基于宽接收域的实时人体姿态估计网络
2023-01-31苟先太陶明江康立烨金炜东
苟先太,陶明江+,李 欣,康立烨,金炜东,3
(1.西南交通大学 电气工程学院,四川 成都 611756;2.四川大学 原子与分子物理研究所,四川 成都 610065;3.南宁学院 中国-东盟综合交通国际联合实验室,广西 南宁 530200)
0 引 言
近年来,基于深度学习的人体姿态识别研究得到不断发展,Newell A等[1]提出了一个结合中间监督过程的堆叠沙漏模型(stacked hourglass),通过连续的池化和上采样不断进行特征的编解码过程以实现关键点的定位和分类。Hua G等[2]针对网络中大幅度卷积导致的原始图像分辨率降低的问题,提出将残差注意力模块纳入堆叠沙漏网络中实现对上采样过程的监督,但在人体遮挡的情况下检测比较困难。Gkioxari G等[3]借鉴于sequence-to-sequence模型的思想提出了一种链式的卷积神经网络,模型分阶段预测不同类别的关键点,充分考虑到关键点之间的结构化关系,缺点是前一阶段的预测结果会直接影响到后续的预测效果且不能较好处理遮挡情况。针对此问题,Bulat A等[4]提出的级联双子网络模型以及Yeonho等[5]提出的基于数据投影转换的深度网络都较好地解决了遮挡问题。除了传统的卷积神经网络外,生成式对抗网络在人体姿态识别领域也得到了极大应用,Chen Y等[6]、Chou C J等[7]、吴春梅等[8]将生成式对抗网络利用到人体姿态检测任务中,通过构建不同的生成器和辨别器以提高模型的预测能力,为该领域的发展提供了一种新的解决思路。但是生成式对抗网络面临的最大问题就是收敛性问题,模型不易收敛到全局最优。文献[9]指出,卷积处理层之间的稠密连接可以提升网络对图像特征的提取能力和利用程度。基于此思想,本文提出一种稠密残差步进网络,并采用基于二维卷积的FReLU激活函数,扩大了模型的接收域,保证较高检测精度的条件下模型的预测速度可以达到实时效果(人体姿态估计如图1所示)。
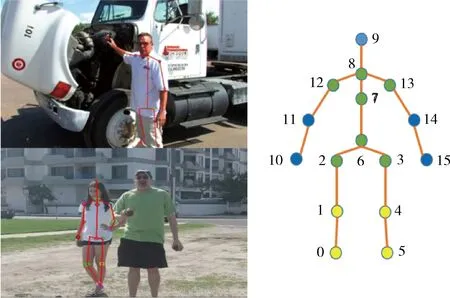
图1 人体姿态估计
1 相关技术
1.1 FReLU激活函数
卷积神经网络的本质就是一系列堆叠的卷积层和池化层,通过分析卷积操作的底层可以看到,实际上卷积操作只能够对输入进行线性变换。但是,在许多实际的应用场景中,需要识别或完成的任务都是十分复杂的问题,并非是线性可解的,需要采用非线性的模型来解决。激活函数大多都是非线性函数,因此在模型的构建中通过加入激活函数可以给网络引入非线性变换,增强模型的表达能力。
