引入积分补偿的四旋翼确定性策略梯度控制器
2023-01-31郑建华
孙 丹,高 东,郑建华+,韩 鹏
(1.中国科学院 国家空间科学中心,北京 100190; 2.中国科学院大学 国家空间科学中心,北京 100190)
0 引 言
四旋翼灵活方便的特点使其被广泛应用于各领域,智能化和自主性的要求越来越高,因此有必要对四旋翼的自主控制进行研究。其中强化学习(reinforcement learning,RL)与最优控制、自适应控制关系密切[1,2],不需要被控对象准确的数学模型,而是通过“试错”探索,不断优化得到最终的控制策略,为实现无人机智能化控制提供了新途径。
已有学者将RL相关算法引入到了无人机控制中。Koch等[3]利用RL构建智能飞行控制系统,用于无人机的内环姿态控制,其精度和性能优于传统的PID控制器。Wang等[4]利用RL原理进行运动规划,实现不确定环境和有噪声情况下多无人机的避撞。Zeng等[5]利用深度RL进行无人机的轨迹优化。Rodriguez-Ramos等[6]利用RL中深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法实现无人机在移动平台上的自主降落。DDPG算法利用神经网络进行值函数逼近,直接对价值期望求导,不需要选取最优动作,适合四旋翼这种连续动作状态空间的情况,但是常规的DDPG算法在进行四旋翼位置控制时,容易出现静差。关于该误差产生的原因,有学者指出,RL中利用贝尔曼方程推导出的动作值函数,是有偏的[7]和非一致的[8],其中Hesselt等[7]证明了贝尔曼等式中的最大值操作将偏差引入到了动作值估计中,从而导致了过估计。Zhang等[9]表明RL中状态、动作值估计的分布是偏斜的,使智能体倾向于选择预期收益较低且被高估的可能性较高的策略,从而限制了算法的性能。为了降低算法中值估计误差产生的影响,实现四旋翼位置的准确跟踪,Tyler Lu等[10]提出了一个本地备份流程用来确保全局一致性,从而减小估计偏差带来的影响,但是该方法会导致算法复杂度的提高,不利于在四旋翼控制器中部署。
