改进YOLOv4的实验室设备检测算法
2023-01-31李昊霖徐凌桦
李昊霖,徐凌桦,张 航
(贵州大学 电气工程学院,贵州 贵阳 550025)
0 引 言
近年来,目标检测技术与各类监控摄像头结合实现自动监测的应用研究越来越广泛[1,2];谭暑秋等[3]基于改进YOLOv3算法对教室监控下学生的异常行为进行检测,提升精度的同时,满足实时检测要求;Lu[4]将深度学习技术应用于交通道路监控视频中的车辆识别,识别效果提升显著;李明等[5]提出一类改进YOLO-tiny算法对矿井闸板阀开度进行检测,避免了传统传感器监测布线困难、成本高昂等问题;忻超[6]设计的卷积神经网络结构对监控下机房设备状态进行实时监测,提高了工作效率,但网络层数较低,难以应对复杂场景下对象的检测。Rashmi等[7]从实验室的监控视频中提取静态图像,利用改进算法对学生在实验课程中的行为进行识别和定位,达到监督学习、改善教学环境的目的,但没有针对实验设备展开研究。
实验室设备是高校培养人才的重要教育资源,需要有效的维护监管,结合上述研究发展,考虑将目标检测算法与监控摄像头结合,实现实验室设备的自动实时监测,提高管理效率,保障设备财产安全。本文主要研究实验室监控下设备的检测问题,与常规应用中检测对象尺度分布较为均匀的情况不同,实验室设备位置及大小均基本固定,尺度分布并不均匀。因此本文以深度学习模型YOLOv4[8]为框架,通过改进先验框的聚类算法来解决尺度分布不均匀带来的问题,并在主干网络中引入了ECA(efficient channel attention)通道注意力模块[9]和改进FPG(feature pyramid grids)特征融合网格结构[10],提高检测精度,实现对实验室设备的有效检测。
1 YOLOv4目标检测算法