在深度学习模型的构建中,常用的激活函数有:sigmod激活函数、tanh激活函数、ReLU激活函数、PReLU激活函数和softmax激活函数。通过分析上述激活函数的特性可知,虽然每一种激活函数都能给模型带来非线性能力,有着不同的激活特性,但是都存在着同样的问题:都是对输入特征图某一个特征点进行激活,而没有考虑到当前特征点周围的特征信息,导致模型的激活域都被固定为1×1的大小,不能很好地关注到图像整体信息。
针对此问题,Ma N等[10]设计了一种全新的二维激活函数FReLU,该激活函数借鉴了ReLU和PReLU两种激活函数的基本思想,但是FReLU对当前特征点的周围信息做二维卷积操作,将卷积操作的结果与当前特征点进行判别激活,FReLU最本质的区别在于非线性激活的条件值不是固定的,而是由局部卷积的结果决定。这样就导致在进行非线性激活的时候,模型将会有更广的接收域。FReLU激活函数可以用式(1)和式(2)联合表示
f(xc,i,j)=max(xc,i,j,T(xc,i,j))
(1)
(2)
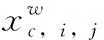
激活特性分析:FReLU激活函数中(激活特性如图2所示),在进行非线性激活时, max(.) 函数给了网络模型是否关注空间信息的两种选择,当卷积的结果T(xc,i,j) 更大的时候,模型将关注到更多的空间信息而不再是单个特征点。例如:如果设计一个有m层的网络M={F1,F2,…,Fm}, FReLU激活函数实现结构中卷积核的尺寸选为k×k, 那么就可以得到网络第一层F1的激活域集合就是activation_set={1,1+r}(r=k-1), 在经过m层之后,模型最终输出特征对应的激活域集合就是activation_set={1,1+r,1+2r,…1+mr}(r=k-1)。
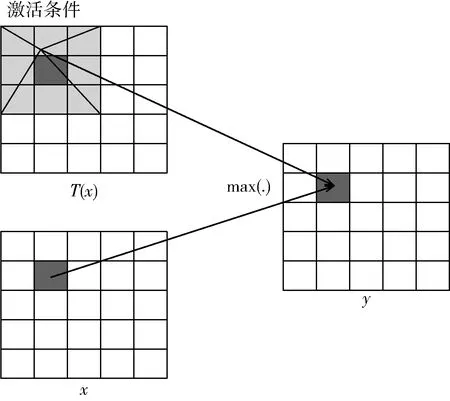
图2 FReLU激活特性
通过分析可以看出,采用FReLU激活函数进行模型搭建将使模型有更广的激活域,同时增强对空间信息捕获能力。
1.2 Residual-Net结构分析
在深度卷积神经网络中,随着网络深度的增加,所构建的模型从理论上可以取得更好的效果。但是通过实验却发现,深度神经网络在训练的过程中存在退化问题,即:网络的深度更深但模型的表现更差。针对这个问题,基于残差学习的残差网络(Residual-Net)[11]被提出。