针对该问题,本文借鉴传统控制方法中积分的思想,提出了带积分补偿器的改进深度确定性策略梯度(deep deterministic policy gradient with integral compensator,DDPG-IC)控制器,用于四旋翼位置姿态的自主稳定控制。本文首先介绍了四旋翼模型,然后简单介绍了RL与DDPG算法的原理,分析了基于普通DDPG算法的四旋翼自主控制器在位置控制中容易产生静差的原因,并将传统控制中积分补偿的思想引入RL算法中,提出了DDPG-IC算法,最后建立仿真环境,验证了基于DDPG-IC算法的四旋翼自主控制系统在消除位置静差方面的有效性。
1 四旋翼模型
本节建立四旋翼模型的目的是产生交互数据用于控制算法的训练,不会对控制算法的设计产生影响。建模过程中涉及两个坐标系,分别为地球固连坐标系和机体坐标系。地球固连坐标系 (E,XE,YE,ZE) 用于研究四旋翼相对于地面的运动,以无人机起飞位置作为坐标原点E,XE指向东,ZE指向地,YE的方向由右手定则得到。机体坐标系 (B,XB,YB,ZB) 与四旋翼固连,其原点B取在四旋翼的重心位置,3个坐标轴的指向与地球固连坐标系一致,如图1所示。
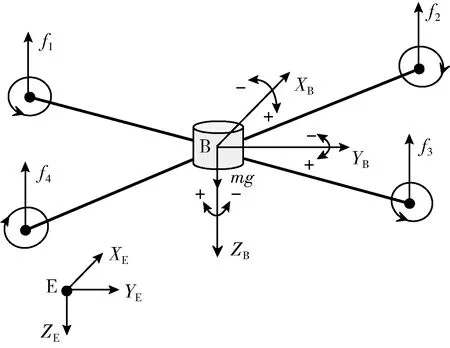
图1 四旋翼及坐标系
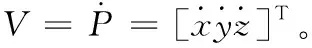
(1)
(2)

对四旋翼进行受力分析,并通过拉格朗日方法对模型进行简化和线性化处理,得到简化后的四旋翼无人机模型为[12]
(3)
其中,m表示四旋翼质量,I1~I3为四旋翼的转动惯量,K1~K6为阻力系数。
2 基于DDPG-IC算法的四旋翼控制器设计
2.1 基于常规DDPG算法的四旋翼控制器设计
强化学习一般将环境建模成马尔科夫决策过程(Markov decision process,MDP),表示为M=(S,A,P,R,γ)[13], 其中S和A分别表示有限状态集合和有限动作集合,R(s,a) 为即时奖励,γ∈[0,1] 为折扣因子,用来计算累积回报,p(st+1|st,at) 为状态转移概率,它具有马尔科夫特性,即
p(st+1|s1,a1,…,st,at)=p(st+1|st,at)
(4)
定义策略为状态到动作的映射,用符号π表示,定义状态值函数Vπ(s)为从状态s开始采用策略π后获得的累积回报的期望值,即
Vπ(s)=E[∑t≥0γtR(st,π(st))]
(5)
在状态s处依据策略π采取动作a后获得的累积回报为动作值函数,即