相较于上一个版本YOLOv3[11],YOLOv4最显著的改进在于引入残差结构的CSPDarknet53主干网络和改进PANet[12]的颈部特征金字塔结构,该结构先自顶向下传递强语义特征,再由自底向上的特征金字塔传递强定位特征,进一步提高了网络的特征提取与融合能力。CSP结构是将原来残差块的堆叠拆分成左右两个部分:第一部分只经过少量处理;第二部分继续原来的残差块堆叠后,再与第一部分的输出相加,图1为其结构示意图。YOLOv4是目标检测中最高效的模型之一,融合了系列改进及训练技巧,在COCO数据集上的mAP相较于YOLOv3有非常显著的提升,同时保持了优异的速度性能。
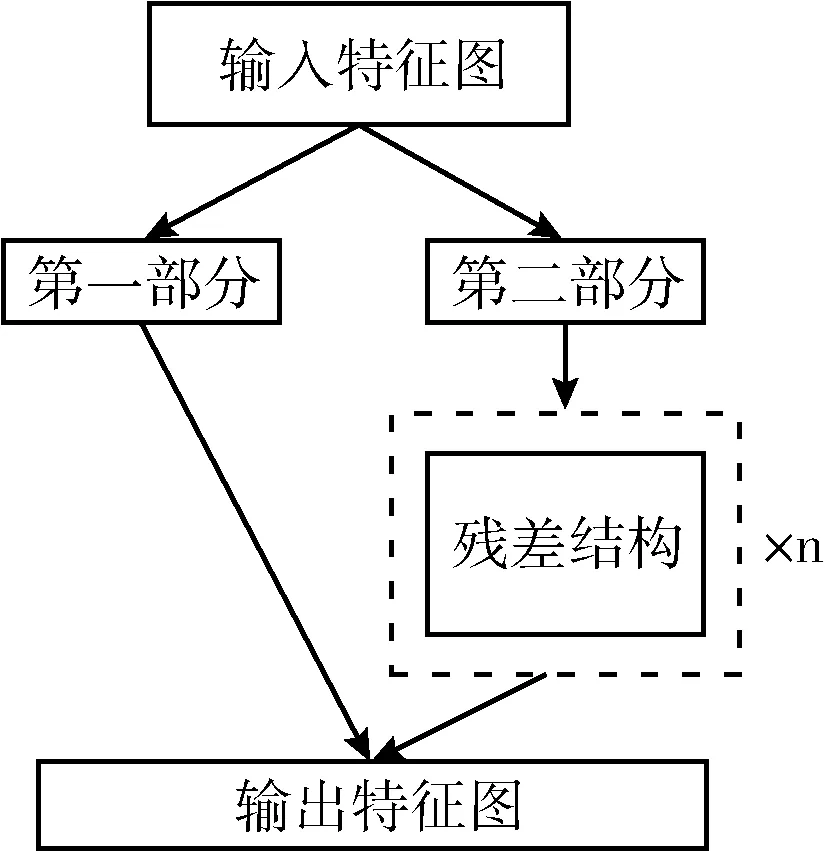
图1 CSP残差结构
对于YOLO这一类Anchors based、多输出层算法,先验框的选取至关重要,目前各种算法的性能评价一般在COCO数据集上测试,该数据集图像接近真实生活场景,物体大小整体分布较为均匀,而在实际应用中,部分场景下检测对象的尺度大小分布并不均匀,使得目前常用的基于K-means聚类算法获取先验框的方法有一定局限性,部分网络分支得不到很好的训练,浪费网络,Hurtik等[13]设计的高速路摄像头检测车牌的实验中也验证了这种情况的存在。
2 模型改进与优化
2.1 数据集先验框聚类算法改进
K-means聚类算法原理简单、聚类效果较好,易于实现,因此被应用于YOLO系列算法数据集先验框的聚类,但该算法存在以下两点问题:
一是聚类结果受到初始聚类中心的影响较大[14],且初始聚类中心是随机产生的,因此本文拟使用K-means++算法进行先验框的聚类。K-means++的特点在其初始聚类中心点的选取上,优先选取距离已有中心点最远的点作为下一个初始类簇的中心点,确定初始中心点后再进行标准K-means算法聚类。
二是在检测对象尺度分布不均匀时,K-means聚类的先验框会使得大小相近的物体被强制分配到不同检测头,从而影响检测精度[13]。在本文实验室场景下,各类设备的标注框大小只有几类特定尺度,而K-means算法在聚类样本满足以下分布时才有较好的聚类效果
A~u(0,r)
(1)
式中: A={a1,a2,…,an}, 表示一组先验框,在YOLOv4中,n=9;r为输入图像的分辨率;u(0,r) 表示物体大小为0~r之间均匀分布。