在深度残差网络中,每一个残差块的结构如图3所示。首先,由上一层残差块的处理结果作为当前块的特征输入x,在当前残差块中,输入x的特征经过一系列的权重层得到当前层的输出F(x), 同时通过设计的一个直连通道可以将上一层的特征输出直接连接到当前层的输出,经过特征的融合得到H(x), 将最后的融合特征作为下一个残差块的输入。
图3 残差块网络(Residual Block)结构
根据图3的残差块网络结构,得到每个残差层的前向计算式(3),假设每一层的损失值loss定义为均方误差式(4),则根据求导法则可以得到loss对上一层输入的梯度如式(5)所示。根据梯度计算式(5)可知,任意一层的输出xL所产生的残差可以传递回任意的上层。除此之外,梯度中包含线性叠加项而非直接连乘,因此可以很好地解决因模型较深导致梯度消失的问题
xL=xL-1+F(xL-1)
(3)
(4)
(5)
式(3)~式(5)中,xL表示当前层的输出,xL-1表示前一层的特征输出,E为当前层的输出xL与当前层的标签数据xlabel计算得到的残差loss值。
1.3 Dense-Net结构分析
作为一种与Residual-Net相比结构完全不同的全新网络,Dense-Net[9]在作为主干网络进行特征提取的任务上有较好的表现。网络结构如图4所示,可以看出Dense-Net在结构上并不复杂,但是却能够对模型提取的特征进行较好地利用。这种形式的网络结构主要有两点优势:①通过将前面特征层的输出直接连接到后面特征层的输入,和Residual-Net思想一样可以减轻梯度消失的问题;②每一层的输出特征信息都被融合到后续的特征处理层,保证网络中层与层之间最大程度的信息传递。
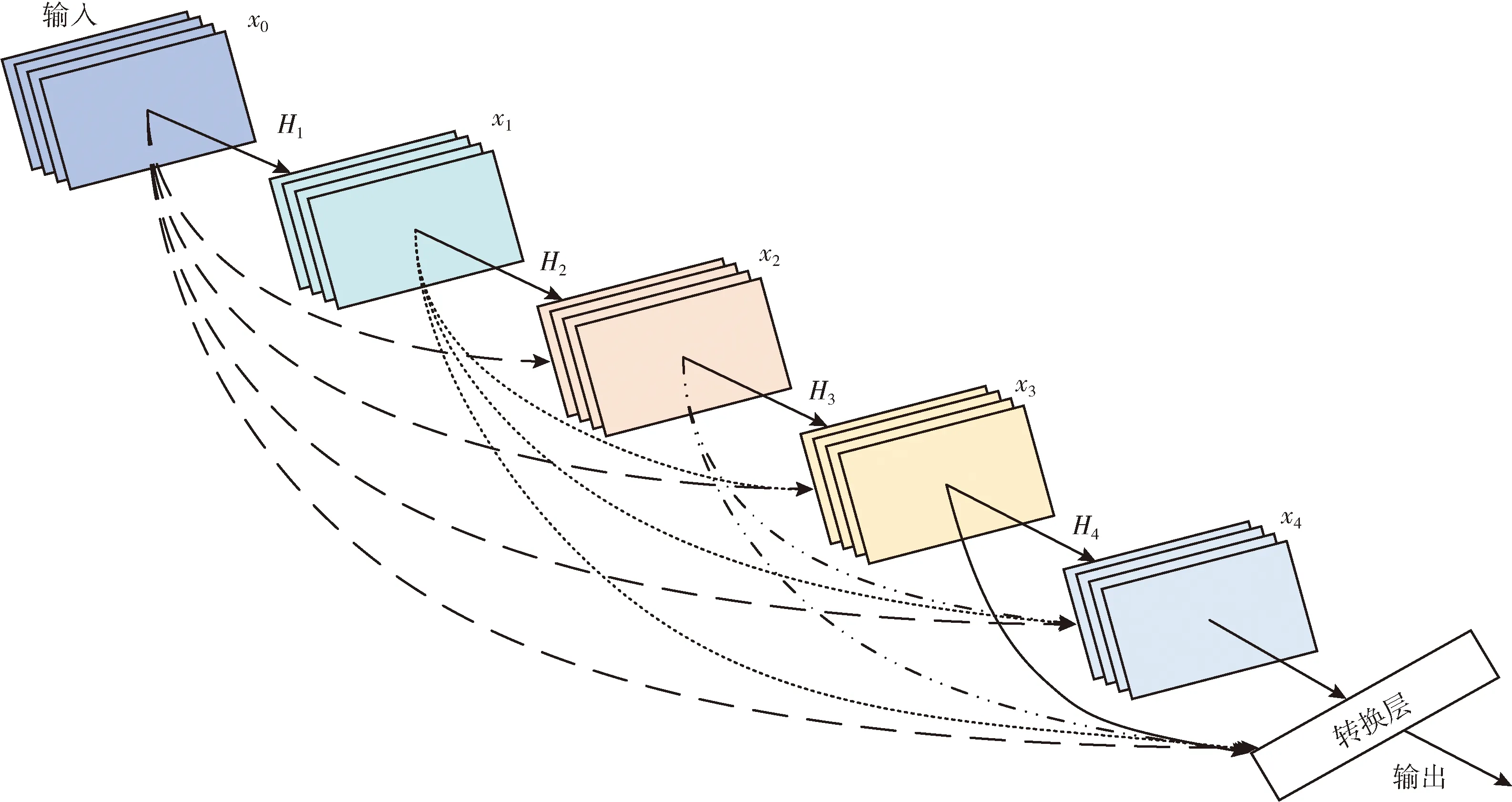
图4 稠密网络(Dense-Net)结构
因此在人体姿态估计这样需要对图像细节特征具有较高提取要求的任务上,采用基于稠密连接的网络结构可以充分利用特征信息,保证网络在提取高维特征的同时也不丢失低维细节信息。
2 模型搭建
2.1 模型结构
本文提出的模型为稠密残差步进网络(dense residual steps network,DRSN),该模型由4个级联的稠密残差步进块(dense residual steps block,DRSB)组成,模型的整体架构如图5所示。模型以RGB图像为输入,首先进行一系列卷积操作层Conv1的处理,得到初始的特征图,该部分的特征图尺寸为64×64×64,即将图像特征变成64通道。