Qπ(s,a)=E[∑t≥0γtR(st,at)]
(6)
经推导,动作值函数遵从贝尔曼期望等式
Qπ(s,a)=Eπ[Rt+1+γQπ(st+1,at+1)]
(7)
强化学习的目标是优化策略使得累积奖励J(π)=∑t≥0γtR(st,π(st)) 最大,DDPG算法即是强化学习中进行策略优化的一种算法。
四旋翼的控制信号由控制策略产生,将控制策略表示为函数Aμ,其中μ是参数,策略函数的优化方向为累积奖励增大。由DDPG算法可知,策略的梯度为
(8)
其中,ρAμ为服从确定性策略的状态分布,QAμ(s,a) 为状态动作值函数值,但是该值难以准确获得,因此用一个近似函数Qω(s,a) 进行逼近,ω为参数,该近似函数称为评价函数。评价函数通过最小化时间差分(temporal-difference,TD)误差进行优化,TD误差δt定义为
δt=rt+γQω(st+1,Aμ(st+1))-Qω(st,at)
(9)
最小化TD误差的一个简单方法是随机梯度下降
(10)
其中,αω为学习速率。动作函数中的参数更新为
(11)
其中,αμ为学习速率,式中用评价函数替换掉原来的动作值函数真值。
神经网络的训练要求数据是相互独立的,但是强化学习的数据是按照顺序采集的,数据之间具有很强的关联性。为了打破数据之间的关联性,增强算法的稳定性和效率,设置经验回放缓存区(replay buffer)和独立的目标网络[14]。
2.2 位置控制存在静差的原因分析
训练过程中发现,基于常规DDPG算法的四旋翼控制器在进行位置控制时存在静差,四旋翼最终稳定的位置与期望位置之间始终存在一个误差。该静差出现的一个主要原因是强化学习中得到准确的值函数估计很难。DDPG算法使用神经网络来估计值函数,并且通过最大化Q函数来优化策略[15],因此,当值函数的估计存在误差时,算法的性能和收敛性会受到很大影响。Lillicrap等[16]通过仿真实验,比较了经过训练之后的DDPG算法得到的值估计和真实回报的差别,发现在简单任务中,DDPG估计的回报值与真实回报之间基本没有系统误差,但是任务越复杂,DDPG中的Q估计越不准确,与真实回报之间的系统误差越大。从式(8)中可以看出,DDPG算法中策略梯度的更新依赖状态动作值函数QAμ(s,a) 的估计值Qω(s,a), 如果学习到的该估计值不准确,那么策略网略的梯度更新方向就存在偏差[17],导致算法无法收敛到全局最优解。