绍3种不同的查询机制,如图2所示。

图2 HAQT算法不同查询机制流程
2 算法性能分析
在防碰撞算法中,时间复杂度(即消耗的总时隙数)和吞吐量是评判算法性能优劣的关键指标。因此下面分析了随着标签数目变化时,多叉树算法消耗的时隙数目与吞吐量的变化情况。假设RFID系统中存在m个标签,通过文献[16]可以得到一个B叉树消耗的总时隙数为
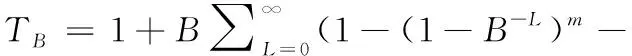
(5)
碰撞时隙数为
(6)
空闲时隙数为
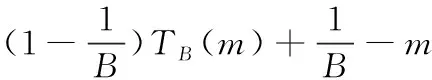
(7)
在标签的查询过程中,主要存在以下情况:
(1)当没有碰撞位时,消耗的总时隙数为
TType0(m)=m
(8)
(2)当只有一个碰撞比特位时,不会产生空闲时隙,消耗的总时隙数为
TType1(m)=T2(m)
(9)
(3)当有两个碰撞比特位时,通过映射可以有效的消除空闲时隙,消耗的总时隙数为
(10)
(4)当有3个碰撞比特位时,通过对其进行分组,可以消除空闲时隙,分组后消耗的时隙数为
(11)
然而当组号发生碰撞的时候,需要二次发送命令才能确定相应的前缀,为了更加准确进行理论分析,于是对二次发送命令消耗的时隙数进行拟合,如图3所示。
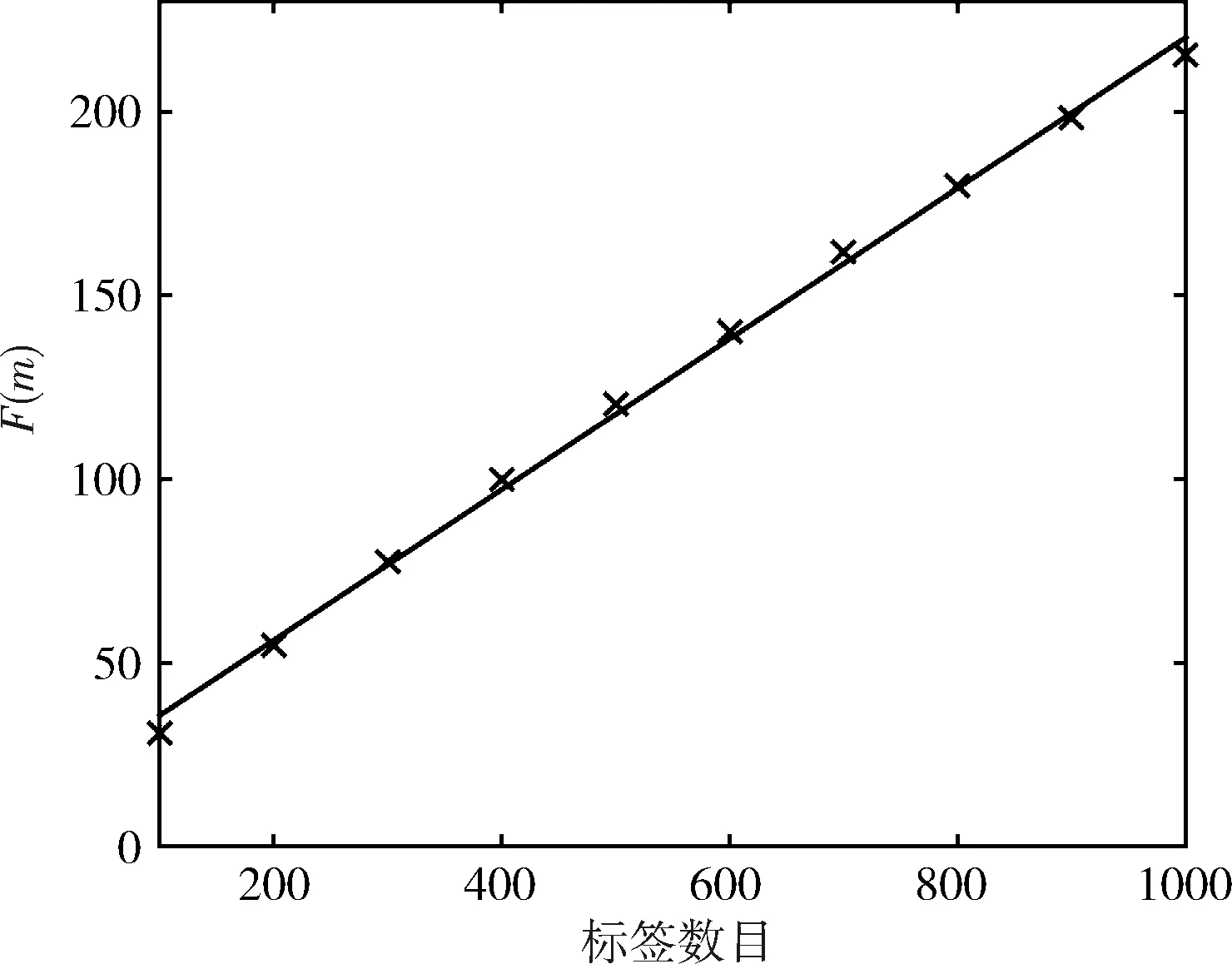
图3 仿真拟合
经过对二次发送命令消耗的时隙数进行拟合,得到二次发送命令消耗的时隙数F(m)为
F(m)=0.2052m+15.066
(12)
整理后得到在Type3查询方式下消耗的总时隙数为
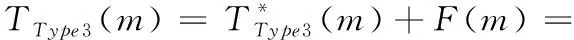
(13)
下面针对在不同查询方式中标签发生碰撞的概率进行计算,假设当RFID系统中存在i个标签时,其中任意一个比特不发生碰撞的概率为
(14)
任意一个比特发生碰撞的概率为
(15)
在连续的3个比特中,没有发生碰撞的概率为
(16)
在连续的3个比特中,从最高碰撞位开始,有一个碰撞比特位的概率为
(17)