随后经过第一阶段的级联网络(每一阶段都是由两个级联的DRSB网络模块组成),经过每一阶段后,特征图的尺寸分别为:第1阶段末(64×64×64)、第2阶段末(32×32×128)、第3阶段末(16×16×256)、第4阶段末(8×8×512)。考虑到人体关键点的回归和分类任务不容易收敛的问题,根据图5的模型结构,在第2阶段和第4阶段末分别进行一次loss值的计算,由于计算loss值时需要模型输出对应的热图,而第二阶段和第四阶段输出特征图的尺寸分别为32×32×128和8×8×512,因此需要对输出的特征进行上采样之后再卷积操作,使其变成64×64×64形状的输出即为需要的预测热图。
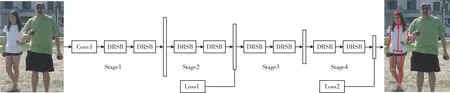
图5 模型整体结构
DRSB网络模块的结构如图6所示,针对每一个DRSB模块而言,都将输入特征进行通道分割,然后依次输入不同的通道处理。首先DRSB将当前阶段的输入特征分割成4个部分fi(i=1,2,3,4), 然后每个fi分别经过一个卷积核尺寸为3×3的卷积操作,DRSB在当前通道i进行卷积操作之前,都需要将前面i-1个通道的上层卷积结果和当前通道的上层卷积结果进行特征相加的融合,这样的网络结构基本思想来源于稠密网络(Dense-Net)[9]。通过将同级卷积的特征进行内联,实现神经元之间的稠密连接,可以丰富模型对空间信息和语义的提取能力,捕获到利于关键点定位和分类的图像特征。
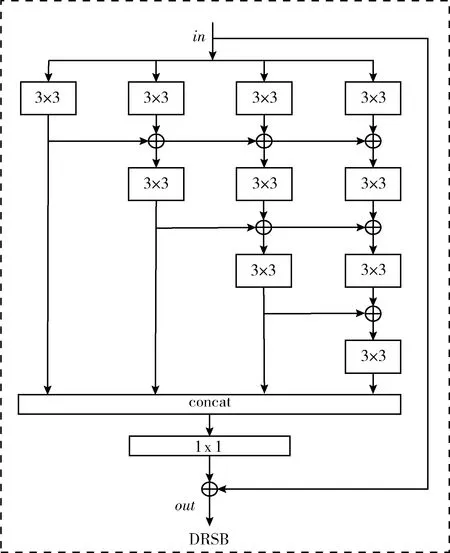
图6 DRSB结构
虽然DRSB和Dense-Net的网络结构都是采用密集连接,两者的最主要的区别在于:Dense-Net中,主要将特征图进行通道维度的拼接,当密集连接程度非常大的时候,会造成后阶段的特征图通道维度灾难;而在DRSB的结构设计中,出于对模型复杂程度和预测速度的考虑,采用的是特征像素点对应位置相加的方式,这样既可以充分利用不同通道的图像特征又有效地避免了由于通道拼接带来的维度问题。根据图6可以得到单个DRSB的表达式如式(6)所示
(6)
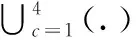
2.2 激活函数设计
激活函数的传统作用是给模型引入非线性变换,使得模型能够拟合更加复杂的问题。在本文的模型构建中,选用更加适合于图像处理的FReLU激活函数(见式(1)、式(2)),在引入非线性的同时能够增广模型的接收域集合。在实际的代码中,FReLU激活函数的实现方式如图7所示。