值函数估计不准确在简单系统或者是离散动作空间中影响不大,但是对四旋翼这种复杂的连续状态动作空间的系统会产生较大的影响,导致位置控制出现静差。同时,DDPG算法中采用的TD学习、异步策略(off-policy)和非线性函数估计器会产生联合效应,将方差和偏差引入到了估计器中[7]。
此外,奖励函数的设置对策略优化的影响大。强化学习的目标是最大化累积奖励,因此奖励函数在强化学习算法中具有非常重要的作用,影响到算法的学习效果。通常,奖励函数根据具体任务人工进行设置,若奖励函数的设计不适合该任务的要求,那么最终学习到的策略在很大程度上无法满足任务的要求。
为了消除静差,提高四旋翼控制系统的准确性,对算法的训练过程进行调整,如增加训练步数、更改神经网络结构等,能够在一定程度上改善控制器的性能,减小位置静差,但是无法将其消除;构造更合适的奖励函数也能减小位置跟踪静差,但是需要仔细调整其中的系数,算法的推广性不好。由于传统控制中普遍使用积分器解决静差问题,本文借鉴其中思想,尝试将积分补偿引入到DDPG算法中,提出了DDPG-IC算法,用于解决DDPG算法在四旋翼位置控制中存在的静差问题,同时降低算法受奖励函数设置的影响程度。
2.3 基于DDPG-IC算法的四旋翼控制器设计
常规四旋翼DDPG控制器中将位置误差作为状态,基于DDPG-IC算法的控制器引入积分器,将过去时刻的误差进行累积作为补偿后的状态误差,即
(12)
其中,set为t时刻的状态误差,sci为补偿后的状态误差,β为系数,数值一般较小。这样,输入到策略网络中的状态包含了当前的状态误差和过去的累积误差,如果静差存在,策略网络会持续输出动作减小静差,直到静差为零,系统取得平衡。直接将积分补偿后的状态误差添加到原始状态空间中,会增加状态空间的维度,增大算法的复杂度和探索的难度,所以采用积分补偿后的状态误差替换原来的状态误差,使得状态空间包含累积误差的同时,不会增加状态空间的维度。
但是积分补偿器的引入一定程度增加了系统的惯性,会增长控制器的调节时间,同时,式(12)定义的积分补偿状态误差包含当前误差与过去所有累积误差,随着时间和控制回合步数的增加,累积误差的作用会越来越大,可能会导致控制算法过分考虑旧数据的累积误差而降低对当前状态误差的关注,从而降低算法的性能。针对该问题,引入权重因子λ,用于调节过去时刻误差在累积误差中的比重,因此积分补偿后的状态误差变为