在连续的3个比特中,从最高碰撞位开始,有两个碰撞比特位的概率为
(18)
在连续的3个比特中,从最高碰撞位开始,有3个碰撞比特位的概率为
(19)
由于HAQT算法是根据每3个比特中碰撞比特位的个数自适应地选择不同的查询机制,因此得到HAQT算法消耗的总时隙数为
THAQT(m)=P0TType0(m)+P1TType1(m)+
P2TType2(m)+P3TType3(m)
(20)
得到吞吐量为
(21)
3 仿真结果与分析
在本文中,利用Matlab2014b平台对RFID系统的通信过程进行了模拟仿真。假设该系统为理想信道,标签在阅读器范围内均匀分布,并且参考EPC C1G2标准,随机生成数量从100到1000变化,长度为96位的唯一标签识别码,最后结果取50次仿真的平均值。下面通过仿真定量分析了HAQT算法、BAT算法、CF-AMTS算法和PACT算法消耗的总时隙数、吞吐量和通信复杂度的变化情况。
为了验证理论分析的正确性,首先对HAQT算法的理论分析和仿真实验进行了比较,如图4(a)和图4(b)所示。通过图4(a)和图4(b)可以看到,在查询过程中,该算法消耗的总时隙数和吞吐量的理论值和仿真值基本吻合,其吞吐量的最大相对误差不超2.8%,在误差允许的范围内,所以可以认为该理论分析和仿真实验是一致的。
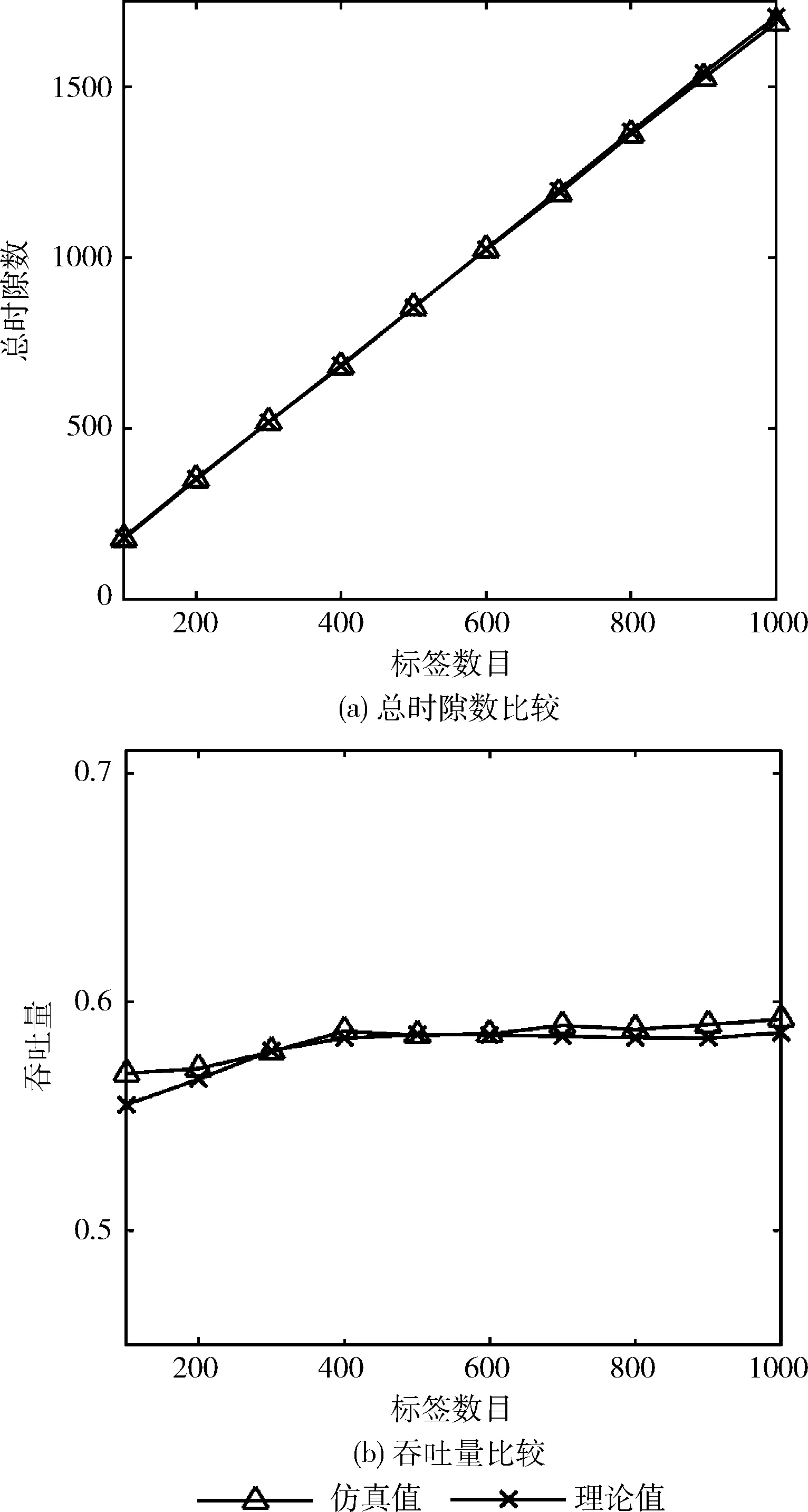
图4 理论值和仿真值比较
图5为HAQT算法、BAT算法、CF-AMTS算法和PACT算法的总时隙数比较。由图5(a)可知,在识别相同数量的标签时,BAT算法、CF-AMTS算法和PACT算法消耗的总时隙数均大于HAQT算法消耗的总时隙数,且随着标签数量的增加,HAQT算法的优势会更加明显。在标签数量等于1000时,该算法消耗的总时隙数目仅为1678,这主要是由于HAQT算法通过采用自适应的查询方法,实现了对标签前缀的准确预测,通过减少空闲时隙降低了消耗的总时隙数。空闲时隙的变化情况如图5(b)所示,可以看出HAQT算法完全避免了空闲时隙的产生。