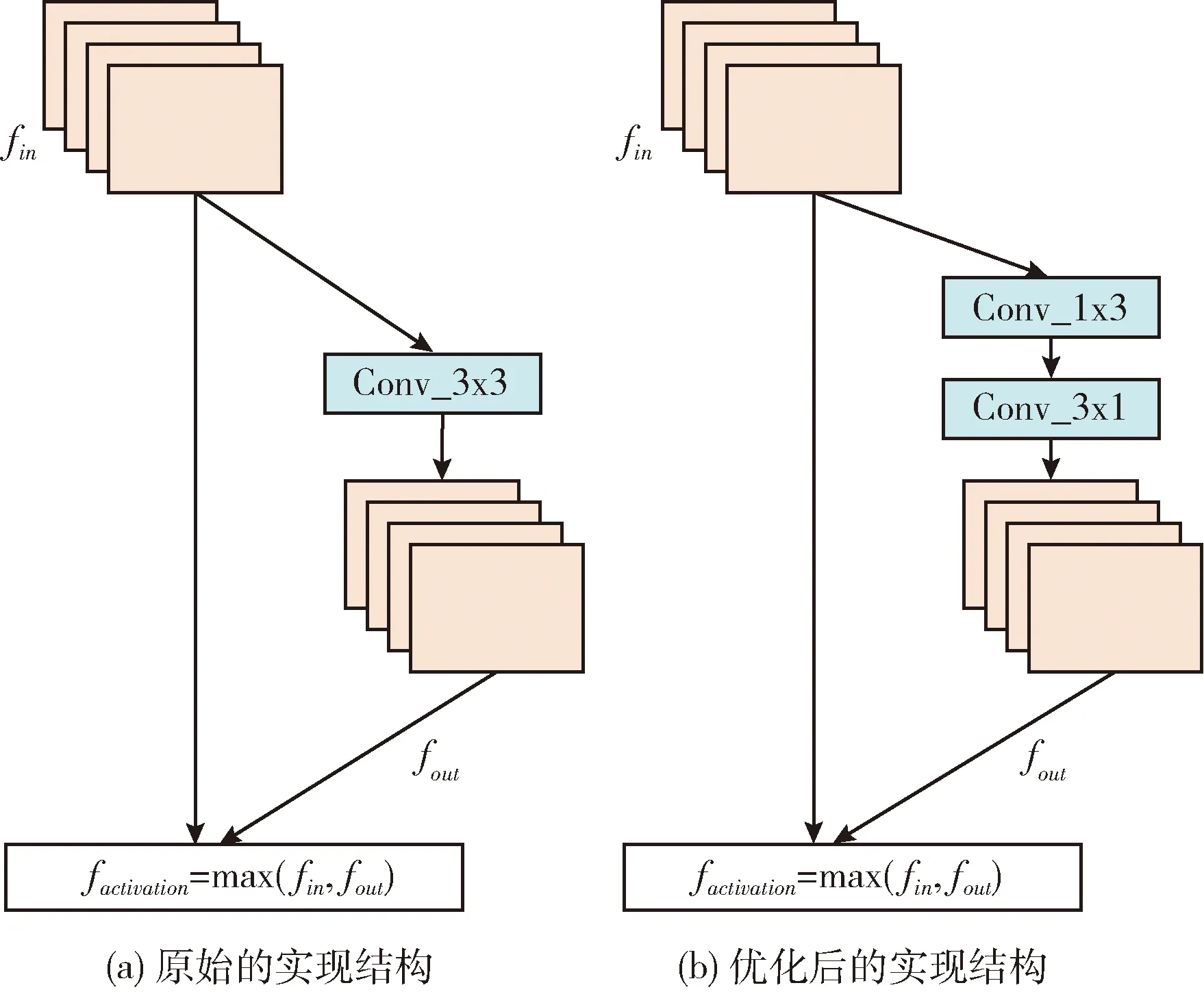
图7 FReLU激活函数实现结构
图7(a)中为FReLU激活函数的原始实现结构,针对当前层的卷积处理结果fin, 首先对其进行卷积核尺寸为3×3大小的卷积操作,卷积处理的结果为fout, 最后根据max(fin,fout) 方法实现选择激活,fin和fout所有维度的尺寸都保持一致。图7(a)中的FReLU实现结构能够完全表达出该激活函数的设计思想,但是需要考虑一个问题:如果需要构建的基础网络深度为n,每一个卷积操作之后都进行激活操作,那么模型需要保存额外的n个卷积操作带来的参数量,这样的模型参数量将会十分巨大。在本文的FReLU实现结构中,采用图7(b)的实现方式,已有相关研究结果表明,降低模型的参数量除了将大卷积核分解成多个小卷积核之外还可以将空间卷积分解为不对称卷积,即将n×n的卷积操作分解为两个级联的1×n和n×1卷积。当输入输出的通道数目一定的前提下,通过非对称分解可以将计算量减少33%。因此,在网络深度较深的时候,采用优化后的FReLU实现结构能够大大降低模型的参数,加快模型的预测速度。
2.3 模型接收域分析
2.3.1 宽接收域定义
在卷积神经网络中,将卷积核能处理的宽度定义为该卷积操作的接收域,卷积操作通常是级联的形式,因此可以将每一层卷积的接收域的计算总结为式(7)
(7)
其中,lk代表第k层卷积的接收域;fk代表第k层卷积核的尺寸;si代表第i层卷积的步长。在本文的模型构建中,卷积核的尺寸都选择3×3的大小,步长设置为1,因此式(7)可以简化为式(8)
lk=lk-1+2
(8)
本文提出的宽接收域定义为:针对每一次网络模块化处理,假设输入特征的接收域为 {m}, 在通过该次处理之后,接收域不再是单个固定值m,而是 {m,m+2,m+4,…,m+2n} (n与模型的深度有关,由式(8)计算得到),接收域集合中的接收域值选择更多,让模型能够在把握大接收域带来的全局信息的同时也能够充分利用小接收域提供的细节特征。采用不同接收域对于模型的预测效果的提升如图8所示。

图8 不同接收域模型的预测对比
图8(a)所示的是当模型采用单通道网络结构时,此时模型最终输出图像特征的接收域只有一种,当接收域比较小时,针对右肩这个关键点的定位和分类会出现很大的问题(因为模型无法得到更多的空间信息和语义信息)。图8(b)所示的是当采用本文提出的宽接收域模型时,模型在最终阶段的输出特征的接收域是一个集合,里面包含多种接收域选择。较小的接收域能够为模型提供丰富的空间信息使得关键点的定位更加精确;较大的接收域为模型提供更宽的视野,包含的语义信息也就更多,关键点的分类也就更准确。因此通过为模型增宽接收域可以有效提升模型对于人体关键点的定位和分类。