(13)
其中,λ∈[0,1], 该系数的加入使得以前时刻的误差的作用逐渐降低,保证了算法对近期状态误差的关注,使得算法在关注当前效果和过去累积误差上达到平衡。式(12)是式(13)在λ=1时的特殊情况。
基于DDPG-IC算法的控制器结构如图2所示,控制器的整体框架采用策略-评价(actor-critic)构架,既要满足控制要求,又要保证四旋翼控制器的训练速度,因此需要选用合适的神经网络构成控制策略和评价函数。策略网络Aμ由包含两个隐藏层的全连接神经网络构成,每个隐藏层含有128个神经元,隐藏层的激活函数为ReLU函数。该策略网络接收补偿后的四旋翼状态误差,输出4个控制信号,为了保证输出的控制信号符合四旋翼的要求,该网络的输出层采用tanh激活函数。评价网络Qω(s,a) 的具体构成如图2所示,由包含两个隐藏成的全连接神经网络构成,每个隐藏层含128个神经元、采用ReLU激活函数,该网络的输入量为四旋翼当前的状态和4个控制信号,其中,四旋翼状态直接作为输入量输入,而4个控制信号在第一个隐藏层中输入。评价网络的输出层采用线性激活函数,输出Q函数的近似值,从而得到策略梯度,用于策略网络的更新。积分补偿器根据式(13)实现,其中参数β的取值为0.01。
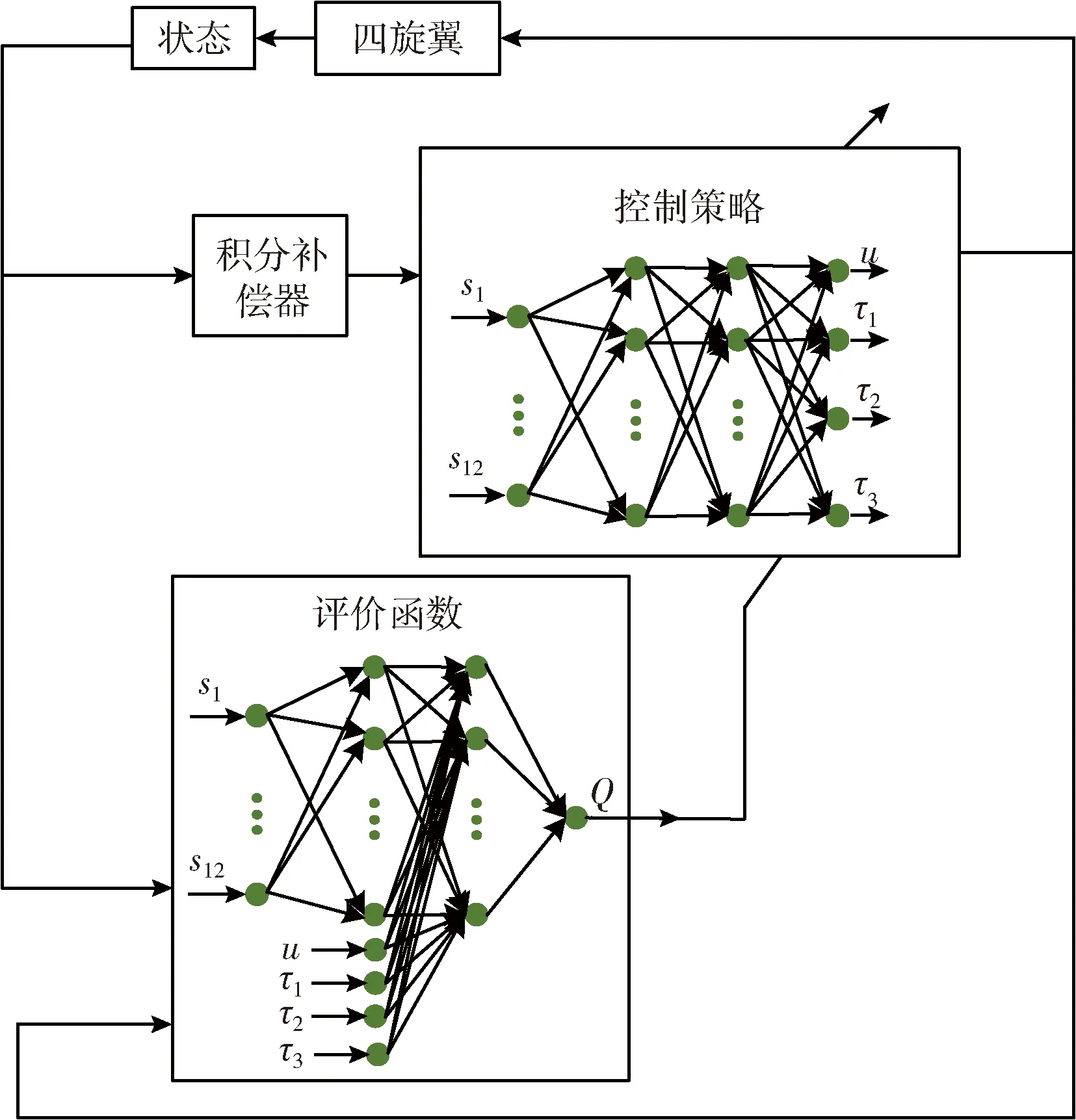
图2 基于DDPG-IC算法的四旋翼控制器结构
在强化学习的过程中,自主控制器根据四旋翼当前的状态st产生控制信号,该控制信号记作at,at作用于四旋翼,四旋翼给出下个状态st+1和奖励值rt,将该数据 (st,at,rt,st+1) 存放到经验回放缓存区中。经验缓存区有容量限制,结构类似于队列,数据按顺序放入,当里面数据存满后,新的数据放入,最早的数据移除。后期自主控制器需要学习优化时,再随机采样从该缓存区中抽取数据,用于神经网络的训练。这种经验回放的方法能够打破数据之间的关联性,促进神经网络训练的收敛和稳定。
