基于多特征后期融合的声学场景分类
2023-01-31康丽霞马建芬张朝霞
康丽霞,马建芬+,张朝霞
(1.太原理工大学 信息与计算机学院,山西 晋中 030600; 2.太原理工大学 物理与光电工程学院,山西 晋中 030600)
0 引 言
声学场景分类(acoustic scene classification, ASC)[1-5]的目的就是识别音频流的产生环境。声学场景含有众多声源,它们在环境的音频段中各自具有明显的非结构化数据特征,环境声音的跨类和类内变化也复杂多变,单一特征难以对此进行表示,针对这一声学环境表征问题,已有学者[6-9]对不同功能特征组成的多特征信道进行了研究,还有研究人员[10]对音频数据不同的通道信息分别进行处理,从不同时频域提取录制音频的信息。但是,现有的这些分类方法通常提取声学场景音频本身的时频域特征,而忽略了声学事件对于声学场景的重要性。此外多数声学场景分类方法[11-14]在分类阶段由于使用单一模型会出现一定程度的欠拟合现象。
为了更加全面描述声学场景音频特征,提升分类准确率,本文提出一种基于多特征后期融合的集成学习方法对声学场景进行分类。针对声学场景中所含有的声学事件本身特征,提出声学事件状态似然特征,结合深度散射谱、谱质心倒谱系数作为网络的输入,该输入既包含音频时频特征又包括主要声学事件特征;此外考虑到单模型分类时存在的欠拟合现象,本文利用随机森林采取加权平均叠加的整体策略提高分类精度以及泛化性能。通过实验对比,进一步探讨本文方法的性能。
1 声学场景分类方法
声学特征表示在声学系统的性能中起着重要的作用,本文研究单个特征AESL以及DSS、SCMC和其组合对声学场景表征的影响,针对不同特征集的组合,采用加权平均堆叠的方法进行ResNet评分融合,图1所示为本文提出的ASC框图。在训练阶段,进行单个声学特征提取,并将其特征向量和类标签一起输入分类器ResNet,以训练声学场景的特征,ResNet输出当前被训练的输入帧关于场景目标类别的后验概率估计,之后对各模型的输出概率进行平均叠加,作为特征训练随机森林。
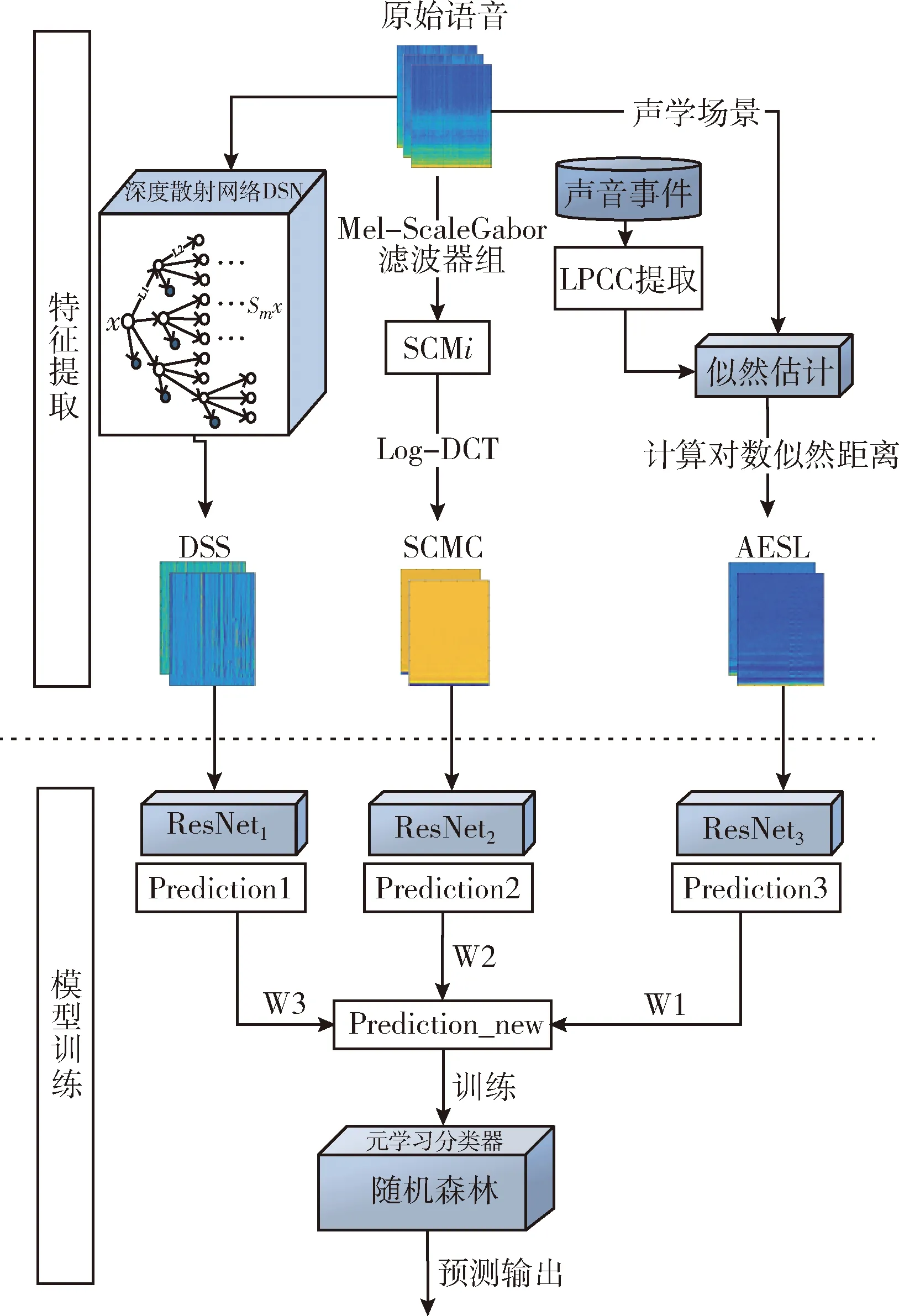
图1 基于多特征后期融合的声学场景分类框架
1.1 多特征提取
图2可视化了从DCASE 2020开发数据集中随机选择的10个场景类别(2个室内、5个室外和3个旅行车辆)的10 s持续时间样本语谱图。由图2可见:在低频区域,能量集中度较高。各类的频谱特征各不相同,且存在类内差异。因此,单个特定功能特征不足以对它们进行有效地表示和区分,而利用互补的特定特征可以更全面地表示或捕获声学场景中存在的感知质量。AESL、SCMC、DSS等特征的功能描述如下。
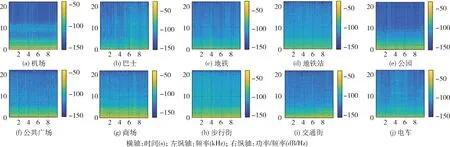
图2 不同场景类别的原始语音语谱
1.1.1 声学事件状态似然AESL