2.3.2 接收域对比分析
针对图6中的DRSB模型结构,可以看出该网络块中的所有卷积核尺寸都为3×3,网络的有效深度为4,假设每个块的输入的特征in的接收域集合都规定为{1}。当模型采用非多通道非递进式(即:一个4层的单卷积通道结构)的网络结构设计时,经过4层的卷积操作,最后的网络块输出特征out的接收域集合为{1,9}(由式(8)计算得到,接收域为1的in直连到out接收域还是为1,经过一层3×3的卷积之后接收域变成3,再经过一层之后变成5,因此经过4层之后变成9),只有两种接收域尺寸。
当采用图6中的DRSB网络块结构时,假设有效深度是4层,但是由于采用了多通道递进式进行处理,网络块输出out的接收域集合就大不相同。第1通道中,在经过一层卷积操作后,接收域为{3};在第2通道中,共包含两个卷积层,接收域为{5};依次类推,第3通道的接收域为{7};第4通道的接收域为{9}。因此网络块out的接收域集合为 {1,3,5,7,9}。
同样针对图6中的DRSB模型结构,当采用FReLU激活函数后,对应的接收域集合会发生变化。对于第1通道原始的接收域集合为{3},对卷积输出特征进行FReLU非线性激活,激活时神经元可以选择当前的特征点是否关注空间信息(即:对当前原始特征点和经过图7(b)卷积处理后的对应特征点进行选择)。如果选择关注空间信息,则对应的接收域变成5,反之,接收域还是3,最终的接收域集合变为{3,5};以此类推,第2通道接收域集合为{5,7};第3通道接收域集合为{7,9};第4通道接收域集合为{9,11}。
对非多通道非递进式的结构、DRSB非FReLU激活函数的结构以及DRSB和FReLU激活函数的结构进行接收域集合对比分析,分析的结果见表1。通过对比分析可以看出,采用DRSB和FReLU相结合的网络结构可以增加模型的接收域集合,这对于提升模型效果是有利的。

表1 接收域对比
3 实验和结果
3.1 数据集和实验环境
为了验证模型的检测性能,将对MPII人体姿态检测标准数据集进行实验和结果分析。该数据集总共包含25 000张图片以及40 000张人类动作的图像,其中用于模型测试和验证的图像共计2958张。本文中的实验环境详细信息见表2。

表2 实验环境配置
3.2 实验细节