评价网络通过最小化式(9)所示的TD误差进行优化,可以看到,在优化时利用了下个时刻的Q值,该值由同一个评价网络产生,容易导致数据之间的关联性,从而使训练不稳定,因此设立单独的目标函数。设置目标策略网络Aμ′, 参数为μ′,结构与图2中的策略网络Aμ的结构一致,只是参数μ′的更新频率低于μ的更新频率;设置目标评价网络Qω′(s,a), 参数为ω′,结构图2中的评价网络Qω(s,a) 的结构一致,参数ω′的更新频率低于ω。目标网络的参数更新公式为
μ′←ημ+(1-η)μ′
(14)
ω′←ηω+(1-η)ω′
(15)
其中,η<1。因此,评价网络参数的更新变为
(16)
其中
(17)
yi=ri+γQω′(si+1,Aμ′(si+1))
(18)
动作函数中的参数更新公式为
(19)
(20)
总结基于DDPG-IC算法的四旋翼控制器的训练学习过程见表1。

表1 基于DDPG-IC的四旋翼控制器优化算法
3 仿真实验
利用上节提出的基于DDPG-IC算法的控制器,对四旋翼进行数值仿真研究,验证积分补偿的加入对位置跟踪静差的抑制作用。仿真采用的四旋翼模拟器根据式(3)进行编写,集成到OpenAI gym的环境中,四旋翼模型的相关参数设置见表2。仿真实验在Ubuntu 16.04操作系统中运行,所有仿真程序采用Python编写,神经网络用TensorFlow实现,神经网络的训练利用Adam优化器实现,仿真过程中没有采用并行计算。本文提出的基于DDPG-IC算法的控制器并不需要对象模型,仿真中的模型知识用来模拟学习过程中与智能体进行交互的外部环境,而不直接提供任何信息。
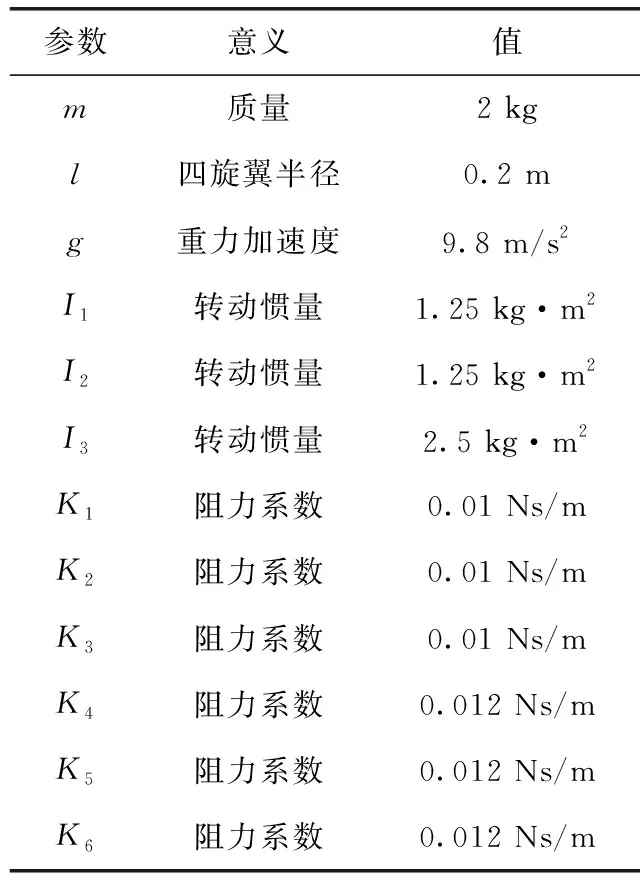
表2 四旋翼动力学模型参数设置
考虑到实际飞行中的安全因素,在仿真实验中给状态量设置安全范围,设定四旋翼3个姿态角的变化范围为[-45°,45°],设定四旋翼的活动范围为长宽高都为10 m的立方体。四旋翼的初始状态从安全范围内随机取得,控制目标是让四旋翼从任意初始状态稳定飞行至目标位置并实现悬停。
控制器结构采用策略-评价(actor-critic)构架,利用算法1对控制器进行训练优化,相关训练参数见表3。在训练的过程中,设置参数done,用来表明四旋翼的状态是否超过了设置的安全范围。如果四旋翼的实际位置和姿态超出了设定的安全范围,该回合训练停止(参数done=True),所有状态重新初始化开始下个回合的训练;如果控制过程中四旋翼的位置和姿态没有超出范围(参数done=False),会转移到下个状态继续进行训练。为了让算法充分地进行探索,同时提高训练效率,设置一个回合的学习最多持续1000步,之后重新初始化所有状态,开始新的训练回合。整个训练过程结束后,将控制器的结构和参数保存下来,用于验证控制器在四旋翼定点悬停任务中的控制精度。