YOLOv4的9个先验框在检测头中分为了3组,分别用于检测小、中、大物体,而在计算机实验室场景下,设备先验框大小并不满足式(1)的分布,因此在使用时会造成尺度大小非常接近的物体被强制分配到不同层进行检测,即大物体可能被分配到中等物体检测头、小物体也被分配到中等物体检测头,使得其余两个检测头得不到有效训练。
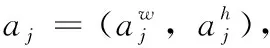
(2)
式中:j=1,2,…,m,m为数据集中所有类标注框的总和;Diag(j) 为所有标注框对应的对角线长度,表示框的大小。
设定3个聚类中心,利用K-means++算法对Diag(j) 聚类,分别得到小、中、大框的聚类中心C0={C1,C2,C3}, 再计算得到阈值Th
(3)
图2为IK-means++算法流程图,通过IK-means++聚类算法对实验室设备图像数据集的标注框进行聚类,得到先验框,效果较K-means和K-means++算法均有所提升,对比结果在后续章节给出。
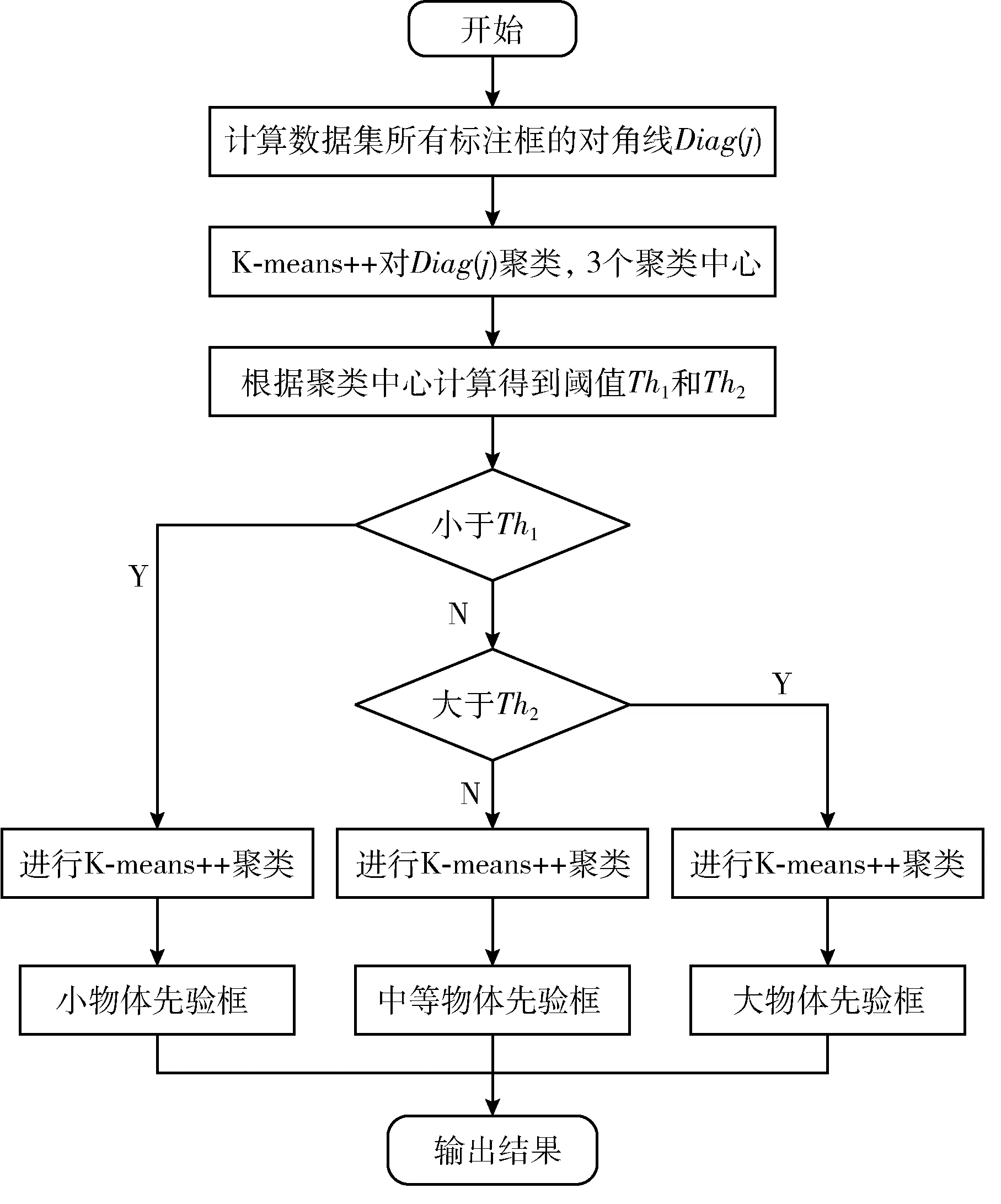
图2 IK-means++算法聚类流程
2.2 引入ECA通道注意力模块
为了进一步提高设备检测模型的精度,在主干网络中引入通道注意力机制;注意力机制借鉴了人类观察事物时,会倾向于有选择性地专注于其中一部分关键信息中的机制[15]。注意力机制可以有效提高深度学习模型的感知信息的效率和准确性。
ECA是目前注意力机制方向较新的研究成果,是在SE-Net[16]分组卷积的基础上,针对其降维操作会给通道注意力预测带来副作用的问题,提出的一种不需要进行降维、捕获了跨通道交互且轻量级的高效通道注意力模块,其结构如图3所示;ECA模块用W{k} 来表示学习到的通道注意力
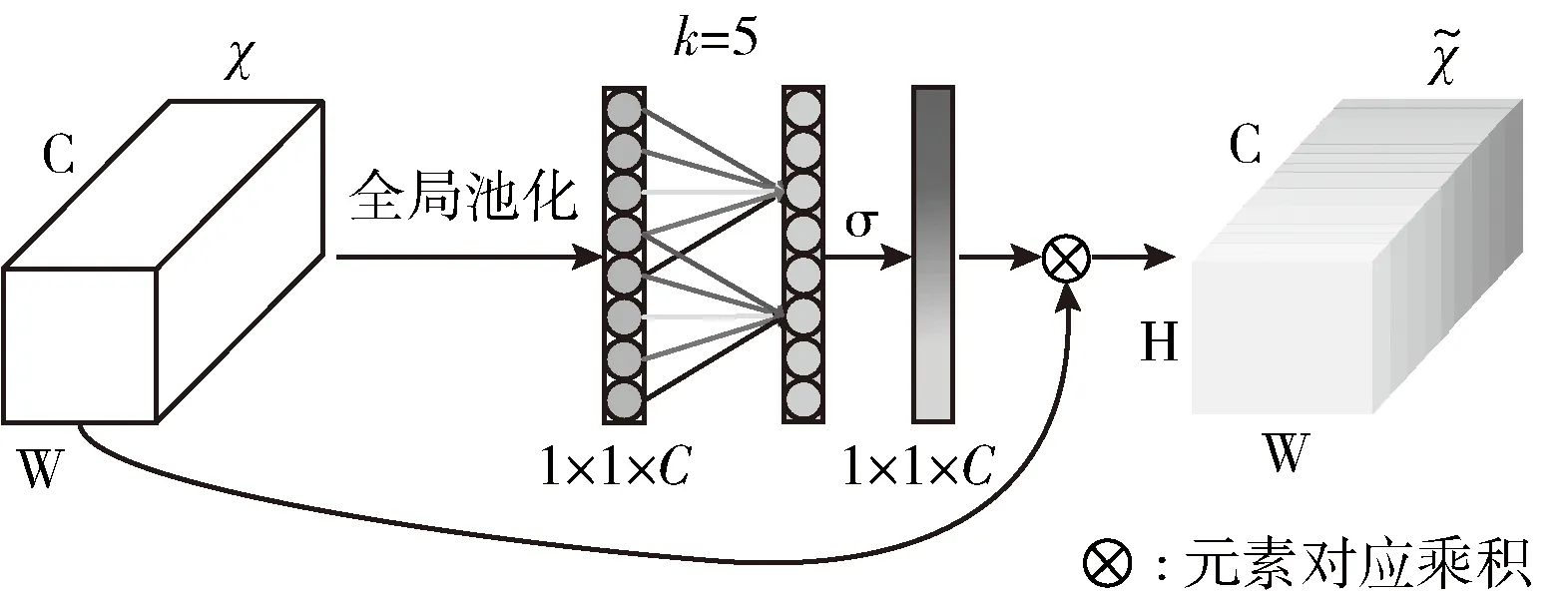
图3 ECA模块结构

(4)
W{k} 共涉及k*C个参数,k为卷积核大小,C为输入特征图的通道数,对于yi的权重,只考虑yi和它k个邻居之间的信息交互,且所有通道共享权重信息,即
(5)
