DeepLab V3+改进的树木图像分割
2023-01-31林宁宁高心丹
林宁宁,高心丹
(东北林业大学 信息与计算机工程学院,黑龙江 哈尔滨 150036)
0 引 言
近年来,树木图像分割作为树木的可视化、三维建模、测量的基础、其精度直接影响后续研究的顺利进行[1]。传统树木图像分割方法[2]需要复杂的图像预处理或交互才能实现。而基于深度学习算法则可以实现批量化、自动化分割。杨国亮等[3]在全卷积神经网络中引入Jaccard-Diceloss损失函数解决皮肤病变与背景差别过大的问题。SegNet[4]提取特征使用VGG-Net,上采样利用pooling indices技术更好地保留了边界。侯腾旋等使用3D-UNet[5]提高了肺结节的识别率。DeepLab V3+[6]的提出使图像的分割精度得到了提升。王俊强等[7]利用DeepLab V3+结合CRF使遥感影像边缘细节更加准确。刘志赢等[8]利用DeepLab V3+对烟雾区域边缘进行精细的分割。仝真等[9]改进ResNet-UNet实现了树木的自动化分割。除此之外,基于深度学习的语义分割还应用在医学[10]、医疗器械[11]、农作物[12]等各个方面,但在树木方面的使用较少。有些结构提取特征的过程中减小了空间分辨率、不利于细节的恢复、忽略了像素之间的关系或者适合小样本数据集。
本文为实现自动化高精度分割树木图像,在编码端使用基于扩张空洞卷积的扩张残留网络(dilated residual networks,DRN)[13]提取特征,加入密集特征传递方式;将空洞空间卷积池化金字塔(atrous spatial pyramid pooling,ASPP)设计为带有交互式信息传递的AIM-ASPP模式;在解码端多增加一个中阶特征图,最后使3支不同来源的特征图进行跨层融合。通过对比实验验证此网络可以提高树木图像的分割精度,使边缘更加清晰。
1 理论基础
1.1 DeepLab V3+基础模型
DeepLab V3+的基础模型是DeepLab[14-16]系列的第四代,在编码阶段,骨干网络使用改进的轻量型网络Xception[17],它分为输入流、中间流和输出流。使用深度可分离卷积使模型的参数量和计算量得到降低。由特征提取网络输出的特征图传递给ASPP。在解码阶段接收来自输入流的低阶特征和编码端的高阶特征进行多尺度融合。但是在特征提取阶段下采样的过程中降低分辨率导致一些有用信息丢失,ASPP中不同的空洞卷积直接融合导致信息不连续,在解码阶段只融合了一支低阶特征图,不能使细节信息得到很好的恢复。