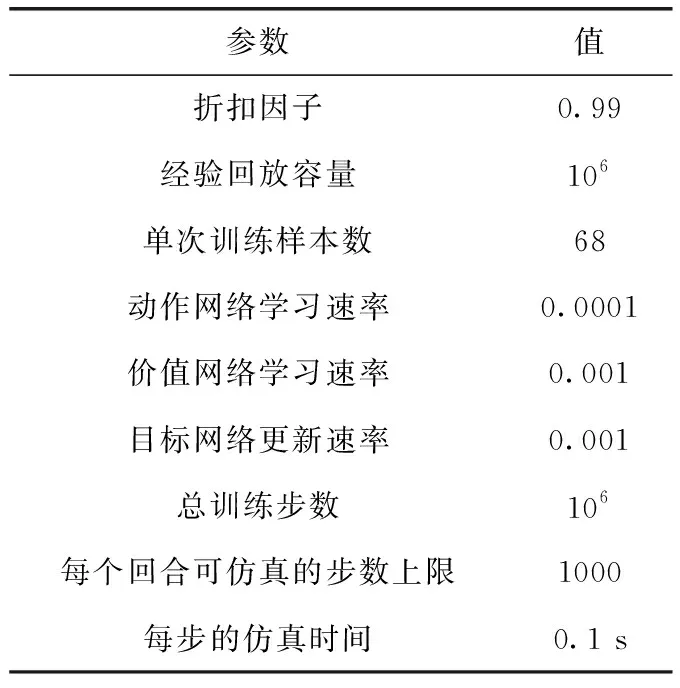
表3 控制器训练参数设置
分别搭建基于DDPG算法、基于DDPG-IC(λ=1)算法和基于DDPG-IC(λ=0.8)算法的四旋翼自主控制系统,3种控制器的结构一致,采用的网络模型一样,用3种算法分别从零开始训练控制策略,训练106步之后,将算法的结构和参数保留下来,在允许范围内随机给出四旋翼的初始状态,仿真50 s,验证3种控制器的控制效果。
由于奖励函数的设置对算法性能的影响大,为了将四旋翼控制到期望位置上,奖励函数应该包含四旋翼状态误差,同时为了防止控制力的震荡,将控制力也加入奖励函数。因此,将奖励函数设置为
在此设置下,经过训练的3种控制器的控制效果如图3所示,控制信号的变化如图4所示,其中,实线表示基于DDPG算法的控制器,虚线代表基于DDPG-IC(λ=1)算法的控制器,点线为基于DDPG-IC(λ=0.8)算法的控制器。从图3中可以看到,在没有人工推导动力学模型的前提下,3种控制器通过不断优化,自主学习到了稳定控制四旋翼的控制策略。但是,基于常规DDPG算法的控制器在位置控制上明显存在静差,x、y、z这3个方向上的位置误差分别为0.5 m, 0.7 m, 0.6 m,而两种基于DDPG-IC算法的控制器能够将四旋翼稳定控制到期望位置,位置误差为0,表明积分补偿的引入能够有效消除静差。图4表明,两种基于DDPG-IC算法的控制器输出的控制信号明显比基于常规DDPG算法的控制器更加平稳,表明积分补偿的引入有利于增强控制器的稳定性。
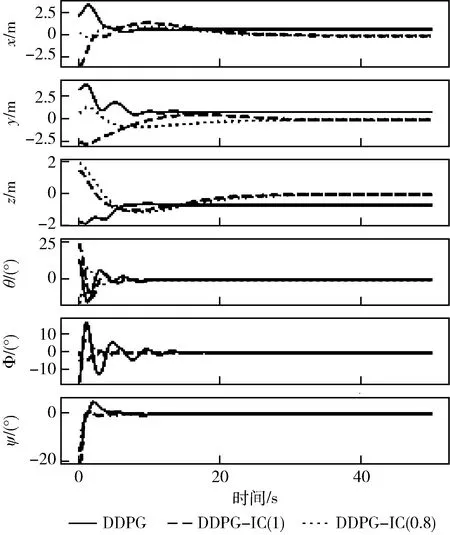
图3 控制器作用下的位置姿态响应曲线
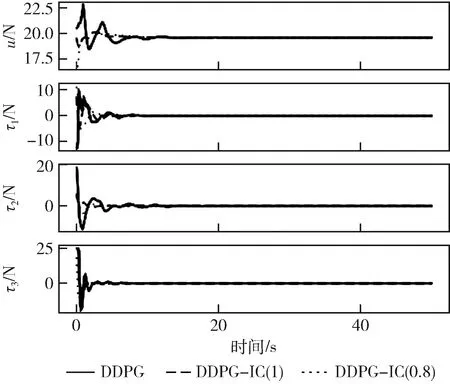
图4 控制器信号
将奖励函数设置为如下形式