YOLOv4的主干网络由多个不同深度的CSP残差结构组成,在其中引入ECA通道注意力模块,可以有效提高主干网络的特征提取及信息感知能力,图4为改进的ICSP-Darknet53的残差块堆叠部分结构图。
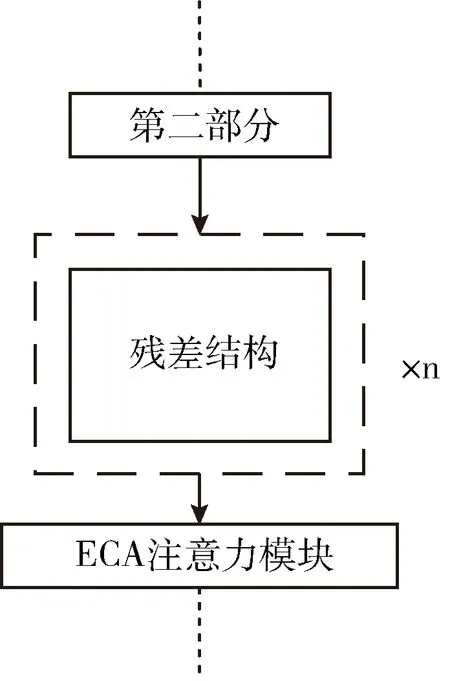
图4 引入ECA模块的ICSP残差堆叠部分结构
2.3 改进的L-FPG特征融合网格结构
不同尺度特征的融合是目标检测中提高模型性能的一个重要手段。不同尺度的特征图对原始图像特征的表达能力不同,浅层特征经过的卷积较少,噪声较多,语义信息低,但特征分辨率高,包含的位置、细节信息更多;而深层特征有更强的语义信息,但是特征分辨率低,对细节信息的表征能力较差,因此如何将两者有机融合,取长补短,是改善模型性能的关键。特征融合结构的发展从FPN特征金字塔[17]的提出到PANet创建自下而上的路径增强,再到ASFF[18]提出的自适应特征融合策略和Bi-FPN[19]在可学习参数的自适应加权融合基础上,增加跨层连接,使多个特征融合模块重复堆叠,进一步增强信息的融合,都逐步突出了深度特征金字塔的优异性能。
FPG是2020年4月提出的一种深层多路径特征金字塔,它将特征尺度空间表示为平行的多向横向连接的网格,实验结果表明了这种平行网格有效性,在提升速度和精度的基础上,也降低了模型的复杂度,其网格结构如图5所示;但过于深层的结构对模型性能的提升并不明显,因此本文在FPG的基础上,对网格结构进行简化,并结合YOLOv4的主干网络和检测头,提出了一种阶梯状特征融合网格结构L-FPG (Ladder-FPG, L-FPG),以加强检测模型对实验室设备特征的融合能力。
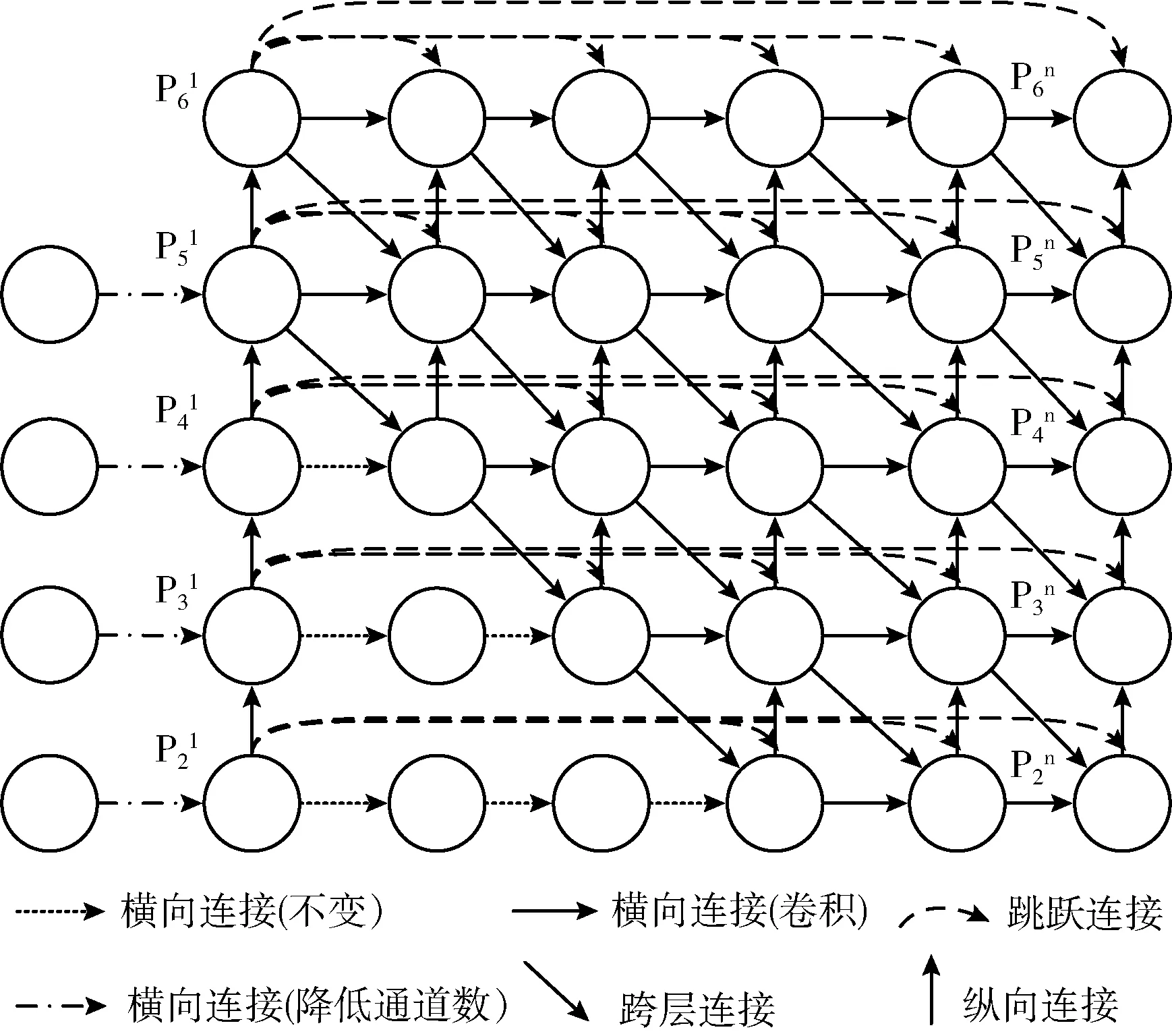
图5 原FPG网络结构
原网格结构中有9层,5个特征输出,较为复杂,不利于与YOLOv4检测头结合及后续模型的轻量化研究;因此改进简化后的L-FPG网络结构如图6所示,保留了原结构中的横向、向上、向下和不同层间的跳跃连接,中间层特征都由临近的4个特征相加得到,使得不同尺度的特征得到了有效融合,最终3个特征输出直接连接到YOLO检测头,整体呈阶梯状。