1.2 扩张卷积
在卷积神经网络中,卷积和下采样分别对特征进行提取和聚合。但是下采样会使原始输入信息细节部分丢失,可以采用扩张卷积的方式解决不缩小分辨率的同时,增大感受野。如图1(a)所示,在扩张率为1的情况下相当于正常的3×3卷积核,卷积核的参数为9。在图1(b)中,扩张率分别采用的是2,padding的大小跟扩张率一样,在卷积核同样是9个参数的情况下,等效于5×5的卷积核。感受野的大小变为7×7。

图1 扩张卷积
等效卷积核和感受野大小的计算如下
K=k+(k-1)×(d-1)
(1)
式中:K为等效卷积;k为卷积核的大小;d为空洞数
(2)
式中:Si为之前所有层的步长乘积;Stridei为第i层的步长
Fi+1=Fi+(K-1)×Si
(3)
式中:Fi+1为当前层的感受野,Fi为上一层的感受野,K如式(1)所示,Si如式(2)所示。
2 改进的DeepLab V3+网络
本文模型以DeepLab V3+基础模型,编码端特征提取网络由Xception替换成带有扩张卷积DRN结构,改变DRN的层数,增加密集连接方式,得到的中阶特征图传入本文所设计的AIM-ASPP形成高阶特征图,解码端增加了中阶特征图,并调整合适的通道数,使其与低阶特征图和高阶特征图进行跨层融合。结构如图2所示。

图2 本文网络结构
2.1 特征提取网络Dense-DRN
ResNet的top layers中使用了下采样层,造成特征图分辨率降低,细节信息丢失。本文构建DRN时使用扩张卷积代替下采样层,不仅扩大感受野的范围,而且可以维持后续的分辨率。但当扩张卷积的扩张率较大,采样点的间隔相距较远的情况下,可能会导致局部信息丢失。为了避免因为局部信息丢失导致预测图产生网格化效应,使用卷积代替最大池化,在网络的后端增加了空洞卷积。DRN-D版本在许多数据集上拥有良好的分割性能,经过树木图像分割对比实验,综合考虑参数量和精确度,设计Dense-DRN-D-54作为本文的骨干网络。其中所使用的卷积层以及大小如图3所示。图中下面横线上的数字代表重复使用几次其所对应的模块,上方的数字代表第几组。其中前两组使用的普通卷积模块,使用7×7的卷积核与两个3×3的卷积核粗略的提取图像的特征信息,使特征图尺寸减少提高语义性。接下来将会使用密集连接方式,增加空洞卷积,在4、5、6组中分别使用2、4、2的膨胀卷积。