该设置用于验证奖励函数粗糙的情况下算法的性能,控制器的控制效果和控制信号分别如图5和图6所示。图5中实线所代表的基于常规DDPG算法的控制器控制效果差,位置和姿态响应曲线没有收敛,说明在奖励函数粗糙的情况下,基于常规DDPG算法的控制器没有学习到稳定的控制策略。基于DDPG-IC(λ=1)算法的控制器在图中用虚线表示,它的控制效果优于常规DDPG控制器,姿态控制没有震荡,说明累积误差的加入增强了算法的稳定性;但是DDPG-IC(λ=1)控制器的收敛速度太慢,在仿真的50 s时间内都没有将位置控制到期望位置。该问题产生的原因是累积误差的比重太大,使得控制器过度关注累积误差而导致控制器控制速率降低,控制性能下降。图5中点线代表的DDPG-IC(λ=0.8)控制器能够在短时间内将无人机稳定控制到期望位置,该控制器利用参数λ对过去的误差进行衰减,保证了当前误差与过去累积误差的平衡,使得控制器仍然能够学习到稳定控制无人机姿态位置的控制策略,同时减少调节时间。此外,与图3中的响应曲线相比,在奖励函数变差的情况下,基于常规DDPG算法的控制器的控制效果明显变差,甚至没有稳定收敛,而两种基于DDPG-IC算法的控制器受影响较小,特别是DDPG-IC(λ=0.8)控制器,两种奖励函数设置之下的响应曲线基本不变,表明积分补偿的引入能够降低学习算法对奖励函数设置的要求,提高了学习算法的性能。
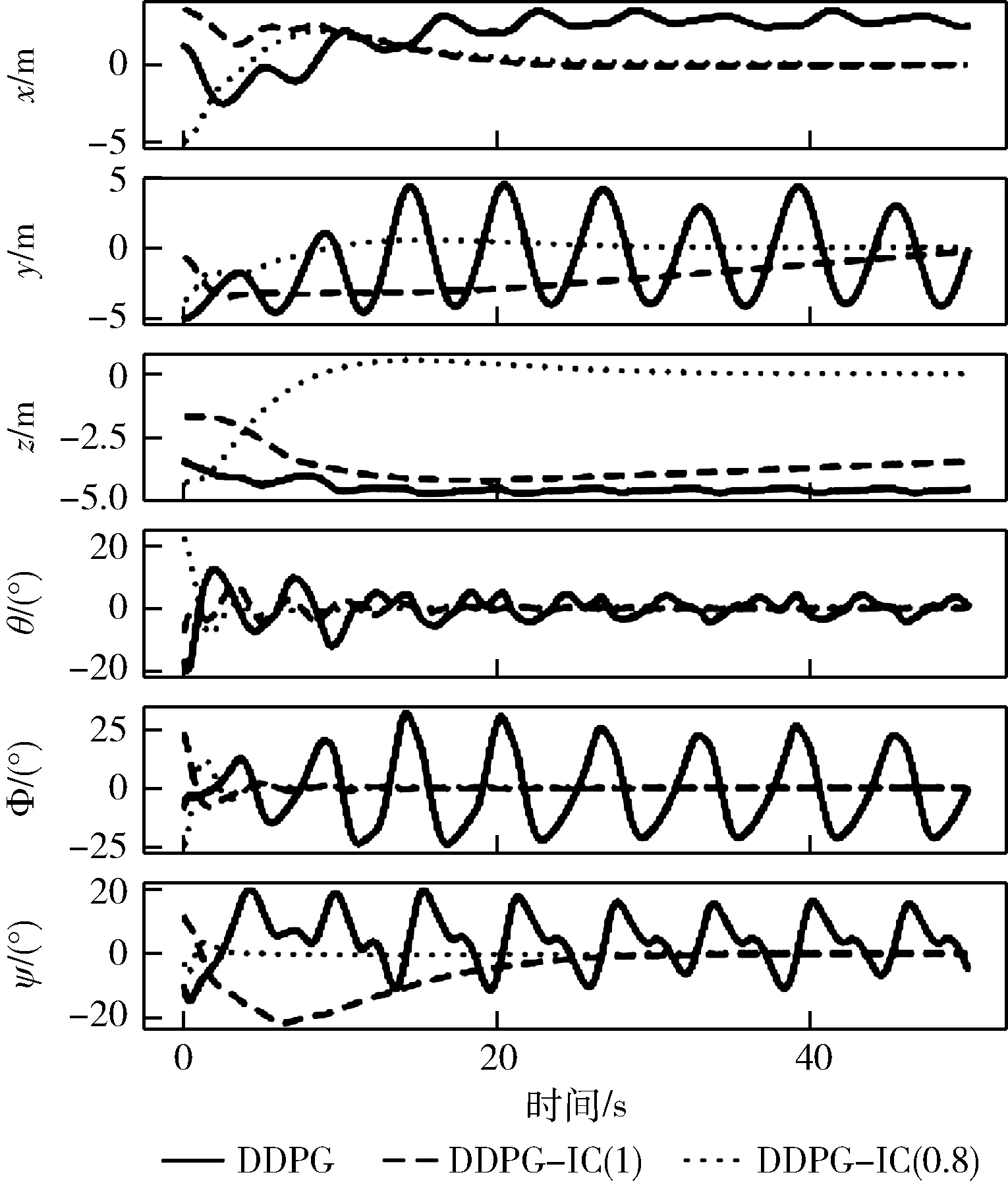
图5 控制器作用下的位置姿态响应曲线
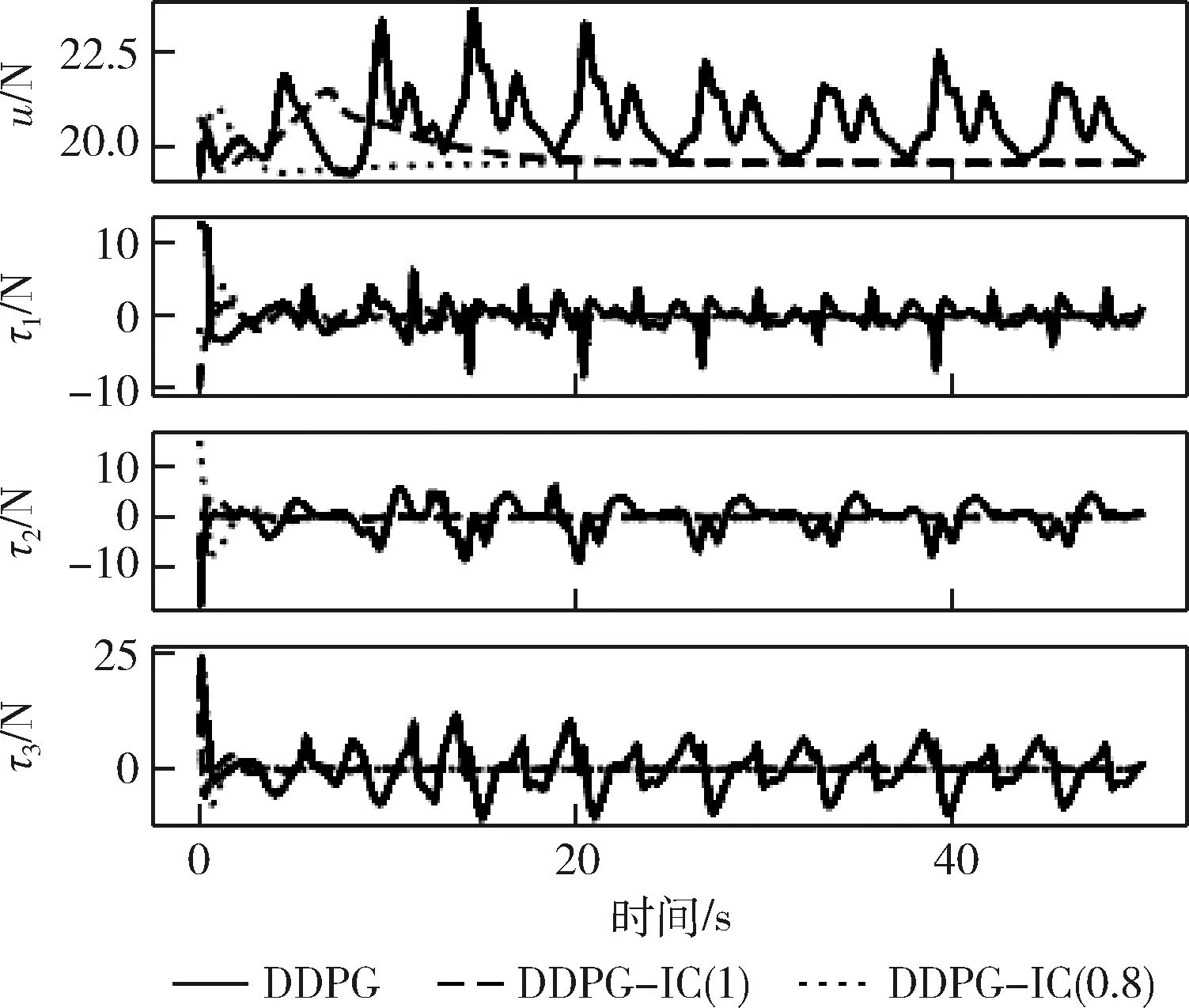
图6 控制器信号
4 结束语
普通的RL算法应用于无人机自主控制中容易出现位置静差的现象,针对该问题,本文引入积分补偿的概念,提出了DDPG-IC(λ)算法,能够在不增加算法复杂度的情况下有效解决位置跟踪静差的问题,进一步提升了RL算法在无人机中的应用范围。仿真结果表明,在被控对象模型未知的情况下,基于DDPG-IC(λ)算法的四旋翼控制器能够通过自主学习,将四旋翼稳定控制到期望位置。相比于普通DDPG算法,基于DDPG-IC(λ)算法的四旋翼控制器的位置控制误差减小为零,控制系统的稳定性和鲁棒性增强。积分补偿的加入能够有效消除位置静差,提高算法的稳定性,同时能够降低学习算法对奖励函数设置的要求;此外,衰减因子λ的引入能够平衡累积误差与当前状态误差的比重,使得算法在保证性能的同时减少调节时间,提高了算法的性能。