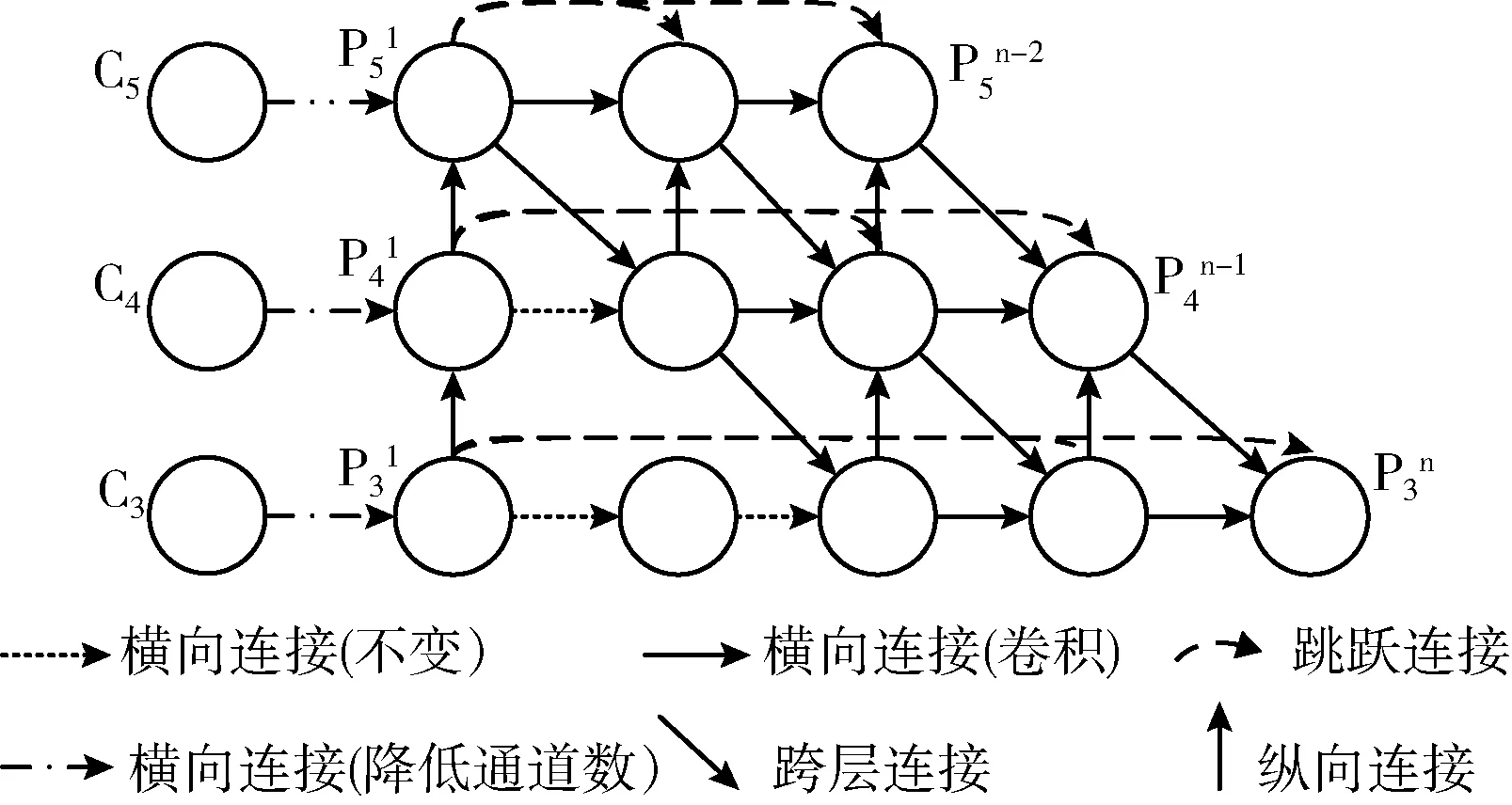
图6 改进的L-FPG网络结构
图6中各向连接具体操作如下:



3 实验与结果分析
3.1 数据集准备
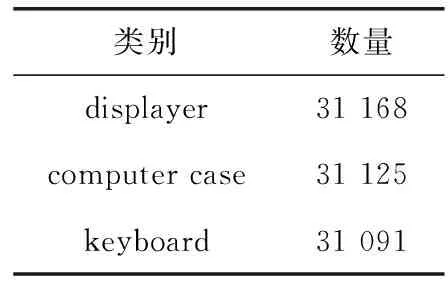
表1 训练集中各类别数量统计结果
3.2 IK-means聚类算法实验
在训练网络模型前,需对数据集按图2流程聚类得到9个先验框,根据式(2)对数据集标注框大小的定义,计算得到式(3)的阈值,将数据集按标注框大小划分为小、中、大框3个区间,如图7所示,图(a)为数据集标注框整体的分布散点图,可以看到整体分布并不均匀,且呈现非球状分布,这也是K-means算法聚类效果不佳的主要原因;图(b)~图(d)分别为数据集标注框按大小划分区间的尺寸分布散点图。
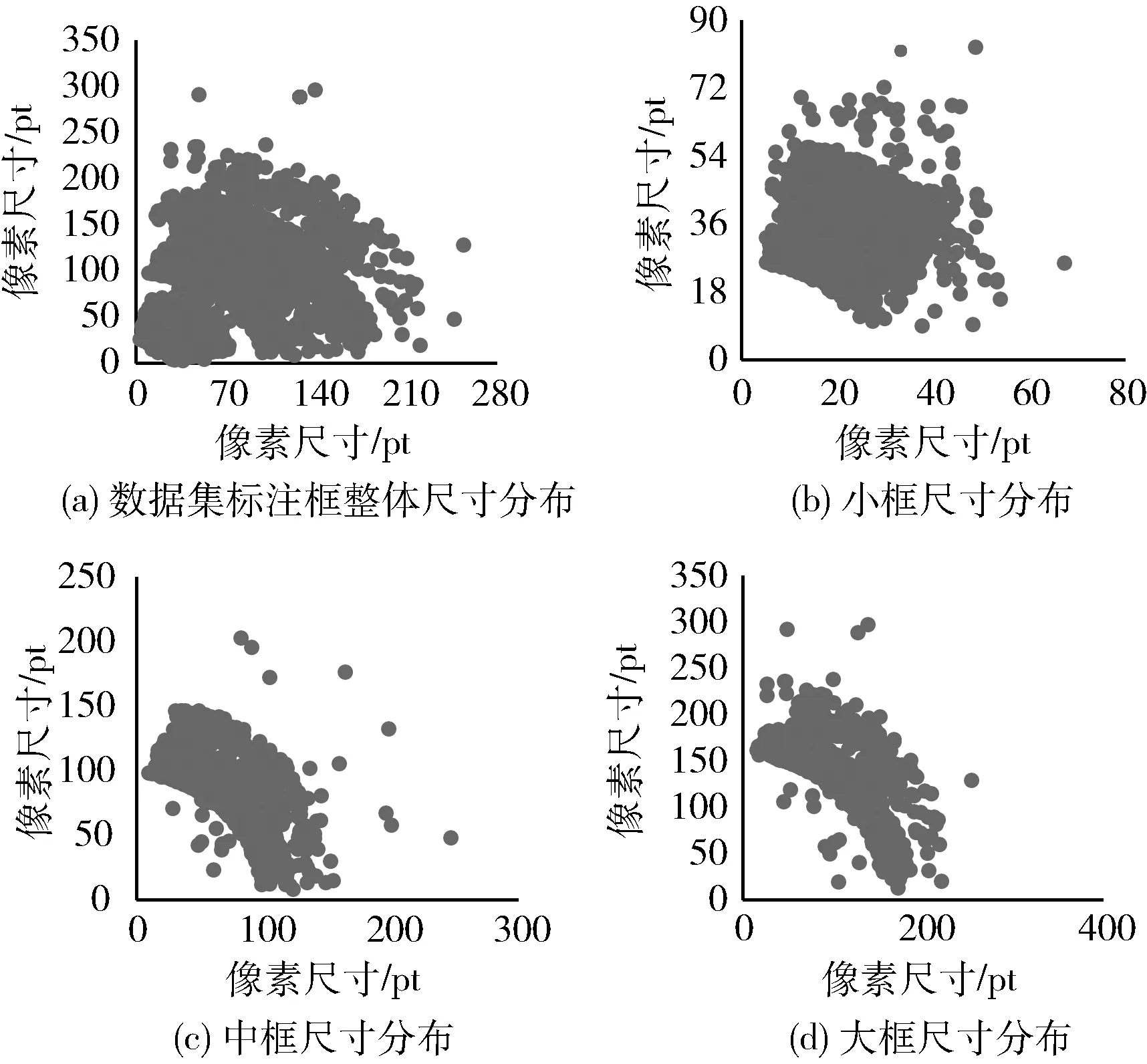
图7 数据集标注框按大小划分区间结果
根据区间划分结果,再分别进行K-mean++聚类,各得到3个聚类中心,以小框区间的聚类过程为例进行说明,迭代过程可视化如图8所示。
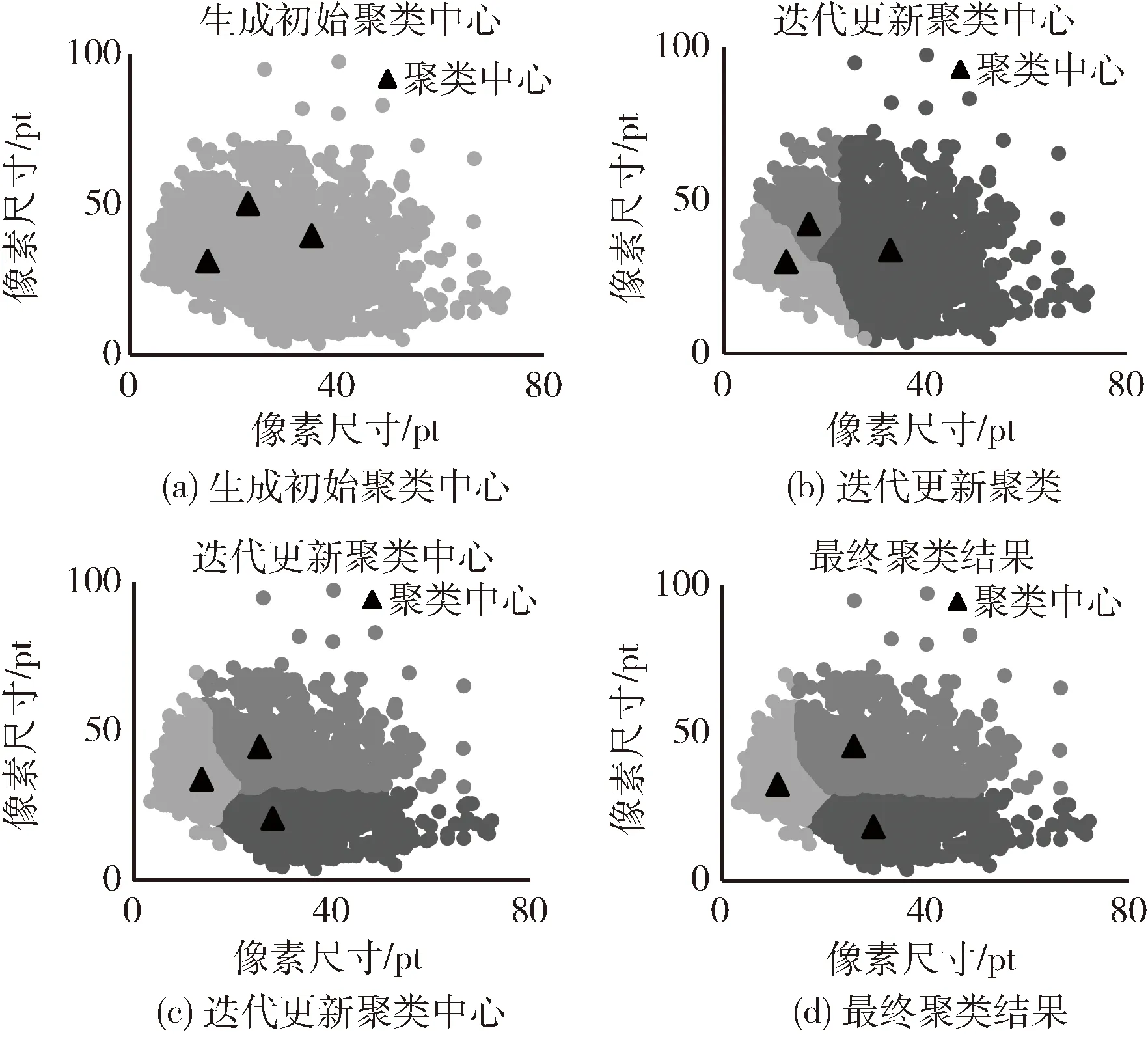
图8 先验框聚类过程可视化
首先,根据初始聚类中心之间距离越远被选择概率越高的思想,选择3个初始聚类中心,如图8(a)所示;然后计算所有点与聚类中心的距离,每个点将归属到距离最近的中心类簇,再计算每个类簇下的中位数,以更新聚类中心,并循环迭代直至中心点与上一次中心点一致,图8(b)、图8(c)为部分迭代过程;最后,当聚类中心不再发生变化时,得到最终聚类结果,如图8(d)所示。
中框和大框的聚类过程与此类似,由此可得到最终9组先验框聚类结果为:[13,29]、[20,44]、[33,29];[103,37]、[40,101]、[82,79];[55,161]、[91,146]、[141,105],两道阈值分别为90.3、224.2。