声学事件指由明确的物理声源产生的特定声音,是一段单一明确的短时连续声音信号,可以引起人们的感知注意,一些声学事件只会出现在特定的声学场景中,并且每种场景中都会有一些出现可能性高或次数多的声学事件,例如街道类声学场景可以包含来往的车辆声、脚步声、人们的交谈声等,家中场景可能出现收音机里的音乐、洗碗机的嗡嗡声和孩子们的叫喊等等。因此可以提取声学场景中主要声学事件的本身特征,建立各声学事件模型,并根据模型匹配待识别的声学场景标签。本文在线性预测倒谱系数(linear predictive cepstral coefficients, LPCC)的基础上与声学场景建模求取似然估计距离,得到一个似然矩阵作为新的音频特征——声学事件状态似然(acoustic event state likelihood, AESL),进而提高语义场景识别分类准确率。
由于声学事件的语音采样值之间存在相关性,因此一个采样值可以通过过去的若干语音采样值的线性组合来逼近,得到一组唯一预测系数,即线性预测系数(linear prediction coefficient, LPC)。之后通过倒谱分析将LPC转化为LPCC,以提高特征参数的稳定性。基于LPC分析的倒谱存在一种如式(1)所示的简单有效的递推求解方法来得到相应的倒谱系数LPCC,用h(n) 表示
(1)
式中: {a1,a2,…,ap} 是LPC系数,h(1)=a1,p为预测器阶数。提取LPCC特征之后在10个声学场景求取对数似然距离,得到一个似然矩阵,形成似然特征集合AELS。将似然估计用到声学事件与场景之间,可以衡量整体场景类别的估计标签和真实标签相同的概率,距离值越大代表越相近,也就意味着类别标签估计准确的概率越大。
1.1.2 谱质心幅度系数SCMC
谱质心幅度(spectral centroid magnitude, SCM)[15]包含着类似于共振峰频率幅度的语音信息,谱质心幅度系数(spectral centroid magnitude coefficients, SCMC)被定义为对数谱质心幅度的离散余弦变换,可以有效捕捉给定子带中的声学场景亮度,已经成功应用于说话人识别领域。与此同时SCMC还是频率成分的重心,含有声音信号的频率分布和能量分布相关重要信息。对原始语音信号s(n) 预处理之后,采用Mel Scale Gabor滤波器组对语音帧的第i个子带进行SCM计算
(2)
式中:A[k] 是语音信号的绝对谱,n[k] 是归一化率 (0≤n[k]≤1),ωi(k) 是用于评估第i个子带质心的频域矩形窗函数。
接下来利用离散余弦变换(discrete cosine transform, DCT)对SCM值的对数进行求值,并将其转化为特征系数,进而得到SCMC,它以一种更好的方式捕捉给定子带的加权平均幅度值。
1.1.3 深度散射谱DSS