图3 特征提取网络Dense-DRN-D-54
使用密集连接方式替代原本DRN的3、4、5、6组中的残差连接方式,可以使信息在传递的过程中保留的更加完整,其计算公式如式(4)所示。为使每组输出的特征图可以融合上组的特征图,提高所有组特征的重复使用性,本文采用密集连接的方式,主要利用其复用与旁路特征,将此组的特征图与此组之前所有输出的特征图进行通道融合,之后输入下一组网络,其计算方式如式(5)所示。由于使用扩张卷积会产生混叠效应,为使混叠效应不传递给接下来的组,在7组之间不使用残差连接或密集连接。最后删除池化层与全连接层,此时输出的特征图设为中阶特征图
Xi=Hi(Xi-1)+Xi-1
(4)
Xi=Hi([X0,X1…Xi-1])
(5)
式(4)、式(5)中Xi为i组的特征图,Hi为在i组中卷积模块运算。 [X0,X1…Xi-1]为对各个组之间特征图的通道拼接运算。
2.2 AIM-ASPP
ASPP为使高维特征图的上下文信息得到更好的概括,主要是依赖于直接融合不同倍率的空洞卷积,结合不同尺度的特征以达到提高分割精度的效果。ASPP结构如图4所示。扩张率分别使用的是6,12,18。

图4 扩张空间金字塔
但利用每个扩张率下的特征图直接进行融合,容易忽略不同扩张率的特征图之间的相关性,感受野利用不足。对于使用空洞卷积的3×3卷积核,参加有效运算的元素数量是9,扩张率只影响感受野的大小,当扩张率为6时,感受野为13。而如果使临近的空洞卷积进行融合后,参与有效运算的元素数量与感受野大小将会增大。比如经过扩张率为6的卷积层与扩展率为12的卷积层进行拼接融合后感受野将会由原先的13扩大为37,而有效运算元素将会由原先的9增加为49。因此为解决长距离之间信息的不连续,同时使有效运算元素与感受野得到增加,本文提出在使用空洞卷积的基础上,再进行交互式特征融合。AIM-ASPP如图5所示。由2.1节得到的中阶特征图分别使用倍率为1、6、12、18输出A1-A4的特征图,A5为进行全局池化得到的特征图。
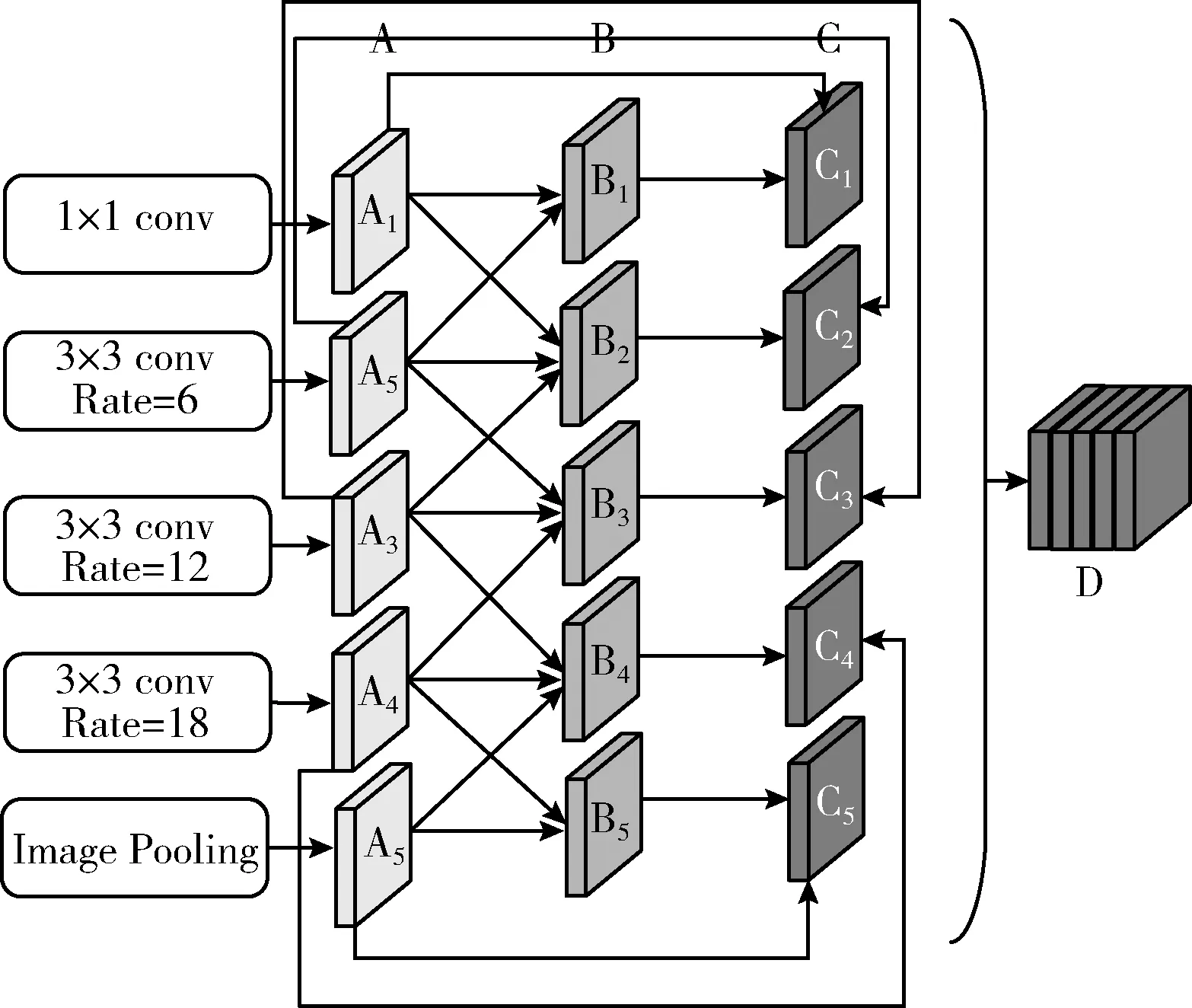
图5 AIM-ASPP