为了实现后面的4个阶段每个阶段的输出特征都是固定的形状,因此需要对输入的图像进行尺寸的裁剪和缩放,使得输入图像固定为256×256像素大小。根据链式求导法则(正向传播简单公式如式(9)所示),当对参数w进行求导的时候,若输入的X全是正数时,反向传播回来的梯度再乘上X以后不会改变方向,这就意味着权重更新在下一次迭代中要么同时增大要么同时减小。为了防止这种现象,需要对输入数据做归一化和均值化处理,最终的输入图像对应的BGR均值为[0.406,0.456,0.485],方差为[0.225,0.224,0.229]。模型的训练选择基于cuda加速的GPU进行,可以加速训练过程,训练的最大迭代次数为300轮次,选择的优化器为Adam优化器,其中动量momentum设置为0.9,基础的学习率设置为5e-4
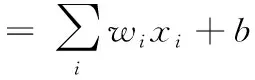
(9)
3.3 损失函数及训练Loss
根据人体姿态估计任务的特性,需要模型回归得到人体关键点的坐标数据并分类出各个关键点,在本文的模型设计中,需要用到两类损失函数,分别用于记录关键点坐标定位损失和分类损失。分类损失函数定义为多分类交叉熵损失函数,函数定义如式(10)所示
(10)
其中,Yi是一个one-hot编码的向量,Yi中的每个元素yij只存在两个可能值(当第i个样本属于类别j时,yij=1; 反之,yij=0),pij表示的是模型对于输入Xi所预测的属于类别j的概率。
针对关键点回归误差采用的是均方误差损失函数来刻画,该损失函数定义如式(11)所示
(11)
经过模型训练,得到最终的损失曲线如图9所示。根据图中所示的loss值趋势可以知道,模型最终的loss仍然是一个相对较大的值,这是因为在本文的模型中,采用了多阶段计算loss值,并且将不同类别的损失值进行加权求和,因此整体上loss偏大,但是模型整体上趋于收敛。
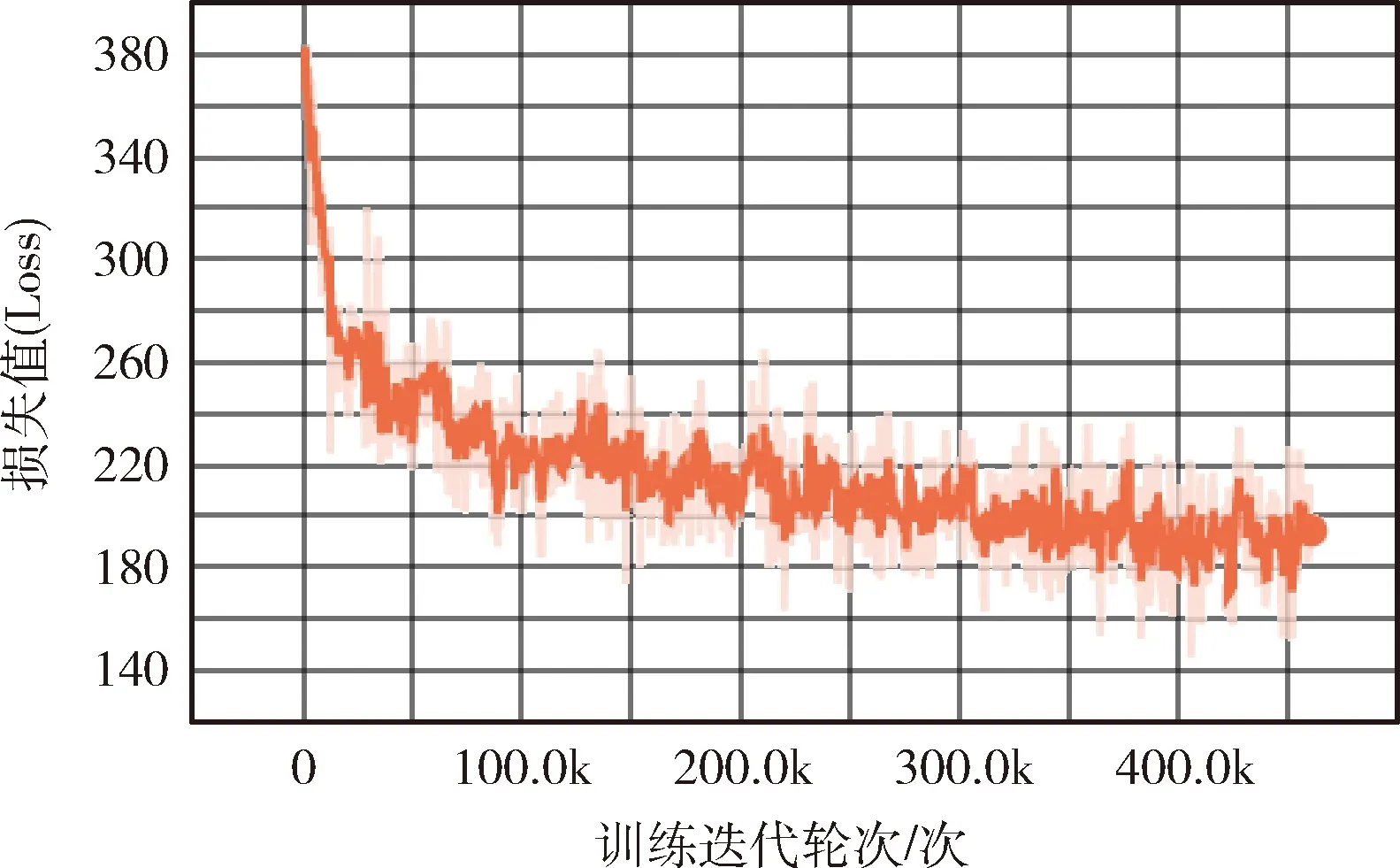
图9 模型训练loss值趋势
3.4 实验结果和讨论
本文提出的基于宽接收域的人体姿态检测模型在MPII标准测试数据集上进行模型验证,该数据集代表了姿态估计任务中最具挑战性的基准数据集,因为数据集中包含了多个人体不同活动下的各种姿态变化情况。
针对人体姿态估计常用的评价指标是关键点正确估计的比例(percentage of correct keypoints,PCK),主要是计算检测的关键点与其对应真值之间的归一化距离小于设定阈值的比例,这个阈值通常也被表示为r(容忍度)。在本文中因为采用的MPII数据集是以头部长度作为归一化参考,即评价指标称为PCKh。