以Avg IOU[20]为评价指标评估IK-means++算法,假设先验框a=(aw,ah),box=(bw,bh), 则有
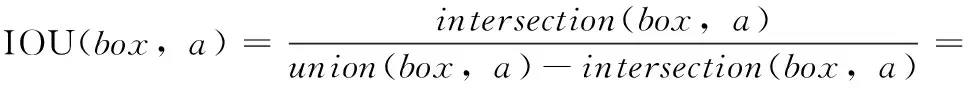
(6)
按式(6)计算每个先验框与对应区间内所有标注框的IOU,再得到Avg IOU的同时与K-means和K-means++算法聚类结果对比,结果见表2。
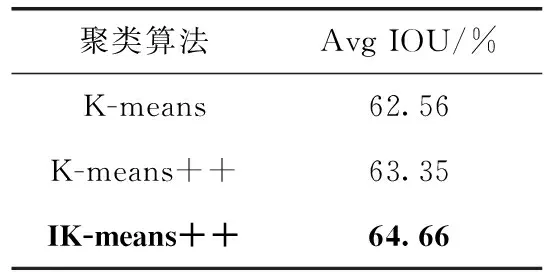
表2 先验框聚类算法结果对比
其中IK-means++算法在划分的小、中、大框区间内的聚类结果见表3。结果表明,改进的IK-means++算法在检测目标尺度分布不均匀的数据集中,相较于常用的K-means以及K-means++的聚类结果均有明显的提升。

表3 IK-means++各区间聚类结果
3.3 网络模型训练
本文在主干网络的CSP残差结构中引入了ECA通道注意力模块,提出改进的L-FPG特征融合网格,替换原PANet,同时去掉了原网络中的SPP结构,输入图像分辨率为416×416;图9为完整网络结构图。
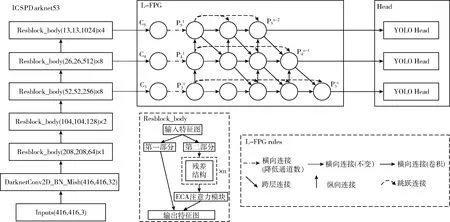
图9 改进YOLOv4的整体网络结构
本文实验平台为并行超算云平台的GPU服务器,主机配置为Gold 61系列v5@2.5 GHz,GPU为32 GB的NVIDIA®Tesla®V100,操作系统为CentOS7;采用Python平台的PyTorch深度学习库构建网络模型,训练时超参数设置如下:训练的epochs设置为100;batch size设置为64,初始学习率为0.001。
3.4 实验结果分析
在训练集上训练图9网络结构,训练的损失函数值如图10所示,模型从20 epoch开始逐渐收敛。结果表明:在同样预训练模型基础上,本文改进的YOLOv4收敛速度更快,最终的损失值更低,稳定在2.1左右。

图10 损失函数值随迭代次数的变化曲线
模型训练完成后,在测试集上与原YOLOv4算法进行对比,采用目标检测领域常用的mAP作为评价指标,计算公式如式(7)所示
(7)