其主要步骤是:①A本特征图与其临近的特征图进行融合后得到特征图B。②B再与A进行融合得到特征图C。③得到所有的C后再进行融合。其计算过程为:设CBR为conv、bn、relu组合,对B1的计算为CBR(CBR(A1)+CBR(A2)), 对B2,B3,B4的计算为CBR(CBR(Ai-1)+CBR(Ai)+CBR(Ai+1)), B5的计算为CBR(CBR(A4)+CBR(A5)), 其中C1-C5的计算为CBR(Ai)+Bi, 其中i表示为本层特征图。最后使 C1-C5进行特征融合得到D高阶特征图。
2.3 多尺度融合
在一张图像输入网络的时候,首先通过编码端的Dense-DRN-D-54网络进行提取特征。由于图像的分类依赖于网络所提取的特征,在只使用原图1/4的低阶特征图进行多尺度融合时,将会导致边缘信息不够精细。为了减少细节信息的损失,提高分割精度,增加一路中阶特征的来源,如图6中间传到解码端路线所示。之后将原图1/16的中阶特征图输入AIM-ASPP,经过通道拼接融合后得到高阶特征图。本文所使用的通道拼接融合如式(6)所示。最后在解码端得到三路来源的特征图,中阶特征图使用1×1的卷积减少通道数。因为过多的通道可能会超过编码器特征的重要性,加大训练的难度。综合对比实验结果,本文多加的这一支中阶特征图选择输出通道数为48。中高阶特征图为了与低阶特征图进行融合,将调节完通道的中阶特征图和高阶特征图进行4倍双线性上采样后恢复到原图的1/4与浅层特征使用通道拼接融合。使得高分辨的细节信息得到更好的补充。接着使用3×3卷积进行细化特征,并且调整通道数为待分割的类别数3。再使用倍数为4的双线性上采样,恢复到原本图像的分辨率。最后通过Softmax函数进行激活后,输出预测的分割图像。
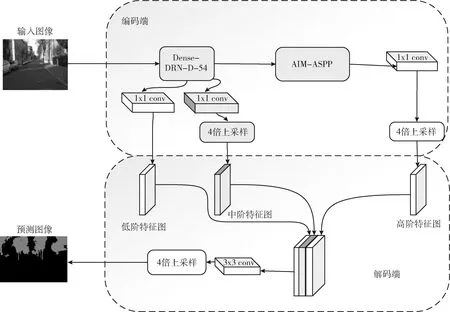
图6 多尺度融合结构
本文多尺度融合时使用的是concat通道拼接,会增加通道数,但每个通道下的特征信息不会增加。式(6)显示的两个特征图进行的通道拼接,对于X与Y都有c个通道数(在实际中通道数可以不同),卷积的时候不共享一个卷积核。当用多个特征图进行融合时,按着此公式继续添加Zi,Wi,Ki+2c,Ki+3c等即可
(6)
式中:c代表的是通道个数;Xi代表的是X输入的通道;Yi代表的是Y输入的通道;*代表的是卷积;K代表的是卷积核。