在表3中,测试了不同容忍度下,模型对于不同人体关键点的定位准确率(用PCKh百分比表示),从测试结果中可以看出,当容忍度r=0.5时,人体各类关键点的平均准确率可以达到90.07%,能够达到较高的检测准确率,其中人体头部、肩部的检测准确率更是高于96%。
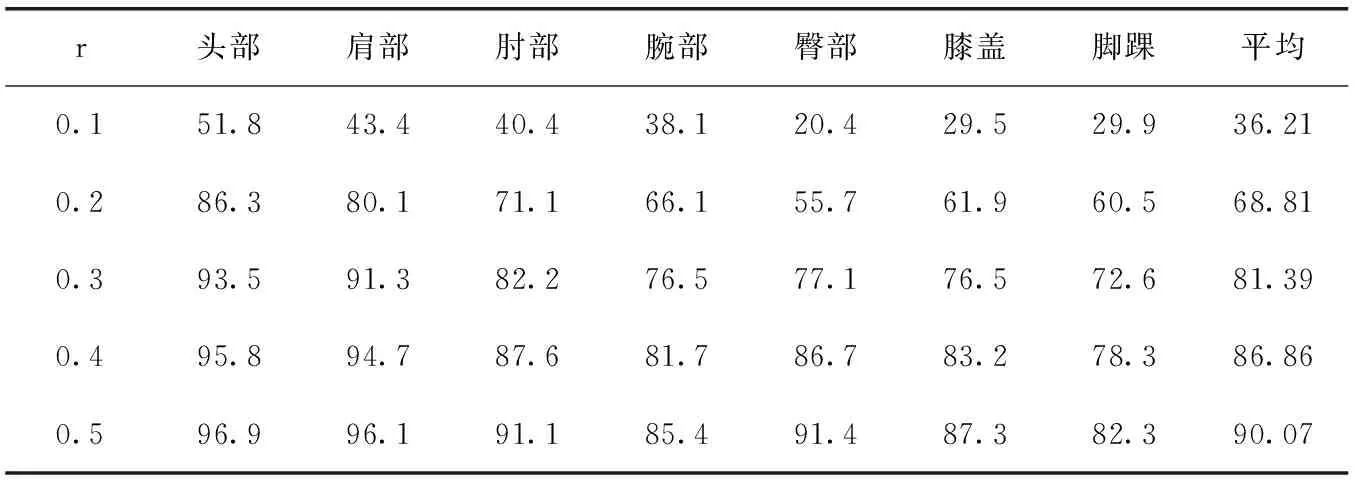
表3 MPII数据集不同容忍度下的PCKh/%
为了验证本文方法的有效性,和同样采用MPII数据集作为评测数据集的其它文献[7,12,13]做对比分析,图10中显示了在MPII数据集上,不同的方法在不同容忍度的条件下对于人体关键点的检测平均PCKh曲线。通过PCKh曲线可以看出,本文提出的方法在容忍度介于0.1~0.4之间测得的平均准确率均高于其它方法,验证了模型的有效性。
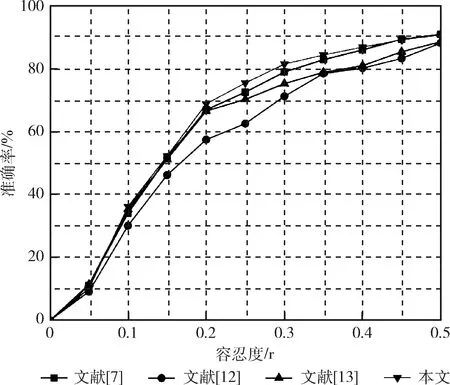
图10 MPII数据集上不同容忍度下平均PCKh曲线
人体姿态估计通常被应用于人机交互、影视制作等领域,因此对模型的检测速度有较高地要求,本文所提出的检测方法在模型体量上有较大地优势。主要源于两个方面:①在模型的稠密连接处,采用的是通道相加而非是通道的拼接,这样可以解决拼接带来的维度灾难问题,减小模型的参数量;②对于激活函数的选取,采用的是适合于图像处理的FReLU激活函数,在引入非线性的同时增加模型的接收域集合,这样可以在网络结构较浅(网络结构浅预测速度更快)的同时使得模型能够关注到更多的全局信息。对MPII数据集的测试集进行检测速度验证,本文所提出的模型在NVIDIA GeForce RTX 2080Ti GPU上测得的检测帧率达到38 FPS,测试效果如图11所示,可以广泛应用于实时的任务。

图11 MPII数据集上姿态检测效果
4 结束语
本文提出了一种基于宽接收域的实时人体姿态检测网络,该网络可以推断出各种活动状态下的人体姿态。通过在模型中采用步进式的结构设计和基于二维卷积的FReLU激活函数,可以有效地增加模型的接收域集合,提升模型对全局信息的掌握能力,关键点分类更加准确。同时,在基础模型块内部采用基于特征点相加的稠密连接,可以有效提升模型的空间信息提取能力又不受通道维度灾难的影响。通过在人体姿态检测标准数据集MPII上进行检测,在容忍度为0.5时,模型的准确率(PCKh)可以达到90.07%,并且检测速度达到实时效果。