式中:N表示N类检测目标,本文中共3类,即N=3;APi为3类检测目标对应的AP值。
模型的mAP对比结果见表4,结果表明,本文改进的网络模型与原YOLOv4相比mAP提高了3.65个百分点,同时由于改进YOLOv4算法的L-FPG网格中大量使用的是1*1卷积核,使得浮点运算数减少了25.1%,参数量下降了43.1%,FPS也提升了6.8帧。
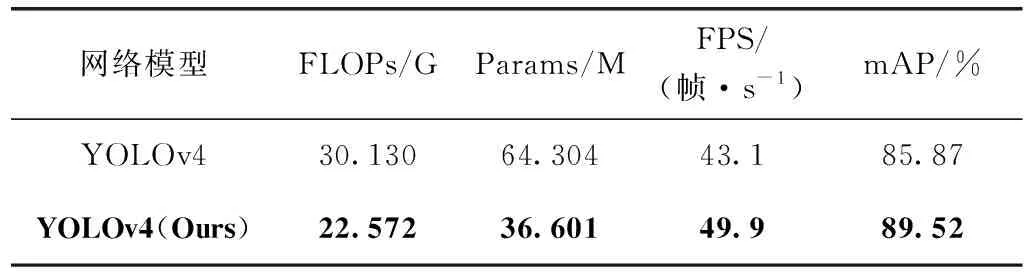
表4 实验对比数据
3.5 光线环境对比实验
由于实验室内不同时段光线不同,拍摄的图片亮度也不同,为了比较网络模型在不同光线环境下的检测性能,设计光线环境对比实验,分别取白天和傍晚拍摄的图片作实际检测对比,如图11所示,用不同颜色的矩形框表示不同设备类别;图11(a)为明亮场景原YOLOv4算法的检测结果,图11(b)为明亮场景改进YOLOv4算法的检测结果;图11(c)和图11(d)分为傍晚昏暗场景对应的检测结果;通过统计各个类别的准确率和误检率,可以更直观地比较网络模型性能,统计结果见表5、表6。

图11 不同光线环境下检测效果对比
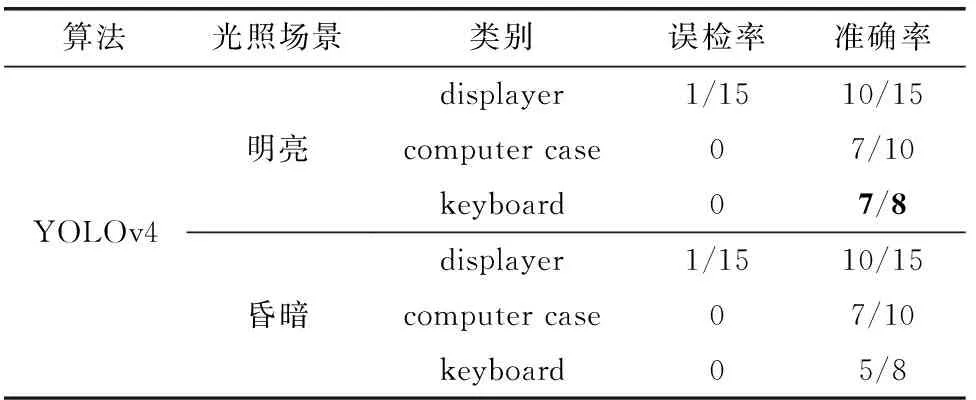
表5 原YOLOv4不同光照场景下检测结果对比
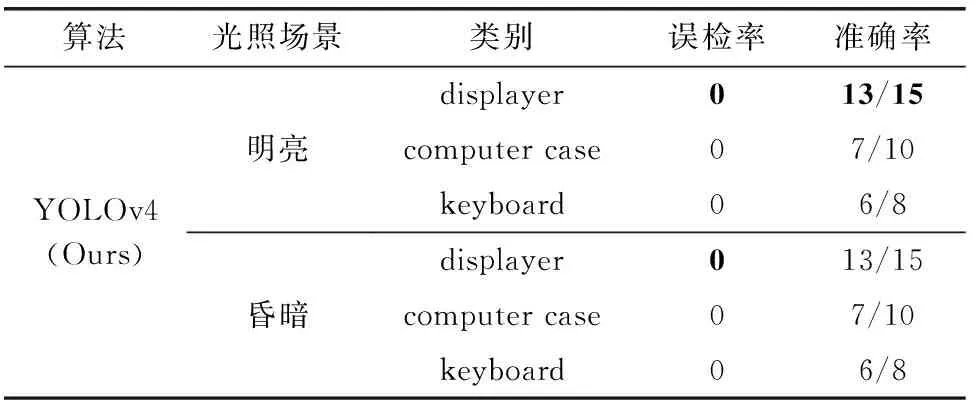
表6 改进YOLOv4不同光照场景下检测结果对比
由表5、表6对比结果可以发现,整体而言,共33个设备中,本文改进的YOLOv4算法在明亮和昏暗场景下的准确率都要更高,误检率更低,在昏暗环境下,整体检测结果与明亮环境相差不大,但置信度有所降低;而原YOLOv4算法在昏暗环境下检测效果下降明显,主要体现在对keyboard的识别率降低,并且将左上方的笔记本电脑检测为displayer,存在误检。对比结果表明本文改进后的网络结构面对不同光照环境条件的表现更稳定。
3.6 消融实验