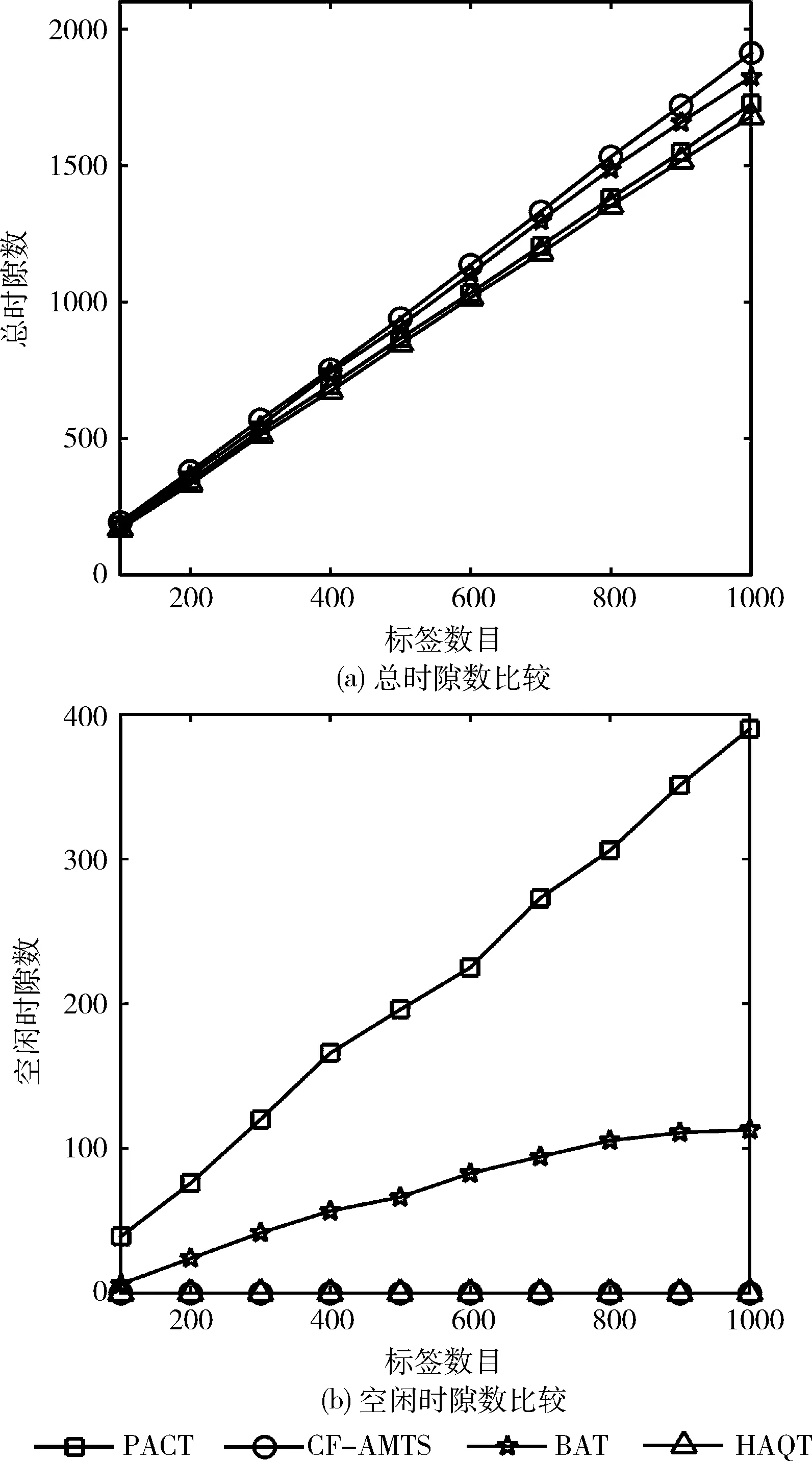
图5 各种算法消耗的时隙数比较
图6为HAQT算法、BAT算法、CF-AMTS算法和PACT算法的吞吐量比较。由图6可以看出,HAQT算法的吞吐量维持在0.60左右,相比于 PACT算法提升了1.7%,相比于BAT算法提升了11.1%,相比于CF-AMTS算法提升了17.6%。

图6 各种算法吞吐量比较
图7为HAQT算法、BAT算法、CF-AMTS算法和PACT算法的通信复杂度比较。从图7可以看到HAQT算法的通信复杂度最低,当待识别标签数量为1000时,该算法的通信复杂度为2.26×105,这是由于HAQT算法通过调整标签的分组方法,减少了无效数据传输。
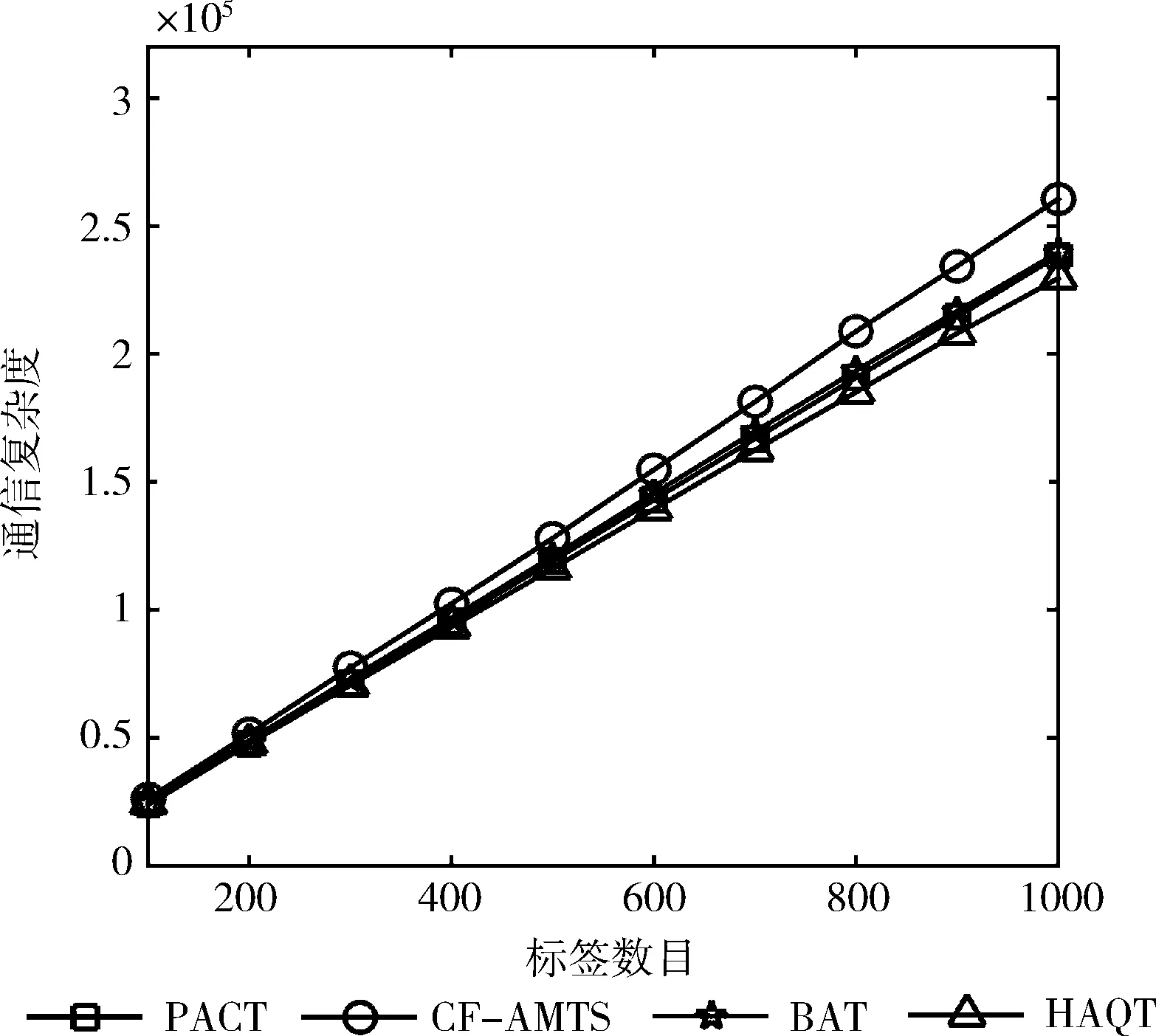
图7 各种算法通信复杂度比较
表2显示了不同算法的性能比较。从中可以看到,HAQT算法通过根据碰撞比特位的个数自适应的选择不同的查询机制,并采用汉明权重方法对标签前缀进行分组,实现了对标签前缀的准确预测,减少了查询过程中产生的空闲时隙,从而使该算法性能明显的优于其它算法。