3 实验研究与结果分析
3.1 数据集及评价标准
3.1.1 数据集

图7 部分数据集
3.1.2 语义分割实验评估指标
本文使用MIoU(mean intersection over union)平均交并比、PA(pixel accuracy)等作为语义分割能力评估的重要指标。
MIoU的实际意义是各个类别上的真实值的集合与预测值的集合之间的交集比上它们的并集,之后再求它们各个类别上的平均值,公式如式(7)所示。PA的实际意义是指预测正确的像素数占总像素数的比例,公式如式(8)所示
(7)
(8)
式(7)、式(8)中:k为类别;k+1为背景类在内的语义类别总数;Pii为像素实际是i类,预测也是i类的数量;pij为像素实际为i类但是预测为j类的数量,pji为本来是j类,但是被判断为i类的像素总量。
3.1.3 训练策略
实验过程中使用的是CUDA 11.1并行计算、操作系统是Ubuntu 16.04,编程语言是python3.7,在深度学习框架pytorch下进行具体实现。实验的参数设置:学习率的初始设置为0.01,采用随机梯度下降(stochastic gradient descent,SGD)方法进行训练网络,损失函数使用交叉熵损失函数,batchsize为4,每一轮的迭代次数为516次,epochs设置为200。
3.2 对比实验
3.2.1 本文网络与DeepLab V3+对比实验
为了验证本文网络的有效性,对比DeepLab V3+与本文网络在自制的数据集上的训练结果如图8所示,DeepLab V3+网络与本文网络在训练过程中的损失值都随着训练次数的增多而趋于稳定,但是可以看出本文的网络损失值(下方折线)小于DeepLab V3+网络,并且收敛速度更快。这是由于骨干网络使用了Dense-DRN-D-54加强了特征映射,使每一层的隐藏信息都能被利用,从而使模型快速收敛。AIM-ASPP加强不同感受野之间信息联系,在整个训练过程中还融合了更多的低阶特征,使细节得到了更好的恢复。最终使网络的MIoU值提升到97.92%。
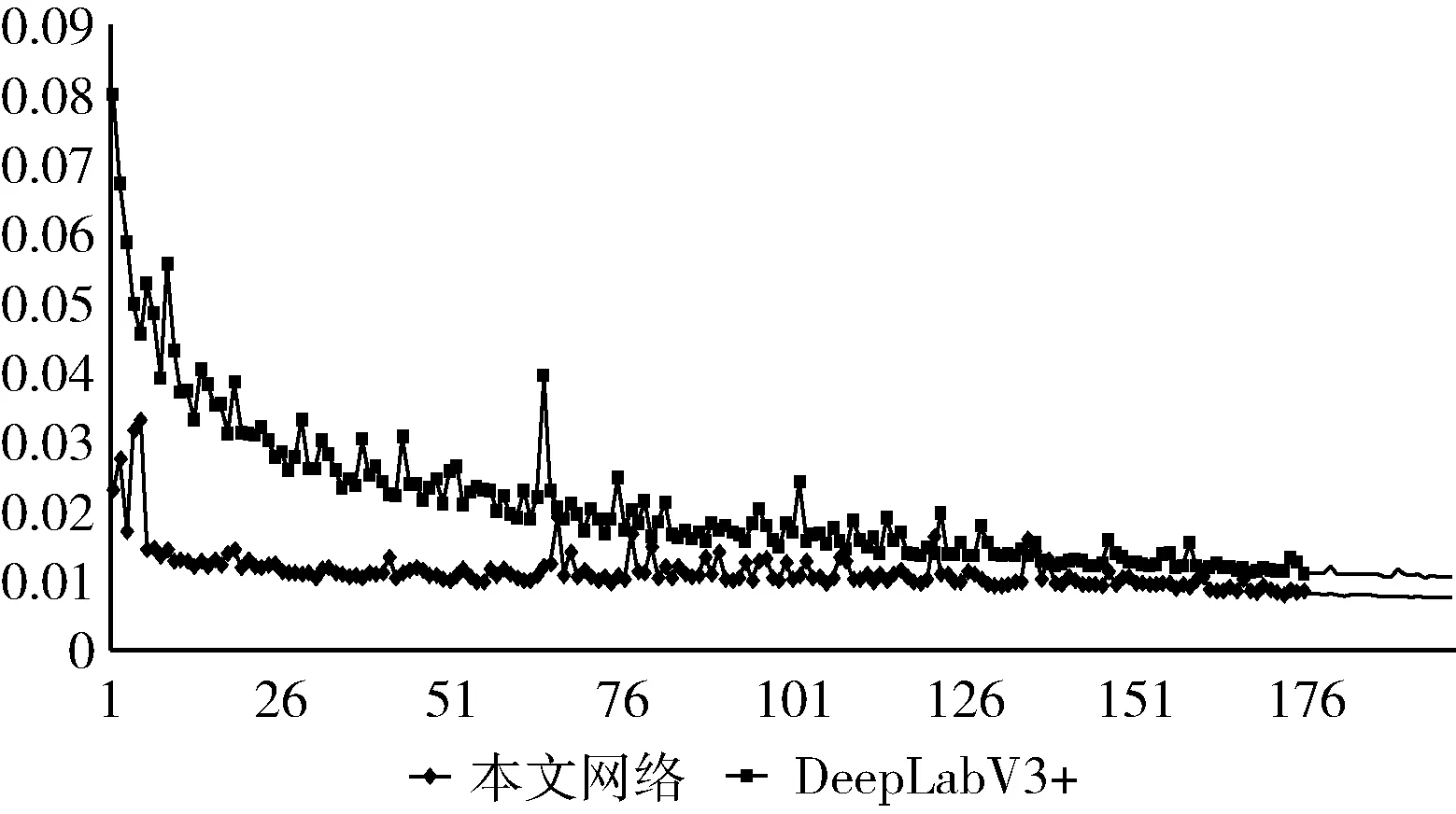
图8 不同算法的loss结果