消融实验是深度学习领域常用的实验方法,用来分析不同的网络分支对整个模型的影响[21]。为了进一步分析本文提出的IK-means++先验框聚类算法和ECA通道注意力模块以及改进的L-FPG特征融合网格对网络模型检测性能的影响,设计了消融实验,实验结果对比见表7。
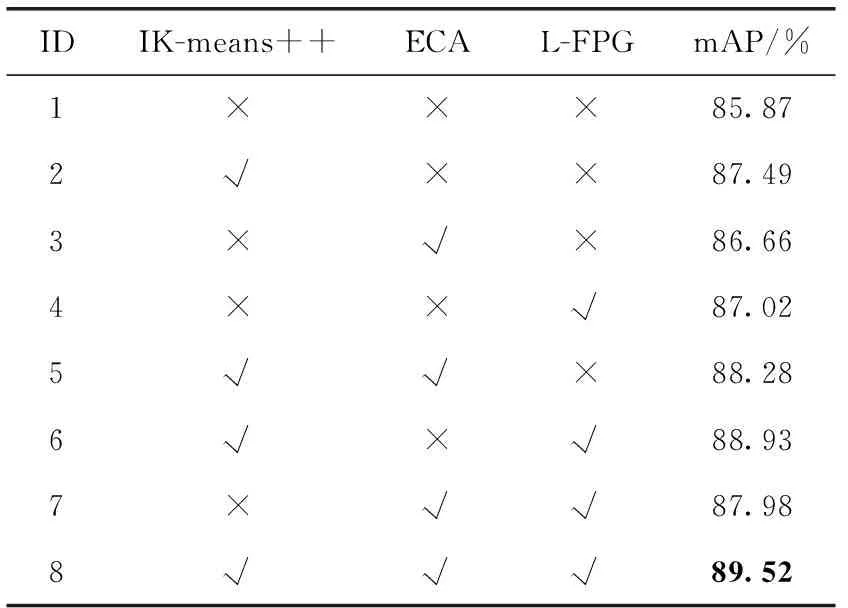
表7 消融实验中mAP结果对比
第1组为原YOLOv4算法检测结果,第2、第3、第4组分别为单独使用其中一种改进方法,相较于第一组,mAP分别提升了1.62、0.79、1.15个百分点,提升最大的是IK-means++先验框聚类算法,这是由于K-means算法适用于聚类对象分布均匀的情况,而本文计算机实验室场景下,电脑设备尺度分布并不均匀;IK-means++算法在K-means++优化了初始聚类中心选择的基础上,强制划分区间再进行聚类,减小了初始聚类中心选择的随机性和大小接近的物体被强制分配到不同检测头的情况,因此先验框聚类的结果表现更好,对模型检测精度的贡献也最大,这也说明先验框的选择对于模型的影响较为显著。
第5组~第7组分别为3种改进点的两两组合,均在一定程度上提升了检测精度,第8组为本文3种改进思路的结合,也是检测效果最好的一组,相较于第1组原算法,mAP提升了3.65个百分点。
4 结束语
针对实验室场景的设备检测,本文提出一种改进的YOLOv4算法,并以本校计算机实验室为研究对象,首先,提出了一种将数据集标注框按大小分布强制划分区间,再分别进行先验框聚类的IK-means++算法;其次,在主干网络的CSP残差结构中引入了ECA通道注意力模块,并提出了一种改进的阶梯状特征融合网格L-FPG。实验结果表明,本文提出的IK-means++算法对先验框的聚类效果要优于K-means和K-means++;同时ECA模块与L-FPG特征融合网格的引入,在降低了模型复杂度的基础上,FPS和mAP均得到提升,显著提高了YOLOv4算法在计算机实验室设备检测上的综合性能。在后续工作中,将主要研究如何进一步提高检测精度,且在不损失精度的同时对模型进行枝剪、轻量化,将模型实际部署到移动设备或嵌入式设备,同时分别以其它各类实验室为研究对象,增强适用性研究。