不同的声学信息存储在不同的时间尺度中。深度散射网络(deep scattering network, DSN)采用原始信号作为输入生成压缩表示,即深度散射谱(deep scattering spectrum, DSS),不仅保留了信号能量,而且确保了时移不变性和对时域形变的稳定性,并在高阶系数内提供附加信息,解决了梅尔倒谱系数(mel-frequency cepstral coefficient, MFCC)在高频下的判断性能低下问题,已在分类和识别任务中显示出了良好的前景[16]。散射表示擅长捕捉不同时间尺度的信息,但实际上,单阶散射表示只是MFCC特征的另一种形式,可以在其上级联两个或多个散射层。因此在使用不同时间尺度提取的散射表示用于声学场景分类任务时,首先将一层散射网络与MFCC连接起来,然后扩展到多层。散射变换在小波模算子|Wm|上迭代,计算m个小波卷积的级联,输出平均散射系数Smx,如式(3)所示
(3)
式中:φ(t)是时间长度为T的窗函数,作为低通滤波器,小波集ψλ提取不同时频尺度下的信息,⊗代表卷积运算。
聚集0≤m≤l所有散射系数S得到一个m阶的DSS
Sx(t)=(Smx)0≤m≤l
(4)
1.2 残差网络
残差网络ResNet内部的残差块使用了跳跃连接,可以在网络层数增加的同时提升模型精度。本文将ResNet作为分类器,模型搭建参考了文献[17]。每个残差层包含两个残差块,每个残差块由批处理归一化、非线性激活函数和卷积层组成,其中所有卷积层的核大小都是3×3。当残差层之间发生下采样时,采用零填充。输出层有10个神经元(类数),使用softmax函数为每个声学场景类生成输出概率值。网络训练过程中,ResNet的最大epoch数为100,Relu作为整个网络的激活函数,Dropout和weight衰减用于正则化避免过拟合;使用ADAM进行梯度下降参数优化,初始学习率为1×10-4。
1.3 随机森林集成
集成学习将多个分类器的预测结果进行组合,是一种常用的后期融合技术。为了减少单模型分类的误差,本文选择加权平均叠加(averaging and stacking)的整体策略对多模型预测输出进行处理;为了提高分类模型的泛化性,相比以往只对预测结果进行加权平均融合,本文选择在随机森林(random forest, RF)上再次训练各模型预测输出。图3所示为RF集成的流程,从初始音频数据集中提取的特征参数被输入3个不同的ResNet分类器并行训练,这3个分类器中的任何一个都包含目标预测输出,对不同模型的预测输出概率进行加权平均并组合创建最终数据集,据此训练元学习器RF,生成数据集的最终分类结果。
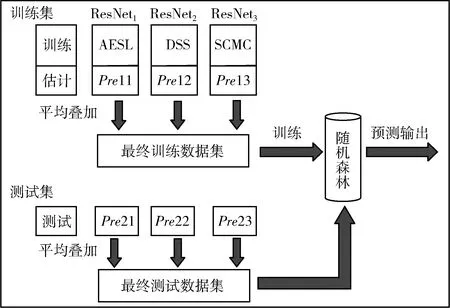
图3 随机森林集成策略
2 实验设置
2.1 数据集