图9是选择了一些树木较不清晰的图像使用本文网络与DeepLab V3+模型进行分割预测结果对比,从图(c)中可以看出比较细的树干未被分割出来,而在图(d)中,树干被很好的分割出来,边缘提取的更加精细,验证了本文网络在分割难度大的情况下也可以分割出较清晰的边缘细节。

图9 本文网络与DeepLab V3+分割效果对比
3.2.2 结构和参数对比实验
采用MIoU,PA作为衡量指标,使用控制变量的方法来对比分析各个改进点对模型的影响。如表1所示,其中组别1为基础DeepLab V3+网络模型,组别2是使用Dense-DRN特征提取网络,组别3是指在组别2的基础上使用AIM-ASPP替代ASPP,组别4是指在组别的基础上增加一个多尺度融合来源。其中“-”代表不使用,“+”代表使用。使用Dense-DRN网络更换骨干网络Xception,使MIoU提高了1.33个百分比,说明使用空洞卷积及密集连接的有效性。对比组别2和组别3,发现使用AIM-ASPP可以更好利用不同感受野得到的特征图,提高信息的利用率。在多增加一路多尺度融合的来源时,MIoU最终达到97.92%,说明融合更多的低阶特征可以使细节信息得到良好的恢复,达到更高的分割精度。
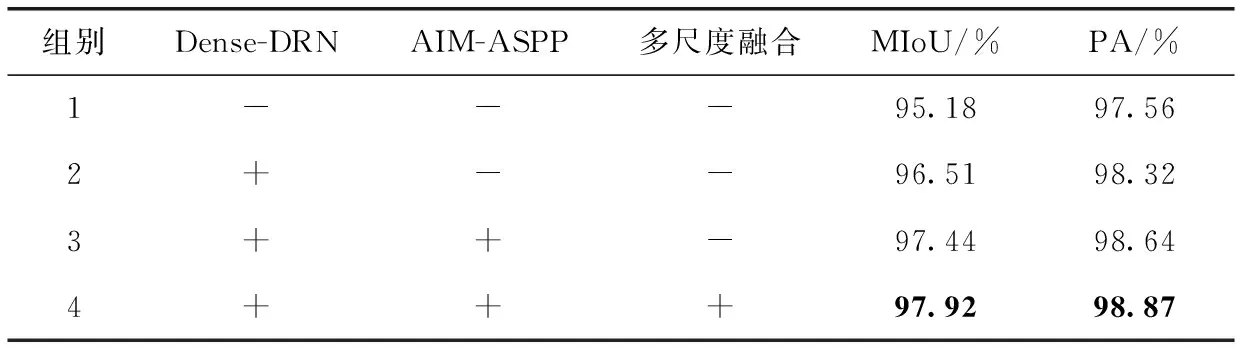
表1 不同改进措施的分割结果对比
本文网络训练的过程中增加了一条多尺度融合特征网络。在特征图进行拼接融合时,为了获得更好的分割性能,需要调整特征图的输出通道。设置通道数为32、48、64做对比实验,实验结果见表2。通过实验结果分析得知,采用过多的通道时会使得网络太过重视编码器,从而导致精度下降,过少的通道将会去掉一些有用的信息。采用通道数为48时,不仅分割精度最高,而且有助于减少网络模型的参数量。

表2 不同通道数分割效果对比
本文网络选择了深度为54、105层的网络做实验对比,见表3。根据实验结果发现,当层数过多时,会提取冗余信息,导致精确度下降。当选取DRN-D-54作为特征提取网络,不仅参数减少,精度也比DRN-D-105高。因此选择了DRN-D-54作为本网络的特征提取网络。
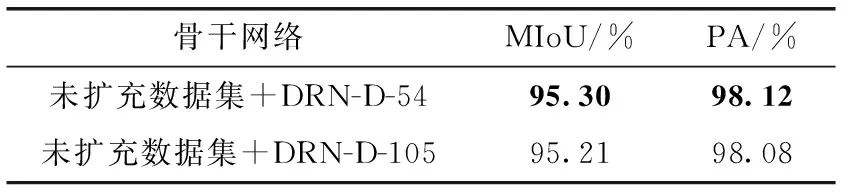
表3 不同层的骨干网络分割效果对比
3.2.3 数据扩充对比实验