另外,该算法通过重建标签集的方式识别上一个阶段中未被识别的标签,因此还具有一定的抗捕获作用[17]。
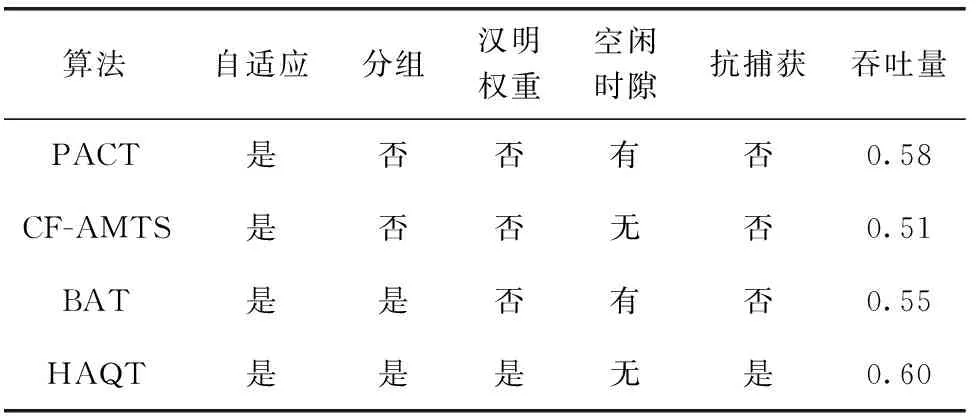
表2 不同算法整体性能比较
4 结束语
在本文中结合分组思想和查询树算法,提出一种基于汉明权重分组的自适应查询树算法,首先根据每3个比特中碰撞比特位的个数自适应地选择不同的查询机制,然后依据不同查询机制中的碰撞位特征推断标签可能存在的查询前缀,从而降低查询过程中产生的空闲时隙,最后通过构建标签集,判断标签是否全部识别。仿真结果显示,HAQT算法能够消除查询过程中产生的空闲时隙,且消耗的总时隙数、吞吐量和通信复杂度均优于PACT、BAT和CF-AMTS算法,吞吐量最高可以达到0.60,且具有一定的抗捕获作用,适合在大规模标签的RFID系统中应用。下一步的工作是对该算法的抗捕获功能进一步改进,并进行定量分析。