实验中的音频数据来自DCASE 2020中Task1的TAU Urban Acoustic Scenes Mobile数据集[18],共有64个小时,包含23 040个单声道音频片段,包含来自10个欧洲城市的录音,由9种不同的设备(3个真实设备A-C和6个模拟设备S1-S6)在10个不同的声学场景(机场、商场、地铁站、步行街、公共广场、交通街、电车、巴士、地铁和公园)中录制得到。使用设备A以44.1 kHz的采样率和24位分辨率在每个位置录制5-6分钟的音频,并将其分割为多个时长为10 s的片段,来自设备B-C和S1-S6的数据是随机选取的同步记录片段,因此它们都与设备A的数据重叠,但不一定相互重叠。
实验中所有音频文件的采样率均为44.1 kHz,时长10 s,在进行特征提取之前对语音进行分帧,其中帧长为2048个采样点,帧移取帧长的一半——1024个采样点,对分帧后的信号加海宁窗并作快速傅里叶变换,统一转换为一个431帧的频谱图。
表1所示为DCASE 2020 Task1A数据集中训练和测试子集的音频数据具体分布,开发数据集进一步划分为训练子集和测试子集两部分,训练子集包含每个设备记录的70%的数据,其余30%的音频测试训练结果,其中设备S4-S6所提供的数据仅用于测试,不出现在训练集,以模拟模型在分类时遇到未经训练设备的情况。

表1 DCASE 2020 Task1A数据集中训练和测试子集的音频分布
2.2 评价指标
声学场景分类是对各音频记录样本进行检测并为其标注场景类别标签,主要采用分类准确率(accuracy, Acc)作为评价指标,多类交叉熵(multi-class cross-entropy)作为补充。
准确率是一个评估分类模型的主要指标,在实际评价过程中,既有整体的分类准确率,又有每个场景类别的分类准确率。定义如式(5)所示
(5)
式中:在计算整体分类准确率时,AccASC代表声学场景的整体分类准确率,Ncorr代表类别预测正确的样本总数,Nall代表所有参与评估的音频样本数;如果分开计算每一类别的分类准确率,那么AccASC表示该类别的场景分类准确率,Ncorr表示该类别中成功预测场景类型的样本数,Nall表示该类别的音频样本总数。本文采用整体分类准确率,即计算声学场景分类准确率的宏观平均值。
多类交叉熵表示分类器决策的不确定性,10个声学场景类别记为X=x1,x2,…,x10, 定义如式(6)所示
(6)
式中:p(xi) 和q(xi) 分别是场景变量X=xi的两个概率分布,其中p(xi) 是目标真实分布,q(xi) 是预测得到的分布。熵值越小,场景类别就越容易确定,该分类系统就越稳定。但是具有最小交叉熵的分类模型在准确性方面不一定是最佳系统,因此,采用多类交叉熵指标作为补充对分类系统进行更加全面的评价。
2.3 基线系统BaseLine2020