为了验证扩充数据集对本文网络的必要性,查看扩充数据集对于分割精度的影响,做了以下对比实验。对比在DeepLab V3+网络下使用扩充数据集和未扩充数据集训练结果下,发现使用扩充数据集训练后,训练集与测试集的精度都比未使用扩充数据集时高。又使用了本文网络作对比,扩充之后仍然可以使精度得到提高。验证扩充数据集可以提高网络的泛化能力。对比实验结果验证了扩充数据集的必要性。实验结果见表4。
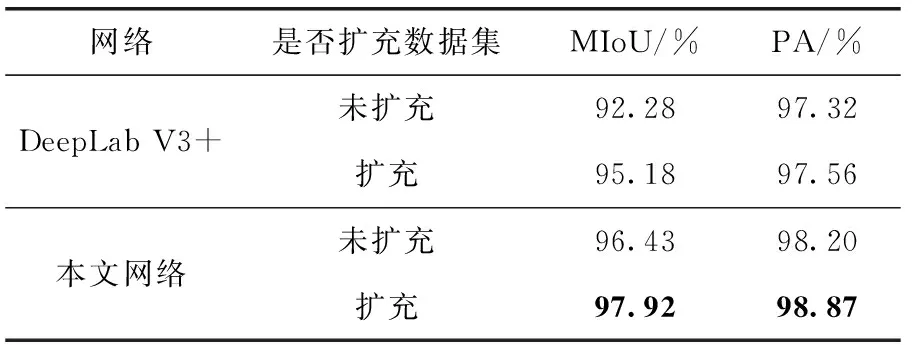
表4 数据集扩充的分割效果对比
3.2.4 本文网络与主流网络实验对比
为了验证分割有效性,利用本文所建立的数据集,选取了当今主流的分割网络U-Net、FCN、DeepLab V3+和本文网络作对比,结果见表5。从本文提出的指标来看,DeepLab V3+比U-net、FCN的精度要好。本文网络在MIoU、PA值方面表现的更加突出,分别为97.92%、98.87%,相比较其它网络更有优势,且模型大小适中,虽然Unet、FCN的模型文件较小,分割效率较高,但它MIOU较低,time是指从一张图片输入到调用模型输出分割结果等整个过程所使用的时间,可以看出本文网络在分割速度上也有所提升。
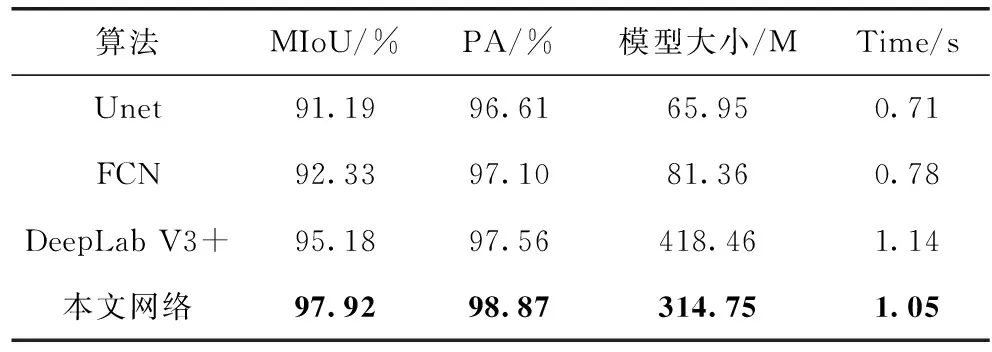
表5 不同分割网络分割效果对比
3.3 泛化性实验
为了验证本文网络在其它数据集上也可以提高精度,使用了公共Cityscapes数据集做对比实验。如表6所示,本文网络相较与Unet、FCN、DeepLab V3+精度都有提升,MIoU比DeepLab V+提升6.11个百分点,表明本文网络具有较好的泛化能力。

表6 不同分割网络使用Cityscapes数据集分割效果对比
4 结束语
为了提高树木图像分割的精度和增强鲁棒性,减少人们的工作量。本文以DeepLab V3+网络为基础模型,使用Dense-DRN-D-54作为特征提取网络,扩张卷积克服了下采样过程中导致树木图像分辨率降低以及树木边缘信息丢失等问题,密集连接可以充分利用浅层的所有信息,减少了细节信息的丢失,同时也使边缘细节信息得到更好的恢复。AIM-ASPP使用了交互式信息补充方式,增强不同感受野之间的相关性。解码端增加了不同尺度的中阶特征图,实现低阶和高阶特征图的跨层拼接融合,更加全面获取高质量的上下文信息,有助于目标细节信息和空间维度的恢复。接下来将继续研究网络模型结构在不减少精度的情况下提高分割速度以及将分割预测结果用于树木测量当中。