DCASE 2020官方网站给出了一个关于声学场景分类的基线系统(BaseLine2020),该系统采用多层感知机(multilayer perceptron, MLP)进行架构,Open L3嵌入作为特征表示,随后是两个完全连接的前馈层,分别包含512个和128个隐藏单元。模型训练200个epoch,批尺寸大小为64,采用ADAM权重优化器快速更新权重,学习速率为0.001,在每个时期之后,学习率将呈指数下降。使用约30%的原始训练数据组成验证数据集进行模型选择,在验证集上对每个epoch后的模型性能进行评价,并选择性能最佳的模型,最终在开发集上的整体性能是54.1%。
3 实验结果分析
3.1 不同特征性能对比
本文共设计4组对比实验,探索不同特征的分类性能表现,包括DSS、SCMC、AELF单个特征以及其特征组合,ResNet作为分类器。表2所示为不同分类系统的特征和模型配置,以及不同系统的分类准确率和多类交叉熵对比,表3所示为4种分类系统对不同场景类别的分类准确率。对比实验E1-E3分别为仅输入AESL、SCMC、DSS单特征以训练ResNet进行分类,BaseLine2020即DCASE2020官方提出的ASC系统,在2.3节中进行具体描述,E4为本文所提分类方法。
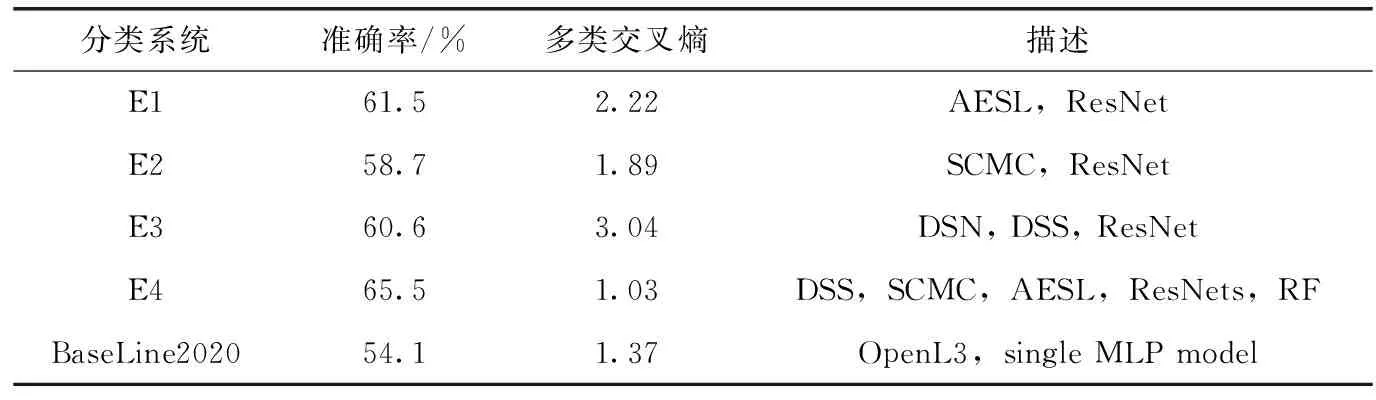
表2 4种实验设置的对比

表3 不同场景下的分类准确率对比
结合表2和表3可知:采用AESL特征作为输入表示的声学场景分类方法效果优于SCMC和DSS特征,准确率相比分别提高2.8%和0.3%;利用AESL和SCMC、DSS特征组合的最终分类在精度上有显著提高,平均准确率达到了65.5%,相比单个特征输入,准确率分别提高了4%、6.8%、4.9%,并且远高于基线系统给出的54.1%的平均分类准确率;与其它类别相比,交通街和公园类分类效果更佳。进一步观察可知,采用DSS特征的实验E3,在准确率较高的同时,多类交叉熵损失函数值也是最大的,即分类系统E3不稳定,场景预测结果具有较大的不确定性,但E4在E3的基础上融合其它两个特征并进行集成学习之后,准确率不仅得到了进一步提高,损失函数值也有所降低。
图4以折线图的形式直观展示了不同分类模型在每一类场景下的分类效果。

图4 各特征对不同场景类别的分类效能对比
由图4可见:在大部分场景类别中,本文所提出的分类模型与对照模型相比都取得了不同程度的提升,尤其是在公共广场、电车以及公园场景中;相比基线模型,每一类场景的分类准确率均有较为明显的提升,这种提升在机场、步行街、公共广场等场景尤为明显。
为了可以深入分析各场景的分类结果,本文利用混淆矩阵将测试集中的每一类声学场景分类结果进行逐一统计,如图5所示,其中的数字即是该类声学场景的具体预测个数。由图5可见:每一类声学场景的大部分音频数据都得到了正确分类结果,说明本文提出的针对声学场景的多特征后融合分类模型是有效的。公园场景中含有鸟鸣声、树叶声等等相对独特的事件类型,而AESL特征很好地利用了声学事件对于场景分类的优势,从图2原始语谱图中也可以看出公园场景在高频阶段亮度较大,有别于其它场景,而SCMC可以很好捕获这一声音亮度特性。若不同的声学场景中含有相似的声学事件,则容易造成不同类别的误判,例如步行街整体环境嘈杂,含有脚步声、说话声等等,而这与公共广场、商场等多个场景类似,因此容易被误判;还有电车、巴士、地铁同属交通工具,含有车厢内平稳行驶声以及乘客之间的交谈声,那么造成这三者相互误判的个数就略多。
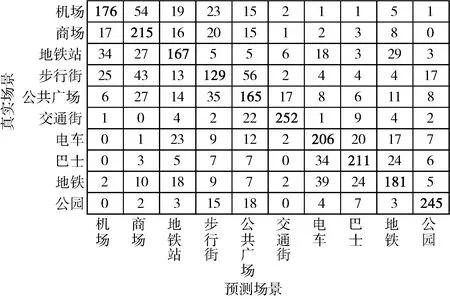
图5 声学场景测试集分类结果-混淆矩阵
3.2 不同方法性能对比
为了验证本文提出的声学场景分类方法可以进一步提高分类性能,将提出的方法与3种对比方法的准确率得分以及多类交叉熵函数值进行比较,3种对比方法分别为文献[19]所用方法(简称为Method_A),采用注意力机制的Resnet-18和Openl3嵌入的方法;文献[20]所用方法(简称为Method_B),采用XGboost算法在两个CNN上进行并行预训练并对各模型输出进行结果平均融合;
文献[21]所用方法(简称为Method_C),在CNN、ResNet以及VGG上进行预训练并对各模型输出进行集成平均;本文提出的方法为Method_D。4种方法均在DCASE 2020中Task1的TAU Urban Acoustic Scenes Mobile数据集上进行实验。表4所示为4种方法的分类准确率以及多类交叉熵函数值的对比,由表4可知:Method_D相比Method_A的分类准确率提升了9.6%,比Method_B提升了4.9%,比 Method_C提升了1.2%;Method_D的多类交叉熵相比Method_A降低了0.94,比Method_B降低了0.03,比Method_C降低了4.24。分析可知:应用随机森林集成的Method_D相比仅对模型预测结果进行平均融合处理的其它3种对照方法,有更好的整体分类准确率以及分类泛化性能,验证了本文所提分类方法的有效性。
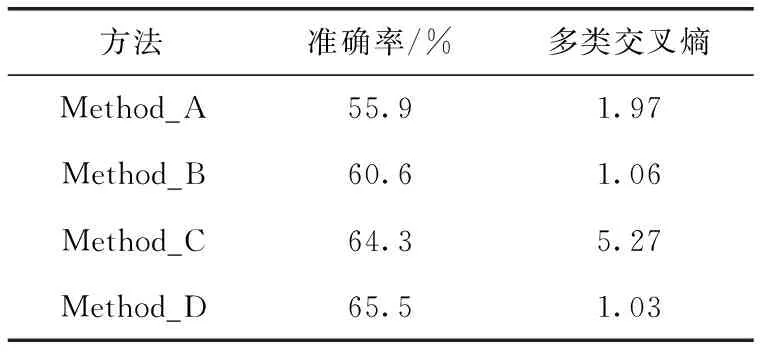
表4 4种方法的分类性能对比
4 结束语
(1)本文提出一种基于多特征后期融合的集成学习方法对声学场景进行分类,使用AESL以及DSS和SCMC这3种互补的光谱特征来表示声学场景,分类器统一为ResNet,本文所提的AESL很好地利用了声学事件对场景分类的影响,结合时频特征有效地提升了分类准确率;此外,验证了在语音识别研究领域中使用的DSS和SCMC特征对于声学场景分类的有效性。
(2)将ResNet模型并行训练,之后采用平均叠加的整体策略将其集成到同一个随机森林模型中作出最终决策。本文在DCASE2020开发数据集上进行实验,最终得到了65.5%的准确率,相比基线系统提高11.4%,其中,交通街、公园的分类准确率均达到80%以上,这表明本文提出的多特征后期融合的方法较单分类器方法在声学场景分类上有更好的效果。
在未来的工作中,针对分类准确率比较低的步行街等场景,将会继续探究不同的声学特征功能,寻找更好的声学事件识别算法来提高声学场景分类准确率。
